कैमरे, घूमने वाले दरवाजे, लिफ्ट, तापमान सेंसर, अलार्म - ये सभी उपकरण बड़ी संख्या में परस्पर जुड़े हुए संकेत उत्पन्न करते हैं जो हमारे आसपास होने वाली घटनाओं से संबंधित होते हैं। अब कल्पना करें कि आप ही वह व्यक्ति हैं जिसे स्थिति को ट्रैक करने, रीयल-टाइम रिपोर्ट तैयार करने और इस सभी सिग्नल डेटा के आधार पर भविष्यवाणियां करने की आवश्यकता है। ऐसा करने के लिए, आपको सबसे पहले उस डेटा को स्टोर करना होगा। इस तरह के सिग्नल प्रोसेसिंग का समर्थन करने वाला डेटा मॉडल आज के लेख का विषय है।
आने वाले संकेतों को संग्रहीत करने का सबसे आसान तरीका केवल एक विशाल सूची में उनका पाठ्य प्रस्तुतिकरण संग्रहीत करना होगा। यह दृष्टिकोण हमें जल्दी से इन्सर्ट करने की अनुमति देगा, लेकिन अपडेट समस्याग्रस्त होंगे। साथ ही, ऐसे मॉडल को सामान्य नहीं किया जाएगा, और इसलिए हम उस दिशा में नहीं जाएंगे।
हम एक सामान्यीकृत डेटा मॉडल बनाएंगे जिसका उपयोग विभिन्न उपकरणों द्वारा उत्पन्न डेटा को संग्रहीत करने के लिए किया जा सकता है और यह भी परिभाषित किया जा सकता है कि उपकरण कैसे संबंधित हैं। ऐसा मॉडल हमारी जरूरत की हर चीज को कुशलता से संग्रहीत करेगा और विश्लेषण और भविष्य कहनेवाला विश्लेषण के लिए भी इस्तेमाल किया जा सकता है।
डेटा मॉडल
सिग्नल प्रोसेसिंग डेटा मॉडल
मॉडल में तीन विषय क्षेत्र होते हैं:
ComplexesInstallations & DevicesSignals & Events
हम इनमें से प्रत्येक विषय क्षेत्र को सूचीबद्ध क्रम में वर्णित करेंगे।
परिसर
इस डेटा मॉडल को बनाते समय, मैं इस धारणा के साथ गया था कि हम इसका उपयोग यह ट्रैक करने के लिए करेंगे कि बड़े परिसरों में क्या हो रहा है। एक कमरे से लेकर एक शॉपिंग मॉल तक परिसरों का आकार भिन्न होता है। यह ज़रूरी है कि हर कॉम्प्लेक्स में कम से कम एक डिवाइस/सेंसर हो, लेकिन उसमें कई और डिवाइस होने की संभावना है।
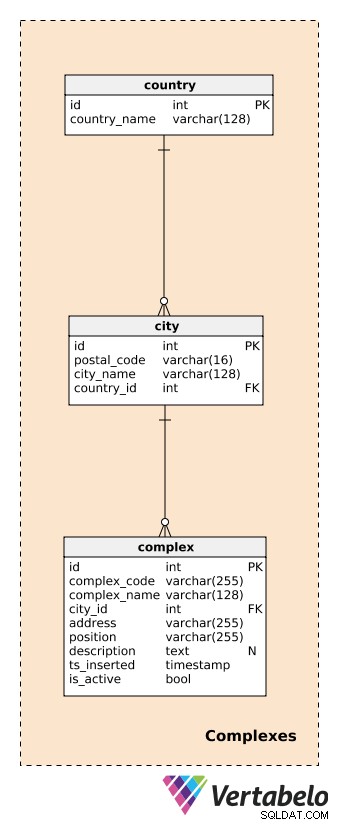
परिसरों का वर्णन करने से पहले, हमें देशों और शहरों को संभालने वाली तालिकाओं को परिभाषित करने की आवश्यकता है। ये प्रत्येक परिसर के स्थान का काफी विस्तृत विवरण प्रदान करेंगे।
प्रत्येक country , हम इसका UNIQUE country_name स्टोर करेंगे; प्रत्येक city , हम postal_code . के UNIQUE संयोजन को संग्रहित करेंगे , city_name , और country_id . मैं यहां विस्तार में नहीं जाऊंगा, और हम मान लेंगे कि प्रत्येक शहर में केवल एक डाक कोड होता है। वास्तव में, अधिकांश शहरों में एक से अधिक पोस्टल कोड होंगे; उस स्थिति में, हम प्रत्येक शहर के लिए मुख्य कोड का उपयोग कर सकते हैं।
एक Complexes वास्तविक भवन या स्थान है जहां डेटा-जनरेटिंग डिवाइस स्थापित हैं। जैसा कि पहले कहा गया है, कॉम्प्लेक्स एक कमरे या मापने के स्टेशन से लेकर बहुत बड़े स्थानों जैसे पार्किंग स्थल, शॉपिंग मॉल, सिनेमा आदि में भिन्न हो सकते हैं। वे हमारे विश्लेषण का विषय हैं। हम वास्तविक समय में जटिल स्तर पर क्या हो रहा है और बाद में रिपोर्ट और विश्लेषण तैयार करने में सक्षम होना चाहते हैं। प्रत्येक परिसर के लिए, हम परिभाषित करेंगे:
complex_code- प्रत्येक परिसर के लिए एक अद्वितीय पहचानकर्ता। जबकि हमारे पास एक अलग प्राथमिक कुंजी विशेषता है (id) इस तालिका के लिए, हम उम्मीद कर सकते हैं कि हम प्रत्येक परिसर के लिए दूसरे सिस्टम से एक और पहचान कोड प्राप्त करेंगे।complex_name- उस परिसर का वर्णन करने के लिए इस्तेमाल किया जाने वाला नाम। शॉपिंग मॉल और सिनेमा के मामले में, यह उनका वास्तविक और जाना-पहचाना नाम हो सकता है; मापन स्टेशन के लिए, हम एक सामान्य नाम का उपयोग कर सकते हैं।city_id- उस शहर का संदर्भ जहां परिसर स्थित है।address- उस परिसर का भौतिक पता।position- परिसर की स्थिति (अर्थात भौगोलिक निर्देशांक) पाठ्य प्रारूप में परिभाषित है।description- एक पाठ्य विवरण जो इस परिसर का अधिक बारीकी से वर्णन करता है।ts_inserted- एक टाइमस्टैम्प जब यह रिकॉर्ड डाला गया था।is_active- एक बूलियन मान यह दर्शाता है कि यह परिसर अभी भी सक्रिय है या नहीं।
इंस्टॉलेशन और डिवाइस
अब हम अपने मॉडल के दिल के करीब जा रहे हैं। हमारे पास प्रत्येक परिसर में कई उपकरण स्थापित होने की संभावना है। हम लगभग निश्चित रूप से इन उपकरणों को उनके उद्देश्य के आधार पर समूहित करेंगे - उदा। हम एक समूह में कैमरा, डोर सेंसर, और एक मोटर लगा सकते हैं जिसका उपयोग एक समूह में एक दरवाजा खोलने और बंद करने के लिए किया जाता है क्योंकि वे एक साथ काम करते हैं।
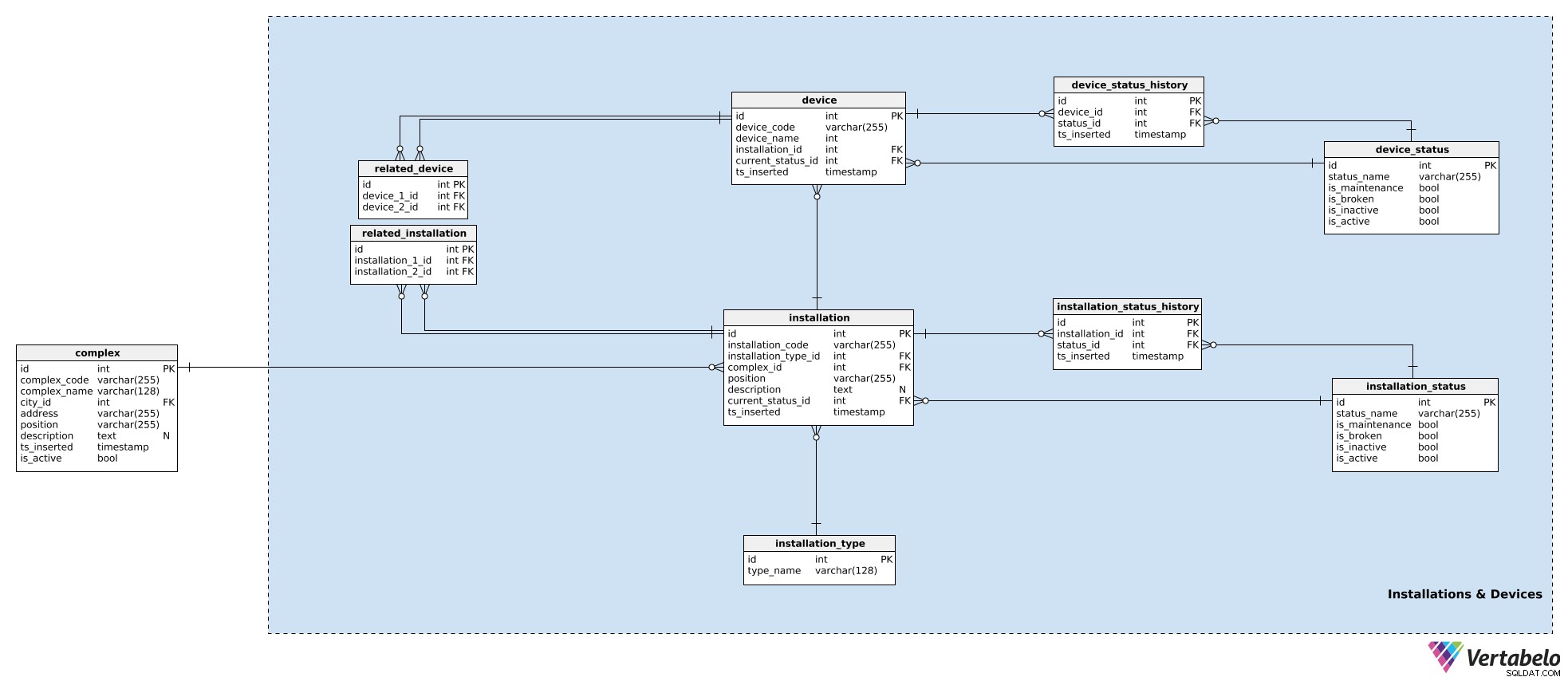
हमारे मॉडल में, एक कॉम्प्लेक्स में एक साथ काम करने वाले उपकरणों को इंस्टॉलेशन में समूहीकृत किया जाता है। ये सामने के दरवाजे, एस्केलेटर, तापमान सेंसर आदि के लिए हो सकते हैं। प्रत्येक इंस्टॉलेशन के लिए, हम निम्नलिखित विवरण installation टेबल:
installation_code- उस इंस्टॉलेशन को दर्शाने के लिए इस्तेमाल किया जाने वाला एक UNIQUE कोड।installation type_id-installation_typeशब्दकोश। यह डिक्शनरी केवल एक UNIQUEtype_namestores स्टोर करती है विशेषता जो प्रकार का वर्णन करती है, उदा। एस्केलेटर, लिफ्ट।complex_id-complexवह स्थापना संबंधित है।position- निर्देशांक, पाठ्य प्रारूप में, परिसर के अंदर उस संस्थापन के।description- उस स्थापना का पाठ्य विवरण।current_status_id- वर्तमान स्थिति का संदर्भ (installation_statusतालिका) उस स्थापना की।ts_inserted- एक टाइमस्टैम्प जब यह रिकॉर्ड हमारे सिस्टम में डाला गया था।
हमने पहले ही स्थापना स्थितियों का उल्लेख किया है। सभी संभावित स्थितियों की सूची installation_status शब्दकोश। प्रत्येक स्थिति को उसके status_name . द्वारा विशिष्ट रूप से परिभाषित किया जाता है . इसके अलावा, हम यह दर्शाते हुए फ़्लैग स्टोर करेंगे कि क्या उस स्थिति का, जब उपयोग किया जाता है, इसका अर्थ है कि इंस्टॉलेशन is_broken , is_inactive , is_maintenance , या is_active . इनमें से केवल एक झंडे को एक समय में सेट किया जाना चाहिए।
हमने पहले ही स्थापना को एक वर्तमान स्थिति निर्दिष्ट कर दी है। यदि हम ट्रैक करने जा रहे हैं कि डिवाइस के साथ क्या हो रहा है, तो हमें इसके इतिहास को भी स्टोर करना होगा। ऐसा करने के लिए, हम एक और तालिका का उपयोग करेंगे, installation_status_history . यहां प्रत्येक रिकॉर्ड के लिए, हम संबंधित इंस्टॉलेशन और स्थिति के साथ-साथ पल (ts_inserted) के संदर्भ संग्रहीत करेंगे। ) जब उस स्थिति को असाइन किया गया था।
प्रतिष्ठान हमारे परिसरों का हिस्सा हैं। जबकि प्रत्येक स्थापना एक एकल इकाई है, फिर भी यह अन्य स्थापनाओं से संबंधित हो सकती है। (उदाहरण के लिए एक शॉपिंग मॉल के सामने के प्रवेश द्वार पर एक वीडियो सिस्टम स्पष्ट रूप से मॉल के सामने के दरवाजे से संबंधित है - लोगों को पहले कैमरे द्वारा देखा जाएगा और फिर दरवाजे खुलेंगे।) अगर हम इन रिश्तों का ट्रैक रखना चाहते हैं, तो हम उन्हें स्टोर करेंगे related_installation टेबल। कृपया ध्यान दें कि इस तालिका में दो कुंजियों के केवल UNIQUE जोड़े हैं, दोनों installation टेबल।
उपकरणों को स्टोर करने के लिए एक ही तर्क का उपयोग किया जाता है। उपकरण हार्डवेयर के एकल टुकड़े होते हैं जो उन संकेतों को उत्पन्न करते हैं जिनमें हम रुचि रखते हैं। जबकि इंस्टॉलेशन कॉम्प्लेक्स से संबंधित होते हैं, डिवाइस इंस्टॉलेशन से संबंधित होते हैं। प्रत्येक device , हम स्टोर करेंगे:
device_code- प्रत्येक डिवाइस को दर्शाने का एक अनूठा तरीका।device_name- इस डिवाइस का एक नाम।installation_id- इस डिवाइस से संबंधित इंस्टॉलेशन का संदर्भ।current_status_id- डिवाइस की वर्तमान स्थिति।ts_inserted- एक टाइमस्टैम्प जब यह रिकॉर्ड डाला गया था।
इसी तरह से स्थितियों को संभाला जाता है। हम device_status सभी संभावित डिवाइस स्थितियों की सूची संग्रहीत करने के लिए तालिका। इस तालिका की संरचना वही है जो installation_status और गुणों का उसी तरह उपयोग किया जाता है। दो अलग-अलग स्टेटस डिक्शनरी होने का कारण यह है कि डिवाइस और उनके इंस्टॉलेशन की अलग-अलग स्थितियां हो सकती हैं - कम से कम नाम में।
वर्तमान स्थिति device.current_status_id . में संग्रहीत है विशेषता और स्थिति इतिहास device_status_history टेबल। यहां प्रत्येक रिकॉर्ड के लिए, हम डिवाइस और स्थिति के साथ-साथ इस रिकॉर्ड को सम्मिलित करने के क्षण के संबंध भी संग्रहीत करेंगे।
इस विषय क्षेत्र में अंतिम तालिका related_device टेबल। हालांकि यह बहुत स्पष्ट है कि एक ही इंस्टॉलेशन के अंदर सभी डिवाइस निकट से संबंधित हैं, मैं किसी भी इंस्टॉलेशन से संबंधित किन्हीं दो डिवाइसों को जोड़ने का विकल्प रखना चाहता हूं। हम इस तालिका में उनकी दो डिवाइस आईडी संग्रहीत करके ऐसा करेंगे।
सिग्नल और इवेंट
अब हम पूरी मॉडल के दिल के लिए तैयार हैं।
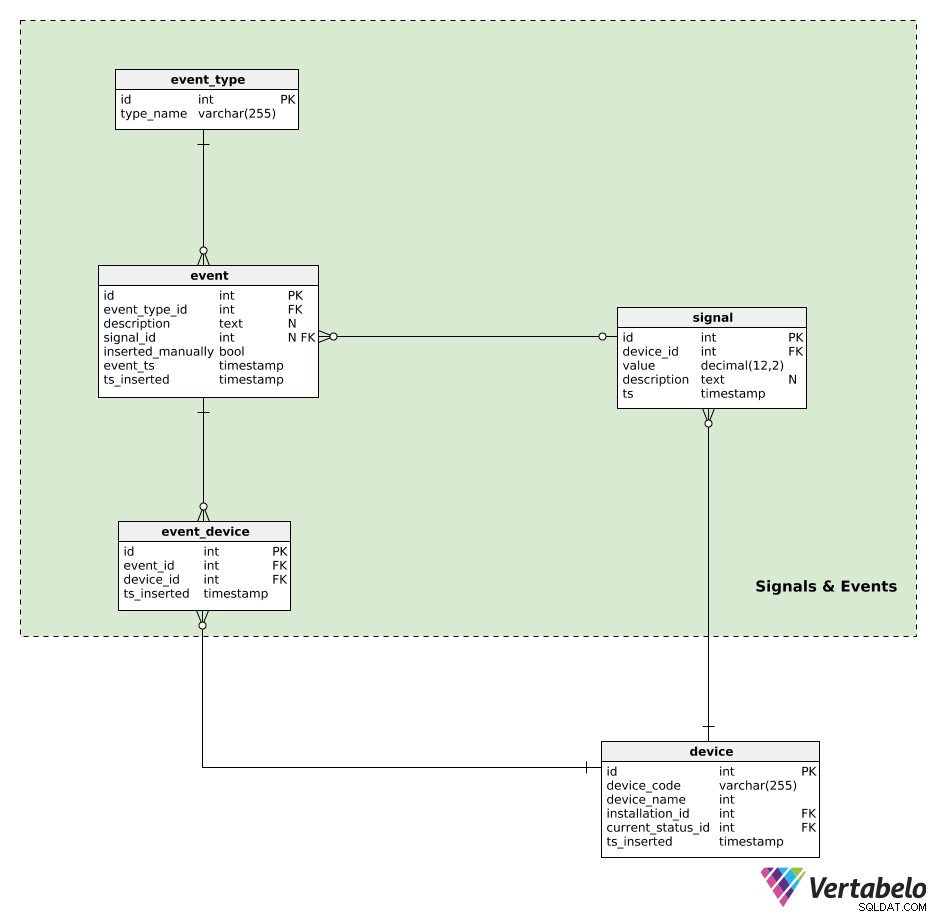
उपकरण संकेत उत्पन्न करते हैं। सभी सिग्नल डेटा signal टेबल। प्रत्येक सिग्नल के लिए, हम इसे स्टोर करेंगे:
device_id- उस उपकरण का संदर्भ जिसने उस संकेत को उत्पन्न किया।value- उस सिग्नल का संख्यात्मक मान।description- एक पाठ्य मान जिसमें उस एकल सिग्नल से संबंधित कोई अतिरिक्त पैरामीटर (जैसे सिग्नल प्रकार, मान, उपयोग की गई माप इकाई) शामिल हो सकते हैं। यह डेटा JSON जैसे प्रारूप में संग्रहीत किया जाता है।ts- एक टाइमस्टैम्प जब यह सिग्नल टेबल पर डाला गया था।
हम उम्मीद कर सकते हैं कि प्रति सेकंड बड़ी संख्या में इन्सर्ट किए जाने के साथ इस तालिका का अत्यधिक उपयोग होगा। इसलिए, डेटाबेस रखरखाव को इस तालिका के आकार को ट्रैक करने पर ध्यान देना चाहिए।
आखिरी चीज जो मैं करना चाहता हूं वह हमारे डेटा मॉडल में ईवेंट जोड़ना है। घटनाओं को स्वचालित रूप से एक संकेत द्वारा उत्पन्न किया जा सकता है या मैन्युअल रूप से डाला जा सकता है। एक स्वचालित रूप से उत्पन्न घटना "5 मिनट के लिए दरवाजा खुला" हो सकता है, जबकि मैन्युअल रूप से सम्मिलित घटना "इस सिग्नल के कारण डिवाइस को बंद करना पड़ा" हो सकता है। संपूर्ण विचार डिवाइस व्यवहार के परिणामस्वरूप होने वाली क्रियाओं को संग्रहीत करना है। बाद में, हम डिवाइस व्यवहार विश्लेषण करते समय इन घटनाओं का उपयोग कर सकते हैं।
इवेंट event_type . प्रत्येक प्रकार को उसके type_name . द्वारा अद्वितीय रूप से परिभाषित किया गया है ।
स्वचालित रूप से उत्पन्न या मैन्युअल रूप से सम्मिलित सभी ईवेंट event टेबल। यहां प्रत्येक रिकॉर्ड के लिए, हम स्टोर करेंगे:
event_type_id- संबंधित घटना प्रकार का संदर्भ।description- उस घटना का पाठ्य विवरण।signal_id- सिग्नल का संदर्भ, यदि कोई हो, जो घटना का कारण बना।inserted_manually- एक झंडा यह दर्शाता है कि यह रिकॉर्ड मैन्युअल रूप से डाला गया था या नहीं।event_tsऔरts_inserted-टाइमस्टैम्प जब यह घटना वास्तव में हुई थी और जब इसका रिकॉर्ड डाला गया था। ये दोनों अलग-अलग हो सकते हैं, खासकर जब इवेंट रिकॉर्ड मैन्युअल रूप से डाले जाते हैं।
हमारे मॉडल में अंतिम तालिका event_device टेबल। इस तालिका का उपयोग उन सभी उपकरणों के साथ घटनाओं को जोड़ने के लिए किया जाता है जो शामिल थे। प्रत्येक रिकॉर्ड के लिए, हम UNIQUE जोड़ी event_id . स्टोर करेंगे - device_id और टाइमस्टैम्प जब रिकॉर्ड डाला गया था।
आप हमारे सिग्नल प्रोसेसिंग डेटा मॉडल के बारे में क्या सोचते हैं?
आज, हमने एक सरलीकृत डेटा मॉडल का विश्लेषण किया है जिसका उपयोग हम विभिन्न स्थानों में स्थापित उपकरणों के एक सेट से संकेतों को ट्रैक करने के लिए कर सकते हैं। स्थिति को ट्रैक करने और विश्लेषण करने के लिए हमें जो कुछ भी चाहिए, उसे स्टोर करने के लिए मॉडल ही पर्याप्त होना चाहिए। फिर भी, बहुत सारे सुधार संभव हैं। हम क्या जोड़ सकते हैं? कृपया हमें नीचे कमेंट्स में बताएं।



