कौन सा डेटा मॉडल आपको आराम से पुस्तकों की खोज करने और उन्हें अपने स्थानीय पुस्तकालय में उधार लेने की अनुमति देगा?
क्या आप कभी किसी पुस्तकालय में गए हैं और कोई पुस्तक उधार ली है? हो सकता है कि तत्काल इंटरनेट ज्ञान और ई-पुस्तकों की आज की दुनिया में यह पुराने जमाने का लगता हो। लेकिन मुझे यकीन है कि आप का यह एनालॉग हिस्सा अभी भी है जो अभी भी किताबों को सूंघना, छूना और पढ़ना पसंद करता है। या हो सकता है कि जब आपको इंटरनेट पर कुछ नहीं मिला तो आपको पुस्तकालय का उपयोग करने के लिए मजबूर होना पड़ा! हाँ, सब कुछ ऑनलाइन नहीं है।
तो, एक डेटा मॉडल पुस्तकालय की पुस्तकों और ऋणों को कैसे व्यवस्थित करेगा? आइए इस मॉडल के बारे में जानें और देखें कि यह कैसे काम करता है!
डेटा मॉडल
जब मैंने यह डेटा मॉडल बनाया तो मेरे दिमाग में सार्वजनिक पुस्तकालय थे। एक धारणा है कि सार्वजनिक पुस्तकालय नेटवर्क में प्रत्येक पुस्तकालय एक ही मॉडल/प्रणाली का उपयोग करता है। यह केंद्रीकृत है और सदस्यों को नेटवर्क में प्रत्येक पुस्तकालय के संग्रह को ब्राउज़ करने की अनुमति देता है। साथ ही, सदस्य नेटवर्क के किसी भी पुस्तकालय से पुस्तकें उधार ले सकते हैं।
पुस्तकालय डेटा मॉडल में दो विषय क्षेत्रों में विभाजित तेरह टेबल होते हैं। वे क्षेत्र हैं:
Books & LibrariesMembers & Loans
हम प्रत्येक विषय क्षेत्र को अलग-अलग देखेंगे और सभी विवरणों का विश्लेषण करेंगे।
किताबें और पुस्तकालय
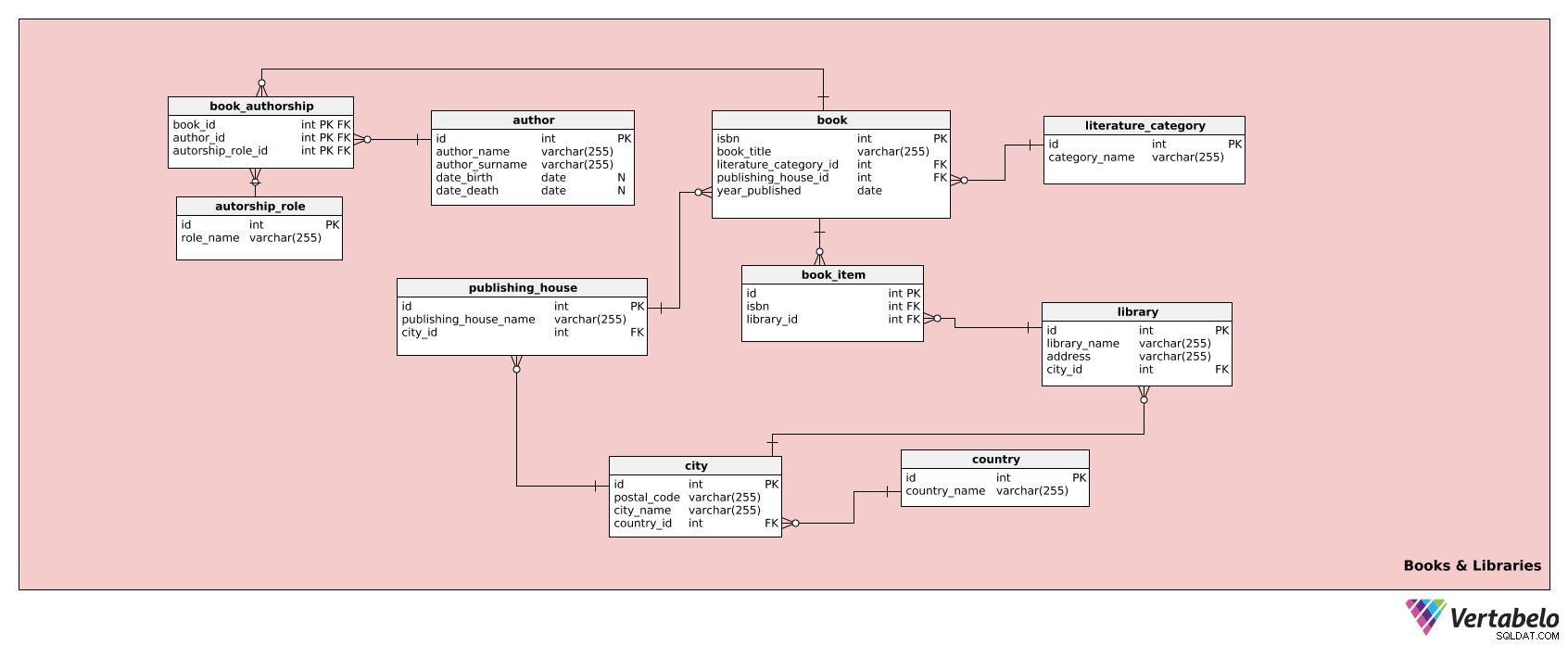
यह विषय क्षेत्र पुस्तकों और पुस्तकालयों के बारे में जानकारी संग्रहीत करता है। इसमें दस टेबल होते हैं:
authorauthorship_roleliterature_categorybookbook_authorshipbook_itempublishing_houselibrarycitycountry
पहली तालिका है author टेबल। यह पुस्तकालय के संग्रह में मौजूद पुस्तकों के सभी लेखकों (साथ ही उनके प्रासंगिक विवरण) को सूचीबद्ध करता है। प्रत्येक लेखक के लिए, हमारे पास होगा:
id- उस लेखक के लिए एक अद्वितीय आईडी।author_name- लेखक का पहला नाम।author_surname- लेखक का उपनाम।date_birth- लेखक की जन्मतिथि।date_death- लेखक की मृत्यु की तिथि।
authorship_role तालिका उन सभी भूमिकाओं को सूचीबद्ध करती है जो एक लेखक की हो सकती है, उदा। लेखक, सह-लेखक, आदि। इस तालिका में निम्नलिखित विशेषताएं हैं:
id- प्रत्येक भूमिका के लिए एक अद्वितीय आईडी।role_name- उस भूमिका का नाम, उदा. "सह-लेखक"। यह तालिका की वैकल्पिक कुंजी है।
तालिका literature_category सभी पुस्तक श्रेणियों को सूचीबद्ध करता है, उदा। थ्रिलर, फ्रांसीसी साहित्य, रूसी यथार्थवाद, दर्शन, आदि। तालिका में निम्नलिखित विशेषताएं हैं:
id- उस श्रेणी के लिए एक विशिष्ट आईडी।category_name- श्रेणी का नाम, उदा। "रहस्य"। यह तालिका की वैकल्पिक कुंजी है।
इसके बाद, हमारे पास book टेबल। यह तालिका पुस्तकालय के संग्रह में मौजूद प्रत्येक शीर्षक के सभी प्रासंगिक विवरणों को संग्रहीत करती है। कृपया ध्यान दें कि यह प्रत्येक पुस्तक के लिए एक आइटम के रूप में उपयोग की जाने वाली तालिका नहीं है। उसके लिए, हम एक अन्य तालिका का उपयोग करेंगे, जिसका नाम है book_item टेबल। book तालिका में विशेषताएँ होती हैं:
isbn- प्रत्येक पुस्तक शीर्षक के लिए एक विशिष्ट आईडी, जो प्रकाशन उद्योग में अंतर्राष्ट्रीय मानक पुस्तक संख्या (ISBN) है।book_title- किताब का शीर्षक।literature_category_id- संदर्भliterature_categoryटेबल.publishing_house_id- संदर्भpublishing_houseटेबल.year_published- वह वर्ष जब पुस्तक प्रकाशित हुई थी।
हमारे मॉडल में अगली तालिका book_authorship टेबल। यह एक चौराहा तालिका है जो book , author , और authorship_role टेबल। इसमें निम्नलिखित विशेषताएं शामिल हैं:
book_id- संदर्भbookटेबल.author_id- संदर्भauthorटेबल.authorship_role_id- संदर्भauthorship_roleटेबल.
ये तीन विशेषताएँ मिलकर तालिका की समग्र प्राथमिक कुंजी बनाती हैं। एक समग्र प्राथमिक कुंजी का अर्थ है कि तीनों विशेषताओं का कोई भी संयोजन अद्वितीय होना चाहिए; प्रत्येक संयोजन केवल एक बार हो सकता है।
आइए अब book_item तालिका, जिसका उल्लेख हमने पहले पुस्तकालय में प्रत्येक भौतिक पुस्तक के लिए जानकारी संग्रहीत करने के रूप में किया था। इसमें निम्नलिखित जानकारी होगी:
id- प्रत्येक पुस्तक के लिए एक आइटम के रूप में एक अद्वितीय आईडी।isbn- संदर्भbookटेबल.library_id- संदर्भlibraryटेबल.
हमारे मॉडल में The publishing_house table is the next one in our model. It lists the publishers of all the books that the library has in its collection. The attributes in the table are as follows: तालिका हमारे मॉडल में अगला है। यह उन सभी पुस्तकों के प्रकाशकों को सूचीबद्ध करता है जो पुस्तकालय के संग्रह में हैं। तालिका में विशेषताएँ इस प्रकार हैं:
id- हर पब्लिशिंग हाउस के लिए एक यूनिक आईडी।publishing_house_name- प्रकाशन गृह का नाम (जैसे पेंगुइन बुक्स, मैकग्रा-हिल, साइमन एंड शूस्टर, आदि)।city_id- संदर्भcityटेबल। यह कनेक्शन हमें पब्लिशिंग हाउस के शहर और देश दोनों का निर्धारण करने की भी अनुमति देगा।publishing_house_name-city_idजोड़ी इस तालिका की वैकल्पिक कुंजी है।
ठीक है, चलिए library टेबल। यह तालिका book_item तालिका, जहां यह पुस्तकालय को परिभाषित करती है जहां पुस्तक की प्रत्येक प्रति रखी जाती है। इसकी आवश्यकता है क्योंकि एक ही पुस्तक के शीर्षक एक नेटवर्क में एक से अधिक पुस्तकालय में पाए जा सकते हैं (उदाहरण के लिए प्रत्येक पुस्तकालय में शायद द लॉर्ड ऑफ द रिंग्स की कम से कम एक प्रति है। ) इसलिए हमें यह जानना होगा कि कौन सी किताब किस पुस्तकालय में है। इसे पूरा करने के लिए, हमें निम्नलिखित विशेषताओं की आवश्यकता होगी:
id- पुस्तकालय के लिए एक विशिष्ट आईडी।library_name- उस पुस्तकालय का नाम।address- उस पुस्तकालय का पता।city_id- संदर्भcityटेबल।library_name-city_idजोड़ी इस तालिका की वैकल्पिक कुंजी है।
इस मॉडल की अगली तालिका city टेबल। यह शहरों की एक सरल सूची है जिसका उपयोग हम प्रकाशकों, पुस्तकालयों और पुस्तकालय के सदस्यों के बारे में जानकारी के लिए करेंगे। विशेषताएं हैं:
id- शहर के लिए एक विशिष्ट आईडी।postal_code- उस शहर का पोस्टल कोड।city_name- उस शहर का नाम।country_id- संदर्भcountryटेबल.
उसके बाद, इस विषय क्षेत्र में केवल एक तालिका बची है:country टेबल। यह उन सभी देशों की सूची है जहां हमारे पुस्तकालय और/या पुस्तक प्रकाशक स्थित हैं। इसमें निम्नलिखित विशेषताएं शामिल हैं:
id- प्रत्येक देश के लिए एक विशिष्ट आईडी।country_name- देश का नाम। यह तालिका की वैकल्पिक कुंजी है।
इसके बाद, आइए दूसरे विषय क्षेत्र की जाँच करें।
सदस्य और ऋण
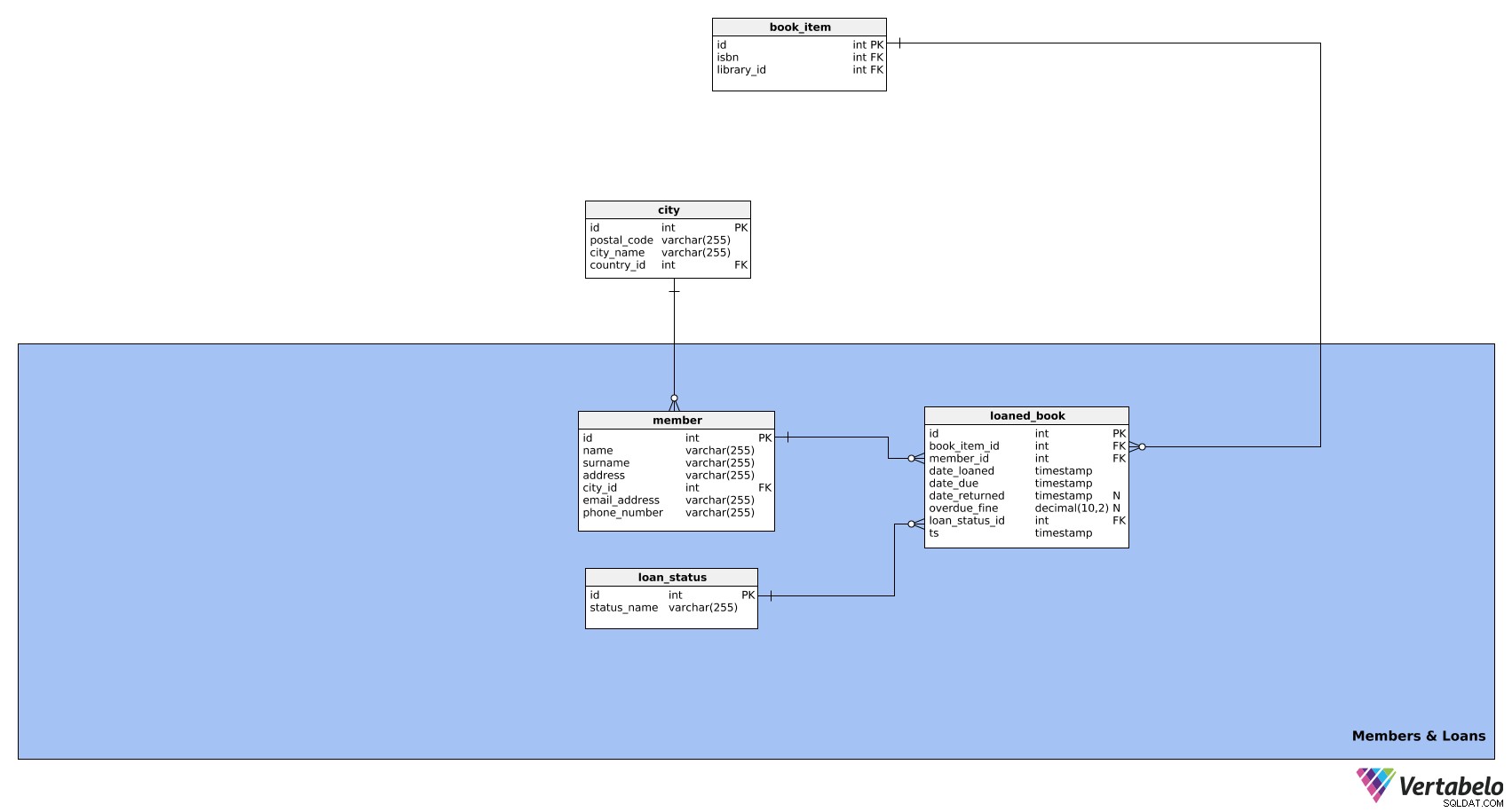
इस विषय क्षेत्र का उद्देश्य पुस्तकालय के सदस्यों और उनके द्वारा उधार ली गई पुस्तकों के बारे में जानकारी का प्रबंधन करना है। इसमें तीन टेबल होते हैं:
memberloaned_bookloan_status
अब टेबल के बारे में बात करते हैं।
इस क्षेत्र में पहली तालिका है member टेबल। इसमें पुस्तकालय के सदस्यों के बारे में सभी प्रासंगिक जानकारी शामिल है। इसकी विशेषताएँ इस प्रकार हैं:
id- प्रत्येक सदस्य के लिए एक विशिष्ट आईडी।name- सदस्य का पहला नाम।surname- सदस्य का उपनाम।address- सदस्य का पता।city_id- संदर्भcityटेबल.email_address- सदस्य का ईमेल पता।phone_number- सदस्य का फोन नंबर।
अगली तालिका है loaned_book टेबल। यह उन सभी पुस्तकों के बारे में जानकारी संग्रहीत करता है जिन्हें कभी उधार दिया गया है। इस तरह, हम पुस्तकालय की सूची और किसी भी उधार ली गई पुस्तकों की स्थिति पर नज़र रख सकते हैं। इस तालिका में निम्नलिखित विशेषताएं हैं:
id- उधार ली गई प्रत्येक पुस्तक के लिए एक अद्वितीय आईडी।book_item_id- संदर्भbook_itemटेबल.member_id- संदर्भmemberटेबल.date_loaned- वह तारीख जब यह किताब उधार ली गई थी।date_due- वह तिथि जब यह पुस्तक लौटा दी जानी चाहिए।date_returned- वह तिथि जब पुस्तक को वास्तव में पुस्तकालय में वापस किया गया था; यह NULL हो सकता है क्योंकि जब तक किताब वापस नहीं हो जाती तब तक हमें तारीख का पता नहीं चलेगा।overdue_fine- सदस्य द्वारा भुगतान किया गया विलंब शुल्क (यदि कोई हो), जिसकी गणना आमतौर परdate_returnedके बीच के अंतर के आधार पर की जाती है औरdate_due. यह NULL हो सकता है क्योंकि समय पर लौटाई गई किताब पर कोई जुर्माना नहीं है।loan_status_id- संदर्भloan_statusटेबल.ts- वह टाइमस्टैम्प जब उस ऋण की स्थिति दर्ज की गई थी।
loan_status तालिका हमारे डेटा मॉडल में अंतिम है। यह केवल सभी संभावित ऋण स्थितियों की एक सूची है, उदा। सक्रिय, अतिदेय, लौटाए गए, आदि। इस तालिका में निम्नलिखित विशेषताएं शामिल होंगी:
id- प्रत्येक ऋण स्थिति के लिए एक विशिष्ट आईडी।status_name- ऋण की स्थिति का वर्णन करने वाला नाम। यह तालिका की वैकल्पिक कुंजी है।
बस इतना ही - हमने अपने डेटा मॉडल के सभी विवरणों को पढ़ लिया है!
लाइब्रेरी डेटा मॉडल के बारे में आप क्या सोचते हैं?
हमने इस मॉडल में सामान्य सिद्धांतों को शामिल किया है, इसलिए यह प्रत्येक पुस्तकालय के लिए (कुछ बदलावों के साथ) होना चाहिए। क्या आप किसी पुस्तकालय की विशिष्टताओं के बारे में जानते हैं जो हमसे छूट गई हैं? या हो सकता है कि आपने मॉडल को उपयोगी और आसानी से लागू पाया हो? कमेंट सेक्शन में अपनी बात रखें।