क्या आप सीखना चाहते हैं कि डेटाबेस सिस्टम को कैसे डिज़ाइन किया जाए और डेटा मॉडल में व्यावसायिक प्रक्रिया को कैसे मैप किया जाए? तो यह पोस्ट आपके लिए है।
इस लेख में, आप देखेंगे कि किसी भर्ती कंपनी के लिए एक साधारण डेटाबेस स्कीमा कैसे डिज़ाइन किया जाए। इस ट्यूटोरियल को पढ़ने के बाद, आप यह समझने में सक्षम होंगे कि वास्तविक दुनिया के अनुप्रयोगों के लिए डेटाबेस स्कीमा कैसे डिज़ाइन किए जाते हैं।
भर्ती प्रणाली व्यवसाय प्रक्रिया
किसी भी डेटाबेस या डेटा मॉडल को डिजाइन करने से पहले, उस सिस्टम के लिए बुनियादी व्यावसायिक प्रक्रिया को समझना अनिवार्य है। हम जो डेटाबेस स्कीमा बनाएंगे वह एक काल्पनिक भर्ती कंपनी या टीम के लिए है। आइए पहले नए कर्मचारियों को काम पर रखने में शामिल चरणों को देखें:
- कंपनियां अपनी ओर से भर्ती करने के लिए भर्ती एजेंसियों से संपर्क करती हैं। कुछ मामलों में, कंपनियां सीधे कर्मचारियों की भर्ती करती हैं।
- भर्ती के लिए जिम्मेदार व्यक्ति भर्ती प्रक्रिया शुरू करता है। इस प्रक्रिया में कई चरण हो सकते हैं, जैसे प्रारंभिक स्क्रीनिंग, एक लिखित परीक्षा, पहला साक्षात्कार, अनुवर्ती साक्षात्कार, वास्तविक भर्ती निर्णय, आदि।
- एक बार जब रिक्रूटर्स किसी विशेष प्रक्रिया पर सहमत हो जाते हैं - और यह क्लाइंट, कंपनी या प्रश्न में नौकरी के आधार पर बदल सकता है - विभिन्न प्लेटफार्मों पर रिक्ति का विज्ञापन किया जाता है।
- आवेदक नौकरी के लिए आवेदन करना शुरू करते हैं।
- आवेदकों को शॉर्टलिस्ट किया जाता है और एक परीक्षा या प्रारंभिक साक्षात्कार के लिए आमंत्रित किया जाता है।
- आवेदक परीक्षा/साक्षात्कार के लिए उपस्थित होते हैं।
- परीक्षणों को भर्ती करने वालों द्वारा वर्गीकृत किया जाता है। कुछ मामलों में, विशेषज्ञों को ग्रेडिंग के लिए परीक्षण भेजे जाते हैं।
- आवेदकों के साक्षात्कार एक या अधिक नियोक्ताओं द्वारा प्राप्त किए जाते हैं।
- आवेदकों का मूल्यांकन परीक्षण और साक्षात्कार के आधार पर किया जाता है।
- नियुक्ति का निर्णय लिया जाता है।
एक भर्ती प्रणाली डेटाबेस स्कीमा
उपरोक्त प्रक्रिया को ध्यान में रखते हुए, हमारे डेटाबेस स्कीमा को पांच विषय क्षेत्रों में विभाजित किया गया है:
ProcessJobsApplication, Applicant, and DocumentsTest and InterviewsRecruiters and Application Evaluation
हम इनमें से प्रत्येक क्षेत्र की विस्तार से समीक्षा करेंगे, जिस क्रम में वे सूचीबद्ध हैं। नीचे, आप संपूर्ण डेटा मॉडल देख सकते हैं।
प्रक्रिया
प्रक्रिया श्रेणी में भर्ती प्रक्रियाओं से संबंधित जानकारी होती है। इसमें तीन टेबल हैं:Process , step , और process_step . हम हर एक को देखेंगे।
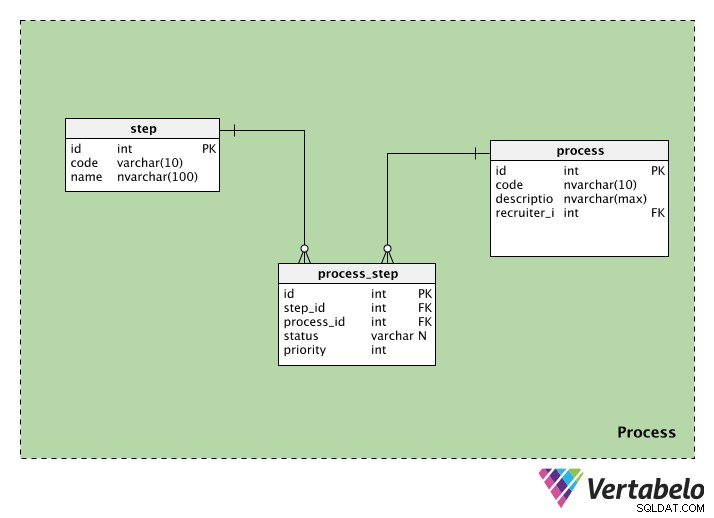
process तालिका प्रत्येक भर्ती प्रक्रिया के बारे में जानकारी संग्रहीत करती है। प्रत्येक प्रक्रिया में एक विशेष आईडी, एक कोड और एक description होगा उस प्रक्रिया का। हमारे पास recruiter_id भी होगा प्रक्रिया शुरू करने वाले व्यक्ति की।
step तालिका में उस भर्ती प्रक्रिया के दौरान अपनाए गए चरणों के बारे में जानकारी है। प्रत्येक चरण में एक id होता है और एक code नाम। नाम कॉलम में "प्रारंभिक स्क्रीनिंग", "लिखित परीक्षा", "एचआर साक्षात्कार" आदि जैसे मान हो सकते हैं।
चूंकि एक प्रक्रिया में कई चरण हो सकते हैं और एक चरण कई प्रक्रियाओं का हिस्सा हो सकता है, इसलिए हमें एक लुकअप तालिका की आवश्यकता है। process_step तालिका में प्रत्येक चरण के बारे में जानकारी होती है (step_id . में) ) और यह जिस प्रक्रिया से संबंधित है (process_id . में) ) हमारे पास एक स्थिति भी है, जो हमें उस प्रक्रिया में उस चरण की स्थिति बताती है; यदि चरण अभी तक प्रारंभ नहीं हुआ है तो यह NULL हो सकता है। अंत में, हमारे पास priority है , जो हमें बताता है कि किस क्रम में चरणों को निष्पादित करना है। उच्चतम priority . वाले चरण मान पहले निष्पादित किया जाएगा।
नौकरियां
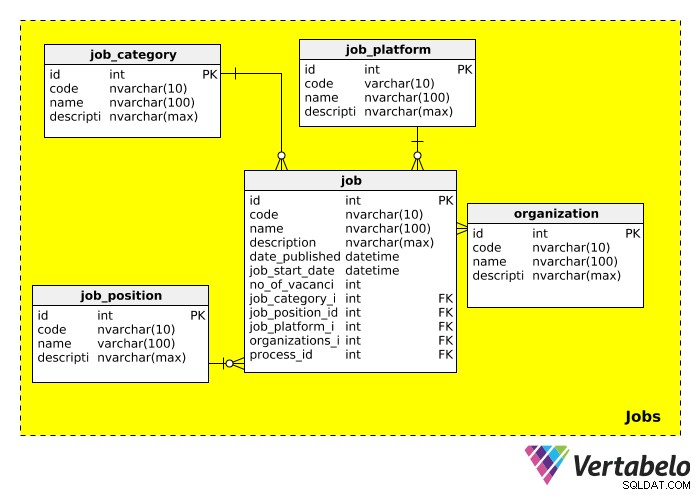
आगे हमारे पास Jobs विषय क्षेत्र, जो उस नौकरी से संबंधित सभी जानकारी संग्रहीत करता है जिसके लिए हम भर्ती कर रहे हैं। इस श्रेणी के लिए स्कीमा इस तरह दिखता है:
आइए प्रत्येक तालिका को विस्तार से समझाएं।
job_category तालिका मोटे तौर पर नौकरी के प्रकार का वर्णन करती है। हम "आईटी", "प्रबंधन", "वित्त", "शिक्षा", आदि जैसी नौकरी श्रेणियों को देखने की उम्मीद कर सकते हैं।
job_position तालिका में वास्तविक नौकरी का शीर्षक है। चूंकि एक शीर्षक कई नौकरियों के लिए विज्ञापित किया जा सकता है (उदाहरण के लिए "आईटी प्रबंधक", "बिक्री प्रबंधक"), हमने नौकरी की स्थिति के लिए एक अलग तालिका बनाई है। हम इस तालिका में "आईटी टीम लीड", "वाइस प्रेसिडेंट" और "मैनेजर" जैसे मूल्यों को देखने की उम्मीद कर सकते हैं।
job_platform तालिका नौकरी के उद्घाटन का विज्ञापन करने के लिए उपयोग किए जाने वाले माध्यम को संदर्भित करती है। उदाहरण के लिए, नौकरी को फेसबुक, ऑनलाइन जॉब बोर्ड या स्थानीय समाचार पत्र में पोस्ट किया जा सकता है। उस जॉब पोस्टिंग का लिंक description . में जोड़ा जा सकता है खेत।
organization तालिका उन सभी कंपनियों के बारे में जानकारी संग्रहीत करती है जिन्होंने कभी भी इस डेटाबेस का उपयोग अपनी भर्ती प्रक्रिया के हिस्से के रूप में किया है। जाहिर है, यह तालिका तब महत्वपूर्ण होती है जब किसी अन्य कंपनी के लिए भर्ती की जा रही हो।
इस विषय क्षेत्र में अंतिम तालिका, job , वास्तविक नौकरी विवरण शामिल है। अधिकांश विशेषताएँ स्व-व्याख्यात्मक हैं। हमें ध्यान देना चाहिए कि इस तालिका में कई विदेशी कुंजी हैं, जिसका अर्थ है कि इसका उपयोग उस नौकरी के उद्घाटन से संबंधित श्रेणी, स्थिति, मंच, भर्ती संगठन और भर्ती प्रक्रिया को देखने के लिए किया जा सकता है।
आवेदन, आवेदक और दस्तावेज़
स्कीमा के तीसरे भाग में टेबल होते हैं जो नौकरी के आवेदकों, उनके आवेदनों और आवेदनों के साथ आने वाले किसी भी दस्तावेज के बारे में जानकारी संग्रहीत करते हैं।
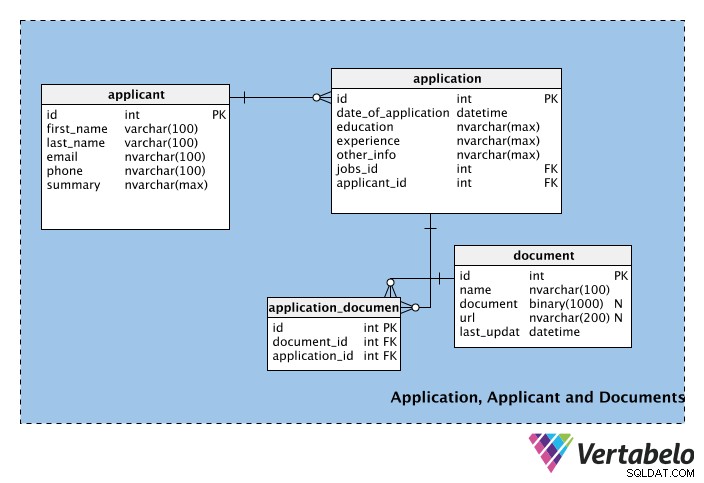
पहली तालिका, applicant , आवेदकों की व्यक्तिगत जानकारी संग्रहीत करता है, जैसे कि उनका पहला नाम, अंतिम नाम, ईमेल, फोन नंबर, आदि। सारांश फ़ील्ड का उपयोग आवेदक की संक्षिप्त प्रोफ़ाइल (अर्थात एक पैराग्राफ) को संग्रहीत करने के लिए किया जा सकता है।
अगली तालिका में प्रत्येक application , इसकी तारीख सहित। तालिका में experience भी शामिल है और education स्तंभ। ये कॉलम applicant तालिका, लेकिन एक आवेदक अपने द्वारा जमा किए गए प्रत्येक आवेदन पर एक विशेष शैक्षिक योग्यता या नौकरी के अनुभव को प्रदर्शित करना चाह सकता है या नहीं। इसलिए, ये कॉलम application टेबल। other_info कॉलम किसी भी अन्य एप्लिकेशन से संबंधित जानकारी संग्रहीत करता है। application तालिका, jobs_id और आवेदक_id क्रमशः नौकरी और आवेदक तालिका से विदेशी कुंजी हैं।
चूंकि प्रत्येक कार्य के लिए कई आवेदन हो सकते हैं लेकिन प्रत्येक आवेदन केवल एक कार्य के लिए है, jobs और applications टेबल। इसी तरह, एक आवेदक कई आवेदन (यानी विभिन्न नौकरियों के लिए) जमा कर सकता है, लेकिन प्रत्येक आवेदन केवल एक प्रतिभागी से होता है; हमने applicants और applications इसे संभालने के लिए टेबल।
document तालिका उन सहायक दस्तावेजों का प्रबंधन करती है जिन्हें आवेदक अपने आवेदन के साथ संलग्न कर सकते हैं। ये सीवी, रिज्यूमे, लेटर ऑफ रेफरेंस, कवर लेटर आदि हो सकते हैं। ध्यान दें कि इस टेबल में डॉक्यूमेंट नाम का एक बाइनरी कॉलम है, जो फाइल को बाइनरी फॉर्मेट में स्टोर करेगा। दस्तावेज़ का लिंक url . में संग्रहीत किया जा सकता है खेत; नाम कॉलम दस्तावेज़ का नाम संग्रहीत करता है, और last_update आवेदक द्वारा अपलोड किए गए नवीनतम संस्करण को दर्शाता है। ध्यान दें कि दोनों document और url अशक्त हैं; न तो अनिवार्य है, और आवेदक अपने आवेदन में जानकारी जोड़ने के लिए या तो या दोनों विधियों का उपयोग करना चुन सकता है।
प्रत्येक आवेदन में एक दस्तावेज संलग्न नहीं होगा। एक दस्तावेज़ को कई अनुप्रयोगों से जोड़ा जा सकता है, और एक आवेदन में कई सहायक दस्तावेज़ हो सकते हैं। इसका मतलब है कि application और document टेबल। इस संबंध को प्रबंधित करने के लिए, लुकअप तालिका application_document बनाया गया है।
परीक्षा और साक्षात्कार
अब हम उन तालिकाओं की ओर बढ़ेंगे जो भर्ती प्रक्रिया से संबंधित परीक्षणों और साक्षात्कारों के बारे में जानकारी संग्रहीत करती हैं।
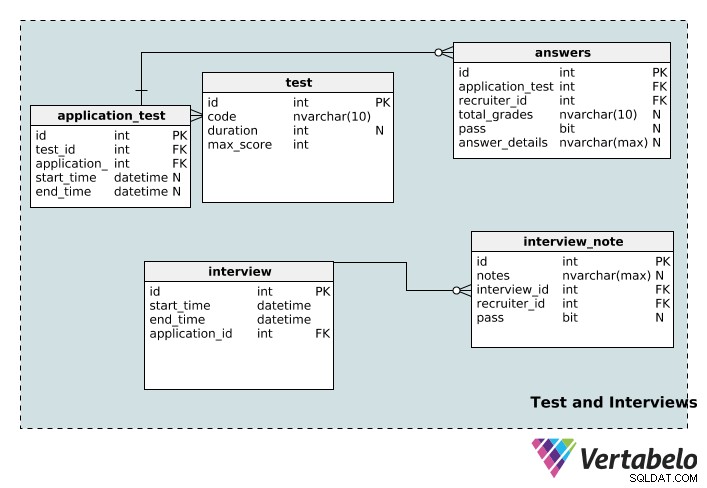
test टेबल अपने अद्वितीय id . सहित परीक्षण विवरण संग्रहीत करता है , code नाम, इसकी duration मिनटों में, और maximum उस परीक्षा के लिए संभव स्कोर।
एक आवेदन को कई परीक्षणों से जोड़ा जा सकता है और एक परीक्षण को कई अनुप्रयोगों से जोड़ा जा सकता है। एक बार फिर, हमारे पास इस संबंध को लागू करने के लिए एक लुकअप टेबल है:application_test . start_time और end_time कॉलम अशक्त हैं, क्योंकि किसी परीक्षण में कोई विशिष्ट अवधि, प्रारंभ समय या समाप्ति समय नहीं हो सकता है।
एक परीक्षा को कई भर्तीकर्ताओं द्वारा वर्गीकृत किया जा सकता है और एक भर्तीकर्ता कई परीक्षणों को ग्रेड कर सकता है। answers तालिका वह तालिका है जो इसे संभव बनाती है। total_grades कॉलम रिकॉर्ड करता है कि उम्मीदवार ने परीक्षा में कितना अच्छा प्रदर्शन किया है, और पास कॉलम केवल यह दर्शाता है कि वह व्यक्ति पास हुआ या असफल। प्रत्येक व्यक्तिगत परीक्षण की विशिष्टताएं answer_details . में दर्ज की जाती हैं कॉलम। ध्यान दें कि ये तीन कॉलम अशक्त हैं; एक आवेदन परीक्षा एक भर्तीकर्ता को सौंपी जा सकती है जिसने अभी तक इसे ग्रेड नहीं किया है। इसके अलावा, भर्ती करने वाले को वास्तव में परीक्षा देने से पहले उसे एक परीक्षण सौंपा जा सकता है।
interview तालिका बुनियादी जानकारी संग्रहीत करती है (start_time , end_time , एक अद्वितीय id , और प्रासंगिक application_id ) प्रत्येक साक्षात्कार के लिए। एक साक्षात्कार को केवल एक आवेदन के साथ जोड़ा जा सकता है। दूसरी ओर, एक आवेदन में कई साक्षात्कार हो सकते हैं। इसलिए, आवेदन और साक्षात्कार तालिका के बीच एक से कई संबंध मौजूद हैं।
एक साक्षात्कार कई समीक्षकों द्वारा आयोजित किया जा सकता है, और एक समीक्षक कई साक्षात्कार ले सकता है। यह एक और अनेक-से-अनेक संबंध है, इसलिए हमने लुकअप तालिका बनाई है interview_note . यह साक्षात्कार के बारे में जानकारी संग्रहीत करता है (interview_id . में) ), रिक्रूटर (recruiter_id . में) ), और साक्षात्कार के बारे में भर्तीकर्ता के नोट्स। रिक्रूटर्स यह भी रिकॉर्ड कर सकते हैं कि आवेदक ने इंटरव्यू पास कॉलम में पास किया है या नहीं, जो कि अशक्त है।
भर्तीकर्ता आवेदन मूल्यांकन और स्थिति
हमारे भर्ती मॉडल का अंतिम भाग भर्ती करने वालों, आवेदन की स्थिति और आवेदन मूल्यांकन के बारे में जानकारी संग्रहीत करता है।
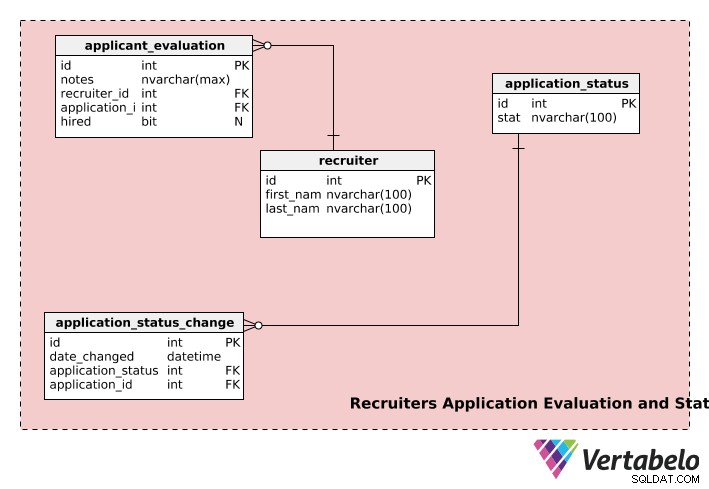
recruiters तालिका प्रत्येक भर्तीकर्ता के first_name . को संग्रहीत करती है , last_name , और अद्वितीय id संख्या।
application_evaluation तालिका आवेदन मूल्यांकन के बारे में जानकारी रखती है। application_id . के अलावा और recruiter_id , इसमें भर्तीकर्ता की प्रतिक्रिया शामिल है (notes . में ) और अंतिम भर्ती निर्णय, यदि कोई हो, hired . में . एक आवेदन का मूल्यांकन कई नियोक्ताओं द्वारा किया जा सकता है और एक भर्तीकर्ता कई आवेदनों का मूल्यांकन कर सकता है, इसलिए दोनों recruiters और application तालिका का application_evaluation टेबल।
भर्ती प्रक्रिया के दौरान एक आवेदन कई चरणों से गुजर सकता है, उदा। "सबमिट नहीं किया गया", "समीक्षा अधीन", "निर्णय की प्रतीक्षा", "निर्णय किया गया", आदि। एक आवेदन की स्थिति "not_submitted" होगी जब उपयोगकर्ता ने एक आवेदन शुरू किया है लेकिन इसे भर्ती करने वालों के लिए समीक्षा के लिए जमा नहीं किया है। एक बार आवेदन जमा करने के बाद, स्थिति "समीक्षा अधीन" में बदल जाती है, और इसी तरह। application_status तालिका का उपयोग ऐसी सूचनाओं को संग्रहीत करने के लिए किया जाता है।
application_status_change तालिका का उपयोग सभी जमा किए गए आवेदनों के लिए स्थिति परिवर्तन का रिकॉर्ड बनाए रखने के लिए किया जाता है। date_changed कॉलम स्थिति परिवर्तन की तारीख संग्रहीत करता है। यदि आप विभिन्न अनुप्रयोगों के प्रत्येक चरण के लिए प्रसंस्करण समय का विश्लेषण करना चाहते हैं तो यह तालिका उपयोगी हो सकती है। इसके अलावा, किसी विशेष कॉलम की स्थिति को application_id . का उपयोग करके पुनर्प्राप्त किया जा सकता है application_status_change टेबल।
एक साधारण भर्ती उपयोग मामला
आइए देखें कि हमारा डेटाबेस भर्ती प्रक्रिया में कैसे मदद कर सकता है।
मान लीजिए कि किसी कंपनी ने आपको प्रोग्रामिंग अनुभव के साथ एक आईटी प्रबंधक को नियुक्त करने के लिए नियुक्त किया है। हमारा डेटाबेस निम्नलिखित चरणों को क्रियान्वित करके ऐसे व्यक्ति को काम पर रखने में हमारी मदद कर सकता है:
- पहला कदम एक नई भर्ती प्रक्रिया शुरू करना है। ऐसा करने के लिए, डेटा को
processऔरstepsटेबल। एक भर्तीकर्ता जितने चाहें उतने कदम जोड़ सकता है। - उपरोक्त कार्य के दौरान, भर्तीकर्ता एक नया कार्य सृजित कर सकता है और
job,job_category,job_position, औरorganizationटेबल। अंत में, नौकरी का विज्ञापनjob_platformटेबल. - आगे, आवेदक अपना डेटा
applicantटेबल। फिर वेapplicationटेबल. - आवेदक अपने आवेदन के साथ दस्तावेज भी संलग्न कर सकते हैं। यह डेटा
documentऔरapplication_documentटेबल. - यदि कोई उपयोगकर्ता एक से अधिक नौकरियों के लिए आवेदन करना चाहता है, तो वह चरण 3 और 4 को दोहराएगा।
- आवेदन जमा करने के बाद, आवेदन की स्थिति "सबमिट" (या भर्तीकर्ता द्वारा चुना गया कोई अन्य स्थिति नाम) पर सेट हो जाएगी।
- नियुक्ति आवेदन का मूल्यांकन करेगा और
application_evaluationटेबल। इस स्तर पर, किराए के कॉलम में कोई जानकारी नहीं होगी। - पर्याप्त संख्या में आवेदन प्राप्त होने के बाद, भर्तीकर्ता
process_stepटेबल. - यदि अगला चरण किसी प्रकार के परीक्षण को प्रशासित करना है, तो भर्तीकर्ता
testटेबल. - चरण 9 में बनाए गए परीक्षण को एक विशेष एप्लिकेशन को सौंपा जाएगा। प्रत्येक एप्लिकेशन को प्रत्येक परीक्षण असाइन करने वाली जानकारी
application_testटेबल। ध्यान दें, प्रत्येक चरण के दौरान, आवेदन की स्थिति बदलती रहेगी। इसेapplication_status_changeटेबल. - एक बार जब आवेदक परीक्षण पूरा कर लेता है, तो प्रत्येक आवेदन परीक्षा के ग्रेड को भर्तीकर्ता द्वारा चिह्नित किया जाएगा और
answerटेबल. - एक बार परीक्षण हो जाने के बाद,
process_stepतालिका निष्पादित की जाएगी। मान लें कि अगला चरण साक्षात्कार है। - साक्षात्कार डेटा
interviewटेबल। रिक्रूटर अपनी टिप्पणियां दर्ज करेगा और बताएगा कि व्यक्ति ने साक्षात्कार पास किया है या नहीं। इसेinterview_noteटेबल. - यदि
Processतालिका में आगे साक्षात्कार और परीक्षण चरण शामिल हैं, उन्हें अंतिम चरण तक पहुंचने तक निष्पादित किया जाएगा। process_stepतालिका आम तौर पर भर्ती निर्णय है। यदि आवेदक अपने परीक्षण और साक्षात्कार पास कर लेता है और कंपनी उन्हें नियुक्त करने का निर्णय लेती है, तो डेटाapplication_evaluationटेबल और व्यक्ति को काम पर रखा गया है।
आप हमारे भर्ती सिस्टम डेटा मॉडल के बारे में क्या सोचते हैं?
इस लेख में, हमने देखा कि भर्ती प्रणाली के लिए एक बहुत ही सरल डेटाबेस स्कीमा कैसे बनाया जाता है। हमने स्कीमा को चार श्रेणियों में विभाजित किया और फिर उनमें से प्रत्येक के बारे में विस्तार से बताया। अंत में, हमने यह दिखाने के लिए एक उपयोग केस चलाया कि हमारी स्कीमा वास्तव में एक कर्मचारी को भर्ती करने में मदद कर सकती है।
डेटाबेस डिजाइन नौकरियां फलफूल रही हैं। अपने डेटाबेस कौशल में जोड़ना चाहते हैं? चाहे आप एक नवागंतुक हों जो SQL मूल बातें सीखना चाहते हों या एक अनुभवी पेशेवर जो SQL में तालिकाएँ बनाना चाहते हैं | इंटरएक्टिव कोर्स | Vertabelo Academy" target="_blank">डेटाबेस डिज़ाइन, LearnSQL.com के स्व-पुस्तक पाठ्यक्रम देखें।



