@rob_farley किसी मान के आधार पर ऑर्डर करने के लिए आपका हालिया स्टैक ओवरफ्लो समाधान पहले एक फ़ील्ड है प्रतिभावान! व्यक्तिगत रूप से आपको धन्यवाद देना चाहता हूं।
- जोएल सैको (@Jsac90) 11 अगस्त, 2016
मैंने इस ट्वीट को आते देखा…
और इसने मुझे यह देखने के लिए प्रेरित किया कि इसका क्या जिक्र था, क्योंकि मैंने डेटा ऑर्डर करने के बारे में स्टैक ओवरफ्लो पर 'हाल ही में' कुछ भी नहीं लिखा था। पता चला कि यह यह उत्तर मैंने लिखा था , जो हालांकि स्वीकृत उत्तर नहीं था, ने सौ से अधिक वोट एकत्र किए हैं।
प्रश्न पूछने वाले व्यक्ति की एक बहुत ही साधारण समस्या थी - कुछ पंक्तियों को पहले दिखाना चाहते थे। और मेरा समाधान सरल था:
ORDER BY CASE WHEN city = 'New York' THEN 1 ELSE 2 END, City;
ऐसा लगता है कि यह एक लोकप्रिय उत्तर रहा है, जिसमें जोएल सैको (उपरोक्त उस ट्वीट के अनुसार) भी शामिल है।
विचार एक अभिव्यक्ति बनाने और उसके द्वारा आदेश देने का है। ORDER BY परवाह नहीं है कि यह एक वास्तविक कॉलम है या नहीं। यदि आप वास्तव में अपने ORDER BY खंड में 'कॉलम' का उपयोग करना पसंद करते हैं, तो आप APPLY का उपयोग करके भी ऐसा ही कर सकते थे।
SELECT Users.* FROM Users CROSS APPLY ( SELECT CASE WHEN City = 'New York' THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, City;
अगर मैं वाइडवर्ल्ड इम्पोर्टर्स के खिलाफ कुछ प्रश्नों का उपयोग करता हूं, तो मैं आपको दिखा सकता हूं कि ये दो प्रश्न वास्तव में समान क्यों हैं। मैं Sales.Orders तालिका को क्वेरी करने जा रहा हूँ, जिसमें Salesperson 7 के लिए पहले दिखाई देने के लिए कहा गया है। मैं एक उपयुक्त कवरिंग इंडेक्स भी बनाने जा रहा हूँ:
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID) INCLUDE (OrderDate);
इन दो प्रश्नों की योजनाएँ समान दिखती हैं। वे समान रूप से प्रदर्शन करते हैं - वही पढ़ता है, वही भाव, वे वास्तव में एक ही प्रश्न हैं। यदि वास्तविक CPU या अवधि में थोड़ा सा अंतर है, तो यह अन्य कारकों के कारण अस्थायी है।
SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders ORDER BY CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END, SalespersonPersonID; SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders CROSS APPLY ( SELECT CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, SalespersonPersonID;
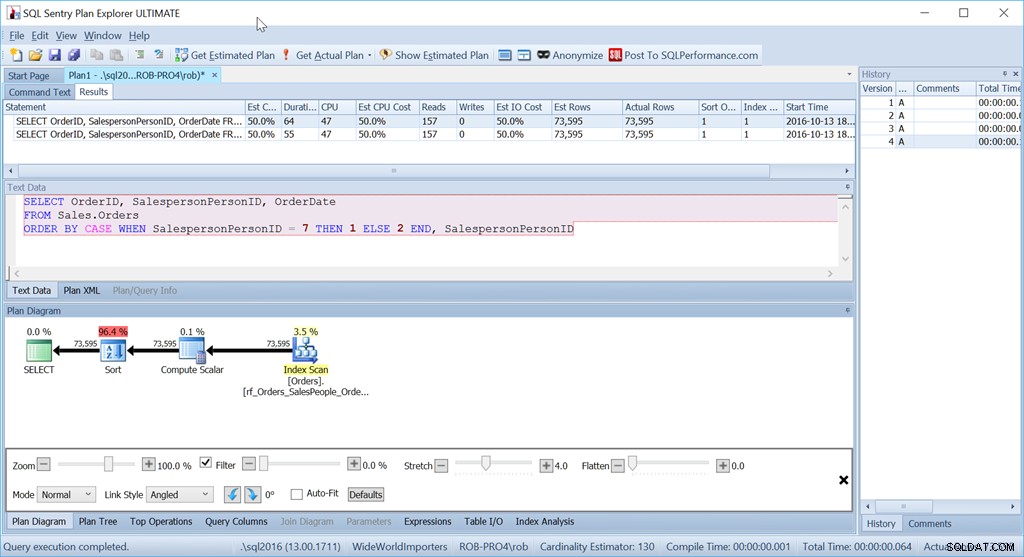
और फिर भी यह वह प्रश्न नहीं है जिसका मैं वास्तव में इस स्थिति में उपयोग करूंगा। नहीं अगर प्रदर्शन मेरे लिए महत्वपूर्ण थे। (यह आमतौर पर होता है, लेकिन डेटा की मात्रा कम होने पर यह हमेशा लंबे समय तक एक प्रश्न लिखने लायक नहीं होता है।)
मुझे जो परेशान करता है वह है सॉर्ट ऑपरेटर। यह लागत का 96.4% है!
विचार करें कि क्या हम केवल SalespersonID द्वारा ऑर्डर करना चाहते हैं:
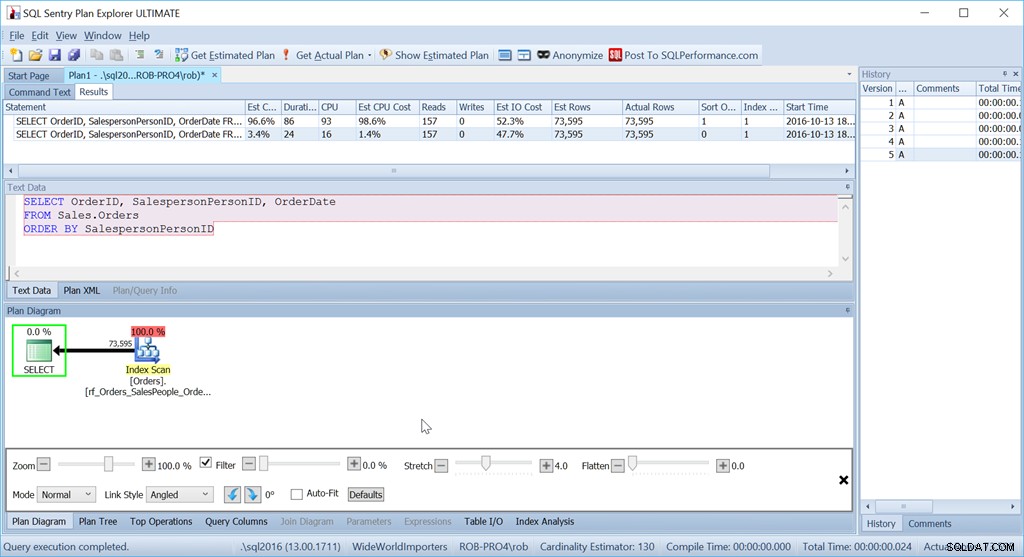
हम देखते हैं कि इस सरल क्वेरी की अनुमानित CPU लागत बैच का 1.4% है, जबकि कस्टम-सॉर्ट किए गए संस्करण की 98.6% है। यह सत्तर गुना बुरा है। हालांकि पढ़ना वही है - यह अच्छा है। अवधि बहुत खराब है, और सीपीयू भी ऐसा ही है।
मुझे सॉर्ट का शौक नहीं है। वे बुरे हो सकते हैं।
मेरे पास यहां एक विकल्प है कि मैं अपनी टेबल और इंडेक्स में एक कंप्यूटेड कॉलम जोड़ूं, लेकिन इसका असर किसी भी चीज पर पड़ेगा जो टेबल पर सभी कॉलम, जैसे ओआरएम, पावर बीआई, या कुछ भी जो चयन करता है * . तो यह इतना अच्छा नहीं है (हालाँकि अगर हमें कभी भी छिपे हुए गणना वाले कॉलम जोड़ने को मिलते हैं, तो यह यहाँ एक बहुत अच्छा विकल्प होगा)।
एक और विकल्प, जो अधिक लंबा है (कुछ सुझाव दे सकते हैं कि यह मेरे अनुरूप होगा - और यदि आपने सोचा कि:ओई! इतना कठोर मत बनो!), और अधिक पढ़ने का उपयोग करता है, यह विचार करना है कि हम वास्तविक जीवन में क्या करेंगे यदि हमें यह करने की ज़रूरत थी।
अगर मेरे पास 73,595 ऑर्डर का ढेर होता, जिसे सेल्सपर्सन ऑर्डर द्वारा सॉर्ट किया जाता है, और मुझे पहले उन्हें किसी विशेष सेल्सपर्सन के साथ वापस करने की आवश्यकता होती है, तो मैं उस ऑर्डर की अवहेलना नहीं करता और बस उन सभी को सॉर्ट करता हूं, मैं इसमें गोता लगाकर शुरू करूंगा और विक्रेता 7 के लिए उन्हें ढूंढना - उन्हें उस क्रम में रखना जिसमें वे थे। फिर मैं उन्हें ढूंढूंगा जो वे नहीं थे जो विक्रेता 7 नहीं थे - उन्हें आगे रखना, और उन्हें फिर से उसी क्रम में रखना जो वे पहले से थे। में।
टी-एसक्यूएल में, यह इस तरह किया जाता है:
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID; यह डेटा के दो सेट प्राप्त करता है और उन्हें जोड़ता है। लेकिन क्वेरी ऑप्टिमाइज़र यह देख सकता है कि दो सेटों के संयोजन के बाद, उसे SalespersonID क्रम को बनाए रखने की आवश्यकता है, इसलिए यह एक विशेष प्रकार का संयोजन करता है जो उस क्रम को बनाए रखता है। यह एक मर्ज जॉइन (Concatenation) जॉइन है, और योजना इस तरह दिखती है:
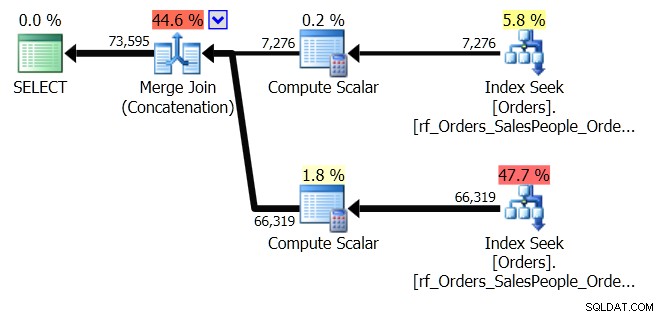
आप देख सकते हैं कि यह बहुत अधिक जटिल है। लेकिन उम्मीद है कि आप यह भी देखेंगे कि कोई सॉर्ट ऑपरेटर नहीं है। मर्ज जॉइन (Concatenation) प्रत्येक शाखा से डेटा खींचता है, और एक डेटासेट तैयार करता है जो सही क्रम में है। इस मामले में, यह पहले विक्रेता 7 के लिए सभी 7,276 पंक्तियों को खींचेगा, और फिर अन्य 66,319 को खींचेगा, क्योंकि यह आवश्यक क्रम है। प्रत्येक सेट के भीतर, डेटा SalespersonID क्रम में होता है, जिसे डेटा प्रवाहित होने पर बनाए रखा जाता है।
मैंने पहले उल्लेख किया था कि यह अधिक पढ़ता है, और यह करता है। यदि मैं दो प्रश्नों की तुलना करते हुए SET STATISTICS IO आउटपुट दिखाता हूं, तो मुझे यह दिखाई देता है:
टेबल 'वर्कटेबल'। स्कैन काउंट 0, लॉजिकल रीड्स 0, फिजिकल रीड्स 0, रीड-फॉरवर्ड रीड्स 0, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-अहेड रीड्स 0।टेबल 'ऑर्डर्स'। स्कैन काउंट 1, लॉजिकल रीड्स 157, फिजिकल रीड्स 0, रीड-फॉरवर्ड रीड्स 0, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-अहेड रीड्स 0.
टेबल 'ऑर्डर्स '। स्कैन काउंट 3, लॉजिकल रीड्स 163, फिजिकल रीड्स 0, रीड-फॉरवर्ड रीड्स 0, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-आगे रीड्स 0।
"कस्टम सॉर्ट" संस्करण का उपयोग करते हुए, यह इंडेक्स का केवल एक स्कैन है, जिसमें 157 रीड्स का उपयोग किया जाता है। "यूनियन ऑल" पद्धति का उपयोग करते हुए, यह तीन स्कैन हैं - एक SalespersonID =7, एक SalespersonID <7 के लिए और एक SalespersonID> 7 के लिए। हम दूसरे इंडेक्स सीक के गुणों को देखकर उन अंतिम दो को देख सकते हैं:
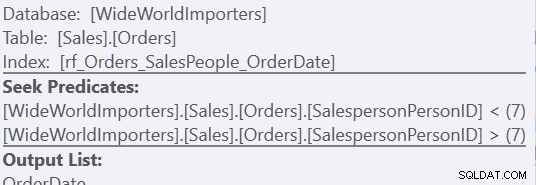
मेरे लिए, हालांकि, वर्कटेबल के अभाव में लाभ मिलता है।
सीपीयू की अनुमानित लागत देखें:

जब हम पूरी तरह से सॉर्ट करने से बचते हैं तो यह हमारे 1.4% जितना छोटा नहीं है, लेकिन यह अभी भी हमारी कस्टम सॉर्ट पद्धति पर एक बड़ा सुधार है।
लेकिन चेतावनी का एक शब्द…
मान लीजिए कि मैंने उस इंडेक्स को अलग तरह से बनाया था, और ऑर्डरडेट को शामिल कॉलम के बजाय एक प्रमुख कॉलम के रूप में था।
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID, OrderDate);
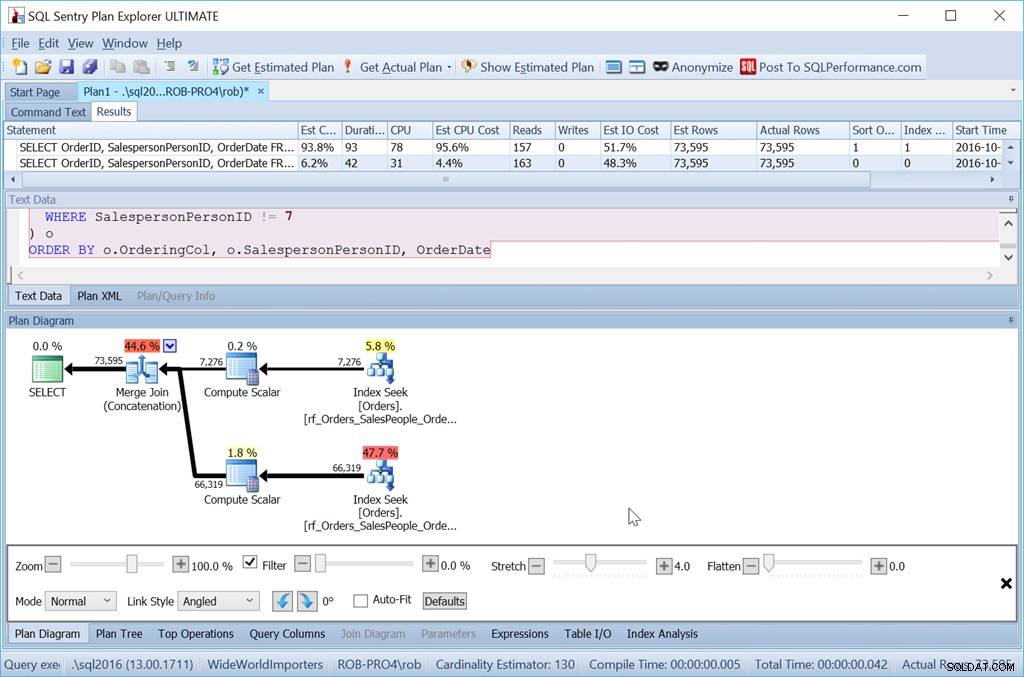
अब, मेरा "यूनियन ऑल" तरीका बिल्कुल भी काम नहीं करता जैसा कि इरादा था।
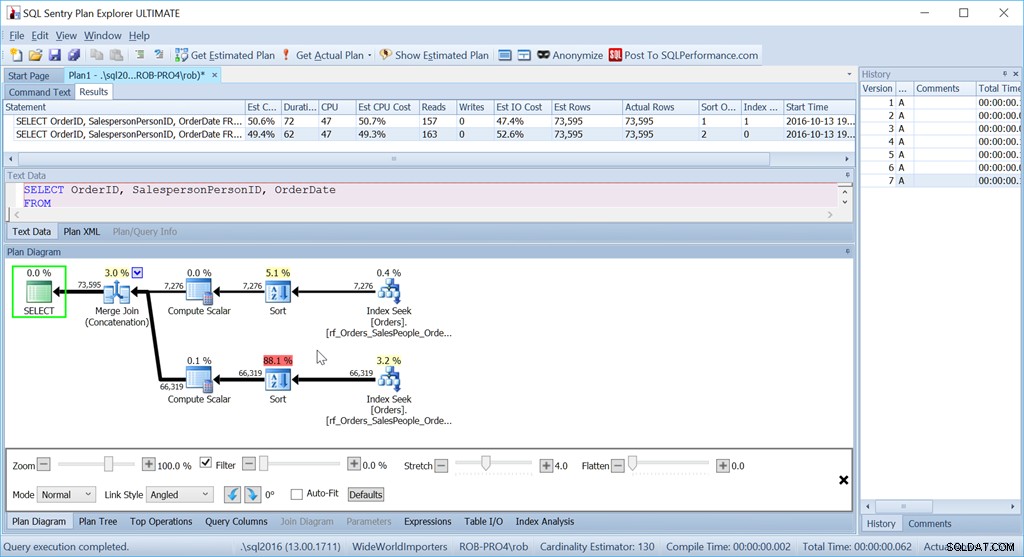
पहले की तरह ही समान प्रश्नों का उपयोग करने के बावजूद, मेरी अच्छी योजना में अब दो सॉर्ट ऑपरेटर हैं, और यह मेरे मूल स्कैन + सॉर्ट संस्करण के रूप में लगभग खराब प्रदर्शन करता है।
इसका कारण मर्ज जॉइन (Concatenation) ऑपरेटर की एक विचित्रता है, और सुराग सॉर्ट ऑपरेटर में है।

यह सेल्सपर्सनआईडी द्वारा ऑर्डर कर रहा है और उसके बाद ऑर्डरआईडी - जो तालिका की क्लस्टर इंडेक्स कुंजी है। यह इसे इसलिए चुनता है क्योंकि इसे अद्वितीय माना जाता है, और यह सेल्सपर्सनआईडी की तुलना में सॉर्ट करने के लिए कॉलम का एक छोटा सेट है, जिसके बाद ऑर्डरडेट और उसके बाद ऑर्डरआईडी, जो तीन इंडेक्स रेंज स्कैन द्वारा उत्पादित डेटासेट ऑर्डर है। उन अवसरों में से एक जब क्वेरी ऑप्टिमाइज़र को कोई बेहतर विकल्प दिखाई नहीं देता है जो ठीक वहीं है।
इस इंडेक्स के साथ, हमें अपने पसंदीदा प्लान को तैयार करने के लिए ऑर्डरडेट द्वारा ऑर्डर किए गए हमारे डेटासेट की भी आवश्यकता होगी।
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID, OrderDate;
तो यह निश्चित रूप से अधिक प्रयास है। मेरे लिए लिखने के लिए क्वेरी लंबी है, यह अधिक पढ़ी जाती है, और मेरे पास अतिरिक्त कुंजी कॉलम के बिना एक अनुक्रमणिका होनी चाहिए। लेकिन यह निश्चित रूप से तेज है। और भी अधिक पंक्तियों के साथ, प्रभाव अभी भी बड़ा है, और मुझे tempdb पर सॉर्ट स्पिलिंग का जोखिम उठाने की आवश्यकता नहीं है।
छोटे सेटों के लिए, मेरा स्टैक ओवरफ्लो उत्तर अभी भी अच्छा है। लेकिन जब वह सॉर्ट ऑपरेटर मुझे प्रदर्शन में खर्च कर रहा है, तो मैं यूनियन ऑल/मर्ज जॉइन (Concatenation) विधि के साथ जा रहा हूं।



