SQL सर्वर में खराब प्रदर्शन करने वाले प्रश्नों को देखने के लिए कई तरीके हैं, विशेष रूप से क्वेरी स्टोर, विस्तारित ईवेंट और गतिशील प्रबंधन दृश्य (DMV)। प्रत्येक विकल्प के पेशेवरों और विपक्ष हैं। विस्तारित ईवेंट क्वेरीज़ के व्यक्तिगत निष्पादन के बारे में डेटा प्रदान करते हैं, जबकि क्वेरी स्टोर और DMVs समग्र प्रदर्शन डेटा प्रदान करते हैं। क्वेरी स्टोर और विस्तारित ईवेंट का उपयोग करने के लिए, आपको उन्हें पहले से कॉन्फ़िगर करना होगा - या तो अपने डेटाबेस के लिए क्वेरी स्टोर को सक्षम करना होगा, या एक XE सत्र सेट करना और इसे शुरू करना होगा। DMV डेटा हमेशा उपलब्ध होता है, इसलिए अक्सर क्वेरी प्रदर्शन पर एक त्वरित पहली नज़र डालने का यह सबसे आसान तरीका है। यह वह जगह है जहां ग्लेन के डीएमवी प्रश्न काम में आते हैं - उनकी स्क्रिप्ट के भीतर उनके पास कई प्रश्न हैं जिनका उपयोग आप सीपीयू, तार्किक I/O, और अवधि के आधार पर उदाहरण के लिए शीर्ष प्रश्नों को खोजने के लिए कर सकते हैं। समस्या निवारण के दौरान उच्चतम संसाधन-खपत प्रश्नों को लक्षित करना अक्सर एक अच्छी शुरुआत होती है, लेकिन हम "हजारों कटौती से मृत्यु" परिदृश्य के बारे में नहीं भूल सकते - क्वेरी या प्रश्नों का सेट जो बहुत बार चलते हैं - शायद सैकड़ों या हजारों बार मिनट। ग्लेन के सेट में एक क्वेरी है जो निष्पादन गणना के आधार पर डेटाबेस के लिए शीर्ष प्रश्नों को सूचीबद्ध करती है, लेकिन मेरे अनुभव में यह आपको आपके कार्यभार की पूरी तस्वीर नहीं देता है।
क्वेरी प्रदर्शन मेट्रिक्स को देखने के लिए उपयोग किया जाने वाला मुख्य DMV sys.dm_exec_query_stats है। संग्रहीत कार्यविधियों (sys.dm_exec_procedure_stats), फ़ंक्शन (sys.dm_exec_function_stats), और ट्रिगर्स (sys.dm_exec_trigger_stats) के लिए विशिष्ट अतिरिक्त डेटा भी उपलब्ध है, लेकिन एक ऐसे कार्यभार पर विचार करें जो विशुद्ध रूप से संग्रहीत कार्यविधियाँ, फ़ंक्शन और ट्रिगर नहीं है। एक मिश्रित कार्यभार पर विचार करें जिसमें कुछ तदर्थ प्रश्न हों, या शायद पूरी तरह से तदर्थ हो।
उदाहरण परिदृश्य
पिछली पोस्ट से कोड उधार लेना और अपनाना, एक एडहॉक वर्कलोड के प्रदर्शन प्रभाव की जांच करना, हम पहले दो संग्रहीत कार्यविधियाँ बनाएंगे। पहला, dbo.Random एक एड हॉक स्टेटमेंट को चुनता है, जेनरेट करता है और निष्पादित करता है, और दूसरा, dbo.SPRandom चयन करता है, एक पैरामीटरयुक्त क्वेरी उत्पन्न करता है और निष्पादित करता है।
उपयोग [वाइडवर्ल्ड आयातकों]; GO DROP प्रक्रिया अगर मौजूद है dbo.[RandomSelects]; जाओ प्रक्रिया बनाएं डीबीओ। [रैंडम चयन] @NumRows INT as DECLARE @ConcatString NVARCHAR (200); DECLARE @QueryString NVARCHAR (1000); DECLARE @RowLoop INT =0; जबकि (@RowLoop <@NumRows) BEGIN SET @ConcatString =CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50)) + CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50)) + CAST((Convert (INT, RAND () * 500) + 1) AS NVARCHAR(50)) + CAST((Convert (INT, RAND () * 1500) + 1) AS NVARCHAR (50)); चयन करें @QueryString =N'Select w.ColorID, s.StockItemName From Warehouse.Colors w JOIN Warehouse.StockItems s ON w.ColorID =s.ColorID जहां w.ColorName =''' + @ConcatString + ''';'; EXEC (@QueryString); @RowLoop =@RowLoop + 1 चुनें; END GO DROP प्रक्रिया यदि मौजूद है तो dbo.[SPRandomSelects]; प्रक्रिया बनाएं डीबीओ। [स्प्रैंडम चयन] @NumRows INT as DECLARE @ConcatString NVARCHAR (200); DECLARE @QueryString NVARCHAR (1000); DECLARE @RowLoop INT =0; जबकि (@RowLoop <@NumRows) BEGIN SET @ConcatString =CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50)) + CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50)) + CAST((Convert (INT, RAND () * 500) + 1) AS NVARCHAR(50)) + CAST((Convert (INT, RAND () * 1500) + 1) AS NVARCHAR (50)) सी. कस्टमर आईडी, सी. अकाउंट ओपन डेट, सेल्स से काउंट (सीटी. कस्टमर ट्रांजैक्शन आईडी) चुनें। ग्राहक सी सेल्स में शामिल हों। कस्टमर ट्रांजेक्शन सीटी ऑन सी। कस्टमर आईडी =सीटी। कस्टमर आईडी जहां सी। कस्टमरनाम =@ConcatString ग्रुप बाय सी। कस्टमर आईडी, सी.खाता खोलने की तिथि; @RowLoop =@RowLoop + 1 चुनें; END GO
अब हम दोनों संग्रहीत कार्यविधियों को 1000 बार निष्पादित करेंगे, मेरी पिछली पोस्ट में .cmd फ़ाइलों के साथ निम्नलिखित कथनों के साथ .sql फ़ाइलों को कॉल करने वाली समान विधि का उपयोग करते हुए:
Adhoc.sql फ़ाइल सामग्री:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows =1000;
Parameterized.sql फ़ाइल सामग्री:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows =1000;
.cmd फ़ाइल में उदाहरण सिंटैक्स जो .sql फ़ाइल को कॉल करता है:
sqlcmd -S WIN2016\SQL2017 -i"Adhoc.sql" बाहर निकलें
यदि हम कार्यकर्ता समय (सीपीयू) के आधार पर शीर्ष प्रश्नों को देखने के लिए ग्लेन की शीर्ष कार्यकर्ता समय क्वेरी की विविधता का उपयोग करते हैं:
- पूरे उदाहरण के लिए शीर्ष कुल कार्यकर्ता समय प्रश्न प्राप्त करें (क्वेरी 44) (शीर्ष कार्यकर्ता समय प्रश्न) शीर्ष चुनें (50) डीबी_नाम (टी। [डीबीआईडी]) एएस [डेटाबेस नाम], रिप्लेस (रीप्लेस (बाएं (टी)) [पाठ], 255), CHAR(10),''), CHAR(13),'') AS [लघु क्वेरी पाठ], qs.total_worker_time AS [कुल कार्यकर्ता समय], qs.execution_count AS [निष्पादन गणना] , qs.total_worker_time/qs.execution_count AS [औसत वर्कर टाइम], qs.creation_time AS [क्रिएशन टाइम] से sys.dm_exec_query_stats AS (NOLOCK) क्रॉस एप्लाई sys.dm_exec_sql_text ) qs.total_worker_time DESC विकल्प (RECOMPILE) द्वारा क्यूपी ऑर्डर के रूप में;
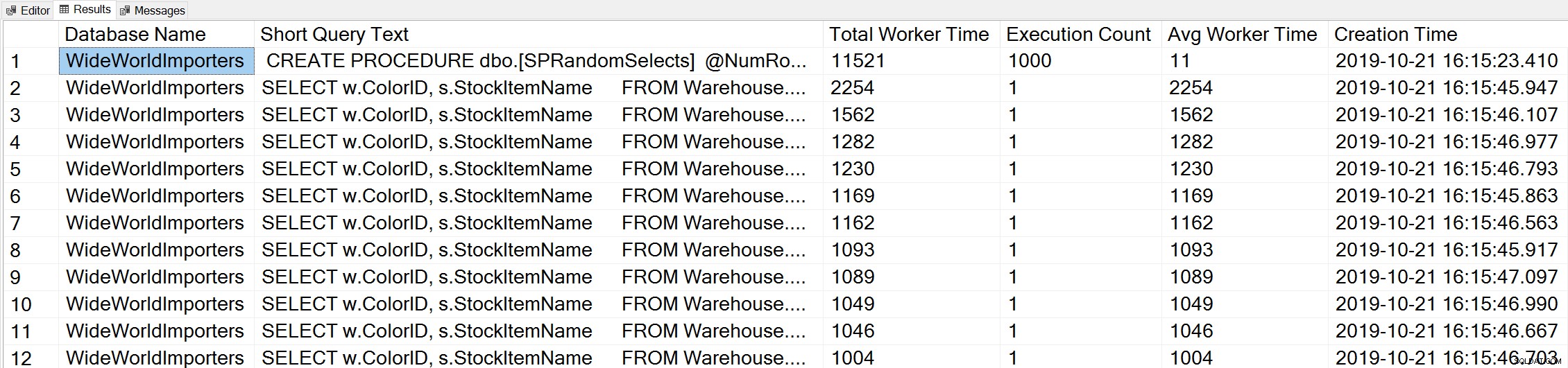
हम अपनी संग्रहीत कार्यविधि के कथन को उस क्वेरी के रूप में देखते हैं जो संचयी CPU की उच्चतम मात्रा के साथ निष्पादित होती है।
अगर हम वाइडवर्ल्ड इम्पोर्टर्स डेटाबेस के खिलाफ ग्लेन की क्वेरी एक्ज़ीक्यूशन काउंट्स क्वेरी की विविधता चलाते हैं:
उपयोग [वाइडवर्ल्ड आयातकों]; जाओ - इस डेटाबेस के लिए सबसे अधिक बार निष्पादित प्रश्न प्राप्त करें (क्वेरी 57) (क्वेरी निष्पादन गणना) शीर्ष चुनें (50) बाएं (टी। [पाठ], 50) एएस [लघु क्वेरी टेक्स्ट], qs.execution_count AS [निष्पादन गणना] , qs.total_logic_reads AS [टोटल लॉजिकल रीड्स], qs.total_logical_reads/qs.execution_count AS [औसत लॉजिकल रीड्स], qs.total_worker_time AS [कुल वर्कर टाइम], qs.total_worker_time/qs.execution_count AS [एक्यूएस. .total_elapsed_time AS [कुल बीता हुआ समय], qs.total_elapsed_time/qs.execution_count AS [औसत बीता हुआ समय] से sys.dm_exec_query_stats AS (NOLOCK) ASROSS APPLY के साथ qs. क्यूपी के रूप में जहां t.dbid =DB_ID() qs.execution_count DESC विकल्प (RECOMPILE) द्वारा आदेश;
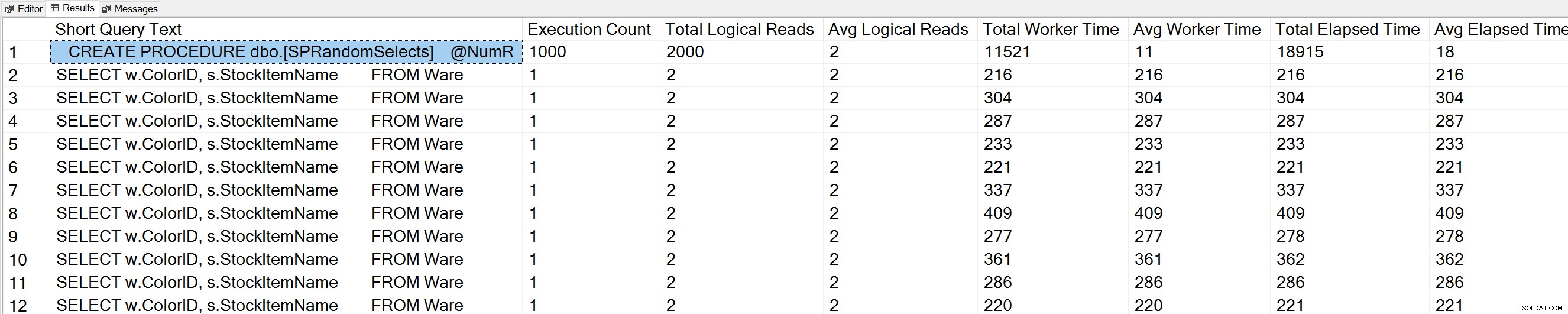
हम सूची के शीर्ष पर अपना संग्रहीत कार्यविधि विवरण भी देखते हैं।
लेकिन जिस तदर्थ क्वेरी को हमने निष्पादित किया, भले ही उसके अलग-अलग शाब्दिक मूल्य हों, अनिवार्य रूप से समान था स्टेटमेंट को बार-बार निष्पादित किया जाता है, जैसा कि हम query_hash को देखकर देख सकते हैं:
सेलेक्ट टॉप(50) DB_NAME(t.[dbid]) AS [डेटाबेस नेम], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13) ,'') AS [लघु क्वेरी टेक्स्ट], qs.query_hash AS [query_hash], qs.creation_time AS [क्रिएशन टाइम] से sys.dm_exec_query_stats AS (NOLOCK) CROSS APPLY sys.dm_exec_sql_text (प्लान CROSS APPLY sys.dm_exec_sql_text) पर लागू होता है। .dm_exec_query_plan(plan_handle) क्यूपी ऑर्डर के अनुसार [लघु क्वेरी टेक्स्ट];
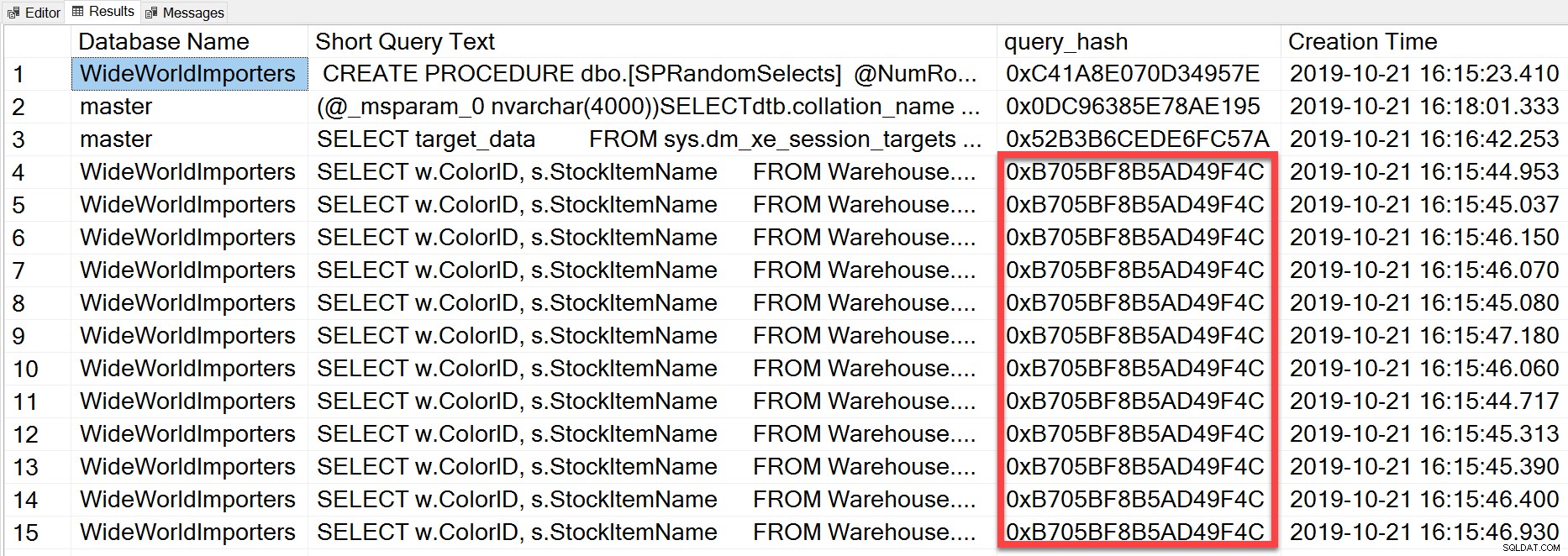
query_hash को SQL Server 2008 में जोड़ा गया था, और यह कथन पाठ के लिए क्वेरी ऑप्टिमाइज़र द्वारा उत्पन्न तार्किक ऑपरेटरों के ट्री पर आधारित है। जिन क्वेरीज़ में एक समान स्टेटमेंट टेक्स्ट होता है जो लॉजिकल ऑपरेटरों के एक ही पेड़ को उत्पन्न करता है, वही query_hash होगा, भले ही क्वेरी विधेय में शाब्दिक मान भिन्न हों। जबकि शाब्दिक मान भिन्न हो सकते हैं, ऑब्जेक्ट और उनके उपनाम समान होने चाहिए, साथ ही क्वेरी संकेत और संभावित रूप से SET विकल्प भी होने चाहिए। RandomSelects संग्रहीत कार्यविधि विभिन्न शाब्दिक मूल्यों के साथ क्वेरी उत्पन्न करती है:
चयन करें w.ColorID, s.StockItemName From Warehouse.Colors w JOIN Warehouse.StockItems s ON w.ColorID =s.ColorID जहां w.ColorName ='1005451175198'; वेयरहाउस से w.ColorID, s.StockItemName का चयन करें। वेयरहाउस में शामिल होने के लिए रंग।लेकिन प्रत्येक निष्पादन में query_hash, 0xB705BF8B5AD49F4C के लिए समान मान होता है। यह समझने के लिए कि कितनी बार एक तदर्थ क्वेरी - और जो query_hash के संदर्भ में समान हैं - निष्पादित होती हैं, हमें sys.dm_exec_query_stats में निष्पादन_काउंट को देखने के बजाय उस गणना पर query_hash क्रम द्वारा समूहित करना होगा (जो अक्सर एक दिखाता है 1 का मान)।
यदि हम वाइडवर्ल्ड इम्पोर्टर्स डेटाबेस के संदर्भ को बदलते हैं और निष्पादन गणना के आधार पर शीर्ष प्रश्नों की तलाश करते हैं, जहां हम query_hash पर समूहित होते हैं, तो अब हम संग्रहीत कार्यविधि और दोनों को देख सकते हैं। हमारी तदर्थ क्वेरी:
; qh AS के साथ (सेलेक्ट टॉप (25) query_hash, COUNT(*) as COUNT FROM sys.dm_exec_query_stats GROUP by query_hash ORDER BY COUNT(*) DESC), qs AS (चुनें obj =COALESCE(ps.object_id, fs) .object_id, ts.object_id), db =COALESCE(ps.database_id, fs.database_id, ts.database_id), qs.query_hash, qs.query_plan_hash, qs.execution_count, qs.sql_handle, qs sys_stat. इनर qh पर qs.query_hash =qh.query_hash लेफ्ट आउटर जॉइन करें sys.dm_exec_procedure_stats [ps] ऑन [qs]। [sql_handle] =[ps]। ]। [sql_handle] =[fs]। [sql_handle] बाएँ बाहरी sys.dm_exec_trigger_stats [ts] पर [qs] के रूप में शामिल हों। [sql_handle] =[ts]। [sql_handle]) शीर्ष (50) OBJECT_NAME (qs.obj) चुनें , qs.db), query_hash, query_plan_hash, SUM([qs].[execution_count]) AS [ExecutionCount], MAX([st].[text]) AS [QueryText] FROM Qs CROSS APPLY sys.dm_exec_sql_text [क्यूएस]। निष्पादन गणना डीईएससी;
नोट:sys.dm_exec_function_stats DMV को SQL Server 2016 में जोड़ा गया था। इस क्वेरी को SQL Server 2014 पर चलाने और इससे पहले इस DMV के संदर्भ को हटाने की आवश्यकता है।
यह आउटपुट इस बात की अधिक व्यापक समझ प्रदान करता है कि कौन से प्रश्न वास्तव में सबसे अधिक बार निष्पादित होते हैं, क्योंकि यह query_hash के आधार पर एकत्रित होता है, न कि केवल sys.dm_exec_query_stats में निष्पादन_काउंट को देखकर, जिसमें एक ही query_hash के लिए कई प्रविष्टियां हो सकती हैं जब विभिन्न शाब्दिक मान होते हैं उपयोग किया गया। क्वेरी आउटपुट में query_plan_hash भी शामिल है, जो समान query_hash वाले प्रश्नों के लिए भिन्न हो सकता है। किसी क्वेरी के लिए योजना के प्रदर्शन का मूल्यांकन करते समय यह अतिरिक्त जानकारी उपयोगी होती है। उपरोक्त उदाहरण में, प्रत्येक क्वेरी में समान query_plan_hash, 0x299275DD475C4B17 है, जो दर्शाता है कि विभिन्न इनपुट मानों के साथ भी, क्वेरी ऑप्टिमाइज़र एक ही योजना बनाता है - यह स्थिर है। जब एक ही query_hash के लिए कई query_plan_hash मान मौजूद होते हैं, तो योजना परिवर्तनशीलता मौजूद होती है। ऐसे परिदृश्य में जहां एक ही क्वेरी, query_hash पर आधारित, हज़ारों बार निष्पादित होती है, एक सामान्य अनुशंसा क्वेरी को पैरामीटराइज़ करना है। यदि आप यह सत्यापित कर सकते हैं कि कोई योजना परिवर्तनशीलता मौजूद नहीं है, तो क्वेरी को पैरामीटराइज़ करना प्रत्येक निष्पादन के लिए अनुकूलन और संकलन समय को हटा देता है, और समग्र CPU को कम कर सकता है। कुछ परिदृश्यों में, पांच से 10 तदर्थ प्रश्नों को पैरामीटर करने से समग्र रूप से सिस्टम के प्रदर्शन में सुधार हो सकता है।
सारांश
किसी भी परिवेश के लिए, यह समझना महत्वपूर्ण है कि संसाधन उपयोग के मामले में कौन सी क्वेरी सबसे महंगी हैं, और कौन सी क्वेरी सबसे अधिक बार चलती हैं। ग्लेन की DMV स्क्रिप्ट का उपयोग करते समय दोनों प्रकार के विश्लेषण के लिए प्रश्नों का एक ही सेट दिखाई दे सकता है, जो भ्रामक हो सकता है। जैसे, यह स्थापित करना महत्वपूर्ण है कि क्या कार्यभार अधिकतर प्रक्रियात्मक है, अधिकतर तदर्थ, या मिश्रित। जबकि संग्रहीत प्रक्रियाओं के लाभों के बारे में बहुत कुछ प्रलेखित है, मुझे लगता है कि मिश्रित या अत्यधिक तदर्थ कार्यभार बहुत आम हैं, विशेष रूप से ऐसे समाधान के साथ जो ऑब्जेक्ट-रिलेशनल मैपर्स (ओआरएम) जैसे एंटिटी फ्रेमवर्क, एनएचबेर्नेट और LINQ से SQL का उपयोग करते हैं। यदि आप सर्वर के लिए कार्यभार के प्रकार के बारे में स्पष्ट नहीं हैं, तो query_hash के आधार पर सबसे अधिक निष्पादित प्रश्नों को देखने के लिए उपरोक्त क्वेरी को चलाना एक अच्छी शुरुआत है। जैसे ही आप कार्यभार को समझना शुरू करते हैं और हजारों कट प्रश्नों से भारी हिटर और मौत दोनों के लिए क्या मौजूद है, आप वास्तव में संसाधन उपयोग और सिस्टम प्रदर्शन पर इन प्रश्नों के प्रभाव को समझने के लिए आगे बढ़ सकते हैं, और ट्यूनिंग के लिए अपने प्रयासों को लक्षित कर सकते हैं।