जैसा कि एक विशिष्ट कंपनी के डेटा की मात्रा में तेजी से वृद्धि हुई है, डेटा संग्रहण को अनुकूलित करना और भी महत्वपूर्ण हो गया है। आपके डेटा का आकार न केवल संग्रहण आकार और लागतों को प्रभावित करता है, बल्कि यह क्वेरी प्रदर्शन को भी प्रभावित करता है। आपके डेटा के आकार को निर्धारित करने में एक महत्वपूर्ण कारक वह डेटा प्रकार है जिसे आप चुनते हैं। यह ट्यूटोरियल समझाएगा कि सही डेटा प्रकारों का चयन कैसे करें।
डेटा प्रकार क्या हैं?
डेटा प्रकार परिभाषित करें कि किसी दिए गए फ़ील्ड (या कॉलम) में किस प्रकार और डेटा की श्रेणी संग्रहीत की जा सकती है।
इन नमूना रिकॉर्ड के साथ बिक्री तालिका पर विचार करें:
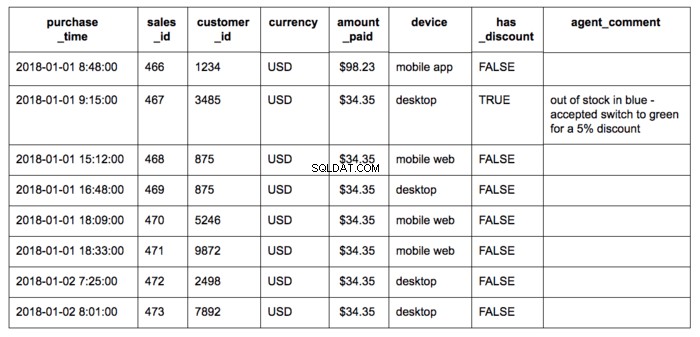
प्रत्येक फ़ील्ड का अपना प्रकार और मानों की श्रेणी होती है:
खरीदारी_समय :बिक्री की तारीख और समयsale_id :प्रत्येक नई बिक्री के लिए पूर्णांक मान एक-एक करके बढ़ते हुएcustomer_id :प्रत्येक नए ग्राहक के लिए पूर्णांक मान एक-एक करके बढ़ते हुएमुद्रा :हमेशा 3-वर्ण मुद्रा कोड में पाठ करेंराशि_भुगतान :$0.00 और $1,000.00डिवाइस . के बीच मौद्रिक वास्तविक संख्यात्मक मान :टेक्स्ट, जहां मान हो सकते हैं:'डेस्कटॉप', 'मोबाइल ऐप', और 'मोबाइल वेब'has_discount :बूलियन जहां प्रविष्टियां TRUE हो सकती हैं या FALSE नोट :टेक्स्ट, जहां प्रविष्टि उतनी ही लंबी हो सकती है जितनी हमारे एजेंट इनपुट टूल (250 वर्ण) में अनुमत है
डेटा का प्रकार (पूर्णांक, टेक्स्ट, वास्तविक संख्या, आदि…) और संभावित मान श्रेणियां (0 से 1,000; कोई भी 3 वर्ण; आदि…) विशिष्ट डेटाबेस डेटा प्रकार से मेल खाती हैं ।
संभावित डेटा प्रकार क्या हैं?
अलग-अलग डेटाबेस में अलग-अलग डेटा प्रकार उपलब्ध होते हैं, लेकिन अधिकांश इन श्रेणियों में फिट होते हैं:
संख्यात्मक:
- पूर्णांक :भिन्नों के बिना संख्याओं के लिए। हस्ताक्षर किए जा सकते हैं (सकारात्मक और नकारात्मक मानों की अनुमति दें) या अहस्ताक्षरित (केवल सकारात्मक संख्याओं की अनुमति दें)। आमतौर पर आईडी फ़ील्ड और किसी चीज़ की गणना के लिए उपयोग किया जाता है
- दशमलव(x,y) :भिन्नों वाली संख्याओं के लिए जिन्हें सटीक सटीकता की आवश्यकता होती है। हस्ताक्षर किए जा सकते हैं (सकारात्मक और नकारात्मक मानों की अनुमति दें) या अहस्ताक्षरित (केवल सकारात्मक संख्याओं की अनुमति दें)। आमतौर पर मौद्रिक क्षेत्रों के लिए उपयोग किया जाता है। उपयोगकर्ता कुल (x) और दशमलव बिंदु (y) के बाद कोष्ठकों में अनुमत महत्वपूर्ण अंकों की संख्या निर्दिष्ट करता है
- फ्लोट / डबल्स :भिन्नों वाली संख्याओं के लिए जिन्हें सटीक सटीकता की आवश्यकता नहीं होती है। हस्ताक्षर किए जा सकते हैं (सकारात्मक और नकारात्मक मानों की अनुमति दें) या अहस्ताक्षरित (केवल सकारात्मक संख्याओं की अनुमति दें)। आम तौर पर मौद्रिक क्षेत्रों को छोड़कर सभी वास्तविक संख्याओं के लिए उपयोग किया जाता है
दिनांक/समय:
तारीख :दिनांक मानों के लिए
- समय :समय मूल्यों के लिए
- टाइमस्टैम्प / डेटाटाइम :दिनांक और समय मानों के लिए
पाठ्य:
- चरित्र(n) :फिक्स्ड-लेंथ कैरेक्टर स्ट्रिंग्स के लिए, जहां कोष्ठक में मान प्रत्येक प्रविष्टि के निश्चित आकार को निर्धारित करता है
- वर्कर(एन) :वेरिएबल-लेंथ कैरेक्टर स्ट्रिंग्स के लिए, जहां कोष्ठक में मान प्रत्येक प्रविष्टि के अधिकतम स्वीकृत आकार को निर्धारित करता है
बूलियन:
- बूलियन :बूलियन (सत्य/गलत) मानों के लिए। कुछ डेटाबेस (जैसे MySQL) में बूलियन डेटा प्रकार नहीं होता है और इसके बजाय बूलियन मानों को पूर्णांकों में परिवर्तित करते हैं (1=TRUE, 0 =FALSE)
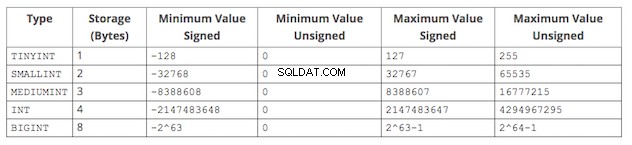
अधिकांश डेटाबेस प्रत्येक प्रकार के लिए आकार भिन्नता प्रदान करते हैं। उदाहरण के लिए, MySQL ये संभावित पूर्णांक डेटा प्रकार प्रदान करता है:
सही डेटा प्रकार कैसे चुनें
सबसे अच्छा डेटा प्रकार चुनने की मूल रणनीति सबसे छोटे डेटा प्रकार का चयन करना है जो आपके पास मौजूद डेटा के प्रकार से मेल खाता है और जो आपके डेटा के सभी व्यवहार्य मूल्यों की अनुमति देता है।
उदाहरण के लिए, customer_id हमारी नमूना बिक्री तालिका में 0 से शुरू होने वाली एक पूर्ण संख्या है। आज हमारी काल्पनिक कंपनी के पास केवल 15,000 ग्राहक हैं। पिछले अनुभाग से MySQL पूर्णांक डेटा प्रकार तालिका का उपयोग करके, हम SMALLINT का चयन करने के लिए प्रेरित हो सकते हैं डेटा प्रकार के रूप में अहस्ताक्षरित, क्योंकि यह सबसे छोटा डेटा प्रकार है जो हमारे वर्तमान पूर्णांक मानों को 0 से 15,000 तक स्वीकार करेगा। हालांकि, हमें अगले 6-12 महीनों में 100,000 ग्राहक मिलने की उम्मीद है। जब हम 65,535 से ऊपर जाते हैं, तो SMALLINT अब पर्याप्त नहीं होगा। इस प्रकार, एक बेहतर चयन है MEDIUMINT अहस्ताक्षरित, जो हमें अगले कई वर्षों के लिए कवर करना चाहिए।
नमूना रिकॉर्ड के साथ अपनी तालिका बनाते समय आप अपने डेटाबेस को आपके लिए डेटा प्रकार चुनने दे सकते हैं। हालांकि, यह आपको शायद ही कभी सबसे अच्छा डेटा प्रकार चयन देगा। उदाहरण के लिए, MySQL को पहले दिखाए गए नमूना मानों के साथ बिक्री तालिका के लिए डेटा प्रकारों का चयन करने से कई समस्याएं आती हैं।
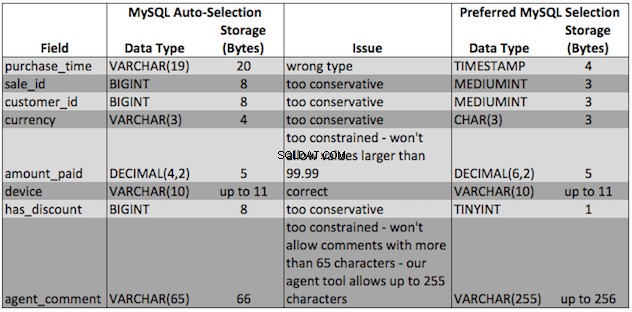
MySQL स्वचालित रूप से चयनित डेटा प्रकारों के साथ हमारे सामने आने वाली समस्याएं हैं:
- गलत डेटा प्रकार :आप फ़ील्ड का उस तरह से उपयोग नहीं कर पाएंगे, जिसकी आप अपेक्षा करते हैं। उदाहरण के लिए,
purchase_time. होना एक स्ट्रिंग के रूप में, न कि समय डेटा प्रकार का अर्थ है कि आप फ़ील्ड पर समय संचालन (जैसे कि यह गणना करना कि खरीदारी के कितने समय बाद हुआ है) करने में सक्षम नहीं होंगे - बहुत सीमित :जब आप डेटा प्रकार की अनुमति से बड़े मानों को इनपुट करने का प्रयास करते हैं तो MySQL त्रुटियां देगा। उदाहरण के लिए, यदि हमारे पास $100.00 या अधिक की राशि_भुगतान वाली बिक्री है या 65 वर्णों से अधिक लंबी एजेंट_टिप्पणी है, तो हमें त्रुटियां मिलेंगी
- बहुत रूढ़िवादी :जबकि डेटा प्रकारों के साथ बहुत अधिक रूढ़िवादी होने से कुछ भी नहीं टूटेगा, आप संग्रहण स्थान बर्बाद कर रहे होंगे। हमारे उदाहरण डेटा के साथ, हम कम रूढ़िवादी पसंदीदा विकल्पों का उपयोग करके 15% संग्रहण बचा सकते हैं
आधुनिक डेटाबेस जितने स्मार्ट हैं, डेटा के मालिक अभी भी इस बारे में सबसे अच्छी तरह जानते हैं कि किस तरह का डेटा संग्रहीत किया जाता है और निकट भविष्य में डेटा के संभावित मूल्य क्या हो सकते हैं। इसलिए आपको अपने प्रत्येक फ़ील्ड के लिए डेटा प्रकारों को सावधानीपूर्वक निर्दिष्ट करने की आवश्यकता है।
विभिन्न सामान्य डेटाबेस के लिए डेटा प्रकारों पर दस्तावेज़ीकरण यहां उपलब्ध कराए गए हैं:
- MySQL
- अमेज़ॅन रेडशिफ्ट
- अपाचे हाइव
- टेराडेटा
निष्कर्ष
आपके डेटाबेस के सही ढंग से कार्य करने और यथासंभव अनुकूलित होने के लिए, अपनी तालिका में प्रत्येक फ़ील्ड के लिए डेटा प्रकारों का सावधानीपूर्वक चयन करना महत्वपूर्ण है।