इंडेक्सिंग क्या करता है?
अनुक्रमण एक अनियंत्रित तालिका को एक क्रम में लाने का तरीका है जो खोज करते समय क्वेरी की दक्षता को अधिकतम करेगा।
जब कोई तालिका अनुक्रमित नहीं होती है, तो पंक्तियों का क्रम किसी भी तरह से अनुकूलित के रूप में क्वेरी द्वारा स्पष्ट नहीं होगा, और इसलिए आपकी क्वेरी को पंक्तियों के माध्यम से रैखिक रूप से खोजना होगा। दूसरे शब्दों में, शर्तों से मेल खाने वाली पंक्तियों को खोजने के लिए प्रश्नों को प्रत्येक पंक्ति में खोजना होगा। जैसा कि आप कल्पना कर सकते हैं, इसमें लंबा समय लग सकता है। हर एक पंक्ति को देखना बहुत कुशल नहीं है।
उदाहरण के लिए, नीचे दी गई तालिका एक काल्पनिक डेटा स्रोत में एक तालिका का प्रतिनिधित्व करती है, जो पूरी तरह से अव्यवस्थित है।
| company_id | <वें शैली="पाठ्य-संरेखण:केंद्र">इकाई <वें शैली="पाठ्य-संरेखण:दाएं">इकाई_लागत||
|---|---|---|
| 10 | 12 | 1.15 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1.31 |
| 18 | 18 | 1.34 |
| 11 | 24 | 1.15 |
| 16 | 12 | 1.31 |
| 10 | 12 | 1.15 |
| 12 | 24 | 1.3 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1.35 |
| 14 | 12 | 1.95 |
| 21 | 18 | 1.36 |
| 12 | 12 | 1.05 |
| 20 | 6 | 1.31 |
| 18 | 18 | 1.34 |
| 11 | 24 | 1.15 |
| 14 | 24 | 1.05 |
अगर हम निम्नलिखित क्वेरी चलाते हैं:
SELECT
company_id,
units,
unit_cost
FROM
index_test
WHERE
company_id = 18
डेटाबेस को सभी 17 पंक्तियों के माध्यम से तालिका में दिखाई देने के क्रम में, ऊपर से नीचे तक, एक समय में एक खोजना होगा। तो company_id . के सभी संभावित उदाहरणों को खोजने के लिए संख्या 18, डेटाबेस को company_id में 18 की सभी उपस्थितियों के लिए संपूर्ण तालिका को देखना चाहिए कॉलम।
तालिका का आकार बढ़ने पर इसमें केवल अधिक से अधिक समय लगेगा। जैसे-जैसे डेटा का परिष्कार बढ़ता है, अंततः क्या हो सकता है कि एक अरब पंक्तियों वाली एक तालिका एक अरब पंक्तियों वाली दूसरी तालिका के साथ जुड़ जाती है; क्वेरी को अब दोगुने समय की लागत वाली पंक्तियों की मात्रा से दोगुनी खोज करनी होगी।
आप देख सकते हैं कि यह कैसे हमारे डेटा से भरपूर दुनिया में समस्याग्रस्त हो जाता है। तालिकाओं का आकार बढ़ता है और निष्पादन समय में खोज बढ़ती है।
अनइंडेक्स की गई तालिका को क्वेरी करना, यदि दृश्य रूप से प्रस्तुत किया जाता है, तो यह ऐसा दिखाई देगा:
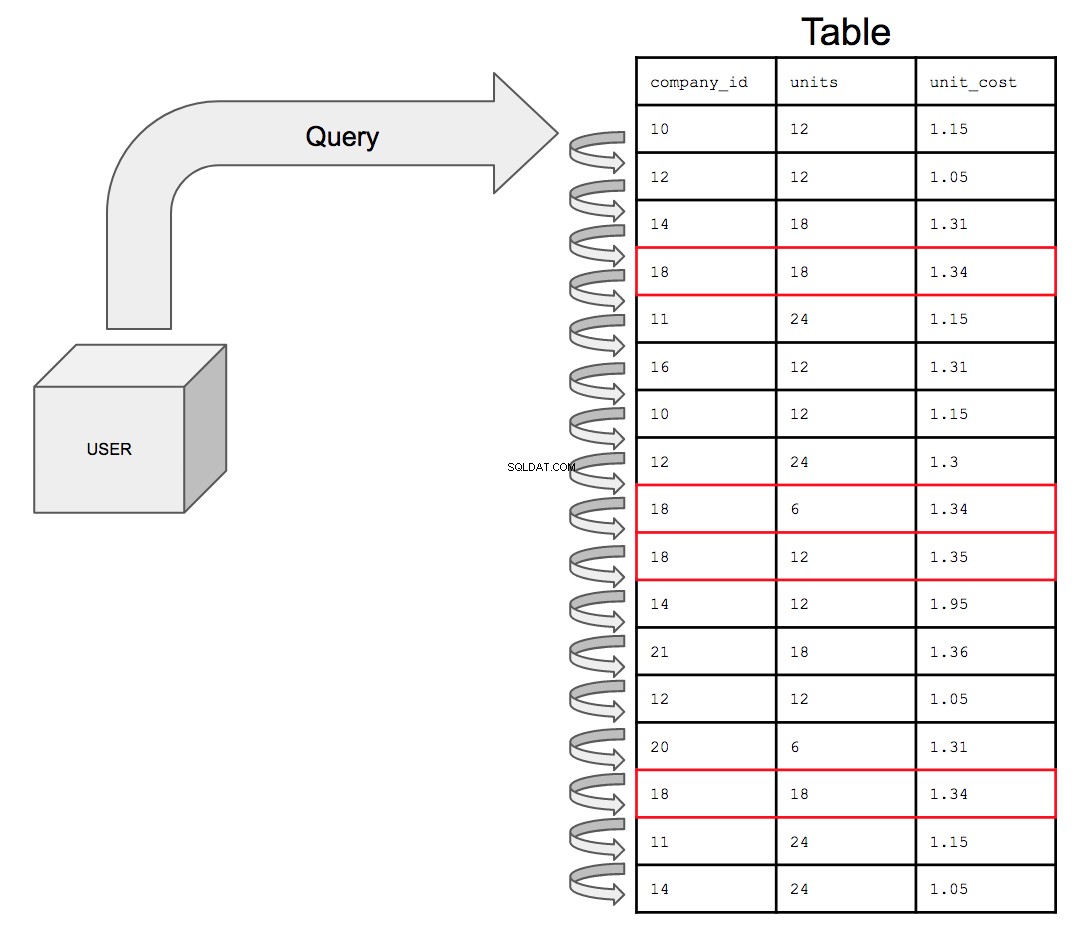
अनुक्रमण क्या करता है, क्वेरी प्रदर्शन को अनुकूलित करने में सहायता करने के लिए उस कॉलम को सेट करता है जिस पर आप खोज की स्थितियाँ क्रमबद्ध क्रम में चालू कर रहे हैं।
company_id . पर एक इंडेक्स के साथ स्तंभ, तालिका, अनिवार्य रूप से, इस तरह "दिखेंगे":
| company_id | <वें शैली="पाठ्य-संरेखण:केंद्र">इकाई <वें शैली="पाठ्य-संरेखण:दाएं">इकाई_लागत||
|---|---|---|
| 10 | 12 | 1.15 |
| 10 | 12 | 1.15 |
| 11 | 24 | 1.15 |
| 11 | 24 | 1.15 |
| 12 | 12 | 1.05 |
| 12 | 24 | 1.3 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1.31 |
| 14 | 12 | 1.95 |
| 14 | 24 | 1.05 |
| 16 | 12 | 1.31 |
| 18 | 18 | 1.34 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1.35 |
| 18 | 18 | 1.34 |
| 20 | 6 | 1.31 |
| 21 | 18 | 1.36 |
अब, डेटाबेस company_id . को खोज सकता है संख्या 18 और उस पंक्ति के लिए सभी अनुरोधित कॉलम लौटाएं और फिर अगली पंक्ति पर जाएं। अगर अगली पंक्ति का comapny_id . है संख्या भी 18 है तो यह क्वेरी में अनुरोधित सभी कॉलम वापस कर देगा। अगर अगली पंक्ति का company_id . है 20 है, क्वेरी खोजना बंद करना जानती है और क्वेरी समाप्त हो जाएगी।
इंडेक्सिंग कैसे काम करता है?
वास्तव में डेटाबेस तालिका हर बार क्वेरी के प्रदर्शन को अनुकूलित करने के लिए क्वेरी की स्थिति बदलने पर खुद को पुन:व्यवस्थित नहीं करती है:यह अवास्तविक होगा। वास्तव में, क्या होता है कि सूचकांक डेटाबेस को डेटा संरचना बनाने का कारण बनता है। डेटा संरचना प्रकार एक बी-ट्री होने की संभावना है। जबकि बी-ट्री के फायदे असंख्य हैं, हमारे उद्देश्यों के लिए मुख्य लाभ यह है कि यह क्रमबद्ध है। जब डेटा संरचना को क्रम में क्रमबद्ध किया जाता है तो यह हमारी खोज को उन स्पष्ट कारणों से अधिक कुशल बनाता है जिन्हें हमने ऊपर बताया था।
जब सूचकांक किसी विशिष्ट कॉलम पर डेटा संरचना बनाता है तो यह ध्यान रखना महत्वपूर्ण है कि डेटा संरचना में कोई अन्य कॉलम संग्रहीत नहीं है। ऊपर दी गई तालिका के लिए हमारी डेटा संरचना में केवल company_id होगा संख्याएं। इकाइयाँ और unit_cost डेटा संरचना में नहीं रखा जाएगा।
डेटाबेस को यह कैसे पता चलता है कि तालिका में कौन-सी अन्य फ़ील्ड वापस आनी हैं?
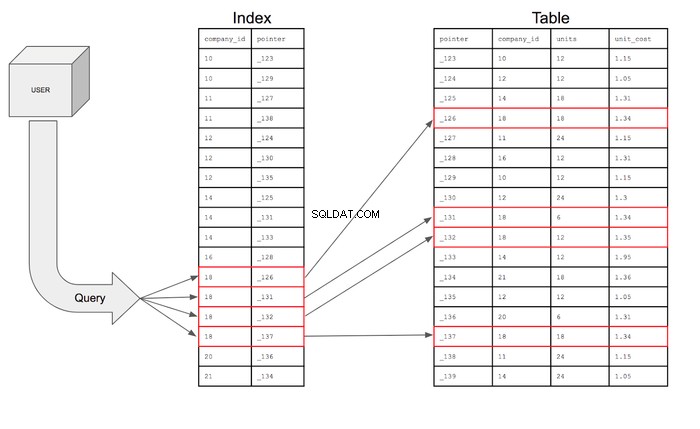
डेटाबेस इंडेक्स पॉइंटर्स को भी स्टोर करेंगे जो मेमोरी में अतिरिक्त जानकारी के स्थान के लिए केवल संदर्भ जानकारी हैं। मूल रूप से सूचकांक में company_id होता है और मेमोरी डिस्क पर उस विशेष पंक्ति का घर का पता। सूचकांक वास्तव में इस तरह दिखेगा:
| company_id | <वें शैली="पाठ्य-संरेखण:केंद्र">सूचक|
|---|---|
| 10 | _123 |
| 10 | _129 |
| 11 | _127 |
| 11 | _138 |
| 12 | _124 |
| 12 | _130 |
| 12 | _135 |
| 14 | _125 |
| 14 | _131 |
| 14 | _133 |
| 16 | _128 |
| 18 | _126 |
| 18 | _131 |
| 18 | _132 |
| 18 | _137 |
| 20 | _136 |
| 21 | _134 |
उस अनुक्रमणिका के साथ, क्वेरी company_id . में केवल पंक्तियों की खोज कर सकती है कॉलम जिसमें 18 है और फिर पॉइंटर का उपयोग करके उस विशिष्ट पंक्ति को खोजने के लिए तालिका में जा सकते हैं जहां वह सूचक रहता है। फिर क्वेरी शर्तों को पूरा करने वाली पंक्तियों के लिए अनुरोध किए गए कॉलम के लिए फ़ील्ड पुनर्प्राप्त करने के लिए तालिका में जा सकती है।
यदि खोज को दृष्टिगत रूप से प्रस्तुत किया जाता है, तो यह ऐसा दिखाई देगा:
रिकैप करें
- अनुक्रमण खोज स्थितियों और सूचक के लिए स्तंभों के साथ एक डेटा संरचना जोड़ता है
- सूचक शेष जानकारी के साथ पंक्ति की मेमोरी डिस्क पर पता है
- इंडेक्स डेटा संरचना को क्वेरी दक्षता को अनुकूलित करने के लिए क्रमबद्ध किया गया है
- क्वेरी इंडेक्स में विशिष्ट पंक्ति की तलाश करती है; सूचकांक उस सूचक को संदर्भित करता है जो शेष जानकारी प्राप्त करेगा।
- इंडेक्स उन पंक्तियों की संख्या को कम करता है जिन्हें क्वेरी को 17 से 4 तक खोजना होता है।