मैं लंबे समय से सही डेटा प्रकार चुनने का समर्थक रहा हूं। मैंने पिछले "बैड हैबिट्स" ब्लॉग पोस्ट में कुछ उदाहरणों के बारे में बात की है, लेकिन इस सप्ताह के अंत में SQL शनिवार #162 (कैम्ब्रिज, यूके) में, DATETIME का उपयोग करने का विषय है। डिफ़ॉल्ट रूप से सामने आया। मेरे टी-एसक्यूएल:बैड हैबिट्स एंड बेस्ट प्रैक्टिसेज प्रेजेंटेशन के बाद एक बातचीत में, एक उपयोगकर्ता ने कहा कि वे सिर्फ DATETIME का उपयोग करते हैं भले ही उन्हें केवल मिनट या दिन के लिए ग्रैन्युलैरिटी की आवश्यकता हो, इस प्रकार उनके उद्यम में दिनांक/समय कॉलम हमेशा एक ही डेटा प्रकार होते हैं। मैंने सुझाव दिया कि यह बेकार हो सकता है, और यह कि निरंतरता इसके लायक नहीं हो सकती है, लेकिन आज मैंने अपने सिद्धांत को साबित करने का फैसला किया।
TL;DR संस्करण
नीचे दिए गए मेरे परीक्षण से पता चलता है कि निश्चित रूप से ऐसे परिदृश्य हैं जहां आप DATETIME के साथ चिपके रहने के बजाय एक स्किनियर डेटा प्रकार का उपयोग करने पर विचार कर सकते हैं। हर जगह। लेकिन यह देखना महत्वपूर्ण है कि इसके लिए मेरे परीक्षणों ने दूसरी तरफ इशारा किया, और इन परिदृश्यों का परीक्षण आपके स्कीमा के खिलाफ, आपके पर्यावरण में, हार्डवेयर और डेटा के साथ करना भी महत्वपूर्ण है जो उत्पादन के लिए जितना संभव हो सके। आपके परिणाम भिन्न हो सकते हैं, और लगभग निश्चित रूप से भिन्न होंगे।
गंतव्य तालिकाएं
आइए उस मामले पर विचार करें जहां ग्रैन्युलैरिटी केवल दिन के लिए महत्वपूर्ण है (हमें घंटों, मिनटों, सेकंडों की परवाह नहीं है)। इसके लिए हम DATETIME चुन सकते हैं (जैसे प्रस्तावित उपयोगकर्ता), या SMALLDATETIME , या DATE SQL सर्वर 2008+ पर। दो अलग-अलग प्रकार के डेटा भी हैं जिन पर मैं विचार करना चाहता था:
- डेटा जो वास्तविक समय में मोटे तौर पर क्रमिक रूप से डाला जाएगा (उदाहरण के लिए जो घटनाएं अभी हो रही हैं);
- डेटा जो बेतरतीब ढंग से डाला जाएगा (जैसे नए सदस्यों की जन्मतिथि)।
मैंने निम्नलिखित की तरह 2 तालिकाओं के साथ शुरुआत की, फिर 4 और बनाए (स्मॉलडेटटाइम के लिए 2, DATE के लिए 2):
टेबल डीबीओ बनाएं।बर्थडेट्सरैंडम_डेटटाइम (आईडी पहचान पहचान (1,1) प्राथमिक कुंजी, डीटी डेटटाइम न्यूल नहीं); तालिका बनाएं dbo.EventsSequential_Datetime (आईडी INT पहचान (1,1) प्राथमिक कुंजी, दिनांक दिनांक पूर्ण नहीं); dbo.BirthDatesRandom_Datetime(dt) पर अनुक्रमणिका बनाएं; dbo.EventsSequential_Datetime(dt) पर अनुक्रमणिका बनाएं; -- फिर DATE और SMALLDATETIME के लिए दोहराएं।
और मेरा लक्ष्य उन दो अलग-अलग तरीकों से बैच इंसर्ट के प्रदर्शन का परीक्षण करना था, साथ ही साथ समग्र भंडारण आकार और विखंडन पर प्रभाव, और अंत में श्रेणी प्रश्नों के प्रदर्शन का परीक्षण करना था।
नमूना डेटा
कुछ नमूना डेटा उत्पन्न करने के लिए, मैंने अपनी एक उपयोगी तकनीक का उपयोग किसी ऐसी चीज़ से सार्थक बनाने के लिए किया जो नहीं है:कैटलॉग दृश्य। मेरे सिस्टम पर इसने लगभग 12 सेकंड में 971 विशिष्ट दिनांक/समय मान (कुल मिलाकर 1,000,000 पंक्तियाँ) लौटा दीं:
;वाई एएस के साथ (सेलेक्ट टॉप (1000000) d =DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20120101')) FROM ( सेलेक्ट s1.[object_id] % 1000 FROM sys.all_objects AS s1 क्रॉस में शामिल हों sys.all_objects AS s2 ) AS x (x) NEWID द्वारा ऑर्डर ()) y से DISTINCT d चुनें;
मैंने इन लाख पंक्तियों को एक तालिका में रखा है ताकि मैं तीन अलग-अलग सत्र विंडो से सटीक समान डेटा के लिए अलग-अलग एक्सेस विधियों का उपयोग करके अनुक्रमिक/यादृच्छिक सम्मिलन अनुकरण कर सकूं:
टेबल डीबीओ बनाएं। स्टेजिंग (आईडी पहचान पहचान (1,1) प्राथमिक कुंजी, स्रोत_डेट डेटाटाइम न्यूल नहीं);;स्टेजिंग_डेटा एएस के साथ (सेलेक्ट टॉप (1000000) डीटी =DATEADD (सेकंड, x, DATEADD (दिन, DATEDIFF (दिन, x, 0)), '20110101')) से (चुनें s1। [object_id]% 1000 sys.all_objects से एस 1 क्रॉस के रूप में एस 2 के रूप में sys.all_objects में शामिल हों) एएस एसडी (एक्स) ऑर्डर द्वारा NEWID ()) INSERT dbo.Staging (source_date) dt द्वारा y ऑर्डर से dt चुनें;
इस प्रक्रिया को पूरा होने में थोड़ा अधिक समय लगा (20 सेकंड)। फिर मैंने उसी डेटा को स्टोर करने के लिए दूसरी तालिका बनाई लेकिन यादृच्छिक रूप से वितरित की (ताकि मैं सभी प्रविष्टियों में समान वितरण दोहरा सकूं)।
टेबल डीबीओ बनाएं। स्टेजिंग_रैंडम (आईडी पहचान पहचान (1,1) प्राथमिक कुंजी, स्रोत_डेट डेटटाइम न्यूल नहीं); INSERT dbo.Staging_Random(source_date) dbo से स्रोत_तिथि चुनें। NEWID द्वारा स्टेजिंग ऑर्डर ();
तालिकाओं को भरने के लिए प्रश्न
इसके बाद, मैंने इस डेटा के साथ अन्य तालिकाओं को पॉप्युलेट करने के लिए प्रश्नों का एक सेट लिखा, कम से कम थोड़ी सी समरूपता का अनुकरण करने के लिए तीन क्वेरी विंडो का उपयोग किया:
प्रतीक्षा समय '13:53'; GO DECLARE @d DATETIME2 =SYSDATETIME(); INSERT dbo.{table_name}(dt) -- विधि/डेटा प्रकार के आधार पर dbo.Staging[_Random] से स्रोत_तिथि चुनें -- गंतव्य के आधार पर जहां आईडी% 3 =<0,1,2> -- क्वेरी विंडो पर निर्भर करता है ORDER आईडी द्वारा; दिनांकित चुनें (मिलीसेकंड, @d, SYSDATETIME ()); अपनी पिछली पोस्ट की तरह, मैंने किसी भी प्रकार की डेटा फ़ाइल ऑटो-ग्रोथ इवेंट्स को परिणामों में हस्तक्षेप करने से रोकने के लिए डेटाबेस का पूर्व-विस्तार किया। मुझे एहसास है कि यह एक पास में मिलियन-पंक्ति सम्मिलन करने के लिए पूरी तरह यथार्थवादी नहीं है, क्योंकि मैं इतने बड़े लेनदेन के लिए लॉग गतिविधि को हस्तक्षेप करने से नहीं रोक सकता, लेकिन इसे प्रत्येक विधि में लगातार ऐसा करना चाहिए। यह देखते हुए कि जिस हार्डवेयर के साथ मैं परीक्षण कर रहा हूं वह आपके द्वारा उपयोग किए जा रहे हार्डवेयर से पूरी तरह से अलग है, पूर्ण परिणाम एक महत्वपूर्ण टेकअवे नहीं होना चाहिए, केवल सापेक्ष तुलना।
(भविष्य के परीक्षण में मैं अपेक्षाकृत मिश्रित डेटा के साथ लॉग फ़ाइलों से आने वाले वास्तविक बैचों के साथ और लूप में स्रोत तालिका के हिस्सों का उपयोग करके भी कोशिश करूंगा - मुझे लगता है कि वे दिलचस्प प्रयोग भी होंगे। और निश्चित रूप से जोड़ना मिश्रण में संपीड़न।)
परिणाम:
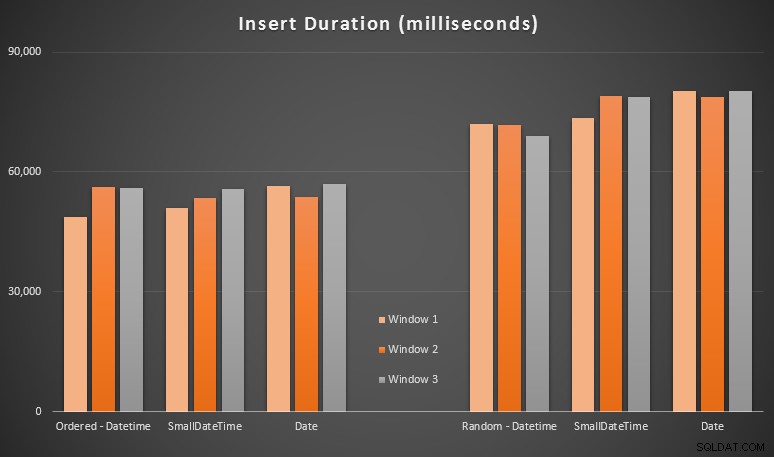
ये सभी परिणाम मेरे लिए आश्चर्यजनक नहीं थे - यादृच्छिक क्रम में डालने से क्रमिक रूप से सम्मिलित करने की तुलना में लंबे समय तक चलने का कारण बनता है, कुछ ऐसा जो हम सभी अपनी जड़ों में वापस ले सकते हैं यह समझने की कि SQL सर्वर में अनुक्रमणिका कैसे काम करती है और "खराब" पृष्ठ विभाजन कितना अधिक हो सकता है यह परिदृश्य (मैंने इस अभ्यास में पृष्ठ विभाजन के लिए विशेष रूप से निगरानी नहीं की थी, लेकिन यह कुछ ऐसा है जिसे मैं भविष्य के परीक्षणों में विचार करूंगा)।
मैंने देखा कि, यादृच्छिक रूप से, आने वाले डेटा पर निहित रूपांतरणों का समय पर प्रभाव पड़ सकता है, क्योंकि वे मूल DATETIME -> DATETIME से थोड़ा अधिक लग रहे थे। सम्मिलित करता है। इसलिए मैंने स्रोत डेटा वाली दो नई तालिकाएँ बनाने का निर्णय लिया:एक DATE . का उपयोग करके और एक SMALLDATETIME . का उपयोग कर रहा है . यह कुछ हद तक अनुकरण करेगा, आपके डेटा प्रकार को सम्मिलित विवरण में पास करने से पहले ठीक से परिवर्तित कर देगा, जैसे कि सम्मिलन के दौरान एक अंतर्निहित रूपांतरण की आवश्यकता नहीं होती है। यहां नई तालिकाएं दी गई हैं और वे कैसे भरे गए थे:
टेबल डीबीओ बनाएं। स्टेजिंग_रैंडम_स्मॉलडेटटाइम (आईडी आईएनटी पहचान (1,1) प्राथमिक कुंजी, स्रोत_डेट स्मॉलडेटटाइम न्यूल नहीं); तालिका बनाएं dbo.Staging_Random_Date (आईडी INT पहचान (1,1) प्राथमिक कुंजी, स्रोत_डेट दिनांक पूर्ण नहीं); INSERT dbo.Staging_Random_SmallDatetime(source_date) सेलेक्ट कन्वर्ट (SMALLDATETIME, source_date) dbo से। स्टेजिंग_रैंडम ऑर्डर द्वारा आईडी; INSERT dbo.Staging_Random_Date(source_date) dbo.Staging_Random ORDER by ID;से कनवर्ट करें (दिनांक, स्रोत_तिथि) चुनें;
इसका वह प्रभाव नहीं पड़ा जिसकी मैं उम्मीद कर रहा था - सभी मामलों में समय समान था। तो यह एक जंगली हंस का पीछा था।
उपयोग की गई जगह और विखंडन
प्रत्येक तालिका के लिए कितने पृष्ठ आरक्षित थे, यह निर्धारित करने के लिए मैंने निम्नलिखित क्वेरी चलाई:
नाम चुनें ='डीबीओ'। + OBJECT_NAME([object_id]), पेज =SUM(reserved_page_count) sys.dm_db_partition_stats GROUP BY OBJECT_NAME([object_id]) पेजों के अनुसार ऑर्डर करें;
परिणाम:
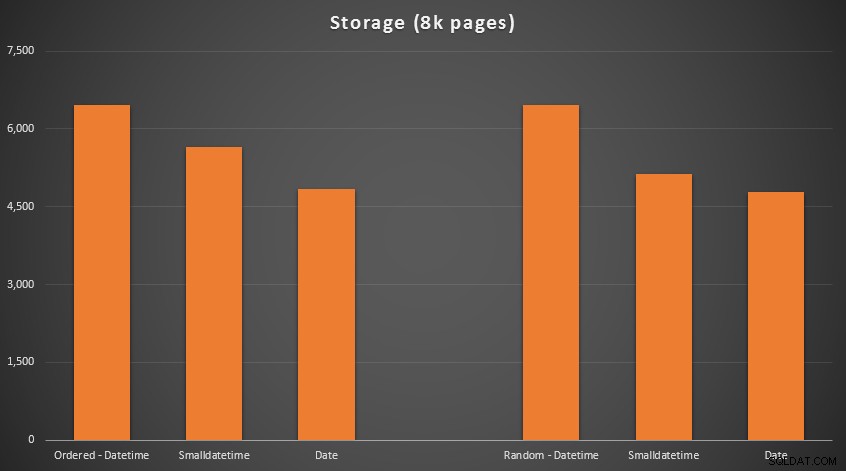
यहां कोई रॉकेट साइंस नहीं है; छोटे डेटा प्रकार का उपयोग करें, आपको कम पृष्ठों का उपयोग करना चाहिए। DATETIME से स्विच किया जा रहा है से DATE . तक उपयोग किए गए पृष्ठों की संख्या में लगातार 25% की कमी आई, जबकि SMALLDATETIME आवश्यकता को 13-20% तक कम कर दिया।
अब गैर-संकुल अनुक्रमणिका पर विखंडन और पृष्ठ घनत्व के लिए (संकुल अनुक्रमणिका के लिए बहुत कम अंतर था):
चुनें '{table_name}', index_id avg_page_space_used_in_percent, avg_fragmentation_in_percent से sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID('{table_name}'), NULL,<, 'DETAILED_level =0 जहां इंडेक्स; /पूर्व>
परिणाम:
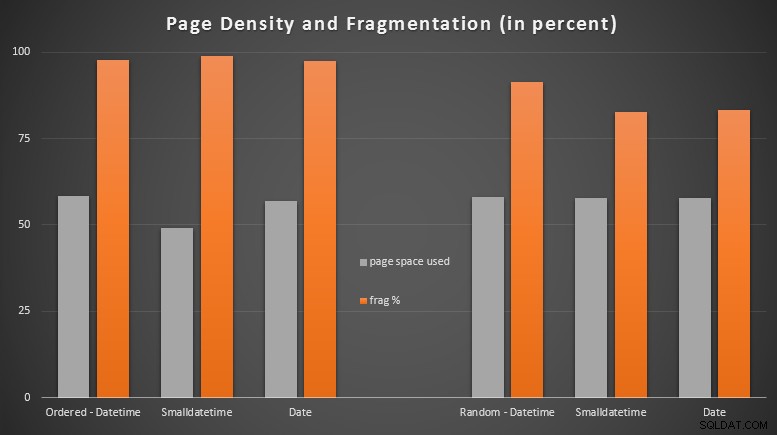
मुझे यह देखकर काफी आश्चर्य हुआ कि ऑर्डर किया गया डेटा लगभग पूरी तरह से खंडित हो गया है, जबकि डेटा जो बेतरतीब ढंग से डाला गया था, वास्तव में थोड़ा बेहतर पेज उपयोग के साथ समाप्त हुआ। मैंने एक नोट किया है कि यह इन विशिष्ट परीक्षणों के दायरे से बाहर आगे की जांच की गारंटी देता है, लेकिन यह कुछ ऐसा हो सकता है जिसे आप जांचना चाहेंगे कि क्या आपके पास गैर-संकुल अनुक्रमणिका हैं जो बड़े पैमाने पर अनुक्रमिक सम्मिलन पर निर्भर हैं।
[सभी 6 टेबलों पर गैर-संकुलित अनुक्रमितों का एक ऑनलाइन पुनर्निर्माण 7 सेकंड में चला, पृष्ठ घनत्व को 99.5% सीमा तक वापस लाया, और विखंडन को 1% से नीचे लाया। लेकिन मैंने इसे तब तक नहीं चलाया जब तक कि नीचे दिए गए क्वेरी परीक्षण नहीं किए गए...]
श्रेणी क्वेरी परीक्षण
अंत में, मैं ओएलटीपी-प्रकार की लेखन गतिविधि के कारण निहित विखंडन के साथ, और फिर से बनाए गए एक स्वच्छ सूचकांक पर, विभिन्न इंडेक्स के खिलाफ सरल दिनांक सीमा प्रश्नों के लिए रनटाइम पर प्रभाव देखना चाहता था। क्वेरी अपने आप में बहुत आसान है:
डीबीओ से टॉप (200000) डीटी चुनें। {table_name} जहां डीटी> ='20110101' डीटी द्वारा ऑर्डर करें;
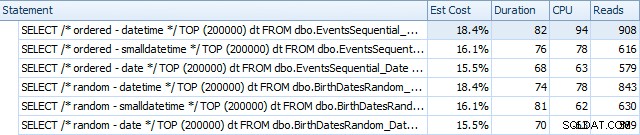
SQL संतरी योजना एक्सप्लोरर का उपयोग करके, अनुक्रमणिका के पुनर्निर्माण से पहले के परिणाम यहां दिए गए हैं:
और वे पुनर्निर्माण के बाद थोड़ा भिन्न होते हैं:
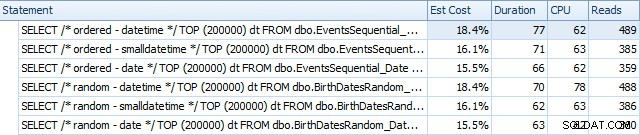
अनिवार्य रूप से हम थोड़ी अधिक अवधि देखते हैं और DATETIME संस्करणों के लिए पढ़ते हैं, लेकिन CPU में बहुत कम अंतर होता है। और तुलना में SMALLDATETIME और DATE के बीच का अंतर नगण्य है। सभी प्रश्नों में इस तरह की सरल क्वेरी योजनाएँ थीं:

(सीक, निश्चित रूप से, एक ऑर्डर किया गया रेंज स्कैन है।)
निष्कर्ष
हालांकि माना जाता है कि ये परीक्षण काफी मनगढ़ंत हैं और अधिक क्रमपरिवर्तन से लाभान्वित हो सकते हैं, वे मोटे तौर पर वही दिखाते हैं जो मुझे देखने की उम्मीद थी:इस विशिष्ट पसंद पर सबसे बड़ा प्रभाव गैर-संकुल सूचकांक द्वारा कब्जा किए गए स्थान पर है (जहां एक स्किनियर डेटा प्रकार चुनना होगा) निश्चित रूप से लाभ), और अनुक्रमिक, क्रम के बजाय मनमाने ढंग से सम्मिलित करने के लिए आवश्यक समय पर (जहां DATETIME केवल एक सीमांत किनारा है)।
मुझे आपके विचारों को सुनना अच्छा लगेगा कि इस तरह के डेटा प्रकार विकल्पों को अधिक गहन और दंडात्मक परीक्षणों के माध्यम से कैसे रखा जाए। मेरी भविष्य की पोस्टों में अधिक विवरण में जाने की योजना है।