SQL डेटाबेस में इंडेक्स स्पीड-बूस्टर हैं। उन्हें क्लस्टर या गैर-क्लस्टर किया जा सकता है। लेकिन इसका क्या मतलब है और आपको प्रत्येक को कहां लागू करना चाहिए?
मैं इस एहसास को जानता हूँ। में वहा गया था। प्रथम-टाइमर अक्सर भ्रमित होते हैं कि किस कॉलम पर किस इंडेक्स का उपयोग करना है। हालांकि, यहां तक कि विशेषज्ञों को भी निर्णय लेने से पहले इस मुद्दे पर विचार करने की जरूरत है, और विभिन्न स्थितियों के लिए अलग-अलग निर्णयों की आवश्यकता होती है। जैसा कि आप बाद में देखेंगे, ऐसे प्रश्न हैं जहां एक गैर-संकुल सूचकांक की तुलना में एक संकुल सूचकांक चमकेगा, और इसके विपरीत।
फिर भी, पहले हमें उनमें से प्रत्येक को जानना होगा। अगर आप भी ऐसी ही जानकारी की तलाश में हैं, तो आज का दिन आपका भाग्यशाली दिन है।
यह आलेख आपको बताएगा कि ये अनुक्रमणिका क्या हैं और प्रत्येक का उपयोग कब करना है। बेशक, अभ्यास में प्रयास करने के लिए आपके लिए कोड नमूने होंगे। तो, अपने चिप्स या पिज्जा और कुछ सोडा या कॉफी ले लो, और इस अंतर्दृष्टिपूर्ण यात्रा में खुद को विसर्जित करने के लिए तैयार हो जाओ।
तैयार हैं?
संकुल अनुक्रमणिका क्या है
क्लस्टर्ड इंडेक्स एक इंडेक्स है जो टेबल या व्यू में पंक्तियों के भौतिक क्रम को परिभाषित करता है।
इसे वास्तविक रूप में देखने के लिए, आइए कर्मचारी . को लें AdventureWorks2017 . में तालिका डेटाबेस।
प्राथमिक कुंजी भी एक संकुल अनुक्रमणिका है, और कुंजी BusinessEntityID पर आधारित है कॉलम। जब आप ORDER BY के बिना इस तालिका पर एक चयन करते हैं, तो आप देखेंगे कि यह प्राथमिक कुंजी द्वारा क्रमबद्ध है।
नीचे दिए गए कोड का उपयोग करके इसे स्वयं आज़माएं:
USE AdventureWorks2017
GO
SELECT TOP 10 * FROM HumanResources.Employee
GO
अब, चित्र 1 में परिणाम देखें:
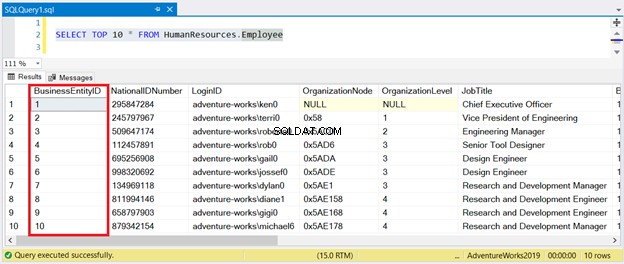
जैसा कि आप देख सकते हैं, आपको परिणाम सेट को BusinessEntityID के साथ क्रमित करने की आवश्यकता नहीं है . क्लस्टर्ड इंडेक्स इसका ख्याल रखता है।
गैर-संकुल अनुक्रमणिका के विपरीत, आपके पास प्रति तालिका केवल 1 संकुल अनुक्रमणिका हो सकती है। क्या होगा अगर हम इसे कर्मचारी . पर आजमाएं टेबल?
CREATE CLUSTERED INDEX IX_Employee_NationalID
ON HumanResources.Employee (NationalIDNumber)
GO
हमारे पास नीचे एक समान त्रुटि है:
Msg 1902, Level 16, State 3, Line 4
Cannot create more than one clustered index on table 'HumanResources.Employee'. Drop the existing clustered index 'PK_Employee_BusinessEntityID' before creating another.
क्लस्टर इंडेक्स का उपयोग कब करें?
यदि निम्न में से कोई एक सत्य है तो एक कॉलम क्लस्टर इंडेक्स के लिए सबसे अच्छा उम्मीदवार है:
- इसका उपयोग WHERE क्लॉज और जॉइन में बड़ी संख्या में प्रश्नों में किया जाता है।
- इसका उपयोग किसी अन्य तालिका में विदेशी कुंजी के रूप में किया जाएगा, और अंततः, जुड़ने के लिए किया जाएगा।
- अद्वितीय स्तंभ मान.
- मान बदलने की संभावना कम होगी।
- उस कॉलम का उपयोग कई प्रकार के मानों को क्वेरी करने के लिए किया जाता है। WHERE क्लॉज में कॉलम के साथ>, <,>=, <=या BETWEEN जैसे ऑपरेटरों का उपयोग किया जाता है।
लेकिन अगर कॉलम या कॉलम में क्लस्टर इंडेक्स अच्छा नहीं है
- अक्सर बदलते हैं
- विस्तृत कुंजी या बड़े कुंजी आकार वाले स्तंभों का संयोजन हैं।
उदाहरण
क्लस्टर्ड इंडेक्स टी-एसक्यूएल कोड या किसी एसक्यूएल सर्वर जीयूआई उपकरण का उपयोग करके बनाया जा सकता है। टेबल बनाने पर आप इसे टी-एसक्यूएल में इस तरह कर सकते हैं:
CREATE TABLE [Person].[Person](
[BusinessEntityID] [int] NOT NULL,
[PersonType] [nchar](2) NOT NULL,
[NameStyle] [dbo].[NameStyle] NOT NULL,
[Title] [nvarchar](8) NULL,
[FirstName] [dbo].[Name] NOT NULL,
[MiddleName] [dbo].[Name] NULL,
[LastName] [dbo].[Name] NOT NULL,
[Suffix] [nvarchar](10) NULL,
[EmailPromotion] [int] NOT NULL,
[AdditionalContactInfo] [xml](CONTENT [Person].[AdditionalContactInfoSchemaCollection]) NULL,
[Demographics] [xml](CONTENT [Person].[IndividualSurveySchemaCollection]) NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED
(
[BusinessEntityID] ASC
)
GO
या, आप ALTER TABLE बाद . का उपयोग करके ऐसा कर सकते हैं बिना संकुल अनुक्रमणिका के तालिका बनाना:
ALTER TABLE Person.Person ADD CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED (BusinessEntityID)
GO
दूसरा तरीका CREATE CLUSTERED INDEX का उपयोग करना है:
CREATE CLUSTERED INDEX [PK_Person_BusinessEntityID] ON Person.Person (BusinessEntityID)
GO
एक और विकल्प SQL सर्वर टूल जैसे SQL सर्वर प्रबंधन स्टूडियो या SQL सर्वर के लिए dbForge स्टूडियो का उपयोग करना है।
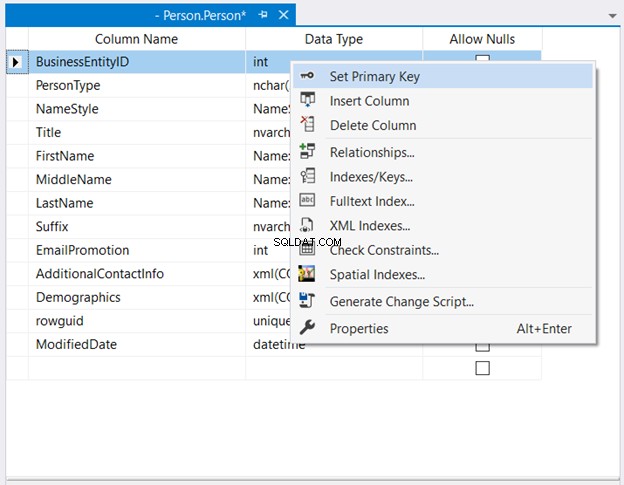
ऑब्जेक्ट एक्सप्लोरर . में , डेटाबेस और टेबल नोड्स का विस्तार करें। फिर, इच्छित तालिका पर राइट-क्लिक करें और डिज़ाइन . चुनें . अंत में, उस कॉलम पर राइट-क्लिक करें जिसे आप प्राथमिक कुंजी बनाना चाहते हैं> प्राथमिक कुंजी सेट करें > परिवर्तनों को तालिका में सहेजें।
नीचे दिया गया चित्र 2 दिखाता है कि BusinessEntityID . कहां है प्राथमिक कुंजी के रूप में सेट है।
सिंगल-कॉलम क्लस्टर इंडेक्स बनाने के अलावा, आप कई कॉलम का उपयोग कर सकते हैं। टी-एसक्यूएल में एक उदाहरण देखें:
[व्यक्ति] परCREATE CLUSTERED INDEX [IX_Person_LastName_FirstName_MiddleName] ON [Person].[Person]
(
[LastName] ASC,
[FirstName] ASC,
[MiddleName] ASC
)
GO
इस क्लस्टर इंडेक्स को बनाने के बाद, व्यक्ति तालिका को भौतिक रूप से अंतिम नाम . द्वारा क्रमबद्ध किया जाएगा , प्रथम नाम , और मध्य नाम ।
इस दृष्टिकोण के फायदों में से एक नाम के आधार पर बेहतर क्वेरी प्रदर्शन है। इसके अलावा, यह ORDER BY निर्दिष्ट किए बिना परिणामों को नाम से क्रमबद्ध करता है। लेकिन ध्यान रहे कि नाम बदलने पर टेबल को फिर से व्यवस्थित करना होगा। हालांकि यह हर दिन नहीं होगा, अगर तालिका बहुत बड़ी है तो प्रभाव बहुत बड़ा हो सकता है।
गैर-संकुल अनुक्रमणिका क्या है
एक गैर-संकुल सूचकांक एक सूचकांक है जिसमें एक कुंजी और पंक्तियों या क्लस्टर सूचकांक कुंजियों के लिए एक सूचक होता है। यह इंडेक्स टेबल और व्यू दोनों पर लागू हो सकता है।
क्लस्टर्ड इंडेक्स के विपरीत, यहां संरचना तालिका से अलग है। चूंकि यह अलग है, इसलिए इसे टेबल पंक्तियों के लिए एक पॉइंटर की आवश्यकता होती है जिसे रो लोकेटर भी कहा जाता है। इस प्रकार, गैर-संकुल अनुक्रमणिका में प्रत्येक प्रविष्टि में एक लोकेटर और एक प्रमुख मान होता है।
गैर-संकुल सूचकांक कुंजी के आधार पर तालिका को भौतिक रूप से क्रमबद्ध नहीं करते हैं।
गैर-संकुल अनुक्रमणिका के लिए अनुक्रमणिका कुंजियों का अधिकतम आकार 1700 बाइट्स होता है। आप शामिल कॉलम जोड़कर इस सीमा को बायपास कर सकते हैं। यदि आपकी क्वेरी को कुंजी आकार बढ़ाए बिना अधिक स्तंभों को कवर करने की आवश्यकता है तो यह विधि अच्छी है।
आप फ़िल्टर किए गए गैर-संकुल अनुक्रमणिका भी बना सकते हैं। यह क्वेरी प्रदर्शन में सुधार करते हुए अनुक्रमणिका रखरखाव लागत और संग्रहण को कम करेगा।
गैर-संकुल अनुक्रमणिका का उपयोग कब करें?
यदि निम्न सत्य है तो एक कॉलम या कॉलम गैर-संकुल अनुक्रमणिका के लिए अच्छे उम्मीदवार हैं:
- कॉलम या कॉलम का उपयोग WHERE क्लॉज या जॉइन में किया जाता है।
- क्वेरी एक बड़ा परिणाम सेट नहीं लौटाएगी।
- समानता ऑपरेटर का उपयोग करते हुए WHERE क्लॉज में सटीक मिलान की आवश्यकता है।
उदाहरण
यह आदेश कर्मचारी . में एक अद्वितीय, गैर-संकुल अनुक्रमणिका तैयार करेगा तालिका:
[HumanResources] परCREATE UNIQUE NONCLUSTERED INDEX [AK_Employee_NationalIDNumber] ON [HumanResources].[Employee]
(
[NationalIDNumber] ASC
)
GO
तालिका के अलावा, आप दृश्य के लिए एक गैर-संकुल अनुक्रमणिका बना सकते हैं:
[उत्पादन] परCREATE NONCLUSTERED INDEX [IDX_vProductAndDescription_ProductModel] ON [Production].[vProductAndDescription]
(
[ProductModel] ASC
)
GO
अन्य सामान्य प्रश्न और संतोषजनक उत्तर
क्लस्टर और नॉन-क्लस्टर इंडेक्स में क्या अंतर हैं?
आपने पहले जो देखा था, उससे आप पहले से ही इस बारे में विचार बना सकते हैं कि विभिन्न क्लस्टर और गैर-संकुल सूचकांक कैसे हैं। लेकिन चलिए इसे आसान संदर्भ के लिए एक टेबल पर रखते हैं।
| जानकारी | संकुल अनुक्रमणिका | गैर-संकुल अनुक्रमणिका |
| इस पर लागू होता है | टेबल और दृश्य | टेबल और दृश्य |
| प्रति तालिका अनुमत | 1 | 999 |
| कुंजी आकार | 900 बाइट्स | 1700 बाइट्स |
| कॉलम प्रति अनुक्रमणिका कुंजी | 32 | 32 |
| के लिए अच्छा है | श्रेणी क्वेरी (>,<,>=, <=, बीच में) | सटीक मिलान (=) |
| गैर-कुंजी शामिल कॉलम | अनुमति नहीं है | अनुमति है |
| शर्त के साथ फ़िल्टर करें | अनुमति नहीं है | अनुमति है |
प्राथमिक कुंजियों को क्लस्टर किया जाना चाहिए या गैर-संकुल अनुक्रमणिका?
एक प्राथमिक कुंजी एक बाधा है। एक बार जब आप किसी कॉलम को प्राथमिक कुंजी बना लेते हैं, तो उसमें से एक क्लस्टर इंडेक्स अपने आप बन जाता है, जब तक कि कोई मौजूदा क्लस्टर इंडेक्स पहले से मौजूद न हो।
एक प्राथमिक कुंजी को संकुल अनुक्रमणिका के साथ भ्रमित न करें! एक प्राथमिक कुंजी क्लस्टर्ड इंडेक्स कुंजी भी हो सकती है। लेकिन एक संकुल अनुक्रमणिका कुंजी प्राथमिक कुंजी के अलावा कोई अन्य स्तंभ हो सकती है।
आइए एक और उदाहरण लेते हैं। व्यक्ति . में AdventureWorks201 . की तालिका 7, हमारे पास BusinessEntityID है प्राथमिक कुंजी। यह संकुल अनुक्रमणिका कुंजी भी है। आप उस संकुल अनुक्रमणिका को छोड़ सकते हैं। फिर, अंतिम नाम . के आधार पर एक संकुल अनुक्रमणिका बनाएं , प्रथम नाम , और मध्य नाम . प्राथमिक कुंजी अभी भी BusinessEntityID है स्तंभ।
लेकिन क्या आपकी प्राथमिक कुंजियों को हमेशा क्लस्टर किया जाना चाहिए?
निर्भर करता है। क्लस्टर इंडेक्स का उपयोग कब करना है, इस प्रश्न पर फिर से विचार करें।
यदि आपके WHERE क्लॉज में बहुत सारे प्रश्नों में कोई कॉलम या कॉलम दिखाई देता है, तो यह क्लस्टर इंडेक्स के लिए एक उम्मीदवार है। लेकिन एक और विचार यह है कि संकुल सूचकांक कुंजी कितनी चौड़ी है। बहुत चौड़ा - और प्रत्येक गैर-संकुल सूचकांक का आकार बढ़ जाएगा यदि वे मौजूद हैं। याद रखें कि गैर-संकुल अनुक्रमणिका भी सूचक के रूप में संकुल अनुक्रमणिका कुंजी का उपयोग करती है। इसलिए, अपनी संकुल अनुक्रमणिका कुंजी को यथासंभव संकीर्ण रखें।
यदि बड़ी संख्या में क्वेरीज़ WHERE क्लॉज में प्राथमिक कुंजी का उपयोग करती हैं, तो इसे क्लस्टर इंडेक्स कुंजी के रूप में भी छोड़ दें। यदि नहीं, तो अपनी प्राथमिक कुंजी को गैर-संकुल अनुक्रमणिका के रूप में बनाएं।
लेकिन क्या होगा अगर आप अभी भी अनिश्चित हैं? फिर, आप किसी स्तंभ के प्रदर्शन लाभ का आकलन कर सकते हैं जब वह क्लस्टर या गैर-संकुल हो। तो, इसके बारे में अगले भाग में ट्यून करें।
कौन सा तेज़ है:संकुलित या गैर-संकुल सूचकांक?
अच्छा प्रश्न। कोई सामान्य नियम नहीं है। आपको अपने प्रश्नों के तार्किक पठन और निष्पादन योजना की जांच करने की आवश्यकता है।
हमारे संक्षिप्त प्रयोग में AdventureWorks2017 . से निम्नलिखित तालिकाओं की प्रतियां शामिल होंगी डेटाबेस:
- व्यक्ति
- BusinessEntityAddress
- पता
- पता प्रकार
ये रही स्क्रिप्ट:
IF NOT EXISTS(SELECT name FROM sys.databases WHERE name = 'TestDatabase')
BEGIN
CREATE DATABASE TestDatabase
END
USE TestDatabase
GO
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkClustered FROM AdventureWorks2017.Person.Person
ALTER TABLE Person_pkClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID2] PRIMARY KEY CLUSTERED (BusinessEntityID)
CREATE NONCLUSTERED INDEX [IX_Person_Name2] ON Person_pkClustered (LastName, FirstName, MiddleName, Suffix)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkNonClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkNonClustered FROM AdventureWorks2017.Person.Person
CREATE CLUSTERED INDEX [IX_Person_Name1] ON Person_pkNonClustered (LastName, FirstName, MiddleName, Suffix)
ALTER TABLE Person_pkNonClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID1] PRIMARY KEY NONCLUSTERED (BusinessEntityID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'AddressType')
BEGIN
SELECT * INTO AddressType FROM AdventureWorks2017.Person.AddressType
ALTER TABLE AddressType
ADD CONSTRAINT [PK_AddressType] PRIMARY KEY CLUSTERED (AddressTypeID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Address')
BEGIN
SELECT * INTO Address FROM AdventureWorks2017.Person.Address
ALTER TABLE Address
ADD CONSTRAINT [PK_Address] PRIMARY KEY CLUSTERED (AddressID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'BusinessEntityAddress')
BEGIN
SELECT * INTO BusinessEntityAddress FROM AdventureWorks2017.Person.BusinessEntityAddress
ALTER TABLE BusinessEntityAddress
ADD CONSTRAINT [PK_BusinessEntityAddress] PRIMARY KEY CLUSTERED (BusinessEntityID, AddressID, AddressTypeID)
END
GO
ऊपर दी गई संरचना का उपयोग करते हुए, हम क्लस्टर्ड और गैर-क्लस्टर इंडेक्स के लिए क्वेरी गति की तुलना करेंगे।
हमारे पास व्यक्ति . की 2 प्रतियां हैं टेबल। पहला BusinessEntityID . का उपयोग करेगा प्राथमिक और संकुल सूचकांक कुंजी के रूप में। दूसरा अभी भी BusinessEntityID . का उपयोग करता है प्राथमिक कुंजी के रूप में। संकुल अनुक्रमणिका अंतिम नाम . पर आधारित है , प्रथम नाम , मध्य नाम , और प्रत्यय ।
आइए शुरू करते हैं।
अंतिम नाम के आधार पर सटीक सटीक मिलान करें
सबसे पहले, आइए एक साधारण क्वेरी करें। साथ ही, सांख्यिकी IO को चालू करने की आवश्यकता है। फिर, हम एक सारणीबद्ध प्रस्तुति के लिए परिणाम सांख्यिकीपार्सर.कॉम में चिपकाते हैं।
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, p.Title
FROM Person_pkClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SET STATISTICS IO OFF
GO
उम्मीद है कि पहला चयन धीमा होगा क्योंकि WHERE क्लॉज क्लस्टर्ड इंडेक्स कुंजी से मेल नहीं खाता है। लेकिन आइए तार्किक पठन की जाँच करें।
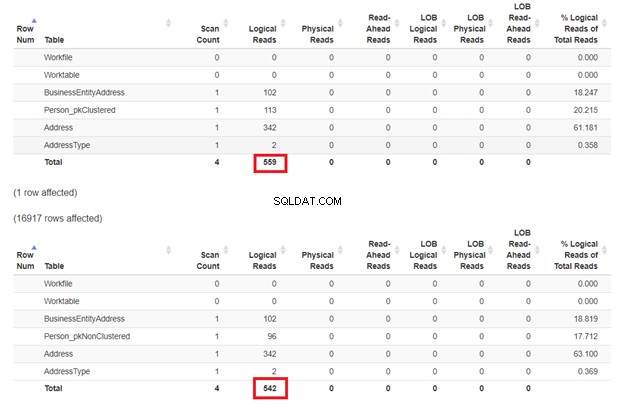
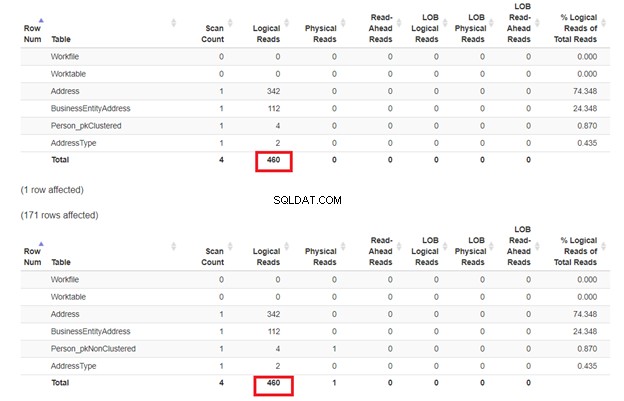
जैसा कि चित्र 3 में अपेक्षित है, Person_pkClustered अधिक तार्किक पठन था। इसलिए, क्वेरी को अधिक I/O की आवश्यकता है। द रीज़न? तालिका को BusinessEntityID . द्वारा क्रमबद्ध किया गया है . फिर भी, दूसरी तालिका में नाम के आधार पर संकुल सूचकांक है। चूंकि क्वेरी नाम के आधार पर परिणाम चाहती है, Person_pkNonClustered जीतता है। कम तार्किक पढ़ता है, तेजी से क्वेरी।
और क्या चल रहा है? चित्र 4 देखें।
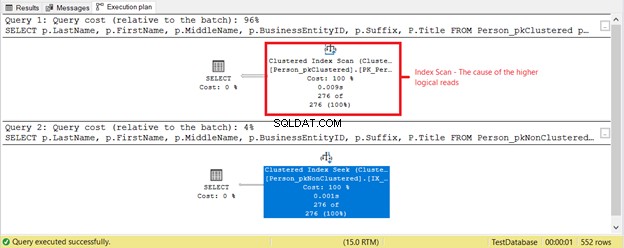
चित्रा 4 में निष्पादन योजना के आधार पर कुछ और हुआ। एक क्लस्टर इंडेक्स स्कैन इंडेक्स सीक के बजाय पहले चयन में क्यों है? अपराधी है शीर्षक चयन में कॉलम। यह किसी भी मौजूदा इंडेक्स द्वारा कवर नहीं किया गया है। SQL सर्वर अनुकूलक ने BusinessEntityID के आधार पर संकुल अनुक्रमणिका का उपयोग करना अधिक तेज़ समझा। फिर, SQL सर्वर ने इसे सही अंतिम नामों के लिए स्कैन किया और पहला नाम, मध्य नाम और शीर्षक प्राप्त किया।
शीर्षक निकालें कॉलम, और इस्तेमाल किया गया ऑपरेटर इंडेक्स सीक . होगा . क्यों? क्योंकि शेष फ़ील्ड अंतिम नाम के आधार पर गैर-संकुल अनुक्रमणिका द्वारा कवर किए जाते हैं , प्रथम नाम , मध्य नाम , और प्रत्यय . इसमें BusinessEntityID . भी शामिल है संकुल अनुक्रमणिका कुंजी लोकेटर के रूप में।
व्यावसायिक इकाई आईडी के आधार पर श्रेणी क्वेरी
क्लस्टर्ड इंडेक्स रेंज क्वेरी के लिए अच्छे हो सकते हैं। क्या हमेशा ऐसा ही होता है? आइए नीचे दिए गए कोड का उपयोग करके पता करें।
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SET STATISTICS IO OFF
GO
लिस्टिंग को BusinessEntityIDs . की श्रेणी के आधार पर पंक्तियों की आवश्यकता है 285 से 290 तक। फिर से, 2 टेबल के क्लस्टर और गैर-क्लस्टर इंडेक्स बरकरार हैं। अब, आइए चित्र 5 में तार्किक रूप से पढ़ें। अपेक्षित विजेता है Person_pkClustered क्योंकि प्राथमिक कुंजी भी संकुल अनुक्रमणिका कुंजी है।

क्या आपको Person_pkClustered . पर कम तार्किक पठन दिखाई देता है ? इस परिदृश्य में क्लस्टर्ड इंडेक्स ने रेंज क्वेरी पर अपना मूल्य साबित किया। आइए देखें कि चित्र 6 में निष्पादन योजना और क्या प्रकट करेगी।
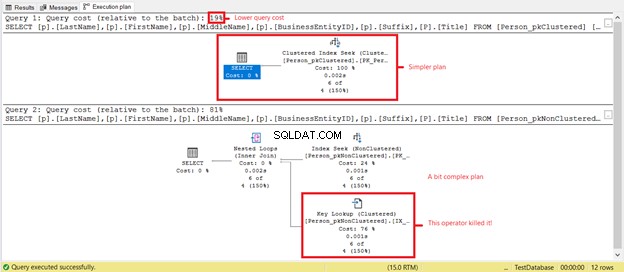
पहले SELECT में चित्र 7 के आधार पर एक सरल योजना और कम क्वेरी लागत है। यह कम तार्किक पठन का भी समर्थन करता है। इस बीच, दूसरे चयन में एक कुंजी लुकअप ऑपरेटर होता है जो क्वेरी को धीमा कर देता है। अपराधी? फिर से, यह शीर्षक . है कॉलम। क्वेरी में कॉलम निकालें या इसे गैर-क्लस्टर इंडेक्स में शामिल कॉलम के रूप में जोड़ें। फिर, आपके पास एक बेहतर योजना होगी और तार्किक पठन कम होगा।
एक जॉइन के साथ सटीक मिलान करें
कई सेलेक्ट स्टेटमेंट में जॉइन शामिल हैं। आइए कुछ परीक्षण करें। यहां हम सटीक मिलान से शुरू करते हैं:
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SET STATISTICS IO OFF
GO
हम उम्मीद करते हैं कि दूसरा चयन Person_pkNonClustered . से होगा नाम पर एक संकुल सूचकांक के साथ कम तार्किक पठन होगा। लेकिन है ना? चित्र 7 देखें।
ऐसा लगता है कि नाम पर गैर-संकुल सूचकांक ठीक था। तार्किक पठन समान हैं। यदि आप निष्पादन योजना की जांच करते हैं, तो ऑपरेटरों में अंतर Person_pkNonClustered पर क्लस्टर्ड इंडेक्स सीक है। , और इंडेक्स सीक Person_pkClustered . पर ।
इसलिए, हमें सुनिश्चित करने के लिए तार्किक पढ़ने और निष्पादन योजना की जांच करने की आवश्यकता है।
श्रेणी क्वेरी के साथ शामिल हों
चूँकि हमारी अपेक्षाएँ वास्तविकता से भिन्न हो सकती हैं, आइए इसे श्रेणी प्रश्नों के साथ आज़माएँ। क्लस्टर्ड इंडेक्स आमतौर पर इसके साथ अच्छे होते हैं। लेकिन क्या होगा यदि आप शामिल हों?
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SET STATISTICS IO OFF
GO
अब, चित्र 8 में इन 2 प्रश्नों के तार्किक पठन का निरीक्षण करें:
क्या हुआ है? चित्र 9 में, वास्तविकता Person_pkClustered . पर काटती है . इसमें Person_pkNonClustered की तुलना में अधिक I/O लागत देखी गई . यह हमारी अपेक्षा से भिन्न है। लेकिन इस फ़ोरम उत्तर के आधार पर, एक गैर-क्लस्टर इंडेक्स की तलाश क्लस्टर इंडेक्स की तुलना में तेज़ हो सकती है जब क्वेरी में सभी कॉलम इंडेक्स में 100% कवर होते हैं। हमारे मामले में, Person_pkNonClustered . के लिए क्वेरी गैर-संकुल अनुक्रमणिका (BusinessEntityID .) का उपयोग करके स्तंभों को कवर किया - चाबी; उपनाम , प्रथम नाम , मध्य नाम , प्रत्यय - क्लस्टर्ड इंडेक्स कुंजी के लिए सूचक)।
प्रदर्शन डालें
फिर, समान तालिकाओं पर INSERT प्रदर्शन का परीक्षण करने का प्रयास करें।
SET STATISTICS IO ON
GO
INSERT INTO Person_pkClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
INSERT INTO Person_pkNonClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
SET STATISTICS IO OFF
GO
चित्र 9 INSERT के तार्किक पठन को दर्शाता है:

दोनों ने समान I/O उत्पन्न किया। इस प्रकार, दोनों ने एक ही प्रदर्शन किया।
प्रदर्शन हटाएं
हमारे अंतिम परीक्षण में DELETE शामिल है:
SET STATISTICS IO ON
GO
DELETE FROM Person_pkClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
DELETE FROM Person_pkNonClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
SET STATISTICS IO OFF
GO
चित्र 10 तार्किक पठन दिखाता है। अंतर नोट करें।

हमारे पास Person_pkClustered . पर उच्च तार्किक पठन क्यों है? ? बात यह है कि DELETE स्टेटमेंट की स्थिति किसी नाम के सटीक मिलान पर आधारित होती है। अनुकूलक को पहले गैर-संकुल सूचकांक का सहारा लेना होगा। इसका मतलब अधिक I/O है। आइए चित्र 11 में निष्पादन योजना का उपयोग करके पुष्टि करें।
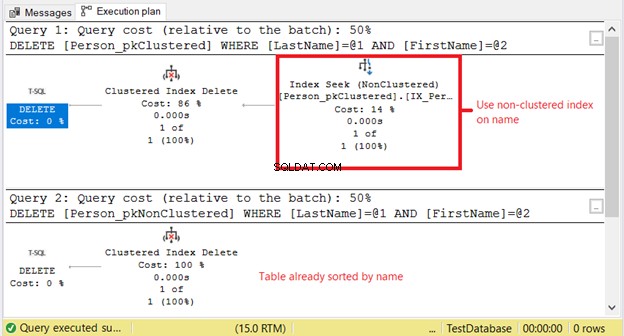
पहले चयन को गैर-संकुल अनुक्रमणिका पर अनुक्रमणिका खोज की आवश्यकता होती है। इसका कारण अंतिम नाम . पर WHERE क्लॉज है और प्रथम नाम . इस बीच, Person_pkNonClustered संकुल अनुक्रमणिका के कारण नाम से पहले से ही भौतिक रूप से क्रमबद्ध है।
टेकअवे
उच्च-प्रदर्शन वाली क्वेरी बनाना भाग्य के बारे में नहीं है। आप केवल एक संकुल और एक गैर-संकुल सूचकांक नहीं डाल सकते हैं और फिर अचानक, आपके प्रश्नों में गति बल होता है। परिणाम सेट के अलावा अन्य छोटे विवरणों पर ध्यान केंद्रित करने के लिए आपको अपने लेंस के रूप में टूल का उपयोग करते रहना होगा।
लेकिन कभी-कभी आपके पास ये सब करने का समय नहीं होता है। मुझे लगता है कि यह सामान्य है। लेकिन जब तक आप इतना गड़बड़ नहीं करते, आपके पास अगले दिन आपका काम है, और आप इसे पूरा कर सकते हैं। यह पहली बार में आसान नहीं होगा। यह वास्तव में भ्रमित करने वाला होगा। आपके भी कई सवाल होंगे। लेकिन लगातार अभ्यास से आप इसे हासिल कर सकते हैं। तो, अपनी ठुड्डी ऊपर रखें।
याद रखें, क्लस्टर्ड और नॉन-क्लस्टर इंडेक्स दोनों ही प्रश्नों को बढ़ाने के लिए हैं। प्रमुख अंतरों, उपयोग परिदृश्यों और उपकरणों को जानने से आपको उच्च-प्रदर्शन प्रश्नों को कोड करने में मदद मिलेगी।
मुझे उम्मीद है कि यह पोस्ट क्लस्टर्ड और नॉन-क्लस्टर इंडेक्स के बारे में आपके सबसे महत्वपूर्ण सवालों का जवाब देगी। क्या आपके पास हमारे पाठकों के लिए जोड़ने के लिए कुछ और है? टिप्पणियाँ अनुभाग खुला है।
और अगर आपको यह पोस्ट ज्ञानवर्धक लगे, तो कृपया इसे अपने पसंदीदा सोशल मीडिया प्लेटफॉर्म पर शेयर करें।
अनुक्रमित और क्वेरी प्रदर्शन के बारे में अधिक जानकारी नीचे दिए गए लेखों में है:
- 22 निफ्टी एसक्यूएल इंडेक्स उदाहरण आपकी क्वेरी को गति देने के लिए
- एसक्यूएल क्वेरी ऑप्टिमाइज़ेशन:आपकी क्वेरी को बढ़ावा देने के लिए 5 मुख्य तथ्य