डेटाटाइम मान से समय अलग करने की सबसे आम आवश्यकता उन सभी पंक्तियों को प्राप्त करना है जो किसी दिए गए दिन हुए ऑर्डर (या विज़िट, या दुर्घटनाएं) का प्रतिनिधित्व करती हैं। हालांकि, ऐसा करने के लिए उपयोग की जाने वाली सभी तकनीकें कुशल या सुरक्षित भी नहीं हैं।
TL;DR संस्करण
यदि आप एक सुरक्षित श्रेणी क्वेरी चाहते हैं जो अच्छा प्रदर्शन करे, तो ओपन-एंडेड श्रेणी का उपयोग करें या SQL Server 2008 और इसके बाद के संस्करण पर एकल-दिवसीय प्रश्नों के लिए, CONVERT(DATE) का उपयोग करें। :
DECLARE @today DATETIME; -- only on <= 2005: SET @today = DATEADD(DAY, DATEDIFF(DAY, '20000101', CURRENT_TIMESTAMP), '20000101'); -- or on 2008 and above: SET @today = CONVERT(DATE, CURRENT_TIMESTAMP); -- and then use an open-ended range in the query: ... WHERE OrderDate >= @today AND OrderDate < DATEADD(DAY, 1, @today); -- you can also do this (again, in SQL Server 2008 and above): ... WHERE CONVERT(DATE, OrderDate) = @today;
कुछ चेतावनी:
DATEDIFFसे सावधान रहें दृष्टिकोण, क्योंकि कुछ कार्डिनैलिटी अनुमान विसंगतियां हो सकती हैं (देखें यह ब्लॉग पोस्ट और स्टैक ओवरफ़्लो प्रश्न जिसने इसे अधिक जानकारी के लिए प्रेरित किया)।- जबकि आखिरी वाला अभी भी संभावित रूप से एक इंडेक्स सीक का उपयोग करेगा (हर दूसरे गैर-सरगने योग्य अभिव्यक्ति के विपरीत जो मैंने कभी देखा है), आपको तुलना करने से पहले कॉलम को तारीख में बदलने के बारे में सावधान रहना होगा। यह दृष्टिकोण भी मौलिक रूप से गलत कार्डिनैलिटी अनुमान उत्पन्न कर सकता है। अधिक जानकारी के लिए मार्टिन स्मिथ का यह उत्तर देखें।
किसी भी मामले में, यह समझने के लिए पढ़ें कि मैं केवल यही दो दृष्टिकोण क्यों सुझाता हूं।
सभी तरीके सुरक्षित नहीं हैं
एक असुरक्षित उदाहरण के रूप में, मुझे लगता है कि यह बहुत उपयोग किया जाता है:
WHERE OrderDate BETWEEN DATEDIFF(DAY, 0, GETDATE()) AND DATEADD(MILLISECOND, -3, DATEDIFF(DAY, 0, GETDATE()) + 1);
इस दृष्टिकोण के साथ कुछ समस्याएं हैं, लेकिन सबसे उल्लेखनीय आज के "अंत" की गणना है - यदि अंतर्निहित डेटा प्रकार SMALLDATETIME है , वह अंतिम सीमा समाप्त होने वाली है; अगर यह DATETIME2 है , आप सैद्धांतिक रूप से दिन के अंत में डेटा को याद कर सकते हैं। यदि आप वर्तमान डेटा प्रकार को समायोजित करने के लिए मिनट या नैनोसेकंड या कोई अन्य अंतराल चुनते हैं, तो आपकी क्वेरी में अजीब व्यवहार होना शुरू हो जाएगा, यदि डेटा प्रकार बाद में कभी भी बदल जाता है (और ईमानदार रहें, अगर कोई उस कॉलम के प्रकार को कम या ज्यादा दानेदार बनाने के लिए बदलता है, वे इसे एक्सेस करने वाली हर एक क्वेरी की जाँच करने के लिए नहीं चल रहे हैं)। अंतर्निहित कॉलम में दिनांक/समय डेटा के प्रकार के आधार पर इस तरह से कोड करना खंडित और त्रुटि-प्रवण है। इसके लिए ओपन-एंडेड दिनांक सीमाओं का उपयोग करना बेहतर है:
मैं इसके बारे में कुछ पुराने ब्लॉग पोस्टों में और बात करता हूँ:
- बीच और शैतान में क्या समानता है?
- बुरी आदतें शुरू करने के लिए :गलत तरीके से संभालने की तारीख / श्रेणी के प्रश्न
लेकिन मैं वहां देखे जाने वाले कुछ और सामान्य दृष्टिकोणों के प्रदर्शन की तुलना करना चाहता था। मैंने हमेशा ओपन-एंडेड रेंज का उपयोग किया है, और SQL सर्वर 2008 के बाद से हम CONVERT(DATE) का उपयोग करने में सक्षम हैं। और फिर भी उस कॉलम पर एक इंडेक्स का उपयोग करें, जो काफी शक्तिशाली है।
SELECT CONVERT(CHAR(8), CURRENT_TIMESTAMP, 112); SELECT CONVERT(CHAR(10), CURRENT_TIMESTAMP, 120); SELECT CONVERT(DATE, CURRENT_TIMESTAMP); SELECT DATEADD(DAY, DATEDIFF(DAY, '19000101', CURRENT_TIMESTAMP), '19000101'); SELECT CONVERT(DATETIME, DATEDIFF(DAY, '19000101', CURRENT_TIMESTAMP)); SELECT CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, CURRENT_TIMESTAMP))); SELECT CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, CURRENT_TIMESTAMP)));
एक साधारण प्रदर्शन परीक्षण
एक बहुत ही सरल प्रारंभिक प्रदर्शन परीक्षण करने के लिए, मैंने उपरोक्त प्रत्येक कथन के लिए निम्नलिखित किया, एक चर को गणना के आउटपुट के लिए 100,000 बार सेट किया:
SELECT SYSDATETIME(); GO DECLARE @d DATETIME = [conversion method]; GO 100000 SELECT SYSDATETIME(); GO
मैंने इसे प्रत्येक विधि के लिए तीन बार किया, और वे सभी 34-38 सेकंड की सीमा में चले। तो कड़ाई से बोलते हुए, स्मृति में संचालन करते समय इन विधियों में बहुत ही नगण्य अंतर होते हैं:
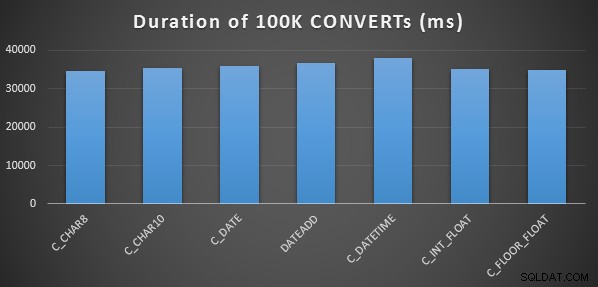
अधिक विस्तृत प्रदर्शन परीक्षण
मैं इन विधियों की तुलना विभिन्न डेटा प्रकारों से भी करना चाहता था (DATETIME , SMALLDATETIME , और DATETIME2 ), एक संकुल सूचकांक और एक ढेर दोनों के खिलाफ, और डेटा संपीड़न के साथ और बिना। तो सबसे पहले मैंने एक साधारण डेटाबेस बनाया। प्रयोग के माध्यम से मैंने निर्धारित किया कि 120 मिलियन पंक्तियों और सभी लॉग गतिविधि को संभालने के लिए इष्टतम आकार (और परीक्षण में हस्तक्षेप करने से ऑटो-ग्रो इवेंट को रोकने के लिए) एक 20GB डेटा फ़ाइल और एक 3GB लॉग था:
CREATE DATABASE [Datetime_Testing] ON PRIMARY ( NAME = N'Datetime_Testing_Data', FILENAME = N'D:\DATA\Datetime_Testing.mdf', SIZE = 20480000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 102400KB ) LOG ON ( NAME = N'Datetime_Testing_Log', FILENAME = N'E:\LOGS\Datetime_Testing_log.ldf', SIZE = 3000000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 20480KB );
इसके बाद, मैंने 12 टेबल बनाए:
-- clustered index with no compression: CREATE TABLE dbo.smalldatetime_nocompression_clustered(dt SMALLDATETIME); CREATE CLUSTERED INDEX x ON dbo.smalldatetime_nocompression_clustered(dt); -- heap with no compression: CREATE TABLE dbo.smalldatetime_nocompression_heap(dt SMALLDATETIME); -- clustered index with page compression: CREATE TABLE dbo.smalldatetime_compression_clustered(dt SMALLDATETIME) WITH (DATA_COMPRESSION = PAGE); CREATE CLUSTERED INDEX x ON dbo.smalldatetime_compression_clustered(dt) WITH (DATA_COMPRESSION = PAGE); -- heap with page compression: CREATE TABLE dbo.smalldatetime_compression_heap(dt SMALLDATETIME) WITH (DATA_COMPRESSION = PAGE);
[फिर DATETIME और DATETIME2 के लिए दोबारा दोहराएं।]
इसके बाद, मैंने प्रत्येक तालिका में 10,000,000 पंक्तियां डालीं। मैंने ऐसा एक दृश्य बनाकर किया जो हर बार समान 10,000,000 तिथियां उत्पन्न करेगा:
CREATE VIEW dbo.TenMillionDates AS SELECT TOP (10000000) d = DATEADD(MINUTE, ROW_NUMBER() OVER (ORDER BY s1.[object_id]), '19700101') FROM sys.all_columns AS s1 CROSS JOIN sys.all_objects AS s2 ORDER BY s1.[object_id];
इसने मुझे तालिकाओं को इस तरह से भरने की अनुमति दी:
INSERT /* dt_comp_clus */ dbo.datetime_compression_clustered(dt) SELECT CONVERT(DATETIME, d) FROM dbo.TenMillionDates; CHECKPOINT; INSERT /* dt2_comp_clus */ dbo.datetime2_compression_clustered(dt) SELECT CONVERT(DATETIME2, d) FROM dbo.TenMillionDates; CHECKPOINT; INSERT /* sdt_comp_clus */ dbo.smalldatetime_compression_clustered(dt) SELECT CONVERT(SMALLDATETIME, d) FROM dbo.TenMillionDates; CHECKPOINT;
[फिर ढेर और गैर-संपीड़ित क्लस्टर इंडेक्स के लिए फिर से दोहराएं। मैंने एक CHECKPOINT put लगाया है लॉग पुन:उपयोग सुनिश्चित करने के लिए प्रत्येक डालने के बीच (पुनर्प्राप्ति मॉडल सरल है)।]
प्रयुक्त समय और स्थान सम्मिलित करें
यहां प्रत्येक इंसर्ट का समय दिया गया है (जैसा कि प्लान एक्सप्लोरर के साथ कैप्चर किया गया है):
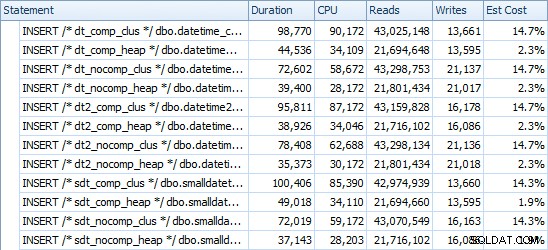
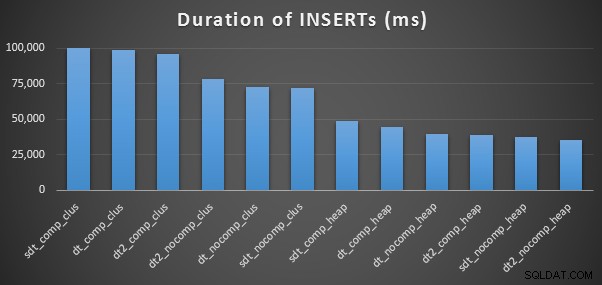
और यहाँ प्रत्येक तालिका द्वारा कब्जा की गई जगह की मात्रा है:
SELECT [table] = OBJECT_NAME([object_id]), row_count, page_count = reserved_page_count, reserved_size_MB = reserved_page_count * 8/1024 FROM sys.dm_db_partition_stats WHERE OBJECT_NAME([object_id]) LIKE '%datetime%';
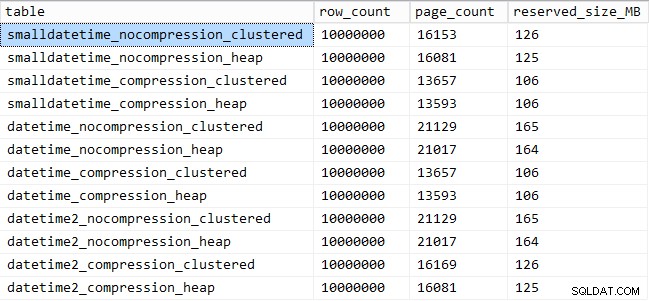
क्वेरी पैटर्न प्रदर्शन
आगे मैंने प्रदर्शन के लिए दो अलग-अलग क्वेरी पैटर्न का परीक्षण करने के लिए निर्धारित किया:
- उपरोक्त सात दृष्टिकोणों के साथ-साथ ओपन-एंडेड दिनांक सीमा का उपयोग करके किसी विशिष्ट दिन के लिए पंक्तियों की गणना करना
- उपरोक्त सात दृष्टिकोणों का उपयोग करके सभी 10,000,000 पंक्तियों को परिवर्तित करना, साथ ही साथ केवल कच्चा डेटा लौटाना (चूंकि क्लाइंट पक्ष पर स्वरूपण बेहतर हो सकता है)
[FLOAT के अपवाद के साथ तरीके और DATETIME2 कॉलम, चूंकि यह रूपांतरण कानूनी नहीं है।]
पहले प्रश्न के लिए, प्रश्न इस तरह दिखते हैं (प्रत्येक तालिका प्रकार के लिए दोहराया जाता है):
SELECT /* C_CHAR10 - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(CHAR(10), dt, 120) = '19860301';
SELECT /* C_CHAR8 - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(CHAR(8), dt, 112) = '19860301';
SELECT /* C_FLOOR_FLOAT - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, dt))) = '19860301';
SELECT /* C_DATETIME - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, DATEDIFF(DAY, '19000101', dt)) = '19860301';
SELECT /* C_DATE - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATE, dt) = '19860301';
SELECT /* C_INT_FLOAT - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, dt))) = '19860301';
SELECT /* DATEADD - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE DATEADD(DAY, DATEDIFF(DAY, '19000101', dt), '19000101') = '19860301';
SELECT /* RANGE - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE dt >= '19860301' AND dt < '19860302'; एक संकुल अनुक्रमणिका के परिणाम इस तरह दिखते हैं (विस्तार करने के लिए क्लिक करें):
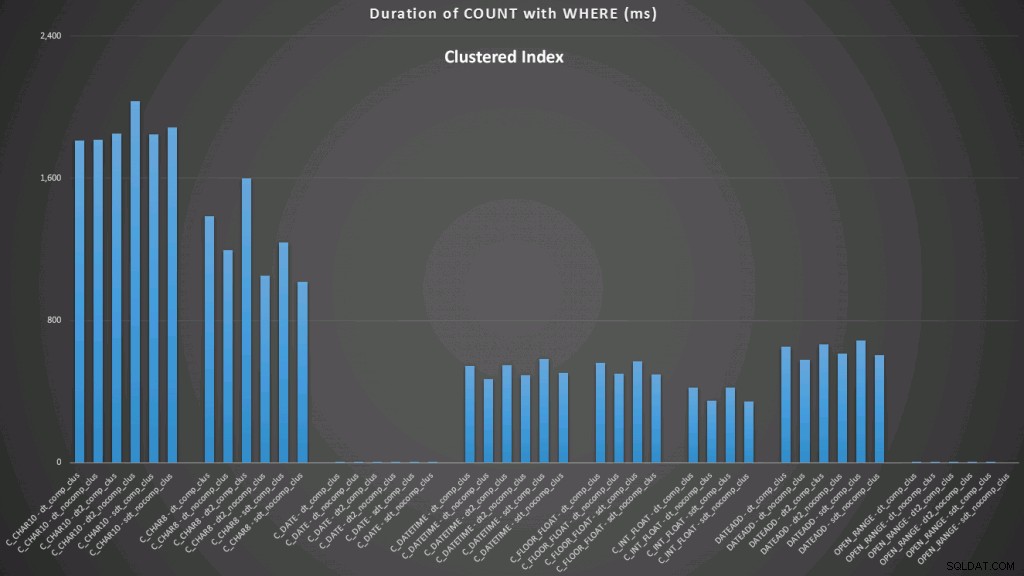
यहां हम देखते हैं कि किसी इंडेक्स का उपयोग करते हुए कन्वर्ट टू डेट और ओपन-एंडेड रेंज सबसे अच्छा प्रदर्शन करने वाले हैं। हालांकि, एक ढेर के खिलाफ, तिथि में कनवर्ट करने में वास्तव में कुछ समय लगता है, जिससे ओपन-एंडेड श्रेणी इष्टतम विकल्प बन जाती है (विस्तार करने के लिए क्लिक करें):
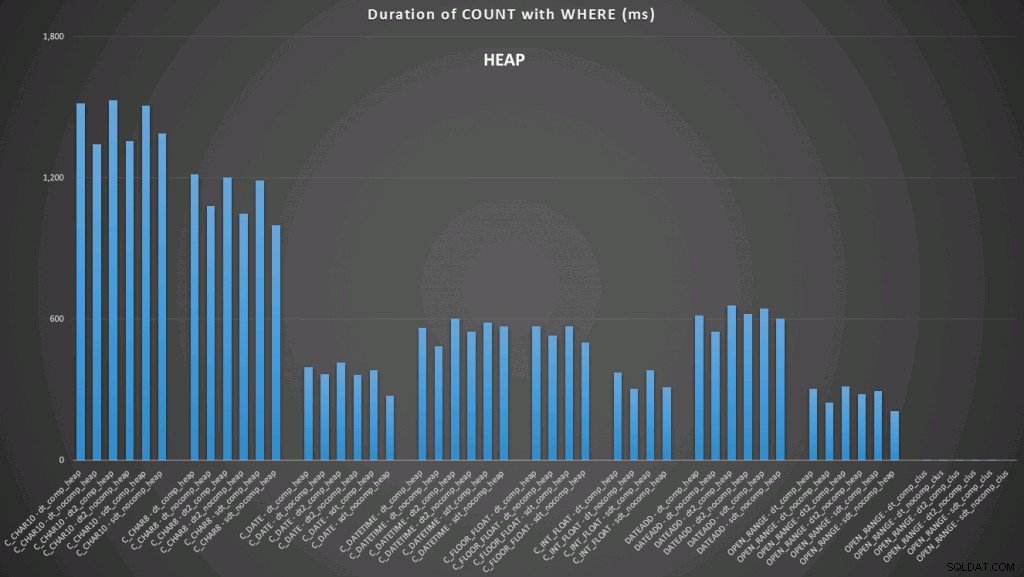
और यहां प्रश्नों का दूसरा सेट है (फिर से, प्रत्येक तालिका प्रकार के लिए दोहराते हुए):
SELECT /* C_CHAR10 - dt_comp_clus */ dt = CONVERT(CHAR(10), dt, 120)
FROM dbo.datetime_compression_clustered;
SELECT /* C_CHAR8 - dt_comp_clus */ dt = CONVERT(CHAR(8), dt, 112)
FROM dbo.datetime_compression_clustered;
SELECT /* C_FLOOR_FLOAT - dt_comp_clus */ dt = CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, dt)))
FROM dbo.datetime_compression_clustered;
SELECT /* C_DATETIME - dt_comp_clus */ dt = CONVERT(DATETIME, DATEDIFF(DAY, '19000101', dt))
FROM dbo.datetime_compression_clustered;
SELECT /* C_DATE - dt_comp_clus */ dt = CONVERT(DATE, dt)
FROM dbo.datetime_compression_clustered;
SELECT /* C_INT_FLOAT - dt_comp_clus */ dt = CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, dt)))
FROM dbo.datetime_compression_clustered;
SELECT /* DATEADD - dt_comp_clus */ dt = DATEADD(DAY, DATEDIFF(DAY, '19000101', dt), '19000101')
FROM dbo.datetime_compression_clustered;
SELECT /* RAW - dt_comp_clus */ dt
FROM dbo.datetime_compression_clustered; क्लस्टर्ड इंडेक्स वाली तालिकाओं के परिणामों पर ध्यान केंद्रित करते हुए, यह स्पष्ट है कि केवल कच्चे डेटा का चयन करने के लिए कन्वर्ट टू डेट एक बहुत ही करीबी प्रदर्शन था (विस्तार करने के लिए क्लिक करें):
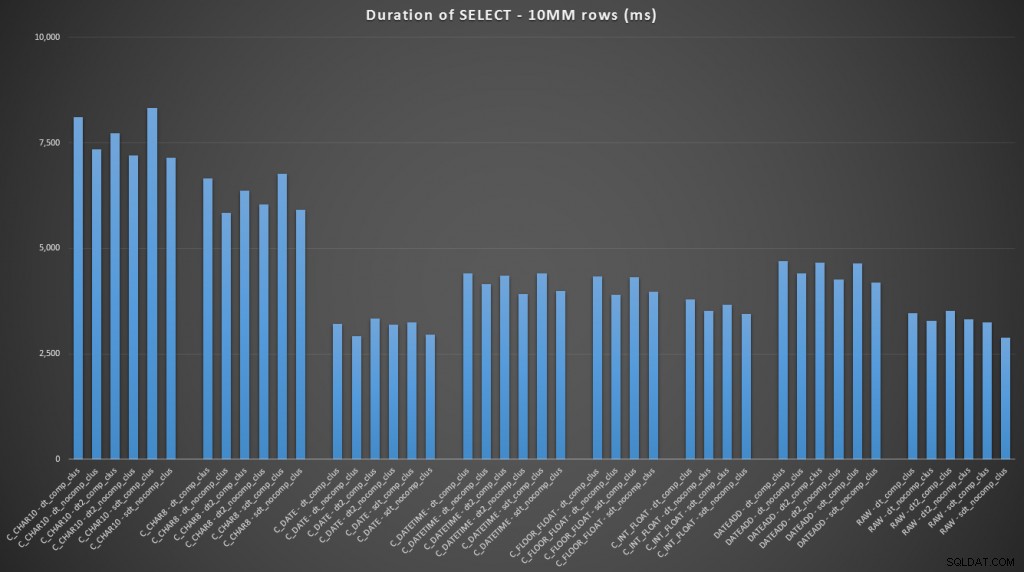
(प्रश्नों के इस सेट के लिए, ढेर ने बहुत ही समान परिणाम दिखाए - व्यावहारिक रूप से अप्रभेद्य।)
निष्कर्ष
यदि आप पंचलाइन पर जाना चाहते हैं, तो ये परिणाम दिखाते हैं कि स्मृति में रूपांतरण महत्वपूर्ण नहीं हैं, लेकिन यदि आप किसी तालिका से बाहर (या खोज विधेय के भाग के रूप में) डेटा परिवर्तित कर रहे हैं, तो आपके द्वारा चुनी गई विधि हो सकती है प्रदर्शन पर नाटकीय प्रभाव। एक DATE में परिवर्तित किया जा रहा है (एक दिन के लिए) या किसी ओपन-एंडेड दिनांक सीमा का उपयोग करने से किसी भी स्थिति में सर्वश्रेष्ठ प्रदर्शन प्राप्त होगा, जबकि सबसे लोकप्रिय तरीका - एक स्ट्रिंग में कनवर्ट करना - बिल्कुल कम है।
हम यह भी देखते हैं कि कंप्रेशन का स्टोरेज स्पेस पर अच्छा प्रभाव पड़ सकता है, क्वेरी प्रदर्शन पर बहुत मामूली प्रभाव पड़ता है। सम्मिलित प्रदर्शन पर प्रभाव इस बात पर निर्भर करता है कि संपीड़न सक्षम है या नहीं, इसके बजाय तालिका में क्लस्टर इंडेक्स है या नहीं। हालांकि, क्लस्टर इंडेक्स के साथ, 10 मिलियन पंक्तियों को सम्मिलित करने में लगने वाली अवधि में एक उल्लेखनीय उछाल था। कुछ ध्यान में रखने और डिस्क स्थान बचत के साथ संतुलन बनाने के लिए।
स्पष्ट रूप से इसमें और अधिक परीक्षण शामिल हो सकते हैं, अधिक पर्याप्त और विविध कार्यभार के साथ, जिसे मैं भविष्य की पोस्ट में और अधिक खोज सकता हूं।