इस लेख में, हम देखेंगे कि कैसे एक इंडेक्स क्वेरी के प्रदर्शन को बेहतर बना सकता है।
परिचय
Oracle और अन्य डेटाबेस में अनुक्रमणिका ऐसी वस्तुएँ हैं जो डेटा के संदर्भों को अन्य तालिकाओं में संग्रहीत करती हैं। उनका उपयोग क्वेरी के प्रदर्शन को बेहतर बनाने के लिए किया जाता है, अक्सर SELECT स्टेटमेंट में।
वे "सिल्वर बुलेट" नहीं हैं - वे हमेशा SELECT स्टेटमेंट के साथ प्रदर्शन समस्याओं को हल नहीं करते हैं। हालांकि, वे निश्चित रूप से मदद कर सकते हैं।
आइए इस पर एक विशेष उदाहरण पर विचार करें।
उदाहरण
इस उदाहरण के लिए, हम ग्राहक नामक एक एकल तालिका का उपयोग करने जा रहे हैं जिसमें आईडी, प्रथम नाम, अंतिम नाम, अधिकतम क्रेडिट मान, निर्मित दिनांक मान और अन्य कॉलम जैसे कॉलम शामिल हैं जिनका हम उपयोग नहीं करेंगे।
SELECT customer_id,first_name,last_name, max_credit, created_date FROM customer;
यहाँ तालिका का एक नमूना है।
[टेबल आईडी=38 /]
अब, हम निम्नलिखित खोजने जा रहे हैं:
- पहले ग्राहकों के साथ एक ही तिथि पर तालिका में किन ग्राहकों को जोड़ा गया था
- ग्राहकों को last_name द्वारा आरोही क्रम में फ़िल्टर किया गया
- ग्राहक आईडी, प्रथम नाम, अंतिम नाम, अधिकतम क्रेडिट और निर्मित तिथि प्रदर्शित करें
ऐसा करने के लिए, निम्न क्वेरी बनाएं:
SELECT customer_id,
first_name,
last_name,
max_credit,
created_date
FROM customer
WHERE created_date = (
SELECT MIN(created_date)
FROM customer
)
ORDER BY last_name; आउटपुट इस तरह दिखता है:
[टेबल आईडी=39 /]
यह वह डेटा दिखाता है जो हम चाहते हैं।
अनुक्रमणिका लागू होने से पहले का प्रदर्शन
अब, आइए इस प्रश्न के लिए व्याख्या योजना देखें। मैंने इसे SELECT स्टेटमेंट और निम्न कमांड के लिए EXPLAIN PLAN FOR चलाकर प्राप्त किया:
SELECT * FROM TABLE(dbms_xplan.display);
आप अपने आईडीई के अंदर भी व्याख्या योजना सुविधा का उपयोग करके एक समान आउटपुट परिणाम प्राप्त कर सकते हैं।
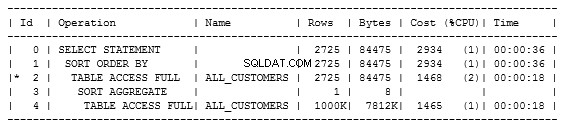
हम देख सकते हैं कि यह दो बिंदुओं पर एक टेबल एक्सेस फुल करता है, अर्थात् सबक्वायरी में और बाहरी क्वेरी में। ऐसा इसलिए है क्योंकि उपयोग के लिए टेबल पर कोई अनुक्रमणिका नहीं है।
इसकी लागत 2934 है। जब मैंने इसे चलाया, तो क्वेरी 1.9 सेकंड में 785 पंक्तियाँ प्राप्त की। यह जल्दी लग सकता है लेकिन यह सिर्फ एक उदाहरण है जिसमें हम सुधार कर सकते हैं। वास्तविक सिस्टम में क्वेरी में अधिक समय लग सकता है।
इस क्वेरी के प्रदर्शन को बेहतर बनाने का एक तरीका यह है कि हम create_date कॉलम में एक इंडेक्स जोड़ दें। इस कॉलम का उपयोग बाहरी क्वेरी के WHERE क्लॉज़ और आंतरिक क्वेरी के MIN फ़ंक्शन दोनों में किया जाता है।
सूचकांक जोड़ें
क्वेरी प्रदर्शन को बेहतर बनाने के लिए हम इस तालिका में एक इंडेक्स जोड़ सकते हैं। इस इंडेक्स को create_date कॉलम में स्टोर किया जाएगा ताकि कोड इस तरह दिख सके:
CREATE INDEX idx_cust_cdate ON customer (created_date);
अब, इस कॉलम पर ही इंडेक्स बनाया जाता है। इससे हमें अपनी क्वेरी में प्रदर्शन में सुधार करना चाहिए, लेकिन हमें पहले इसकी जांच करनी होगी।
हमने एक बी-ट्री इंडेक्स बनाया है, जो शायद इस कॉलम पर हमें चाहिए। हम शीघ्र ही व्याख्या योजना में इसकी पुष्टि करेंगे। मैंने Oracle अनुक्रमणिका पर एक मार्गदर्शिका लिखी है जिसमें यह जानना शामिल है कि किस प्रकार के अनुक्रमणिका का उपयोग किया जाना है, साथ ही साथ बहुत सी अन्य मूल्यवान जानकारी।
सूचकांक के बाद प्रदर्शन जोड़ा गया
आइए इस प्रश्न पर व्याख्या योजना को फिर से चलाएं।
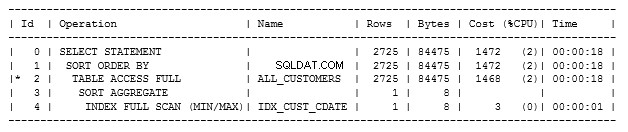
हम देख सकते हैं कि अंतिम चरण में एक इंडेक्स का उपयोग किया गया है। यह दर्शाता है कि idx_cust_cdate अनुक्रमणिका के साथ एक पूर्ण स्कैन निष्पादित किया गया है, जिसे हमने अभी बनाया है।
यह 1472 की कुल लागत भी दिखाता है और 0.9 सेकंड में 785 रिकॉर्ड प्राप्त करता है।
रनटाइम में केवल थोड़ा सुधार हुआ है (1.9 से 0.9 सेकंड तक), लेकिन इस छोटे डेटासेट में केवल इंडेक्स जोड़ने से यह लगभग 50% सुधार है।
जैसा कि पहले उल्लेख किया गया है, वास्तविक प्रश्न इससे अधिक जटिल होंगे और इसे निष्पादित करने में अधिक समय लगेगा। लेकिन, यह एक उदाहरण है कि कैसे एक इंडेक्स क्वेरी प्लान और क्वेरी रनटाइम को बेहतर बना सकता है।



