आपने MySQL प्रतिकृति के संदर्भ में "विफलता" शब्द के बारे में सुना होगा। हो सकता है कि आपने सोचा हो कि यह क्या है जब आप डेटाबेस के साथ अपने साहसिक कार्य की शुरुआत कर रहे हैं। हो सकता है कि आप जानते हों कि यह क्या है, लेकिन आप इससे संबंधित संभावित समस्याओं के बारे में सुनिश्चित नहीं हैं और उन्हें कैसे हल किया जा सकता है?
इस ब्लॉग पोस्ट में हम आपको MySQL और MariaDB में फ़ेलओवर हैंडलिंग का परिचय देने का प्रयास करेंगे।
हम चर्चा करेंगे कि फेलओवर क्या है, यह अपरिहार्य क्यों है, फेलओवर और स्विचओवर में क्या अंतर है। हम सबसे सामान्य रूप में विफलता प्रक्रिया पर चर्चा करेंगे। हम अलग-अलग मुद्दों पर भी थोड़ा स्पर्श करेंगे, जिनसे आपको फ़ेलओवर प्रक्रिया के संबंध में निपटना होगा।
“विफलता” का क्या अर्थ है?
MySQL प्रतिकृति नोड्स का एक सामूहिक है, उनमें से प्रत्येक एक समय में एक भूमिका निभा सकता है। यह मास्टर या प्रतिकृति बन सकता है। एक निश्चित समय में केवल एक मास्टर नोड होता है। इस नोड को लिखने का ट्रैफ़िक प्राप्त होता है और यह अपनी प्रतिकृतियों को लिखने की नकल करता है।
जैसा कि आप कल्पना कर सकते हैं, प्रतिकृति क्लस्टर में डेटा के लिए प्रवेश का एकल बिंदु होने के नाते, मास्टर नोड काफी महत्वपूर्ण है। क्या होता अगर यह विफल हो जाता और अनुपलब्ध हो जाता?
प्रतिकृति क्लस्टर के लिए यह काफी गंभीर स्थिति है। यह किसी भी समय किसी भी लेखन को स्वीकार नहीं कर सकता है। जैसा कि आप उम्मीद कर सकते हैं, प्रतिकृतियों में से एक को मास्टर के कार्यों को लेना होगा और लेखन स्वीकार करना शुरू करना होगा। बाकी प्रतिकृति टोपोलॉजी को भी बदलना पड़ सकता है - शेष प्रतिकृतियों को अपने मास्टर को पुराने, विफल नोड से नए चुने गए नोड में बदलना चाहिए। पुराने मास्टर के विफल होने के बाद एक प्रतिकृति को मास्टर बनने के लिए "प्रचारित" करने की इस प्रक्रिया को "विफलता" कहा जाता है।
दूसरी ओर, "स्विचओवर" तब होता है जब उपयोगकर्ता प्रतिकृति के प्रचार को ट्रिगर करता है। उपयोगकर्ता द्वारा बताई गई प्रतिकृति से एक नए मास्टर का प्रचार किया जाता है और पुराना मास्टर, आमतौर पर, नए मास्टर की प्रतिकृति बन जाता है।
"विफलता" और "स्विचओवर" के बीच सबसे महत्वपूर्ण अंतर पुराने गुरु की स्थिति है। जब एक फेलओवर किया जाता है तो पुराना मास्टर किसी तरह से पहुंच योग्य नहीं होता है। हो सकता है कि यह क्रैश हो गया हो, हो सकता है कि इसे नेटवर्क विभाजन का सामना करना पड़ा हो। इसका उपयोग किसी निश्चित क्षण में नहीं किया जा सकता है और इसकी स्थिति, आमतौर पर, अज्ञात होती है।
दूसरी ओर, जब एक स्विचओवर किया जाता है, तो बूढ़ा मालिक जीवित और स्वस्थ होता है। इसके गंभीर परिणाम होते हैं। यदि मास्टर पहुंच योग्य नहीं है, तो इसका मतलब यह हो सकता है कि कुछ डेटा अभी तक दासों को नहीं भेजा गया है (जब तक कि अर्ध-तुल्यकालिक प्रतिकृति का उपयोग नहीं किया गया था)। हो सकता है कि कुछ डेटा दूषित हो गया हो या आंशिक रूप से भेजा गया हो।
दासों पर इस तरह के भ्रष्टाचारों को फैलाने से बचने के लिए तंत्र मौजूद हैं लेकिन मुद्दा यह है कि प्रक्रिया में कुछ डेटा खो सकता है। दूसरी ओर, स्विचओवर करते समय, पुराना मास्टर उपलब्ध होता है और डेटा स्थिरता बनी रहती है।
विफलता प्रक्रिया
आइए कुछ समय इस बात पर चर्चा करने में बिताएं कि वास्तव में विफलता प्रक्रिया कैसी दिखती है।
मास्टर क्रैश का पता चला है
शुरुआत के लिए, विफलता के प्रदर्शन से पहले एक मास्टर को क्रैश करना होगा। एक बार जब यह उपलब्ध नहीं होता है, तो एक विफलता शुरू हो जाती है। अब तक, यह आसान लगता है लेकिन सच्चाई यह है कि हम पहले से ही फिसलन वाली जमीन पर हैं।
सबसे पहले, मास्टर स्वास्थ्य का परीक्षण कैसे किया जाता है? क्या इसका एक स्थान से परीक्षण किया जाता है या परीक्षण वितरित किए जाते हैं? क्या फ़ेलओवर प्रबंधन सॉफ़्टवेयर केवल मास्टर से कनेक्ट करने का प्रयास करता है या क्या यह मास्टर विफलता घोषित होने से पहले अधिक उन्नत सत्यापन लागू करता है?
आइए निम्नलिखित टोपोलॉजी की कल्पना करें:
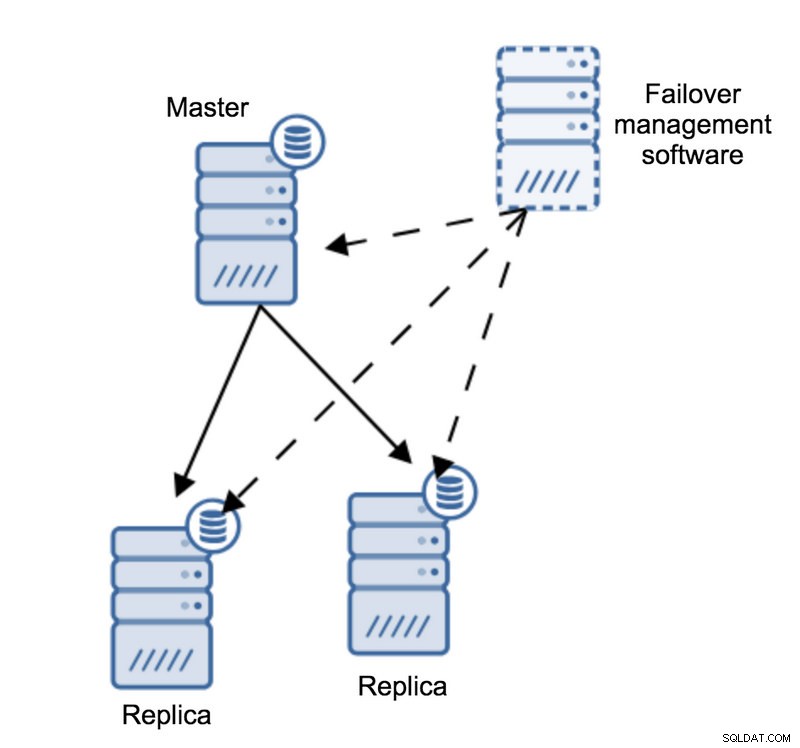
हमारे पास एक मास्टर और दो प्रतिकृतियां हैं। हमारे पास कुछ बाहरी होस्ट पर स्थित एक फ़ेलओवर प्रबंधन सॉफ़्टवेयर भी है। यदि फ़ेलओवर सॉफ़्टवेयर वाले होस्ट और मास्टर के बीच नेटवर्क कनेक्शन विफल हो जाए तो क्या होगा?
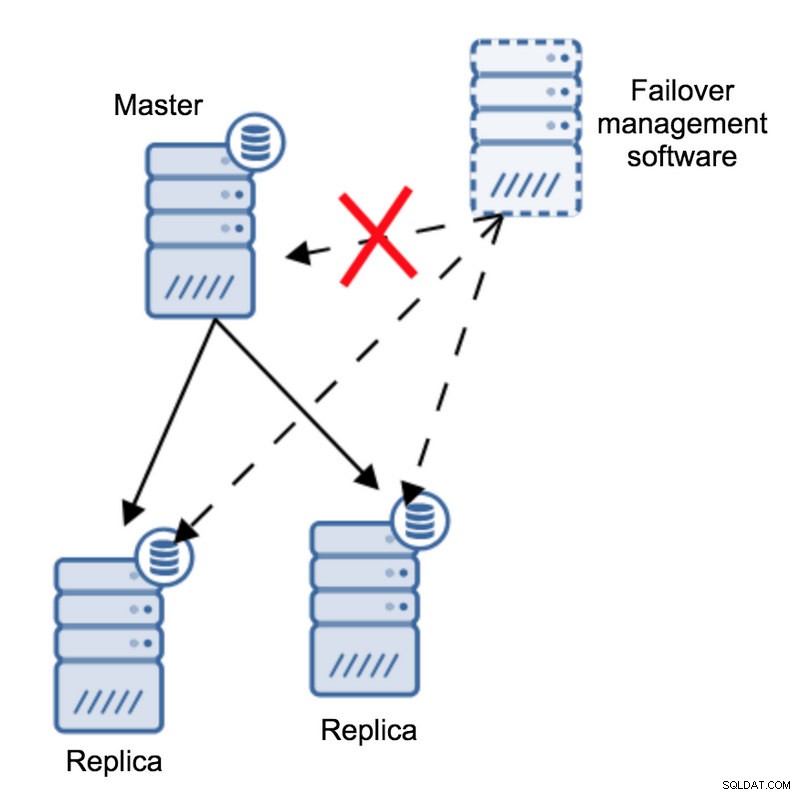
फ़ेलओवर प्रबंधन सॉफ़्टवेयर के अनुसार, मास्टर क्रैश हो गया है - इसमें कोई कनेक्टिविटी नहीं है। फिर भी, प्रतिकृति ही ठीक काम कर रही है। यहाँ क्या होना चाहिए कि फ़ेलओवर प्रबंधन सॉफ़्टवेयर प्रतिकृतियों से जुड़ने का प्रयास करेगा और देखेगा कि उनका दृष्टिकोण क्या है।
क्या वे एक टूटी हुई प्रतिकृति के बारे में शिकायत करते हैं या वे खुशी से नकल कर रहे हैं?
चीजें और भी जटिल हो सकती हैं। क्या होगा यदि हम एक प्रॉक्सी (या प्रॉक्सी का एक सेट) जोड़ दें? इसका उपयोग यातायात को रूट करने के लिए किया जाएगा - मास्टर को लिखता है और प्रतिकृतियों को पढ़ता है। क्या होगा यदि कोई प्रॉक्सी मास्टर तक नहीं पहुंच सकता है? क्या होगा यदि कोई भी प्रॉक्सी मास्टर तक नहीं पहुंच सकता है?
इसका मतलब है कि एप्लिकेशन उन शर्तों के तहत कार्य नहीं कर सकता है। क्या फ़ेलओवर (वास्तव में, यह एक स्विचओवर के रूप में अधिक होगा क्योंकि मास्टर तकनीकी रूप से जीवित है) को ट्रिगर किया जाना चाहिए?
तकनीकी रूप से, मास्टर जीवित है लेकिन इसका उपयोग एप्लिकेशन द्वारा नहीं किया जा सकता है। यहां, व्यावसायिक तर्क आना है और निर्णय लेना है।
पुराने मास्टर को दौड़ने से रोकना
कोई फर्क नहीं पड़ता कि कैसे और क्यों, यदि प्रतिकृतियों में से एक को नया मास्टर बनने के लिए बढ़ावा देने का निर्णय है, तो पुराने मास्टर को रोकना होगा और, आदर्श रूप से, इसे फिर से शुरू करने में सक्षम नहीं होना चाहिए।
यह कैसे प्राप्त किया जा सकता है यह विशेष पर्यावरण के विवरण पर निर्भर करता है; इसलिए फ़ेलओवर प्रक्रिया के इस भाग को आमतौर पर विभिन्न हुक के माध्यम से फ़ेलओवर प्रक्रिया में एकीकृत बाहरी स्क्रिप्ट द्वारा प्रबलित किया जाता है।
उन लिपियों को पुराने मास्टर को रोकने के लिए विशेष वातावरण में उपलब्ध उपकरणों का उपयोग करने के लिए डिज़ाइन किया जा सकता है। यह एक सीएलआई या एपीआई कॉल हो सकता है जो एक वीएम को रोक देगा; यह शेल कोड हो सकता है जो किसी प्रकार के "लाइट आउट मैनेजमेंट" डिवाइस के माध्यम से कमांड चलाता है; यह एक स्क्रिप्ट हो सकती है जो पावर डिस्ट्रीब्यूशन यूनिट को एसएनएमपी ट्रैप भेजती है जो पुराने मास्टर द्वारा उपयोग किए जा रहे पावर आउटलेट को अक्षम कर देता है (विद्युत शक्ति के बिना हम सुनिश्चित हो सकते हैं कि यह फिर से शुरू नहीं होगा)।
यदि एक फ़ेलओवर प्रबंधन सॉफ़्टवेयर अधिक जटिल उत्पाद का एक भाग है, जो नोड्स की पुनर्प्राप्ति को भी संभालता है (जैसे यह ClusterControl के मामले में है), तो पुराने मास्टर को पुनर्प्राप्ति रूटीन से बाहर रखा गया के रूप में चिह्नित किया जा सकता है।
आपको आश्चर्य हो सकता है कि पुराने मास्टर को एक बार फिर उपलब्ध होने से रोकना इतना महत्वपूर्ण क्यों है?
मुख्य मुद्दा यह है कि प्रतिकृति सेटअप में, लिखने के लिए केवल एक नोड का उपयोग किया जा सकता है। आम तौर पर आप यह सुनिश्चित करते हैं कि सभी प्रतिकृतियों पर केवल read_only (और super_read_only, यदि लागू हो) चर को सक्षम करके और इसे केवल मास्टर पर अक्षम रखा जाए।
एक बार जब एक नए मास्टर का प्रचार हो जाता है, तो वह केवल पढ़ने के लिए अक्षम हो जाएगा। समस्या यह है कि, यदि पुराना मास्टर अनुपलब्ध है, तो हम उसे वापस read_only=1 पर स्विच नहीं कर सकते। यदि MySQL या कोई होस्ट क्रैश हो जाता है, तो यह कोई बड़ी समस्या नहीं है क्योंकि my.cnf को उस सेटिंग के साथ कॉन्फ़िगर करने के लिए अच्छा अभ्यास है, इसलिए MySQL के प्रारंभ होने के बाद, यह हमेशा केवल पढ़ने के लिए मोड में प्रारंभ होता है।
समस्या तब दिखाई देती है जब यह क्रैश नहीं बल्कि नेटवर्क समस्या होती है। पुराना मास्टर अभी भी read_only अक्षम के साथ चल रहा है, यह अभी उपलब्ध नहीं है। जब नेटवर्क अभिसरण करते हैं, तो आप दो लिखने योग्य नोड्स के साथ समाप्त हो जाएंगे। यह समस्या हो भी सकती है और नहीं भी। कुछ परदे के पीछे एक संकेतक के रूप में read_only सेटिंग का उपयोग करते हैं कि क्या नोड एक मास्टर या प्रतिकृति है। दिए गए समय में दो मास्टर्स दिखाई देने के परिणामस्वरूप एक बड़ी समस्या हो सकती है क्योंकि डेटा दोनों मेजबानों को लिखा जाता है, लेकिन प्रतिकृतियों को केवल आधे ट्रैफ़िक (नए मास्टर को हिट करने वाला हिस्सा) मिलता है।
कभी-कभी यह कुछ लिपियों में हार्डकोडेड सेटिंग्स के बारे में होता है जो केवल किसी दिए गए होस्ट से कनेक्ट करने के लिए कॉन्फ़िगर की जाती हैं। आम तौर पर वे असफल हो जाते हैं और किसी को पता चल जाता है कि मास्टर बदल गया है।
पुराने मास्टर के उपलब्ध होने से, वे खुशी-खुशी इससे जुड़ जाएंगे और डेटा विसंगति पैदा होगी। जैसा कि आप देख सकते हैं, यह सुनिश्चित करना कि पुराना मास्टर शुरू नहीं होगा, काफी उच्च प्राथमिकता वाली वस्तु है।
एक मास्टर उम्मीदवार का फैसला करें
पुराना गुरु नीचे है और वह अपनी कब्र से नहीं लौटेगा, अब यह तय करने का समय है कि हमें नए गुरु के रूप में किस मेजबान का उपयोग करना चाहिए। आमतौर पर चुनने के लिए एक से अधिक प्रतिकृति होती है, इसलिए निर्णय लेना पड़ता है। एक प्रतिकृति को दूसरे पर लेने के कई कारण हो सकते हैं, इसलिए जांच की जानी चाहिए।
श्वेत सूचियां और काली सूचियां
शुरुआत के लिए, डेटाबेस का प्रबंधन करने वाली टीम के पास एक मास्टर उम्मीदवार के बारे में निर्णय लेते समय एक प्रतिकृति को दूसरे पर लेने के अपने कारण हो सकते हैं। हो सकता है कि यह कमजोर हार्डवेयर का उपयोग कर रहा हो या इसे कोई विशेष कार्य सौंपा गया हो (जो प्रतिकृति बैकअप, विश्लेषणात्मक प्रश्नों को चलाती है, डेवलपर्स के पास इसकी पहुंच होती है और कस्टम, हाथ से बने प्रश्न चलाते हैं)। शायद यह एक परीक्षण प्रतिकृति है जहां अपग्रेड के साथ आगे बढ़ने से पहले एक नया संस्करण स्वीकृति परीक्षण से गुजर रहा है। अधिकांश फ़ेलओवर प्रबंधन सॉफ़्टवेयर श्वेत और काली सूची का समर्थन करता है, जिसका उपयोग सटीक रूप से परिभाषित करने के लिए किया जा सकता है कि कौन सी प्रतिकृतियां मास्टर उम्मीदवारों के रूप में उपयोग की जानी चाहिए या नहीं।
अर्ध-तुल्यकालिक प्रतिकृति
एक प्रतिकृति सेटअप अतुल्यकालिक और अर्ध-तुल्यकालिक प्रतिकृतियों का मिश्रण हो सकता है। उनके बीच बहुत बड़ा अंतर है - अर्ध-तुल्यकालिक प्रतिकृति में मास्टर की सभी घटनाओं को शामिल करने की गारंटी है। एक अतुल्यकालिक प्रतिकृति को सभी डेटा प्राप्त नहीं हो सकते हैं, इस प्रकार इसे विफल करने से डेटा हानि हो सकती है। हम इसके बजाय सेमी-सिंक्रोनस प्रतिकृतियों को बढ़ावा देना चाहेंगे।
प्रतिकृति अंतराल
भले ही एक सेमी-सिंक्रोनस प्रतिकृति में सभी ईवेंट होंगे, फिर भी वे ईवेंट केवल रिले लॉग में रह सकते हैं। भारी ट्रैफ़िक के साथ, सभी प्रतिकृतियां, भले ही सेमी-सिंक या एसिंक्स हों, पिछड़ सकती हैं।
प्रतिकृति अंतराल के साथ समस्या यह है कि, जब आप किसी प्रतिकृति का प्रचार करते हैं, तो आपको प्रतिकृति सेटिंग्स को रीसेट करना चाहिए ताकि वह पुराने मास्टर से कनेक्ट करने का प्रयास न करे। यह सभी रिले लॉग को भी हटा देगा, भले ही वे अभी तक लागू न हों - जिससे डेटा हानि होती है।
यहां तक कि अगर आप प्रतिकृति सेटिंग्स को रीसेट नहीं करेंगे, तब भी आप कनेक्शन के लिए एक नया मास्टर नहीं खोल सकते हैं यदि उसने अपने रिले लॉग से सभी घटनाओं को लागू नहीं किया है। अन्यथा आप जोखिम लेंगे कि नए प्रश्न रिले लॉग से लेन-देन को प्रभावित करेंगे, जिससे सभी प्रकार की समस्याएं उत्पन्न होंगी (उदाहरण के लिए, एक एप्लिकेशन कुछ पंक्तियों को हटा सकता है जो रिले लॉग से लेनदेन द्वारा एक्सेस की जाती हैं)।
इस सब को ध्यान में रखते हुए, रिले लॉग के लागू होने की प्रतीक्षा करना एकमात्र सुरक्षित विकल्प है। फिर भी, अगर प्रतिकृति भारी रूप से पिछड़ रही थी तो इसमें कुछ समय लग सकता है। निर्णय लेना होगा कि कौन सी प्रतिकृति एक बेहतर मास्टर - अतुल्यकालिक, लेकिन छोटे अंतराल या अर्ध-तुल्यकालिक के साथ, लेकिन अंतराल के साथ जिसे लागू करने के लिए महत्वपूर्ण समय की आवश्यकता होगी।
गलत लेनदेन
भले ही प्रतिकृतियां नहीं लिखी जानी चाहिए, फिर भी ऐसा हो सकता है कि किसी (या कुछ) ने इसे लिखा हो।
हो सकता है कि यह अतीत में केवल एक ही लेन-देन का तरीका रहा हो, लेकिन यह अभी भी एक विफलता प्रदर्शन करने की क्षमता पर गंभीर प्रभाव डाल सकता है। यह मुद्दा ग्लोबल ट्रांजैक्शन आईडी (GTID) से पूरी तरह से संबंधित है, यह एक ऐसी सुविधा है जो किसी दिए गए MySQL नोड पर निष्पादित प्रत्येक लेनदेन के लिए एक अलग आईडी प्रदान करती है।
आजकल यह काफी लोकप्रिय सेटअप है क्योंकि यह लचीलेपन के महान स्तर लाता है और यह बेहतर प्रदर्शन (मल्टी-थ्रेडेड प्रतिकृतियों के साथ) की अनुमति देता है।
मुद्दा यह है कि, एक नए मास्टर के लिए पुन:स्लाव करते समय, GTID प्रतिकृति के लिए उस मास्टर की सभी घटनाओं (जो प्रतिकृति पर निष्पादित नहीं की गई हैं) को प्रतिकृति में दोहराने की आवश्यकता होती है।
आइए निम्नलिखित परिदृश्य पर विचार करें:अतीत में किसी समय, एक प्रतिकृति पर एक लेखन हुआ था। यह बहुत समय पहले की बात है और इस घटना को प्रतिकृति के बाइनरी लॉग से हटा दिया गया है। किसी बिंदु पर एक मास्टर विफल हो गया है और प्रतिकृति को एक नए मास्टर के रूप में नियुक्त किया गया था। शेष सभी प्रतिकृतियों को नए मास्टर से अलग कर दिया जाएगा। वे नए मास्टर पर निष्पादित लेनदेन के बारे में पूछेंगे। यह GTID की सूची के साथ प्रतिक्रिया देगा जो पुराने मास्टर से आया था और एकल GTID उस पुराने लेखन से संबंधित था। पुराने मास्टर के GTID कोई समस्या नहीं हैं क्योंकि सभी शेष प्रतिकृतियों में कम से कम उनमें से अधिकांश (यदि सभी नहीं हैं) होते हैं और सभी अनुपलब्ध ईवेंट नए मास्टर के बाइनरी लॉग में उपलब्ध होने के लिए पर्याप्त हाल के होने चाहिए।
सबसे खराब स्थिति, कुछ लापता घटनाओं को बाइनरी लॉग से पढ़ा जाएगा और प्रतिकृतियों में स्थानांतरित कर दिया जाएगा। मुद्दा उस पुराने लेखन के साथ है - यह केवल एक नए मास्टर पर हुआ, जबकि यह अभी भी एक प्रतिकृति था, इस प्रकार यह शेष मेजबानों पर मौजूद नहीं है। यह एक पुरानी घटना है इसलिए इसे बाइनरी लॉग से पुनर्प्राप्त करने का कोई तरीका नहीं है। नतीजतन, कोई भी प्रतिकृति नए मास्टर को गुलाम नहीं बना पाएगी। यहां एकमात्र समाधान मैन्युअल कार्रवाई करना और सभी प्रतिकृतियों पर उस समस्याग्रस्त GTID के साथ एक खाली घटना को इंजेक्ट करना है। इसका मतलब यह भी होगा कि, जो हुआ उसके आधार पर, हो सकता है कि प्रतिकृतियां नए मास्टर के साथ समन्वयित न हों।
जैसा कि आप देख सकते हैं, गलत लेन-देन को ट्रैक करना और यह निर्धारित करना काफी महत्वपूर्ण है कि एक नया मास्टर बनने के लिए दी गई प्रतिकृति को बढ़ावा देना सुरक्षित है या नहीं। यदि इसमें गलत लेन-देन शामिल हैं, तो यह सबसे अच्छा विकल्प नहीं हो सकता है।
एप्लिकेशन के लिए फ़ेलओवर हैंडलिंग
यह ध्यान रखना महत्वपूर्ण है कि मास्टर स्विच, मजबूर या नहीं, पूरे टोपोलॉजी पर प्रभाव डालता है। राइट्स को एक नए नोड पर रीडायरेक्ट करना होगा। यह कई तरीकों से किया जा सकता है और यह सुनिश्चित करना महत्वपूर्ण है कि यह परिवर्तन आवेदन के लिए यथासंभव पारदर्शी हो। इस खंड में हम कुछ उदाहरणों पर एक नज़र डालेंगे कि कैसे आवेदन के लिए विफलता को पारदर्शी बनाया जा सकता है।
डीएनएस
किसी एप्लिकेशन को मास्टर की ओर इंगित करने का एक तरीका DNS प्रविष्टियों का उपयोग करना है। कम टीटीएल के साथ आईपी पते को बदलना संभव है जिसमें एक DNS प्रविष्टि जैसे 'master.dc1.example.com' अंक। ऐसा परिवर्तन फ़ेलओवर प्रक्रिया के दौरान निष्पादित बाहरी स्क्रिप्ट के माध्यम से किया जा सकता है।
सेवा खोज
यातायात को सही स्थान पर निर्देशित करने के लिए कॉन्सल या आदि जैसे उपकरणों का भी उपयोग किया जा सकता है। ऐसे टूल में यह जानकारी हो सकती है कि वर्तमान मास्टर का IP कुछ मान पर सेट है। उनमें से कुछ सही आईपी को इंगित करने के लिए होस्टनाम लुकअप का उपयोग करने की क्षमता भी देते हैं। फिर से, सर्विस डिस्कवरी टूल्स में प्रविष्टियों को बनाए रखना होता है और ऐसा करने का एक तरीका यह है कि फेलओवर प्रक्रिया के दौरान उन बदलावों को किया जाए, जो फेलओवर के विभिन्न चरणों में निष्पादित हुक का उपयोग करते हैं।
प्रॉक्सी
प्रॉक्सी का उपयोग टोपोलॉजी के बारे में सच्चाई के स्रोत के रूप में भी किया जा सकता है। सामान्यतया, कोई फर्क नहीं पड़ता कि वे टोपोलॉजी की खोज कैसे करते हैं (यह या तो एक स्वचालित प्रक्रिया हो सकती है या टोपोलॉजी में परिवर्तन होने पर प्रॉक्सी को फिर से कॉन्फ़िगर करना पड़ता है), उनमें प्रतिकृति श्रृंखला की वर्तमान स्थिति होनी चाहिए अन्यथा वे सक्षम नहीं होंगे। प्रश्नों को सही तरीके से रूट करें।
प्रॉक्सी को सत्य के स्रोत के रूप में उपयोग करने का दृष्टिकोण एप्लिकेशन होस्ट पर प्रॉक्सी को कॉलोकेट करने के दृष्टिकोण के संयोजन के साथ काफी सामान्य हो सकता है। प्रॉक्सी और वेब सर्वर को कॉलोकेट करने के कई फायदे हैं:यूनिक्स सॉकेट का उपयोग करके तेज और सुरक्षित संचार, एक कैशिंग परत रखना (जैसा कि कुछ प्रॉक्सी, जैसे प्रॉक्सीएसक्यूएल भी कैशिंग कर सकता है) एप्लिकेशन के करीब है। ऐसे मामले में, यह समझ में आता है कि एप्लिकेशन केवल प्रॉक्सी से कनेक्ट होता है और यह मानता है कि यह प्रश्नों को सही तरीके से रूट करेगा।
ClusterControl में विफलता
ClusterControl यह सुनिश्चित करने के लिए उद्योग की सर्वोत्तम प्रथाओं को लागू करता है कि विफलता प्रक्रिया सही तरीके से की जाती है। यह यह भी सुनिश्चित करता है कि प्रक्रिया सुरक्षित रहेगी - यदि संभावित समस्याओं का पता चलता है तो डिफ़ॉल्ट सेटिंग्स का उद्देश्य विफलता को रोकना है। उन सेटिंग्स को उपयोगकर्ता द्वारा ओवरराइड किया जा सकता है, अगर वे डेटा सुरक्षा पर फ़ेलओवर को प्राथमिकता देना चाहते हैं।
ClusterControl द्वारा एक मास्टर विफलता का पता चलने के बाद, एक विफलता प्रक्रिया शुरू की जाती है और पहला फ़ेलओवर हुक तुरंत निष्पादित किया जाता है:

इसके बाद, मास्टर उपलब्धता का परीक्षण किया जाता है।

क्लस्टर कंट्रोल यह सुनिश्चित करने के लिए व्यापक परीक्षण करता है कि मास्टर वास्तव में अनुपलब्ध है। यह व्यवहार डिफ़ॉल्ट रूप से सक्षम है और इसे निम्न चर द्वारा प्रबंधित किया जाता है:
replication_check_external_bf_failover
Before attempting a failover, perform extended checks by checking the slave status to detect if the master is truly down, and also check if ProxySQL (if installed) can still see the master. If the master is detected to be functioning, then no failover will be performed. Default is 1 meaning the checks are enabled.निम्नलिखित कदम के रूप में, ClusterControl सुनिश्चित करता है कि पुराना मास्टर नीचे है और यदि नहीं, तो ClusterControl इसे पुनर्प्राप्त करने का प्रयास नहीं करेगा:

अगला कदम यह निर्धारित करना है कि मास्टर उम्मीदवार के रूप में किस मेजबान का उपयोग किया जा सकता है। ClusterControl जाँचता है कि कोई श्वेतसूची या काली सूची परिभाषित है या नहीं।
आप cmon कॉन्फ़िगरेशन फ़ाइल में निम्न चर का उपयोग करके ऐसा कर सकते हैं:
replication_failover_blacklist
Comma separated list of hostname:port pairs. Blacklisted servers will not be considered as a candidate during failover. replication_failover_blacklist is ignored if replication_failover_whitelist is set.replication_failover_whitelist
Comma separated list of hostname:port pairs. Only whitelisted servers will be considered as a candidate during failover. If no server on the whitelist is available (up/connected) the failover will fail. replication_failover_blacklist is ignored if replication_failover_whitelist is set.सभी प्रतिकृतियों में बाइनरी लॉग फ़िल्टर में अंतर देखने के लिए क्लस्टरकंट्रोल को कॉन्फ़िगर करना भी संभव है। यह प्रतिकृति_चेक_बिनलॉग_फिल्ट्रेशन_बीएफ_फेलओवर चर का उपयोग करके किया जा सकता है। डिफ़ॉल्ट रूप से, वे चेक अक्षम होते हैं। ClusterControl यह भी सत्यापित करता है कि कहीं कोई गलत लेन-देन तो नहीं हुआ है, जिससे समस्या हो सकती है।

आप Cmon कॉन्फ़िगरेशन फ़ाइल में निम्न सेटिंग का उपयोग करके ClusterControl से प्रतिकृतियों को ऑटो-पुनर्निर्माण करने के लिए भी कह सकते हैं जो नए मास्टर से दोहराई नहीं जा सकती हैं:
* replication_auto_rebuild_slave:
If the SQL THREAD is stopped and error code is non-zero then the slave will be automatically rebuilt. 1 means enable, 0 means disable (default).
बाद में एक दूसरी स्क्रिप्ट निष्पादित की जाती है:इसे प्रतिकृति_pre_failover_script सेटिंग में परिभाषित किया गया है। इसके बाद, एक उम्मीदवार तैयारी प्रक्रिया से गुजरता है।


ClusterControl लॉग को फिर से लागू करने की प्रतीक्षा करता है (यह सुनिश्चित करना कि डेटा हानि न्यूनतम है)। यह यह भी जांचता है कि क्या शेष प्रतिकृतियों पर अन्य लेनदेन उपलब्ध हैं, जिन्हें मास्टर उम्मीदवार पर लागू नहीं किया गया है। दोनों व्यवहारों को उपयोगकर्ता द्वारा cmon कॉन्फ़िगरेशन फ़ाइल में निम्न सेटिंग्स का उपयोग करके नियंत्रित किया जा सकता है:
replication_skip_apply_missing_txs
Force failover/switchover by skipping applying transactions from other slaves. Default disabled. 1 means enabled.replication_failover_wait_to_apply_timeout
Candidate waits up to this many seconds to apply outstanding relay log (retrieved_gtids) before failing over. Default -1 seconds (wait forever). 0 means failover immediately.जैसा कि आप देख सकते हैं, आप एक विफलता को बाध्य कर सकते हैं, भले ही सभी रीडो लॉग इवेंट लागू नहीं किए गए हों - यह उपयोगकर्ता को यह तय करने की अनुमति देता है कि उच्च प्राथमिकता क्या है - डेटा स्थिरता या विफलता वेग।


अंत में, मास्टर चुना जाता है और अंतिम स्क्रिप्ट निष्पादित की जाती है (एक स्क्रिप्ट जिसे प्रतिकृति_पोस्ट_फेलओवर_स्क्रिप्ट के रूप में परिभाषित किया जा सकता है।
यदि आपने अभी तक ClusterControl की कोशिश नहीं की है, तो मैं आपको इसे डाउनलोड करने के लिए प्रोत्साहित करता हूँ (यह मुफ़्त है) और इसे आज़माएँ।
ClusterControl में मास्टर डिटेक्शन
ClusterControl आपको डेटाबेस और प्रॉक्सी परतों सहित पूर्ण उच्च उपलब्धता स्टैक को परिनियोजित करने की क्षमता देता है। मास्टर डिस्कवरी हमेशा से निपटने के मुद्दों में से एक है।
यह ClusterControl में कैसे काम करता है?
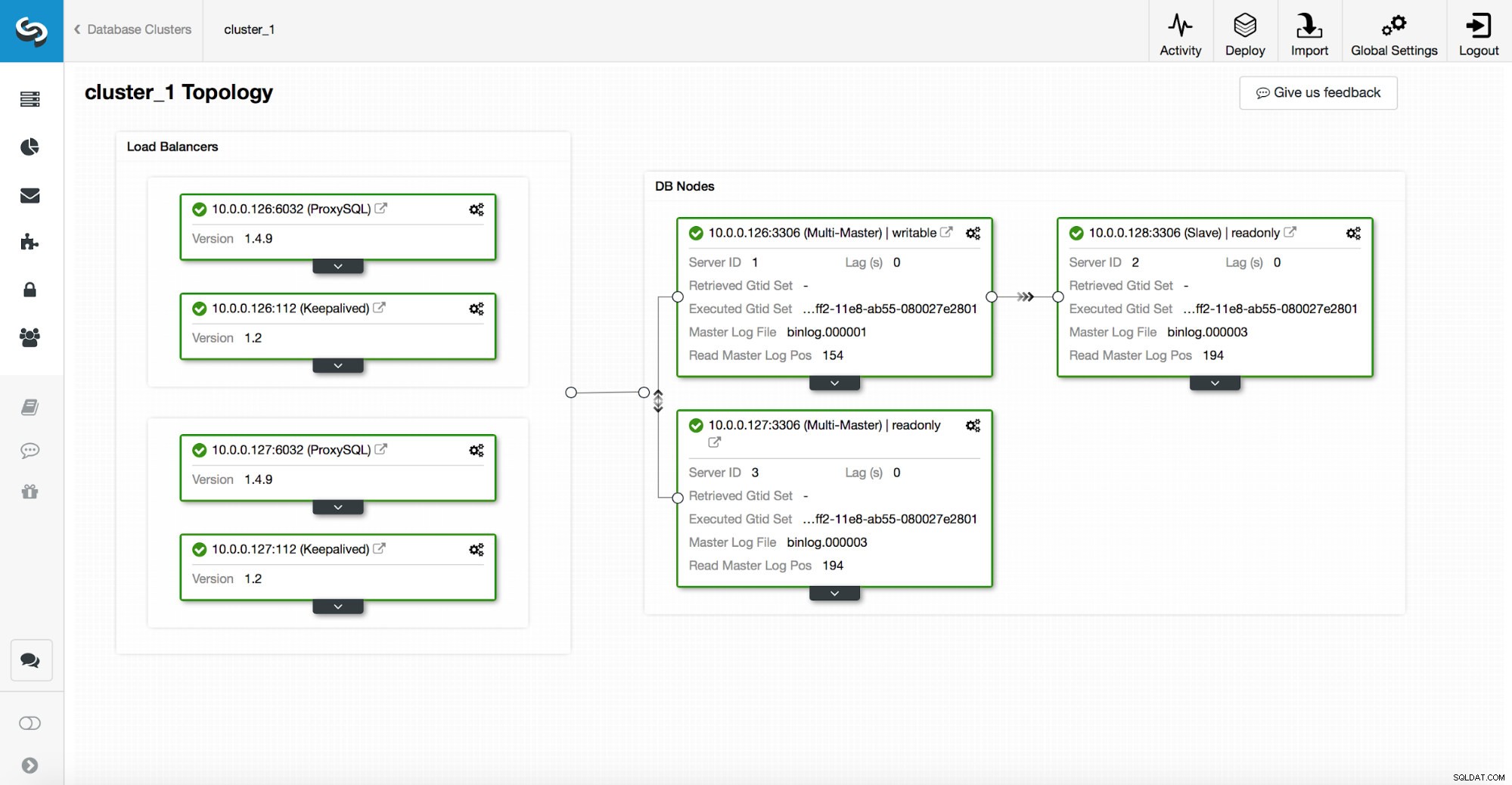
ClusterControl के माध्यम से परिनियोजित एक उच्च उपलब्धता स्टैक में तीन भाग होते हैं:
- डेटाबेस परत
- प्रॉक्सी लेयर जो HAProxy या ProxySQL हो सकती है
- रखने वाली परत, जो वर्चुअल आईपी के उपयोग के साथ, प्रॉक्सी परत की उच्च उपलब्धता सुनिश्चित करती है
प्रॉक्सी नोड्स पर केवल read_only चर पर निर्भर करते हैं।
जैसा कि आप ऊपर स्क्रीनशॉट में देख सकते हैं, टोपोलॉजी में केवल एक नोड को "लिखने योग्य" के रूप में चिह्नित किया गया है। यह मास्टर है और यह एकमात्र नोड है जो लेखन प्राप्त करेगा।
एक प्रॉक्सी (इस उदाहरण में, ProxySQL) इस चर की निगरानी करेगा और यह अपने आप अपने आप पुन:कॉन्फ़िगर हो जाएगा।
उस समीकरण के दूसरी ओर, ClusterControl टोपोलॉजी परिवर्तनों का ध्यान रखता है:फ़ेलओवर और स्विचओवर। यह परिवर्तन के बाद टोपोलॉजी की स्थिति को दर्शाने के लिए केवल read_only मान में आवश्यक परिवर्तन करेगा। यदि एक नए मास्टर को पदोन्नत किया जाता है, तो यह एकमात्र लिखने योग्य नोड बन जाएगा। अगर कोई मास्टर फ़ेलओवर के बाद चुना जाता है, तो वह केवल पढ़ने के लिए अक्षम होगा।
प्रॉक्सी परत के ऊपर, Keepalived तैनात है। यह एक वीआईपी को तैनात करता है और यह अंतर्निहित प्रॉक्सी नोड्स की स्थिति की निगरानी करता है। VIP एक निश्चित समय में एक प्रॉक्सी नोड की ओर इशारा करता है। यदि यह नोड नीचे चला जाता है, तो वर्चुअल आईपी को दूसरे नोड पर रीडायरेक्ट किया जाता है, यह सुनिश्चित करता है कि वीआईपी को निर्देशित ट्रैफिक एक स्वस्थ प्रॉक्सी नोड तक पहुंच जाएगा।
इसे योग करने के लिए, एक एप्लिकेशन वर्चुअल आईपी एड्रेस का उपयोग करके डेटाबेस से जुड़ता है। यह आईपी प्रॉक्सी में से एक को इंगित करता है। प्रॉक्सी टोपोलॉजी संरचना के अनुसार यातायात को पुनर्निर्देशित करता है। टोपोलॉजी के बारे में जानकारी केवल read_only राज्य से ली गई है। यह चर ClusterControl द्वारा प्रबंधित किया जाता है और यह उपयोगकर्ता द्वारा अनुरोधित टोपोलॉजी परिवर्तनों या स्वचालित रूप से किए गए ClusterControl के आधार पर सेट किया जाता है।