एक क्वेरी निष्पादित करते समय, SQL सर्वर अनुकूलक मौजूदा अनुक्रमणिका और उपलब्ध नवीनतम आंकड़ों के आधार पर एक उचित समय के लिए सर्वोत्तम क्वेरी योजना खोजने का प्रयास करता है, निश्चित रूप से, यदि यह योजना पहले से सर्वर कैश में संग्रहीत नहीं है। यदि नहीं, तो इस योजना के अनुसार क्वेरी निष्पादित की जाती है, और योजना सर्वर कैश में संग्रहीत होती है। यदि इस क्वेरी के लिए पहले से ही योजना बनाई गई है, तो मौजूदा योजना के अनुसार क्वेरी निष्पादित की जाती है।
हम निम्नलिखित मुद्दे में रुचि रखते हैं:
एक क्वेरी प्लान के संकलन के दौरान, संभावित इंडेक्स को सॉर्ट करते समय, यदि सर्वर को सर्वश्रेष्ठ इंडेक्स नहीं मिलता है, तो लापता इंडेक्स को क्वेरी प्लान में चिह्नित किया जाता है, और सर्वर ऐसे इंडेक्स पर आंकड़े रखता है:सर्वर कितनी बार इस इंडेक्स का उपयोग करेगा और इस क्वेरी की लागत कितनी होगी।
इस लेख में, हम इन लापता इंडेक्स का विश्लेषण करने जा रहे हैं - उनसे कैसे निपटें।
आइए इस पर एक विशेष उदाहरण पर विचार करें। स्थानीय और परीक्षण सर्वर पर हमारे डेटाबेस में कुछ टेबल बनाएं:
[शीर्षक विस्तृत करें ="कोड"]
if object_id ('orders_detail') is not null drop table orders_detail;
if object_id('orders') is not null drop table orders;
go
create table orders
(
id int identity primary key,
dt datetime,
seller nvarchar(50)
)
create table orders_detail
(
id int identity primary key,
order_id int foreign key references orders(id),
product nvarchar(30),
qty int,
price money,
cost as qty * price
)
go
with cte as
(
select 1 id union all
select id+1 from cte where id < 20000
)
insert orders
select
dt,
seller
from
(
select
dateadd(day,abs(convert(int,convert(binary(4),newid()))%365),'2016-01-01') dt,
abs(convert(int,convert(binary(4),newid()))%5)+1 seller_id
from cte
) c
left join
(
values
(1,'John'),
(2,'Mike'),
(3,'Ann'),
(4,'Alice'),
(5,'George')
) t (id,seller) on t.id = c.seller_id
option(maxrecursion 0)
insert orders_detail
select
order_id,
product,
qty,
price
from
(
select
o.id as order_id,
abs(convert(int,convert(binary(4),newid()))%5)+1 product_id,
abs(convert(int,convert(binary(4),newid()))%20)+1 qty
from orders o cross join
(
select top(abs(convert(int,convert(binary(4),newid()))%5)+1) *
from
(
values (1),(2),(3),(4),(5),(6),(7),(8)
) n(num)
) n
) c
left join
(
values
(1,'Sugar', 50),
(2,'Milk', 80),
(3,'Bread', 20),
(4,'Pasta', 40),
(5,'Beer', 100)
) t (id,product, price) on t.id = c.product_id
go [/विस्तार]
संरचना सरल है और इसमें दो टेबल हैं। पहचानकर्ता, बिक्री की तारीख और विक्रेता जैसे क्षेत्रों के साथ पहली तालिका को ऑर्डर कहा जाता है। दूसरा ऑर्डर विवरण है, जहां कुछ सामान कीमत और मात्रा के साथ निर्दिष्ट किए जाते हैं।
एक साधारण प्रश्न और उसकी योजना देखें:
select count(*) from orders o join orders_detail d on o.id = d.order_id where d.cost > 1800 go
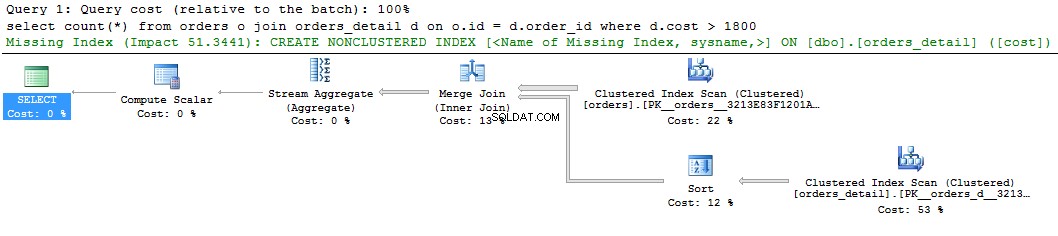
हम क्वेरी प्लान के ग्राफिक डिस्प्ले पर लापता इंडेक्स के बारे में एक हरा संकेत देख सकते हैं। यदि आप इसे राइट-क्लिक करते हैं और "मिसिंग इंडेक्स विवरण .." का चयन करते हैं, तो सुझाए गए इंडेक्स का टेक्स्ट होगा। केवल एक ही काम करना है कि पाठ में टिप्पणियों को हटा दें और अनुक्रमणिका को एक नाम दें। स्क्रिप्ट निष्पादित होने के लिए तैयार है।
हम SSMS द्वारा प्रदान किए गए संकेत से प्राप्त सूचकांक का निर्माण नहीं करेंगे। इसके बजाय, हम देखेंगे कि क्या इस अनुक्रमणिका की अनुशंसा अनुपलब्ध अनुक्रमणिका से जुड़े गतिशील दृश्यों द्वारा की जाएगी। विचार इस प्रकार हैं:
select * from sys.dm_db_missing_index_group_stats select * from sys.dm_db_missing_index_details select * from sys.dm_db_missing_index_groups
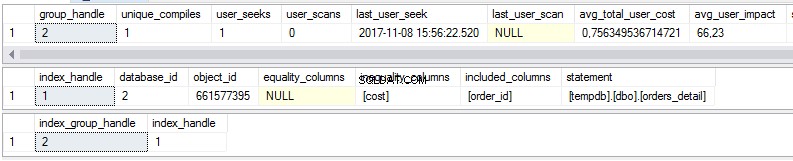
जैसा कि हम देख सकते हैं, पहले दृश्य में अनुपलब्ध अनुक्रमणिका के कुछ आँकड़े हैं:
- यदि सुझाई गई अनुक्रमणिका मौजूद होती तो कितनी बार खोज की जाती?
- सुझाई गई अनुक्रमणिका मौजूद होने पर कितनी बार स्कैन किया जाएगा?
- नवीनतम दिनांक और समय हमने अनुक्रमणिका का उपयोग किया
- सुझाई गई अनुक्रमणिका के बिना क्वेरी योजना की वर्तमान वास्तविक लागत।
दूसरा दृश्य इंडेक्स बॉडी है:
- डेटाबेस
- ऑब्जेक्ट/टेबल
- सॉर्ट किए गए कॉलम
- इंडेक्स कवरेज बढ़ाने के लिए जोड़े गए कॉलम
तीसरा दृश्य पहले और दूसरे दृश्य का संयोजन है।
तदनुसार, ऐसी स्क्रिप्ट प्राप्त करना मुश्किल नहीं है जो इन गतिशील विचारों से लापता अनुक्रमणिका बनाने के लिए एक स्क्रिप्ट उत्पन्न करे। स्क्रिप्ट इस प्रकार है:
[विस्तार शीर्षक ="कोड"]
with igs as
(
select *
from sys.dm_db_missing_index_group_stats
)
, igd as
(
select *,
isnull(equality_columns,'')+','+isnull(inequality_columns,'') as ix_col
from sys.dm_db_missing_index_details
)
select --top(10)
'use ['+db_name(igd.database_id)+'];
create index ['+'ix_'+replace(convert(varchar(10),getdate(),120),'-','')+'_'+convert(varchar,igs.group_handle)+'] on '+
igd.[statement]+'('+
case
when left(ix_col,1)=',' then stuff(ix_col,1,1,'')
when right(ix_col,1)=',' then reverse(stuff(reverse(ix_col),1,1,''))
else ix_col
end
+') '+isnull('include('+igd.included_columns+')','')+' with(online=on, maxdop=0)
go
' command
,igs.user_seeks
,igs.user_scans
,igs.avg_total_user_cost
from igs
join sys.dm_db_missing_index_groups link on link.index_group_handle = igs.group_handle
join igd on link.index_handle = igd.index_handle
where igd.database_id = db_id()
order by igs.avg_total_user_cost * igs.user_seeks desc द्वारा ऑर्डर करें [/विस्तार]
सूचकांक दक्षता के लिए, लापता सूचकांक आउटपुट हैं। सही समाधान तब होता है जब यह परिणाम सेट कुछ भी नहीं लौटाता है। हमारे उदाहरण में, परिणाम सेट कम से कम एक इंडेक्स लौटाएगा:

जब समय नहीं होता है और आपको क्लाइंट बग से निपटने का मन नहीं करता है, तो मैंने क्वेरी को निष्पादित किया, पहले कॉलम की प्रतिलिपि बनाई और इसे सर्वर पर निष्पादित किया। इसके बाद, सब कुछ ठीक रहा।
मैं अनुशंसा करता हूं कि इन अनुक्रमितों की जानकारी को होशपूर्वक व्यवहार करें। उदाहरण के लिए, यदि सिस्टम निम्नलिखित अनुक्रमणिकाओं की अनुशंसा करता है:
create index ix_01 on tbl1 (a,b) include (c) create index ix_02 on tbl1 (a,b) include (d) create index ix_03 on tbl1 (a)
और इन अनुक्रमणिकाओं का उपयोग खोज के लिए किया जाता है, यह बिल्कुल स्पष्ट है कि इन अनुक्रमणिकाओं को एक के साथ प्रतिस्थापित करना अधिक तार्किक है जो सुझाए गए तीनों को कवर करेगा:
create index ix_1 on tbl1 (a,b) include (c,d)
इस प्रकार, हम लापता अनुक्रमितों को उत्पादन सर्वर पर परिनियोजित करने से पहले उनकी समीक्षा करते हैं। यद्यपि…। फिर से, उदाहरण के लिए, मैंने खोए हुए इंडेक्स को टीएफएस सर्वर पर तैनात किया, इस प्रकार, समग्र प्रदर्शन में वृद्धि हुई। इस अनुकूलन को करने में न्यूनतम समय लगा। हालांकि, टीएफएस 2015 से टीएफएस 2017 में बदलते समय, मुझे इस मुद्दे का सामना करना पड़ा कि इन नए इंडेक्स के कारण कोई अपडेट नहीं था। फिर भी, उन्हें आसानी से मास्क द्वारा पाया जा सकता है
select * from sys.indexes where name like 'ix[_]2017%'
उपयोगी टूल:
डीबीफोर्ज इंडेक्स मैनेजर - एसक्यूएल इंडेक्स की स्थिति का विश्लेषण करने और इंडेक्स विखंडन के साथ मुद्दों को ठीक करने के लिए आसान एसएसएमएस ऐड-इन।