मेरी 'घुटने-झटका प्रदर्शन ट्यूनिंग' श्रृंखला से एक प्रस्थान में, मैं इस बात पर चर्चा करना चाहता हूं कि कुछ परिस्थितियों में सूचकांक विखंडन आप पर कैसे आ सकता है।
सूचकांक विखंडन क्या है?
अधिकांश लोग 'इंडेक्स फ़्रेग्मेंटेशन' को उस समस्या के रूप में समझते हैं जहां इंडेक्स लीफ पेज क्रम से बाहर हैं - इंडेक्स लीफ पेज अगले कुंजी मान वाला वह नहीं है जो वर्तमान में जांचे जा रहे इंडेक्स लीफ पेज पर डेटा फ़ाइल में भौतिक रूप से सन्निहित है। . इसे तार्किक विखंडन कहा जाता है (और कुछ लोग इसे बाहरी विखंडन के रूप में संदर्भित करते हैं - एक भ्रमित करने वाला शब्द जो मुझे पसंद नहीं है)।
तार्किक विखंडन तब होता है जब एक इंडेक्स लीफ पेज भरा होता है और उस पर जगह की आवश्यकता होती है, या तो एक डालने के लिए या मौजूदा रिकॉर्ड को लंबा बनाने के लिए (एक चर-लंबाई कॉलम को अपडेट करने से)। उस स्थिति में, संग्रहण इंजन एक नया, खाली पृष्ठ बनाता है और 50% पंक्तियों (आमतौर पर, लेकिन हमेशा नहीं) को पूर्ण पृष्ठ से नए पृष्ठ पर ले जाता है। यह ऑपरेशन दोनों पेजों में जगह बनाता है, जिससे इन्सर्ट या अपडेट को आगे बढ़ने की अनुमति मिलती है, और इसे पेज स्प्लिट कहा जाता है। ऐसे दिलचस्प पैथोलॉजिकल मामले हैं जिनमें एक ही ऑपरेशन से बार-बार पेज स्प्लिट और इंडेक्स लेवल को कैस्केड करने वाले पेज स्प्लिट शामिल हैं, लेकिन वे इस पोस्ट के दायरे से बाहर हैं।
जब कोई पृष्ठ विभाजन होता है, तो यह आमतौर पर तार्किक विखंडन का कारण बनता है क्योंकि आवंटित किया गया नया पृष्ठ विभाजित होने वाले पृष्ठ से भौतिक रूप से सन्निहित होने की अत्यधिक संभावना नहीं है। जब किसी अनुक्रमणिका में बहुत अधिक तार्किक विखंडन होता है, तो अनुक्रमणिका स्कैन धीमा हो जाता है क्योंकि आवश्यक पृष्ठों का भौतिक पठन उतनी कुशलता से नहीं किया जा सकता है (बहु-पृष्ठ 'रीडहेड' का उपयोग करके) जब डेटा फ़ाइल में पत्ती पृष्ठों को क्रम में संग्रहीत नहीं किया जाता है ।
यह इंडेक्स फ़्रेग्मेंटेशन की मूल परिभाषा है, लेकिन एक दूसरे प्रकार का इंडेक्स फ़्रेग्मेंटेशन है जिस पर ज़्यादातर लोग विचार नहीं करते हैं:कम पेज डेंसिटी (कभी-कभी आंतरिक फ़्रेग्मेंटेशन कहते हैं, फिर से, एक भ्रमित करने वाला शब्द जो मुझे पसंद नहीं है)।
पेज डेंसिटी इस बात का माप है कि इंडेक्स लीफ पेज पर कितना डेटा स्टोर किया जाता है। जब सामान्य 50/50 मामले के साथ एक पृष्ठ विभाजन होता है, तो प्रत्येक पत्ती पृष्ठ (विभाजन एक और नया एक) केवल 50% के पृष्ठ घनत्व के साथ छोड़ दिया जाता है। पृष्ठ घनत्व जितना कम होगा, अनुक्रमणिका में उतनी ही अधिक खाली जगह होगी और इसलिए अधिक डिस्क स्थान और बफर पूल मेमोरी जिसे आप बर्बाद होने के बारे में सोच सकते हैं। मैंने कुछ साल पहले इस समस्या के बारे में ब्लॉग किया था और आप इसके बारे में यहाँ पढ़ सकते हैं।
अब जब मैंने दो प्रकार के सूचकांक विखंडन की एक बुनियादी परिभाषा दी है, तो मैं उन्हें सामूहिक रूप से केवल 'विखंडन' के रूप में संदर्भित करने जा रहा हूं।
इस पोस्ट के शेष भाग के लिए मैं उन तीन मामलों पर चर्चा करना चाहता हूं जहां क्लस्टर इंडेक्स खंडित हो सकते हैं, भले ही आप ऐसे कार्यों से बच रहे हों जो स्पष्ट रूप से विखंडन का कारण बनेंगे (यानी यादृच्छिक सम्मिलन और रिकॉर्ड लंबे समय तक अपडेट करना)।
डिलीट से फ्रैगमेंटेशन
"क्लस्टर इंडेक्स लीफ पेज से डिलीट पेज को कैसे विभाजित कर सकता है?" आप शायद पूछ रहे होंगे। यह सामान्य परिस्थितियों में नहीं होगा (और मैं यह सुनिश्चित करने के लिए कुछ मिनटों के लिए इसके बारे में सोचता रहा कि कोई अजीब रोग संबंधी मामला तो नहीं है! लेकिन नीचे अनुभाग देखें...) हालांकि, हटाए जाने से पृष्ठ घनत्व उत्तरोत्तर कम हो सकता है।
उस मामले की कल्पना करें जहां क्लस्टर्ड इंडेक्स का एक बड़ा पहचान कुंजी मान होता है, इसलिए इंसर्ट हमेशा इंडेक्स के दाईं ओर जाएगा और कभी भी इंडेक्स के पहले वाले हिस्से में नहीं डाला जाएगा (पहचान मूल्य को फिर से शुरू करने वाले किसी व्यक्ति को छोड़कर - संभावित रूप से बहुत समस्याग्रस्त!) अब कल्पना करें कि कार्यभार तालिका से उन रिकॉर्ड्स को हटा देता है जिनकी अब आवश्यकता नहीं है, जिसके बाद बैकग्राउंड घोस्ट क्लीनअप कार्य पृष्ठ पर स्थान को पुनः प्राप्त करेगा और यह खाली स्थान बन जाएगा।
किसी भी यादृच्छिक प्रविष्टि की अनुपस्थिति में (हमारे परिदृश्य में असंभव जब तक कि कोई व्यक्ति पहचान को फिर से शुरू नहीं करता है या तालिका के लिए SET IDENTITY INSERT को सक्षम करने के बाद उपयोग करने के लिए एक महत्वपूर्ण मूल्य निर्दिष्ट नहीं करता है), कोई भी नया रिकॉर्ड कभी भी उस स्थान का उपयोग नहीं करेगा जो हटाए गए रिकॉर्ड से मुक्त किया गया था। इसका मतलब यह है कि क्लस्टर इंडेक्स के पहले के हिस्सों की औसत पृष्ठ घनत्व लगातार कम हो जाएगी, जिससे बर्बाद डिस्क स्थान और बफर पूल मेमोरी की मात्रा बढ़ जाएगी जैसा कि मैंने पहले बताया था।
जब तक आप पृष्ठ घनत्व को 'विखंडन' के भाग के रूप में मानते हैं, तब तक हटाने से विखंडन हो सकता है।
स्नैपशॉट अलगाव से विखंडन
SQL सर्वर 2005 ने दो नए आइसोलेशन स्तर पेश किए:स्नैपशॉट आइसोलेशन और रीड-प्रतिबद्ध स्नैपशॉट आइसोलेशन। इन दोनों में थोड़ा अलग शब्दार्थ है, लेकिन मूल रूप से क्वेरीज़ को डेटाबेस के पॉइंट-इन-टाइम दृश्य और लॉक-टकराव-मुक्त चयनों को देखने की अनुमति देता है। यह एक बहुत बड़ा सरलीकरण है, लेकिन यह मेरे उद्देश्यों के लिए पर्याप्त है।
इन अलगाव स्तरों को सुविधाजनक बनाने के लिए, Microsoft की विकास टीम जिसका मैंने नेतृत्व किया, ने वर्जनिंग नामक एक तंत्र लागू किया। वर्जनिंग काम करने का तरीका यह है कि जब भी कोई रिकॉर्ड बदलता है, तो रिकॉर्ड के पूर्व-परिवर्तन संस्करण को tempdb में वर्जन स्टोर में कॉपी किया जाता है, और बदले गए रिकॉर्ड को इसके अंत में 14-बाइट वर्जनिंग टैग जोड़ा जाता है। टैग में रिकॉर्ड के पिछले संस्करण के लिए एक पॉइंटर होता है, साथ ही एक टाइमस्टैम्प भी होता है जिसका उपयोग यह निर्धारित करने के लिए किया जा सकता है कि किसी विशेष क्वेरी को पढ़ने के लिए रिकॉर्ड का सही संस्करण क्या है। फिर से, बेहद सरलीकृत, लेकिन यह केवल उन 14-बाइट्स का जोड़ है जिसमें हम रुचि रखते हैं।
इसलिए जब भी इनमें से किसी एक आइसोलेशन स्तर के प्रभावी होने पर कोई रिकॉर्ड बदलता है, तो रिकॉर्ड के लिए पहले से कोई वर्जनिंग टैग नहीं होने पर यह 14 बाइट्स तक विस्तारित हो सकता है। क्या होगा अगर इंडेक्स लीफ पेज पर अतिरिक्त 14 बाइट्स के लिए पर्याप्त जगह नहीं है? यह सही है, एक पृष्ठ विभाजन होगा, जिससे विखंडन होगा।
बड़ी बात, आप सोच सकते हैं, क्योंकि रिकॉर्ड वैसे भी बदल रहा है, इसलिए यदि यह आकार बदल रहा था, तो शायद एक पृष्ठ विभाजन हुआ होगा। नहीं - वह तर्क केवल तभी मान्य होता है जब रिकॉर्ड परिवर्तन एक चर-लंबाई वाले कॉलम के आकार को बढ़ाने के लिए होता है। एक निश्चित लंबाई वाला कॉलम अपडेट होने पर भी एक वर्जनिंग टैग जोड़ा जाएगा!
यह सही है - जब वर्जनिंग चल रही हो, तो फिक्स्ड-लेंथ कॉलम के अपडेट से रिकॉर्ड का विस्तार हो सकता है, संभावित रूप से पेज स्प्लिट और फ्रैगमेंटेशन हो सकता है। और भी दिलचस्प बात यह है कि एक डिलीट 14-बाइट टैग भी जोड़ देगा, इसलिए क्लस्टर्ड इंडेक्स में डिलीट होने पर वर्जनिंग उपयोग में होने पर पेज स्प्लिट हो सकता है!
यहां लब्बोलुआब यह है कि स्नैपशॉट अलगाव के किसी भी रूप को सक्षम करने से क्लस्टर इंडेक्स में अचानक विखंडन शुरू हो सकता है जहां पहले विखंडन की कोई संभावना नहीं थी।
पठनीय माध्यमिक से विखंडन
आखिरी मामला जिस पर मैं चर्चा करना चाहता हूं, वह पठनीय सेकेंडरी का उपयोग कर रहा है, उपलब्धता समूह सुविधा का हिस्सा जो SQL सर्वर 2012 में जोड़ा गया था।
जब आप किसी पठनीय द्वितीयक को सक्षम करते हैं, तो द्वितीयक प्रतिकृति के विरुद्ध आपके द्वारा की जाने वाली सभी क्वेरी को कवर के अंतर्गत स्नैपशॉट आइसोलेशन का उपयोग करने में परिवर्तित कर दिया जाता है। यह क्वेरी को प्राथमिक प्रतिकृति से लॉग रिकॉर्ड के निरंतर पुन:चलाने को अवरुद्ध करने से रोकता है, क्योंकि पुनर्प्राप्ति कोड के साथ-साथ लॉक हो जाता है।
ऐसा करने के लिए, द्वितीयक प्रतिकृति पर रिकॉर्ड पर 14-बाइट संस्करण टैग होना आवश्यक है। एक समस्या है, क्योंकि सभी प्रतिकृतियां समान होनी चाहिए, ताकि लॉग रीप्ले काम करे। खैर, बिलकुल नहीं। वर्जनिंग टैग सामग्री प्रासंगिक नहीं हैं क्योंकि उनका उपयोग केवल उस उदाहरण पर किया जाता है जिसने उन्हें बनाया है। लेकिन सेकेंडरी रेप्लिका वर्जनिंग टैग नहीं जोड़ सकती है, जिससे रिकॉर्ड लंबा हो जाता है, क्योंकि इससे पेज पर रिकॉर्ड्स का भौतिक लेआउट बदल जाएगा और लॉग रीप्लेइंग टूट जाएगा। यदि संस्करण टैग पहले से मौजूद थे, तो यह बिना कुछ तोड़े अंतरिक्ष का उपयोग कर सकता था।
तो ठीक ऐसा ही होता है। संग्रहण इंजन यह सुनिश्चित करता है कि द्वितीयक प्रतिकृति के लिए आवश्यक संस्करण टैग पहले से मौजूद हैं, उन्हें प्राथमिक प्रतिकृति पर जोड़कर!
जैसे ही एक डेटाबेस की एक पठनीय माध्यमिक प्रतिकृति बनाई जाती है, प्राथमिक प्रतिकृति में किसी रिकॉर्ड के लिए कोई भी अद्यतन रिकॉर्ड को एक खाली 14-बाइट टैग जोड़ने का कारण बनता है, ताकि सभी लॉग रिकॉर्ड में 14-बाइट्स का ठीक से हिसाब लगाया जा सके . टैग का उपयोग किसी भी चीज़ के लिए नहीं किया जाता है (जब तक कि प्राथमिक प्रतिकृति पर स्नैपशॉट अलगाव सक्षम न हो), लेकिन तथ्य यह है कि इसे बनाया गया है, यह रिकॉर्ड का विस्तार करने का कारण बनता है, और यदि पृष्ठ पहले से ही भरा हुआ है तो…
हां, एक पठनीय माध्यमिक को सक्षम करने से प्राथमिक प्रतिकृति पर वही प्रभाव पड़ता है जैसे कि आपने उस पर स्नैपशॉट अलगाव को सक्षम किया था - विखंडन।
सारांश
ऐसा मत सोचो क्योंकि आप GUID को क्लस्टर कुंजियों के रूप में उपयोग करने से बच रहे हैं और अपनी तालिकाओं में चर-लंबाई वाले कॉलम को अपडेट करने से बच रहे हैं, तो आपके क्लस्टर इंडेक्स विखंडन के प्रति प्रतिरक्षित होंगे। जैसा कि मैंने ऊपर वर्णित किया है, अन्य कार्यभार और पर्यावरणीय कारक हैं जो आपके क्लस्टर इंडेक्स में विखंडन की समस्या पैदा कर सकते हैं जिनसे आपको अवगत होने की आवश्यकता है।
अब न झुकें और सोचें कि आपको रिकॉर्ड नहीं हटाना चाहिए, स्नैपशॉट अलगाव का उपयोग नहीं करना चाहिए, और पठनीय सेकेंडरी का उपयोग नहीं करना चाहिए। आपको बस इस बात से अवगत रहना होगा कि वे सभी विखंडन का कारण बन सकते हैं और यह जान सकते हैं कि इसका पता कैसे लगाया जाए, हटाया जाए और इसे कम किया जाए।
SQL संतरी में एक अच्छा उपकरण है, Fragmentation Manager, जिसका उपयोग आप प्रदर्शन सलाहकार के ऐड-ऑन के रूप में कर सकते हैं ताकि यह पता लगाया जा सके कि विखंडन की समस्याएँ कहाँ हैं और फिर उनका समाधान करें। जब आप जाँच करते हैं तो आपको मिलने वाले विखंडन पर आपको आश्चर्य हो सकता है! एक त्वरित उदाहरण के रूप में, यहाँ मैं देख सकता हूँ - व्यक्तिगत विभाजन स्तर तक - कितना विखंडन मौजूद है, यह कितनी जल्दी इस तरह से मिला, कोई भी पैटर्न जो मौजूद है, और सिस्टम में व्यर्थ स्मृति पर इसका वास्तविक प्रभाव है:
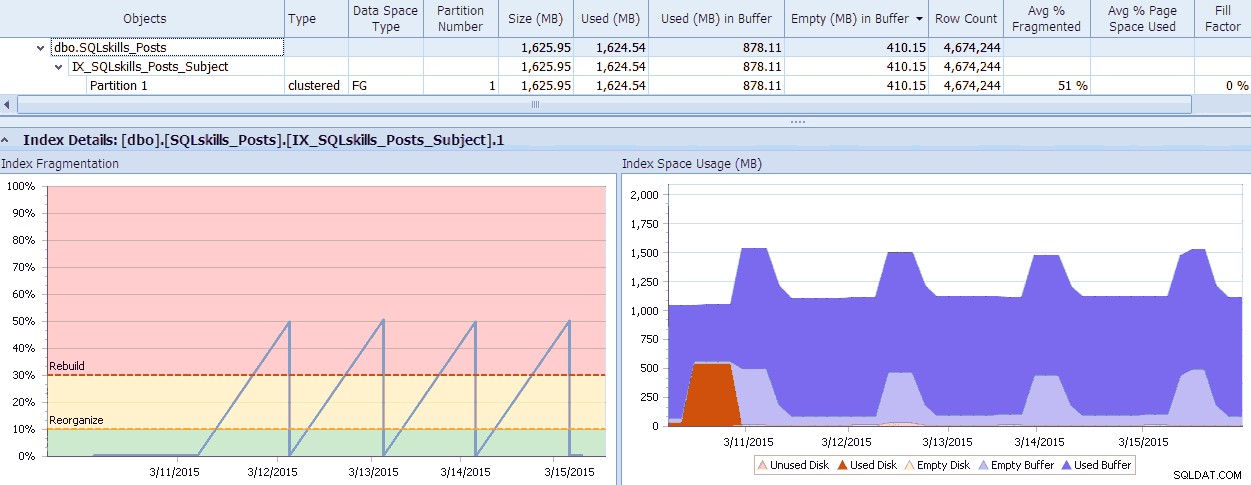 SQL संतरी विखंडन प्रबंधक डेटा (विस्तार करने के लिए क्लिक करें)
SQL संतरी विखंडन प्रबंधक डेटा (विस्तार करने के लिए क्लिक करें)
अपनी अगली पोस्ट में, मैं विखंडन के बारे में और इसे कम समस्याग्रस्त बनाने के लिए इसे कम करने के तरीके के बारे में अधिक चर्चा करूँगा।