
यह महीने का वह मंगलवार है - आप जानते हैं, जब ब्लॉगर ब्लॉक पार्टी जिसे टी-एसक्यूएल मंगलवार के रूप में जाना जाता है, होता है। इस महीने यह रस थॉमस (@SQLJudo) द्वारा होस्ट किया गया है, और विषय है, "सभी ट्यूनर और गियर प्रमुखों को कॉल करना।" मैं यहां एक प्रदर्शन-संबंधी समस्या का इलाज करने जा रहा हूं, हालांकि मैं क्षमा चाहता हूं कि यह पूरी तरह से उन दिशानिर्देशों के अनुरूप नहीं हो सकता है जो रसेल ने अपने निमंत्रण में निर्धारित किए हैं (मैं संकेत, ट्रेस झंडे या योजना गाइड का उपयोग नहीं करने जा रहा हूं) ।
पिछले हफ्ते SQLBits में, मैंने ट्रिगर्स पर एक प्रेजेंटेशन दिया, और मेरे अच्छे दोस्त और साथी MVP Erland Somarskog उपस्थित हुए। एक बिंदु पर मैंने सुझाव दिया कि एक टेबल पर एक नया ट्रिगर बनाने से पहले, आपको यह देखने के लिए जांच करनी चाहिए कि क्या कोई ट्रिगर पहले से मौजूद है, और अतिरिक्त ट्रिगर जोड़ने के बजाय तर्क को संयोजित करने पर विचार करें। मेरे कारण मुख्य रूप से कोड रखरखाव के लिए थे, लेकिन प्रदर्शन के लिए भी। एरलैंड ने पूछा कि क्या मैंने कभी यह देखने के लिए परीक्षण किया था कि क्या एक ही कार्रवाई के लिए कई ट्रिगर्स आग लगने में कोई अतिरिक्त ओवरहेड था, और मुझे यह स्वीकार करना पड़ा कि, नहीं, मैंने कुछ भी व्यापक नहीं किया था। तो मैं अभी ऐसा करने जा रहा हूँ।
AdventureWorks2014 में, मैंने टेबल का एक सरल सेट बनाया जो मूल रूप से sys.all_objects का प्रतिनिधित्व करता है। (~2,700 पंक्तियाँ) और sys.all_columns (~9,500 पंक्तियाँ)। मैं दोनों तालिकाओं को अद्यतन करने के लिए विभिन्न दृष्टिकोणों के कार्यभार पर प्रभाव को मापना चाहता था - अनिवार्य रूप से आपके पास कॉलम तालिका अपडेट करने वाले उपयोगकर्ता हैं, और आप एक ही तालिका में एक अलग कॉलम और ऑब्जेक्ट तालिका में कुछ कॉलम अपडेट करने के लिए ट्रिगर का उपयोग करते हैं।
- T1:आधार रेखा :मान लें कि आप संग्रहीत कार्यविधि के माध्यम से सभी डेटा एक्सेस को नियंत्रित कर सकते हैं; इस मामले में, दोनों तालिकाओं के खिलाफ अद्यतन सीधे किया जा सकता है, ट्रिगर्स की कोई आवश्यकता नहीं है। (यह वास्तविक दुनिया में व्यावहारिक नहीं है, क्योंकि आप तालिकाओं तक सीधे पहुंच को विश्वसनीय रूप से प्रतिबंधित नहीं कर सकते हैं।)
- T2:अन्य तालिका के विरुद्ध एकल ट्रिगर :मान लें कि आप प्रभावित तालिका के विरुद्ध अद्यतन कथन को नियंत्रित कर सकते हैं और अन्य स्तंभ जोड़ सकते हैं, लेकिन द्वितीयक तालिका के अद्यतनों को ट्रिगर के साथ कार्यान्वित करने की आवश्यकता है। हम तीनों कॉलम को एक स्टेटमेंट के साथ अपडेट करेंगे।
- T3:दोनों तालिकाओं के विरुद्ध एकल ट्रिगर :इस मामले में, हमारे पास दो कथनों के साथ एक ट्रिगर है, एक जो प्रभावित तालिका में दूसरे कॉलम को अपडेट करता है, और एक जो द्वितीयक तालिका में सभी तीन कॉलम को अपडेट करता है।
- T4:दोनों तालिकाओं के विरुद्ध एकल ट्रिगर :T3 की तरह, लेकिन इस बार, हमारे पास चार कथनों के साथ एक ट्रिगर है, एक जो प्रभावित तालिका में दूसरे कॉलम को अपडेट करता है, और द्वितीयक तालिका में अपडेट किए गए प्रत्येक कॉलम के लिए एक स्टेटमेंट। यदि समय के साथ आवश्यकताओं को जोड़ा जाता है और प्रतिगमन परीक्षण के संदर्भ में एक अलग कथन को सुरक्षित माना जाता है, तो इसे इस तरह से संभाला जा सकता है।
- T5:दो ट्रिगर :एक ट्रिगर केवल प्रभावित तालिका को अपडेट करता है; दूसरा द्वितीयक तालिका में तीन स्तंभों को अद्यतन करने के लिए एकल कथन का उपयोग करता है। यदि अन्य ट्रिगर्स पर ध्यान नहीं दिया जाता है या यदि उन्हें संशोधित करना प्रतिबंधित है, तो इसे इसी तरह से किया जा सकता है।
- T6:चार ट्रिगर :एक ट्रिगर केवल प्रभावित तालिका को अपडेट करता है; अन्य तीन द्वितीयक तालिका में प्रत्येक स्तंभ को अद्यतन करते हैं। दोबारा, यदि आप नहीं जानते कि अन्य ट्रिगर मौजूद हैं, या यदि आप प्रतिगमन चिंताओं के कारण अन्य ट्रिगर्स को छूने से डरते हैं, तो यह उसी तरह से किया जा सकता है।
यहां वह स्रोत डेटा है जिसके साथ हम काम कर रहे हैं:
-- sys.all_objects: SELECT * INTO dbo.src FROM sys.all_objects; CREATE UNIQUE CLUSTERED INDEX x ON dbo.src([object_id]); GO -- sys.all_columns: SELECT * INTO dbo.tr1 FROM sys.all_columns; CREATE UNIQUE CLUSTERED INDEX x ON dbo.tr1([object_id], column_id); -- repeat 5 times: tr2, tr3, tr4, tr5, tr6
अब, 6 परीक्षणों में से प्रत्येक के लिए, हम अपने अपडेट 1,000 बार चलाने जा रहे हैं, और समय की लंबाई को मापेंगे
T1:बेसलाइन
यह वह परिदृश्य है जहां हम ट्रिगर से बचने के लिए पर्याप्त भाग्यशाली हैं (फिर से, बहुत यथार्थवादी नहीं)। इस मामले में, हम इस बैच की रीडिंग और अवधि को मापेंगे। मैंने /*real*/ डाला क्वेरी टेक्स्ट में ताकि मैं केवल इन कथनों के आंकड़े आसानी से खींच सकूं, न कि ट्रिगर्स के भीतर से कोई भी कथन, क्योंकि अंततः मेट्रिक्स ट्रिगर्स को लागू करने वाले कथनों तक रोल अप करते हैं। यह भी ध्यान दें कि मेरे द्वारा किए जा रहे वास्तविक अपडेट का वास्तव में कोई मतलब नहीं है, इसलिए इस बात पर ध्यान न दें कि मैं सर्वर/इंस्टेंस नाम और ऑब्जेक्ट के principal_id पर कॉलेशन सेट कर रहा हूं। वर्तमान सत्र के session_id . पर ।
UPDATE /*real*/ dbo.tr1 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; UPDATE /*real*/ s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID FROM dbo.src AS s INNER JOIN dbo.tr1 AS t ON s.[object_id] = t.[object_id] WHERE t.name LIKE '%s%'; GO 1000
T2:सिंगल ट्रिगर
इसके लिए हमें निम्नलिखित सरल ट्रिगर की आवश्यकता है, जो केवल dbo.src को अपडेट करता है :
CREATE TRIGGER dbo.tr_tr2
ON dbo.tr2
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = SUSER_ID()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO तब हमारे बैच को केवल प्राथमिक तालिका में दो स्तंभों को अपडेट करने की आवश्यकता होती है:
UPDATE /*real*/ dbo.tr2 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; GO 1000
T3:दोनों तालिकाओं के विरुद्ध एकल ट्रिगर
इस परीक्षण के लिए, हमारा ट्रिगर इस तरह दिखता है:
CREATE TRIGGER dbo.tr_tr3
ON dbo.tr3
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr3 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO और अब हम जिस बैच का परीक्षण कर रहे हैं, उसे केवल प्राथमिक तालिका में मूल कॉलम को अपडेट करना है; दूसरे को ट्रिगर द्वारा नियंत्रित किया जाता है:
UPDATE /*real*/ dbo.tr3 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T4:दोनों तालिकाओं के विरुद्ध एकल ट्रिगर
यह बिल्कुल T3 जैसा है, लेकिन अब ट्रिगर के चार कथन हैं:
CREATE TRIGGER dbo.tr_tr4
ON dbo.tr4
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr4 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO डाला गया परीक्षण बैच अपरिवर्तित है:
UPDATE /*real*/ dbo.tr4 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T5:दो ट्रिगर
यहां हमारे पास प्राथमिक तालिका को अपडेट करने के लिए एक ट्रिगर है, और द्वितीयक तालिका को अपडेट करने के लिए एक ट्रिगर है:
CREATE TRIGGER dbo.tr_tr5_1
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr5 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr5_2
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO परीक्षण बैच फिर से बहुत ही बुनियादी है:
UPDATE /*real*/ dbo.tr5 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T6:चार ट्रिगर
इस बार हमारे पास प्रभावित होने वाले प्रत्येक कॉलम के लिए एक ट्रिगर है; एक प्राथमिक तालिका में, और तीन माध्यमिक तालिकाओं में।
CREATE TRIGGER dbo.tr_tr6_1
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr6 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_2
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_3
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_4
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO डाला गया और परीक्षण बैच:
UPDATE /*real*/ dbo.tr6 SET name += N'' WHERE name LIKE '%s%'; GO 1000
कार्यभार के प्रभाव को मापना
अंत में, मैंने sys.dm_exec_query_stats . के विरुद्ध एक सरल क्वेरी लिखी प्रत्येक परीक्षण के लिए पठन और अवधि मापने के लिए:
SELECT [cmd] = SUBSTRING(t.text, CHARINDEX(N'U', t.text), 23), avg_elapsed_time = total_elapsed_time / execution_count * 1.0, total_logical_reads FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.text LIKE N'%UPDATE /*real*/%' ORDER BY cmd;
परिणाम
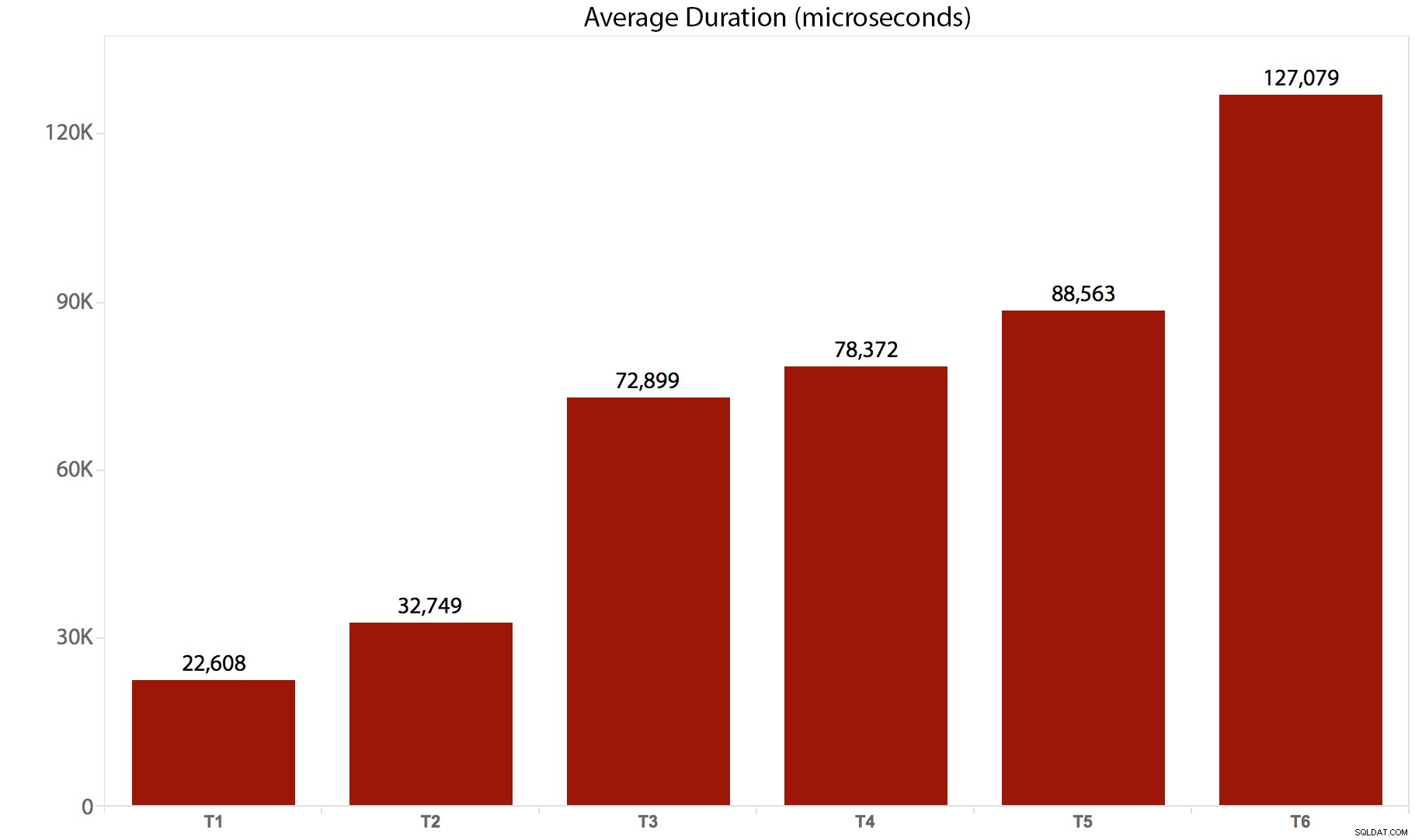
मैंने 10 बार परीक्षण चलाए, परिणाम एकत्र किए, और सब कुछ औसत किया। यहां बताया गया है कि यह कैसे टूट गया:
| परीक्षा/बैच | औसत अवधि (माइक्रोसेकंड) | कुल पढ़ा गया (8K पेज) |
|---|---|---|
| T1 :अद्यतन /*असली*/ dbo.tr1 … | 22,608 | 205,134 |
| T2 :अद्यतन /*असली*/ dbo.tr2 … | 32,749 | 11,331,628 |
| T3 :अद्यतन /*असली*/ dbo.tr3 … | 72,899 | 22,838,308 |
| T4 :अद्यतन /*असली*/ dbo.tr4 … | 78,372 | 44,463,275 |
| T5 :अद्यतन /*असली*/ dbo.tr5 … | 88,563 | 41,514,778 |
| T6 :अद्यतन /*असली*/ dbo.tr6 … | 127,079 | 100,330,753 |
और यहां अवधि का चित्रमय प्रतिनिधित्व है:
निष्कर्ष
यह स्पष्ट है कि, इस मामले में, लागू होने वाले प्रत्येक ट्रिगर के लिए कुछ पर्याप्त ओवरहेड है - इन सभी बैचों ने अंततः समान पंक्तियों को प्रभावित किया, लेकिन कुछ मामलों में एक ही पंक्तियों को कई बार छुआ गया था। जब एक ही पंक्ति को एक से अधिक बार स्पर्श नहीं किया जाता है, तो अंतर को मापने के लिए मैं शायद आगे अनुवर्ती परीक्षण करूंगा - एक अधिक जटिल स्कीमा, शायद, जहां हर बार 5 या 10 अन्य तालिकाओं को छूना पड़ता है, और ये अलग-अलग कथन हो सकते हैं एक ट्रिगर में या एकाधिक में। मेरा अनुमान है कि ओवरहेड अंतर समवर्ती जैसी चीजों और ट्रिगर के ऊपरी हिस्से की तुलना में प्रभावित पंक्तियों की संख्या से अधिक संचालित होंगे - लेकिन हम देखेंगे।
स्वयं डेमो आज़माना चाहते हैं? स्क्रिप्ट यहाँ से डाउनलोड करें।



