SQL सर्वर के प्रदर्शन के लिए जिम्मेदार होना एक कठिन काम हो सकता है। ऐसे कई क्षेत्र हैं जिन पर हमें निगरानी रखनी है और समझना है। हमसे यह भी अपेक्षा की जाती है कि हम उन सभी मेट्रिक्स में शीर्ष पर रहें और जानें कि हमारे सर्वर पर हर समय क्या हो रहा है। मैं डीबीए से पूछना चाहता हूं कि जब वे "ट्यूनिंग SQL सर्वर" वाक्यांश सुनते हैं तो वे सबसे पहले क्या सोचते हैं। मुझे जो जबरदस्त प्रतिक्रिया मिलती है वह है "क्वेरी ट्यूनिंग।" मैं मानता हूं कि प्रश्नों को समायोजित करना बहुत महत्वपूर्ण है और यह एक कभी न खत्म होने वाला कार्य है जिसका हम सामना करते हैं क्योंकि कार्यभार लगातार बदल रहा है।
हालाँकि SQL सर्वर के प्रदर्शन के बारे में सोचते समय विचार करने के लिए कई अन्य पहलू हैं। बहुत सारे उदाहरण हैं- OS- और डेटाबेस-स्तरीय सेटिंग्स जिन्हें डिफ़ॉल्ट से ट्वीक करने की आवश्यकता है। एक सलाहकार होने के नाते मुझे व्यवसाय के कई अलग-अलग क्षेत्रों में काम करने और सभी प्रकार के प्रदर्शन मुद्दों के संपर्क में आने की अनुमति मिलती है। एक नए क्लाइंट के साथ काम करते समय मैं यह जानने के लिए हमेशा सर्वर का हेल्थ ऑडिट करने की कोशिश करता हूं कि मैं किसके साथ काम कर रहा हूं। इन ऑडिटों को करते समय, एक चीज़ जो मुझे बार-बार मिली है, वह है डिस्क पर अत्यधिक पढ़ने और लिखने की विलंबता, जहाँ SQL सर्वर डेटा और लॉग फ़ाइलें रहती हैं।
विलंबता पढ़ें/लिखें
SQL सर्वर में अपनी डिस्क लेटेंसी देखने के लिए आप DMV sys.dm_io_virtual_file_stats को जल्दी और आसानी से क्वेरी कर सकते हैं . यह DMV दो पैरामीटर स्वीकार करता है:database_id और file_id . कमाल की बात यह है कि आप NULL . पास कर सकते हैं दोनों मूल्यों के रूप में और सभी डेटाबेस के लिए सभी फाइलों के लिए विलंबता लौटाएं। आउटपुट कॉलम में शामिल हैं:
- डेटाबेस_आईडी
- file_id
- नमूना_एमएस
- num_of_reads
- num_of_bytes_read
- io_stall_read_ms
- num_of_writes
- num_of_bytes_लिखित
- io_stall_write_ms
- io_stall
- size_on_disk_bytes
- file_handle
जैसा कि आप कॉलम सूची से देख सकते हैं, वास्तव में उपयोगी जानकारी है कि यह डीएमवी पुनर्प्राप्त करता है, हालांकि बस चल रहा है SELECT * FROM sys.dm_io_virtual_file_stats(NULL, NULL); जब तक आप अपने डेटाबेस_आईडी को याद नहीं कर लेते और अपने दिमाग में कुछ गणित नहीं कर लेते, तब तक यह बहुत मदद नहीं करता है।
जब मैं फ़ाइल आँकड़ों की क्वेरी करता हूँ, तो मैं पॉल रान्डल के ब्लॉग पोस्ट से एक क्वेरी का उपयोग करता हूँ, "SQL सर्वर के भीतर से IO सबसिस्टम विलंबता की जाँच कैसे करें।" यह स्क्रिप्ट कॉलम नामों को पढ़ने में आसान बनाती है, इसमें वह ड्राइव शामिल है जिस पर फ़ाइल है, डेटाबेस का नाम और फ़ाइल का पथ शामिल है।
इस डीएमवी को क्वेरी करके आप आसानी से बता सकते हैं कि आपकी फाइलों के लिए I/O हॉट स्पॉट कहां हैं। आप देख सकते हैं कि उच्चतम लिखने और पढ़ने की विलंबताएँ कहाँ हैं और कौन से डेटाबेस अपराधी हैं। इसे जानने से आप उन विशिष्ट डेटाबेस के लिए ट्यूनिंग के अवसरों को देखना शुरू कर सकेंगे। इसमें इंडेक्स ट्यूनिंग, यह देखने के लिए जांच करना शामिल हो सकता है कि बफर पूल मेमोरी दबाव में है या नहीं, संभवतः डेटाबेस को I/O सबसिस्टम के तेज़ हिस्से में ले जाना, या संभवतः डेटाबेस को विभाजित करना और अन्य LUN में फ़ाइल समूह फैलाना।
तो आप क्वेरी चलाते हैं और यह विलंबता के लिए एमएस में बहुत सारे मान देता है - कौन से मान ठीक हैं, और कौन से खराब हैं?
कौन से मान अच्छे या बुरे हैं?
यदि आप SQLskills से पूछते हैं, तो हम आपको कुछ इस प्रकार बताएंगे:
- उत्कृष्ट:<1ms
- बहुत अच्छा:<5ms
- अच्छा:5 - 10ms
- खराब:10 - 20ms
- खराब:20 - 100ms
- वास्तव में खराब:100 - 500ms
- ओएमजी!:> 500ms
यदि आप एक बिंग खोज करते हैं, तो आप माइक्रोसॉफ्ट के लेखों को इसी तरह की सिफारिशें करते हुए पाएंगे:
- अच्छा:<10ms
- ठीक है:10 - 20 मि.से.
- खराब:20 - 50 मि.से.
- गंभीर रूप से खराब:> 50 मि.से.
जैसा कि आप देख सकते हैं, संख्याओं में कुछ मामूली भिन्नताएं हैं, लेकिन आम सहमति यह है कि 20ms से अधिक कुछ भी परेशानी माना जा सकता है। कहा जा रहा है कि, आपकी औसत लेखन विलंबता 20ms हो सकती है और यह आपके संगठन के लिए 100% स्वीकार्य है और यह ठीक है। आपको अपने सिस्टम के लिए सामान्य I/O विलंबता जानने की आवश्यकता है ताकि, जब चीजें खराब हों, तो आप जान सकें कि सामान्य क्या है।
मेरे पढ़ने/लिखने की विलंबता खराब है, मैं क्या करूँ?
यदि आप पाते हैं कि आपके सर्वर पर पढ़ने और लिखने की विलंबता खराब है, तो ऐसे कई स्थान हैं जहां आप समस्याओं की तलाश शुरू कर सकते हैं। यह एक व्यापक सूची नहीं है, बल्कि कुछ मार्गदर्शन है कि कहां से शुरू करें।
- अपने कार्यभार का विश्लेषण करें। क्या आपकी अनुक्रमण रणनीति सही है? उचित अनुक्रमणिका नहीं होने से डिस्क से बहुत अधिक डेटा पढ़ा जाएगा। तलाश के बजाय स्कैन करें।
- क्या आपके आंकड़े अप टू डेट हैं? निष्पादन योजनाओं के लिए खराब विकल्प खराब आंकड़े बना सकते हैं।
- क्या आपके पास पैरामीटर सूँघने की समस्या है जो खराब निष्पादन योजनाओं का कारण बन रही है?
- क्या बफर पूल मेमोरी दबाव में है, उदाहरण के लिए फूला हुआ प्लान कैश से?
- कोई नेटवर्क समस्या? क्या आपका सैन फैब्रिक सही ढंग से प्रदर्शन कर रहा है? अपने स्टोरेज इंजीनियर से पाथिंग और नेटवर्क की पुष्टि करवाएं।
- हॉट स्पॉट को अलग-अलग स्टोरेज ऐरे में ले जाएं। कुछ मामलों में यह एक एकल डेटाबेस या केवल कुछ डेटाबेस हो सकता है जो सभी समस्याओं का कारण बन रहे हैं। उन्हें डिस्क के एक अलग सेट, या एसएसडी जैसे तेज हाई एंड डिस्क में अलग करना सबसे अच्छा तार्किक समाधान हो सकता है।
- क्या आप लोड को फैलाने के लिए परेशानी वाली तालिकाओं को अलग डिस्क पर ले जाने के लिए डेटाबेस को विभाजित कर सकते हैं?
प्रतीक्षा आंकड़े
अपने फ़ाइल आँकड़ों की निगरानी की तरह, अपने प्रतीक्षा आँकड़ों की निगरानी करना आपको अपने वातावरण में बाधाओं के बारे में बहुत कुछ बता सकता है। हम भाग्यशाली हैं कि हमारे पास एक और शानदार DMV है (sys.dm_os_wait_stats ) कि हम क्वेरी कर सकते हैं जो पिछले पुनरारंभ के बाद या पिछली बार प्रतीक्षा रीसेट होने के बाद से एकत्रित सभी उपलब्ध प्रतीक्षा जानकारी को खींच लेगा; डिस्क प्रदर्शन से संबंधित प्रतीक्षा भी हैं। यह DMV निम्नलिखित सहित महत्वपूर्ण जानकारी लौटाएगा:
- प्रतीक्षा_प्रकार
- प्रतीक्षा_कार्य_गिनती
- wait_time_ms
- max_wait_time_ms
- सिग्नल_वेट_टाइम_एमएस
मेरे SQL सर्वर 2014 मशीन पर इस DMV को क्वेरी करने से 771 प्रतीक्षा प्रकार वापस आ गए। SQL सर्वर हमेशा किसी न किसी चीज़ का इंतज़ार कर रहा होता है, लेकिन ऐसे बहुत से इंतज़ार हैं जिनसे हमें खुद की चिंता नहीं करनी चाहिए। इस कारण से, मैं पॉल रान्डल से एक अन्य प्रश्न का उपयोग करता हूं; उनकी ब्लॉग पोस्ट, "सांख्यिकी की प्रतीक्षा करें, या कृपया मुझे बताएं कि यह कहां दर्द होता है," एक उत्कृष्ट स्क्रिप्ट है जिसमें प्रतीक्षा का एक गुच्छा शामिल नहीं है जिसकी हम वास्तव में परवाह नहीं करते हैं। पॉल कई सामान्य समस्याग्रस्त प्रतीक्षाओं को सूचीबद्ध करता है और साथ ही सामान्य प्रतीक्षा के लिए मार्गदर्शन प्रदान करता है।
प्रतीक्षा आँकड़े क्यों महत्वपूर्ण हैं?
कुछ घटनाओं के लिए उच्च प्रतीक्षा समय की निगरानी आपको बताएगी कि समस्याएँ कब चल रही हैं। आपको यह जानने के लिए आधार रेखा की आवश्यकता है कि सामान्य क्या है और जब चीजें दहलीज या दर्द के स्तर से अधिक हो जाती हैं। यदि आपके पास वास्तव में उच्च PAGEIOLATCH_XX है तो आप जानते हैं कि SQL सर्वर को डिस्क से डेटा पृष्ठ को पढ़ने के लिए प्रतीक्षा करनी पड़ रही है। यह डिस्क, मेमोरी, वर्कलोड परिवर्तन या कई अन्य मुद्दे हो सकते हैं।
मैं जिस हाल के क्लाइंट के साथ काम कर रहा था, वह कुछ बहुत ही असामान्य व्यवहार देख रहा था। जब मैं डेटाबेस सर्वर से जुड़ा और एक कार्य भार के तहत सर्वर का निरीक्षण करने में सक्षम था, तो मैंने तुरंत फ़ाइल आँकड़े, प्रतीक्षा आँकड़े, स्मृति उपयोग, tempdb उपयोग, आदि की जाँच शुरू कर दी। एक चीज़ जो तुरंत सामने आई वह थी WRITELOG कोड> सबसे प्रचलित प्रतीक्षा होने के नाते। मुझे पता है कि इस प्रतीक्षा का डिस्क पर लॉग फ्लश के साथ क्या करना है और मुझे पॉल की श्रृंखला को ट्रिमिंग द ट्रांजेक्शन लॉग फैट पर याद दिलाया। उच्च WRITELOG प्रतीक्षा को आमतौर पर लेन-देन लॉग फ़ाइल के लिए उच्च-लेखन विलंबता द्वारा पहचाना जा सकता है। इसलिए मैंने डिस्क पर पढ़ने और लिखने की विलंबता की समीक्षा करने के लिए अपनी फ़ाइल आँकड़े स्क्रिप्ट का उपयोग किया। मैं तब डेटा फ़ाइल पर उच्च लेखन विलंबता देखने में सक्षम था, लेकिन मेरी लॉग फ़ाइल नहीं। WRITELOG . को देखते हुए यह एक उच्च प्रतीक्षा थी लेकिन एमएस में प्रतीक्षा करने का समय बेहद कम था। हालाँकि पॉल की श्रृंखला की दूसरी पोस्ट में कुछ अभी भी मेरे दिमाग में था। मुझे डेटाबेस के लिए ऑटो ग्रोथ सेटिंग्स को सिर्फ "एक हजार कटौती से मौत" को रद्द करने के लिए देखना चाहिए। डेटाबेस के डेटाबेस गुणों को देखते हुए मैंने देखा कि डेटा फ़ाइल को 1MB द्वारा स्वतः बढ़ने के लिए सेट किया गया था और लेन-देन लॉग को 10% तक स्वतः बढ़ने के लिए सेट किया गया था। दोनों फाइलों में लगभग 0 अप्रयुक्त स्थान था। मैंने क्लाइंट के साथ साझा किया कि मुझे क्या मिला और यह उनके प्रदर्शन को कैसे मार रहा था। हमने जल्दी से उचित परिवर्तन किया और परीक्षण आगे बढ़ा, वैसे भी बहुत बेहतर। अफसोस की बात है कि यह एकमात्र समय नहीं है जब मुझे इस सटीक मुद्दे का सामना करना पड़ा है। दूसरी बार एक डेटाबेस का आकार 66GB था, यह 1MB की वृद्धि से वहां पहुंचा।
अपना डेटा कैप्चर करना
कई डेटा पेशेवरों ने विश्लेषण के लिए नियमित आधार पर फ़ाइल कैप्चर करने और आँकड़ों की प्रतीक्षा करने के लिए प्रक्रियाएँ बनाई हैं। चूंकि प्रतीक्षा आँकड़े संचयी होते हैं, इसलिए आप उन्हें कैप्चर करना चाहते हैं और दिन के अलग-अलग समय के बीच या कुछ प्रक्रियाओं के चलने से पहले और बाद में डेल्टा की तुलना करना चाहते हैं। यह बहुत जटिल नहीं है और ऐसे कई ब्लॉग पोस्ट उपलब्ध हैं जहां लोग साझा करते हैं कि उन्होंने इसे कैसे पूरा किया। महत्वपूर्ण हिस्सा इस डेटा को मापना है ताकि आप इसकी निगरानी कर सकें। आप आज कैसे जानते हैं कि आपके डेटाबेस सर्वर पर चीजें बेहतर या बदतर हैं जब तक कि आप कल के डेटा को नहीं जानते?
SQL संतरी कैसे मदद कर सकता है?
मुझे खुशी है कि आपने पूछा! SQL संतरी प्रदर्शन सलाहकार विलंबता लाता है और डैशबोर्ड पर सामने और केंद्र में प्रतीक्षा करता है। किसी भी विसंगति को पहचानना आसान है; आप ऐतिहासिक मोड पर स्विच कर सकते हैं और पिछली प्रवृत्ति देख सकते हैं और इसकी तुलना पिछली अवधियों से भी कर सकते हैं। "क्या हुआ?" का विश्लेषण करते समय यह अमूल्य साबित हो सकता है। क्षण। सभी को वह कॉल प्राप्त हुई है, "कल अपराह्न लगभग 3:00 बजे सिस्टम जम गया था, क्या आप हमें बता सकते हैं कि क्या हुआ?" उम, निश्चित रूप से, मुझे प्रोफाइलर को ऊपर खींचने दें और समय पर वापस जाएं। यदि आपके पास प्रदर्शन सलाहकार जैसा कोई निगरानी उपकरण है, तो आपके पास वह ऐतिहासिक जानकारी आपकी उंगलियों पर होगी।
डैशबोर्ड पर चार्ट और ग्राफ़ के अलावा, आपके पास हाई डिस्क वेट्स, हाई वीएलएफ काउंट्स, हाई सीपीयू, लो पेज लाइफ एक्सपेक्टेंसी, और कई अन्य स्थितियों के लिए बिल्ट-इन अलर्ट का उपयोग करने की क्षमता है। आपके पास अपनी स्वयं की कस्टम स्थितियां बनाने की क्षमता भी है, और आप SQL संतरी साइट पर या कंडीशन एक्सचेंज के माध्यम से उदाहरणों से सीख सकते हैं (हारून बर्ट्रेंड ने इस बारे में ब्लॉग किया है)। मैंने SQL सर्वर एजेंट अलर्ट पर अपने पिछले लेख में इसके चेतावनी पक्ष को छुआ था।
प्रदर्शन सलाहकार के डिस्क स्पेस टैब पर, ऑटोग्रोथ सेटिंग्स और उच्च वीएलएफ गणना जैसी चीजों को देखना बहुत आसान है। आपको पता होना चाहिए, लेकिन यदि आप ऐसा नहीं करते हैं, तो 1MB या 10% तक ऑटोग्रोथ सबसे अच्छी सेटिंग नहीं है। यदि आप इन मूल्यों को देखते हैं (प्रदर्शन सलाहकार उन्हें आपके लिए हाइलाइट करता है), तो आप जल्दी से नोट कर सकते हैं और उचित समायोजन करने के लिए समय निर्धारित कर सकते हैं। मुझे यह पसंद है कि यह कुल वीएलएफ कैसे प्रदर्शित करता है; बहुत सारे वीएलएफ बहुत समस्याग्रस्त हो सकते हैं। आपको किम्बर्ली की पोस्ट पढ़नी चाहिए "लेन-देन लॉग वीएलएफ - बहुत अधिक या बहुत कम?" यदि आपने पहले से नहीं किया है।
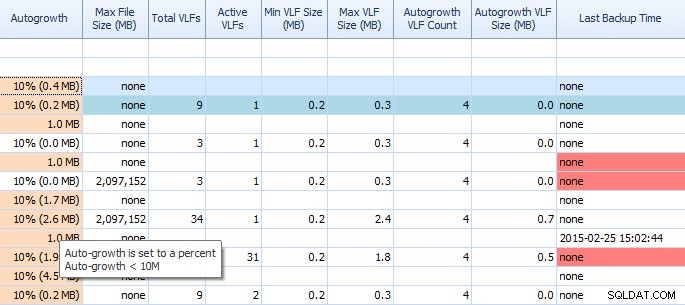 प्रदर्शन सलाहकार के डिस्क स्थान टैब पर आंशिक ग्रिड
प्रदर्शन सलाहकार के डिस्क स्थान टैब पर आंशिक ग्रिड
एक और तरीका है कि प्रदर्शन सलाहकार मदद कर सकता है इसके पेटेंट डिस्क गतिविधि मॉड्यूल के माध्यम से। यहाँ आप देख सकते हैं कि F:पर tempdb पर्याप्त लेखन विलंबता का अनुभव कर रहा है; आप इसे डिस्क ग्राफ़िक्स के नीचे मोटी लाल रेखाओं द्वारा बता सकते हैं। आप यह भी देख सकते हैं कि F:एकमात्र ड्राइव अक्षर है जिसकी डिस्क को लाल रंग में दर्शाया गया है; यह एक दृश्य संकेत है कि ड्राइव में गलत संरेखित विभाजन है, जो I/O समस्याओं में योगदान कर सकता है।
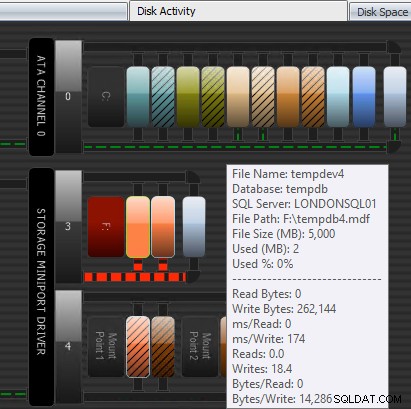 प्रदर्शन सलाहकार डिस्क गतिविधि मॉड्यूल
प्रदर्शन सलाहकार डिस्क गतिविधि मॉड्यूल
और आप नीचे दी गई ग्रिड में इस जानकारी को सहसंबंधित कर सकते हैं - वहां भी ग्रिड में समस्याओं को हाइलाइट किया जाता है, और ms/Write पर एक नज़र डालें कॉलम:
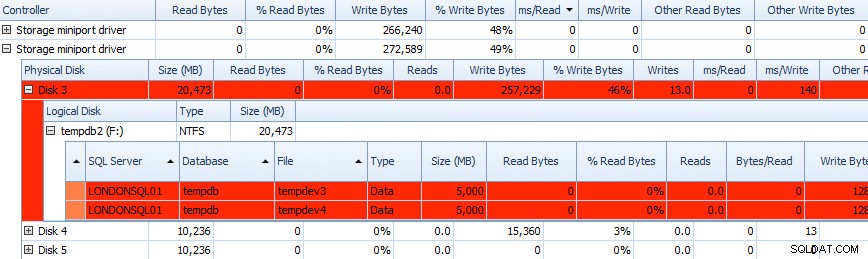 प्रदर्शन सलाहकार डिस्क गतिविधि डेटा का आंशिक ग्रिड
प्रदर्शन सलाहकार डिस्क गतिविधि डेटा का आंशिक ग्रिड
आप इस जानकारी को पूर्वव्यापी रूप से भी देख सकते हैं; अगर कोई कल दोपहर या पिछले मंगलवार को डिस्क की कथित अड़चन के बारे में शिकायत करता है, तो आप टूलबार में डेट पिकर का उपयोग करके वापस जा सकते हैं और किसी भी श्रेणी के लिए औसत थ्रूपुट और विलंबता देख सकते हैं। डिस्क गतिविधि मॉड्यूल के बारे में अधिक जानकारी के लिए, उपयोगकर्ता मार्गदर्शिका देखें।
परफॉर्मेंस एडवाइजर के पास परफॉर्मेंस, ब्लॉकिंग, टॉप एसक्यूएल, डिस्क/फाइल स्पेस और डेडलॉक कैटेगरी के तहत बहुत सारी बिल्ट-इन रिपोर्ट्स हैं। नीचे दिया गया चित्र आपको दिखाता है कि डिस्क/फ़ाइल स्थान रिपोर्ट कैसे प्राप्त करें। केवल कुछ माउस क्लिक दूर रिपोर्ट्स का होना बहुत मूल्यवान है, ताकि आप तुरंत पता लगा सकें और देख सकें कि आपके सर्वर पर क्या हो रहा है (या था)।
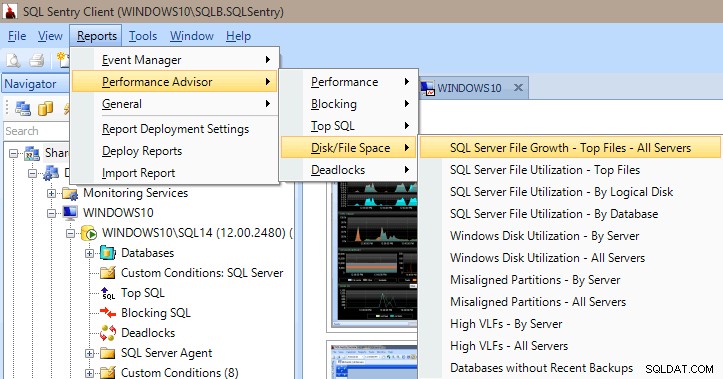 प्रदर्शन सलाहकार रिपोर्ट
प्रदर्शन सलाहकार रिपोर्ट
सारांश
इस पोस्ट से महत्वपूर्ण निष्कर्ष अपने प्रदर्शन मेट्रिक्स को जानना है। डेटा पेशेवरों के बीच एक सामान्य कथन यह है कि डिस्क हमारी #1 अड़चन है। आपके सर्वर के फ़ाइल आँकड़ों को जानने से आपके सर्वर पर दर्द बिंदुओं को समझने में मदद मिलेगी। फ़ाइल आँकड़ों के संयोजन के साथ, आपके प्रतीक्षा आँकड़े भी देखने के लिए एक बेहतरीन जगह हैं। मेरे सहित कई लोग वहां से शुरू करते हैं। SQL संतरी प्रदर्शन सलाहकार जैसे उपकरण होने से आपको बहुत अधिक समस्या होने से पहले समस्या निवारण और प्रदर्शन समस्याओं का पता लगाने में काफी मदद मिल सकती है; हालांकि, अगर आपके पास ऐसा कोई टूल नहीं है, तो sys.dm_os_wait_stats से परिचित हो जाएं। और sys.dm_io_virtual_file_stats आपके सर्वर को ट्यून करना शुरू करने के लिए आपकी अच्छी सेवा करेगा।