पिछले कुछ वर्षों में मेरे द्वारा सामना की गई हर गणना कॉलम से संबंधित प्रदर्शन समस्या में निम्नलिखित मूल कारणों में से एक (या अधिक) रहा है:
- कार्यान्वयन सीमाएं
- क्वेरी अनुकूलक में लागत मॉडल समर्थन की कमी
- ऑप्टिमाइज़ेशन शुरू होने से पहले परिकलित स्तंभ परिभाषा विस्तार
कार्यान्वयन सीमा . का एक उदाहरण गणना किए गए कॉलम पर फ़िल्टर किए गए इंडेक्स को बनाने में सक्षम नहीं है (यहां तक कि जारी रहने पर भी)। इस समस्या श्रेणी के बारे में हम बहुत कुछ नहीं कर सकते हैं; जब तक हम उत्पाद सुधारों के आने की प्रतीक्षा करते हैं, तब तक हमें वर्कअराउंड का उपयोग करना होगा।
अनुकूलक की कमी लागत मॉडल समर्थन इसका मतलब है कि SQL सर्वर जटिलता या कार्यान्वयन की परवाह किए बिना स्केलर गणनाओं के लिए एक छोटी निश्चित लागत प्रदान करता है। एक परिणाम के रूप में, सर्वर अक्सर स्थायी या अनुक्रमित मान को सीधे पढ़ने के बजाय संग्रहीत गणना किए गए कॉलम मान को फिर से गणना करने का निर्णय लेता है। यह विशेष रूप से दर्दनाक होता है जब गणना की गई अभिव्यक्ति महंगी होती है, उदाहरण के लिए जब इसमें स्केलर उपयोगकर्ता-परिभाषित फ़ंक्शन को कॉल करना शामिल होता है।
परिभाषा विस्तार के आसपास की समस्याएं थोड़े अधिक शामिल हैं, और उनके व्यापक प्रभाव हैं।
गणना कॉलम विस्तार की समस्याएं
क्वेरी सामान्यीकरण के बाध्यकारी चरण के दौरान SQL सर्वर सामान्य रूप से गणना किए गए कॉलम को उनकी अंतर्निहित परिभाषाओं में विस्तारित करता है। यह क्वेरी संकलन प्रक्रिया में एक बहुत ही प्रारंभिक चरण है, किसी भी योजना चयन निर्णय लेने से पहले (तुच्छ योजना सहित)।
सिद्धांत रूप में, प्रारंभिक विस्तार करने से वे अनुकूलन सक्षम हो सकते हैं जो अन्यथा छूट जाते हैं। उदाहरण के लिए, ऑप्टिमाइज़र क्वेरी और मेटाडेटा (जैसे बाधाओं) में अन्य जानकारी दिए गए सरलीकरण को लागू करने में सक्षम हो सकता है। यह उसी प्रकार का तर्क है जो देखने की परिभाषाओं को विस्तारित करने की ओर ले जाता है (जब तक कि NOEXPAND संकेत का उपयोग किया जाता है)।
बाद में संकलन प्रक्रिया में (लेकिन अभी भी एक तुच्छ योजना पर विचार करने से पहले), ऑप्टिमाइज़र निरंतर या अनुक्रमित गणना वाले स्तंभों के लिए अभिव्यक्ति का मिलान करना चाहता है। समस्या यह है कि इस दौरान अनुकूलक गतिविधियों ने विस्तारित अभिव्यक्तियों को इस तरह बदल दिया है कि वापस मिलान करना अब संभव नहीं है।
जब ऐसा होता है, तो अंतिम निष्पादन योजना ऐसी दिखती है जैसे ऑप्टिमाइज़र ने एक स्थायी या अनुक्रमित गणना कॉलम का उपयोग करने के लिए "स्पष्ट" अवसर खो दिया है। निष्पादन योजनाओं में कुछ विवरण हैं जो कारण निर्धारित करने में मदद कर सकते हैं, जिससे यह डिबग और ठीक करने के लिए संभावित रूप से निराशाजनक समस्या बन जाती है।
अभिव्यक्तियों का संगणित स्तंभों से मिलान करना
यह विशेष रूप से स्पष्ट है कि यहां दो अलग-अलग प्रक्रियाएं हैं:
- गणना किए गए स्तंभों का प्रारंभिक विस्तार; और
- बाद में कंप्यूटेड कॉलम से एक्सप्रेशन का मिलान करने का प्रयास किया गया।
विशेष रूप से, ध्यान दें कि किसी भी क्वेरी एक्सप्रेशन का बाद में एक उपयुक्त कंप्यूटेड कॉलम से मिलान किया जा सकता है, न कि केवल कंप्यूटेड कॉलम के विस्तार से उत्पन्न होने वाले एक्सप्रेशन से।
कंप्यूटेड कॉलम एक्सप्रेशन मैचिंग योजना में सुधार को सक्षम कर सकता है, तब भी जब मूल क्वेरी के टेक्स्ट को संशोधित नहीं किया जा सकता है। उदाहरण के लिए, किसी ज्ञात क्वेरी एक्सप्रेशन से मिलान करने के लिए एक कंप्यूटेड कॉलम बनाना ऑप्टिमाइज़र को कंप्यूटेड कॉलम से जुड़े आंकड़ों और इंडेक्स का उपयोग करने की अनुमति देता है। यह सुविधा अवधारणात्मक रूप से एंटरप्राइज़ संस्करण में अनुक्रमित दृश्य मिलान के समान है। परिकलित स्तंभ मिलान सभी संस्करणों में कार्यात्मक है।
व्यावहारिक दृष्टिकोण से, मेरा अपना अनुभव रहा है कि गणना किए गए कॉलम में सामान्य क्वेरी अभिव्यक्तियों का मिलान वास्तव में प्रदर्शन, दक्षता और निष्पादन योजना स्थिरता को लाभ पहुंचा सकता है। दूसरी ओर, मैंने शायद ही कभी (यदि कभी हो) गणना की गई कॉलम विस्तार को सार्थक पाया है। ऐसा लगता है कि यह कभी भी कोई उपयोगी अनुकूलन नहीं देता है।
गणना कॉलम उपयोग
परिकलित स्तंभ जो न तो . हैं निरंतर और न ही अनुक्रमित के वैध उपयोग हैं। उदाहरण के लिए, यदि कॉलम नियतात्मक और सटीक है (कोई फ़्लोटिंग पॉइंट तत्व नहीं) तो वे स्वचालित आंकड़ों का समर्थन कर सकते हैं। उनका उपयोग भंडारण स्थान को बचाने के लिए भी किया जा सकता है (थोड़ा अतिरिक्त रनटाइम प्रोसेसर उपयोग की कीमत पर)। अंतिम उदाहरण के रूप में, वे यह सुनिश्चित करने के लिए एक साफ तरीका प्रदान कर सकते हैं कि हर बार प्रश्नों में स्पष्ट रूप से लिखे जाने के बजाय एक साधारण गणना हमेशा सही ढंग से की जाती है।
लगातार गणना किए गए कॉलम उत्पाद में विशेष रूप से नियतात्मक लेकिन "अशुद्ध" (फ़्लोटिंग पॉइंट) कॉलम पर इंडेक्स बनाने की अनुमति देने के लिए जोड़े गए थे। मेरे अनुभव में, यह इच्छित उपयोग अपेक्षाकृत दुर्लभ है। शायद यह केवल इसलिए है क्योंकि मुझे फ़्लोटिंग पॉइंट डेटा का बहुत अधिक सामना नहीं करना पड़ता है।
फ़्लोटिंग पॉइंट इंडेक्स एक तरफ, लगातार कॉलम बहुत आम हैं। कुछ हद तक, ऐसा इसलिए हो सकता है क्योंकि अनुभवहीन उपयोगकर्ता यह मानते हैं कि एक गणना किए गए कॉलम को अनुक्रमित करने से पहले हमेशा कायम रहना चाहिए। अधिक अनुभवी उपयोगकर्ता स्थायी कॉलम को केवल इसलिए नियोजित कर सकते हैं क्योंकि उन्होंने पाया है कि प्रदर्शन उस तरह से बेहतर होता है।
अनुक्रमित गणना किए गए कॉलम (जारी रहे या नहीं) का उपयोग ऑर्डरिंग और एक कुशल एक्सेस विधि प्रदान करने के लिए किया जा सकता है। किसी परिकलित मान को आधार तालिका में बनाए बिना किसी अनुक्रमणिका में संग्रहीत करना उपयोगी हो सकता है। समान रूप से, उपयुक्त परिकलित स्तंभ भी प्रमुख स्तंभ होने के बजाय अनुक्रमणिका में शामिल किए जा सकते हैं।
खराब प्रदर्शन
खराब प्रदर्शन का एक प्रमुख कारण अपेक्षित रूप से अनुक्रमित या निरंतर गणना किए गए कॉलम मान का उपयोग करने में एक साधारण विफलता है। मैंने उन प्रश्नों की संख्या खो दी है जो मैंने वर्षों से पूछे हैं कि क्यों अनुकूलक एक भयानक निष्पादन योजना का चयन करेगा जब एक अनुक्रमित या निरंतर गणना कॉलम का उपयोग करने वाली स्पष्ट रूप से बेहतर योजना मौजूद है।
प्रत्येक मामले में सटीक कारण भिन्न होता है, लेकिन लगभग हमेशा एक दोषपूर्ण लागत-आधारित निर्णय होता है (क्योंकि स्केलर को कम निश्चित लागत सौंपी जाती है); या किसी विस्तारित एक्सप्रेशन का किसी स्थायी गणना किए गए कॉलम या इंडेक्स से मिलान करने में विफलता।
मैच-बैक विफलताएं मेरे लिए विशेष रूप से दिलचस्प हैं, क्योंकि उनमें अक्सर ऑर्थोगोनल इंजन सुविधाओं के साथ जटिल इंटरैक्शन शामिल होते हैं। समान रूप से अक्सर, "वापस मिलान" करने में विफलता आंतरिक क्वेरी ट्री की स्थिति में एक अभिव्यक्ति (स्तंभ के बजाय) छोड़ती है जो एक महत्वपूर्ण अनुकूलन नियम को मिलान से रोकती है। किसी भी मामले में, परिणाम समान है:एक उप-इष्टतम निष्पादन योजना।
अब, मुझे लगता है कि यह कहना उचित है कि लोग आम तौर पर एक गणना कॉलम को इंडेक्स करते हैं या मजबूत उम्मीद के साथ जारी रखते हैं कि संग्रहीत मूल्य वास्तव में उपयोग किया जाएगा। जानबूझकर प्रदान किए गए संग्रहीत मूल्य को अनदेखा करते हुए, एसक्यूएल सर्वर को हर बार अंतर्निहित अभिव्यक्ति को पुन:गणना करने के लिए यह काफी सदमे के रूप में आ सकता है। लोग हमेशा आंतरिक बातचीत और लागत मॉडल की कमियों में बहुत रुचि नहीं रखते हैं जिसके कारण अवांछनीय परिणाम सामने आए। यहां तक कि जहां कामकाज मौजूद हैं, उन्हें खोजने और परीक्षण करने के लिए समय, कौशल और प्रयास की आवश्यकता होती है।
संक्षेप में:बहुत से लोग लगातार या अनुक्रमित मान का उपयोग करने के लिए SQL सर्वर को पसंद करेंगे। हमेशा।
एक नया विकल्प
ऐतिहासिक रूप से, SQL सर्वर को हमेशा संग्रहीत मान का उपयोग करने के लिए बाध्य करने का कोई तरीका नहीं रहा है (NOEXPAND के बराबर नहीं) विचारों के लिए संकेत)। ऐसी कुछ परिस्थितियां हैं जिनमें एक योजना मार्गदर्शिका काम करेगी, लेकिन पहली जगह में आवश्यक योजना आकार बनाना हमेशा संभव नहीं होता है, और सभी योजना तत्वों और पदों को मजबूर नहीं किया जा सकता है (उदाहरण के लिए स्केलर को फ़िल्टर और गणना करें)।
अभी भी कोई साफ-सुथरा, पूरी तरह से प्रलेखित समाधान नहीं है, लेकिन SQL सर्वर 2016 के हालिया अपडेट ने एक दिलचस्प नया दृष्टिकोण प्रदान किया है। यह SQL सर्वर 2016 इंस्टेंस पर लागू होता है जिसमें SQL Server 2016 SP1 के लिए कम से कम संचयी अद्यतन 2 या SQL Server 2016 RTM के लिए संचयी अद्यतन 4 के साथ पैच किया गया है।
प्रासंगिक अद्यतन में प्रलेखित है:FIX:SQL सर्वर 2016 में एक परिकलित विभाजन स्तंभ वाली तालिका के लिए ऑनलाइन विभाजन को फिर से बनाने में असमर्थ
जैसा कि अक्सर समर्थन दस्तावेज़ीकरण के साथ होता है, यह ठीक से यह नहीं बताता है कि समस्या को हल करने के लिए इंजन में क्या बदलाव किया गया है। शीर्षक और विवरण के आधार पर यह निश्चित रूप से हमारी वर्तमान चिंताओं के लिए बहुत प्रासंगिक नहीं लगता है। फिर भी, यह सुधार एक नया समर्थित ट्रेस ध्वज पेश करता है 176 , जिसे FDontExpandPersistedCC . नामक कोड विधि में चेक किया जाता है . जैसा कि विधि के नाम से पता चलता है, यह एक निरंतर गणना किए गए कॉलम को विस्तारित होने से रोकता है।
इसमें तीन महत्वपूर्ण चेतावनी हैं:
- गणना कॉलम निरंतर होना चाहिए . अनुक्रमित होने पर भी, कॉलम को भी कायम रहना चाहिए।
- सामान्य क्वेरी अभिव्यक्तियों से लगातार गणना किए गए कॉलम से मिलान करें अक्षम ।
- दस्तावेज ट्रेस फ्लैग के कार्य का वर्णन नहीं करता है, और इसे किसी अन्य उपयोग के लिए निर्धारित नहीं करता है। यदि आप लगातार गणना किए गए स्तंभों के विस्तार को रोकने के लिए ट्रेस फ़्लैग 176 का उपयोग करना चुनते हैं, तो यह आपके अपने जोखिम पर होगा।
यह ट्रेस फ्लैग एक स्टार्ट-अप के रूप में प्रभावी है –T विकल्प, वैश्विक और सत्र दोनों दायरे में DBCC TRACEON . का उपयोग करके , और प्रति क्वेरी OPTION (QUERYTRACEON) . के साथ ।
उदाहरण
यह एक प्रश्न का सरलीकृत संस्करण है (वास्तविक दुनिया की समस्या पर आधारित) जिसका उत्तर मैंने कुछ साल पहले डेटाबेस एडमिनिस्ट्रेटर स्टैक एक्सचेंज पर दिया था। तालिका परिभाषा में एक स्थायी गणना कॉलम शामिल है:
CREATE TABLE dbo.T
(
ID integer IDENTITY NOT NULL,
A varchar(20) NOT NULL,
B varchar(20) NOT NULL,
C varchar(20) NOT NULL,
D date NULL,
Computed AS A + '-' + B + '-' + C PERSISTED,
CONSTRAINT PK_T_ID
PRIMARY KEY CLUSTERED (ID),
);
GO
INSERT dbo.T WITH (TABLOCKX)
(A, B, C, D)
SELECT
A = STR(SV.number % 10, 2),
B = STR(SV.number % 20, 2),
C = STR(SV.number % 30, 2),
D = DATEADD(DAY, 0 - SV.number, SYSUTCDATETIME())
FROM master.dbo.spt_values AS SV
WHERE SV.[type] = N'P'; नीचे दी गई क्वेरी तालिका से सभी पंक्तियों को एक विशेष क्रम में लौटाती है, साथ ही कॉलम डी के अगले मान को उसी क्रम में लौटाती है:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
(
SELECT TOP (1)
t2.D
FROM dbo.T AS T2
WHERE
T2.Computed = T1.Computed
AND T2.D > T1.D
ORDER BY
T2.D ASC
)
FROM dbo.T AS T1
ORDER BY
T1.Computed, T1.D; उप-क्वेरी में अंतिम ऑर्डरिंग और लुकअप का समर्थन करने के लिए एक स्पष्ट कवरिंग इंडेक्स है:
CREATE UNIQUE NONCLUSTERED INDEX IX_T_Computed_D_ID ON dbo.T (Computed, D, ID);
अनुकूलक द्वारा दी गई निष्पादन योजना आश्चर्यजनक और निराशाजनक है:
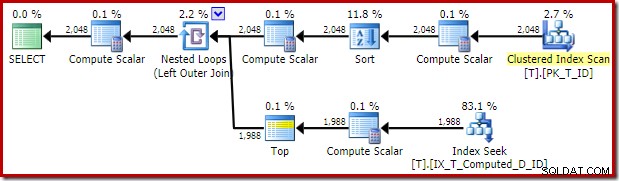
नेस्टेड लूप्स जॉइन के अंदरूनी हिस्से पर इंडेक्स सीक सब अच्छा लगता है। हालाँकि, बाहरी इनपुट पर क्लस्टर्ड इंडेक्स स्कैन और सॉर्ट अप्रत्याशित है। हम इसके बजाय अपने कवर किए गए गैर-संकुलित अनुक्रमणिका का एक आदेशित स्कैन देखने की आशा करते।
हम ऑप्टिमाइज़र को तालिका संकेत के साथ गैर-संकुल अनुक्रमणिका का उपयोग करने के लिए बाध्य कर सकते हैं:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
(
SELECT TOP (1)
t2.D
FROM dbo.T AS T2
WHERE
T2.Computed = T1.Computed
AND T2.D > T1.D
ORDER BY
T2.D ASC
)
FROM dbo.T AS T1
WITH (INDEX(IX_T_Computed_D_ID)) -- New!
ORDER BY
T1.Computed, T1.D; परिणामी निष्पादन योजना है:
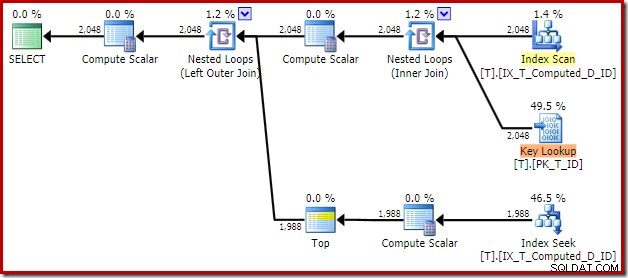
गैर-क्लस्टर किए गए इंडेक्स को स्कैन करने से सॉर्ट हटा दिया जाता है, लेकिन एक कुंजी लुकअप जोड़ता है! इस नई योजना में लुकअप आश्चर्यजनक है, यह देखते हुए कि हमारी अनुक्रमणिका निश्चित रूप से क्वेरी के लिए आवश्यक सभी कॉलम शामिल करती है।
की लुकअप ऑपरेटर के गुणों को देखते हुए:
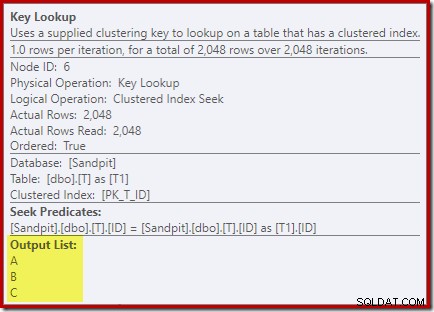
किसी कारण से, ऑप्टिमाइज़र ने निर्णय लिया है कि क्वेरी में उल्लिखित तीन स्तंभों को आधार तालिका से प्राप्त करने की आवश्यकता नहीं है (क्योंकि वे डिज़ाइन द्वारा हमारे गैर-संकुलित अनुक्रमणिका में मौजूद नहीं हैं)।
निष्पादन योजना के चारों ओर देखते हुए, हम पाते हैं कि इनर साइड इंडेक्स सीक द्वारा लुक-अप कॉलम की आवश्यकता होती है:

इस खोज विधेय का पहला भाग सहसंबंध T2.Computed = T1.Computed से मेल खाता है मूल क्वेरी में। ऑप्टिमाइज़र ने दोनों परिकलित स्तंभों की परिभाषाओं का विस्तार किया है, लेकिन केवल आंतरिक पक्ष के उपनाम T1 के लिए स्थायी और अनुक्रमित गणना किए गए कॉलम से मिलान करने में कामयाब रहा है। . T2 को छोड़कर संदर्भ के विस्तार के परिणामस्वरूप शामिल होने के बाहरी हिस्से को आधार तालिका कॉलम प्रदान करने की आवश्यकता होती है (A , B , और C ) प्रत्येक पंक्ति के लिए उस व्यंजक की गणना करने के लिए आवश्यक है।
जैसा कि कभी-कभी होता है, इस क्वेरी को फिर से लिखना संभव है ताकि समस्या दूर हो जाए (एक विकल्प स्टैक एक्सचेंज प्रश्न के मेरे पुराने उत्तर में दिखाया गया है)। SQL सर्वर 2016 का उपयोग करके, हम गणना किए गए कॉलम को विस्तारित होने से रोकने के लिए ट्रेस फ़्लैग 176 को भी आज़मा सकते हैं:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
(
SELECT TOP (1)
t2.D
FROM dbo.T AS T2
WHERE
T2.Computed = T1.Computed
AND T2.D > T1.D
ORDER BY
T2.D ASC
)
FROM dbo.T AS T1
ORDER BY
T1.Computed, T1.D
OPTION (QUERYTRACEON 176); -- New! निष्पादन योजना में अब काफी सुधार हुआ है:
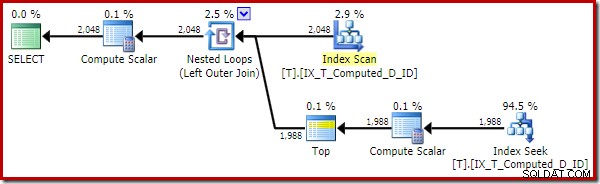
इस निष्पादन योजना में केवल गणना किए गए कॉलम के संदर्भ हैं। कंप्यूट स्केलर्स कुछ भी उपयोगी नहीं करते हैं और अगर ऑप्टिमाइज़र घर के आसपास थोड़ा सा साफ होता तो साफ हो जाता।
महत्वपूर्ण बिंदु यह है कि इष्टतम सूचकांक अब सही ढंग से उपयोग किया जाता है, और सॉर्ट और की लुकअप को समाप्त कर दिया गया है। SQL सर्वर को कुछ ऐसा करने से रोककर, जिसकी हमने पहले कभी उम्मीद नहीं की होगी (एक निरंतर और अनुक्रमित गणना कॉलम का विस्तार)।
लीड का उपयोग करना
मूल स्टैक एक्सचेंज प्रश्न को SQL Server 2008 पर लक्षित किया गया था, जहां LEAD उपलब्ध नहीं है। आइए नए सिंटैक्स का उपयोग करके SQL सर्वर 2016 पर आवश्यकता व्यक्त करने का प्रयास करें:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
LEAD(T1.D) OVER (
PARTITION BY T1.Computed
ORDER BY T1.D)
FROM dbo.T AS T1
ORDER BY
T1.Computed; SQL सर्वर 2016 निष्पादन योजना है:
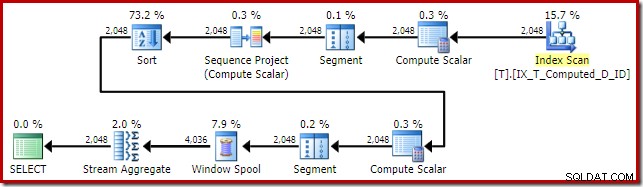
यह योजना आकार एक साधारण पंक्ति मोड विंडो फ़ंक्शन के लिए काफी विशिष्ट है। एक अनपेक्षित आइटम बीच में सॉर्ट ऑपरेटर है। यदि डेटा सेट बड़ा होता, तो यह सॉर्ट प्रदर्शन और मेमोरी उपयोग पर बड़ा प्रभाव डाल सकता था।
मुद्दा, एक बार फिर, गणना कॉलम विस्तार है। इस मामले में, विस्तारित अभिव्यक्तियों में से एक ऐसी स्थिति में बैठता है जो सामान्य अनुकूलक तर्क को सॉर्ट अवे को सरल बनाने से रोकता है।
ट्रेस फ़्लैग 176 के साथ ठीक उसी क्वेरी का प्रयास कर रहा है:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
LEAD(T1.D) OVER (
PARTITION BY T1.Computed
ORDER BY T1.D)
FROM dbo.T AS T1
ORDER BY
T1.Computed
OPTION (QUERYTRACEON 176); योजना तैयार करता है:
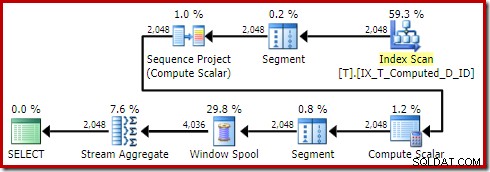
सॉर्ट गायब हो गया है जैसा इसे करना चाहिए। यह भी ध्यान दें कि यह प्रश्न लागत-आधारित अनुकूलन से पूरी तरह से बचते हुए, एक तुच्छ योजना के लिए योग्य है।
अक्षम सामान्य अभिव्यक्ति मिलान
पहले बताई गई चेतावनियों में से एक यह थी कि ट्रेस फ़्लैग 176 भी स्रोत क्वेरी में एक्सप्रेशन से लगातार गणना किए गए कॉलम से मेल खाने को अक्षम करता है।
उदाहरण के लिए, उदाहरण क्वेरी के निम्न संस्करण पर विचार करें। LEAD गणना हटा दी गई है, और SELECT . में परिकलित कॉलम के संदर्भ और ORDER BY उपवाक्यों को अंतर्निहित भावों से बदल दिया गया है। ट्रेस फ्लैग के बिना इसे पहले चलाएं 176:
SELECT
T1.ID,
Computed = T1.A + '-' + T1.B + '-' + T1.C,
T1.D
FROM dbo.T AS T1
ORDER BY
T1.A + '-' + T1.B + '-' + T1.C; एक्सप्रेशन्स का मिलान लगातार कंप्यूटेड कॉलम से किया जाता है, और निष्पादन योजना गैर-क्लस्टर इंडेक्स का एक सरल ऑर्डर किया गया स्कैन है:
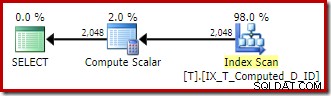
कंप्यूट स्केलर वहाँ एक बार फिर बस बचा हुआ वास्तु कबाड़ है।
अब उसी क्वेरी को ट्रेस फ़्लैग 176 सक्षम के साथ आज़माएँ:
SELECT
T1.ID,
Computed = T1.A + '-' + T1.B + '-' + T1.C,
T1.D
FROM dbo.T AS T1
ORDER BY
T1.A + '-' + T1.B + '-' + T1.C
OPTION (QUERYTRACEON 176); -- New! नई निष्पादन योजना है:
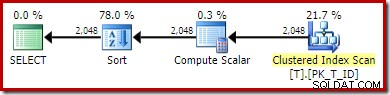
गैर संकुल सूचकांक स्कैन को संकुल सूचकांक स्कैन से बदल दिया गया है। गणना स्केलर अभिव्यक्ति का मूल्यांकन करता है, और परिणाम के आधार पर क्रमबद्ध करें। लगातार गणना किए गए स्तंभों के लिए भावों का मिलान करने की क्षमता से वंचित, अनुकूलक स्थायी मूल्य, या गैर-संकुल सूचकांक का उपयोग नहीं कर सकता है।
ध्यान दें कि अभिव्यक्ति मिलान सीमा केवल निरंतर . पर लागू होती है ट्रेस फ्लैग 176 सक्रिय होने पर परिकलित कॉलम। यदि हम गणना किए गए कॉलम को अनुक्रमित करते हैं लेकिन कायम नहीं रहते हैं, तो अभिव्यक्ति मिलान सही ढंग से काम करता है।
निरंतर विशेषता को छोड़ने के लिए, हमें पहले गैर-संकुल सूचकांक को छोड़ना होगा। एक बार परिवर्तन करने के बाद हम सूचकांक को सीधे वापस रख सकते हैं (क्योंकि व्यंजक नियतात्मक और सटीक है):
DROP INDEX IX_T_Computed_D_ID ON dbo.T; GO ALTER TABLE dbo.T ALTER COLUMN Computed DROP PERSISTED; GO CREATE UNIQUE NONCLUSTERED INDEX IX_T_Computed_D_ID ON dbo.T (Computed, D, ID);
ट्रेस फ़्लैग 176 के सक्रिय होने पर ऑप्टिमाइज़र को अब क्वेरी एक्सप्रेशन को परिकलित कॉलम से मिलान करने में कोई समस्या नहीं है:
-- Computed column no longer persisted
-- but still indexed. TF 176 active.
SELECT
T1.ID,
Computed = T1.A + '-' + T1.B + '-' + T1.C,
T1.D
FROM dbo.T AS T1
ORDER BY
T1.A + '-' + T1.B + '-' + T1.C
OPTION (QUERYTRACEON 176); निष्पादन योजना बिना किसी प्रकार के इष्टतम गैर-संकुल सूचकांक स्कैन पर वापस आती है:
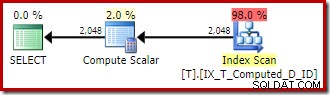
संक्षेप में:ट्रेस ध्वज 176 लगातार गणना किए गए कॉलम विस्तार को रोकता है। एक साइड-इफ़ेक्ट के रूप में, यह क्वेरी एक्सप्रेशन को केवल लगातार गणना किए गए कॉलम से मेल खाने से रोकता है।
बाध्यकारी चरण के दौरान स्कीमा मेटाडेटा केवल एक बार लोड किया जाता है। ट्रेस ध्वज 176 विस्तार को रोकता है इसलिए परिकलित स्तंभ परिभाषा उस समय लोड नहीं होती है। बाद में एक्सप्रेशन-टू-कॉलम मिलान गणना की गई कॉलम परिभाषा के विरुद्ध मिलान किए बिना काम नहीं कर सकता।
प्रारंभिक मेटाडेटा लोड सभी स्तंभों में लाता है, न कि केवल क्वेरी में संदर्भित (कि अनुकूलन बाद में किया जाता है)। यह सभी गणना किए गए कॉलम मिलान के लिए उपलब्ध कराता है, जो आम तौर पर एक अच्छी बात है। दुर्भाग्य से, यदि लोड किए गए कंप्यूटेड कॉलम में से एक में स्केलर उपयोगकर्ता-परिभाषित फ़ंक्शन होता है, तो इसकी उपस्थिति पूरी क्वेरी के लिए समांतरता को अक्षम कर देती है, भले ही समस्याग्रस्त कॉलम का उपयोग न किया गया हो। यदि विचाराधीन कॉलम बना रहता है, तो ट्रेस फ्लैग 176 भी इसमें मदद कर सकता है। परिभाषा को लोड न करने से, एक अदिश उपयोगकर्ता-परिभाषित फ़ंक्शन कभी मौजूद नहीं होता है, इसलिए समांतरता अक्षम नहीं होती है।
अंतिम विचार
मुझे ऐसा लगता है कि SQL सर्वर की दुनिया एक बेहतर जगह हो सकती है यदि ऑप्टिमाइज़र नियमित कॉलम की तरह लगातार या अनुक्रमित गणना वाले कॉलम का इलाज करता है। लगभग सभी उदाहरणों में, यह मौजूदा व्यवस्था की तुलना में डेवलपर की अपेक्षाओं से बेहतर मेल खाएगा। गणना किए गए स्तंभों को उनके अंतर्निहित भावों में विस्तारित करना और बाद में उनका मिलान करने का प्रयास करना व्यवहार में उतना सफल नहीं है जितना कि सिद्धांत सुझाव दे सकता है।
जब तक SQL सर्वर निरंतर या अनुक्रमित कंप्यूटेड कॉलम विस्तार को रोकने के लिए विशिष्ट समर्थन प्रदान नहीं करता है, तब तक नया ट्रेस फ्लैग 176 SQL सर्वर 2016 उपयोगकर्ताओं के लिए एक आकर्षक विकल्प है, भले ही यह अपूर्ण हो। यह थोड़ा दुर्भाग्यपूर्ण है कि यह सामान्य अभिव्यक्ति मिलान को साइड इफेक्ट के रूप में अक्षम कर देता है। यह भी शर्म की बात है कि अनुक्रमित होने पर गणना किए गए कॉलम को जारी रखना पड़ता है। इसके बाद इसके प्रलेखित उद्देश्य के अलावा अन्य के लिए ट्रेस ध्वज का उपयोग करने का जोखिम है।
यह कहना उचित है कि परिकलित कॉलम प्रश्नों के साथ अधिकांश समस्याओं को अंततः अन्य तरीकों से हल किया जा सकता है, बशर्ते पर्याप्त समय, प्रयास और विशेषज्ञता हो। दूसरी ओर, ट्रेस फ्लैग 176 अक्सर जादू की तरह काम करता प्रतीत होता है। चुनाव, जैसा कि वे कहते हैं, आपका है।
समाप्त करने के लिए, यहां कुछ दिलचस्प गणना की गई कॉलम समस्याएं हैं जो ट्रेस फ्लैग 176 से लाभान्वित होती हैं:
- गणना किए गए कॉलम इंडेक्स का उपयोग नहीं किया गया
- विंडोिंग फ़ंक्शन विभाजन में उपयोग नहीं किए गए परसिस्टेड परिकलित कॉलम
- स्कैन करने वाला लगातार परिकलित कॉलम
- कंप्यूटेड कॉलम इंडेक्स MAX डेटा प्रकारों के साथ उपयोग नहीं किया जाता है
- स्थायी गणना वाले कॉलम और जॉइन के साथ गंभीर प्रदर्शन समस्या
- जब मैं एक स्थायी गणना कॉलम का चयन करता हूं तो SQL सर्वर "गणना स्केलर" क्यों करता है?
- इंजन द्वारा लगातार गणना किए गए कॉलम के बजाय उपयोग किए जाने वाले बेस कॉलम
- यूडीएफ के साथ परिकलित कॉलम *अन्य* कॉलम पर प्रश्नों के लिए समानता को अक्षम करता है