PostgreSQL Streaming Replication PostgreSQL क्लस्टर को स्केल करने का एक शानदार तरीका है और ऐसा करने से उनमें उच्च उपलब्धता जुड़ जाती है। जैसा कि हर प्रतिकृति के साथ होता है, विचार यह है कि दास मास्टर की एक प्रति है और यह कि दास को किसी प्रकार की प्रतिकृति तंत्र का उपयोग करके मास्टर पर होने वाले परिवर्तनों के साथ लगातार अद्यतन किया जाता है।
ऐसा हो सकता है कि दास, किसी कारणवश, स्वामी के साथ तालमेल बिठा लेता है। मैं इसे प्रतिकृति श्रृंखला में वापस कैसे ला सकता हूं? मैं यह कैसे सुनिश्चित कर सकता हूं कि दास फिर से गुरु के साथ तालमेल बिठा रहा है? आइए इस संक्षिप्त ब्लॉग पोस्ट पर एक नज़र डालते हैं।
क्या बहुत उपयोगी है, यदि दास पुनर्प्राप्ति मोड में है तो उस पर लिखने का कोई तरीका नहीं है। आप इसका परीक्षण इस तरह कर सकते हैं:
postgres=# SELECT pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
postgres=# CREATE DATABASE mydb;
ERROR: cannot execute CREATE DATABASE in a read-only transactionअभी भी ऐसा हो सकता है कि दास स्वामी के साथ तालमेल बिठाएगा। डेटा भ्रष्टाचार - न तो हार्डवेयर या सॉफ्टवेयर बग और मुद्दों के बिना है। डिस्क ड्राइव के साथ कुछ समस्याएं दास पर डेटा भ्रष्टाचार को ट्रिगर कर सकती हैं। "वैक्यूम" प्रक्रिया में कुछ समस्याओं के परिणामस्वरूप डेटा में परिवर्तन हो सकता है। उस अवस्था से कैसे उबरें?
pg_basebackup का उपयोग करके दास का पुनर्निर्माण करना
मुख्य चरण मास्टर से डेटा का उपयोग करके दास को प्रावधान करना है। यह देखते हुए कि हम स्ट्रीमिंग प्रतिकृति का उपयोग करेंगे, हम तार्किक बैकअप का उपयोग नहीं कर सकते। सौभाग्य से एक तैयार उपकरण है जिसका उपयोग चीजों को सेट करने के लिए किया जा सकता है:pg_basebackup। आइए देखें कि स्लेव सर्वर को प्रोविजन करने के लिए हमें क्या कदम उठाने होंगे। इसे स्पष्ट करने के लिए, हम इस ब्लॉग पोस्ट के लिए PostgreSQL 12 का उपयोग कर रहे हैं।
प्रारंभिक अवस्था सरल है। हमारा गुलाम अपने मालिक से नकल नहीं कर रहा है। इसमें शामिल डेटा दूषित है और इसका उपयोग नहीं किया जा सकता है और न ही उस पर भरोसा किया जा सकता है। इसलिए पहला कदम जो हम करेंगे वह यह होगा कि हम अपने दास पर PostgreSQL को रोकें और उसमें मौजूद डेटा को हटा दें:
example@sqldat.com:~# systemctl stop postgresqlया यहां तक कि:
example@sqldat.com:~# killall -9 postgresअब, postgresql.auto.conf फ़ाइल की सामग्री की जांच करते हैं, हम बाद में उस फ़ाइल में संग्रहीत प्रतिकृति क्रेडेंशियल का उपयोग pg_basebackup के लिए कर सकते हैं:
example@sqldat.com:~# cat /var/lib/postgresql/12/main/postgresql.auto.conf
# Do not edit this file manually!
# It will be overwritten by the ALTER SYSTEM command.
promote_trigger_file='/tmp/failover_5432.trigger'
recovery_target_timeline=latest
primary_conninfo='application_name=pgsql_0_node_1 host=10.0.0.126 port=5432 user=cmon_replication password=qZnVoV7LV97CFX9F'हम प्रतिकृति सेट करने के लिए उपयोग किए जाने वाले उपयोगकर्ता और पासवर्ड में रुचि रखते हैं।
आखिरकार हम डेटा निकालने के लिए तैयार हैं:
example@sqldat.com:~# rm -rf /var/lib/postgresql/12/main/*डेटा हटा दिए जाने के बाद, हमें मास्टर से डेटा प्राप्त करने के लिए pg_basebackup का उपयोग करना होगा:
example@sqldat.com:~# pg_basebackup -h 10.0.0.126 -U cmon_replication -Xs -P -R -D /var/lib/postgresql/12/main/
Password:
waiting for checkpointजिन झंडों का हमने उपयोग किया है उनके निम्नलिखित अर्थ हैं:
- -Xs: हम बैकअप बनाते समय WAL को स्ट्रीम करना चाहेंगे। जब आपके पास एक बड़ा डेटासेट होता है तो यह WAL फ़ाइलों को निकालने में आने वाली समस्याओं से बचने में मदद करता है।
- -P: हम बैकअप की प्रगति देखना चाहते हैं।
- -R: हम चाहते हैं कि pg_basebackup स्टैंडबाय.सिग्नल फ़ाइल बनाए और कनेक्शन सेटिंग्स के साथ postgresql.auto.conf फ़ाइल तैयार करे।
pg_basebackup बैकअप शुरू करने से पहले चेकपॉइंट की प्रतीक्षा करेगा। यदि इसमें बहुत अधिक समय लगता है, तो आप दो विकल्पों का उपयोग कर सकते हैं। सबसे पहले, '-c फास्ट' विकल्प का उपयोग करके pg_basebackup में चेकपॉइंट मोड को फास्ट पर सेट करना संभव है। वैकल्पिक रूप से, आप चेकपॉइंटिंग को क्रियान्वित करके बाध्य कर सकते हैं:
postgres=# CHECKPOINT;
CHECKPOINTकिसी न किसी रूप में, pg_basebackup प्रारंभ हो जाएगा। -P ध्वज के साथ हम प्रगति को ट्रैक कर सकते हैं:
416906/1588478 kB (26%), 0/1 tablespaceceaceबैकअप तैयार हो जाने के बाद, हमें केवल यह सुनिश्चित करना है कि डेटा निर्देशिका सामग्री में सही उपयोगकर्ता और समूह असाइन किया गया है - हमने pg_basebackup को 'रूट' के रूप में निष्पादित किया है इसलिए हम इसे 'पोस्टग्रेज़' में बदलना चाहते हैं ':
example@sqldat.com:~# chown -R postgres.postgres /var/lib/postgresql/12/main/बस इतना ही, हम गुलाम को शुरू कर सकते हैं और इसे मास्टर से दोहराना शुरू करना चाहिए।
example@sqldat.com:~# systemctl start postgresqlआप मास्टर पर निम्नलिखित क्वेरी निष्पादित करके प्रतिकृति प्रगति की दोबारा जांच कर सकते हैं:
postgres=# SELECT * FROM pg_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state | reply_time
-------+----------+------------------+------------------+-------------+-----------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------+-----------+------------+---------------+------------+-------------------------------
23565 | 16385 | cmon_replication | pgsql_0_node_1 | 10.0.0.128 | | 51554 | 2020-02-27 15:25:00.002734+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:32.594213+00
11914 | 16385 | cmon_replication | 12/main | 10.0.0.127 | | 25058 | 2020-02-28 13:42:09.160576+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:42.41722+00
(2 rows)जैसा कि आप देख सकते हैं, दोनों दास सही ढंग से नकल कर रहे हैं।
ClusterControl का उपयोग करके दास का पुनर्निर्माण
यदि आप एक ClusterControl उपयोगकर्ता हैं तो आप UI से कोई विकल्प चुनकर आसानी से ठीक वैसा ही प्राप्त कर सकते हैं।
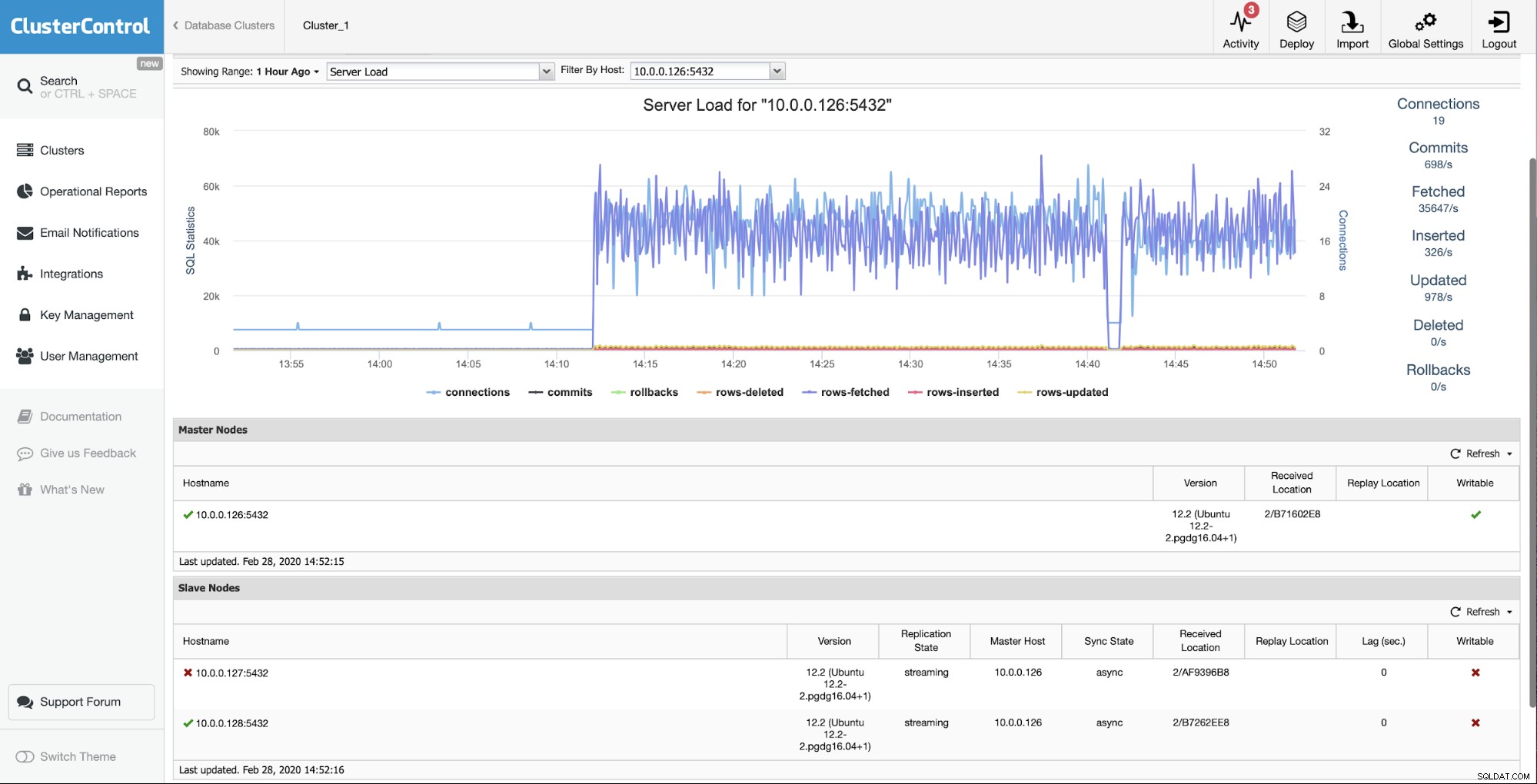
प्रारंभिक स्थिति यह है कि दासों में से एक (10.0.0.127) है काम नहीं कर रहा है और यह नकल नहीं कर रहा है। हमने माना कि पुनर्निर्माण हमारे लिए सबसे अच्छा विकल्प है।
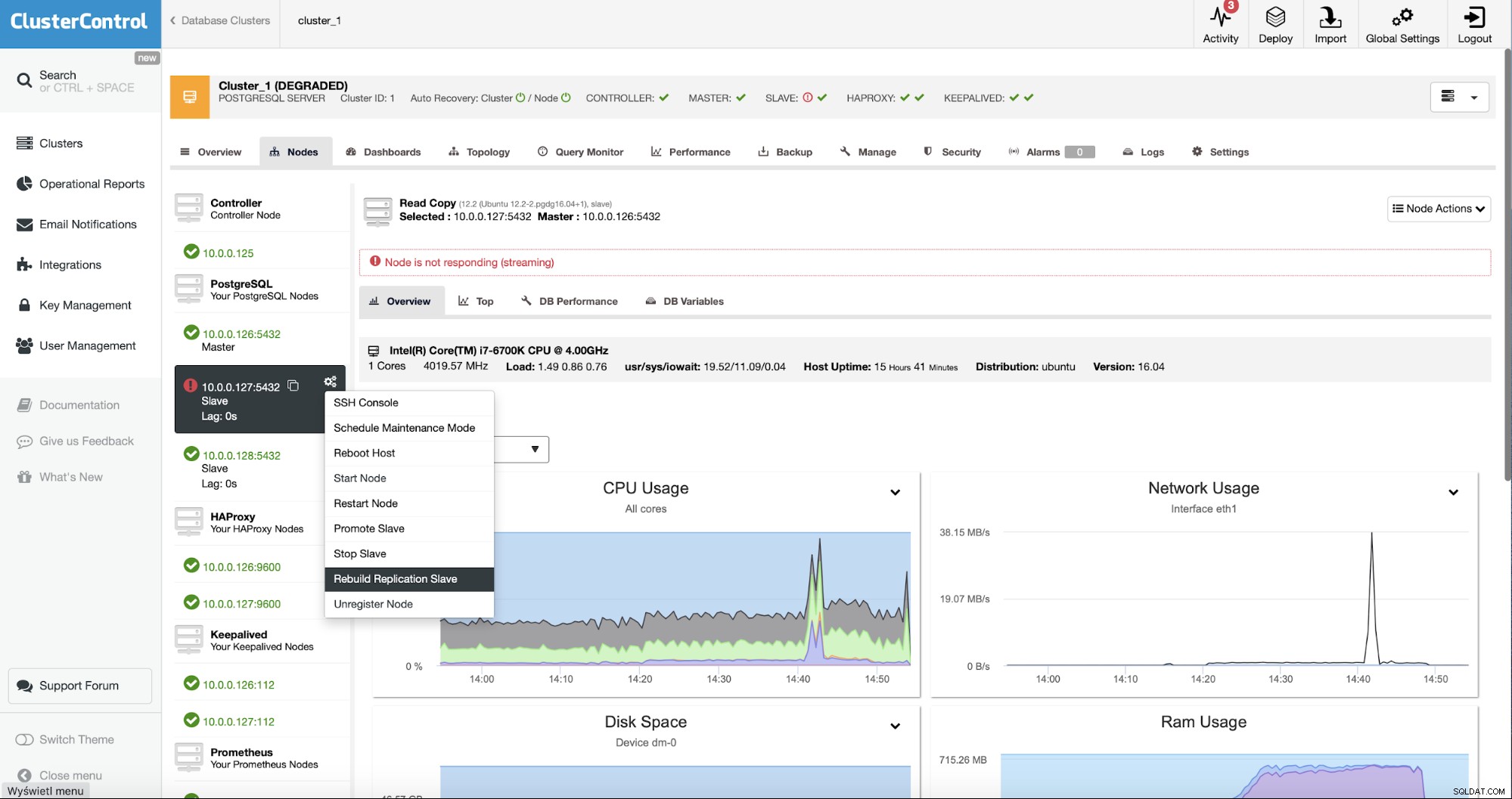
क्लस्टरकंट्रोल के उपयोगकर्ताओं के रूप में हमें केवल "नोड्स" पर जाना है। "टैब करें और "रिबिल्ड रेप्लिकेशन स्लेव" जॉब चलाएं।
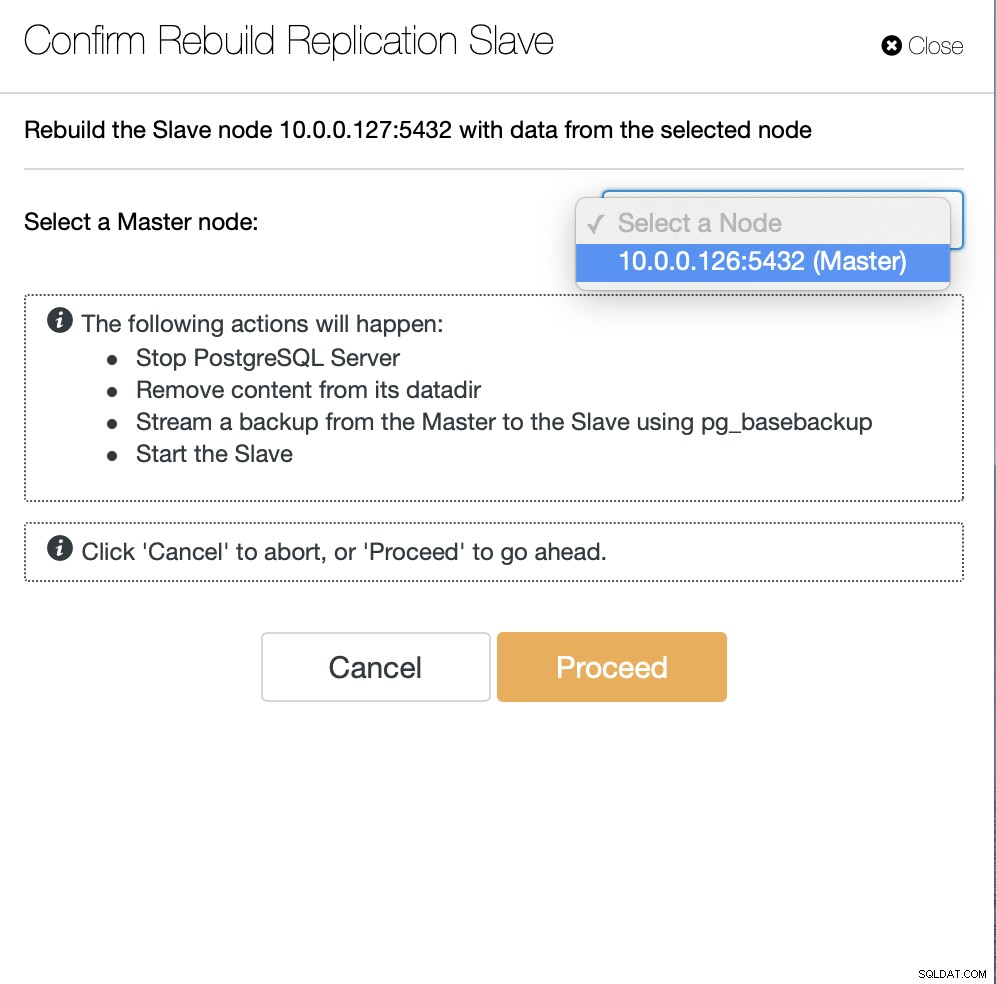
अगला, हमें दास के पुनर्निर्माण के लिए नोड चुनना होगा और वह है सब। ClusterControl प्रतिकृति स्लेव को सेट करने के लिए pg_basebackup का उपयोग करेगा और डेटा स्थानांतरित होते ही प्रतिकृति को कॉन्फ़िगर करेगा।
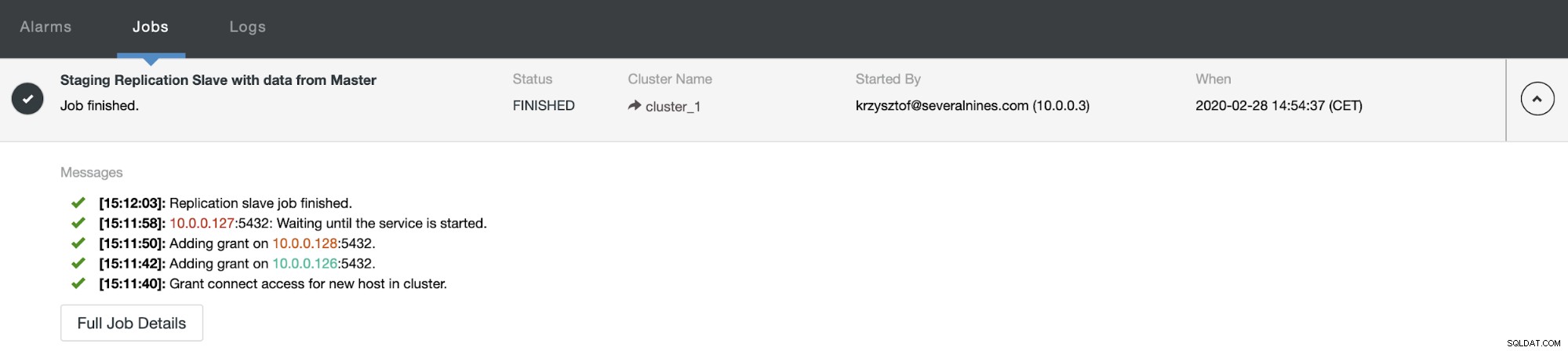
कुछ समय बाद काम पूरा हो जाता है और दास प्रतिकृति श्रृंखला में वापस आ जाता है:
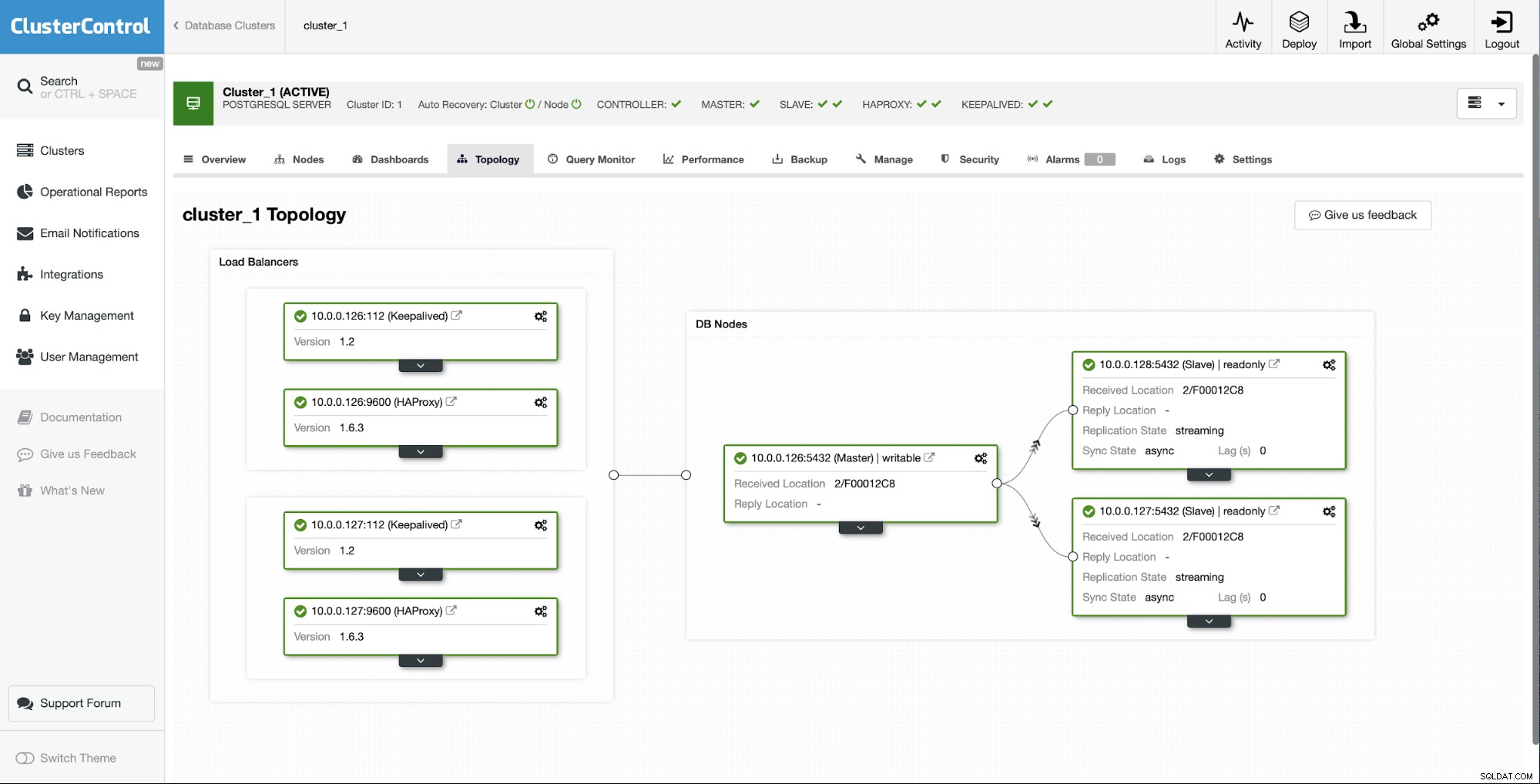
जैसा कि आप देख सकते हैं, बस कुछ ही क्लिक के साथ, ClusterControl के लिए धन्यवाद, हम अपने असफल स्लेव को फिर से बनाने और उसे क्लस्टर में वापस लाने में कामयाब रहे।