उत्तर निश्चित रूप से "यह निर्भर करता है" लेकिन इस अंत के परीक्षण के आधार पर होगा...
मान लीजिए
- 1 मिलियन उत्पाद
productproduct_id. पर एक संकुल अनुक्रमणिका है- अधिकांश (यदि सभी नहीं) उत्पादों की संबंधित जानकारी
product_code. में होती है टेबल - आदर्श अनुक्रमणिका
product_codeपर मौजूद हैं दोनों प्रश्नों के लिए।
PIVOT संस्करण को आदर्श रूप से एक अनुक्रमणिका की आवश्यकता होती है product_code(product_id, type) INCLUDE (code) जबकि JOIN संस्करण को आदर्श रूप से एक अनुक्रमणिका की आवश्यकता होती है product_code(type,product_id) INCLUDE (code)
अगर ये नीचे दिए गए प्लान दे रहे हैं
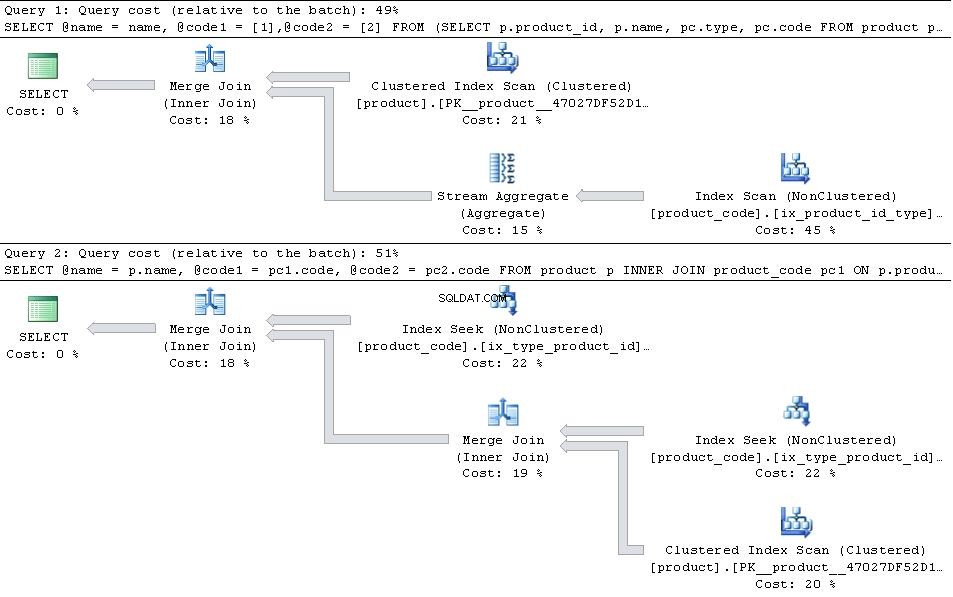
फिर JOIN संस्करण अधिक कुशल है।
इस मामले में कि type 1 और type 2 केवल types हैं तालिका में फिर PIVOT संस्करण में पढ़ने की संख्या के मामले में थोड़ा बढ़त है क्योंकि इसमें product_code की तलाश नहीं है दो बार लेकिन यह स्ट्रीम एग्रीगेट ऑपरेटर के अतिरिक्त ओवरहेड से अधिक है
पिवट
Table 'product_code'. Scan count 1, logical reads 10467
Table 'product'. Scan count 1, logical reads 4750
CPU time = 3297 ms, elapsed time = 3260 ms.
शामिल हों
Table 'product_code'. Scan count 2, logical reads 10471
Table 'product'. Scan count 1, logical reads 4750
CPU time = 1906 ms, elapsed time = 1866 ms.
यदि अतिरिक्त types हैं तो 1 . के अलावा अन्य रिकॉर्ड और 2 JOIN version इसके लाभ को बढ़ाएगा क्योंकि यह type,product_id के प्रासंगिक अनुभागों में सिर्फ मर्ज जॉइन करता है अनुक्रमणिका जबकि PIVOT योजना product_id, type . का उपयोग करती है और इसलिए अतिरिक्त types . पर स्कैन करना होगा पंक्तियाँ जो 1 . के साथ मिश्रित हैं और 2 पंक्तियाँ।