यह पोस्ट Oracle SQL ट्यूटोरियल का हिस्सा है और हम उदाहरणों, विस्तृत विवरण के साथ oracle (ओवर बाय पार्टीशन) में विश्लेषणात्मक कार्यों पर चर्चा करेंगे।
हम पहले ही Oracle एग्रीगेट फंक्शन जैसे avg, sum, count के बारे में पढ़ चुके हैं। आइए एक उदाहरण लेते हैं
सबसे पहले नमूना डेटा बनाते हैं
CREATE TABLE "DEPT"
( "DEPTNO" NUMBER(2,0),
"DNAME" VARCHAR2(14),
"LOC" VARCHAR2(13),
CONSTRAINT "PK_DEPT" PRIMARY KEY ("DEPTNO")
)
CREATE TABLE "EMP"
( "EMPNO" NUMBER(4,0),
"ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9),
"MGR" NUMBER(4,0),
"HIREDATE" DATE,
"SAL" NUMBER(7,2),
"COMM" NUMBER(7,2),
"DEPTNO" NUMBER(2,0),
CONSTRAINT "PK_EMP" PRIMARY KEY ("EMPNO"),
CONSTRAINT "FK_DEPTNO" FOREIGN KEY ("DEPTNO")
REFERENCES "DEPT" ("DEPTNO") ENABLE
);
SQL> desc emp
Name Null? Type
---- ---- -----
EMPNO NOT NULL NUMBER(4)
ENAME VARCHAR2(10)
JOB VARCHAR2(9)
MGR NUMBER(4)
HIREDATE DATE
SAL NUMBER(7,2)
COMM NUMBER(7,2)
DEPTNO NUMBER(2)
SQL> desc dept
Name Null? Type
---- ----- ----
DEPTNO NOT NULL NUMBER(2)
DNAME VARCHAR2(14)
LOC VARCHAR2(13)
insert into DEPT values(10, 'ACCOUNTING', 'NEW YORK');
insert into dept values(20, 'RESEARCH', 'DALLAS');
insert into dept values(30, 'RESEARCH', 'DELHI');
insert into dept values(40, 'RESEARCH', 'MUMBAI');
commit;
insert into emp values( 7839, 'Allen', 'MANAGER', 7839, to_date('17-11-1981','dd-mm-yyyy'), 20, null, 10 );
insert into emp values( 7782, 'CLARK', 'MANAGER', 7839, to_date('9-06-1981','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7934, 'MILLER', 'MANAGER', 7839, to_date('23-01-1982','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7788, 'SMITH', 'ANALYST', 7788, to_date('17-12-1980','dd-mm-yyyy'), 800, null, 20 );
insert into emp values( 7902, 'ADAM, 'ANALYST', 7832, to_date('23-05-1987','dd-mm-yyyy'), 1100, null, 20 );
insert into emp values( 7876, 'FORD', 'ANALYST', 7566, to_date('3-12-1981','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7369, 'SCOTT', 'ANALYST', 7566, to_date('19-04-1987','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7698, 'JAMES', 'ANALYST', 7788, to_date('03-12-1981','dd-mm-yyyy'), 950, null, 30 );
insert into emp values( 7499, 'MARTIN', 'ANALYST', 7698, to_date('28-09-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7844, 'WARD', 'ANALYST', 7698, to_date('22-02-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7654, 'TURNER', 'ANALYST', 7698, to_date('08-09-1981','dd-mm-yyyy'), 1500, null, 30 );
insert into emp values( 7521, 'ALLEN', 'ANALYST', 7698, to_date('20-02-1981','dd-mm-yyyy'), 1600, null, 30 );
insert into emp values( 7900, 'BLAKE', 'ANALYST', 77698, to_date('01-05-1981','dd-mm-yyyy'), 2850, null, 30 );
commit;
अब समग्र कार्यों का उदाहरण नीचे दिया जाएगा
select count(*) from EMP; --------- 13 select sum (bytes) from dba_segments where tablespace_name='TOOLS'; ----- 100 SQL> select deptno ,count(*) from emp group by deptno; DEPTNO COUNT(*) ---------- ---------- 30 6 20 4 10 3
यहां हम देख सकते हैं कि यह प्रत्येक प्रश्न में पंक्तियों की संख्या को कम करता है। अब सवाल आता है कि अगर हमें गिनती (*) के साथ सभी पंक्तियों को वापस करने की ज़रूरत है तो क्या करना चाहिए
इसके लिए ओरेकल ने विश्लेषणात्मक कार्यों का एक सेट प्रदान किया है। तो आखिरी समस्या को हल करने के लिए, हम इस रूप में लिख सकते हैं
select empno ,deptno , count(*) over (partition by deptno) from emp group by deptno;
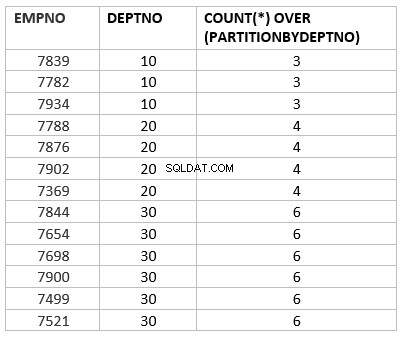
यहां काउंट (*) ओवर (डिप्टीशन बाय डिपार्टमेंट) काउंट एग्रीगेट फंक्शन का एनालिटिकल वर्जन है। मुख्य कुंजी कार्य जो समग्र कार्य से भिन्न होता है, वह है
विश्लेषणात्मक कार्य पंक्तियों के समूह के आधार पर कुल मूल्य की गणना करते हैं। वे कुल कार्यों से भिन्न होते हैं जिसमें वे प्रत्येक समूह के लिए कई पंक्तियाँ लौटाते हैं। पंक्तियों के समूह को विंडो कहा जाता है और इसे analytic_clause द्वारा परिभाषित किया जाता है।
यहाँ सामान्य वाक्य रचना है
analytic_function([ arguments ]) OVER ([ query_partition_clause ] [ order_by_clause [ windowing_clause ] ])
उदाहरण
count(*) over (partition by deptno) avg(Sal) over (partition by deptno)
आइए प्रत्येक भाग को देखें
query_partition_clause
यह पंक्तियों के समूह को परिभाषित करता है। इसे नीचे पसंद किया जा सकता है
विभाग द्वारा विभाजन:समान विभाग की पंक्तियों का समूह
या
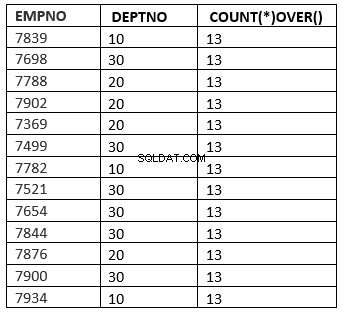
() :सभी पंक्तियाँ
SQL> select empno ,deptno , count(*) over () from emp;
[order_by_clause [windowing_clause] ]
इस खंड का उपयोग तब किया जाता है जब आप विभाजन में पंक्तियों को क्रमित करना चाहते हैं। यह विशेष रूप से उपयोगी है यदि आप चाहते हैं कि विश्लेषणात्मक कार्य पंक्तियों के क्रम पर विचार करें।
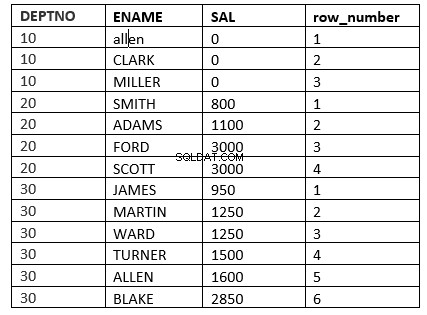
उदाहरण होगा row_number फ़ंक्शन
SQL> select deptno, ename, sal, row_number() over (partition by deptno order by sal) "row_number" from emp;
एक और उदाहरण होगा
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
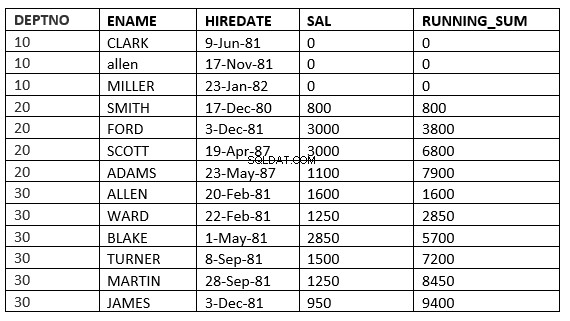
विंडोिंग_क्लॉज
यह हमेशा खंड दर क्रम के साथ प्रयोग किया जाता है और समूह में पंक्तियों के सेट पर अधिक नियंत्रण देता है
विंडिंग क्लॉज के साथ, प्रत्येक पंक्ति के लिए, पंक्तियों की एक स्लाइडिंग विंडो परिभाषित की जाती है। विंडो वर्तमान पंक्ति के लिए गणना करने के लिए उपयोग की जाने वाली पंक्तियों की श्रेणी निर्धारित करती है। विंडो का आकार या तो पंक्तियों की भौतिक संख्या या समय जैसे तार्किक अंतराल पर आधारित हो सकता है।
क्लॉज द्वारा ऑर्डर का उपयोग करते समय और windowing_clause के लिए कुछ भी नहीं दिया जाता है, windowing_clause के डिफ़ॉल्ट मान से नीचे लिया जाता है
अनबाउंडेड प्रीसीडिंग और करंट रो या RANGE अनबाउंडेड प्रीसीडिंग के बीच की रेंज
इसका अर्थ है "वर्तमान में वर्तमान और पिछली पंक्तियाँ विभाजन वे पंक्तियाँ हैं जिनका उपयोग गणना में किया जाना चाहिए”
नीचे दिया गया उदाहरण स्पष्ट रूप से यह बताता है। यह विभाग में औसत चल रहा है
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
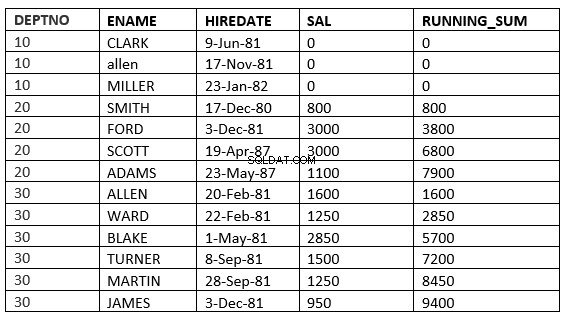
अब windowing_clause को कई तरीकों से परिभाषित किया जा सकता है
आइए पहले शब्दावली को समझें
पंक्तियां विंडो को भौतिक इकाइयों (पंक्तियों) में निर्दिष्ट करता है।
RANGE विंडो को तार्किक ऑफसेट के रूप में निर्दिष्ट करता है। RANGE विंडोिंग क्लॉज़ का उपयोग केवल ORDER BY क्लॉज़ के साथ किया जा सकता है जिसमें संख्यात्मक या दिनांक डेटाटाइप के कॉलम या एक्सप्रेशन शामिल हैं
PRECEDING - वर्तमान पंक्ति से पहले पंक्तियाँ प्राप्त करें।
अनुसरण करें - वर्तमान पंक्ति के बाद पंक्तियाँ प्राप्त करें।
अनबाउंडेड - जब PRECEDING या FOLLOWING के साथ उपयोग किया जाता है, तो यह पहले या बाद में वापस आ जाता है। वर्तमान पंक्ति
तो इसे आम तौर पर
. के रूप में परिभाषित किया जाता हैपंक्तियां असीमित पूर्ववर्ती :वर्तमान विभाजन में वर्तमान और पिछली पंक्तियाँ वे पंक्तियाँ हैं जिनका उपयोग गणना में किया जाना चाहिए
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS UNBOUNDED PRECEDING) running_sum from emp;
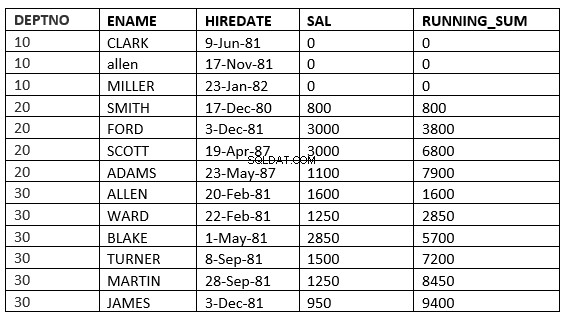
अनबाउंड प्रीसीडिंग रेंज करें :वर्तमान विभाजन में वर्तमान और पिछली पंक्तियाँ वे पंक्तियाँ हैं जिनका उपयोग गणना में किया जाना चाहिए। इसके अलावा चूंकि सीमा निर्दिष्ट है, यह सभी उन मानों को लेता है जो वर्तमान पंक्तियों के बराबर हैं।
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE UNBOUNDED PRECEDING) running_sum from emp;
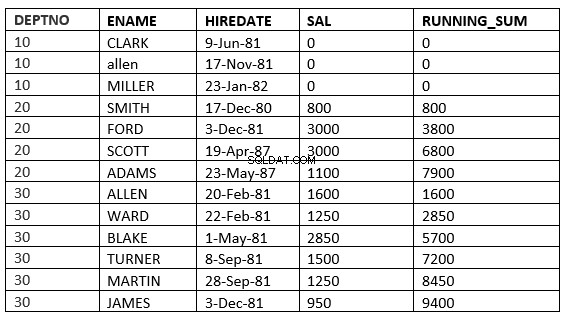
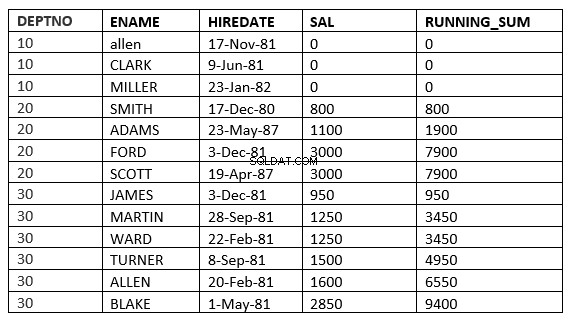
हो सकता है कि आपको श्रेणी और पंक्तियों के बीच अंतर दिखाई न दे क्योंकि सभी के लिए किराया_तिथि अलग है। अंतर और अधिक स्पष्ट हो जाएगा यदि हम खंड द्वारा आदेश के रूप में सैल का उपयोग करते हैं
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal RANGE UNBOUNDED PRECEDING) running_sum from emp;
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal ROWS UNBOUNDED PRECEDING) running_sum from emp;
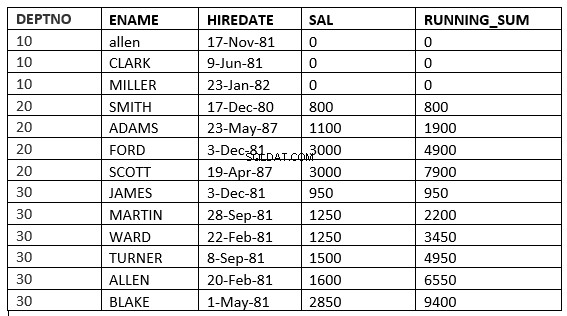
आप लाइन 6 पर अंतर पा सकते हैं
RANGE value_expr PRECEDING :विंडो उस पंक्ति से शुरू होती है जिसका ORDER BY मान संख्यात्मक अभिव्यक्ति पंक्तियाँ हैं, जो वर्तमान पंक्ति से कम या पूर्ववर्ती हैं और वर्तमान पंक्ति के संसाधित होने के साथ समाप्त होती हैं।
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE 365 PRECEDING) running_sum from emp;
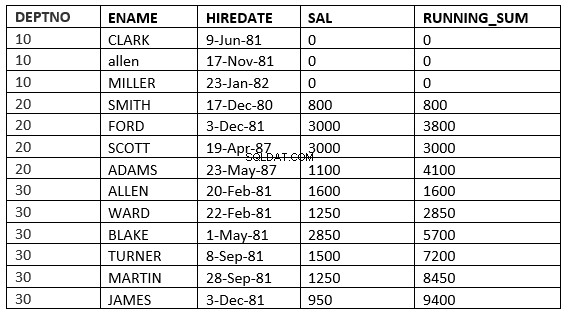
यहां यह उन सभी पंक्तियों को लेता है जहां किराया मूल्य वर्तमान पंक्ति के किराए के मूल्य से पहले 365 दिनों के भीतर आता है
ROWS value_expr PRECEDING :विंडो दी गई पंक्ति से शुरू होती है और वर्तमान पंक्ति के संसाधित होने के साथ समाप्त होती है
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS 2 PRECEDING) running_sum from emp;
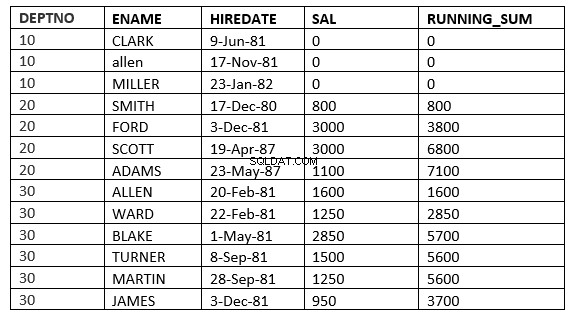
यहां विंडो वर्तमान पंक्ति से पहले की 2 पंक्तियों से शुरू होती है
वर्तमान पंक्ति के बीच की सीमा और निम्नलिखित मान_expr :विंडो वर्तमान पंक्ति से शुरू होती है और उस पंक्ति के साथ समाप्त होती है जिसका ORDER BY मान संख्यात्मक अभिव्यक्ति पंक्तियों से कम या निम्नलिखित है
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
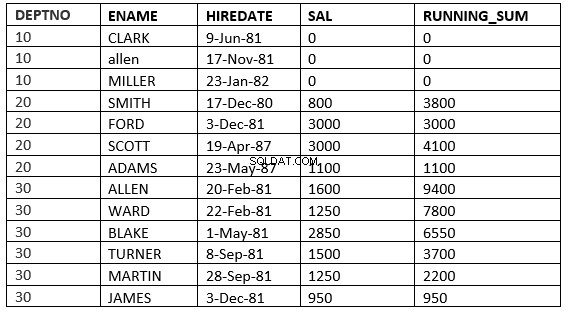
वर्तमान पंक्ति के बीच की पंक्तियाँ और निम्नलिखित value_expr :विंडो वर्तमान पंक्ति से शुरू होती है और वर्तमान पंक्ति के बाद पंक्तियों के साथ समाप्त होती है
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
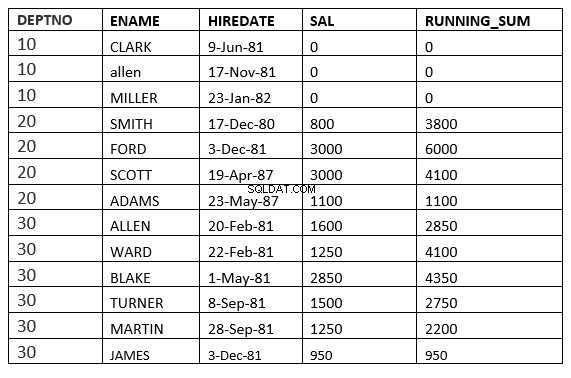
असंबद्ध पूर्ववर्ती और असीमित अनुवर्ती के बीच की सीमा
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING ) running_sum from emp;
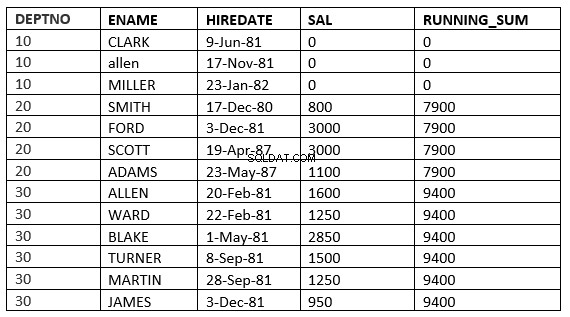
value_expr PRECEDING और value_expr FOLLOWING के बीच की सीमा
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN 365 PRECEDING and 365 FOLLOWING ) running_sum from emp; 2 DEPTNO ENAME HIREDATE SAL RUNNING_SUM ---------- ---------- --------------- ---------- ----------- 10 CLARK 09-JUN-81 0 0 10 ALLEN 17-NOV-81 0 0 10 MILLER 23-JAN-82 0 0 20 SMITH 17-DEC-80 800 3800 20 FORD 03-DEC-81 3000 3800 20 SCOTT 19-APR-87 3000 4100 20 ADAMS 23-MAY-87 1100 4100 30 ALLEN 20-FEB-81 1600 9400 30 WARD 22-FEB-81 1250 9400 30 BLAKE 01-MAY-81 2850 9400 30 TURNER 08-SEP-81 1500 9400 30 MARTIN 28-SEP-81 1250 9400 30 JAMES 03-DEC-81 950 9400 13 rows selected.
कुछ महत्वपूर्ण नोट
(1) विश्लेषणात्मक कार्य अंतिम ORDER BY खंड को छोड़कर किसी क्वेरी में किए गए संचालन का अंतिम सेट है। विश्लेषणात्मक कार्यों के संसाधित होने से पहले सभी जॉइन और सभी WHERE, GROUP BY, और HAVING क्लॉज़ पूरे हो जाते हैं। इसलिए, विश्लेषणात्मक कार्य केवल चुनिंदा सूची या ORDER BY खंड में दिखाई दे सकते हैं।
(2) विश्लेषणात्मक कार्यों का उपयोग आमतौर पर संचयी, चलती, केंद्रित और रिपोर्टिंग समुच्चय की गणना के लिए किया जाता है।
मुझे आशा है कि आपको ऑरैकल में विश्लेषणात्मक कार्यों का यह विस्तृत विवरण पसंद आया होगा (विभाजन खंड के अनुसार)
संबंधित लेख
Oracle में लीड फ़ंक्शन
Oracle में DENSE फ़ंक्शन
Oracle LISTAGG फ़ंक्शन
ग्रुप फ़ंक्शंस का उपयोग करके डेटा एकत्र करना
https://docs.oracle.com/cd/E11882_01/ server.112/e41084/functions004.htm