मैं जो करता हूं उसे सुनकर, लोग मुझसे वही सवाल पूछते हैं:क्या आप एक ऐसा सिस्टम विकसित कर सकते हैं जो फुटबॉल मैच के परिणामों की भविष्यवाणी करता हो? या ओलंपिक पदक के परिणाम? निजी तौर पर, मैं भविष्यवाणियों में ज्यादा विश्वास नहीं रखता। फिर भी, यदि हमारे पास बड़ी मात्रा में ऐतिहासिक डेटा और प्रासंगिक संकेतक थे, तो हम निश्चित रूप से अधिक सटीक धारणाओं के साथ आने में हमारी सहायता के लिए एक प्रणाली तैयार कर सकते थे। इस लेख में, हम एक ऐसे मॉडल पर विचार करेंगे जो मैचों और टूर्नामेंटों के परिणामों को संग्रहीत कर सकता है।
यह मॉडल मुख्य रूप से यूरोपीय फुटबॉल (सॉकर) मैचों, आंकड़ों और परिणामों पर केंद्रित है, लेकिन कई अन्य खेलों को समायोजित करने के लिए इसे आसानी से बदल दिया जा सकता है। इस लेख के लिए मेरी मुख्य प्रेरणा इस साल की दो बड़ी फ़ुटबॉल प्रतियोगिताएं थीं:यूईएफए यूरो 2016 चैम्पियनशिप जो अभी-अभी हुई और 2016 के ग्रीष्मकालीन ओलंपिक खेल जो अभी हो रहे हैं।
टूर्नामेंट शुरू होने से पहले हम क्या जानते हैं?
टूर्नामेंट शुरू होने से पहले, हम इसके बारे में लगभग सब कुछ जानते हैं - सबसे महत्वपूर्ण बात को छोड़कर:कौन जीतेगा। आइए संक्षेप में बताएं कि हम पहले से क्या जानते हैं:
- टूर्नामेंट शुरू होने और खत्म होने की तारीख
- वे स्थान जहां मैच होंगे
- मैच शुरू होने का सही समय
- किस टीमों ने टूर्नामेंट के लिए क्वालीफाई किया है
- इनमें से प्रत्येक टीम के खिलाड़ी
- हर खिलाड़ी का पिछला प्रदर्शन और उनका मौजूदा स्वरूप
हम कौन से मैच विवरण स्टोर करना चाहते हैं?
टूर्नामेंट में कई मैच होते हैं। इससे पहले कि हम किसी भी मैच के विवरण को स्टोर करें, हमें चाहिए:
- हर मैच को टूर्नामेंट से जोड़ो
- टूर्नामेंट के उस चरण को रिकॉर्ड करें जब मैच खेला गया था (जैसे ग्रुप स्टेज, सेमी-फ़ाइनल)
हमें एकल मैचों के लिए विवरण स्टोर करने की भी आवश्यकता है, जिसमें शामिल हैं:
- मैच में शामिल टीमें
- लाइनअप और प्रतिस्थापन प्रारंभ करना
- मैच इवेंट (फुटबॉल में ये हैं:गोल, पेनल्टी, फाउल, येलो कार्ड, आदि)
- अंतिम स्कोर
- मैच के दौरान खिलाड़ियों की हरकत
हम इस डेटा का उपयोग सभी महत्वपूर्ण मैच इवेंट को कैप्चर करने के लिए करेंगे। मैच से पहले और दौरान किसी खिलाड़ी के प्रदर्शन की तुलना करने से कुछ निष्कर्ष निकल सकते हैं। हो सकता है कि हम उनके प्रदर्शन (यानी जीत या हार) के अंतिम परिणामों की भविष्यवाणी करने में सक्षम न हों, लेकिन आंकड़े निश्चित रूप से विश्वसनीयता की डिग्री के साथ अनुमान लगाने में हमारी मदद कर सकते हैं।
मॉडल का परिचय
मॉडल को चार मुख्य क्षेत्रों में बांटा गया है:
Tournament detailsMatch detailsEventsIndicators and Performance
इन क्षेत्रों के बाहर की तालिकाएँ शब्दकोश हैं (sport , phase , position ), कैटलॉग (sport_event , team , player ) और एक एकल कई-से-अनेक संबंध (plays )।
हम पहले गैर-वर्गीकृत तालिकाओं का वर्णन करेंगे, और फिर प्रत्येक क्षेत्र पर करीब से नज़र डालेंगे।
अवर्गीकृत तालिकाएं
ये तालिकाएँ महत्वपूर्ण हैं क्योंकि चारों क्षेत्रों की तालिकाएँ इन्हें शब्दकोशों या कैटलॉग के रूप में उपयोग करती हैं।

sport तालिका उन सभी खेलों को सूचीबद्ध करती है जिन्हें हम अपने डेटाबेस में संग्रहीत करेंगे। हमारे यहां शायद केवल एक ही खेल होगा, पुरुष फ़ुटबॉल, लेकिन यह तालिका हमें ज़रूरत पड़ने पर समान खेलों (जैसे महिला फ़ुटबॉल) को जोड़ने की सुविधा देती है।

sport_event तालिका, हम अपने खेल (खेलों) से जुड़ी घटनाओं को संग्रहीत करेंगे। एक उदाहरण "2016 ओलंपिक खेल" होगा।
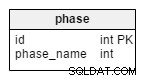
phase तालिका एक शब्दकोश है जिसमें सभी संभावित टूर्नामेंट चरण होते हैं। इसमें “ग्रुप स्टेज” . जैसे मान शामिल हैं , “16 का दौर” , “क्वार्टर फ़ाइनल” , “सेमीफ़ाइनल” , “अंतिम” ।
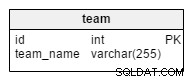
team जैसा कि आप अनुमान लगा सकते हैं, तालिका सभी टीमों की एक साधारण सूची है। संभावित मान हैं “क्रोएशिया” , “पोलैंड” , “यूएसए” आदि। यदि हम क्लब या लीग प्रतियोगिता के बारे में जानकारी संग्रहीत करने के लिए डेटाबेस का उपयोग करते हैं, तो हमारे पास “बार्सिलोना” जैसे मान भी होंगे। , “रियल मैड्रिड” , “बायर्न” , “मैनचेस्टर यूनाइटेड” आदि.
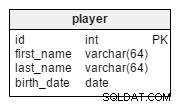
player तालिका में, हम संबंधित टीमों से संबंधित सभी खिलाड़ियों के रिकॉर्ड संग्रहीत करेंगे।
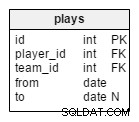
plays टेबल हमारा एकमात्र कई-से-अनेक संबंध है, और यह खिलाड़ियों और टीमों से संबंधित है। एक खिलाड़ी एक ही समय में एक से अधिक टीमों (जैसे राष्ट्रीय टीम और एक क्लब) से संबंधित हो सकता है, लेकिन एक टूर्नामेंट के दौरान वे स्पष्ट रूप से केवल एक टीम के लिए खेलेंगे।
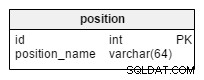
अंत में, हमारे पास position टेबल। यह सरल शब्दकोश सभी आवश्यक पदों की एक सूची संग्रहीत करेगा। फ़ुटबॉल में, इनमें गोलकीपर, सेंटर-हाफ़, स्ट्राइकर आदि शामिल हैं।
टूर्नामेंट विवरण
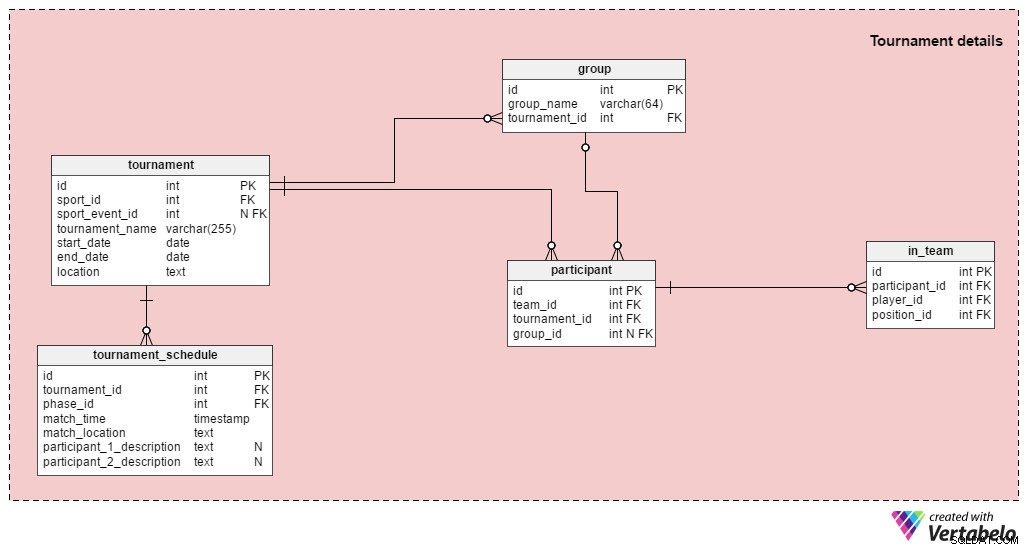
नोट: यदि आप केवल एकल मैचों के परिणामों को संग्रहीत करना चाहते हैं, तो आपको इस अनुभाग का उपयोग करने की आवश्यकता नहीं है।
एक टूर्नामेंट में एक से अधिक मैच होते हैं; यूईएफए यूरो 2016 और 2016 ग्रीष्मकालीन ओलंपिक में फुटबॉल प्रतियोगिताएं दोनों टूर्नामेंट हैं। जैसा कि हमने पहले कहा, हम अपने डेटाबेस में एक मैच को स्टोर कर सकते हैं, लेकिन हम मैचों को उनके प्रासंगिक टूर्नामेंट से भी जोड़ सकते हैं। टूर्नामेंट अनुभाग में टेबल हैं:
tournament- इसमें सभी बुनियादी टूर्नामेंट डेटा शामिल हैं:खेल, प्रारंभ तिथि, समाप्ति तिथि, आदि। हमें टूर्नामेंट का नाम और यह कहां हो रहा है इसका विवरण भी संग्रहीत करने की आवश्यकता है।sport_event_idएट्रिब्यूट वैकल्पिक है क्योंकि किसी टूर्नामेंट को किसी बड़े इवेंट (जैसे ओलंपिक) से संबद्ध होने की ज़रूरत नहीं है।group- यह उस टूर्नामेंट के सभी समूहों को सूचीबद्ध करता है। यूईएफए यूरो 2016 में छह समूह थे, ए से एफ तक।participant- ये टूर्नामेंट में खेलने वाली टीमें हैं; प्रत्येक प्रतिभागी को एक समूह को सौंपा जा सकता है। अधिकांश टूर्नामेंट समूह चरण से शुरू होते हैं और फिर नॉकआउट चरण (जैसे यूईएफए यूरो, यूईएफए विश्व कप, ओलंपिक फुटबॉल) तक जारी रहते हैं। कुछ टूर्नामेंटों में केवल एक समूह चरण (जैसे राष्ट्रीय लीग) होगा, जबकि अन्य में केवल एक नॉकआउट चरण (जैसे राष्ट्रीय कप) होगा।in_team- यह तालिका कई-से-अनेक संबंध प्रदान करती है जो उस टूर्नामेंट के लिए पंजीकृत खिलाड़ियों और उनकी अपेक्षित स्थिति के बारे में जानकारी संग्रहीत करती है।tournament_schedule- मेरी राय में, यह इस खंड की सबसे दिलचस्प तालिका है। इस टूर्नामेंट के दौरान खेले गए सभी खेलों की सूची यहां संग्रहीत है।tournament_idविशेषता दर्शाती है कि प्रत्येक मैच किस टूर्नामेंट से संबंधित है, औरphase_idविशेषता उस चरण को परिभाषित करती है जिसके दौरान मैच होगा। हम मैच की लोकेशन और उसके शुरू होने का समय भी स्टोर करेंगे। दोनों प्रतिभागियों का वर्णन टेक्स्ट फ़ील्ड द्वारा किया जाएगा। जब ग्रुप स्टेज खत्म हो जाएगा, तो हम एलिमिनेशन राउंड के लिए सभी मैचअप के बारे में जानेंगे। उदाहरण के लिए, यूईएफए यूरो 2016 की शुरुआत में, हम जानते थे कि ग्रुप ई (1ई) का विजेता ग्रुप डी रनर-अप (2डी) के खिलाफ खेलेगा। ग्रुप चरण में तीनों राउंड खेले जाने के बाद, यह जोड़ी इटली बनाम स्पेन थी।
मैच विवरण
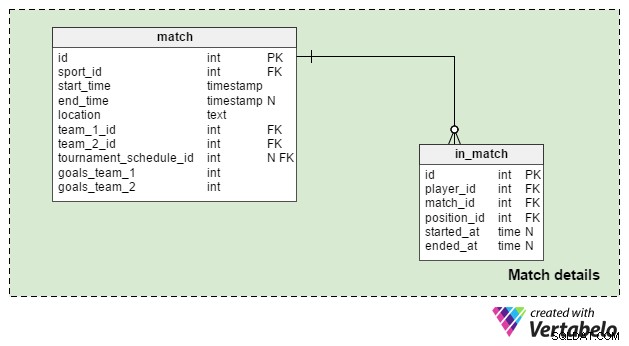
Match details क्षेत्र का उपयोग एकल मैचों के लिए डेटा संग्रहीत करने के लिए किया जाता है। हम दो तालिकाओं का उपयोग करेंगे:
match- इसमें एक मैच के बारे में सभी विवरण शामिल हैं; यह मैच एक टूर्नामेंट से संबंधित हो सकता है, लेकिन यह एक एकल खेल भी हो सकता है। तोtournament_schedule_idविशेषता वैकल्पिक है, और हमsport_id. स्टोर करेंगे ,start_timeऔरlocationयहाँ फिर से विशेषताएँ। अगर मैच किसी टूर्नामेंट का हिस्सा है, तोtournament_schedule_idमान दिया जाएगा।team_1_idऔरteam_2_idविशेषताएँ मैच में शामिल टीमों के संदर्भ हैं।goals_team_1औरgoals_team_2विशेषताओं में मैच का परिणाम होता है। वे अनिवार्य हैं और दोनों के लिए डिफ़ॉल्ट मान के रूप में "0" होना चाहिए।in_match- यह तालिका उन सभी खिलाड़ियों की सूची है जो उस मैच के लिए पंजीकृत हैं; जो खिलाड़ी भाग नहीं लेंगे उनके पासstarted_at. में एक NULL होगा विशेषता, जबकि खिलाड़ी जो प्रतिस्थापन के रूप में आए हैं उनके पासstarted_at. होगा> 0 . अगर किसी खिलाड़ी को बदल दिया जाता है, तो उनके पास एकended_atहोगा विशेषता जोstarted_at. से मेल खाती है उन्हें बदलने वाले खिलाड़ी की विशेषता। यदि खिलाड़ी पूरे मैच के लिए रुका रहता है, तो उनकाended_atविशेषता का वही मान होगा जोend_time. है विशेषता।
मैच इवेंट
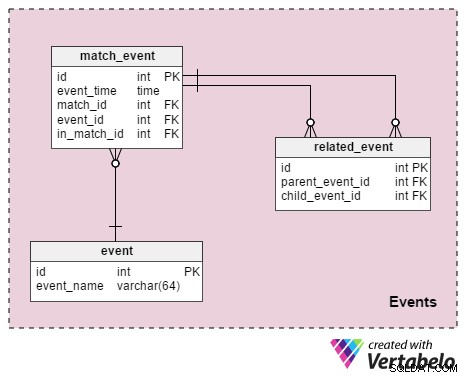
इस खंड का उद्देश्य खेल के दौरान हुई सभी विवरणों या घटनाओं को संग्रहीत करना है। और टेबल हैं:
event- यह एक शब्दकोश है जो उन सभी घटनाओं को सूचीबद्ध करता है जिन्हें हम स्टोर करना चाहते हैं। फ़ुटबॉल में, ये “गलत तरीके से किए गए” . जैसे मान हैं , “बेईमानी का सामना करना पड़ा” , “पीला कार्ड” , “लाल कार्ड” , “फ्री किक” , “जुर्माना” , “लक्ष्य” , “ऑफसाइड” , “प्रतिस्थापन” , “मैच से बाहर किया गया खिलाड़ी” ।match_event- यह मैच के साथ घटनाओं से संबंधित है। हमevent_timeस्टोर करेंगे साथ ही उस घटना से संबंधित खिलाड़ी की जानकारी (in_match_id)।related_event- यह वही है जो घटना की जानकारी को एक साथ लाता है। समझाने के लिए, आइए एक उदाहरण देखें जब खिलाड़ी A खिलाड़ी B को गलत ठहराता है। हमmatch_eventतालिका जो इंगित करती है कि खिलाड़ी A ने एक बेईमानी की है और एक अन्य जो इंगित करती है कि खिलाड़ी B को एक बेईमानी का सामना करना पड़ा है। हमrelated_eventतालिका, जहां 'प्रतिबद्ध बेईमानी' माता-पिता होगी और 'पीड़ित बेईमानी' बच्चा होगा। हम फाउल के परिणाम भी रिकॉर्ड करेंगे:एक पीला कार्ड, एक फ्री किक या पेनल्टी किक, और शायद एक गोल।
संकेतक और प्रदर्शन
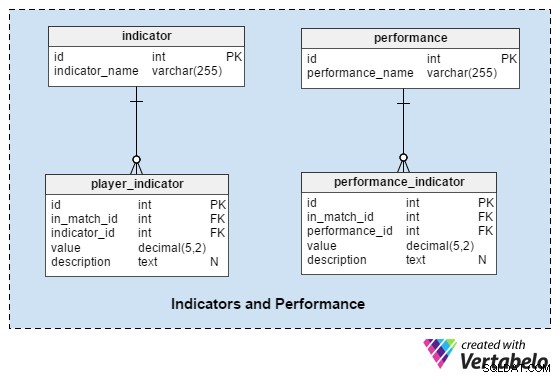
इस खंड से हमें मैच से पहले और बाद में खिलाड़ियों और टीमों का विश्लेषण करने में मदद मिलेगी।
indicator तालिका प्रत्येक मैच से पहले प्रत्येक खिलाड़ी के लिए संकेतकों के पूर्वनिर्धारित सेट के साथ एक शब्दकोश है। इन संकेतकों को खिलाड़ी के वर्तमान स्वरूप का वर्णन करना चाहिए। इस सूची में ये मान हो सकते हैं:“पिछले 10 मैचों में गोलों की संख्या” , “पिछले 10 मैचों में तय की गई औसत दूरी” , “पिछले 10 मैचों में GK के लिए सेव की संख्या” ।
performance शब्दकोश बहुत हद तक indicator . के समान है , लेकिन हम इसका उपयोग केवल उन मानों को संग्रहीत करने के लिए करेंगे जो एकल मिलान से संबंधित हैं:“दूरी तय” , “सटीक पास” , आदि.
player_indicator और performance_indicator टेबल लगभग समान संरचना साझा करते हैं:
in_match_id- एक निश्चित मैच में भाग लेने वाले खिलाड़ी को संदर्भित करता हैindicator_id/performance_id-indicator. का संदर्भ देता है या "प्रदर्शन शब्दकोशvalue- उस संकेतक के लिए मान संग्रहीत करता है (उदाहरण के लिए एक खिलाड़ी जो 10.72 किमी की दूरी तय करता है)description- यदि आवश्यक हो तो एक अतिरिक्त विवरण रखता है
मैच के दौरान क्या हुआ?
इन सभी डेटा को दर्ज करने से, हम आसानी से अपने डेटाबेस में प्रत्येक मैच के लिए मिलान विवरण, ईवेंट और आंकड़े प्राप्त कर सकते हैं।
यह सरल प्रश्न आगामी मैच के लिए बुनियादी विवरण लौटाएगा:
SELECT team_1.`team_name`, team_2.`team_name`, `match`.`start_time`, `match`.`location` FROM `match`, `team` AS team_1, `team` AS team_2 WHERE `match`.`team_1_id` = team_1.`id` AND `match`.`team_2_id` = team_2.`id`
एक निश्चित मैच के दौरान सभी इन-प्ले इवेंट की सूची प्राप्त करने के लिए, हम नीचे दी गई क्वेरी का उपयोग करेंगे:
SELECT `event`.`event_name`, `match_event`.`event_time`, `player`.`first_name`, `player`.`last_name` FROM `match`, `match_event`, `event`, `in_match`, `player` WHERE `match_event`.`match_id` = `match`.`id` AND `event`.`id` = `match_event`.`event_id` AND `in_match`.`id` = `match_event`.`in_match_id` AND `player`.`id` = `in_match`.`player_id` AND `match`.`id` = @match ORDER BY `match_event`.`event_time` ASC
ऐसे कई अतिरिक्त प्रश्न हैं जिनके बारे में मैं सोच सकता हूं; जब आपके पास डेटा हो तो विश्लेषण करना आसान होता है। यदि आपने बड़ी संख्या में संकेतक और खिलाड़ी के प्रदर्शन डेटा को मापा और संग्रहीत किया है, तो आप इन मापदंडों को अंतिम परिणाम के साथ जोड़ने में सक्षम हो सकते हैं। मैं व्यक्तिगत रूप से ऐसी भविष्यवाणियों में विश्वास नहीं करता; मैचों के दौरान भाग्य कारक होता है, साथ ही कई अन्य कारक जिन्हें आप खेल शुरू होने तक नहीं जान सकते। फिर भी, यदि आपके पास एक बड़ा डेटासेट और बहुत सारे पैरामीटर हैं, तो आपके अधिक सटीक पूर्वानुमान लगाने की संभावना बढ़ जाती है।
इस लेख में प्रस्तुत मॉडल हमें मैच, मैच विवरण और प्रत्येक खिलाड़ी के प्रदर्शन के इतिहास को संग्रहीत करने की अनुमति देता है। हम मैच से पहले प्रत्येक खिलाड़ी के लिए फॉर्म संकेतक भी सेट कर सकते हैं। पर्याप्त विवरण संग्रहीत करने से हमें अधिक पैरामीटर प्रदान करने चाहिए जिन पर हमारी धारणाओं को आधार बनाया जा सके। मैं यह नहीं कह रहा हूं कि हम खेल के परिणाम की भविष्यवाणी कर सकते हैं, लेकिन हम इसके साथ कुछ मजा कर सकते हैं।
हम अन्य खेलों के लिए डेटा स्टोर करने के लिए इस मॉडल को आसानी से बदल सकते हैं। ये परिवर्तन बहुत जटिल नहीं होने चाहिए। एक sport_idजोड़ना शब्दकोशों की विशेषता को चाल चलनी चाहिए। फिर भी, मुझे लगता है कि प्रत्येक अलग खेल के लिए एक नया उदाहरण होना बुद्धिमानी होगी।