अपने डेटा मॉडल में बहु-भाषा समर्थन लागू करने के लिए, आपको पहिया को फिर से शुरू करने की आवश्यकता नहीं है। यह लेख आपको इसे करने के विभिन्न तरीके दिखाएगा और आपके लिए सबसे अच्छा काम करने वाले को चुनने में मदद करेगा।
एक सॉफ्टवेयर एप्लिकेशन के विकास के लिए स्थानीयकरण की अवधारणा महत्वपूर्ण है, खासकर जब उस एप्लिकेशन का दायरा वैश्विक हो। अनेक भाषाओं के लिए समर्थन विचार करने का मुख्य पहलू है; एक डेटाबेस डिज़ाइन जो एक बहु-भाषा एप्लिकेशन का समर्थन करता है, आपको अपने लक्षित बाजारों में विविधता लाने और इस प्रकार कई और ग्राहकों तक पहुंचने की अनुमति देता है। इसके अलावा, ऐसा डेटाबेस डिज़ाइन स्थानीयकरण-तैयार सिस्टम को डिज़ाइन करने के लिए आपकी दीर्घकालिक रणनीति का हिस्सा हो सकता है।
आपके एप्लिकेशन में बहु-भाषा समर्थन को शामिल करने की कुंजी इसे इस तरह से करना है जिससे विकास या रखरखाव लागत में अत्यधिक वृद्धि न हो। चूंकि डेटाबेस मॉडलिंग सॉफ्टवेयर विकास प्रक्रिया का एक अविभाज्य हिस्सा है, इसलिए आपको अपने एप्लिकेशन को बहु-भाषा समर्थन देने के लिए सर्वोत्तम डेटा मॉडल डिज़ाइन रणनीति के बारे में सोचने की आवश्यकता है।
एक उचित डेटा मॉडल को आपको बहु-भाषा समर्थन बनाए रखते हुए एप्लिकेशन को संशोधित करने या नई कार्यक्षमता जोड़ने की अनुमति देनी चाहिए - बिना अतिरिक्त प्रयास या लागत जोड़े। यह आपको एप्लिकेशन को छुए बिना नई भाषाओं को शामिल करने की अनुमति भी देनी चाहिए; आपको केवल डेटाबेस में संबंधित अनुवाद डेटा जोड़ने की आवश्यकता है।
सरल कार्यान्वयन बनाम लचीलापन और कार्यक्षमता
बहु-भाषा अनुप्रयोगों के लिए डेटाबेस डिज़ाइन बनाने के लिए विभिन्न दृष्टिकोण हैं। प्रत्येक के अपने फायदे और नुकसान है। जिन्हें लागू करना आसान है वे कम लचीलेपन और कम कार्यक्षमता प्रदान करते हैं; जो अधिक लचीलापन और कार्यक्षमता प्रदान करते हैं, उनके कार्यान्वयन अधिक जटिल होते हैं।
यहां मेरी सलाह है कि हमेशा उन लोगों के लिए जाएं जो अधिक कार्यक्षमता और लचीलापन प्रदान करते हैं , भले ही उन्हें लागू करना अधिक महंगा हो। कभी-कभी हम यह सोचने की गलती करते हैं कि कोई एप्लिकेशन बहुत छोटा है, कि बहु-भाषा समर्थन जैसी चीज़ों को हल करने के लिए जटिल स्कीमा को लागू करना इसके लायक नहीं है। लेकिन अंततः, वह एप्लिकेशन बढ़ेगा और हमें "त्वरित और गंदे" दृष्टिकोण को चुनने का पछतावा होगा जो कि सरल और कम खर्चीला लग रहा था।
किसी एप्लिकेशन के लिए एक्सेसरी कार्यक्षमता को लागू करने के लिए आदर्श - चाहे वह बहु-भाषा समर्थन हो, लॉगिंग परिवर्तन, उपयोगकर्ता प्रमाणीकरण, या कुछ और हो - उस कार्यक्षमता के लिए इसकी अपनी उप-योजना और इसके तर्क को पुन:प्रयोज्य घटकों में समझाया गया है। इस तरह, सहायक कार्यक्षमता और इसकी उपयोजना दोनों को न्यूनतम प्रयास के साथ किसी भी नए एप्लिकेशन में शामिल किया जा सकता है।
वर्टाबेलो जैसा एक बुद्धिमान डेटाबेस डिज़ाइन और डेटा मॉडलिंग टूल आपके स्कीमा और सबस्कीमा के कुशल प्रबंधन के लिए एक बड़ी मदद है। साथ ही, बेहतर डेटाबेस डिज़ाइन के लिए इन युक्तियों को देखें और सुनिश्चित करें कि आप उन सभी का पालन करते हैं। इससे पहले कि आप अपना ईआर आरेख बनाना शुरू करें, मेरा सुझाव है कि आप डेटाबेस मॉडलिंग युक्तियों की इस आवश्यक श्रृंखला पर विचार करें।
कुछ आकर्षक (लेकिन सलाह नहीं देने योग्य) बहु-भाषा डेटाबेस डिज़ाइन समाधान
सबसे आसान - लेकिन कम से कम अनुशंसित
आइए बहु-भाषा एप्लिकेशन डेटाबेस को लागू करने के लिए कम से कम अनुशंसित लेकिन सबसे आसान तरीके से शुरू करें। यह आपको बहु-भाषा एप्लिकेशन का समर्थन करने की आवश्यकता को जल्दी से हल करने की अनुमति देता है, लेकिन जब एप्लिकेशन कार्यक्षमता या भौगोलिक कवरेज में बढ़ता है तो यह आपको समस्याएं लाएगा।
इस सरल रणनीति में टेक्स्ट के प्रत्येक कॉलम के लिए एक अतिरिक्त कॉलम जोड़ना शामिल है जिसे अनुवाद की आवश्यकता है और प्रत्येक भाषा के लिए जिसमें टेक्स्ट का अनुवाद किया जाना चाहिए।
उदाहरण के लिए, Movies . में नीचे दी गई तालिका में एक OriginalTitle है खेत। प्रत्येक भाषा के अनुवाद के लिए एक अतिरिक्त शीर्षक कॉलम जोड़ा जाता है:
| मूल शीर्षक | Title_sp | Title_it | Title_fr | |
|---|---|---|---|---|
| 1 | डाई हार्ड | दुरो दे मटर | ट्रैपोला डि क्रिस्टालो | पिएज डी क्रिस्टल |
| 2 | भविष्य में वापस | वोल्वर अल फ़्यूचूरो | रिटोर्नो अल फ़्यूचूरो | रिटोर वर्स ले फ्यूचर |
| 3 | जुरासिक पार्क | पार्क जुरासिको | गिउरासिको पार्को | Parc जुरासिक |
एप्लिकेशन को उपयोगकर्ता द्वारा चुनी गई भाषा के अनुरूप कॉलम से विवरण डेटा प्राप्त करना होगा। जब आपको एक नई भाषा जोड़ने की आवश्यकता होती है, तो आपको नई भाषा में अनुवादित पाठों को शामिल करने के लिए तालिका में एक अतिरिक्त कॉलम जोड़ना होगा। आपको अतिरिक्त भाषा और कॉलम को स्वीकार करने के लिए एप्लिकेशन को भी अनुकूलित करना होगा।
इस समाधान के लिए अनुवादित पाठ प्राप्त करने के लिए जटिल जॉइन की आवश्यकता नहीं है, न ही इसे डुप्लिकेट रिकॉर्ड की आवश्यकता है - केवल पाठ सामग्री कॉलम की प्रतिकृति। लेकिन इसकी प्रयोज्यता उन स्थितियों तक सीमित है जहां केवल कुछ तालिकाओं का अनुवाद करने की आवश्यकता होती है।
उदाहरण के लिए, मान लें कि आपके पास Products है तालिका और एक Processes टेबल। उनमें से प्रत्येक के पास एक विवरण फ़ील्ड है जिसे अनुवाद की आवश्यकता है; काफी आसान लगता है, है ना? लेकिन यदि संपूर्ण एप्लिकेशन (इसके सभी मेनू विकल्पों, त्रुटि संदेशों आदि सहित) को बहुभाषी होने की आवश्यकता है, तो यह समाधान लागू नहीं होता है।
अधिक बहुमुखी, लेकिन सलाह योग्य भी नहीं
अनुवादों को एक ही तालिका में रखने के विचार को जारी रखते हुए, पिछले विकल्प का एक विकल्प टेक्स्ट फ़ील्ड को बड़ा करना है। यह हमें सभी अनुवादों को एक ही क्षेत्र में संग्रहीत करने की अनुमति देगा, उन्हें डेटा संरचना (जैसे एक XML दस्तावेज़ या JSON ऑब्जेक्ट) में व्यवस्थित करेगा। नीचे हमारे पास एक उदाहरण है:
| मूवी आईडी | <टीडी>
| 1 | <टीडी>
| 2 | <टीडी>
| 3 | <टीडी>
इस विकल्प को अतिरिक्त कॉलम की आवश्यकता नहीं है, लेकिन जटिलता जोड़ता है। डेटा क्वेरी अब बहु-भाषा समर्थन के लिए उपयोग की जाने वाली डेटा संरचना को सही ढंग से संसाधित और व्याख्या करने में सक्षम होनी चाहिए। उदाहरण के लिए, यदि अनुवादों को संग्रहीत करने के लिए JSON या XML का उपयोग किया जाता है, तो SQL क्वेरीज़ को एक SQL संस्करण का उपयोग करना चाहिए जो चुने हुए डेटा प्रकार का समर्थन करता है।
निम्न SQL कमांड MS SQL सर्वर का उपयोग करता है OPENJSON() Translations . की सामग्री का उपयोग करने के लिए कार्य करता है एक अधीनस्थ तालिका के रूप में फ़ील्ड:
SELECT m.MovieId, m.OriginalTitle, t.TranslatedTitle FROM Movies AS m CROSS APPLY OPENJSON(m.Translations) WITH ( language char(2) '$.language', TranslatedTitle varchar(100) '$.title’ ) AS t WHERE t.language = 'fr';
चूंकि मानक SQL में JSON या XML स्वरूपित डेटा में हेरफेर करने के लिए कोई फ़ंक्शन या ऑपरेटर नहीं हैं, इसलिए यदि आप अनुवादित ग्रंथों को संग्रहीत करने के लिए इस तकनीक का उपयोग करना चाहते हैं, तो आपको किसी विशेष RDBMS के लिए अपने प्रश्न लिखने के लिए मजबूर किया जाता है। उदाहरण के लिए, पिछली क्वेरी MySQL द्वारा समर्थित नहीं है। अगर आपको Movies MySQL के साथ तालिका, आप यह प्रश्न लिखेंगे:
SELECT m.MovieId, m.OriginalTitle, JSON_EXTRACT(m.Translations, '$.title') AS TranslatedTitle FROM Movies AS m WHERE JSON_EXTRACT(m.Translations. '$.language') = 'fr';
अनुवादित पाठ को विभिन्न अभिलेखों में संग्रहीत करना
आप प्रत्येक भाषा के लिए अलग-अलग रिकॉर्ड का उपयोग करना भी चुन सकते हैं। हालांकि, आपको सामान्यीकरण खोने के लिए खुद को इस्तीफा देना होगा:एक ही डेटा कई रिकॉर्ड में दोहराया जाता है, जिसमें केवल अनुवाद भिन्न होता है।
| LanguageId | <थ>शीर्षक||
|---|---|---|
| 1 | en | डाई हार्ड |
| 1 | सपा | दुरो दे मटर |
| 1 | यह | ट्रैपोला डि क्रिस्टालो |
| 1 | fr | पिएज डी क्रिस्टल |
| 2 | en | भविष्य में वापस |
| 2 | सपा | वोल्वर अल फ़्यूचूरो |
| 2 | यह | रिटोर्नो अल फ़्यूचूरो |
इस विकल्प के साथ, आप प्रत्येक तालिका के दृश्य बना सकते हैं जो किसी दी गई भाषा में केवल पंक्तियाँ लौटाती हैं:
CREATE VIEW Movies_en AS SELECT MovieId, Title FROM Movies WHERE LanguageId = 'en'; CREATE VIEW Movies_sp as SELECT MovieId, Title FROM Movies WHERE LanguageId = 'sp';
फिर, तालिका को क्वेरी करने के लिए, आप लक्ष्य अनुवाद भाषा के अनुसार एक भिन्न दृश्य का उपयोग कर सकते हैं। लेकिन मॉडल का सामान्यीकरण खो गया है और टेबल रखरखाव अनावश्यक रूप से जटिल है।
अनुवादित पाठ को अलग-अलग तालिकाओं में संग्रहीत करना
संबंधपरक मॉडल को तोड़े बिना अनुवादित ग्रंथों को संग्रहीत करने का एक तरीका यह है कि प्रत्येक तालिका के लिए एक विवरण तालिका हो जिसमें ग्रंथों का अनुवाद किया जाना है। अनुवाद वाली अधीनस्थ तालिका में मूल तालिका के समान कुंजी फ़ील्ड, साथ ही अनुवाद भाषा को दर्शाने वाला फ़ील्ड होना चाहिए।
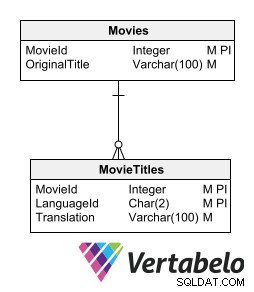
अनुवाद वाली एक अधीनस्थ तालिका में मूल तालिका के समान कुंजी फ़ील्ड, साथ ही अनुवाद भाषा को इंगित करने वाला फ़ील्ड होना चाहिए।
यह विकल्प तालिका संरचना को बदले बिना नई भाषाओं को शामिल करने की अनुमति देता है। इसके लिए अनावश्यक जानकारी उत्पन्न करने या मॉडल सामान्यीकरण को तोड़ने की आवश्यकता नहीं है।
इस विकल्प का दोष यह है कि इसके लिए प्रत्येक तालिका के लिए एक अधीनस्थ तालिका के निर्माण की आवश्यकता होती है जो अनुवाद की आवश्यकता वाले पाठ्य डेटा को संग्रहीत करती है। हालांकि, संबंधित तालिकाओं में अनुवादों को संग्रहीत करने का विचार हमें बहु-भाषा डेटाबेस को डिजाइन करने के सबसे उचित तरीके के करीब लाता है।
सार्वभौमिक समाधान:एक अनुवाद उपयोजना
किसी एप्लिकेशन और उसके डेटाबेस को वास्तव में बहुभाषी होने के लिए, सभी ग्रंथों का प्रत्येक समर्थित भाषा में अनुवाद होना चाहिए - न कि केवल किसी विशेष तालिका में टेक्स्ट डेटा। यह एक अनुवाद उपयोजना के साथ हासिल किया जाता है जहां उपयोगकर्ता की आंखों तक पहुंचने वाली पाठ्य सामग्री के साथ सभी डेटा संग्रहीत किया जाता है।
विभिन्न भाषाओं में उपयोग के लिए लक्षित वेब अनुप्रयोगों में, अनुवाद उपयोजना एक आवश्यकता है, विकल्प नहीं। और कुछ भी जटिलताएं पैदा करेगा जिससे एप्लिकेशन का उचित रखरखाव असंभव हो जाएगा।
अनुवादों को एक अलग स्कीमा में रखने की कुंजी उन सभी पाठों के साथ एक अनुक्रमित कैटलॉग को बनाए रखना है जिन्हें अनुवाद की आवश्यकता है, चाहे वे इकाई विवरण, त्रुटि संदेश या मेनू विकल्प हों। विचार यह है कि उपयोगकर्ता की आंखों तक पहुंचने वाला कोई भी पाठ इस उप-योजना के बाहर किसी भी तालिका में संग्रहीत नहीं है।
अनुवाद सूची को व्यवस्थित करने का एक तरीका तीन तालिकाओं का उपयोग करना है:
- भाषाओं की एक मास्टर टेबल।
- मूल भाषा में ग्रंथों की एक तालिका।
- अनुवादित ग्रंथों की एक तालिका।
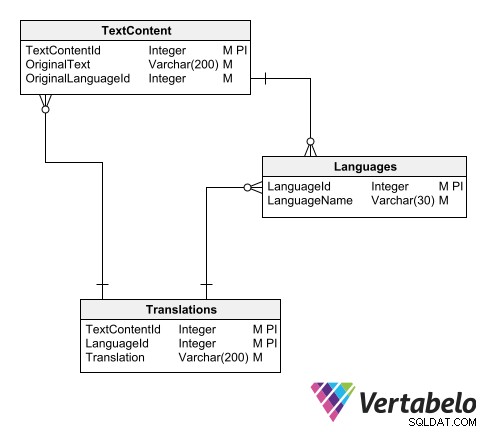
सार्वभौम अनुवाद कैटलॉग के लिए स्कीमा.
भाषाओं की मास्टर तालिका में, हम केवल डेटा मॉडल द्वारा समर्थित प्रत्येक भाषा के लिए एक रिकॉर्ड सम्मिलित करते हैं। प्रत्येक का एक आईडी कोड और एक नाम होता है:
| LanguageId | भाषा का नाम |
|---|---|
| en | अंग्रेज़ी |
| sp | स्पेनिश |
| यह | इतालवी |
| fr | फ़्रेंच |
टेक्स्ट टेबल उन सभी टेक्स्ट को रिकॉर्ड करती है जिन्हें अनुवाद की आवश्यकता होती है। प्रत्येक रिकॉर्ड में एक मनमाना आईडी, मूल पाठ और मूल भाषा की आईडी होती है।
TextContent . में तालिका, मूल पाठ और मूल भाषा की आईडी कड़ाई से आवश्यक नहीं हैं। लेकिन वे उन प्रश्नों को सरल करते हैं जिन्हें अनुवाद की आवश्यकता नहीं होती है। उदाहरण के लिए, सांख्यिकीय विश्लेषण या प्रबंधन नियंत्रण प्रश्न करते समय (जो आमतौर पर केवल मूल भाषा को समझने वाले उपयोगकर्ताओं के लिए उपलब्ध होते हैं) डिफ़ॉल्ट (गैर-अनुवादित) टेक्स्ट का उपयोग करके प्रश्नों को सरल बनाया जा सकता है।
मूल ग्रंथ उन लोगों के लिए भी उपयोगी हैं जिन्हें अनुवादित ग्रंथों की तालिका भरनी है। अनुवाद डेटा प्रविष्टि सभी उपलब्ध भाषाओं में मूल पाठ और अनुवाद दिखाते हुए एक मिनी-एप्लिकेशन के माध्यम से की जा सकती है। अनुवाद API का उपयोग करके स्वचालित प्रक्रिया के माध्यम से अनुवाद उपस्कीमा के लिए जानकारी उत्पन्न करना भी संभव है।
मुख्य स्कीमा से लिंक करना
एप्लिकेशन के मुख्य स्कीमा में, टेक्स्ट मानों वाले कॉलम जिन्हें अनुवाद करने की आवश्यकता होती है, उन्हें उन आईडी से बदल दिया जाता है जो अनुवादित टेक्स्ट की तालिका की ओर इशारा करते हैं:
मुख्य स्कीमा अनुवाद स्कीमा से उन तालिकाओं के माध्यम से जुड़ी हुई है जिनमें अनुवाद की आवश्यकता है।
जहां अनुवाद की आवश्यकता नहीं है, वहां प्रश्नों को सुविधाजनक बनाने के लिए आप कुछ मुख्य स्कीमा तालिकाओं में मूल टेक्स्ट फ़ील्ड छोड़ सकते हैं, भले ही यह अनावश्यक जानकारी उत्पन्न करता हो। उदाहरण के लिए, हम ProductDescription रख सकते हैं Products . में फ़ील्ड तालिका सांख्यिकीय प्रश्नों की सुविधा के लिए या डेटा वेयरहाउस के आयामों को पॉप्युलेट करने के लिए, जब अनुवाद उपस्कीमा की आवश्यकता नहीं होती है।
- बहु-भाषा डेटाबेस डिज़ाइन:इसे एक बार करें और इसे सही करें
हमने बहु-भाषा डेटाबेस डिज़ाइन बनाने के लिए कई विकल्प देखे हैं। कुछ लागू करने में आसान और तेज़ हैं। अंतिम समाधान थोड़ा अधिक जटिल है, लेकिन यह आपको अधिक लचीलापन देता है। एप्लिकेशन और डेटाबेस को बनाए रखने का समय आने पर यह आपको परेशानी से भी बचाएगा। इस प्रकार, लंबे समय में, यह बहुत कम खर्चीला होगा।
कभी-कभी, डेटाबेस डिज़ाइन में सबसे छोटा रास्ता आपको यह विश्वास दिलाने के लिए प्रेरित करता है कि आप समय और प्रयास बचाएंगे। लेकिन जब आप इसे चुनते हैं, तो आप इस तथ्य की अनदेखी कर रहे हैं कि आपको इसे कई बार नीचे जाना होगा। यदि आप बहु-भाषा डेटाबेस डिज़ाइन के लिए सर्वोत्तम अभ्यासों की उपेक्षा करते हैं, तो आप संभवतः एक ही कार्य को बार-बार करना समाप्त कर देंगे।