आप सोच सकते हैं कि डेटाबेस रखरखाव आपके किसी काम का नहीं है। लेकिन अगर आप अपने मॉडलों को सक्रिय रूप से डिजाइन करते हैं, तो आपको ऐसे डेटाबेस मिलते हैं जो उन लोगों के लिए जीवन आसान बनाते हैं जिन्हें उन्हें बनाए रखना होता है।
एक अच्छे डेटाबेस डिज़ाइन के लिए सक्रियता की आवश्यकता होती है, किसी भी कार्य वातावरण में एक अच्छी तरह से माना जाने वाला गुण। यदि आप इस शब्द से अपरिचित हैं, तो सक्रियता समस्याओं का अनुमान लगाने और समस्या होने पर समाधान तैयार करने की क्षमता है - या बेहतर अभी तक, योजना बनाएं और कार्य करें ताकि समस्याएं पहले स्थान पर न हों।
नियोक्ता समझते हैं कि उनके कर्मचारियों या ठेकेदारों की सक्रियता लागत बचत के बराबर है। इसलिए वे इसे महत्व देते हैं और लोगों को इसका अभ्यास करने के लिए प्रोत्साहित करते हैं।
डेटा मॉडलर के रूप में आपकी भूमिका में, सक्रियता प्रदर्शित करने का सबसे अच्छा तरीका उन मॉडलों को डिज़ाइन करना है जो नियमित रूप से डेटाबेस रखरखाव को प्रभावित करने वाली समस्याओं का अनुमान लगाते हैं और उनसे बचते हैं। या, कम से कम, यह उन समस्याओं के समाधान को काफी हद तक सरल करता है।
भले ही आप डेटाबेस रखरखाव के लिए ज़िम्मेदार नहीं हैं, आसान डेटाबेस रखरखाव के लिए मॉडलिंग करने से कई लाभ मिलते हैं। उदाहरण के लिए, यह आपको डेटा आपात स्थितियों को हल करने के लिए किसी भी समय कॉल किए जाने से रोकता है जो आपके द्वारा डिज़ाइन या मॉडलिंग कार्यों पर खर्च किए जा सकने वाले मूल्यवान समय को दूर ले जाते हैं!
आईटी लोगों के जीवन को आसान बनाना
हमारे डेटाबेस को डिजाइन करते समय, हमें एक डीईआर की डिलीवरी और अद्यतन स्क्रिप्ट की पीढ़ी से परे सोचने की जरूरत है। एक बार एक डेटाबेस उत्पादन में चला जाता है, रखरखाव इंजीनियरों को सभी प्रकार की संभावित समस्याओं से निपटना पड़ता है, और डेटाबेस मॉडलर के रूप में हमारे कार्य का एक हिस्सा उन समस्याओं के होने की संभावना को कम करना है।
आइए देखें कि एक अच्छा डेटाबेस डिज़ाइन बनाने का क्या अर्थ है और यह गतिविधि नियमित डेटाबेस रखरखाव कार्यों से कैसे संबंधित है।
डेटा मॉडलिंग क्या है?
डेटा मॉडलिंग एक अमूर्त, आमतौर पर ग्राफिकल, सूचना भंडार का प्रतिनिधित्व करने का कार्य है। डेटा मॉडलिंग का लक्ष्य उन संस्थाओं की विशेषताओं और उनके बीच संबंधों को उजागर करना है, जिनका डेटा रिपॉजिटरी में संग्रहीत है।
डेटा मॉडल व्यावसायिक समस्या की ज़रूरतों के इर्द-गिर्द बनाए जाते हैं। व्यापार विशेषज्ञों से इनपुट के माध्यम से नियमों और आवश्यकताओं को अग्रिम रूप से परिभाषित किया जाता है ताकि उन्हें एक नए डेटा भंडार के डिजाइन में शामिल किया जा सके या किसी मौजूदा के पुनरावृत्ति में अनुकूलित किया जा सके।
आदर्श रूप से, डेटा मॉडल जीवित दस्तावेज़ होते हैं जो बदलती व्यावसायिक आवश्यकताओं के साथ विकसित होते हैं। वे व्यावसायिक निर्णयों का समर्थन करने और सिस्टम आर्किटेक्चर और रणनीति की योजना बनाने में महत्वपूर्ण भूमिका निभाते हैं। डेटा मॉडल को उन डेटाबेस के साथ सिंक में रखा जाना चाहिए जिनका वे प्रतिनिधित्व करते हैं ताकि वे उन डेटाबेस के रखरखाव दिनचर्या के लिए उपयोगी हों।
आम डेटाबेस रखरखाव चुनौतियां
डेटाबेस को बनाए रखने के लिए निरंतर निगरानी की आवश्यकता होती है, स्वचालित या अन्यथा, यह सुनिश्चित करने के लिए कि यह अपने गुणों को नहीं खोता है। डेटाबेस रखरखाव सर्वोत्तम अभ्यास सुनिश्चित करते हैं कि डेटाबेस हमेशा अपना रखें:
- सूचना की सत्यता और गुणवत्ता
- प्रदर्शन
- उपलब्धता
- मापनीयता
- परिवर्तनों के अनुकूलता
- ट्रेसेबिलिटी
- सुरक्षा
हर बार एक अच्छा डेटाबेस डिज़ाइन बनाने में आपकी मदद करने के लिए कई डेटा मॉडलिंग युक्तियाँ उपलब्ध हैं। नीचे जिन पर चर्चा की गई है, उनका उद्देश्य विशेष रूप से ऊपर वर्णित डेटाबेस गुणों के रखरखाव को सुनिश्चित करना या सुविधाजनक बनाना है।
अखंडता और सूचना गुणवत्ता
डेटाबेस रखरखाव सर्वोत्तम प्रथाओं का एक मौलिक लक्ष्य यह सुनिश्चित करना है कि डेटाबेस में जानकारी अपनी अखंडता बनाए रखे। यह उपयोगकर्ताओं के लिए जानकारी में विश्वास बनाए रखने के लिए महत्वपूर्ण है।
अखंडता दो प्रकार की होती है:भौतिक अखंडता और तार्किक अखंडता ।
शारीरिक सत्यनिष्ठा
डेटाबेस की भौतिक अखंडता को बनाए रखना बाहरी कारकों जैसे हार्डवेयर या बिजली की विफलता से जानकारी की रक्षा करके किया जाता है। सबसे आम और व्यापक रूप से स्वीकृत दृष्टिकोण एक पर्याप्त बैकअप रणनीति के माध्यम से है जो एक उचित समय में एक डेटाबेस की पुनर्प्राप्ति की अनुमति देता है यदि कोई आपदा इसे नष्ट कर देती है।
डेटाबेस संग्रहण का प्रबंधन करने वाले DBA और सर्वर व्यवस्थापकों के लिए, यह जानना उपयोगी है कि क्या डेटाबेस को विभिन्न अद्यतन आवृत्तियों के साथ अनुभागों में विभाजित किया जा सकता है। यह उन्हें भंडारण उपयोग और बैकअप योजनाओं को अनुकूलित करने की अनुमति देता है।
डेटा मॉडल अलग-अलग डेटा "तापमान" के क्षेत्रों की पहचान करके और उन क्षेत्रों में संस्थाओं को समूहीकृत करके उस विभाजन को प्रतिबिंबित कर सकते हैं। "तापमान" उस आवृत्ति को संदर्भित करता है जिसके साथ तालिकाएँ नई जानकारी प्राप्त करती हैं। बहुत बार अद्यतन की जाने वाली तालिकाएँ "सबसे गर्म" होती हैं; वे जो कभी अपडेट नहीं होते या शायद ही कभी अपडेट होते हैं वे "सबसे ठंडे" होते हैं।

गर्म, गर्म और ठंडे डेटा में अंतर करने वाले ई-कॉमर्स सिस्टम का डेटा मॉडल।
एक DBA या सिस्टम एडमिनिस्ट्रेटर इस तार्किक समूह का उपयोग डेटाबेस फ़ाइलों को विभाजित करने और प्रत्येक विभाजन के लिए अलग बैकअप योजनाएँ बनाने के लिए कर सकता है।
तार्किक सत्यनिष्ठा
डेटाबेस की तार्किक अखंडता को बनाए रखना उसके द्वारा प्रदान की जाने वाली जानकारी की विश्वसनीयता और उपयोगिता के लिए आवश्यक है। यदि किसी डेटाबेस में तार्किक अखंडता का अभाव है, तो इसका उपयोग करने वाले एप्लिकेशन डेटा में विसंगतियों को जल्द या बाद में प्रकट करते हैं। इन विसंगतियों का सामना करते हुए, उपयोगकर्ता जानकारी पर भरोसा नहीं करते हैं और केवल अधिक विश्वसनीय डेटा स्रोतों की तलाश करते हैं।
डेटाबेस रखरखाव कार्यों के बीच, सूचना की तार्किक अखंडता को बनाए रखना डेटाबेस मॉडलिंग कार्य का एक विस्तार है, केवल यह कि यह डेटाबेस के उत्पादन में आने के बाद शुरू होता है और अपने पूरे जीवनकाल में जारी रहता है। रखरखाव के इस क्षेत्र का सबसे महत्वपूर्ण हिस्सा परिवर्तनों के अनुकूल होना है।
प्रबंधन बदलें
व्यावसायिक नियमों या आवश्यकताओं में परिवर्तन डेटाबेस की तार्किक अखंडता के लिए एक निरंतर खतरा है। आप अपने द्वारा बनाए गए डेटा मॉडल से खुश महसूस कर सकते हैं, यह जानते हुए कि यह व्यवसाय के लिए पूरी तरह से अनुकूलित है, कि यह किसी भी प्रश्न के लिए सही जानकारी के साथ प्रतिक्रिया करता है, और यह कि किसी भी प्रविष्टि, अद्यतन, या हटाने की विसंगतियों को छोड़ देता है। संतुष्टि के इस पल का आनंद लें, क्योंकि यह अल्पकालिक है!
डेटाबेस के रखरखाव में प्रतिदिन मॉडल में बदलाव करने की आवश्यकता का सामना करना पड़ता है। यह आपको नई वस्तुओं को जोड़ने या मौजूदा को बदलने, संबंधों की प्रमुखता को संशोधित करने, प्राथमिक कुंजियों को फिर से परिभाषित करने, डेटा प्रकार बदलने और अन्य चीजें करने के लिए मजबूर करता है जो हमें मॉडलर कांपते हैं।
परिवर्तन हर समय होते हैं। हो सकता है कि कुछ आवश्यकता को शुरू से ही गलत बताया गया हो, नई आवश्यकताएं सामने आई हों, या आपने अनजाने में अपने मॉडल में कुछ खामी पेश कर दी हो (आखिरकार, हम डेटा मॉडलर केवल मानव हैं)।
परिवर्तनों की आवश्यकता होने पर आपके मॉडल को संशोधित करना आसान होना चाहिए। मॉडलिंग के लिए डेटाबेस डिज़ाइन टूल का उपयोग करना महत्वपूर्ण है जो आपको अपने मॉडलों को संस्करणित करने, डेटाबेस को एक संस्करण से दूसरे संस्करण में माइग्रेट करने के लिए स्क्रिप्ट जेनरेट करने और प्रत्येक डिज़ाइन निर्णय को ठीक से दस्तावेज़ित करने की अनुमति देता है।
इन उपकरणों के बिना, आप अपने डिजाइन में किए गए प्रत्येक परिवर्तन से अखंडता जोखिम पैदा करते हैं जो सबसे अधिक समय पर प्रकाश में आते हैं। Vertabelo आपको यह सारी कार्यक्षमता देता है और आपके द्वारा इसके बारे में सोचने के बिना किसी मॉडल के संस्करण इतिहास को बनाए रखने का ख्याल रखता है।
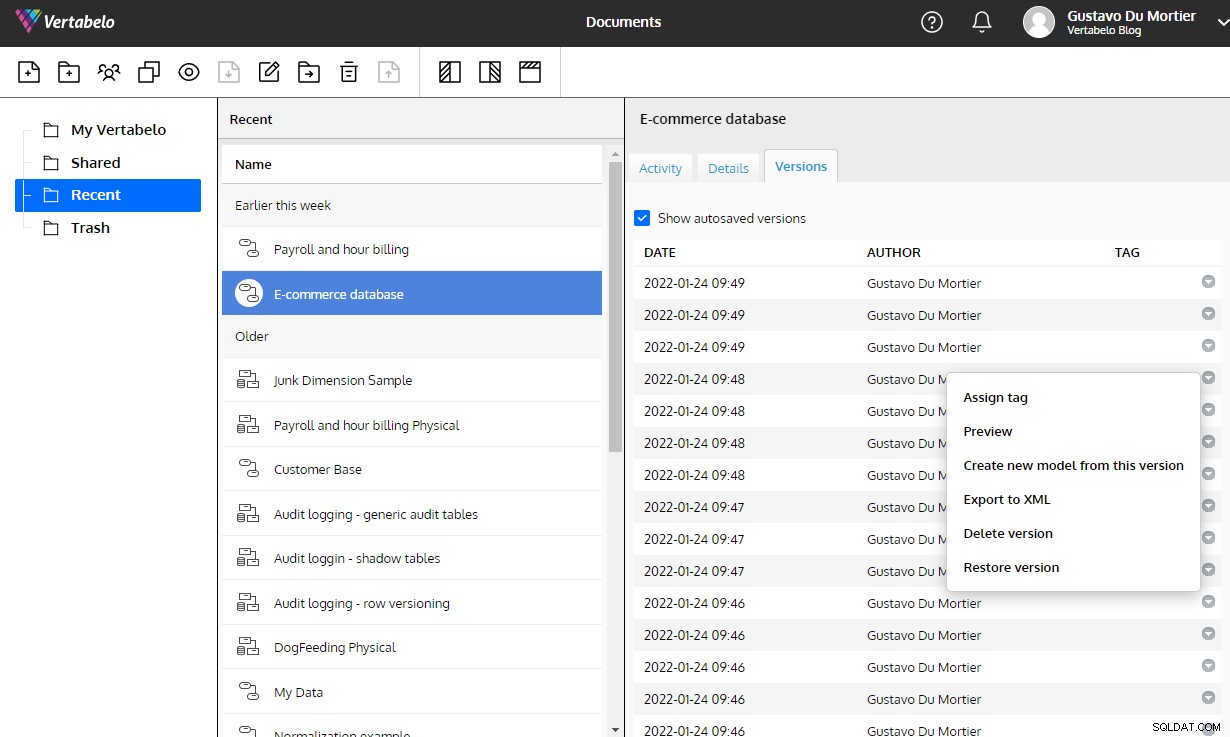
वर्टाबेलो में निर्मित स्वचालित संस्करण डेटा मॉडल में परिवर्तनों को बनाए रखने में एक जबरदस्त मदद है।
सॉफ्टवेयर विकास जीवनचक्र में डेटा मॉडलिंग गतिविधियों को एम्बेड करने में परिवर्तन प्रबंधन और संस्करण नियंत्रण भी महत्वपूर्ण कारक हैं।
रिफैक्टरिंग
जब आप उपयोग में आने वाले डेटाबेस में परिवर्तन लागू करते हैं, तो आपको 100% सुनिश्चित होना चाहिए कि कोई भी जानकारी गुम न हो और परिवर्तनों के परिणामस्वरूप इसकी अखंडता अप्रभावित रहे। ऐसा करने के लिए, आप रिफैक्टरिंग तकनीकों का उपयोग कर सकते हैं। वे आम तौर पर तब लागू होते हैं जब आप किसी डिज़ाइन को उसके शब्दार्थ को प्रभावित किए बिना सुधारना चाहते हैं, लेकिन उनका उपयोग डिज़ाइन त्रुटियों को ठीक करने या किसी मॉडल को नई आवश्यकताओं के अनुकूल बनाने के लिए भी किया जा सकता है।
बड़ी संख्या में रिफैक्टरिंग तकनीकें हैं। वे आम तौर पर विरासती डेटाबेस को नया जीवन देने के लिए नियोजित होते हैं, और पाठ्यपुस्तक प्रक्रियाएं हैं जो सुनिश्चित करती हैं कि परिवर्तन मौजूदा जानकारी को नुकसान नहीं पहुंचाते हैं। इसके बारे में पूरी किताबें लिखी गई हैं; मेरा सुझाव है कि आप उन्हें पढ़ें।
लेकिन संक्षेप में, हम रिफैक्टरिंग तकनीकों को निम्नलिखित श्रेणियों में समूहित कर सकते हैं:
- डेटा गुणवत्ता: डेटा स्थिरता और सुसंगतता सुनिश्चित करने वाले परिवर्तन करना। उदाहरणों में एक लुकअप टेबल जोड़ना और दूसरी टेबल में दोहराए गए डेटा को माइग्रेट करना और कॉलम पर एक बाधा जोड़ना शामिल है।
- संरचनात्मक: तालिका संरचनाओं में परिवर्तन करना जो मॉडल के शब्दार्थ को नहीं बदलते हैं। उदाहरणों में दो स्तंभों को एक में जोड़ना, एक स्थानापन्न कुंजी जोड़ना और एक स्तंभ को दो में विभाजित करना शामिल है।
- संदर्भात्मक अखंडता: यह सुनिश्चित करने के लिए परिवर्तन लागू करना कि संबंधित तालिका में एक संदर्भित पंक्ति मौजूद है या एक गैर-संदर्भित पंक्ति को हटाया जा सकता है। उदाहरणों में एक कॉलम पर एक विदेशी कुंजी बाधा जोड़ना और एक तालिका में एक गैर-शून्य मान बाधा जोड़ना शामिल है।
- वास्तुकला: डेटाबेस के साथ अनुप्रयोगों की बातचीत में सुधार लाने के उद्देश्य से परिवर्तन करना। उदाहरणों में शामिल हैं एक इंडेक्स बनाना, टेबल को केवल पढ़ने के लिए बनाना, और एक व्यू में एक या अधिक टेबल को इनकैप्सुलेट करना।
ऐसी तकनीकें जो मॉडल के शब्दार्थ को संशोधित करती हैं, साथ ही वे जो किसी भी तरह से डेटा मॉडल को नहीं बदलती हैं, उन्हें रिफैक्टरिंग तकनीक नहीं माना जाता है। इनमें तालिका में पंक्तियाँ सम्मिलित करना, नया स्तंभ जोड़ना, नई तालिका या दृश्य बनाना और तालिका में डेटा को अद्यतन करना शामिल है।
सूचना की गुणवत्ता बनाए रखना
एक डेटाबेस में सूचना की गुणवत्ता वह डिग्री है जिस तक डेटा सटीकता, वैधता, पूर्णता और स्थिरता के लिए संगठन की अपेक्षाओं को पूरा करता है। डेटाबेस के पूरे जीवन चक्र में डेटा गुणवत्ता बनाए रखना इसके उपयोगकर्ताओं के लिए डेटा का उपयोग करके सही और सूचित निर्णय लेने के लिए महत्वपूर्ण है।
डेटा मॉडलर के रूप में आपकी ज़िम्मेदारी यह सुनिश्चित करना है कि आपके मॉडल अपनी सूचना गुणवत्ता को उच्चतम संभव स्तर पर रखें। ऐसा करने के लिए:
- डिजाइन को कम से कम तीसरे सामान्य फॉर्म का पालन करना चाहिए ताकि सम्मिलन, अद्यतन, या हटाने संबंधी विसंगतियां उत्पन्न न हों। यह विचार मुख्य रूप से लेन-देन संबंधी उपयोग के लिए डेटाबेस पर लागू होता है, जहां डेटा को नियमित रूप से जोड़ा, अद्यतन और हटाया जाता है। यह विश्लेषणात्मक उपयोग (यानी, डेटा वेयरहाउस) के लिए डेटाबेस में सख्ती से लागू नहीं होता है, क्योंकि डेटा अपडेट और विलोपन शायद ही कभी किया जाता है।
- प्रत्येक तालिका में प्रत्येक फ़ील्ड के डेटा प्रकार उस विशेषता के लिए उपयुक्त होना चाहिए जो वे तार्किक मॉडल में प्रदर्शित करते हैं। यह ठीक से परिभाषित करने से परे है कि कोई फ़ील्ड संख्यात्मक, दिनांक या अल्फ़ान्यूमेरिक डेटा प्रकार का है या नहीं। प्रत्येक क्षेत्र द्वारा समर्थित मूल्यों की सीमा और सटीकता को सही ढंग से परिभाषित करना भी महत्वपूर्ण है। एक उदाहरण:दिनांक/समय फ़ील्ड के रूप में डेटाबेस में कार्यान्वित दिनांक प्रकार की विशेषता प्रश्नों में समस्या पैदा कर सकती है, क्योंकि शून्य के अलावा इसके समय भाग के साथ संग्रहीत मान किसी दिनांक सीमा का उपयोग करने वाली क्वेरी के दायरे से बाहर हो सकता है।
- डेटा वेयरहाउस की संरचना को परिभाषित करने वाले आयाम और तथ्य व्यवसाय की आवश्यकताओं के अनुरूप होने चाहिए। डेटा वेयरहाउस डिजाइन करते समय, मॉडल के आयामों और तथ्यों को शुरुआत से ही सही ढंग से परिभाषित किया जाना चाहिए। डेटाबेस के चालू होने के बाद संशोधन करना बहुत अधिक रखरखाव लागत के साथ आता है।
विकास का प्रबंधन
डेटाबेस को बनाए रखने में एक और बड़ी चुनौती इसकी वृद्धि को अप्रत्याशित रूप से भंडारण क्षमता सीमा तक पहुंचने से रोक रही है। भंडारण स्थान प्रबंधन में सहायता के लिए, आप बैकअप प्रक्रियाओं में उपयोग किए गए समान सिद्धांत को लागू कर सकते हैं:अपने मॉडल में तालिकाओं को उनके बढ़ने की दर के अनुसार समूहित करें।
आमतौर पर दो क्षेत्रों में विभाजन पर्याप्त होता है। एक क्षेत्र में लगातार पंक्ति परिवर्धन के साथ तालिकाओं को रखें, जिनमें पंक्तियों को दूसरे में शायद ही कभी डाला जाता है। इस तरह से मॉडल को सेक्टर में रखने से स्टोरेज एडमिनिस्ट्रेटर को प्रत्येक क्षेत्र की विकास दर के अनुसार डेटाबेस फाइलों को विभाजित करने की अनुमति मिलती है। वे अलग-अलग क्षमता या विकास संभावनाओं के साथ अलग-अलग स्टोरेज मीडिया के बीच विभाजन वितरित कर सकते हैं।
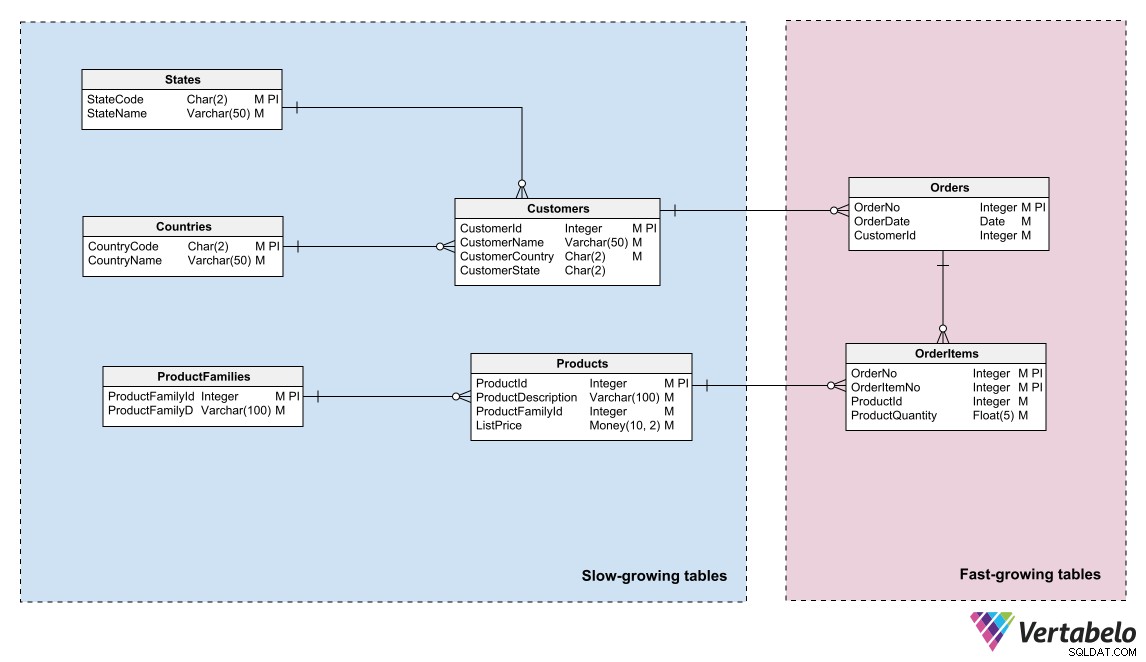
तालिकाओं को उनकी वृद्धि दर के आधार पर समूहित करने से भंडारण आवश्यकताओं को निर्धारित करने और इसके विकास को प्रबंधित करने में मदद मिलती है।
लॉगिंग
हम एक डेटा मॉडल बनाते हैं जो यह अपेक्षा करता है कि यह जानकारी प्रदान करे जैसा कि यह क्वेरी के समय है। हालांकि, हम अतीत में हुई हर चीज को याद रखने के लिए डेटाबेस की आवश्यकता को नजरअंदाज कर देते हैं, जब तक कि उपयोगकर्ताओं को विशेष रूप से इसकी आवश्यकता न हो।
डेटाबेस को बनाए रखने का एक हिस्सा यह जानना है कि कैसे, कब, क्यों और किसके द्वारा डेटा का एक विशेष टुकड़ा बदल दिया गया था। यह उन चीजों के लिए हो सकता है जैसे किसी उत्पाद की कीमत में बदलाव का पता लगाना या अस्पताल में किसी मरीज के मेडिकल रिकॉर्ड में बदलाव की समीक्षा करना। लॉगिंग का उपयोग उपयोगकर्ता या एप्लिकेशन त्रुटियों को ठीक करने के लिए भी किया जा सकता है क्योंकि यह आपको जटिल बैकअप बहाली प्रक्रियाओं का सहारा लिए बिना जानकारी की स्थिति को अतीत में वापस लाने की अनुमति देता है।
फिर से, भले ही उपयोगकर्ताओं को इसकी स्पष्ट रूप से आवश्यकता न हो, सक्रिय लॉगिंग की आवश्यकता पर विचार करना डेटाबेस रखरखाव को सुविधाजनक बनाने और समस्याओं का अनुमान लगाने की आपकी क्षमता का प्रदर्शन करने का एक बहुत ही मूल्यवान साधन है। जब किसी को ऐतिहासिक जानकारी की समीक्षा करने की आवश्यकता होती है, तो लॉगिंग डेटा होने से तत्काल प्रतिक्रिया की अनुमति मिलती है।
लॉगिंग का समर्थन करने के लिए डेटाबेस मॉडल के लिए अलग-अलग रणनीतियां हैं, जो सभी मॉडल में जटिलता जोड़ती हैं। एक दृष्टिकोण को इन-प्लेस लॉगिंग कहा जाता है, जो संस्करण की जानकारी रिकॉर्ड करने के लिए प्रत्येक तालिका में कॉलम जोड़ता है। यह एक आसान विकल्प है जिसमें अलग स्कीमा या लॉगिंग-विशिष्ट टेबल बनाना शामिल नहीं है। हालाँकि, यह मॉडल डिज़ाइन को प्रभावित करता है क्योंकि तालिकाओं की मूल प्राथमिक कुंजियाँ अब प्राथमिक कुंजियों के रूप में मान्य नहीं हैं - उनके मान पंक्तियों में दोहराए जाते हैं जो एक ही डेटा के विभिन्न संस्करणों का प्रतिनिधित्व करते हैं।
लॉग जानकारी रखने का एक अन्य विकल्प शैडो टेबल का उपयोग करना है। शैडो टेबल लॉग ट्रेल डेटा रिकॉर्ड करने के लिए कॉलम के अतिरिक्त मॉडल टेबल की प्रतिकृतियां हैं। इस रणनीति के लिए मूल मॉडल में तालिकाओं को संशोधित करने की आवश्यकता नहीं है, लेकिन जब आप अपना डेटा मॉडल बदलते हैं तो आपको संबंधित छाया तालिकाओं को अपडेट करना याद रखना होगा।
फिर भी एक अन्य रणनीति सामान्य तालिकाओं की एक उपयोजना को नियोजित करना है जो किसी अन्य तालिका में प्रत्येक सम्मिलन, विलोपन या संशोधन को रिकॉर्ड करती है।
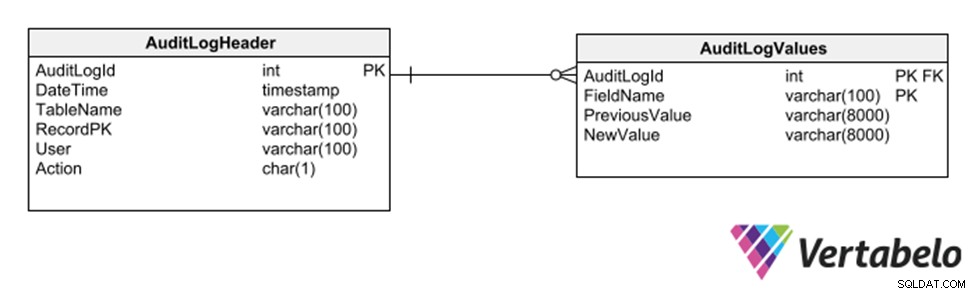
डेटाबेस का ऑडिट ट्रेल रखने के लिए सामान्य तालिकाएँ।
इस रणनीति का यह फायदा है कि ऑडिट ट्रेल को रिकॉर्ड करने के लिए मॉडल में संशोधन की आवश्यकता नहीं है। हालांकि, क्योंकि यह वर्चर प्रकार के सामान्य कॉलम का उपयोग करता है, यह डेटा के प्रकार को सीमित करता है जिसे लॉग ट्रेल में रिकॉर्ड किया जा सकता है।
प्रदर्शन रखरखाव और अनुक्रमणिका निर्माण
व्यावहारिक रूप से किसी भी डेटाबेस का अच्छा प्रदर्शन होता है जब इसका उपयोग शुरू होता है और इसकी तालिकाओं में केवल कुछ पंक्तियां होती हैं। लेकिन जैसे ही एप्लिकेशन इसे डेटा से भरना शुरू करते हैं, अगर मॉडल को डिजाइन करने में सावधानी नहीं बरती जाती है तो प्रदर्शन बहुत जल्दी खराब हो सकता है। जब ऐसा होता है, तो DBA और सिस्टम एडमिनिस्ट्रेटर प्रदर्शन समस्याओं को हल करने में उनकी मदद करने के लिए आपसे संपर्क करते हैं।
उत्पादन डेटाबेस पर अनुक्रमणिका का स्वत:निर्माण/सुझाव प्रदर्शन समस्याओं को हल करने के लिए "पल की गर्मी में" एक उपयोगी उपकरण है। डेटाबेस इंजन यह देखने के लिए डेटाबेस गतिविधियों का विश्लेषण कर सकते हैं कि कौन से संचालन में सबसे लंबा समय लगता है और जहां इंडेक्स बनाकर तेजी लाने के अवसर हैं।
हालांकि, डेटा मॉडल के हिस्से के रूप में इंडेक्स को परिभाषित करके सक्रिय होना और स्थिति का अनुमान लगाना बेहतर है। यह डेटाबेस के प्रदर्शन में सुधार के लिए रखरखाव के प्रयासों को बहुत कम करता है। यदि आप डेटाबेस इंडेक्स के लाभों से परिचित नहीं हैं, तो मेरा सुझाव है कि इंडेक्स के बारे में सब कुछ पढ़ना शुरू करें, मूल बातें से शुरू करें।
ऐसे व्यावहारिक नियम हैं जो कुशल प्रश्नों के लिए सबसे महत्वपूर्ण अनुक्रमणिका बनाने के लिए पर्याप्त मार्गदर्शन प्रदान करते हैं। पहला प्रत्येक तालिका की प्राथमिक कुंजी के लिए अनुक्रमणिका उत्पन्न करना है। व्यावहारिक रूप से प्रत्येक आरडीबीएमएस प्रत्येक प्राथमिक कुंजी के लिए स्वचालित रूप से एक अनुक्रमणिका उत्पन्न करता है, ताकि आप इस नियम को भूल सकें।
एक अन्य नियम तालिका की वैकल्पिक कुंजियों के लिए अनुक्रमणिका बनाना है, विशेष रूप से उन तालिकाओं में जिसके लिए एक सरोगेट कुंजी बनाई गई है। यदि किसी तालिका में एक प्राकृतिक कुंजी है जिसका उपयोग प्राथमिक कुंजी के रूप में नहीं किया जाता है, तो उस तालिका में दूसरों के साथ जुड़ने के लिए प्रश्न प्राकृतिक कुंजी के साथ ऐसा करने की संभावना है, सरोगेट नहीं। जब तक आप नेचुरल की पर एक इंडेक्स नहीं बनाते, तब तक वे क्वेरीज़ अच्छा प्रदर्शन नहीं करती हैं।
इंडेक्स के लिए अंगूठे का अगला नियम उन सभी क्षेत्रों के लिए उत्पन्न करना है जो विदेशी कुंजी हैं। अन्य तालिकाओं के साथ जुड़ने के लिए ये क्षेत्र महान उम्मीदवार हैं। यदि उन्हें इंडेक्स में शामिल किया जाता है, तो उनका उपयोग क्वेरी पार्सर्स द्वारा निष्पादन में तेजी लाने और डेटाबेस के प्रदर्शन को बेहतर बनाने के लिए किया जाता है।
अंत में, प्रदर्शन परीक्षणों के दौरान स्टेजिंग या क्यूए डेटाबेस पर प्रोफाइलिंग टूल का उपयोग करना एक अच्छा विचार है ताकि किसी भी इंडेक्स निर्माण के अवसरों का पता लगाया जा सके जो स्पष्ट नहीं हैं। प्रोफाइलिंग टूल द्वारा सुझाए गए इंडेक्स को डेटा मॉडल में शामिल करना डेटाबेस के उत्पादन में होने के बाद उसके प्रदर्शन को प्राप्त करने और बनाए रखने में अत्यंत सहायक होता है।
सुरक्षा
डेटा मॉडलर के रूप में आपकी भूमिका में, आप उपयोगकर्ता प्रमाणीकरण के लिए डेटा संग्रहीत करने के लिए एक ठोस और सुरक्षित आधार प्रदान करके डेटाबेस सुरक्षा बनाए रखने में सहायता कर सकते हैं। ध्यान रखें कि यह जानकारी अत्यधिक संवेदनशील है और इसे साइबर हमलों के संपर्क में नहीं लाया जाना चाहिए।
डेटाबेस सुरक्षा के रखरखाव को सरल बनाने के लिए आपके डिज़ाइन के लिए, प्रमाणीकरण डेटा को संग्रहीत करने के लिए सर्वोत्तम प्रथाओं का पालन करें, जिनमें से एक मुख्य रूप से एन्क्रिप्टेड रूप में भी डेटाबेस में पासवर्ड संग्रहीत नहीं करना है। प्रत्येक उपयोगकर्ता के लिए पासवर्ड के बजाय केवल अपने हैश को संग्रहीत करने से एप्लिकेशन को पासवर्ड जोखिम जोखिम पैदा किए बिना उपयोगकर्ता लॉगिन को प्रमाणित करने की अनुमति मिलती है।
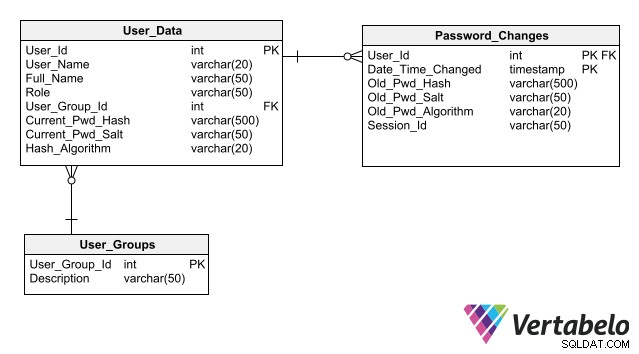
उपयोगकर्ता प्रमाणीकरण के लिए एक पूर्ण स्कीमा जिसमें पासवर्ड हैश संग्रहीत करने के लिए कॉलम शामिल हैं।
भविष्य के लिए दृष्टि
तो, ऊपर दिए गए सुझावों को ध्यान में रखते हुए अच्छे डेटाबेस डिज़ाइन के साथ आसान डेटाबेस रखरखाव के लिए अपने मॉडल बनाएं। अधिक रखरखाव योग्य डेटा मॉडल के साथ, आपका काम बेहतर दिखता है, और आपको डीबीए, रखरखाव इंजीनियरों और सिस्टम प्रशासकों की सराहना मिलती है।
आप मन की शांति में भी निवेश करते हैं। आसानी से बनाए रखने योग्य डेटाबेस बनाने का मतलब है कि आप समय पर सही जानकारी देने में विफल रहने वाले डेटाबेस को पैच करने के बजाय नए डेटा मॉडल तैयार करने में अपने काम के घंटे बिता सकते हैं।