सभी सॉफ़्टवेयर एप्लिकेशन डेटा के साथ इंटरैक्ट करते हैं , आमतौर पर एक डेटाबेस प्रबंधन प्रणाली (DBMS) के माध्यम से। कुछ प्रोग्रामिंग भाषाएं मॉड्यूल के साथ आती हैं जिनका उपयोग आप डीबीएमएस के साथ बातचीत करने के लिए कर सकते हैं, जबकि अन्य को तीसरे पक्ष के पैकेज के उपयोग की आवश्यकता होती है। इस ट्यूटोरियल में, आप विभिन्न पायथन SQL लाइब्रेरी के बारे में जानेंगे जिसका आप उपयोग कर सकते हैं। आप SQLite, MySQL और PostgreSQL डेटाबेस के साथ इंटरैक्ट करने के लिए एक सीधा एप्लिकेशन विकसित करेंगे।
इस ट्यूटोरियल में, आप सीखेंगे कि कैसे:
- कनेक्ट करें पायथन एसक्यूएल पुस्तकालयों के साथ विभिन्न डेटाबेस प्रबंधन प्रणालियों के लिए
- बातचीत करें SQLite, MySQL और PostgreSQL डेटाबेस के साथ
- प्रदर्शन पायथन एप्लिकेशन का उपयोग कर सामान्य डेटाबेस क्वेरी
- विकसित करें पायथन लिपि का उपयोग करते हुए विभिन्न डेटाबेस में अनुप्रयोग
इस ट्यूटोरियल का अधिकतम लाभ उठाने के लिए, आपको बुनियादी पायथन, एसक्यूएल और डेटाबेस प्रबंधन प्रणालियों के साथ काम करने का ज्ञान होना चाहिए। आपको पायथन में पैकेज डाउनलोड और आयात करने में सक्षम होना चाहिए और स्थानीय या दूरस्थ रूप से विभिन्न डेटाबेस सर्वरों को स्थापित और चलाने का तरीका पता होना चाहिए।
मुफ्त PDF डाउनलोड: पायथन 3 चीट शीट
डेटाबेस स्कीमा को समझना
इस ट्यूटोरियल में, आप सोशल मीडिया एप्लिकेशन के लिए एक बहुत छोटा डेटाबेस विकसित करेंगे। डेटाबेस में चार टेबल होंगे:
userspostscommentslikes
डेटाबेस स्कीमा का एक उच्च-स्तरीय आरेख नीचे दिखाया गया है:
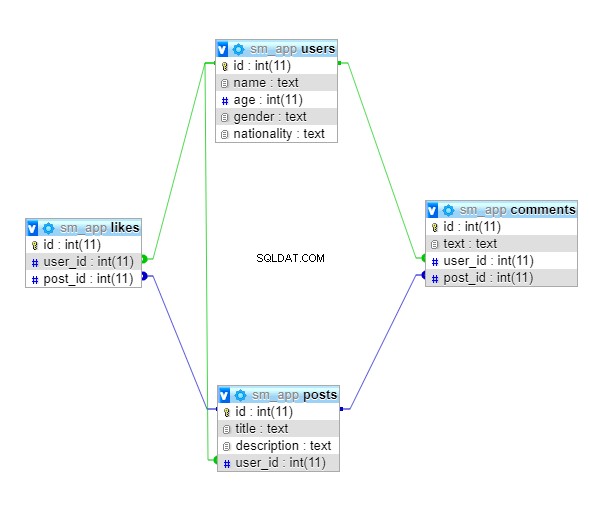
दोनों users और posts एक-से-अनेक संबंध होंगे क्योंकि एक उपयोगकर्ता कई पोस्ट पसंद कर सकता है। इसी तरह, एक उपयोगकर्ता कई टिप्पणियाँ पोस्ट कर सकता है, और एक पोस्ट में कई टिप्पणियाँ भी हो सकती हैं। तो, दोनों users और posts comments . के साथ एक-से-अनेक संबंध भी होंगे टेबल। यह likes . पर भी लागू होता है तालिका, इसलिए दोनों users और posts likes . के साथ एक-से-अनेक संबंध होगा टेबल।
किसी डेटाबेस से कनेक्ट करने के लिए Python SQL लाइब्रेरी का उपयोग करना
इससे पहले कि आप किसी भी डेटाबेस के साथ Python SQL लाइब्रेरी के माध्यम से इंटरैक्ट करें, आपको कनेक्ट . करना होगा उस डेटाबेस के लिए। इस खंड में, आप देखेंगे कि पायथन एप्लिकेशन के भीतर से SQLite, MySQL और PostgreSQL डेटाबेस से कैसे कनेक्ट किया जाए।
नोट: MySQL और PostgreSQL डेटाबेस अनुभागों में स्क्रिप्ट निष्पादित करने से पहले आपको MySQL और PostgreSQL सर्वर की आवश्यकता होगी। एक MySQL सर्वर कैसे शुरू करें, इस पर एक त्वरित परिचय के लिए, Django प्रोजेक्ट शुरू करने का MySQL अनुभाग देखें। PostgreSQL में डेटाबेस बनाने का तरीका जानने के लिए, Python के साथ SQL इंजेक्शन हमलों को रोकने के लिए एक डेटाबेस सेट करना अनुभाग देखें।
यह अनुशंसा की जाती है कि आप तीन अलग-अलग पायथन फाइलें बनाएं, इसलिए आपके पास तीन डेटाबेस में से प्रत्येक के लिए एक है। आप प्रत्येक डेटाबेस के लिए उसकी संबंधित फ़ाइल में स्क्रिप्ट निष्पादित करेंगे।
SQLite
SQLite पायथन एप्लिकेशन से जुड़ने के लिए शायद सबसे सीधा डेटाबेस है क्योंकि ऐसा करने के लिए आपको किसी बाहरी पायथन एसक्यूएल मॉड्यूल को स्थापित करने की आवश्यकता नहीं है। डिफ़ॉल्ट रूप से, आपके पायथन इंस्टॉलेशन में sqlite3 . नामक एक Python SQL लाइब्रेरी होती है जिसे आप SQLite डेटाबेस के साथ इंटरैक्ट करने के लिए उपयोग कर सकते हैं।
इसके अलावा, SQLite डेटाबेस सर्वर रहित हैं और स्व-निहित , क्योंकि वे फ़ाइल में डेटा पढ़ते और लिखते हैं। इसका मतलब है कि, MySQL और PostgreSQL के विपरीत, आपको डेटाबेस संचालन करने के लिए SQLite सर्वर को स्थापित करने और चलाने की भी आवश्यकता नहीं है!
यहां बताया गया है कि आप sqlite3 का उपयोग कैसे करते हैं Python में SQLite डेटाबेस से कनेक्ट करने के लिए:
1import sqlite3
2from sqlite3 import Error
3
4def create_connection(path):
5 connection = None
6 try:
7 connection = sqlite3.connect(path)
8 print("Connection to SQLite DB successful")
9 except Error as e:
10 print(f"The error '{e}' occurred")
11
12 return connection
यहां बताया गया है कि यह कोड कैसे काम करता है:
- पंक्ति 1 और 2 आयात
sqlite3और मॉड्यूल कीErrorकक्षा। - पंक्ति 4 एक फ़ंक्शन को परिभाषित करता है
.create_connection()जो SQLite डेटाबेस के पथ को स्वीकार करता है। - पंक्ति 7
.connect(). का उपयोग करता हैsqlite3. से मॉड्यूल और पैरामीटर के रूप में SQLite डेटाबेस पथ लेता है। यदि डेटाबेस निर्दिष्ट स्थान पर मौजूद है, तो डेटाबेस से कनेक्शन स्थापित हो जाता है। अन्यथा, निर्दिष्ट स्थान पर एक नया डेटाबेस बनाया जाता है, और एक कनेक्शन स्थापित किया जाता है। - पंक्ति 8 सफल डेटाबेस कनेक्शन की स्थिति को प्रिंट करता है।
- पंक्ति 9 किसी भी अपवाद को पकड़ता है जिसे फेंका जा सकता है यदि
.connect()एक कनेक्शन स्थापित करने में विफल रहता है। - पंक्ति 10 कंसोल में त्रुटि संदेश प्रदर्शित करता है।
sqlite3.connect(path) एक connection देता है ऑब्जेक्ट, जो बदले में create_connection() . द्वारा लौटाया जाता है . यह connection ऑब्जेक्ट का उपयोग SQLite डेटाबेस पर प्रश्नों को निष्पादित करने के लिए किया जा सकता है। निम्न स्क्रिप्ट SQLite डेटाबेस से कनेक्शन बनाती है:
connection = create_connection("E:\\sm_app.sqlite")
उपरोक्त स्क्रिप्ट को निष्पादित करने के बाद, आप देखेंगे कि एक डेटाबेस फ़ाइल sm_app.sqlite रूट डायरेक्टरी में बनाया गया है। ध्यान दें कि आप अपने सेटअप से मेल खाने के लिए स्थान बदल सकते हैं।
MySQL
SQLite के विपरीत, कोई डिफ़ॉल्ट Python SQL मॉड्यूल नहीं है जिसका उपयोग आप MySQL डेटाबेस से कनेक्ट करने के लिए कर सकते हैं। इसके बजाय, आपको एक पायथन SQL ड्राइवर स्थापित करना होगा MySQL के लिए एक पायथन एप्लिकेशन के भीतर से एक MySQL डेटाबेस के साथ बातचीत करने के लिए। ऐसा ही एक ड्राइवर है mysql-connector-python . आप इस Python SQL मॉड्यूल को pip . के साथ डाउनलोड कर सकते हैं :
$ pip install mysql-connector-python
ध्यान दें कि MySQL एक सर्वर-आधारित है डेटाबेस प्रबंधन प्रणाली। एक MySQL सर्वर में कई डेटाबेस हो सकते हैं। SQLite के विपरीत, जहां कनेक्शन बनाना एक डेटाबेस बनाने के समान है, एक MySQL डेटाबेस में डेटाबेस निर्माण के लिए दो-चरणीय प्रक्रिया होती है:
- कनेक्शन बनाएं एक MySQL सर्वर के लिए।
- एक अलग क्वेरी निष्पादित करें डेटाबेस बनाने के लिए।
एक फ़ंक्शन को परिभाषित करें जो MySQL डेटाबेस सर्वर से जुड़ता है और कनेक्शन ऑब्जेक्ट देता है:
1import mysql.connector
2from mysql.connector import Error
3
4def create_connection(host_name, user_name, user_password):
5 connection = None
6 try:
7 connection = mysql.connector.connect(
8 host=host_name,
9 user=user_name,
10 passwd=user_password
11 )
12 print("Connection to MySQL DB successful")
13 except Error as e:
14 print(f"The error '{e}' occurred")
15
16 return connection
17
18connection = create_connection("localhost", "root", "")
उपरोक्त स्क्रिप्ट में, आप एक फ़ंक्शन को परिभाषित करते हैं create_connection() जो तीन पैरामीटर स्वीकार करता है:
- होस्ट_नाम
- उपयोगकर्ता_नाम
- user_password
mysql.connector पायथन एसक्यूएल मॉड्यूल में एक विधि है .connect() जिसका उपयोग आप लाइन 7 में MySQL डेटाबेस सर्वर से कनेक्ट करने के लिए करते हैं। एक बार कनेक्शन स्थापित हो जाने के बाद, connection ऑब्जेक्ट कॉलिंग फ़ंक्शन पर वापस आ जाता है। अंत में, लाइन 18 में आप create_connection() . पर कॉल करें होस्ट नाम, उपयोगकर्ता नाम और पासवर्ड के साथ।
अब तक, आपने केवल कनेक्शन स्थापित किया है। डेटाबेस अभी तक नहीं बना है। ऐसा करने के लिए, आप एक अन्य फ़ंक्शन को परिभाषित करेंगे create_database() जो दो पैरामीटर स्वीकार करता है:
connectionconnectionहै उस डेटाबेस सर्वर पर आपत्ति करें जिसके साथ आप इंटरैक्ट करना चाहते हैं।queryवह क्वेरी है जो डेटाबेस बनाती है।
यह फ़ंक्शन कैसा दिखता है:
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("Database created successfully")
except Error as e:
print(f"The error '{e}' occurred")
क्वेरी निष्पादित करने के लिए, आप cursor . का उपयोग करते हैं वस्तु। query निष्पादित करने के लिए cursor.execute() . को पास किया जाता है स्ट्रिंग प्रारूप में।
sm_app . नाम से एक डेटाबेस बनाएं MySQL डेटाबेस सर्वर में आपके सोशल मीडिया ऐप के लिए:
create_database_query = "CREATE DATABASE sm_app"
create_database(connection, create_database_query)
अब आपने एक डेटाबेस बना लिया है sm_app डेटाबेस सर्वर पर। हालांकि, connection create_connection() . द्वारा लौटाई गई वस्तु MySQL डेटाबेस सर्वर से जुड़ा है। आपको sm_app . से कनेक्ट करना होगा डेटाबेस। ऐसा करने के लिए, आप create_connection() . को संशोधित कर सकते हैं इस प्रकार है:
1def create_connection(host_name, user_name, user_password, db_name):
2 connection = None
3 try:
4 connection = mysql.connector.connect(
5 host=host_name,
6 user=user_name,
7 passwd=user_password,
8 database=db_name
9 )
10 print("Connection to MySQL DB successful")
11 except Error as e:
12 print(f"The error '{e}' occurred")
13
14 return connection
आप पंक्ति 8 में देख सकते हैं कि create_connection() अब एक अतिरिक्त पैरामीटर स्वीकार करता है जिसे db_name . कहा जाता है . यह पैरामीटर उस डेटाबेस का नाम निर्दिष्ट करता है जिससे आप कनेक्ट करना चाहते हैं। जब आप इस फ़ंक्शन को कॉल करते हैं तो आप उस डेटाबेस के नाम से पास कर सकते हैं जिसे आप कनेक्ट करना चाहते हैं:
connection = create_connection("localhost", "root", "", "sm_app")
उपरोक्त स्क्रिप्ट सफलतापूर्वक create_connection() को कॉल करती है और sm_app . से जुड़ता है डेटाबेस।
पोस्टग्रेएसक्यूएल
MySQL की तरह, कोई डिफ़ॉल्ट पायथन SQL लाइब्रेरी नहीं है जिसका उपयोग आप PostgreSQL डेटाबेस के साथ बातचीत करने के लिए कर सकते हैं। इसके बजाय, आपको एक तृतीय-पक्ष Python SQL ड्राइवर स्थापित करने की आवश्यकता है PostgreSQL के साथ बातचीत करने के लिए। PostgreSQL के लिए ऐसा ही एक Python SQL ड्राइवर है psycopg2 . psycopg2 . को इंस्टाल करने के लिए अपने टर्मिनल पर निम्न कमांड निष्पादित करें पायथन एसक्यूएल मॉड्यूल:
$ pip install psycopg2
SQLite और MySQL डेटाबेस की तरह, आप create_connection() . को परिभाषित करेंगे अपने PostgreSQL डेटाबेस के साथ संबंध बनाने के लिए:
import psycopg2
from psycopg2 import OperationalError
def create_connection(db_name, db_user, db_password, db_host, db_port):
connection = None
try:
connection = psycopg2.connect(
database=db_name,
user=db_user,
password=db_password,
host=db_host,
port=db_port,
)
print("Connection to PostgreSQL DB successful")
except OperationalError as e:
print(f"The error '{e}' occurred")
return connection
आप psycopg2.connect() . का उपयोग करते हैं अपने पायथन एप्लिकेशन के भीतर से PostgreSQL सर्वर से कनेक्ट करने के लिए।
फिर आप create_connection() . का उपयोग कर सकते हैं PostgreSQL डेटाबेस से कनेक्शन बनाने के लिए। सबसे पहले, आप डिफ़ॉल्ट डेटाबेस postgres . के साथ संबंध बनाएंगे निम्नलिखित स्ट्रिंग का उपयोग करके:
connection = create_connection(
"postgres", "postgres", "abc123", "127.0.0.1", "5432"
)
इसके बाद, आपको डेटाबेस बनाना होगा sm_app डिफ़ॉल्ट के अंदर postgres डेटाबेस। आप PostgreSQL में किसी भी SQL क्वेरी को निष्पादित करने के लिए एक फ़ंक्शन को परिभाषित कर सकते हैं। नीचे, आप create_database() . को परिभाषित करते हैं PostgreSQL डेटाबेस सर्वर में एक नया डेटाबेस बनाने के लिए:
def create_database(connection, query):
connection.autocommit = True
cursor = connection.cursor()
try:
cursor.execute(query)
print("Query executed successfully")
except OperationalError as e:
print(f"The error '{e}' occurred")
create_database_query = "CREATE DATABASE sm_app"
create_database(connection, create_database_query)
ऊपर स्क्रिप्ट चलाने के बाद, आपको sm_app . दिखाई देगा आपके PostgreSQL डेटाबेस सर्वर में डेटाबेस।
sm_app . पर क्वेरी निष्पादित करने से पहले डेटाबेस, आपको इससे कनेक्ट करने की आवश्यकता है:
connection = create_connection(
"sm_app", "postgres", "abc123", "127.0.0.1", "5432"
)
एक बार जब आप उपरोक्त स्क्रिप्ट को निष्पादित कर लेते हैं, तो sm_app . के साथ एक कनेक्शन स्थापित हो जाएगा postgres . में स्थित डेटाबेस डेटाबेस सर्वर। यहां, 127.0.0.1 डेटाबेस सर्वर होस्ट आईपी पते को संदर्भित करता है, और 5432 डेटाबेस सर्वर के पोर्ट नंबर को संदर्भित करता है।
टेबल बनाना
पिछले खंड में, आपने देखा कि विभिन्न पायथन एसक्यूएल पुस्तकालयों का उपयोग करके SQLite, MySQL और PostgreSQL डेटाबेस सर्वर से कैसे कनेक्ट किया जाए। आपने sm_app . बनाया है सभी तीन डेटाबेस सर्वर पर डेटाबेस। इस अनुभाग में, आप देखेंगे कि तालिकाएं कैसे बनाएं इन तीन डेटाबेस के अंदर।
जैसा कि पहले चर्चा की गई है, आप चार टेबल बनाएंगे:
userspostscommentslikes
आप SQLite से शुरुआत करेंगे।
SQLite
SQLite में क्वेरी निष्पादित करने के लिए, cursor.execute() use का उपयोग करें . इस सेक्शन में, आप एक फ़ंक्शन को परिभाषित करेंगे execute_query() जो इस पद्धति का उपयोग करता है। आपका फ़ंक्शन connection स्वीकार करेगा ऑब्जेक्ट और एक क्वेरी स्ट्रिंग, जिसे आप cursor.execute() . पर पास करेंगे ।
.execute() स्ट्रिंग के रूप में इसे पास की गई किसी भी क्वेरी को निष्पादित कर सकता है। आप इस खंड में टेबल बनाने के लिए इस पद्धति का उपयोग करेंगे। आगामी अनुभागों में, आप अपडेट को निष्पादित करने और प्रश्नों को हटाने के लिए भी इसी विधि का उपयोग करेंगे।
नोट: इस स्क्रिप्ट को उसी फ़ाइल में निष्पादित किया जाना चाहिए जहां आपने अपने SQLite डेटाबेस के लिए कनेक्शन बनाया था।
यहां आपकी फ़ंक्शन परिभाषा है:
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query executed successfully")
except Error as e:
print(f"The error '{e}' occurred")
यह कोड दिए गए query . को निष्पादित करने का प्रयास करता है और यदि आवश्यक हो तो एक त्रुटि संदेश प्रिंट करता है।
इसके बाद, अपनी क्वेरी write लिखें :
create_users_table = """
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
age INTEGER,
gender TEXT,
nationality TEXT
);
"""
यह एक टेबल बनाने के लिए कहता है users निम्नलिखित पाँच स्तंभों के साथ:
idnameagegendernationality
अंत में, आप execute_query() . को कॉल करेंगे तालिका बनाने के लिए। आप connection . में पास होंगे ऑब्जेक्ट जिसे आपने पिछले अनुभाग में create_users_table . के साथ बनाया था स्ट्रिंग जिसमें तालिका बनाएं क्वेरी शामिल है:
execute_query(connection, create_users_table)
posts बनाने के लिए निम्न क्वेरी का उपयोग किया जाता है तालिका:
create_posts_table = """
CREATE TABLE IF NOT EXISTS posts(
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT NOT NULL,
description TEXT NOT NULL,
user_id INTEGER NOT NULL,
FOREIGN KEY (user_id) REFERENCES users (id)
);
"""
चूंकि users . के बीच एक-से-अनेक संबंध है और posts , आप एक विदेशी कुंजी देख सकते हैं user_id posts . में तालिका जो id . का संदर्भ देती है users . में कॉलम टेबल। posts बनाने के लिए निम्न स्क्रिप्ट निष्पादित करें तालिका:
execute_query(connection, create_posts_table)
अंत में, आप comments बना सकते हैं और likes निम्नलिखित स्क्रिप्ट के साथ टेबल:
create_comments_table = """
CREATE TABLE IF NOT EXISTS comments (
id INTEGER PRIMARY KEY AUTOINCREMENT,
text TEXT NOT NULL,
user_id INTEGER NOT NULL,
post_id INTEGER NOT NULL,
FOREIGN KEY (user_id) REFERENCES users (id) FOREIGN KEY (post_id) REFERENCES posts (id)
);
"""
create_likes_table = """
CREATE TABLE IF NOT EXISTS likes (
id INTEGER PRIMARY KEY AUTOINCREMENT,
user_id INTEGER NOT NULL,
post_id integer NOT NULL,
FOREIGN KEY (user_id) REFERENCES users (id) FOREIGN KEY (post_id) REFERENCES posts (id)
);
"""
execute_query(connection, create_comments_table)
execute_query(connection, create_likes_table)
आप देख सकते हैं कि टेबल बनाना SQLite में कच्चे SQL का उपयोग करने के समान ही है। आपको बस क्वेरी को एक स्ट्रिंग वेरिएबल में स्टोर करना है और फिर उस वेरिएबल को cursor.execute() पर पास करना है। ।
MySQL
आप mysql-connector-python . का उपयोग करेंगे MySQL में टेबल बनाने के लिए Python SQL मॉड्यूल। SQLite की तरह ही, आपको अपनी क्वेरी cursor.execute() . पर पास करनी होगी , जिसे .cursor() . पर कॉल करके लौटाया जाता है connection . पर वस्तु। आप एक और फ़ंक्शन बना सकते हैं execute_query() जो connection को स्वीकार करता है और query स्ट्रिंग:
1def execute_query(connection, query):
2 cursor = connection.cursor()
3 try:
4 cursor.execute(query)
5 connection.commit()
6 print("Query executed successfully")
7 except Error as e:
8 print(f"The error '{e}' occurred")
पंक्ति 4 में, आप query पास करते हैं करने के लिए cursor.execute() ।
अब आप अपने users . बना सकते हैं इस फ़ंक्शन का उपयोग कर तालिका:
create_users_table = """
CREATE TABLE IF NOT EXISTS users (
id INT AUTO_INCREMENT,
name TEXT NOT NULL,
age INT,
gender TEXT,
nationality TEXT,
PRIMARY KEY (id)
) ENGINE = InnoDB
"""
execute_query(connection, create_users_table)
SQLite की तुलना में MySQL में विदेशी कुंजी संबंध को लागू करने की क्वेरी थोड़ी अलग है। इसके अलावा, MySQL AUTO_INCREMENT . का उपयोग करता है कीवर्ड (SQLite AUTOINCREMENT . की तुलना में) कीवर्ड) कॉलम बनाने के लिए जहां मान स्वचालित रूप से बढ़ जाते हैं जब नए रिकॉर्ड डाले जाते हैं।
निम्न स्क्रिप्ट posts बनाती है तालिका, जिसमें एक विदेशी कुंजी शामिल है user_id जो id . का संदर्भ देता है users . का स्तंभ तालिका:
create_posts_table = """
CREATE TABLE IF NOT EXISTS posts (
id INT AUTO_INCREMENT,
title TEXT NOT NULL,
description TEXT NOT NULL,
user_id INTEGER NOT NULL,
FOREIGN KEY fk_user_id (user_id) REFERENCES users(id),
PRIMARY KEY (id)
) ENGINE = InnoDB
"""
execute_query(connection, create_posts_table)
इसी तरह, comments बनाने के लिए और likes टेबल, आप संबंधित CREATE . पास कर सकते हैं execute_query() के लिए क्वेरीज़ ।
पोस्टग्रेएसक्यूएल
SQLite और MySQL डेटाबेस की तरह, connection ऑब्जेक्ट जो psycopg2.connect() . द्वारा लौटाया गया है एक cursor शामिल है वस्तु। आप cursor.execute() . का उपयोग कर सकते हैं अपने PostgreSQL डेटाबेस पर Python SQL क्वेरी को निष्पादित करने के लिए।
फ़ंक्शन को परिभाषित करें execute_query() :
def execute_query(connection, query):
connection.autocommit = True
cursor = connection.cursor()
try:
cursor.execute(query)
print("Query executed successfully")
except OperationalError as e:
print(f"The error '{e}' occurred")
आप इस फ़ंक्शन का उपयोग टेबल बनाने, रिकॉर्ड डालने, रिकॉर्ड संशोधित करने और अपने PostgreSQL डेटाबेस में रिकॉर्ड हटाने के लिए कर सकते हैं।
अब users . बनाएं sm_app . के अंदर तालिका डेटाबेस:
create_users_table = """
CREATE TABLE IF NOT EXISTS users (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
age INTEGER,
gender TEXT,
nationality TEXT
)
"""
execute_query(connection, create_users_table)
आप देख सकते हैं कि users . बनाने के लिए क्वेरी PostgreSQL में तालिका SQLite और MySQL से थोड़ी अलग है। यहां, कीवर्ड SERIAL कॉलम बनाने के लिए उपयोग किया जाता है जो स्वचालित रूप से बढ़ता है। याद रखें कि MySQL AUTO_INCREMENT keyword कीवर्ड का उपयोग करता है ।
इसके अलावा, विदेशी कुंजी संदर्भ को भी अलग तरीके से निर्दिष्ट किया जाता है, जैसा कि निम्न स्क्रिप्ट में दिखाया गया है जो posts बनाता है तालिका:
create_posts_table = """
CREATE TABLE IF NOT EXISTS posts (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
description TEXT NOT NULL,
user_id INTEGER REFERENCES users(id)
)
"""
execute_query(connection, create_posts_table)
comments बनाने के लिए तालिका, आपको एक CREATE write लिखना होगा comments . के लिए क्वेरी तालिका और इसे पास करें execute_query() . likes . बनाने की प्रक्रिया टेबल एक ही है। आपको केवल CREATE . को संशोधित करना होगा likes . बनाने के लिए क्वेरी comments . के बजाय तालिका टेबल।
रिकॉर्ड सम्मिलित करना
पिछले अनुभाग में, आपने देखा कि विभिन्न पायथन SQL मॉड्यूल का उपयोग करके अपने SQLite, MySQL और PostgreSQL डेटाबेस में तालिकाएँ कैसे बनाई जाती हैं। इस अनुभाग में, आप देखेंगे कि रिकॉर्ड कैसे डालें आपकी टेबल में।
SQLite
अपने SQLite डेटाबेस में रिकॉर्ड डालने के लिए, आप उसी execute_query() . का उपयोग कर सकते हैं वह फ़ंक्शन जिसका उपयोग आप टेबल बनाने के लिए करते हैं। सबसे पहले, आपको अपना INSERT INTO . स्टोर करना होगा एक स्ट्रिंग में क्वेरी। फिर, आप connection . पास कर सकते हैं ऑब्जेक्ट और query स्ट्रिंग से execute_query() . आइए users . में पांच रिकॉर्ड डालें तालिका:
create_users = """
INSERT INTO
users (name, age, gender, nationality)
VALUES
('James', 25, 'male', 'USA'),
('Leila', 32, 'female', 'France'),
('Brigitte', 35, 'female', 'England'),
('Mike', 40, 'male', 'Denmark'),
('Elizabeth', 21, 'female', 'Canada');
"""
execute_query(connection, create_users)
चूंकि आपने id . सेट किया है कॉलम ऑटो-इन्क्रीमेंट के लिए, आपको id . का मान निर्दिष्ट करने की आवश्यकता नहीं है इन users . के लिए कॉलम . users तालिका इन पांच अभिलेखों को id . के साथ स्वतः भर देगी 1 . से मान करने के लिए 5 ।
अब posts . में छह रिकॉर्ड डालें तालिका:
create_posts = """
INSERT INTO
posts (title, description, user_id)
VALUES
("Happy", "I am feeling very happy today", 1),
("Hot Weather", "The weather is very hot today", 2),
("Help", "I need some help with my work", 2),
("Great News", "I am getting married", 1),
("Interesting Game", "It was a fantastic game of tennis", 5),
("Party", "Anyone up for a late-night party today?", 3);
"""
execute_query(connection, create_posts)
यह उल्लेख करना महत्वपूर्ण है कि user_id posts . का कॉलम तालिका एक विदेशी कुंजी है जो id . का संदर्भ देता है users . का स्तंभ टेबल। इसका मतलब है कि user_id कॉलम में एक मान होना चाहिए जो पहले से मौजूद है id . में users . का स्तंभ टेबल। यदि यह मौजूद नहीं है, तो आपको एक त्रुटि दिखाई देगी।
इसी तरह, निम्न स्क्रिप्ट comments . में रिकॉर्ड सम्मिलित करती है और likes टेबल:
create_comments = """
INSERT INTO
comments (text, user_id, post_id)
VALUES
('Count me in', 1, 6),
('What sort of help?', 5, 3),
('Congrats buddy', 2, 4),
('I was rooting for Nadal though', 4, 5),
('Help with your thesis?', 2, 3),
('Many congratulations', 5, 4);
"""
create_likes = """
INSERT INTO
likes (user_id, post_id)
VALUES
(1, 6),
(2, 3),
(1, 5),
(5, 4),
(2, 4),
(4, 2),
(3, 6);
"""
execute_query(connection, create_comments)
execute_query(connection, create_likes)
दोनों ही मामलों में, आप अपना INSERT INTO . स्टोर करते हैं एक स्ट्रिंग के रूप में क्वेरी करें और इसे execute_query() . के साथ निष्पादित करें ।
MySQL
Python एप्लिकेशन से MySQL डेटाबेस में रिकॉर्ड डालने के दो तरीके हैं। पहला दृष्टिकोण SQLite के समान है। आप INSERT INTO . को स्टोर कर सकते हैं एक स्ट्रिंग में क्वेरी करें और फिर cursor.execute() . का उपयोग करें रिकॉर्ड डालने के लिए।
इससे पहले, आपने एक रैपर फ़ंक्शन को परिभाषित किया था execute_query() जिसे आप रिकॉर्ड डालने के लिए इस्तेमाल करते थे। अब आप इसी फ़ंक्शन का उपयोग अपनी MySQL तालिका में रिकॉर्ड डालने के लिए कर सकते हैं। निम्न स्क्रिप्ट users . में रिकॉर्ड सम्मिलित करती है execute_query() . का उपयोग कर तालिका :
create_users = """
INSERT INTO
`users` (`name`, `age`, `gender`, `nationality`)
VALUES
('James', 25, 'male', 'USA'),
('Leila', 32, 'female', 'France'),
('Brigitte', 35, 'female', 'England'),
('Mike', 40, 'male', 'Denmark'),
('Elizabeth', 21, 'female', 'Canada');
"""
execute_query(connection, create_users)
दूसरा दृष्टिकोण cursor.executemany() . का उपयोग करता है , जो दो पैरामीटर स्वीकार करता है:
- प्रश्न रिकॉर्ड डालने के लिए प्लेसहोल्डर युक्त स्ट्रिंग
- सूची उन रिकॉर्डों की संख्या जिन्हें आप सम्मिलित करना चाहते हैं
निम्नलिखित उदाहरण को देखें, जो likes में दो रिकॉर्ड सम्मिलित करता है तालिका:
sql = "INSERT INTO likes ( user_id, post_id ) VALUES ( %s, %s )"
val = [(4, 5), (3, 4)]
cursor = connection.cursor()
cursor.executemany(sql, val)
connection.commit()
यह आप पर निर्भर करता है कि आप अपनी MySQL तालिका में रिकॉर्ड डालने के लिए कौन सा दृष्टिकोण चुनते हैं। यदि आप SQL के विशेषज्ञ हैं, तो आप .execute() . का उपयोग कर सकते हैं . यदि आप SQL से अधिक परिचित नहीं हैं, तो आपके लिए .executemany() का उपयोग करना अधिक सरल हो सकता है . दोनों में से किसी एक दृष्टिकोण के साथ, आप posts . में रिकॉर्ड सफलतापूर्वक सम्मिलित कर सकते हैं , comments , और likes टेबल.
पोस्टग्रेएसक्यूएल
पिछले खंड में, आपने SQLite डेटाबेस तालिकाओं में रिकॉर्ड डालने के लिए दो दृष्टिकोण देखे थे। पहला SQL स्ट्रिंग क्वेरी का उपयोग करता है, और दूसरा .executemany() . का उपयोग करता है . psycopg2 इस दूसरे दृष्टिकोण का अनुसरण करता है, हालांकि .execute() प्लेसहोल्डर-आधारित क्वेरी को निष्पादित करने के लिए उपयोग किया जाता है।
आप SQL क्वेरी को प्लेसहोल्डर्स और रिकॉर्ड्स की सूची के साथ .execute() . पर पास करते हैं . सूची में प्रत्येक रिकॉर्ड एक टपल होगा, जहां टपल मान डेटाबेस तालिका में कॉलम मानों के अनुरूप होते हैं। यहां बताया गया है कि आप users . में उपयोगकर्ता रिकॉर्ड कैसे सम्मिलित कर सकते हैं PostgreSQL डेटाबेस में तालिका:
users = [
("James", 25, "male", "USA"),
("Leila", 32, "female", "France"),
("Brigitte", 35, "female", "England"),
("Mike", 40, "male", "Denmark"),
("Elizabeth", 21, "female", "Canada"),
]
user_records = ", ".join(["%s"] * len(users))
insert_query = (
f"INSERT INTO users (name, age, gender, nationality) VALUES {user_records}"
)
connection.autocommit = True
cursor = connection.cursor()
cursor.execute(insert_query, users)
ऊपर दी गई स्क्रिप्ट users . की एक सूची बनाती है जिसमें टुपल्स के रूप में पांच उपयोगकर्ता रिकॉर्ड होते हैं। इसके बाद, आप पांच प्लेसहोल्डर तत्वों के साथ एक प्लेसहोल्डर स्ट्रिंग बनाते हैं (%s ) जो पांच उपयोगकर्ता रिकॉर्ड के अनुरूप है। प्लेसहोल्डर स्ट्रिंग को उस क्वेरी के साथ जोड़ा जाता है जो users . में रिकॉर्ड सम्मिलित करती है टेबल। अंत में, क्वेरी स्ट्रिंग और उपयोगकर्ता रिकॉर्ड .execute() . को पास कर दिए जाते हैं . उपरोक्त स्क्रिप्ट users . में सफलतापूर्वक पांच रिकॉर्ड सम्मिलित करती है टेबल।
PostgreSQL तालिका में रिकॉर्ड डालने का एक और उदाहरण देखें। निम्न स्क्रिप्ट posts में रिकॉर्ड सम्मिलित करती है तालिका:
posts = [
("Happy", "I am feeling very happy today", 1),
("Hot Weather", "The weather is very hot today", 2),
("Help", "I need some help with my work", 2),
("Great News", "I am getting married", 1),
("Interesting Game", "It was a fantastic game of tennis", 5),
("Party", "Anyone up for a late-night party today?", 3),
]
post_records = ", ".join(["%s"] * len(posts))
insert_query = (
f"INSERT INTO posts (title, description, user_id) VALUES {post_records}"
)
connection.autocommit = True
cursor = connection.cursor()
cursor.execute(insert_query, posts)
आप comments . में रिकॉर्ड सम्मिलित कर सकते हैं और likes समान दृष्टिकोण वाली तालिकाएँ।
रिकॉर्ड चुनना
इस खंड में, आप देखेंगे कि विभिन्न पायथन SQL मॉड्यूल का उपयोग करके डेटाबेस तालिकाओं से रिकॉर्ड का चयन कैसे करें। विशेष रूप से, आप SELECT प्रदर्शन करने का तरीका देखेंगे आपके SQLite, MySQL, और PostgreSQL डेटाबेस पर क्वेरीज़।
SQLite
SQLite का उपयोग करके रिकॉर्ड का चयन करने के लिए, आप फिर से cursor.execute() . का उपयोग कर सकते हैं . हालांकि, ऐसा करने के बाद, आपको .fetchall() . पर कॉल करना होगा . यह विधि ट्यूपल्स की एक सूची लौटाती है जहां प्रत्येक टपल को पुनर्प्राप्त रिकॉर्ड में संबंधित पंक्ति में मैप किया जाता है।
प्रक्रिया को सरल बनाने के लिए, आप एक फ़ंक्शन बना सकते हैं execute_read_query() :
def execute_read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as e:
print(f"The error '{e}' occurred")
यह फ़ंक्शन connection को स्वीकार करता है ऑब्जेक्ट और SELECT क्वेरी और चयनित रिकॉर्ड लौटाता है।
SELECT
आइए अब users . से सभी रिकॉर्ड का चयन करें तालिका:
select_users = "SELECT * from users"
users = execute_read_query(connection, select_users)
for user in users:
print(user)
उपरोक्त लिपि में, SELECT क्वेरी users . में से सभी उपयोगकर्ताओं का चयन करती है टेबल। यह execute_read_query() . को पास कर दिया जाता है , जो users . से सभी रिकॉर्ड लौटाता है टेबल। फिर रिकॉर्ड्स को ट्रेस किया जाता है और कंसोल पर प्रिंट किया जाता है।
नोट: SELECT * . का इस्तेमाल करने की सलाह नहीं दी जाती है बड़ी तालिकाओं पर क्योंकि इसके परिणामस्वरूप बड़ी संख्या में I/O संचालन हो सकते हैं जो नेटवर्क ट्रैफ़िक को बढ़ाते हैं।
उपरोक्त क्वेरी का आउटपुट इस तरह दिखता है:
(1, 'James', 25, 'male', 'USA')
(2, 'Leila', 32, 'female', 'France')
(3, 'Brigitte', 35, 'female', 'England')
(4, 'Mike', 40, 'male', 'Denmark')
(5, 'Elizabeth', 21, 'female', 'Canada')
इसी तरह, आप posts . से सभी रिकॉर्ड्स को पुनः प्राप्त कर सकते हैं नीचे दी गई स्क्रिप्ट के साथ तालिका:
select_posts = "SELECT * FROM posts"
posts = execute_read_query(connection, select_posts)
for post in posts:
print(post)
आउटपुट इस तरह दिखता है:
(1, 'Happy', 'I am feeling very happy today', 1)
(2, 'Hot Weather', 'The weather is very hot today', 2)
(3, 'Help', 'I need some help with my work', 2)
(4, 'Great News', 'I am getting married', 1)
(5, 'Interesting Game', 'It was a fantastic game of tennis', 5)
(6, 'Party', 'Anyone up for a late-night party today?', 3)
परिणाम posts . में सभी रिकॉर्ड दिखाता है टेबल।
JOIN
आप JOIN . से जुड़े जटिल प्रश्नों को भी निष्पादित कर सकते हैं संचालन दो संबंधित तालिकाओं से डेटा पुनर्प्राप्त करने के लिए। उदाहरण के लिए, निम्न स्क्रिप्ट उपयोगकर्ता आईडी और नाम लौटाती है, साथ ही इन उपयोगकर्ताओं द्वारा पोस्ट की गई पोस्ट का विवरण:
select_users_posts = """
SELECT
users.id,
users.name,
posts.description
FROM
posts
INNER JOIN users ON users.id = posts.user_id
"""
users_posts = execute_read_query(connection, select_users_posts)
for users_post in users_posts:
print(users_post)
Here’s the output:
(1, 'James', 'I am feeling very happy today')
(2, 'Leila', 'The weather is very hot today')
(2, 'Leila', 'I need some help with my work')
(1, 'James', 'I am getting married')
(5, 'Elizabeth', 'It was a fantastic game of tennis')
(3, 'Brigitte', 'Anyone up for a late night party today?')
You can also select data from three related tables by implementing multiple JOIN operators . The following script returns all posts, along with the comments on the posts and the names of the users who posted the comments:
select_posts_comments_users = """
SELECT
posts.description as post,
text as comment,
name
FROM
posts
INNER JOIN comments ON posts.id = comments.post_id
INNER JOIN users ON users.id = comments.user_id
"""
posts_comments_users = execute_read_query(
connection, select_posts_comments_users
)
for posts_comments_user in posts_comments_users:
print(posts_comments_user)
The output looks like this:
('Anyone up for a late night party today?', 'Count me in', 'James')
('I need some help with my work', 'What sort of help?', 'Elizabeth')
('I am getting married', 'Congrats buddy', 'Leila')
('It was a fantastic game of tennis', 'I was rooting for Nadal though', 'Mike')
('I need some help with my work', 'Help with your thesis?', 'Leila')
('I am getting married', 'Many congratulations', 'Elizabeth')
You can see from the output that the column names are not being returned by .fetchall() . To return column names, you can use the .description attribute of the cursor वस्तु। For instance, the following list returns all the column names for the above query:
cursor = connection.cursor()
cursor.execute(select_posts_comments_users)
cursor.fetchall()
column_names = [description[0] for description in cursor.description]
print(column_names)
The output looks like this:
['post', 'comment', 'name']
You can see the names of the columns for the given query.
WHERE
Now you’ll execute a SELECT query that returns the post, along with the total number of likes that the post received:
select_post_likes = """
SELECT
description as Post,
COUNT(likes.id) as Likes
FROM
likes,
posts
WHERE
posts.id = likes.post_id
GROUP BY
likes.post_id
"""
post_likes = execute_read_query(connection, select_post_likes)
for post_like in post_likes:
print(post_like)
The output is as follows:
('The weather is very hot today', 1)
('I need some help with my work', 1)
('I am getting married', 2)
('It was a fantastic game of tennis', 1)
('Anyone up for a late night party today?', 2)
By using a WHERE clause, you’re able to return more specific results.
MySQL
The process of selecting records in MySQL is absolutely identical to selecting records in SQLite. You can use cursor.execute() followed by .fetchall() . The following script creates a wrapper function execute_read_query() that you can use to select records:
def execute_read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as e:
print(f"The error '{e}' occurred")
Now select all the records from the users तालिका:
select_users = "SELECT * FROM users"
users = execute_read_query(connection, select_users)
for user in users:
print(user)
The output will be similar to what you saw with SQLite.
PostgreSQL
The process of selecting records from a PostgreSQL table with the psycopg2 Python SQL module is similar to what you did with SQLite and MySQL. Again, you’ll use cursor.execute() followed by .fetchall() to select records from your PostgreSQL table. The following script selects all the records from the users table and prints them to the console:
def execute_read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except OperationalError as e:
print(f"The error '{e}' occurred")
select_users = "SELECT * FROM users"
users = execute_read_query(connection, select_users)
for user in users:
print(user)
Again, the output will be similar to what you’ve seen before.
Updating Table Records
In the last section, you saw how to select records from SQLite, MySQL, and PostgreSQL databases. In this section, you’ll cover the process for updating records using the Python SQL libraries for SQLite, PostgresSQL, and MySQL.
SQLite
Updating records in SQLite is pretty straightforward. You can again make use of execute_query() . As an example, you can update the description of the post with an id of 2 . First, SELECT the description of this post:
select_post_description = "SELECT description FROM posts WHERE id = 2"
post_description = execute_read_query(connection, select_post_description)
for description in post_description:
print(description)
You should see the following output:
('The weather is very hot today',)
The following script updates the description:
update_post_description = """
UPDATE
posts
SET
description = "The weather has become pleasant now"
WHERE
id = 2
"""
execute_query(connection, update_post_description)
Now, if you execute the SELECT query again, you should see the following result:
('The weather has become pleasant now',)
The output has been updated.
MySQL
The process of updating records in MySQL with mysql-connector-python is also a carbon copy of the sqlite3 Python SQL module. You need to pass the string query to cursor.execute() . For example, the following script updates the description of the post with an id of 2 :
update_post_description = """
UPDATE
posts
SET
description = "The weather has become pleasant now"
WHERE
id = 2
"""
execute_query(connection, update_post_description)
Again, you’ve used your wrapper function execute_query() to update the post description.
PostgreSQL
The update query for PostgreSQL is similar to what you’ve seen with SQLite and MySQL. You can use the above scripts to update records in your PostgreSQL table.
Deleting Table Records
In this section, you’ll see how to delete table records using the Python SQL modules for SQLite, MySQL, and PostgreSQL databases. The process of deleting records is uniform for all three databases since the DELETE query for the three databases is the same.
SQLite
You can again use execute_query() to delete records from YOUR SQLite database. All you have to do is pass the connection object and the string query for the record you want to delete to execute_query() . Then, execute_query() will create a cursor object using the connection and pass the string query to cursor.execute() , which will delete the records.
As an example, try to delete the comment with an id of 5 :
delete_comment = "DELETE FROM comments WHERE id = 5"
execute_query(connection, delete_comment)
Now, if you select all the records from the comments table, you’ll see that the fifth comment has been deleted.
MySQL
The process for deletion in MySQL is also similar to SQLite, as shown in the following example:
delete_comment = "DELETE FROM comments WHERE id = 2"
execute_query(connection, delete_comment)
Here, you delete the second comment from the sm_app database’s comments table in your MySQL database server.
PostgreSQL
The delete query for PostgreSQL is also similar to SQLite and MySQL. You can write a delete query string by using the DELETE keyword and then passing the query and the connection object to execute_query() . This will delete the specified records from your PostgreSQL database.
Conclusion
In this tutorial, you’ve learned how to use three common Python SQL libraries. sqlite3 , mysql-connector-python , and psycopg2 allow you to connect a Python application to SQLite, MySQL, and PostgreSQL databases, respectively.
Now you can:
- Interact with SQLite, MySQL, or PostgreSQL databases
- Use three different Python SQL modules
- Execute SQL queries on various databases from within a Python application
However, this is just the tip of the iceberg! There are also Python SQL libraries for object-relational mapping , such as SQLAlchemy and Django ORM, that automate the task of database interaction in Python. You’ll learn more about these libraries in other tutorials in our Python databases section.