[ भाग 1 | भाग 2 | भाग 3 ]
इस श्रृंखला के भाग 1 में, मैंने 1TB तालिका को संपीड़ित करने के कुछ तरीके आज़माए। जबकि मुझे अपने पहले प्रयास में अच्छे परिणाम मिले, मैं यह देखना चाहता था कि क्या मैं भाग 2 में प्रदर्शन में सुधार कर सकता हूं। वहां मैंने कुछ चीजों को रेखांकित किया जो मुझे लगा कि प्रदर्शन के मुद्दे हो सकते हैं, और यह निर्धारित किया कि मैं गंतव्य तालिका को बेहतर तरीके से कैसे विभाजित करूंगा। इष्टतम कॉलमस्टोर संपीड़न के लिए। मेरे पास पहले से ही है:
- तालिका को 8 विभाजनों में विभाजित किया (एक प्रति कोर);
- प्रत्येक पार्टीशन की डेटा फ़ाइल को उसके अपने फ़ाइलग्रुप पर रखें; और,
- संग्रह संपीड़न को "सक्रिय" विभाजन को छोड़कर सभी पर सेट करें।
मुझे अभी भी इसे बनाने की आवश्यकता है ताकि प्रत्येक अनुसूचक अपने स्वयं के विभाजन के लिए विशेष रूप से लिखे।
सबसे पहले, मुझे अपने द्वारा बनाई गई बैच तालिका में परिवर्तन करने की आवश्यकता है। मुझे प्रति बैच जोड़ी गई पंक्तियों की संख्या को संग्रहीत करने के लिए एक कॉलम की आवश्यकता है (एक तरह की सेल्फ-ऑडिटिंग सैनिटी चेक), और प्रगति को मापने के लिए प्रारंभ/समाप्ति समय।
ALTER TABLE dbo.BatchQueue ADD RowsAdded int, StartTime datetime2, EndTime datetime2;
इसके बाद, मुझे एफ़िनिटी प्रदान करने के लिए एक टेबल बनाने की आवश्यकता है - हम कभी भी किसी शेड्यूलर पर एक से अधिक प्रक्रिया नहीं चलाना चाहते हैं, भले ही इसका मतलब तर्क को पुनः प्रयास करने के लिए कुछ समय खोना है। इसलिए हमें एक ऐसी तालिका की आवश्यकता है जो किसी विशिष्ट शेड्यूलर पर किसी भी सत्र का ट्रैक रखे और स्टैकिंग को रोके:
CREATE TABLE dbo.OpAffinity ( SchedulerID int NOT NULL, SessionID int NULL, CONSTRAINT PK_OpAffinity PRIMARY KEY CLUSTERED (SchedulerID) );
विचार यह है कि मेरे पास एक एप्लिकेशन (SQLQueryStress) के आठ उदाहरण होंगे जो प्रत्येक एक समर्पित शेड्यूलर पर चलेंगे, केवल एक विशिष्ट विभाजन/फ़ाइल समूह/डेटा फ़ाइल के लिए नियत डेटा को संभालने, एक समय में ~ 100 मिलियन पंक्तियां (विस्तार करने के लिए क्लिक करें) :
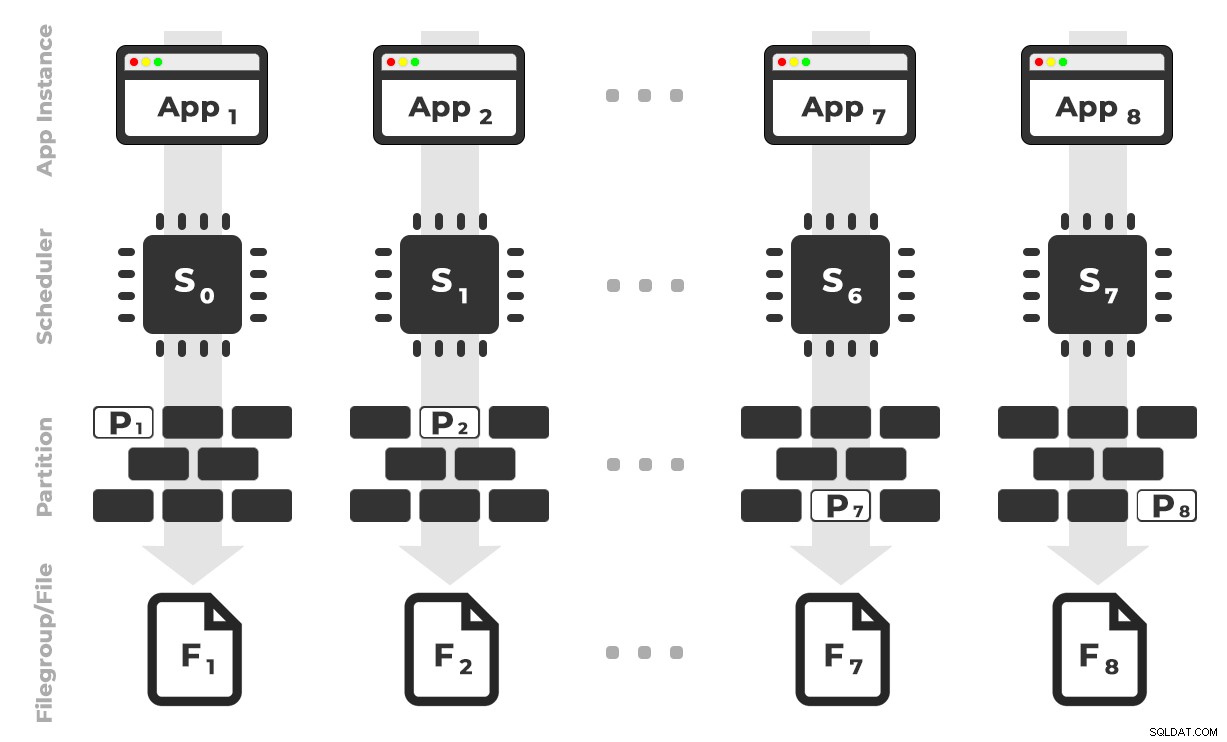 ऐप 1 को शेड्यूलर 0 मिलता है और फाइलग्रुप 1 पर विभाजन 1 को लिखता है, और इसी तरह आगे भी …
ऐप 1 को शेड्यूलर 0 मिलता है और फाइलग्रुप 1 पर विभाजन 1 को लिखता है, और इसी तरह आगे भी …
आगे हमें एक संग्रहीत कार्यविधि की आवश्यकता है जो एप्लिकेशन के प्रत्येक उदाहरण को एकल अनुसूचक पर समय आरक्षित करने में सक्षम बनाएगी। जैसा कि मैंने पिछली पोस्ट में उल्लेख किया है, यह मेरा मूल विचार नहीं है (और जो ओबिश के लिए नहीं तो मैं इसे उस गाइड में कभी नहीं मिला होता)। यहाँ वह प्रक्रिया है जिसे मैंने Utility में बनाया है :
CREATE PROCEDURE dbo.DoMyBatch
@PartitionID int, -- pass in 1 through 8
@BatchID int -- pass in 1 through 4
AS
BEGIN
DECLARE @BatchSize bigint,
@MinID bigint,
@MaxID bigint,
@rc bigint,
@ThisSchedulerID int =
(
SELECT scheduler_id
FROM sys.dm_exec_requests
WHERE session_id = @@SPID
);
-- try to get the requested scheduler, 0-based
IF @ThisSchedulerID <> @PartitionID - 1
BEGIN
-- surface the scheduler we got to the application, but force a delay
RAISERROR('Got wrong scheduler %d.', 11, 1, @ThisSchedulerID);
WAITFOR DELAY '00:00:05';
RETURN -3;
END
ELSE
BEGIN
-- we are on our scheduler, now serializibly make sure we're exclusive
INSERT Utility.dbo.OpAffinity(SchedulerID, SessionID)
SELECT @ThisSchedulerID, @@SPID
WHERE NOT EXISTS
(
SELECT 1 FROM Utility.dbo.OpAffinity WITH (TABLOCKX)
WHERE SchedulerID = @ThisSchedulerID
);
-- if someone is already using this scheduler, raise roar:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Wrong scheduler %d, try again.',11,1,@ThisSchedulerID) WITH NOWAIT;
RETURN @ThisSchedulerID;
END
-- checkpoint twice to clear log
EXEC OCopy.sys.sp_executesql N'CHECKPOINT; CHECKPOINT;';
-- get our range of rows for the current batch
SELECT @MinID = MinID, @MaxID = MaxID
FROM Utility.dbo.BatchQueue
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID
AND StartTime IS NULL;
-- if we couldn't get a row here, must already be done:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Already done.', 11, 1) WITH NOWAIT;
RETURN -1;
END
-- update the BatchQueue table to indicate we've started:
UPDATE msdb.dbo.BatchQueue
SET StartTime = sysdatetime(), EndTime = NULL
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- do the work - copy from Original to Partitioned
INSERT OCopy.dbo.tblPartitionedCCI
SELECT * FROM OCopy.dbo.tblOriginal AS o
WHERE o.CostID >= @MinID AND o.CostID <= @MaxID
OPTION (MAXDOP 1); -- don't want parallelism here!
/*
You might think, don't I want a TABLOCK hint on the insert,
to benefit from minimal logging? I thought so too, but while
this leads to a BULK UPDATE lock on rowstore tables, it is a
TABLOCKX with columnstore. This isn't going to work well if
we want to have multiple processes inserting into separate
partitions simultaneously. We need a PARTITIONLOCK hint!
*/
SET @rc = @@ROWCOUNT;
-- update BatchQueue that we've finished and how many rows:
UPDATE Utility.dbo.BatchQueue
SET EndTime = sysdatetime(), RowsAdded = @rc
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- remove our lock to this scheduler:
DELETE Utility.dbo.OpAffinity
WHERE SchedulerID = @ThisSchedulerID
AND SessionID = @@SPID;
END
END सरल, है ना? SQLQueryStress के 8 इंस्टेंस को सक्रिय करें, और इस बैच को प्रत्येक में डालें:
EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 1; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 2; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 3; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 4;
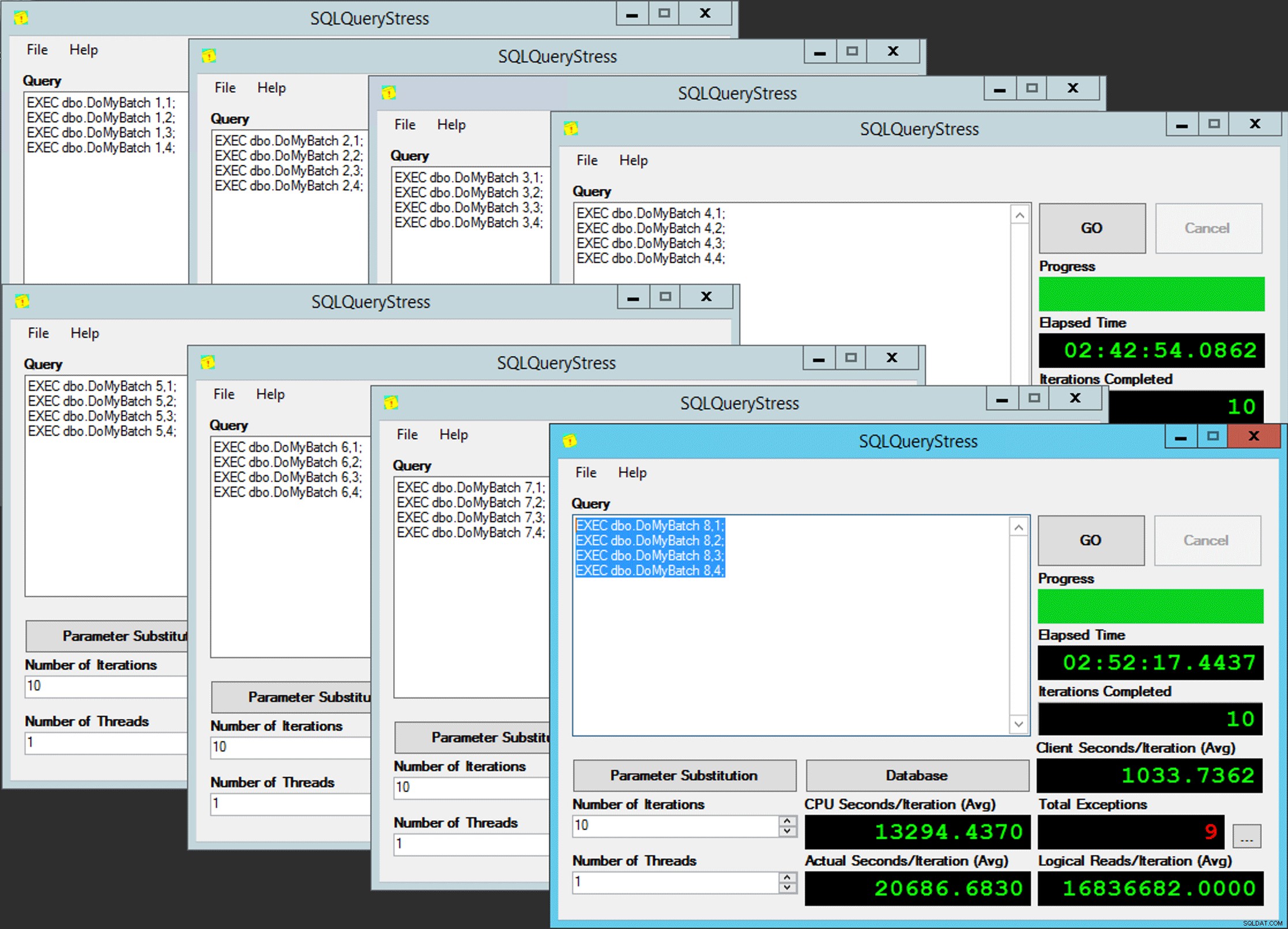 गरीबों की समानता
गरीबों की समानता
सिवाय यह इतना आसान नहीं है, क्योंकि शेड्यूलर असाइनमेंट चॉकलेट के एक बॉक्स की तरह है। अपेक्षित शेड्यूलर पर ऐप के प्रत्येक इंस्टेंस को प्राप्त करने में कई प्रयास हुए; मैं ऐप के किसी भी उदाहरण पर अपवादों का निरीक्षण करूंगा, और PartitionID . को बदलूंगा मैच के लिए। यही कारण है कि मैंने एक से अधिक पुनरावृत्तियों का उपयोग किया (लेकिन मैं अभी भी प्रति उदाहरण केवल एक धागा चाहता था)। उदाहरण के तौर पर, ऐप का यह उदाहरण शेड्यूलर 3 पर होने की उम्मीद कर रहा था, लेकिन इसे शेड्यूलर 4 मिला:
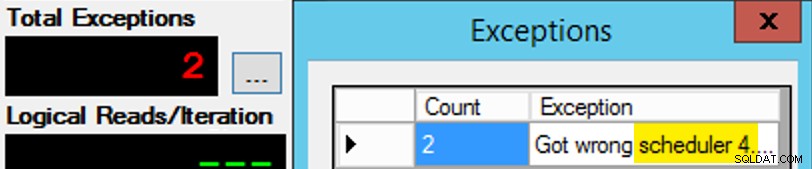 अगर पहली बार में आप सफल नहीं होते हैं...
अगर पहली बार में आप सफल नहीं होते हैं...
मैंने क्वेरी विंडो में 3s को 4s में बदल दिया, और पुनः प्रयास किया। अगर मैं जल्दी था, तो शेड्यूलर असाइनमेंट "चिपचिपा" था कि वह इसे ठीक से उठाएगा और दूर चिपकना शुरू कर देगा। लेकिन मैं हमेशा तेज नहीं था, इसलिए यह एक अजीब तरह का तिल जैसा था। मैं शायद काम को कम मैनुअल बनाने के लिए एक बेहतर रिट्री/लूप रूटीन तैयार कर सकता था, और देरी को कम कर देता था, इसलिए मुझे तुरंत पता चल गया कि यह काम करता है या नहीं, लेकिन यह मेरी जरूरतों के लिए काफी अच्छा था। यह प्रत्येक प्रक्रिया के लिए प्रारंभ समय के अनजाने में चौंका देने वाला, मिस्टर ओबिश की एक और सलाह के लिए भी बना।
निगरानी
जबकि एफ़िनिटाइज़्ड कॉपी चल रही है, मैं निम्नलिखित दो प्रश्नों के साथ वर्तमान स्थिति के बारे में संकेत प्राप्त कर सकता हूँ:
SELECT r.session_id, r.[status], r.scheduler_id, partition_id = o.SchedulerID + 1,
r.logical_reads, r.total_elapsed_time, r.last_wait_type, longest_wait_type =
(
SELECT TOP (1) wait_type
FROM sys.dm_exec_session_wait_stats
WHERE session_id = r.session_id AND wait_type <> 'WAITFOR'
ORDER BY wait_time_ms - signal_wait_time_ms DESC
)
FROM sys.dm_exec_requests AS r
INNER JOIN Utility.dbo.OpAffinity AS o
ON o.SessionID = r.session_id
WHERE r.command = N'INSERT'
ORDER BY r.scheduler_id;
SELECT SchedulerID = PartitionID - 1, Duration = DATEDIFF(SECOND, StartTime, EndTime), *
FROM Utility.dbo.BatchQueue WITH (NOLOCK)
WHERE StartTime IS NOT NULL -- AND EndTime IS NULL
ORDER BY PartitionID;
अगर मैंने सब कुछ ठीक किया, तो दोनों प्रश्न 8 पंक्तियों को वापस कर देंगे, और तार्किक पठन और अवधि में वृद्धि दिखाएंगे। प्रतीक्षा प्रकार PAGEIOLATCH_SH . के बीच घूमेंगे , SOS_SCHEDULER_YIELD , और कभी-कभी RESERVED_MEMORY_ALLOCATION_EXT. जब एक बैच समाप्त हो गया था (मैं -- AND EndTime IS NULL को बिना टिप्पणी करके इनकी समीक्षा कर सकता था , मैं पुष्टि करूंगा कि RowsAdded = RowsInRange ।
एक बार SQLQueryStress के सभी 8 इंस्टेंस पूरे हो जाने के बाद, मैं बस एक SELECT INTO <newtable> FROM dbo.BatchQueue कर सकता था। बाद के विश्लेषण के लिए अंतिम परिणाम लॉग करने के लिए।
अन्य परीक्षण
डेटा को विभाजित क्लस्टर्ड कॉलमस्टोर इंडेक्स में कॉपी करने के अलावा, जो पहले से मौजूद था, आत्मीयता का उपयोग करते हुए, मैं कुछ अन्य चीजों को भी आज़माना चाहता था:
- एफ़िनिटी को नियंत्रित करने की कोशिश किए बिना डेटा को नई तालिका में कॉपी करना। मैंने एफ़िनिटी लॉजिक को प्रक्रिया से बाहर कर दिया और पूरी "आशा-आप-प्राप्त-सही-अनुसूचक" चीज़ को मौका देने के लिए छोड़ दिया। इसमें अधिक समय लगा क्योंकि, निश्चित रूप से, शेड्यूलर स्टैकिंग किया घटित होना। उदाहरण के लिए, इस विशिष्ट बिंदु पर, शेड्यूलर 3 दो प्रक्रियाएं चला रहा था, जबकि शेड्यूलर 0 लंच ब्रेक लेना बंद कर रहा था:
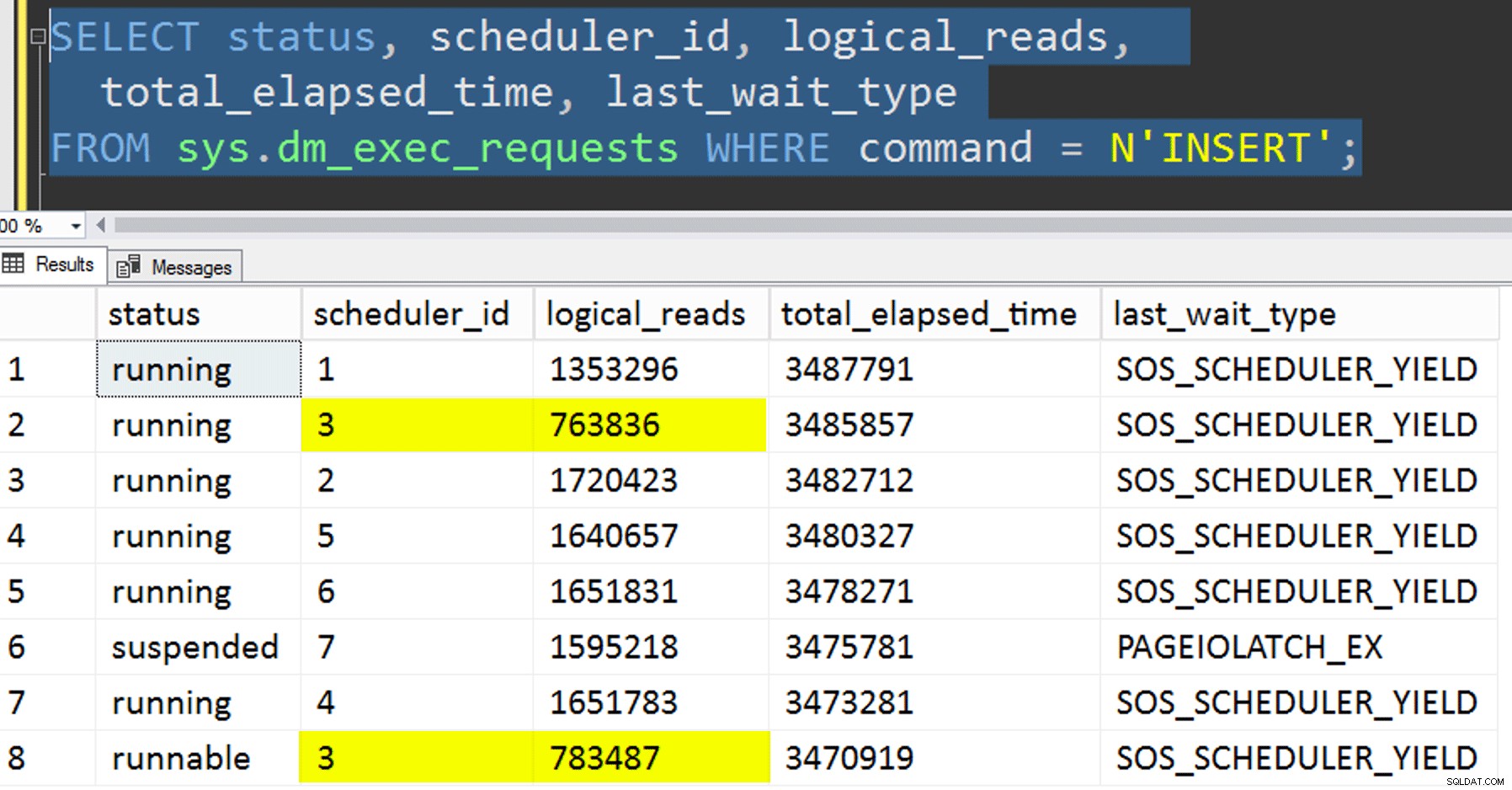 आप कहां हैं, शेड्यूलर नंबर 0?
आप कहां हैं, शेड्यूलर नंबर 0? - पेज लागू करना या पंक्ति स्रोत से पहले . संपीड़न (ऑनलाइन/ऑफ़लाइन दोनों) एफ़िनिटाइज़्ड कॉपी (ऑफ़लाइन), यह देखने के लिए कि क्या पहले डेटा को संपीड़ित करने से गंतव्य को गति मिल सकती है। ध्यान दें कि कॉपी ऑनलाइन भी की जा सकती है, लेकिन एंडी मॉलन के
int. की तरह करने के लिएbigintरूपांतरण, इसके लिए कुछ जिम्नास्टिक की आवश्यकता होती है। ध्यान दें कि इस मामले में हम CPU एफ़िनिटी का लाभ नहीं उठा सकते हैं (हालाँकि हम स्रोत तालिका को पहले ही विभाजित कर सकते हैं)। मैं होशियार था और मूल स्रोत का बैकअप लिया, और डेटाबेस को उसकी प्रारंभिक स्थिति में वापस लाने के लिए एक प्रक्रिया बनाई। मैन्युअल रूप से किसी विशिष्ट स्थिति में वापस जाने की कोशिश करने की तुलना में बहुत तेज़ और आसान।-- refresh source, then do page online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do page offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = OFF); -- then run SQLQueryStress -- refresh source, then do row online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do row offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = OFF); -- then run SQLQueryStress
- और अंत में, पहले विभाजन योजना पर संकुल सूचकांक का पुनर्निर्माण करना, फिर उसके ऊपर क्लस्टर्ड कॉलमस्टोर इंडेक्स बनाना। उत्तरार्द्ध का नकारात्मक पक्ष यह है कि, SQL सर्वर 2017 में, आप इसे ऑनलाइन नहीं चला सकते… लेकिन आप 2019 में सक्षम होंगे।
यहां हमें पहले पीके बाधा को छोड़ना होगा; आप
संदेश 1907, स्तर 16, राज्य 1DROP_EXISTINGका उपयोग नहीं कर सकते , चूंकि मूल अद्वितीय बाधा को क्लस्टर्ड कॉलमस्टोर इंडेक्स द्वारा लागू नहीं किया जा सकता है, और आप एक अद्वितीय क्लस्टर इंडेक्स को गैर-अद्वितीय क्लस्टर इंडेक्स के साथ प्रतिस्थापित नहीं कर सकते हैं।
सूचकांक 'pk_tblOriginal' को फिर से नहीं बनाया जा सकता। नई अनुक्रमणिका परिभाषा मौजूदा अनुक्रमणिका द्वारा लागू की जा रही बाधा से मेल नहीं खाती।ये सभी विवरण इसे तीन चरणों वाली प्रक्रिया बनाते हैं, केवल दूसरा चरण ऑनलाइन। पहला चरण मैंने केवल स्पष्ट रूप से
OFFLINEका परीक्षण किया है; जो तीन मिनट में चला, जबकिONLINEमैं 15 मिनट के बाद रुक गया। उन चीजों में से एक जो शायद किसी भी मामले में डेटा के आकार का संचालन नहीं होना चाहिए, लेकिन मैं इसे एक और दिन के लिए छोड़ दूंगा।ALTER TABLE dbo.tblOriginal DROP CONSTRAINT PK_tblOriginal WITH (ONLINE = OFF); GO CREATE CLUSTERED INDEX CCI_tblOriginal -- yes, a bad name, but only temporarily ON dbo.tblOriginal(OID) WITH (ONLINE = ON) ON PS_OID (OID); -- this moves the data CREATE CLUSTERED COLUMNSTORE INDEX CCI_tblOriginal ON dbo.tblOriginal WITH ( DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) -- in 2019, CCI can be ONLINE = ON as well ) ON PS_OID (OID); GO
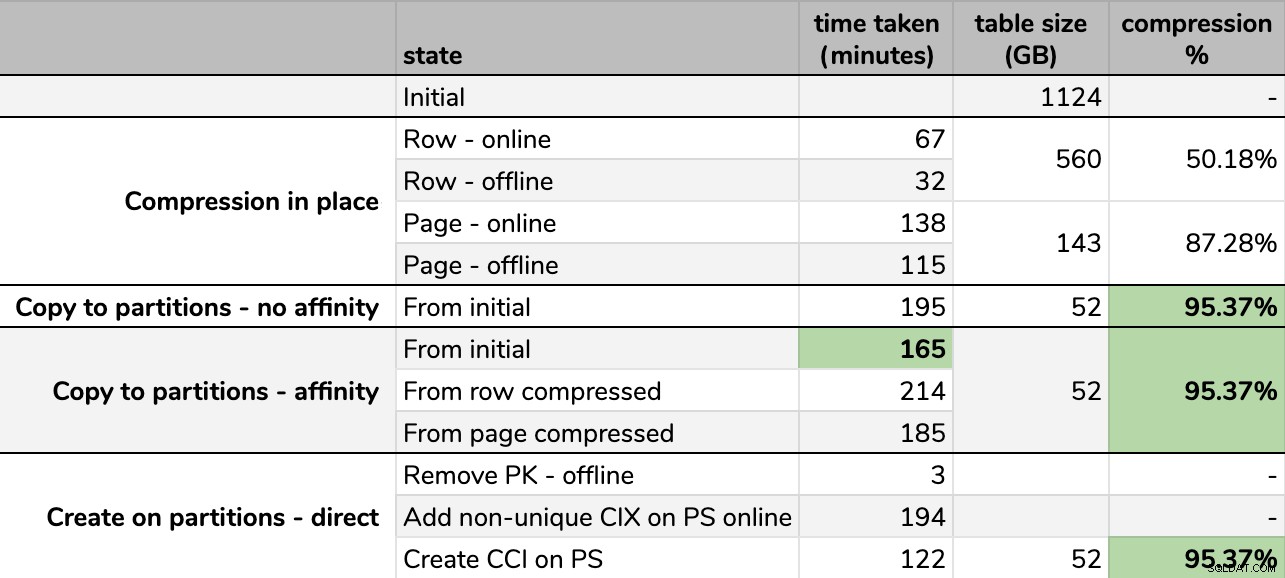
परिणाम
समय और संपीड़न दर:
 कुछ विकल्प दूसरों से बेहतर होते हैं
कुछ विकल्प दूसरों से बेहतर होते हैं
ध्यान दें कि मैंने जीबी तक गोल किया क्योंकि प्रत्येक रन के बाद अंतिम आकार में मामूली अंतर होगा, यहां तक कि उसी तकनीक का उपयोग करके भी। साथ ही, एफ़िनिटी विधियों का समय औसत . पर आधारित था व्यक्तिगत शेड्यूलर/बैच रनटाइम, क्योंकि कुछ शेड्यूलर दूसरों की तुलना में तेज़ी से समाप्त होते हैं।
जैसा दिखाया गया है, स्प्रैडशीट से एक सटीक तस्वीर की कल्पना करना कठिन है, क्योंकि कुछ कार्यों में निर्भरताएं होती हैं, इसलिए मैं जानकारी को समयरेखा के रूप में प्रदर्शित करने का प्रयास करूंगा और दिखाऊंगा कि आपको खर्च किए गए समय की तुलना में कितना संपीड़न मिलता है:
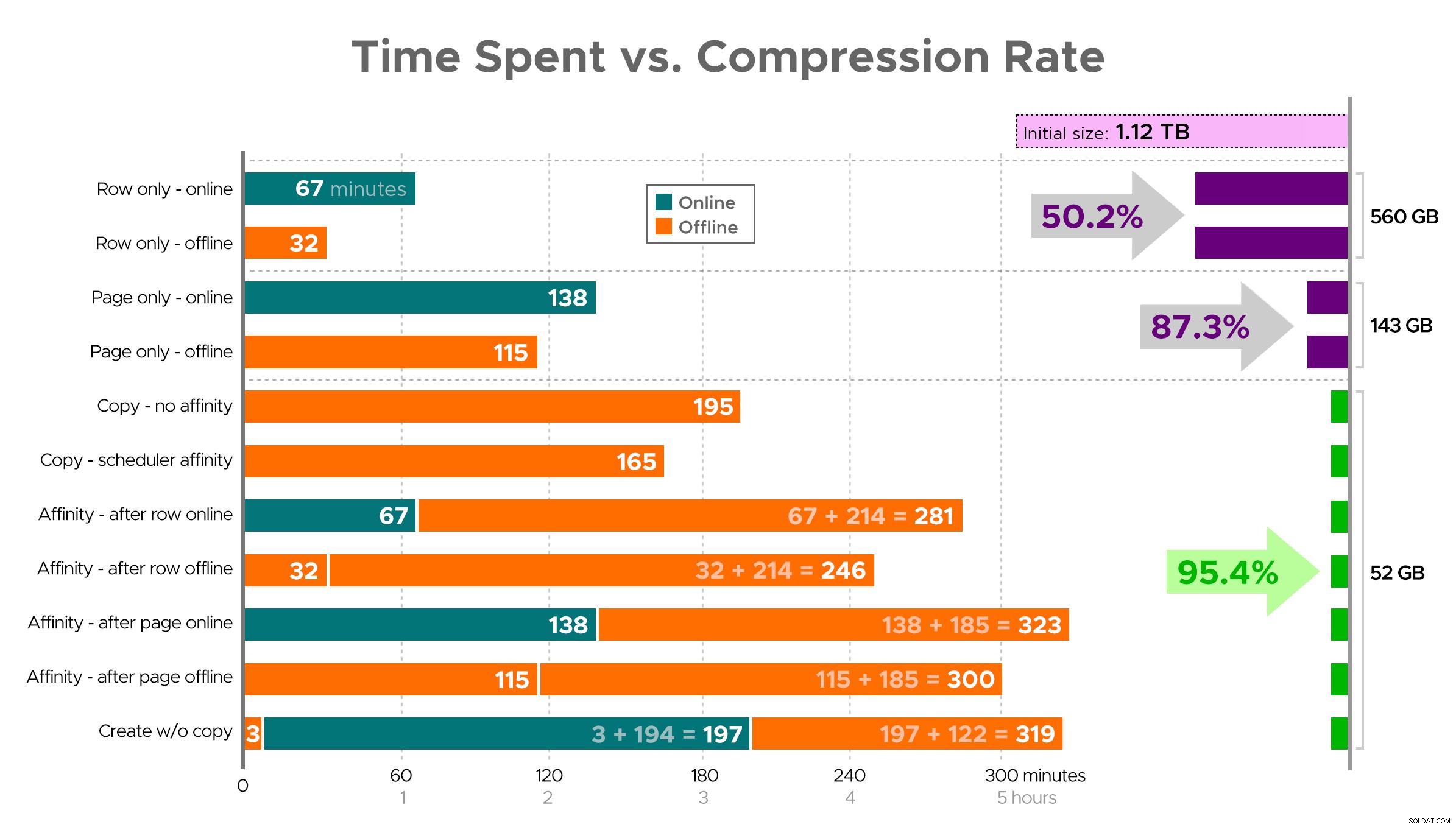 समय व्यतीत (मिनट) बनाम संपीड़न दर
समय व्यतीत (मिनट) बनाम संपीड़न दर
परिणामों से कुछ अवलोकन, इस चेतावनी के साथ कि आपका डेटा अलग तरह से संपीड़ित हो सकता है (और यह कि ऑनलाइन संचालन केवल आप पर लागू होता है यदि आप एंटरप्राइज़ संस्करण का उपयोग करते हैं):
- यदि आपकी प्राथमिकता जितनी जल्दी हो सके कुछ स्थान बचाना है , आपका सबसे अच्छा दांव जगह पर पंक्ति संपीड़न लागू करना है। यदि आप व्यवधान को कम करना चाहते हैं, तो ऑनलाइन उपयोग करें; यदि आप गति को अनुकूलित करना चाहते हैं, तो ऑफ़लाइन उपयोग करें।
- यदि आप शून्य व्यवधान के साथ संपीड़न को अधिकतम करना चाहते हैं , आप ऑनलाइन पृष्ठ संपीड़न का उपयोग करके, बिना किसी व्यवधान के 90% संग्रहण कमी प्राप्त कर सकते हैं।
- यदि आप संपीड़न और व्यवधान को अधिकतम करना चाहते हैं तो ठीक है , डेटा को क्लस्टर्ड कॉलमस्टोर इंडेक्स के साथ तालिका के एक नए, विभाजित संस्करण में कॉपी करें, और डेटा को माइग्रेट करने के लिए ऊपर वर्णित एफ़िनिटी प्रक्रिया का उपयोग करें। (और फिर, यदि आप मुझसे बेहतर योजनाकार हैं तो आप इस व्यवधान को समाप्त कर सकते हैं।)
अंतिम विकल्प ने मेरे परिदृश्य के लिए सबसे अच्छा काम किया, हालांकि हमें अभी भी कार्यभार पर टायरों को लात मारना होगा (हाँ, बहुवचन)। यह भी ध्यान दें कि SQL सर्वर 2019 में यह तकनीक इतनी अच्छी तरह से काम नहीं कर सकती है, लेकिन आप वहां ऑनलाइन क्लस्टर्ड कॉलमस्टोर इंडेक्स बना सकते हैं, इसलिए यह उतना मायने नहीं रखता।
इनमें से कुछ दृष्टिकोण आपको कम या ज्यादा स्वीकार्य हो सकते हैं, क्योंकि आप "उपलब्ध रहने" पर "जितनी जल्दी हो सके खत्म करने" या "उपलब्ध रहने" पर "डिस्क उपयोग को कम करने" या केवल पढ़ने के प्रदर्शन को संतुलित करने और ओवरहेड लिखने का पक्ष ले सकते हैं। .
यदि आप इसके किसी भी पहलू के बारे में अधिक जानकारी चाहते हैं, तो बस पूछें। मैंने पाचनशक्ति के साथ विस्तार को संतुलित करने के लिए कुछ वसा की छंटनी की, और मैं पहले उस संतुलन के बारे में गलत था। एक बिदाई विचार यह है कि मैं उत्सुक हूं कि यह कितना रैखिक है - हमारे पास समान संरचना वाली एक और तालिका है जो 25 टीबी से अधिक है, और मैं उत्सुक हूं कि क्या हम वहां कुछ समान प्रभाव डाल सकते हैं। तब तक, हैप्पी कंप्रेसिंग!
[ भाग 1 | भाग 2 | भाग 3 ]