आप एक ऐसे डेवलपर के साथ काम कर रहे हैं जो निम्न संग्रहीत कार्यविधि कॉल के लिए धीमे प्रदर्शन की रिपोर्ट कर रहा है:
EXEC [dbo].[charge_by_date] '2/28/2013';
आप पूछते हैं कि डेवलपर क्या समस्या देख रहा है, लेकिन केवल अतिरिक्त जानकारी जो आप सुनते हैं वह यह है कि यह "धीमी गति से चल रहा है।" तो आप SQL सर्वर इंस्टेंस पर कूदें और वास्तविक . पर एक नज़र डालें निष्पादन योजना। आप ऐसा इसलिए करते हैं क्योंकि आप न केवल इस बात में रुचि रखते हैं कि निष्पादन योजना कैसी दिखती है, बल्कि यह भी है कि योजना के लिए अनुमानित बनाम वास्तविक पंक्तियों की संख्या क्या है:
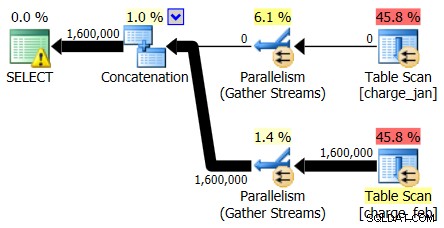
पहले केवल प्लान ऑपरेटरों को देखते हुए, आप कुछ उल्लेखनीय विवरण देख सकते हैं:
- रूट ऑपरेटर में एक चेतावनी है
- लीफ स्तर (चार्ज_जन और चार्ज_फेब) पर संदर्भित दोनों तालिकाओं के लिए एक टेबल स्कैन है और आपको आश्चर्य है कि ये दोनों अभी भी ढेर क्यों हैं और क्लस्टर इंडेक्स नहीं हैं
- आप देखते हैं कि केवल चार्ज_फेब टेबल से होकर बहने वाली पंक्तियां हैं, चार्ज_जन टेबल से नहीं
- आप योजना में समानांतर क्षेत्र देखते हैं
जहां तक रूट इटरेटर में चेतावनी का सवाल है, आप उस पर होवर करें और देखें कि निम्नलिखित इंडेक्स के लिए अनुशंसा के साथ अनुपलब्ध इंडेक्स चेतावनियां हैं:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_feb] ([charge_dt]) INCLUDE ([charge_no]) GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_jan] ([charge_dt]) INCLUDE ([charge_no]) GO
आप मूल डेटाबेस डेवलपर से पूछते हैं कि क्लस्टर इंडेक्स क्यों नहीं है, और जवाब है "मुझे नहीं पता।"
कोई भी परिवर्तन करने से पहले जांच जारी रखते हुए, आप SQL संतरी योजना एक्सप्लोरर में प्लान ट्री टैब को देखते हैं और आप वास्तव में देखते हैं कि किसी एक तालिका के लिए अनुमानित बनाम वास्तविक पंक्तियों के बीच महत्वपूर्ण विषमताएं हैं:

ऐसा लगता है कि दो मुद्दे हैं:
- चार्ज_जन टेबल स्कैन में पंक्तियों के लिए कम अनुमान
- चार्ज_फेब टेबल स्कैन में पंक्तियों के लिए अधिक अनुमान
तो कार्डिनैलिटी अनुमान हैं तिरछा, और आपको आश्चर्य होता है कि क्या यह पैरामीटर सूँघने से संबंधित है। आप पैरामीटर संकलित मान की जांच करने और पैरामीटर रनटाइम मान से इसकी तुलना करने का निर्णय लेते हैं, जिसे आप पैरामीटर्स टैब पर देख सकते हैं:

वास्तव में रनटाइम मान और संकलित मान के बीच अंतर हैं। आप डेटाबेस को एक उत्पाद-जैसे परीक्षण वातावरण में कॉपी करते हैं और फिर पहले 2/28/2013 के रनटाइम मान के साथ संग्रहीत कार्यविधि के निष्पादन का परीक्षण करते हैं और उसके बाद 1/31/2013 के बाद।
2/28/2013 और 1/31/2013 योजनाओं में समान आकार हैं लेकिन विभिन्न वास्तविक डेटा प्रवाह हैं। 2/28/2013 की योजना और कार्डिनैलिटी अनुमान इस प्रकार थे:
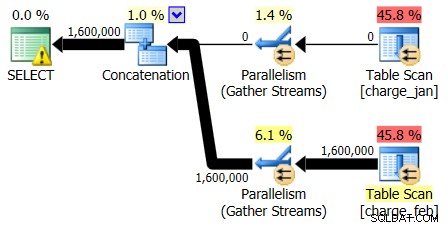

और जबकि 2/28/2013 योजना कोई कार्डिनैलिटी अनुमान समस्या नहीं दिखाती है, 1/31/2013 योजना यह करती है:
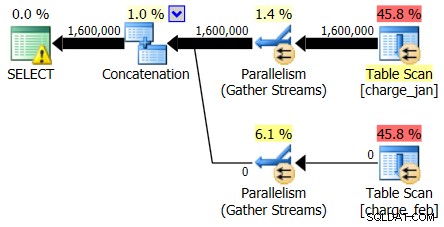

तो दूसरी योजना वही अधिक और कम अनुमान दिखाती है, जो आपके द्वारा देखी गई मूल योजना से बिल्कुल उलट है।
आप चार्ज_जन और चार्ज_फेब टेबल दोनों के लिए सुझाए गए इंडेक्स को प्रोड-जैसे परीक्षण वातावरण में जोड़ने का निर्णय लेते हैं और देखते हैं कि इससे कोई मदद मिलती है या नहीं। जनवरी/फरवरी क्रम में संग्रहीत कार्यविधियों को निष्पादित करते हुए, आप निम्नलिखित नई योजना आकृतियों और संबद्ध कार्डिनैलिटी अनुमानों को देखते हैं:
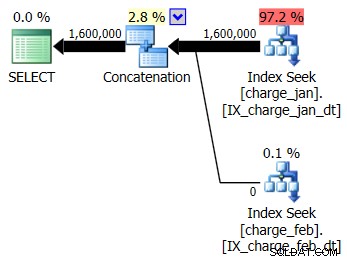

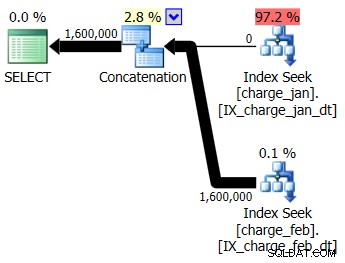

नई योजना प्रत्येक तालिका से इंडेक्स सीक ऑपरेशन का उपयोग करती है, लेकिन आप अभी भी शून्य पंक्तियों को एक तालिका से बहते हुए देखते हैं और दूसरी नहीं, और आप तब भी देखते हैं जब रनटाइम मान संकलन से अलग महीने में होता है, तो आप पैरामीटर सूँघने के आधार पर कार्डिनैलिटी का अनुमान लगाते हैं। समय मूल्य।
आपकी टीम के पास पर्याप्त लाभ के प्रमाण और संबद्ध प्रतिगमन परीक्षण के बिना अनुक्रमणिका नहीं जोड़ने की नीति है। आप कुछ समय के लिए, आपके द्वारा अभी बनाए गए गैर-संकुल अनुक्रमणिका को निकालने का निर्णय लेते हैं। जबकि आप लापता क्लस्टर . को तुरंत संबोधित नहीं करते हैं अनुक्रमणिका, आप तय करते हैं कि आप बाद में इसका ध्यान रखेंगे।
इस बिंदु पर आप महसूस करते हैं कि आपको संग्रहीत कार्यविधि की परिभाषा पर और गौर करने की आवश्यकता है, जो इस प्रकार है:
CREATE PROCEDURE dbo.charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt GO
आगे आप चार्ज_व्यू ऑब्जेक्ट की परिभाषा देखें:
CREATE VIEW charge_view AS SELECT * FROM [charge_jan] UNION ALL SELECT * FROM [charge_feb] GO
दृश्य संदर्भ उस डेटा को चार्ज करते हैं जिसे दिनांक के अनुसार अलग-अलग तालिकाओं में विभाजित किया जाता है। और फिर आपको आश्चर्य होता है कि क्या दूसरी क्वेरी निष्पादन योजना तिरछा को संग्रहीत कार्यविधि परिभाषा को बदलकर रोका जा सकता है।
शायद अगर ऑप्टिमाइज़र रनटाइम पर जानता है कि मूल्य क्या है, तो कार्डिनैलिटी अनुमान की समस्या दूर हो जाएगी और समग्र प्रदर्शन में सुधार होगा?
आप आगे बढ़ें और संग्रहीत प्रक्रिया कॉल को निम्नानुसार फिर से परिभाषित करें, एक RECOMPILE संकेत जोड़ें (यह जानते हुए कि आपने यह भी सुना है कि यह CPU उपयोग को बढ़ा सकता है, लेकिन चूंकि यह एक परीक्षण वातावरण है, आप इसे आज़माने में सुरक्षित महसूस करते हैं):
ALTER PROCEDURE charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt OPTION (RECOMPILE); GO
फिर आप 1/31/2013 मान और फिर 2/28/2013 मान का उपयोग करके संग्रहीत कार्यविधि को फिर से निष्पादित करते हैं।
योजना का आकार वही रहता है, लेकिन अब कार्डिनैलिटी अनुमान का मुद्दा हटा दिया गया है।
1/31/2013 कार्डिनैलिटी अनुमान डेटा दिखाता है:

और 2/28/2013 कार्डिनैलिटी अनुमान डेटा दिखाता है:

यह आपको एक पल के लिए खुश करता है, लेकिन फिर आपको एहसास होता है कि समग्र क्वेरी निष्पादन की अवधि अपेक्षाकृत पहले जैसी ही लगती है। आपको संदेह होने लगता है कि डेवलपर आपके परिणामों से खुश होगा। आपने कार्डिनैलिटी अनुमान की विषमता को हल कर लिया है, लेकिन अपेक्षित प्रदर्शन में वृद्धि के बिना, आप सुनिश्चित नहीं हैं कि आपने किसी सार्थक तरीके से मदद की है।
यह इस बिंदु पर है कि आप महसूस करते हैं कि क्वेरी निष्पादन योजना आपके लिए आवश्यक जानकारी का केवल एक सबसेट है, और इसलिए आप तालिका I/O टैब को देखकर अपने अन्वेषण का और विस्तार करते हैं। आप 1/31/2013 निष्पादन के लिए निम्न आउटपुट देखते हैं:

और 2/28/2013 निष्पादन के लिए आपको समान डेटा दिखाई देता है:

उस समय आपको आश्चर्य होता है कि क्या दोनों . के लिए डेटा एक्सेस संचालन प्रत्येक योजना में तालिकाएँ आवश्यक हैं। यदि अनुकूलक जानता है कि आपको केवल जनवरी पंक्तियों की आवश्यकता है, तो फरवरी तक क्यों पहुंचें, और इसके विपरीत? आपको यह भी याद है कि क्वेरी ऑप्टिमाइज़र की कोई गारंटी नहीं है कि नहीं हैं "गलत" तालिका में अन्य महीनों से वास्तविक पंक्तियाँ, जब तक कि ऐसी गारंटी स्पष्ट रूप से तालिका पर ही बाधाओं के माध्यम से नहीं की गई थी।
आप प्रत्येक तालिका के लिए sp_help के माध्यम से तालिका परिभाषाओं की जांच करते हैं और आपको किसी भी तालिका के लिए परिभाषित कोई बाधा नहीं दिखाई देती है।
तो एक परीक्षण के रूप में, आप निम्नलिखित दो बाधाओं को जोड़ते हैं:
ALTER TABLE [dbo].[charge_jan] ADD CONSTRAINT charge_jan_chk CHECK (charge_dt >= '1/1/2013' AND charge_dt < '2/1/2013'); GO ALTER TABLE [dbo].[charge_feb] ADD CONSTRAINT charge_feb_chk CHECK (charge_dt >= '2/1/2013' AND charge_dt < '3/1/2013'); GO
आप संग्रहीत कार्यविधियों को फिर से निष्पादित करते हैं और निम्न योजना आकार और कार्डिनैलिटी अनुमान देखते हैं।
1/31/2013 निष्पादन:
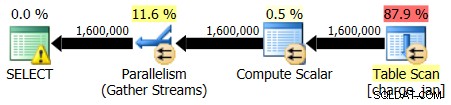

2/28/2013 निष्पादन:


तालिका I/O को फिर से देखते हुए, आप 1/31/2013 निष्पादन के लिए निम्न आउटपुट देखते हैं:

और 2/28/2013 निष्पादन के लिए आप समान डेटा देखते हैं, लेकिन चार्ज_फेब तालिका के लिए:

याद रखें कि आपके पास अभी भी संग्रहीत कार्यविधि परिभाषा में RECOMPILE है, आप इसे हटाने का प्रयास करते हैं और देखते हैं कि क्या आपको वही प्रभाव दिखाई देता है। ऐसा करने के बाद, आप दो-टेबल एक्सेस रिटर्न देखते हैं, लेकिन उस तालिका के लिए कोई वास्तविक तार्किक रीड नहीं है जिसमें इसमें कोई पंक्तियाँ नहीं हैं (बाधाओं के बिना मूल योजना की तुलना में)। उदाहरण के लिए, 1/31/2013 निष्पादन ने निम्न तालिका I/O आउटपुट दिखाया:

आप नई CHECK बाधाओं और RECOMPILE समाधान के लोड-परीक्षण के साथ आगे बढ़ने का निर्णय लेते हैं, जिससे टेबल एक्सेस पूरी तरह से योजना (और संबंधित योजना ऑपरेटरों) से हटा दिया जाता है। आप क्लस्टर इंडेक्स कुंजी और एक उपयुक्त सहायक गैर-क्लस्टर इंडेक्स के बारे में बहस के लिए खुद को तैयार करते हैं जो वर्तमान में संबंधित तालिकाओं तक पहुंचने वाले वर्कलोड के व्यापक सेट को समायोजित करेगा।