सबसे पहले, यह जानना महत्वपूर्ण है कि आप किन कॉलमों को समूहबद्ध करना चाहते हैं और आप उन्हें कैसे समूहबद्ध करना चाहते हैं। CASE STATEMENT . को सेट करने के लिए आपको यह जानना होगा कि हम अपने चुनिंदा स्टेटमेंट में कॉलम के रूप में लिखने जा रहे हैं। हमारे मामले में, हमारी साइट तक पहुँचने वाले ईमेल के एक समूह में, हम जानना चाहते हैं कि अगस्त की शुरुआत से प्रत्येक ईमेल प्रदाता कितने क्लिक का हिसाब दे रहा है। हम एक व्यक्तिगत ईमेल सेवा प्रदाता की तुलना अन्य से भी करना चाहेंगे। इस उदाहरण के लिए, हम अपने सेवा प्रदाता के रूप में Gmail का उपयोग करने जा रहे हैं।
हमारे चुनें . में विवरण, हमें DATE . की आवश्यकता होगी , प्रदाता और योग CLICKS . में से हमारी साइट पर। हम इन्हें TEST E MAILS . से प्राप्त कर सकते हैं हमारे डेटा स्रोत में तालिका।
दिनांक कॉलम बहुत सीधा है:
"Test E Mails"."Created_Date" AS "DATE
और चूंकि हम SUM . की तलाश कर रहे हैं CLICKS . में से , हमें एक SUM cast डालना होगा CLICKS पर कार्य करें कॉलम।
SUM("Test E Mails"."Clicks") AS "CLICKS"
यह हमें हमारे CASE STATEMENT . पर लाता है . हम PostgreSQL दस्तावेज़ीकरण से जानते हैं कि एक केस स्टेटमेंट, या एक सशर्त स्टेटमेंट को निम्नलिखित तरीके से व्यवस्थित करने की आवश्यकता है:
CASE
WHEN condition THEN result
[WHEN ...]
[ELSE result]
END
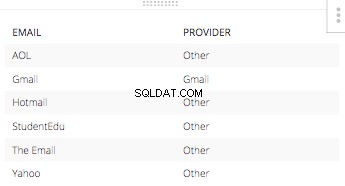
हमारी पहली और, केवल इस मामले में, शर्त यह है कि हम उन सभी ईमेल पतों को जानना चाहते हैं जो जीमेल द्वारा हर दूसरे ईमेल प्रदाता से अलग होने के लिए प्रदान किए जाते हैं। तो केवल कब है:
WHEN "Test E Mails"."Provider" = 'Gmail' THEN 'Gmail'
और, हर दूसरे ईमेल पता प्रदाता के लिए अन्य कथन 'अन्य' होगा। इस CASE STATEMENT . की परिणामी तालिका अकेले संबंधित ईमेल के साथ। इस तरह दिखेगा:
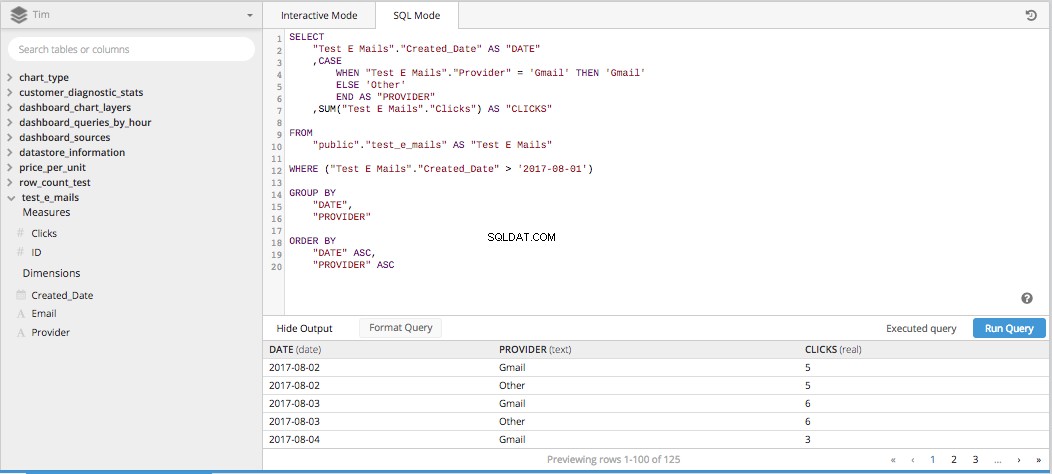
जब आप उन तीनों कॉलमों को एक SELECT STATEMENT . के लिए पीसते हैं और SQL क्वेरी बनाने के लिए बाकी आवश्यक टुकड़ों में फेंक दें, यह सब नीचे आकार लेता है।
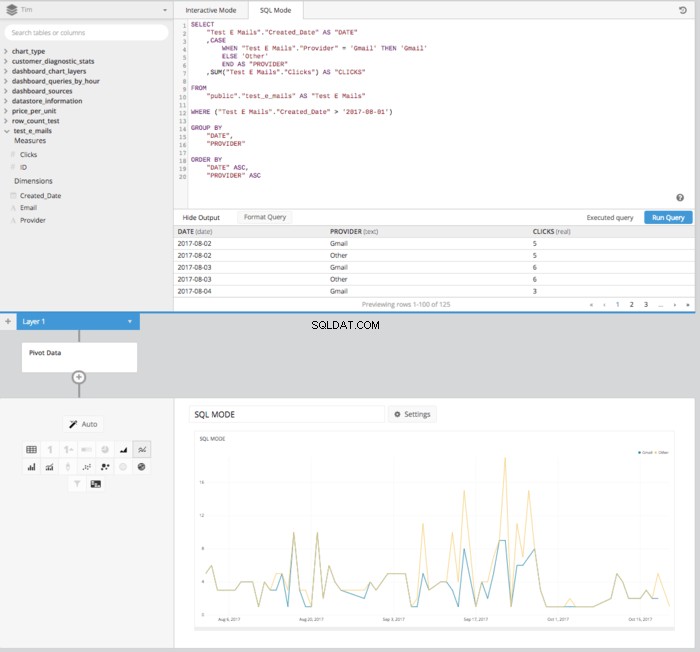
फिर एक पिवट डेटा जोड़ने के बाद डेटा पाइपलाइन में कदम रखने के बाद, हमें एक लाइन चार्ट सेट करने के लिए उचित प्रारूप में उचित रूप से व्यवस्थित एक तालिका मिलेगी, जिसमें दिखाया जाएगा कि समय के साथ क्लिकों की तुलना कैसे की जाती है।
चार्टियो का उपयोग करने में, हम उपरोक्त सभी को बिना कोई एसक्यूएल लिखे कर सकते हैं लेकिन डेटा एक्सप्लोरर और डेटा पाइपलाइन सुविधाओं का लाभ उठा सकते हैं। उन सभी कॉलमों को खींचने के लिए हमारी अंतर्निहित क्वेरी बनाने के बाद, जिनकी हमें आवश्यकता होगी SUM OF CLICKS , दिनांक और ईमेल पता हम इस डेटा पोस्ट-एसक्यूएल में हेरफेर करने के लिए डेटा पाइपलाइन का उपयोग कर सकते हैं। सबसे पहले, क्वेरी बनाते हैं।
'क्लिक कॉलम' को माप बॉक्स में खींचें और इसे TOTAL SUM . द्वारा एकत्रित करें कॉलम क्लिकों में से, फिर इसे 'क्लिक' फिर से लेबल करें।
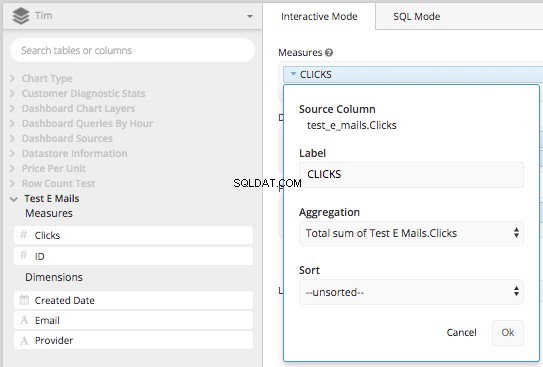
फिर 'बनाई गई तिथि' और 'प्रदाता' को आयाम बॉक्स में खींचें और उन्हें 'दिनांक' और 'ईमेल प्रदाता' फिर से लेबल करें। उसके बाद, 'बनाई गई तिथि' कॉलम का उपयोग करके आप तिथि अवधि निर्धारित कर सकते हैं (या अपना <कोड बना सकते हैं)>कहां क्लॉज) 2017-08-01 के बाद सब कुछ होना। यह CASE STATEMENT . बनाने के लिए एक अंतर्निहित क्वेरी में प्रभावी रूप से वह सब कुछ तैयार करेगा जिसकी हमें आवश्यकता है हमने चार्टियो की डेटा पाइपलाइन में ऊपर किया था।
एक केस स्टेटमेंट जोड़ना पाइपलाइन चरण हमें WHEN . के लिए शर्तें निर्धारित करने की अनुमति देता है और ELSE ठीक वैसे ही जैसे हमने पहले किया था, पूरे SQL सिंटैक्स में टाइप किए बिना।
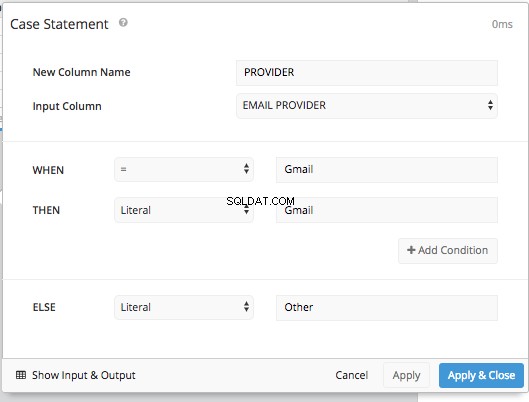
फिर मूल 'प्रदाता' कॉलम को छुपाने और REORDER COLUMNS . का उपयोग करने के बाद चरण और एक पिवट डेटा चरण हमें वही तालिका व्यवस्था मिलेगी जो हमें SQL मोड में मिली थी और उसी तालिका को प्रस्तुत कर सकते हैं जो हमने SQL मोड में की थी।
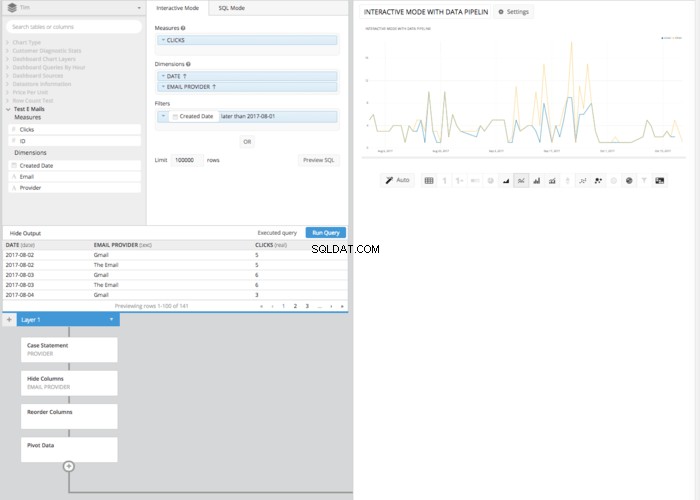
हालांकि इसमें SQL मोड की तुलना में कुछ अधिक क्लिक और चरण लग सकते हैं, परिणामी लाइन चार्ट इंटरएक्टिव मोड में किए गए SQL सिंटैक्स के ज्ञान की आवश्यकता नहीं है। इसके बजाय इसमें शामिल सिद्धांतों की एक बुनियादी समझ है। यह एक और उदाहरण है कि कैसे चार्टियो एसक्यूएल ज्ञान की परवाह किए बिना डेटा की शक्ति को हर किसी के हाथों में रखने में मदद कर रहा है।