मैं अपने घर को अव्यवस्थित करने की प्रक्रिया में हूं (गर्मियों में बहुत देर हो चुकी है और इसे वसंत की सफाई के रूप में पारित करने की कोशिश कर रहा हूं)। आप जानते हैं, कोठरी की सफाई करना, बच्चों के खिलौनों से गुजरना और तहखाने का आयोजन करना। यह एक दर्दनाक प्रक्रिया है। जब हम 10 साल पहले अपने घर आए थे तो हमारे पास बहुत जगह थी। अब मुझे लगता है कि हर जगह सामान है, और जो मैं वास्तव में ढूंढ रहा हूं उसे ढूंढना कठिन हो जाता है और इसे साफ करने और व्यवस्थित करने में अधिक समय लगता है।
क्या यह आपके द्वारा प्रबंधित किसी डेटाबेस की तरह लगता है?
कई क्लाइंट जिनके साथ मैंने काम किया है, वे डेटा को शुद्ध करने के बाद एक विचार के रूप में काम करते हैं। क्रियान्वयन के समय हर कोई सब कुछ बचाना चाहता है। "हम कभी नहीं जानते कि हमें इसकी आवश्यकता कब हो सकती है।" एक या दो साल बाद किसी को पता चलता है कि डेटाबेस में बहुत सारी अतिरिक्त चीजें हैं, लेकिन अब लोग इससे छुटकारा पाने से डरते हैं। "हमें यह देखने के लिए कानूनी से जांच करने की आवश्यकता है कि क्या हम इसे हटा सकते हैं।" लेकिन कोई भी कानूनी के साथ जांच नहीं करता है, या यदि कोई करता है, तो कानूनी वापस व्यापार मालिकों के पास यह पूछने के लिए जाता है कि क्या रखना है, और फिर परियोजना रुक जाती है। "हम इस बारे में आम सहमति नहीं बना सकते कि क्या हटाया जा सकता है।" परियोजना को भुला दिया जाता है, और फिर सड़क के नीचे दो या चार साल, डेटाबेस अचानक एक टेराबाइट है, जिसे प्रबंधित करना मुश्किल है, और लोग डेटाबेस के आकार पर सभी प्रदर्शन मुद्दों को दोष देते हैं। आप चारों ओर "विभाजन" और "संग्रह डेटाबेस" शब्द सुनते हैं, और कभी-कभी आपको केवल डेटा का एक समूह हटाना पड़ता है, जिसमें अपनी समस्याएं होती हैं।
आदर्श रूप से आपको कार्यान्वयन से पहले या लाइव होने के पहले छह से बारह महीनों के भीतर अपनी शुद्ध रणनीति पर निर्णय लेना चाहिए। लेकिन चूंकि हम उस चरण को पार कर चुके हैं, आइए देखें कि इस अतिरिक्त डेटा का क्या प्रभाव हो सकता है।
परीक्षण पद्धति
स्टेज सेट करने के लिए, मैंने क्रेडिट डेटाबेस की एक प्रति ली और इसे अपने SQL Server 2012 इंस्टेंस में पुनर्स्थापित किया। मैंने तीन मौजूदा गैर-संकुल अनुक्रमितों को गिरा दिया और अपने स्वयं के दो जोड़े:
उपयोग [मास्टर]; GO RESTORE DATABASE [क्रेडिट] डिस्क से =N'C:\SQLskills\SampleDatabases\Credit\CreditBackup100.bak' with FILE =1, MOVE N'CreditData' to N'D:\Databases\ SQL2012\CreditData.mdf', N'CreditLog' को N'D में ले जाएँ:\Databases\SQL2012\CreditLog.ldf', STATS =5; डेटाबेस बदलें [क्रेडिट] संशोधित फ़ाइल (नाम =N'CreditData', SIZE =14680064KB , FILEGROWTH =524288KB );GOALTER DATABASE [क्रेडिट] फ़ाइल को संशोधित करें (NAME =N'CreditLog', SIZE =2097152KB, FILEGROWTH =524288KB); उपयोग करें [क्रेडिट]; GO DROP INDEX [dbo]।;ड्रॉप इंडेक्स [डीबीओ]। [चार्ज]। [चार्ज_प्रोवाइडर_लिंक]; ड्रॉप इंडेक्स [डीबीओ]। [चार्ज]। [चार्ज_स्टेटमेंट_लिंक]; [dbo] पर गैर-अनुक्रमित सूचकांक [चार्ज_चार्जडेट] बनाएं।फिर मैंने पंक्तियों के मूल सेट को कई बार फिर से सम्मिलित करके, तिथियों को थोड़ा संशोधित करके तालिका में पंक्तियों की संख्या को बढ़ाकर 14.4 मिलियन कर दिया:
INSERT INTO [डीबीओ]। [category_no], [charge_dt] - 175, [charge_amt], [statement_no], [charge_code]FROM [dbo]।[चार्ज] जहां [चार्ज_नो] 1 और 2000000 के बीच; GO 3 INSERT INTO [dbo]।[चार्ज] ( [सदस्य_नो], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code]) चुनें [सदस्य_नो], [provider_no], [category_no], [charge_dt], [charge_amt], [ कथन_नो], [चार्ज_कोड] [डीबीओ] से। , [charge_amt], [statement_no], [charge_code]) चुनें [member_no], [provider_no], [category_no], [charge_dt] + 79, [charge_amt], [statement_no], [charge_code]FROM [dbo] से।[चार्ज ] जहां [चार्ज_नो] 1 और 2000000 के बीच; जाओ 3अंत में, मैंने डेटाबेस के विरुद्ध कथनों की एक श्रृंखला को चार बार निष्पादित करने के लिए एक परीक्षण हार्नेस स्थापित किया। बयान नीचे दिए गए हैं:
ALTER INDEX ALL ON [dbo]।[चार्ज] रीबिल्ड; DBCC CHECKDB (क्रेडिट) ALL_ERRORMSGS, NO_INFOMSGS के साथ; बैकअप डेटाबेस [क्रेडिट] डिस्क पर =N'D:\Backups\SQL2012\Credit.bak' NOFORMAT के साथ, INIT, NAME =N'क्रेडिट-पूर्ण डेटाबेस बैकअप', STATS =10; [चार्ज_नो], [सदस्य_नो], [चार्ज_डीटी], [चार्ज_एएमटी] [डीबीओ] से चुनें।[चार्ज] जहां [चार्ज_नो] =841345; DECLARE @StartDate DATETIME ='1999-07-01'; DECLARE @EndDate DATETIME ='1999-07-31'; [चार्ज_डीटी], COUNT ([चार्ज_डीटी]) [डीबीओ] से चुनें। [चार्ज] जहां [चार्ज_डीटी] @ स्टार्टडेट और @ एंडडेट ग्रुप बाय [चार्ज_डीटी] के बीच; चुनें [provider_no], COUNT([provider_no]) [dbo] से।[शुल्क] जहां [provider_no] =475 GROUP BY [provider_no]; [provider_no], COUNT([provider_no]) [dbo] से चुनें।[शुल्क] जहां [provider_no] =140 GROUP BY [provider_no];प्रत्येक कथन से पहले मैंने निष्पादित किया
DBCC DROPCLEANBUFFERS;GOबफर पूल को साफ करने के लिए। जाहिर है यह उत्पादन के माहौल के खिलाफ निष्पादित करने के लिए कुछ नहीं है। मैंने इसे यहां प्रत्येक परीक्षण के लिए एक सुसंगत प्रारंभिक बिंदु प्रदान करने के लिए किया था।
प्रत्येक निष्पादन के बाद, मैंने अपने द्वारा शुरू की गई 14.4 मिलियन पंक्तियों को सम्मिलित करके dbo.charge तालिका का आकार बढ़ाया, लेकिन मैंने प्रत्येक निष्पादन के लिए चार्ज_डीटी को एक वर्ष बढ़ा दिया। उदाहरण के लिए:
INSERT INTO [डीबीओ]। [category_no], [charge_dt] + 365, [charge_amt], [statement_no], [charge_code]FROM [dbo]।[चार्ज]जहां [चार्ज_नो] 1 और 14800000 के बीच;जाओ14.4 मिलियन पंक्तियों को जोड़ने के बाद, मैंने परीक्षण हार्नेस को फिर से चलाया। मैंने इसे छह बार दोहराया, अनिवार्य रूप से छह "वर्ष" डेटा जोड़ना। dbo.charge तालिका 1999 से डेटा के साथ शुरू हुई, और बार-बार डालने के बाद 2005 तक डेटा शामिल था।
परिणाम
निष्पादन के परिणाम यहां देखे जा सकते हैं:
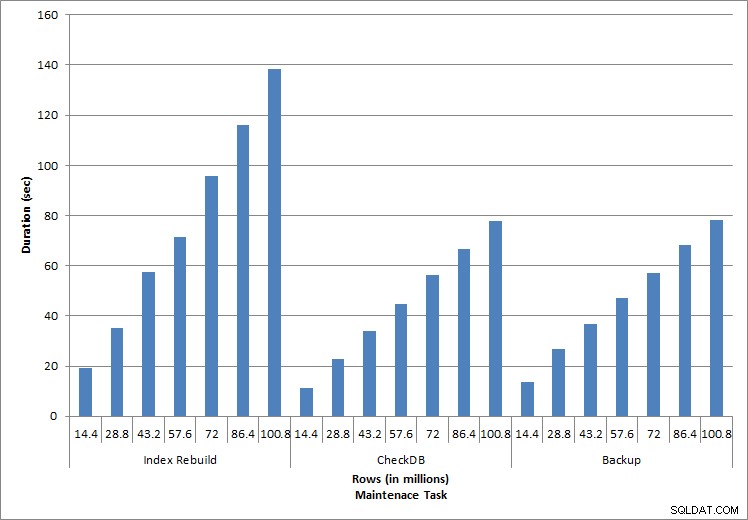
रखरखाव कार्यों की अवधि
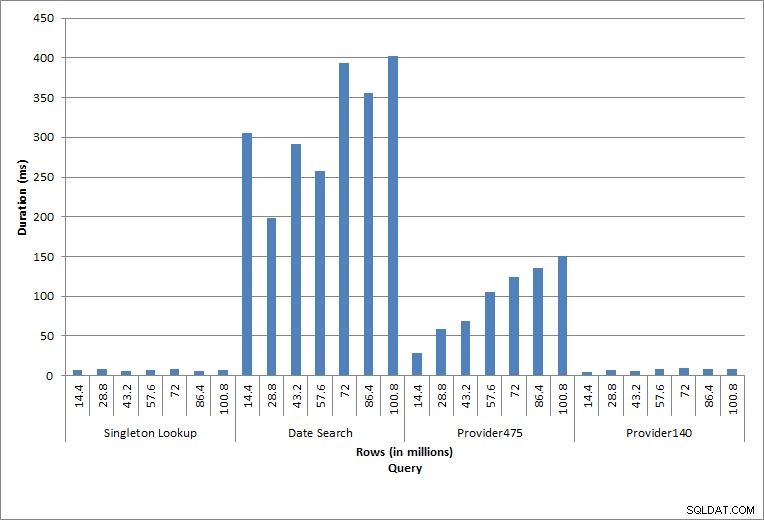
प्रश्नों की अवधिनिष्पादित व्यक्तिगत विवरण विशिष्ट डेटाबेस गतिविधि को दर्शाते हैं। सूचकांक पुनर्निर्माण, अखंडता जांच और बैकअप नियमित डेटाबेस रखरखाव का हिस्सा हैं। चार्ज टेबल के खिलाफ क्वेरीज़ सिंगलटन लुकअप के साथ-साथ तालिका में डेटा के लिए विशिष्ट रेंज स्कैन के तीन रूपांतरों का प्रतिनिधित्व करती हैं।
सूचकांक पुनर्निर्माण, CHECKDB, और बैकअप
जैसा कि रखरखाव कार्यों के लिए अपेक्षित था, डेटाबेस में अधिक पंक्तियों को जोड़ने के साथ-साथ अवधि और IO मान में वृद्धि हुई। डेटाबेस का आकार 10 के कारक से बढ़ा, और जबकि अवधि समान दर से नहीं बढ़ी, लगातार वृद्धि देखी गई। प्रत्येक रखरखाव कार्य को शुरू में पूरा होने में 20 सेकंड से भी कम समय लगा, लेकिन जैसे-जैसे अधिक पंक्तियाँ जोड़ी गईं, कार्यों की अवधि 100 मिलियन पंक्तियों के लिए लगभग 1 मिनट और 20 सेकंड तक बढ़ गई (और सूचकांक के पुनर्निर्माण के लिए 2 मिनट से अधिक)। यह अतिरिक्त डेटा के कारण कार्य को पूरा करने के लिए आवश्यक अतिरिक्त समय SQL सर्वर को दर्शाता है।
सिंगलटन लुकअप
किसी विशिष्ट चार्ज_नो के लिए dbo.charge के विरुद्ध क्वेरी ने हमेशा एक पंक्ति का उत्पादन किया - और उपयोग किए गए मान की परवाह किए बिना एक पंक्ति का उत्पादन किया होगा, क्योंकि चार्ज_नो एक विशिष्ट पहचान है। इस लुकअप के लिए न्यूनतम भिन्नता है। जैसे-जैसे पंक्तियों को तालिका में लगातार जोड़ा जाता है, सूचकांक एक या दो स्तरों तक गहराई में बढ़ सकता है (जैसे-जैसे तालिका चौड़ी होती जाती है), इसलिए कुछ आईओ जोड़ना, लेकिन यह बहुत कम आईओ के साथ सिंगलटन लुकअप है।
रेंज स्कैन
दिनांक सीमा (चार्ज_डीटी) के लिए क्वेरी को जुलाई के नवीनतम वर्ष के डेटा (जैसे '2005-07-01' से '2005-07-01' परीक्षणों के अंतिम सेट के लिए) खोजने के लिए प्रत्येक प्रविष्टि के बाद संशोधित किया गया था, लेकिन वापस आ गया हर बार केवल 1.2 मिलियन से अधिक पंक्तियाँ। वास्तविक दुनिया के परिदृश्य में, हम उम्मीद नहीं करेंगे कि एक ही महीने में, साल दर साल पंक्तियों की समान संख्या लौटाई जाएगी, और न ही हम यह उम्मीद करेंगे कि साल में हर महीने उतनी ही पंक्तियों को वापस किया जाएगा। लेकिन पंक्तियों की संख्या महीनों के बीच समान सीमा के भीतर रह सकती है, जिसमें समय के साथ मामूली वृद्धि होती है। इस क्वेरी की अवधि में उतार-चढ़ाव मौजूद है, लेकिन sys.dm_io_virtual_file_stats से कैप्चर किए गए IO डेटा की समीक्षा पढ़ने की संख्या में निरंतरता दिखाती है।
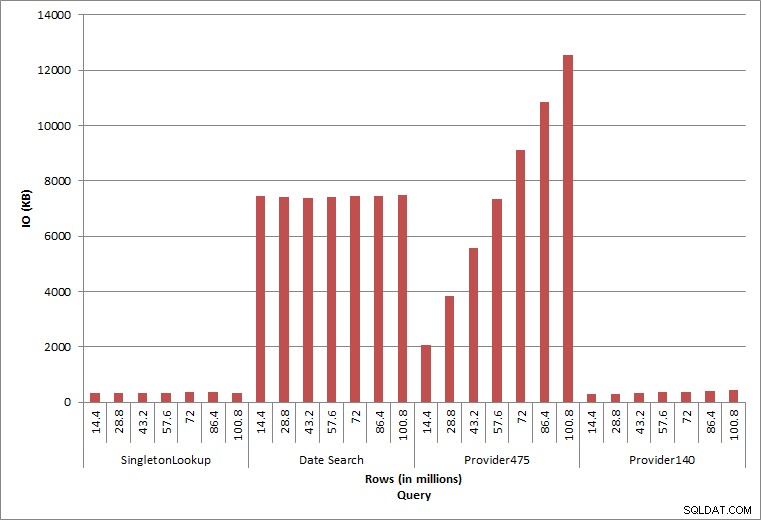
क्वेरी IOअंतिम दो प्रश्न, दो अलग-अलग प्रदाता_नो मानों के लिए, डेटा रखने का सही प्रभाव दिखाते हैं। प्रारंभिक dbo.चार्ज तालिका में, प्रदाता_नंबर 475 में 126,000 से अधिक पंक्तियां थीं और प्रदाता_नंबर 140 में 1700 से अधिक पंक्तियां थीं। जोड़े गए प्रत्येक 14.4 मिलियन पंक्तियों के लिए, प्रत्येक प्रदाता_नो के लिए लगभग समान पंक्तियों को जोड़ा गया था। उत्पादन परिवेश में, इस प्रकार का डेटा वितरण असामान्य नहीं है, और इस डेटा के लिए क्वेरी समाधान के पहले वर्षों में अच्छा प्रदर्शन कर सकती हैं, लेकिन समय के साथ घट सकती हैं क्योंकि अधिक पंक्तियाँ जोड़ी जाती हैं। प्रदाता_संख्या 475 के लिए प्रारंभिक और अंतिम निष्पादन के बीच क्वेरी अवधि पांच के कारक (31 एमएस से 153 एमएस तक) बढ़ जाती है। हालांकि यह प्रभाव महत्वपूर्ण नहीं लग सकता है, आईओ (ऊपर) में समानांतर वृद्धि पर ध्यान दें। यदि यह एक ऐसी क्वेरी थी जिसे उच्च आवृत्ति के साथ निष्पादित किया गया था, और/या ऐसे ही प्रश्न थे जो नियमित आवृत्ति के साथ निष्पादित किए गए थे, तो अतिरिक्त भार समग्र संसाधन उपयोग को जोड़ और प्रभावित कर सकता है। इसके अलावा, जब आप अरबों पंक्तियों वाली तालिकाओं के साथ काम कर रहे हों, और जटिल जोड़ के साथ प्रश्नों में उपयोग किया जाता है, और आपके नियमित - और अत्यंत महत्वपूर्ण - रखरखाव कार्यों पर प्रभाव पर विचार करें। अंत में, पुनर्प्राप्ति समय को ध्यान में रखें। आपकी आपदा पुनर्प्राप्ति योजना पुनर्स्थापना समय पर आधारित होनी चाहिए, और जैसे-जैसे डेटाबेस का आकार बढ़ता है, डेटाबेस को इसकी संपूर्णता में पुनर्स्थापित होने में अधिक समय लगेगा। यदि आप नियमित रूप से परीक्षण नहीं कर रहे हैं और अपनी पुनर्स्थापना का समय नहीं दे रहे हैं, तो किसी आपदा से उबरने में आपके विचार से अधिक समय लग सकता है।
सारांश
यहां दिखाए गए उदाहरण सरल उदाहरण हैं कि क्या हो सकता है जब डेटाबेस कार्यान्वयन के दौरान डेटा संग्रह रणनीति निर्धारित नहीं की जाती है, और अन्वेषण और परीक्षण के लिए कई अन्य परिदृश्य हैं। पुराना डेटा, जो शायद ही कभी, एक्सेस किया गया हो, डिस्क पर केवल स्थान की तुलना में अधिक प्रभाव डालता है। यह क्वेरी प्रदर्शन और रखरखाव कार्यों की अवधि को प्रभावित कर सकता है। एक उदाहरण पर कई डेटाबेस का प्रबंधन करने वाले DBA के रूप में, ऐतिहासिक डेटा रखने वाला एक डेटाबेस अन्य डेटाबेस के प्रदर्शन और रखरखाव कार्यों को प्रभावित कर सकता है। इसके अलावा, यदि रिपोर्ट ऐतिहासिक डेटा के विरुद्ध निष्पादित होती है, तो यह पहले से ही व्यस्त OLTP वातावरण पर कहर बरपा सकती है।
शुरुआत से ही, यह महत्वपूर्ण है कि डेटाबेस में डेटा का जीवनकाल निर्धारित किया जाए, और कार्य योजना बनाई जाए। कुछ समाधानों के लिए, सभी डेटा को हमेशा के लिए रखना आवश्यक है। इस मामले में, डेटाबेस आकार को प्रबंधनीय रखने के लिए रणनीतियों को नियोजित करें, उदाहरण के लिए:नियमित रूप से डेटा को एक अलग टेबल या अलग डेटाबेस में संग्रहित करें। इस घटना में कि डेटा को वर्षों और वर्षों तक संग्रहीत करने की आवश्यकता नहीं है, एक शुद्धिकरण रणनीति लागू करें जो नियमित रूप से डेटा को हटा देती है। इस तरह, आप उन खिलौनों को बाहर फेंक सकते हैं जिनके साथ अब खेला नहीं जाता है, ऐसे कपड़े जो अब फिट नहीं होते हैं, और बेतरतीब कबाड़ जिसे आप हर तीन महीने में इस्तेमाल नहीं करते हैं… हर 10 साल में एक बार के बजाय।