मुझे हाल ही में यह सुझाव देने के लिए डांटा गया था कि, कुछ मामलों में, एक गैर-क्लस्टर इंडेक्स क्लस्टर इंडेक्स की तुलना में किसी विशेष क्वेरी के लिए बेहतर प्रदर्शन करेगा। इस व्यक्ति ने कहा कि क्लस्टर्ड इंडेक्स हमेशा सबसे अच्छा होता है क्योंकि यह हमेशा परिभाषा के अनुसार कवर होता है, और यह कि कुछ या सभी समान कुंजी कॉलम वाला कोई भी गैर-क्लस्टर इंडेक्स हमेशा बेमानी था।
मैं खुशी-खुशी इस बात से सहमत हूं कि क्लस्टर इंडेक्स हमेशा कवर होता है (और यहां किसी भी अस्पष्टता से बचने के लिए, हम पारंपरिक बी-ट्री इंडेक्स के साथ डिस्क-आधारित टेबल से चिपके रहेंगे)।
 मैं इस बात से असहमत हूं कि क्लस्टर इंडेक्स हमेशा होता है एक गैर-संकुल सूचकांक से तेज। मैं इस बात से भी असहमत हूं कि क्लस्टरिंग कुंजी में एक ही (या कुछ समान) कॉलम से मिलकर एक गैर-संकुल सूचकांक या अद्वितीय बाधा बनाना हमेशा बेमानी है।
मैं इस बात से असहमत हूं कि क्लस्टर इंडेक्स हमेशा होता है एक गैर-संकुल सूचकांक से तेज। मैं इस बात से भी असहमत हूं कि क्लस्टरिंग कुंजी में एक ही (या कुछ समान) कॉलम से मिलकर एक गैर-संकुल सूचकांक या अद्वितीय बाधा बनाना हमेशा बेमानी है।
आइए इस उदाहरण को लेते हैं, Warehouse.StockItemTransactions , वाइडवर्ल्ड इंपोर्टर्स से। संकुल सूचकांक केवल StockItemTransactionID . पर प्राथमिक कुंजी के माध्यम से कार्यान्वित किया जाता है कॉलम (बहुत विशिष्ट जब आपके पास किसी पहचान या अनुक्रम द्वारा उत्पन्न किसी प्रकार की सरोगेट आईडी होती है)।
संपूर्ण तालिका की गिनती की आवश्यकता के लिए यह एक बहुत ही सामान्य बात है (हालांकि कई मामलों में बेहतर तरीके हैं)। यह आकस्मिक निरीक्षण के लिए या पेजिनेशन प्रक्रिया के भाग के रूप में हो सकता है। अधिकांश लोग इसे इस तरह से करेंगे:
SELECT COUNT(*) FROM Warehouse.StockItemTransactions;
वर्तमान स्कीमा के साथ, यह एक गैर-संकुल अनुक्रमणिका का उपयोग करेगा:
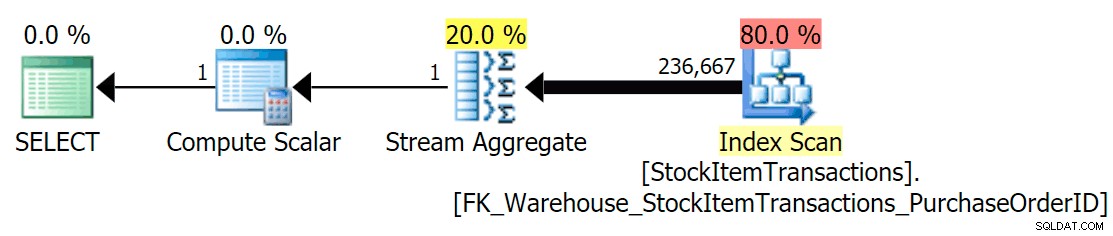
हम जानते हैं कि गैर-संकुल अनुक्रमणिका में संकुल अनुक्रमणिका के सभी स्तंभ नहीं होते हैं। काउंट ऑपरेशन को केवल यह सुनिश्चित करने की आवश्यकता है कि सभी पंक्तियों को शामिल किया गया है, इस बात की परवाह किए बिना कि कौन से कॉलम मौजूद हैं, इसलिए SQL सर्वर आमतौर पर सबसे कम पृष्ठों वाले इंडेक्स का चयन करेगा (इस मामले में, चुने गए इंडेक्स में ~ 414 पेज हैं)।
अब क्वेरी को फिर से चलाते हैं, इस बार इसकी तुलना एक संकेतित क्वेरी से करते हैं जो क्लस्टर्ड इंडेक्स के उपयोग के लिए बाध्य करती है।
SELECT COUNT(*) FROM Warehouse.StockItemTransactions; SELECT COUNT(*) /* with hint */ FROM Warehouse.StockItemTransactions WITH (INDEX(1));
हमें लगभग एक समान योजना आकार मिलता है, लेकिन हम पढ़ने में एक बड़ा अंतर देख सकते हैं (चुने गए इंडेक्स के लिए 414 बनाम क्लस्टर इंडेक्स के लिए 1,982):
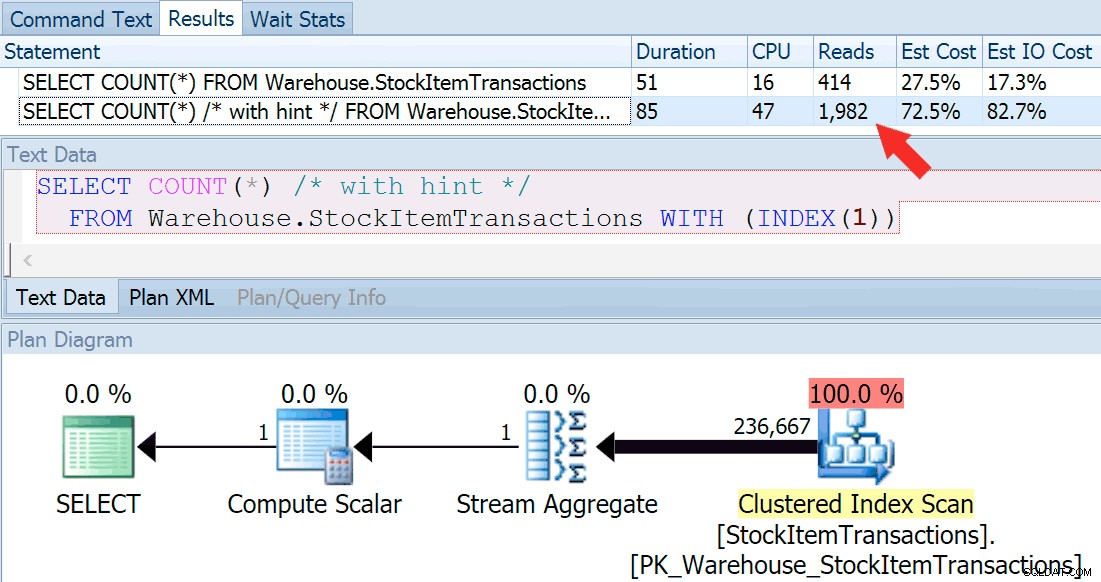
क्लस्टर्ड इंडेक्स के लिए अवधि थोड़ी अधिक होती है, लेकिन जब हम फास्ट डिस्क पर कैश्ड डेटा की एक छोटी मात्रा के साथ काम कर रहे होते हैं तो अंतर नगण्य होता है। धीमी डिस्क पर, या मेमोरी प्रेशर वाले सिस्टम पर अधिक डेटा के साथ यह विसंगति बहुत अधिक स्पष्ट होगी।
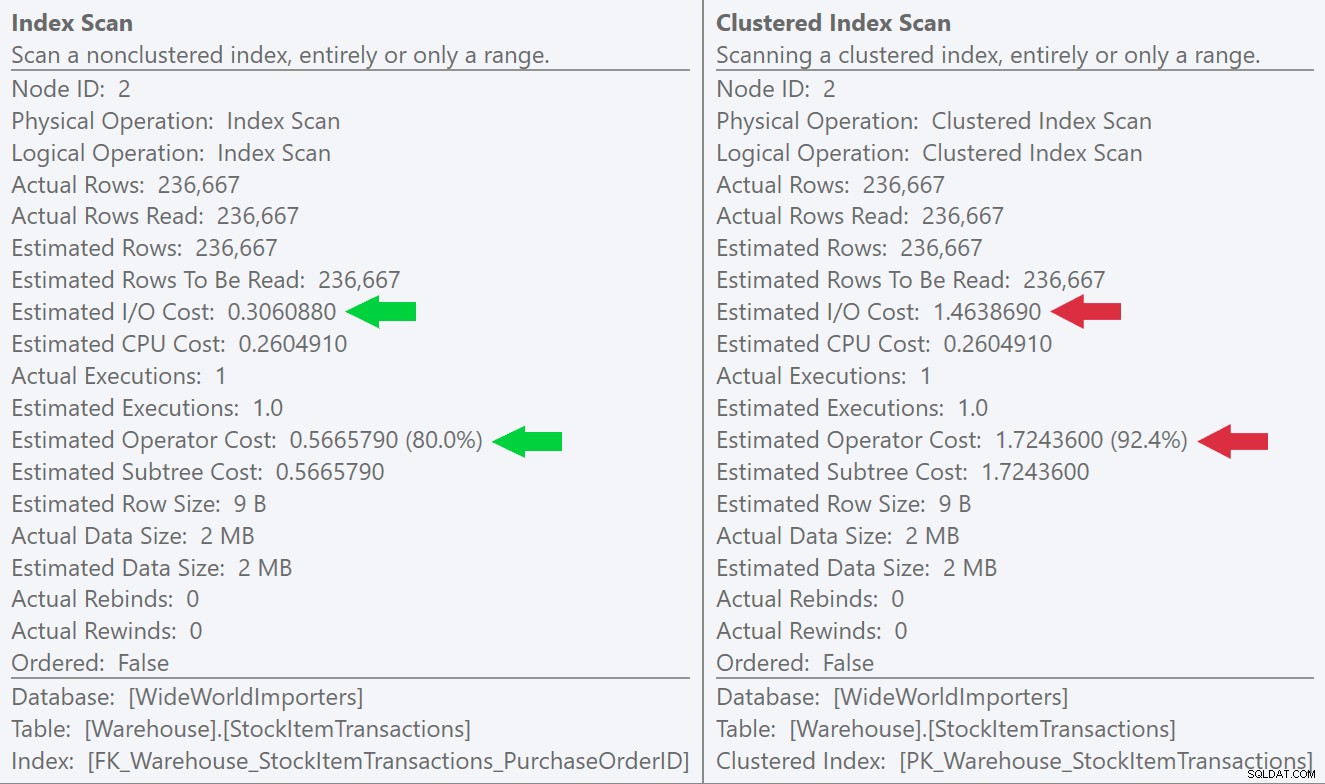
यदि हम स्कैन संचालन के लिए टूलटिप्स को देखते हैं, तो हम देख सकते हैं कि पंक्तियों की संख्या और अनुमानित CPU लागत समान हैं, बड़ा अंतर अनुमानित I/O लागत से आता है (क्योंकि SQL सर्वर जानता है कि इसमें अधिक पृष्ठ हैं गैर-संकुल सूचकांक की तुलना में संकुल सूचकांक):
हम इस अंतर को और भी स्पष्ट रूप से देख सकते हैं यदि हम केवल आईडी कॉलम पर एक नया, अद्वितीय इंडेक्स बनाते हैं (इसे क्लस्टर इंडेक्स के साथ "अनावश्यक" बनाते हैं, है ना?):
CREATE UNIQUE INDEX NewUniqueNCIIndex ON Warehouse.StockItemTransactions(StockItemTransactionID);
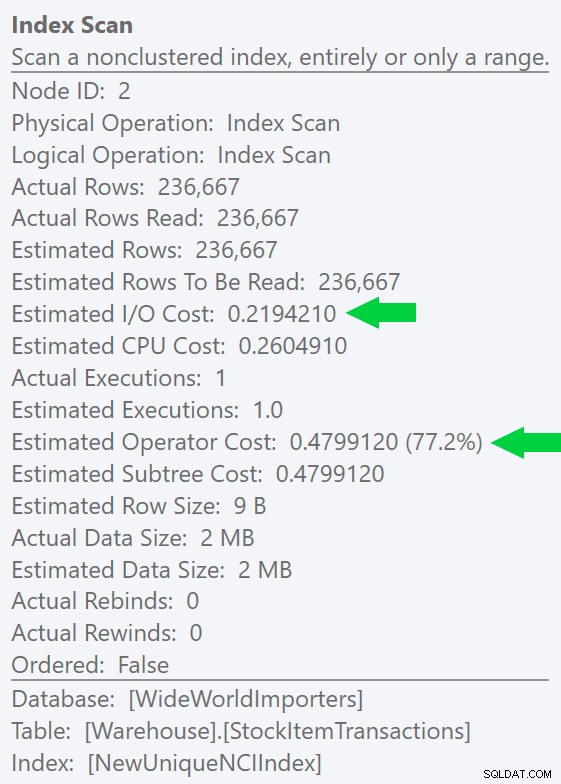 एक स्पष्ट इंडेक्स संकेत के साथ एक समान क्वेरी चलाने से समान योजना आकार उत्पन्न होता है, लेकिन इससे भी कम अनुमानित I/O लागत (और इससे भी कम अवधि) - दाईं ओर छवि देखें। और यदि आप बिना संकेत के मूल क्वेरी चलाते हैं, तो आप देखेंगे कि SQL सर्वर अब इस अनुक्रमणिका को भी चुनता है।
एक स्पष्ट इंडेक्स संकेत के साथ एक समान क्वेरी चलाने से समान योजना आकार उत्पन्न होता है, लेकिन इससे भी कम अनुमानित I/O लागत (और इससे भी कम अवधि) - दाईं ओर छवि देखें। और यदि आप बिना संकेत के मूल क्वेरी चलाते हैं, तो आप देखेंगे कि SQL सर्वर अब इस अनुक्रमणिका को भी चुनता है।
यह स्पष्ट लग सकता है, लेकिन बहुत से लोग मानते हैं कि क्लस्टर्ड इंडेक्स यहां सबसे अच्छा विकल्प है। SQL सर्वर लगभग हमेशा भारी समर्थन देने वाला है, जो भी विधि सभी I/O को निष्पादित करने का सबसे सस्ता तरीका प्रदान करेगी, और पूर्ण स्कैन के मामले में, यह "सबसे पतला" सूचकांक होने जा रहा है। यह दोनों तरह के सीक्स (सिंगलटन और रेंज स्कैन) के साथ भी हो सकता है, कम से कम जब इंडेक्स कवर कर रहा हो।
अब, हमेशा की तरह, यह नहीं है किसी भी तरह से इसका मतलब है कि गिनती प्रश्नों को पूरा करने के लिए आपको अपनी सभी टेबलों पर अतिरिक्त इंडेक्स बनाना चाहिए। न केवल तालिका आकार की जांच करने का एक अक्षम तरीका है (फिर से, यह आलेख देखें), लेकिन समर्थन के लिए एक अनुक्रमणिका का मतलब यह होगा कि आप डेटा को अपडेट करने की तुलना में उस क्वेरी को अधिक बार चला रहे हैं। याद रखें कि प्रत्येक अनुक्रमणिका को डिस्क पर स्थान, स्मृति पर स्थान की आवश्यकता होती है, और तालिका के विरुद्ध सभी लेखन को भी प्रत्येक अनुक्रमणिका को स्पर्श करना चाहिए (फ़िल्टर किए गए अनुक्रमणिका एक तरफ)।
सारांश
मैं कई अन्य उदाहरणों के साथ आ सकता हूं जो दिखाते हैं कि जब एक गैर-संकुल उपयोगी हो सकता है और रखरखाव की लागत के लायक हो सकता है, तब भी जब क्लस्टर्ड इंडेक्स के प्रमुख कॉलम को डुप्लिकेट किया जाता है। गैर-संकुल अनुक्रमणिका को एक ही कुंजी कॉलम के साथ बनाया जा सकता है, लेकिन एक अलग कुंजी क्रम में, या वैकल्पिक प्रस्तुति आदेश का बेहतर समर्थन करने के लिए कॉलम पर अलग-अलग एएससी/डीईएससी के साथ बनाया जा सकता है। आपके पास गैर-संकुल अनुक्रमणिका भी हो सकती है जो फ़िल्टर के उपयोग के माध्यम से पंक्तियों का केवल एक छोटा सा उपसमूह ले जाती है। अंत में, यदि आप अपने सबसे सामान्य प्रश्नों को स्किनियर, गैर-क्लस्टर इंडेक्स के साथ संतुष्ट कर सकते हैं, तो यह मेमोरी खपत के लिए भी बेहतर है।
लेकिन वास्तव में, इस श्रृंखला का मेरा बिंदु केवल एक प्रति-उदाहरण दिखाने के लिए है जो इस तरह के कंबल बयान देने की मूर्खता को दर्शाता है। मैं आपको पॉल व्हाइट के एक स्पष्टीकरण के साथ छोड़ दूँगा, जो एक DBA.SE उत्तर में बताता है कि ऐसा गैर-संकुल सूचकांक वास्तव में एक संकुल सूचकांक की तुलना में बहुत बेहतर प्रदर्शन क्यों कर सकता है। यह तब भी सच है जब दोनों किसी भी प्रकार की तलाश का उपयोग करते हैं:
- क्लस्टर इंडेक्स सीक और नॉन क्लस्टर्ड इंडेक्स सीक के बीच अंतर