[ भाग 1 | भाग 2 | भाग 3 | भाग 4 ]
MERGE स्टेटमेंट (एसक्यूएल सर्वर 2008 में पेश किया गया) हमें INSERT . का मिश्रण करने की अनुमति देता है , UPDATE , और DELETE एकल कथन का उपयोग करके संचालन। MERGE . के लिए हैलोवीन सुरक्षा मुद्दे ज्यादातर व्यक्तिगत संचालन की आवश्यकताओं का एक संयोजन है, लेकिन कुछ महत्वपूर्ण अंतर और कुछ दिलचस्प अनुकूलन हैं जो केवल MERGE पर लागू होते हैं ।
MERGE के साथ हैलोवीन समस्या से बचना
हम भाग दो से डेमो और स्टेजिंग उदाहरण को फिर से देखकर शुरू करते हैं:
टेबल डीबीओ बनाएं। डेमो (कुछकी पूर्णांक शून्य नहीं है, सीमित पीके_डेमो प्राथमिक कुंजी (कुछकी)); टेबल डीबीओ बनाएं। स्टेजिंग (कुछकी पूर्णांक न्यूल नहीं); INSERT dbo.Staging (SomeKey)VALUES (1234), (1234); dbo.Staging (SomeKey) पर गैर-संकुल अनुक्रमणिका बनाएं; INSERT dbo.DemoSELECT s.someKeyFROM dbo. वहाँ के रूप में मंचन जहाँ मौजूद नहीं है (dbo से 1 चुनें। d जहाँ d.someKey =s.SomeKey);
जैसा कि आपको याद होगा, इस उदाहरण का उपयोग यह दिखाने के लिए किया गया था कि एक INSERT हैलोवीन सुरक्षा की आवश्यकता होती है जब सम्मिलित लक्ष्य तालिका को SELECT . में भी संदर्भित किया जाता है क्वेरी का हिस्सा (EXISTS इस मामले में खंड)। INSERT . के लिए सही व्यवहार उपरोक्त कथन दोनों . को जोड़ने का प्रयास करने के लिए है 1234 मान, और परिणामस्वरूप PRIMARY KEY . के साथ विफल होने के लिए उल्लंघन। चरण पृथक्करण के बिना, INSERT गलत तरीके से एक मान जोड़ देगा, बिना किसी त्रुटि के पूरा किया जा रहा है।
INSERT निष्पादन योजना
ऊपर दिए गए कोड में एक अंतर है जो भाग दो में उपयोग किया गया है; स्टेजिंग टेबल पर एक गैर-संकुल सूचकांक जोड़ा गया है। INSERT निष्पादन योजना अभी भी हालांकि हैलोवीन सुरक्षा की आवश्यकता है:
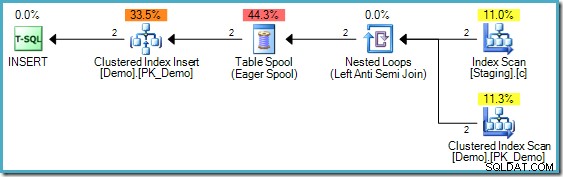
MERGE निष्पादन योजना
अब MERGE . का उपयोग करके व्यक्त किए गए समान तार्किक सम्मिलन का प्रयास करें वाक्य रचना:
MERGE dbo.Demo as dUSING dbo.Staging as s ON s.SomeKey =d.someKeyWHen T match the TARGET तब INSERT (SomeKey) VALUES (s.SomeKey);
यदि आप सिंटैक्स से परिचित नहीं हैं, तो स्टेजिंग और डेमो टेबल में समकी वैल्यू पर पंक्तियों की तुलना करने का तर्क है, और यदि लक्ष्य (डेमो) तालिका में कोई मिलान पंक्ति नहीं मिलती है, तो हम एक नई पंक्ति डालते हैं। यह बिल्कुल पिछले INSERT...WHERE NOT EXISTS . के समान ही है कोड, बिल्कुल। हालांकि निष्पादन योजना काफी अलग है:
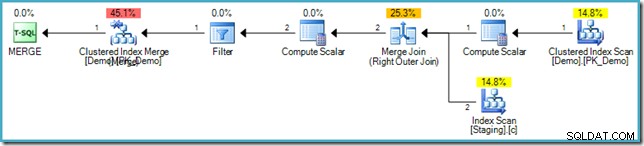
इस योजना में उत्सुक टेबल स्पूल की कमी पर ध्यान दें। इसके बावजूद, क्वेरी अभी भी सही त्रुटि संदेश उत्पन्न करती है। ऐसा लगता है कि SQL सर्वर ने MERGE को निष्पादित करने का एक तरीका ढूंढ लिया है SQL मानक द्वारा आवश्यक तार्किक चरण पृथक्करण का सम्मान करते हुए पुनरावृत्त रूप से योजना बनाएं।
छेद भरने का अनुकूलन
सही परिस्थितियों में, SQL सर्वर अनुकूलक यह पहचान सकता है कि MERGE कथन छेद भरना है , जो यह कहने का एक और तरीका है कि कथन केवल उन पंक्तियों को जोड़ता है जहां लक्ष्य तालिका की कुंजी में मौजूदा अंतर है।
इस अनुकूलन को लागू करने के लिए, WHEN NOT MATCHED BY TARGET में उपयोग किए गए मान खंड बिल्कुल होना चाहिए ON से मिलान करें USING . का भाग खंड। साथ ही, लक्ष्य तालिका में एक अद्वितीय कुंजी होनी चाहिए (PRIMARY KEY द्वारा संतुष्ट एक आवश्यकता वर्तमान मामले में)। जहां ये आवश्यकताएं पूरी होती हैं, वहां MERGE कथन को हैलोवीन समस्या से सुरक्षा की आवश्यकता नहीं है।
बेशक, MERGE कथन तार्किक रूप से है कम या ज्यादा नहीं छेद भरना मूल INSERT...WHERE NOT EXISTS . की तुलना में वाक्य - विन्यास। अंतर यह है कि ऑप्टिमाइज़र का MERGE . को लागू करने पर पूरा नियंत्रण होता है स्टेटमेंट, जबकि INSERT सिंटैक्स को क्वेरी के व्यापक शब्दार्थ के बारे में तर्क करने की आवश्यकता होगी। मानव आसानी से देख सकता है कि INSERT छेद भरने वाला भी है, लेकिन अनुकूलक चीजों के बारे में उसी तरह नहीं सोचता जैसा हम सोचते हैं।
सटीक मिलान . को स्पष्ट करने के लिए आवश्यकता का मैंने उल्लेख किया है, निम्नलिखित क्वेरी सिंटैक्स पर विचार करें, जो नहीं करता है छेद भरने के अनुकूलन से लाभ। परिणाम एक उत्सुक टेबल स्पूल द्वारा प्रदान किया गया पूर्ण हैलोवीन संरक्षण है:
MERGE dbo.Demo as dUSING dbo.Staging as s ON s.SomeKey =d.someKeyWHen D Matched तब INSERT (SomeKey) VALUES (s.SomeKey * 1);

केवल अंतर यह है कि VALUES . में एक से गुणा किया जाता है क्लॉज - कुछ ऐसा जो क्वेरी के तर्क को नहीं बदलता है, लेकिन जो होल-फिलिंग ऑप्टिमाइज़ेशन को लागू होने से रोकने के लिए पर्याप्त है।
नेस्टेड लूप्स के साथ छेद भरना
पिछले उदाहरण में, ऑप्टिमाइज़र ने मर्ज जॉइन का उपयोग करके तालिकाओं में शामिल होना चुना। होल-फिलिंग ऑप्टिमाइज़ेशन को भी लागू किया जा सकता है जहाँ एक नेस्टेड लूप्स जॉइन चुना जाता है, लेकिन इसके लिए सोर्स टेबल पर एक अतिरिक्त विशिष्टता की गारंटी की आवश्यकता होती है, और एक इंडेक्स जॉइन के अंदरूनी हिस्से की तलाश करता है। इसे क्रिया में देखने के लिए, हम मौजूदा स्टेजिंग डेटा को हटा सकते हैं, गैर-संकुल सूचकांक में विशिष्टता जोड़ सकते हैं, और MERGE आज़मा सकते हैं। फिर से:
-- मौजूदा डुप्लिकेट पंक्तियों को हटा दें TRUNCATE TABLE dbo.Staging; - अनुक्रमणिका को अद्वितीय में परिवर्तित करेंअद्वितीय गैर-अनुक्रमित अनुक्रमणिका बनाएं c ON dbo.Staging (SomeKey)साथ (DROP_EXISTING =ON); - नमूना डेटा INSERT dbo.Staging (SomeKey) VALUES (1234), (5678); -- होल-फिलिंग मर्ज MERGE dbo.Demo as dUSING dbo.Staging as s ON s.SomeKey =d.SomeKeyWHen MATCHED N INSERT (SomeKey) VALUES (s.SomeKey);
परिणामी निष्पादन योजना फिर से हैलोवीन प्रोटेक्शन से बचने के लिए होल-फिलिंग ऑप्टिमाइज़ेशन का उपयोग करती है, एक नेस्टेड लूप जॉइन का उपयोग करके और लक्ष्य तालिका में एक आंतरिक पक्ष की तलाश करती है:
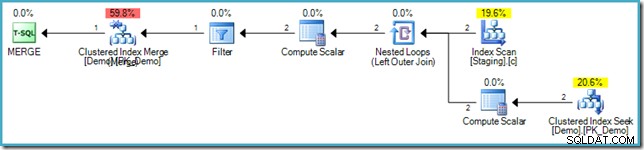
अनावश्यक इंडेक्स ट्रैवर्सल से बचना
जहां होल-फिलिंग ऑप्टिमाइज़ेशन लागू होता है, इंजन एक और ऑप्टिमाइज़ेशन भी लागू कर सकता है। पढ़ने . के दौरान यह इंडेक्स की मौजूदा स्थिति को याद रख सकता है लक्ष्य तालिका (एक समय में एक पंक्ति को संसाधित करना, याद रखें) और सम्मिलित स्थान खोजने के लिए बी-पेड़ की तलाश करने के बजाय, सम्मिलित करते समय उस जानकारी का पुन:उपयोग करें। तर्क यह है कि वर्तमान पढ़ने की स्थिति उसी पृष्ठ पर होने की संभावना है जहां नई पंक्ति डाली जानी चाहिए। यह जाँचना कि पंक्ति वास्तव में इस पृष्ठ से संबंधित है, बहुत तेज़ है, क्योंकि इसमें वर्तमान में संग्रहीत केवल निम्नतम और उच्चतम कुंजियों की जाँच करना शामिल है।
ईगर टेबल स्पूल को खत्म करने और प्रति पंक्ति एक इंडेक्स नेविगेशन को सहेजने का संयोजन ओएलटीपी वर्कलोड में एक महत्वपूर्ण लाभ प्रदान कर सकता है, बशर्ते निष्पादन योजना कैश से पुनर्प्राप्त की गई हो। MERGE . के लिए संकलन लागत कथन INSERT . के बजाय उच्चतर हैं , UPDATE और DELETE , इसलिए पुन:उपयोग की योजना बनाना एक महत्वपूर्ण विचार है। यह सुनिश्चित करना भी सहायक होता है कि पृष्ठ विभाजन से बचने के लिए पृष्ठों में नई पंक्तियों को समायोजित करने के लिए पर्याप्त खाली स्थान है। यह आम तौर पर सामान्य सूचकांक रखरखाव और एक उपयुक्त FILLFACTOR . के असाइनमेंट के माध्यम से प्राप्त किया जाता है ।
मैं OLTP वर्कलोड का उल्लेख करता हूं, जिसमें आमतौर पर बड़ी संख्या में अपेक्षाकृत छोटे परिवर्तन होते हैं, क्योंकि MERGE अनुकूलन एक अच्छा विकल्प नहीं हो सकता है जहां बड़ी संख्या में पंक्तियों को प्रति कथन संसाधित किया जाता है। अन्य अनुकूलन जैसे न्यूनतम लॉग किए गए INSERTs वर्तमान में होल-फिलिंग के साथ नहीं जोड़ा जा सकता है। हमेशा की तरह, अपेक्षित लाभों की प्राप्ति सुनिश्चित करने के लिए प्रदर्शन विशेषताओं को बेंचमार्क किया जाना चाहिए।
MERGE . के लिए होल-फिलिंग ऑप्टिमाइज़ेशन इंसर्ट को अपडेट के साथ जोड़ा जा सकता है और अतिरिक्त MERGE . का उपयोग करके हटाया जा सकता है खंड; हैलोवीन समस्या के लिए प्रत्येक डेटा-परिवर्तन ऑपरेशन का अलग से मूल्यांकन किया जाता है।
शामिल होने से बचना
अंतिम अनुकूलन जिसे हम देखेंगे, उसे लागू किया जा सकता है जहां MERGE स्टेटमेंट में अपडेट और डिलीट ऑपरेशंस के साथ-साथ एक होल-फिलिंग इंसर्ट होता है, और टारगेट टेबल में एक यूनिक क्लस्टर इंडेक्स होता है। निम्न उदाहरण एक सामान्य MERGE दिखाता है पैटर्न जहां बेजोड़ पंक्तियां डाली जाती हैं, और एक अतिरिक्त शर्त के आधार पर मिलान पंक्तियों को अद्यतन या हटा दिया जाता है:
टेबल # टी बनाएं (कॉल 1 पूर्णांक शून्य नहीं है, कॉल 2 पूर्णांक शून्य नहीं है, सीमित पीके_टी प्राथमिक कुंजी (कॉल 1)); तालिका #S बनाएं (col1 पूर्णांक शून्य नहीं है, col2 पूर्णांक शून्य नहीं है, सीमित PK_S प्राथमिक कुंजी (col1)); INSERT #T (col1, col2) VALUES (1, 50), (3, 90); INSERT #S (col1, col2) VALUES (1, 40), (2, 80), (3, 90);
MERGE सभी आवश्यक परिवर्तन करने के लिए आवश्यक विवरण उल्लेखनीय रूप से कॉम्पैक्ट है:
t.col1 =s.col1 पर #S को t.col1 =s.col1 के रूप में मर्ज करें जब मिलान न हो तो मान डालें (s.col1, s.col2) मिलान होने पर और t.col2 - s.col2 =0 तब हटाएं जब मिलान हो जाए अद्यतन सेट t.col2 -=s.col2;
निष्पादन योजना काफी आश्चर्यजनक है:

कोई हैलोवीन सुरक्षा नहीं, स्रोत और लक्ष्य तालिकाओं के बीच कोई जुड़ाव नहीं है, और ऐसा अक्सर नहीं होता है कि आप एक क्लस्टर इंडेक्स इंसर्ट ऑपरेटर के बाद एक क्लस्टर इंडेक्स मर्ज को उसी तालिका में देखेंगे। यह उच्च योजना पुन:उपयोग और उपयुक्त अनुक्रमण के साथ OLTP कार्यभार पर लक्षित एक और अनुकूलन है।
विचार स्रोत तालिका से एक पंक्ति को पढ़ना है और तुरंत इसे लक्ष्य में सम्मिलित करने का प्रयास करना है। यदि एक प्रमुख उल्लंघन का परिणाम होता है, तो त्रुटि को दबा दिया जाता है, सम्मिलित करें ऑपरेटर इसे मिली परस्पर विरोधी पंक्ति को आउटपुट करता है, और उस पंक्ति को सामान्य रूप से मर्ज प्लान ऑपरेटर का उपयोग करके अपडेट या डिलीट ऑपरेशन के लिए संसाधित किया जाता है।
यदि मूल सम्मिलन सफल होता है (बिना कुंजी उल्लंघन के) स्रोत से अगली पंक्ति के साथ प्रसंस्करण जारी रहता है (मर्ज ऑपरेटर केवल अद्यतनों को संसाधित करता है और हटा देता है)। यह अनुकूलन मुख्य रूप से MERGE . को लाभ पहुंचाता है वे प्रश्न जहां अधिकांश स्रोत पंक्तियों का परिणाम सम्मिलित होता है। फिर, अलग-अलग कथनों के उपयोग की तुलना में प्रदर्शन बेहतर है, यह सुनिश्चित करने के लिए सावधानीपूर्वक बेंचमार्किंग की आवश्यकता है।
सारांश
MERGE कथन कई अद्वितीय अनुकूलन अवसर प्रदान करता है। सही परिस्थितियों में, यह समतुल्य INSERT की तुलना में स्पष्ट हेलोवीन सुरक्षा जोड़ने की आवश्यकता से बच सकता है ऑपरेशन, या शायद INSERT . का संयोजन भी , UPDATE , और DELETE बयान। अतिरिक्त MERGE -विशिष्ट अनुकूलन इंडेक्स बी-ट्री ट्रैवर्सल से बच सकते हैं जो आमतौर पर एक नई पंक्ति के लिए सम्मिलित स्थिति का पता लगाने के लिए आवश्यक होता है, और स्रोत और लक्ष्य तालिका को पूरी तरह से जोड़ने की आवश्यकता से भी बच सकता है।
इस श्रृंखला के अंतिम भाग में, हम देखेंगे कि क्वेरी अनुकूलक किस प्रकार हैलोवीन सुरक्षा की आवश्यकता के बारे में कारण बताता है, और कुछ और तरकीबों की पहचान करेगा जो डेटा को बदलने वाली निष्पादन योजनाओं में ईगर टेबल स्पूल को जोड़ने की आवश्यकता से बचने के लिए नियोजित कर सकती हैं।
[ भाग 1 | भाग 2 | भाग 3 | भाग 4 ]