आजकल, आपके द्वारा उपयोग की जा रही किसी भी डेटाबेस तकनीक के लिए प्रतिकृति एक उच्च उपलब्धता और दोष सहिष्णु वातावरण में दी गई है। यह एक ऐसा विषय है जिसे हमने बार-बार देखा है, लेकिन यह कभी पुराना नहीं होता।
यदि आप TimescaleDB का उपयोग कर रहे हैं, तो सबसे सामान्य प्रकार की प्रतिकृति स्ट्रीमिंग प्रतिकृति है, लेकिन यह कैसे काम करती है?
इस ब्लॉग में, हम प्रतिकृति से संबंधित कुछ अवधारणाओं की समीक्षा करने जा रहे हैं और हम TimescaleDB के लिए स्ट्रीमिंग प्रतिकृति पर ध्यान केंद्रित करेंगे, जो अंतर्निहित PostgreSQL इंजन से विरासत में मिली एक कार्यक्षमता है। फिर, हम देखेंगे कि कैसे ClusterControl इसे कॉन्फ़िगर करने में हमारी मदद कर सकता है।
इसलिए, स्ट्रीमिंग प्रतिकृति वाल रिकॉर्ड को शिपिंग करने और उन्हें स्टैंडबाय सर्वर पर लागू करने पर आधारित है। तो, पहले देखते हैं कि वाल क्या है।
वाल
राइट अहेड लॉग (WAL) डेटा अखंडता सुनिश्चित करने के लिए एक मानक तरीका है, यह डिफ़ॉल्ट रूप से स्वचालित रूप से सक्षम होता है।
WALs TimescaleDB में REDO लॉग हैं। लेकिन, REDO लॉग क्या हैं?
REDO लॉग में डेटाबेस में किए गए सभी परिवर्तन होते हैं और इनका उपयोग प्रतिकृति, पुनर्प्राप्ति, ऑनलाइन बैकअप और पॉइंट इन टाइम रिकवरी (PITR) द्वारा किया जाता है। कोई भी परिवर्तन जो डेटा पृष्ठों पर लागू नहीं किया गया है, उन्हें REDO लॉग से फिर से किया जा सकता है।
WAL का उपयोग करने से डिस्क लिखने की संख्या काफी कम हो जाती है, क्योंकि लेन-देन द्वारा बदली गई प्रत्येक डेटा फ़ाइल के बजाय केवल लॉग फ़ाइल को डिस्क पर फ़्लश करने की आवश्यकता होती है ताकि यह सुनिश्चित हो सके कि लेन-देन प्रतिबद्ध है।
WAL रिकॉर्ड डेटा में किए गए परिवर्तनों को थोड़ा-थोड़ा करके निर्दिष्ट करेगा। प्रत्येक WAL रिकॉर्ड को WAL फ़ाइल में जोड़ा जाएगा। सम्मिलित स्थिति एक लॉग अनुक्रम संख्या (LSN) है जो लॉग में एक बाइट ऑफ़सेट है, प्रत्येक नए रिकॉर्ड के साथ बढ़ती जा रही है।
WALs को डेटा निर्देशिका के अंतर्गत pg_wal निर्देशिका में संग्रहीत किया जाता है। इन फ़ाइलों का डिफ़ॉल्ट आकार 16MB है (सर्वर बनाते समय --with-wal-segsize कॉन्फ़िगर विकल्प को बदलकर आकार बदला जा सकता है)। उनका एक अद्वितीय वृद्धिशील नाम है, जो निम्न प्रारूप में है:"00000001 00000000 00000000"।
pg_wal में निहित WAL फ़ाइलों की संख्या, postgresql.conf कॉन्फ़िगरेशन फ़ाइल में min_wal_size और max_wal_size पैरामीटर को निर्दिष्ट मान पर निर्भर करेगी।
एक पैरामीटर जिसे हमें अपने सभी TimescaleDB इंस्टॉलेशन को कॉन्फ़िगर करते समय सेटअप करने की आवश्यकता होती है, वह है wal_level. यह निर्धारित करता है कि वाल को कितनी जानकारी लिखी गई है। डिफ़ॉल्ट मान न्यूनतम है, जो केवल क्रैश या तत्काल शटडाउन से पुनर्प्राप्त करने के लिए आवश्यक जानकारी लिखता है। आर्काइव वाल संग्रह के लिए आवश्यक लॉगिंग जोड़ता है; hot_standby आगे एक स्टैंडबाय सर्वर पर केवल-पढ़ने के लिए क्वेरी चलाने के लिए आवश्यक जानकारी जोड़ता है; और, अंत में तार्किक तार्किक डिकोडिंग का समर्थन करने के लिए आवश्यक जानकारी जोड़ता है। इस पैरामीटर को पुनरारंभ करने की आवश्यकता है, इसलिए, यदि हम इसे भूल गए हैं तो चल रहे उत्पादन डेटाबेस को बदलना मुश्किल हो सकता है।
स्ट्रीमिंग प्रतिकृति
स्ट्रीमिंग प्रतिकृति लॉग शिपिंग विधि पर आधारित है। WAL रिकॉर्ड्स को लागू करने के लिए सीधे एक डेटाबेस सर्वर से दूसरे में ले जाया जाता है। हम कह सकते हैं कि यह एक सतत PITR है।
यह स्थानांतरण दो अलग-अलग तरीकों से किया जाता है, WAL रिकॉर्ड एक समय में एक फ़ाइल (WAL सेगमेंट) को स्थानांतरित करके (फ़ाइल-आधारित लॉग शिपिंग) और WAL रिकॉर्ड्स (एक WAL फ़ाइल WAL रिकॉर्ड से बनी होती है) को फ़्लाई पर स्थानांतरित करके (रिकॉर्ड आधारित) लॉग शिपिंग), एक मास्टर सर्वर और एक या कई स्लेव सर्वरों के बीच, WAL फ़ाइल के भरने की प्रतीक्षा किए बिना।
व्यवहार में, दास सर्वर पर चलने वाली वाल रिसीवर नामक एक प्रक्रिया, टीसीपी/आईपी कनेक्शन का उपयोग कर मास्टर सर्वर से कनेक्ट होगी। मास्टर सर्वर में, एक अन्य प्रक्रिया मौजूद है, जिसका नाम WAL प्रेषक है, और यह WAL रजिस्ट्रियों को स्लेव सर्वर पर भेजने का प्रभारी है जैसा कि वे होते हैं।
स्ट्रीमिंग प्रतिकृति को निम्न के रूप में दर्शाया जा सकता है:
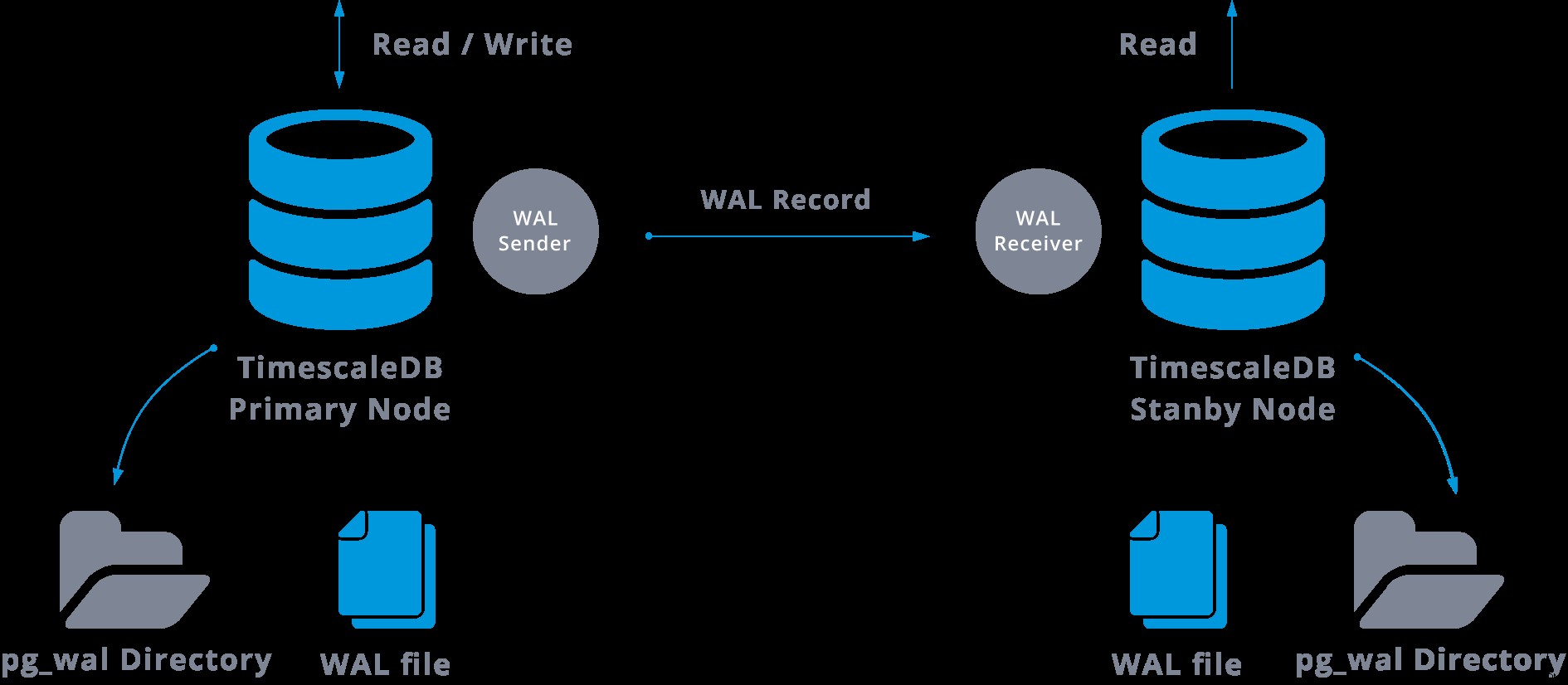
ऊपर दिए गए आरेख को देखकर हम सोच सकते हैं कि क्या होता है जब WAL प्रेषक और WAL रिसीवर के बीच संचार विफल हो जाता है?
स्ट्रीमिंग प्रतिकृति को कॉन्फ़िगर करते समय, हमारे पास WAL संग्रह को सक्षम करने का विकल्प होता है।
यह कदम वास्तव में अनिवार्य नहीं है, लेकिन मजबूत प्रतिकृति सेटअप के लिए अत्यंत महत्वपूर्ण है, क्योंकि पुरानी WAL फ़ाइलों को रीसायकल करने के लिए मुख्य सर्वर से बचना आवश्यक है जो अभी तक दास पर लागू नहीं हुई हैं। अगर ऐसा होता है तो हमें शुरुआत से ही प्रतिकृति को फिर से बनाना होगा।
निरंतर संग्रह के साथ प्रतिकृति को कॉन्फ़िगर करते समय, हम बैकअप से शुरू कर रहे हैं और, मास्टर के साथ सिंक स्थिति पर पहुंचने के लिए, हमें बैकअप के बाद हुए वाल में होस्ट किए गए सभी परिवर्तनों को लागू करने की आवश्यकता है। इस प्रक्रिया के दौरान, स्टैंडबाय पहले संग्रह स्थान में उपलब्ध सभी WAL को पुनर्स्थापित करेगा (Restore_command को कॉल करके किया गया)। जब हम अंतिम संग्रहीत WAL रिकॉर्ड तक पहुँचते हैं तो पुनर्स्थापना_कमांड विफल हो जाएगा, इसलिए उसके बाद, स्टैंडबाय pg_wal निर्देशिका को देखने के लिए जा रहा है यह देखने के लिए कि क्या परिवर्तन मौजूद है (यह वास्तव में डेटा हानि से बचने के लिए बनाया गया है जब मास्टर सर्वर क्रैश हो जाता है और कुछ परिवर्तन जो पहले से ही प्रतिकृति में ले जाया जा चुका है और वहां लागू किया गया है, अभी तक संग्रहीत नहीं किया गया है)।
यदि वह विफल हो जाता है, और अनुरोधित रिकॉर्ड वहां मौजूद नहीं है, तो यह स्ट्रीमिंग प्रतिकृति के माध्यम से मास्टर के साथ संचार करना शुरू कर देगा।
जब भी स्ट्रीमिंग प्रतिकृति विफल हो जाती है, तो यह चरण 1 पर वापस चली जाएगी और अभिलेखों को फिर से संग्रह से पुनर्स्थापित करेगी। संग्रह, pg_wal, और स्ट्रीमिंग प्रतिकृति के माध्यम से पुनर्प्राप्त करने का यह चक्र तब तक चलता रहता है जब तक सर्वर बंद नहीं हो जाता या ट्रिगर फ़ाइल द्वारा विफलता ट्रिगर नहीं हो जाती।
यह इस तरह के कॉन्फ़िगरेशन का आरेख होगा:
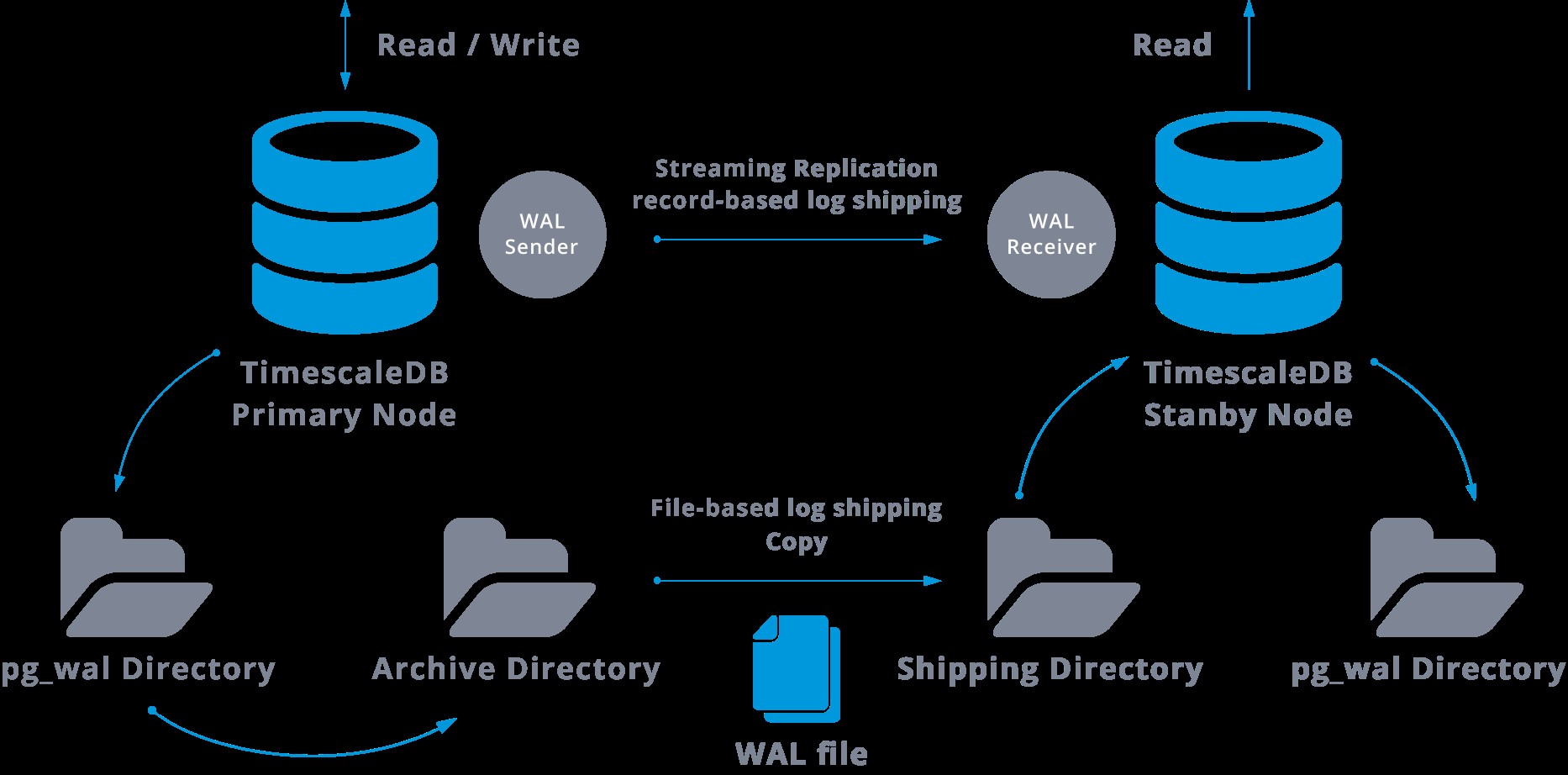
स्ट्रीमिंग प्रतिकृति डिफ़ॉल्ट रूप से अतुल्यकालिक है, इसलिए किसी समय हम कुछ लेन-देन कर सकते हैं जो मास्टर में किए जा सकते हैं और अभी तक स्टैंडबाय सर्वर में दोहराए नहीं गए हैं। इसका मतलब कुछ संभावित डेटा हानि है।
हालांकि, प्रतिकृति में परिवर्तनों की प्रतिबद्धता और प्रभाव के बीच यह विलंब वास्तव में छोटा (कुछ मिलीसेकंड) माना जाता है, यह मानते हुए कि प्रतिकृति सर्वर लोड को बनाए रखने के लिए पर्याप्त शक्तिशाली है।
ऐसे मामलों के लिए जब एक छोटे से डेटा हानि का जोखिम भी सहनीय नहीं है, हम सिंक्रोनस प्रतिकृति सुविधा का उपयोग कर सकते हैं।
सिंक्रोनस प्रतिकृति में, एक लिखित लेन-देन की प्रत्येक प्रतिबद्धता तब तक प्रतीक्षा करेगी जब तक यह पुष्टि न हो जाए कि प्रतिबद्धता प्राथमिक और स्टैंडबाय सर्वर दोनों की डिस्क पर राइट-फॉरवर्ड लॉग पर लिखी गई है।
यह विधि डेटा हानि की संभावना को कम करती है, क्योंकि ऐसा होने के लिए हमें एक ही समय में मास्टर और स्टैंडबाय दोनों के विफल होने की आवश्यकता होगी।
इस कॉन्फ़िगरेशन का स्पष्ट नकारात्मक पक्ष यह है कि प्रत्येक लेखन लेनदेन के लिए प्रतिक्रिया समय बढ़ जाता है, क्योंकि हमें तब तक प्रतीक्षा करने की आवश्यकता होती है जब तक कि सभी पक्षों ने प्रतिक्रिया नहीं दी। तो कमिट करने का समय, कम से कम, मास्टर और प्रतिकृति के बीच की राउंड ट्रिप है। रीड ओनली लेन-देन इससे प्रभावित नहीं होंगे।
तुल्यकालिक प्रतिकृति सेटअप करने के लिए हमें प्रत्येक स्टैंडबाय सर्वर के लिए पुनर्प्राप्ति.conf फ़ाइल के Primary_conninfo में एक application_name निर्दिष्ट करने की आवश्यकता है:Primary_conninfo ='...aplication_name=slaveX' ।
हमें उन स्टैंडबाय सर्वरों की सूची भी निर्दिष्ट करने की आवश्यकता है जो सिंक्रोनस प्रतिकृति में भाग लेने जा रहे हैं:तुल्यकालिक_स्टैंडबाय_नाम ='स्लेवएक्स, स्लेववाई'।
हम एक या कई सिंक्रोनस सर्वर सेट कर सकते हैं, और यह पैरामीटर यह भी निर्दिष्ट करता है कि कौन सी विधि (FIRST और कोई भी) सूचीबद्ध लोगों में से सिंक्रोनस स्टैंडबाय चुनने के लिए है।
स्ट्रीमिंग प्रतिकृति सेटअप (सिंक्रोनस या एसिंक्रोनस) के साथ TimescaleDB को परिनियोजित करने के लिए, हम ClusterControl का उपयोग कर सकते हैं, जैसा कि हम यहां देख सकते हैं।
जब हमने अपनी प्रतिकृति को कॉन्फ़िगर कर लिया है, और यह चालू है और चल रहा है, तो हमें निगरानी और बैकअप प्रबंधन के लिए कुछ अतिरिक्त सुविधाओं की आवश्यकता होगी। ClusterControl हमें बिना किसी बाहरी टूल के एक ही स्थान से हमारे TimescaleDB क्लस्टर के बैकअप/रिटेंशन की निगरानी और प्रबंधन करने की अनुमति देता है।
TimescaleDB पर स्ट्रीमिंग प्रतिकृति को कैसे कॉन्फ़िगर करें
स्ट्रीमिंग प्रतिकृति सेट करना एक ऐसा कार्य है जिसके लिए कुछ चरणों का पूरी तरह से पालन करने की आवश्यकता होती है। यदि आप इसे मैन्युअल रूप से कॉन्फ़िगर करना चाहते हैं, तो आप इस विषय के बारे में हमारे ब्लॉग का अनुसरण कर सकते हैं।
हालाँकि, आप अपने वर्तमान TimescaleDB को ClusterControl पर परिनियोजित या आयात कर सकते हैं, और फिर, आप कुछ क्लिक के साथ स्ट्रीमिंग प्रतिकृति को कॉन्फ़िगर कर सकते हैं। आइए देखें कि हम इसे कैसे कर सकते हैं।
इस कार्य के लिए, हम मान लेंगे कि आपका TimescaleDB क्लस्टर ClusterControl द्वारा प्रबंधित है। ClusterControl पर जाएँ -> क्लस्टर चुनें -> क्लस्टर क्रियाएँ -> प्रतिकृति स्लेव जोड़ें।
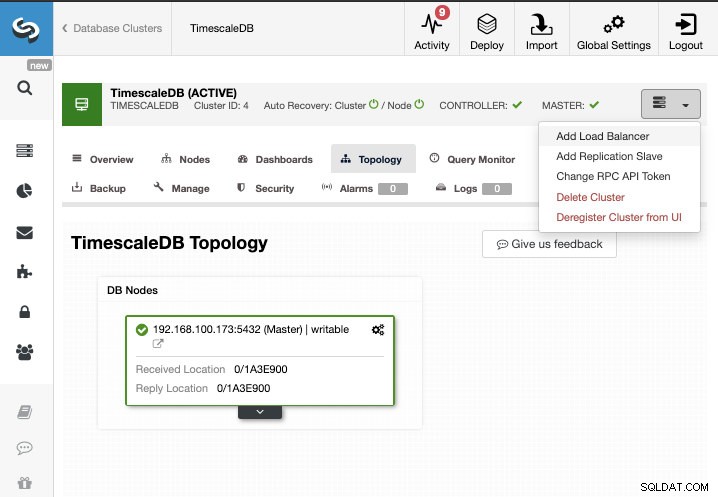
हम एक नया प्रतिकृति दास (स्टैंडबाय) बना सकते हैं या हम मौजूदा एक को आयात कर सकते हैं। इस मामले में, हम एक नया बनाएंगे।
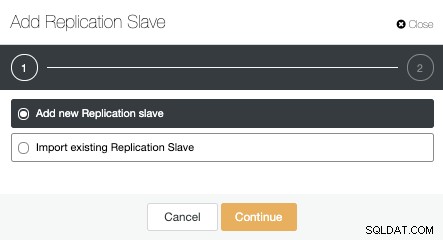
अब, हमें मास्टर नोड का चयन करना होगा, नए स्टैंडबाय सर्वर और डेटाबेस पोर्ट के लिए आईपी एड्रेस या होस्टनाम जोड़ना होगा। हम यह भी निर्दिष्ट कर सकते हैं कि क्या हम चाहते हैं कि क्लस्टरकंट्रोल सॉफ़्टवेयर स्थापित करे और यदि हम सिंक्रोनस या एसिंक्रोनस स्ट्रीमिंग प्रतिकृति को कॉन्फ़िगर करना चाहते हैं।
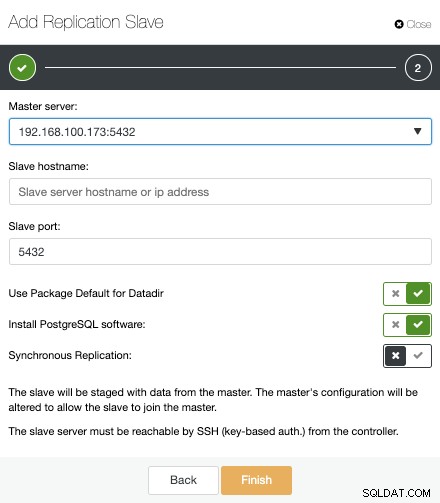
बस इतना ही। हमें केवल तब तक प्रतीक्षा करने की आवश्यकता है जब तक कि ClusterControl काम पूरा नहीं कर लेता। हम गतिविधि अनुभाग से स्थिति की निगरानी कर सकते हैं।
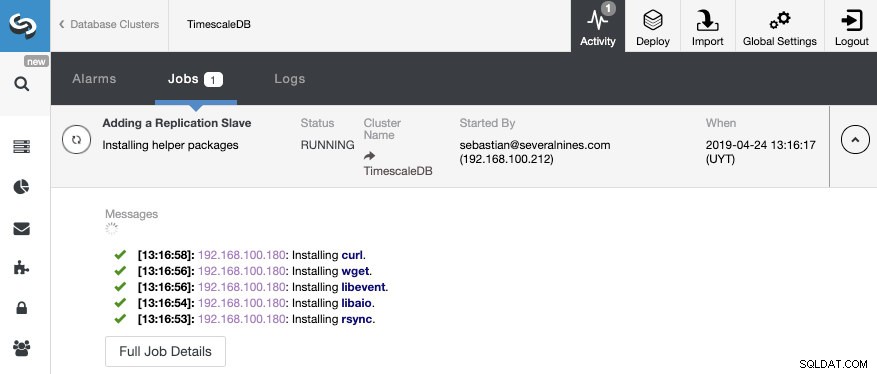
कार्य समाप्त होने के बाद, हमारे पास स्ट्रीमिंग प्रतिकृति कॉन्फ़िगर होनी चाहिए और हम ClusterControl टोपोलॉजी व्यू अनुभाग में नई टोपोलॉजी की जांच कर सकते हैं।
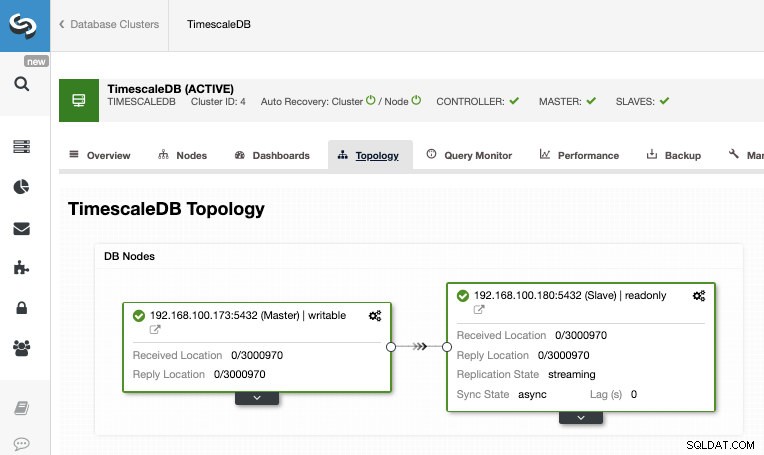
ClusterControl का उपयोग करके, आप अपने TimescaleDB पर कई प्रबंधन कार्य भी कर सकते हैं जैसे बैकअप, मॉनिटर और अलर्ट, स्वचालित विफलता, नोड्स जोड़ना, लोड बैलेंसर जोड़ना, और भी बहुत कुछ।
विफलता
जैसा कि हम देख सकते हैं, TimescaleDB स्टैंडबाय डेटाबेस को सिंक्रोनाइज़ करने के लिए राइट-फ़ॉरवर्ड लॉग (WAL) रिकॉर्ड की एक स्ट्रीम का उपयोग करता है। यदि मुख्य सर्वर विफल हो जाता है, तो स्टैंडबाय में मुख्य सर्वर का लगभग सभी डेटा होता है और इसे जल्दी से नया मास्टर डेटाबेस सर्वर बनाया जा सकता है। यह सिंक्रोनस या एसिंक्रोनस हो सकता है और केवल संपूर्ण डेटाबेस सर्वर के लिए किया जा सकता है।
उच्च उपलब्धता को प्रभावी ढंग से सुनिश्चित करने के लिए, मास्टर-स्टैंडबाय आर्किटेक्चर होना पर्याप्त नहीं है। हमें विफलता के कुछ स्वचालित रूप को भी सक्षम करने की आवश्यकता है, इसलिए यदि कुछ विफल हो जाता है तो हमें सामान्य कार्यक्षमता को फिर से शुरू करने में सबसे छोटा संभव विलंब हो सकता है।
TimescaleDB में मास्टर डेटाबेस पर विफलताओं की पहचान करने और दास को स्वामित्व लेने के लिए सूचित करने के लिए एक स्वचालित विफलता तंत्र शामिल नहीं है, जिससे DBA के पक्ष में थोड़ा सा काम करने की आवश्यकता होगी। आपके पास केवल एक सर्वर काम कर रहा होगा, इसलिए मास्टर-स्टैंडबाय आर्किटेक्चर का पुन:निर्माण करने की आवश्यकता है, इसलिए हम उसी सामान्य स्थिति में वापस आ जाते हैं जो हमारे पास समस्या से पहले थी।
ClusterControl में TimescaleDB के लिए आपके उच्च उपलब्धता वातावरण में मीन टाइम टू रिपेयर (MTTR) में सुधार करने के लिए एक स्वचालित विफलता सुविधा शामिल है। विफलता के मामले में, क्लस्टरकंट्रोल सबसे उन्नत दास को मास्टर करने के लिए बढ़ावा देगा, और यह शेष दास को नए मास्टर से कनेक्ट करने के लिए पुन:कॉन्फ़िगर करेगा। अनुप्रयोगों के लिए एकल डेटाबेस समापन बिंदु की पेशकश करने के लिए HAProxy को स्वचालित रूप से तैनात किया जा सकता है, इसलिए वे मास्टर सर्वर के परिवर्तन से प्रभावित नहीं होते हैं।
सीमाएं
TimescaleDB के लिए संबंधित संसाधन ClusterControl TimescaleDB को आसानी से कैसे परिनियोजित करें PostgreSQL स्ट्रीमिंग प्रतिकृति - एक गहरा गोतास्ट्रीमिंग प्रतिकृति का उपयोग करते समय हमारी कुछ प्रसिद्ध सीमाएं हैं:
- हम किसी भिन्न संस्करण या आर्किटेक्चर में प्रतिकृति नहीं बना सकते हैं
- हम स्टैंडबाय सर्वर पर कुछ भी नहीं बदल सकते हैं
- हम जो दोहरा सकते हैं उस पर हमारे पास बहुत अधिक विवरण नहीं है
इसलिए, इन सीमाओं को पार करने के लिए, हमारे पास तार्किक प्रतिकृति विशेषता है। इस प्रतिकृति प्रकार के बारे में अधिक जानने के लिए, आप निम्न ब्लॉग देख सकते हैं।
निष्कर्ष
एक मास्टर-स्टैंडबाय टोपोलॉजी में एनालिटिक्स, बैकअप, उच्च उपलब्धता, फेलओवर जैसे कई अलग-अलग उपयोग होते हैं। किसी भी मामले में, यह समझना आवश्यक है कि स्ट्रीमिंग प्रतिकृति TimescaleDB पर कैसे काम करती है। सभी क्लस्टर को प्रबंधित करने के लिए और आपको इस टोपोलॉजी को आसान तरीके से बनाने की संभावना देने के लिए एक सिस्टम होना भी उपयोगी है। इस ब्लॉग में, हमने देखा कि ClusterControl का उपयोग करके इसे कैसे प्राप्त किया जाए, और हमने स्ट्रीमिंग प्रतिकृति के बारे में कुछ बुनियादी अवधारणाओं की समीक्षा की।