समय-श्रृंखला डेटाबेस, जैसा कि नाम से पता चलता है, डेटा को संग्रहीत करने के लिए डिज़ाइन किया गया है जो समय के साथ बदलता है। यह किसी भी प्रकार का डेटा हो सकता है जो समय के साथ एकत्र किया गया था। यह कुछ प्रणालियों से एकत्रित मेट्रिक्स हो सकता है, और वास्तव में, सभी ट्रेंडिंग सिस्टम समय-श्रृंखला डेटा के उदाहरण हैं।
हमारे पास विभिन्न प्रकार के समय-श्रृंखला डेटाबेस हैं, हमें किसका उपयोग करना चाहिए?
इस ब्लॉग में, हम देखेंगे कि दो मुख्य विकल्पों, TimescaleDB और InfluxDB के बीच मुख्य अंतर क्या हैं।
InfluxDB
InfluxDB को InfluxData द्वारा बनाया गया है। यह गो में लिखा गया एक कस्टम, ओपन-सोर्स, नोएसक्यूएल टाइम-सीरीज़ डेटाबेस है। डेटास्टोर डेटा को क्वेरी करने के लिए SQL जैसी भाषा प्रदान करता है, जिसे InfluxQL कहा जाता है, जो डेवलपर्स के लिए अपने अनुप्रयोगों में एकीकृत करना आसान बनाता है। इसमें फ्लक्स नामक एक नई कस्टम क्वेरी भाषा भी है, यह भाषा कुछ कार्यों को आसान बना सकती है, लेकिन कस्टम क्वेरी भाषा को अपनाते समय हमेशा सीखने की अवस्था होती है।
यह एक Flux क्वेरी उदाहरण है:
from(db:"testing")
|> range(start:-1h)
|> filter(fn: (r) => r._measurement == "cpu")
|> exponentialMovingAverage()इस डेटाबेस में, प्रत्येक माप में एक टाइमस्टैम्प, और टैग का एक संबद्ध सेट और फ़ील्ड का सेट होता है। फ़ील्ड वास्तविक माप पढ़ने के मूल्यों का प्रतिनिधित्व करता है, जबकि टैग माप का वर्णन करने के लिए मेटाडेटा का प्रतिनिधित्व करता है। फ़ील्ड डेटा प्रकार फ़्लोट्स, इनट्स, स्ट्रिंग्स और बूलियन्स तक सीमित हैं, और डेटा को फिर से लिखे बिना बदला नहीं जा सकता है। टैग मान अनुक्रमित हैं। उन्हें स्ट्रिंग के रूप में दर्शाया जाता है, और उन्हें अपडेट नहीं किया जा सकता है।
InfluxDB शुरू करना काफी आसान है, क्योंकि आपको स्कीमा या इंडेक्स बनाने के बारे में चिंता करने की ज़रूरत नहीं है। हालांकि, यह काफी कठोर और सीमित है, अतिरिक्त इंडेक्स बनाने की कोई क्षमता नहीं है, निरंतर फ़ील्ड पर इंडेक्स, तथ्य के बाद मेटाडेटा अपडेट करें, डेटा सत्यापन लागू करें, आदि।
यह स्कीमालेस नहीं है। एक अंतर्निहित स्कीमा है जो इनपुट डेटा से स्वतः निर्मित होती है।
InfluxDB को गलती-सहनशीलता के लिए कई उपकरणों को खरोंच से लागू करना पड़ता है, जैसे प्रतिकृति, उच्च उपलब्धता और बैकअप/पुनर्स्थापना, और यह इसकी ऑन-डिस्क विश्वसनीयता के लिए जिम्मेदार है। हम इन उपकरणों का उपयोग करने तक सीमित हैं और इनमें से कई सुविधाएं, जैसे HA, केवल एंटरप्राइज़ संस्करण में उपलब्ध हैं।
InfluxDB बैकअप टूल पूर्ण या वृद्धिशील बैकअप कर सकता है, और इसका उपयोग पॉइंट-इन-टाइम-रिकवरी के लिए किया जा सकता है।
InfluxDB भी PostgreSQL और TimescaleDB की तुलना में डिस्क पर बेहतर संपीड़न प्रदान करता है।
टाइमस्केलडीबी
TimescaleDB एक खुला स्रोत समय-श्रृंखला डेटाबेस है जो पूर्ण SQL का समर्थन करने वाले तीव्र अंतर्ग्रहण और जटिल प्रश्नों के लिए अनुकूलित है। यह पोस्टग्रेएसक्यूएल पर आधारित है और यह टाइम-सीरीज़ डेटा के लिए सर्वश्रेष्ठ नोएसक्यूएल और रिलेशनल वर्ल्ड की पेशकश करता है।
यह TimescaleDB क्वेरी उदाहरण है:
SELECT time,
exponential_moving_average(value, 0.5) OVER (ORDER BY time)
FROM testing
WHERE measurement = cpu and time > now() - '1 hour';TimescaleDB, PostgreSQL एक्सटेंशन के रूप में, एक रिलेशनल डेटाबेस है। यह नए उपयोगकर्ताओं के लिए एक संक्षिप्त सीखने की अवस्था की अनुमति देता है, और बैक अप के लिए pg_dump या pg_backup जैसे टूल और उच्च उपलब्धता टूल को इनहेरिट करने की अनुमति देता है, जो अन्य समय-श्रृंखला डेटाबेस के सामने एक फायदा है। यह प्रतिकृति की प्राथमिक विधि के रूप में स्ट्रीमिंग प्रतिकृति का भी समर्थन करता है, जिसका उपयोग उच्च उपलब्धता सेटअप में किया जा सकता है। विफलता और बैकअप के संदर्भ में, आप ClusterControl जैसे बाहरी सिस्टम का उपयोग करके इस प्रक्रिया को स्वचालित कर सकते हैं।
TimescaleDB में, प्रत्येक समय-श्रृंखला माप को अपनी पंक्ति में दर्ज किया जाता है, एक समय क्षेत्र के साथ किसी भी अन्य फ़ील्ड के बाद, जो फ्लोट्स, इनट्स, स्ट्रिंग्स, बूलियन्स, एरेज़, जेएसओएन ब्लॉब्स, भू-स्थानिक आयाम, दिनांक/समय/ टाइमस्टैम्प, मुद्राएं, बाइनरी डेटा, और बहुत कुछ।
आप किसी भी फ़ील्ड (मानक अनुक्रमणिका) या एकाधिक फ़ील्ड (समग्र अनुक्रमणिका), या फ़ंक्शंस जैसे अभिव्यक्तियों पर अनुक्रमणिका बना सकते हैं, या किसी अनुक्रमणिका को पंक्तियों के सबसेट (आंशिक अनुक्रमणिका) तक सीमित भी कर सकते हैं। इनमें से किसी भी फ़ील्ड का उपयोग द्वितीयक तालिकाओं के लिए एक विदेशी कुंजी के रूप में किया जा सकता है, जो तब अतिरिक्त मेटाडेटा संग्रहीत कर सकता है।
इस तरह, आपको एक स्कीमा चुनना होगा, और यह तय करना होगा कि आपको अपने सिस्टम के लिए किन इंडेक्स की आवश्यकता होगी।
प्रदर्शन
अगर हम प्रदर्शन के बारे में बात करते हैं, तो हम महान TimescaleDB तुलना ब्लॉग की जांच कर सकते हैं। वहां आपके पास चार्ट और मेट्रिक्स के साथ दोनों डेटाबेस के बीच प्रदर्शन के लिए एक विस्तृत तुलना है। आइए देखें इस ब्लॉग की कुछ सबसे महत्वपूर्ण जानकारी।
सम्मिलित करें
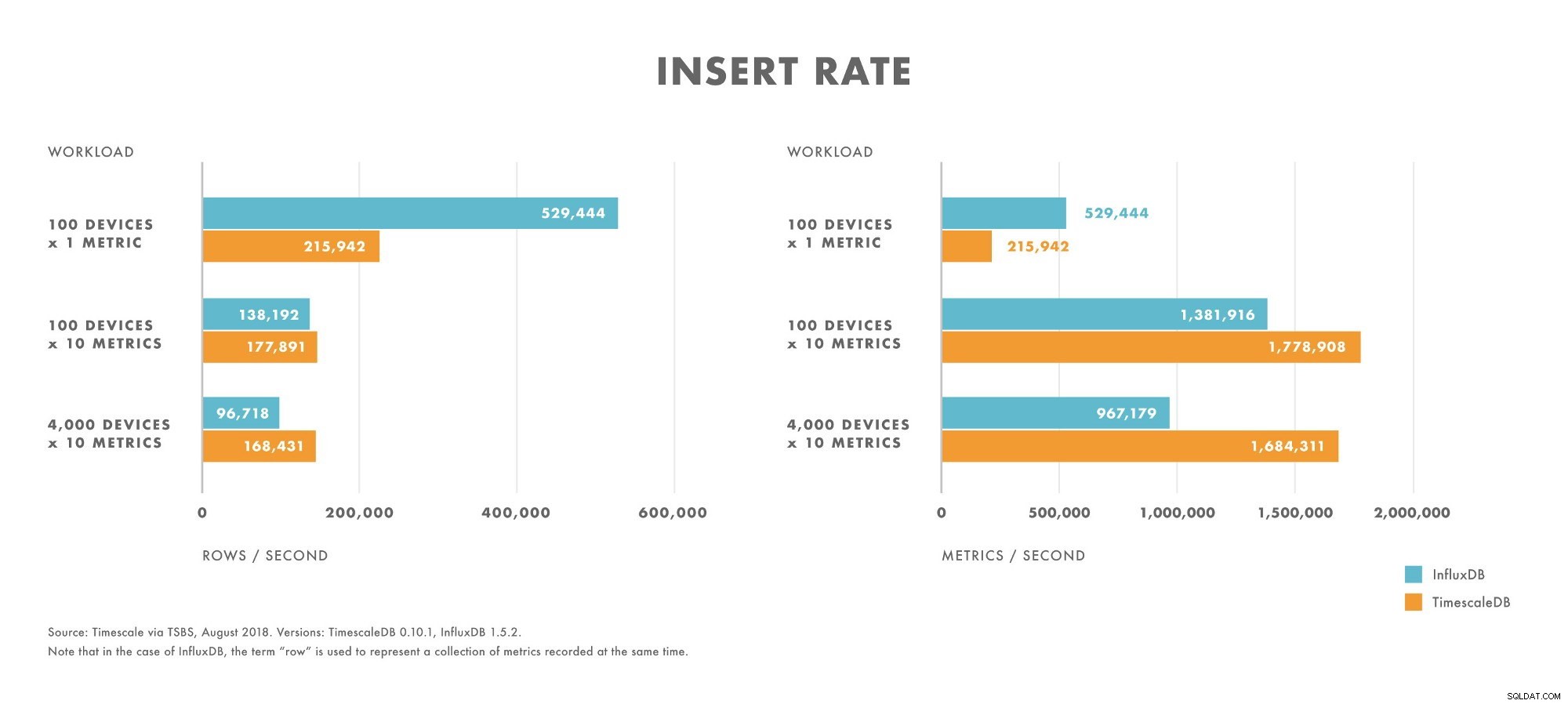
- बहुत कम कार्डिनैलिटी वाले वर्कलोड (जैसे, 100 डिवाइस) के लिए, InfluxDB TimescaleDB से बेहतर प्रदर्शन करता है।
- जैसे-जैसे कार्डिनैलिटी बढ़ती है, InfluxDB इंसर्ट का प्रदर्शन TimescaleDB की तुलना में तेज़ी से कम होता जाता है।
- मध्यम से उच्च कार्डिनैलिटी वाले कार्यभार के लिए (उदाहरण के लिए, 10 मीट्रिक भेजने वाले 100 उपकरण), TimescaleDB InfluxDB से बेहतर प्रदर्शन करता है।

विलंबता पढ़ें
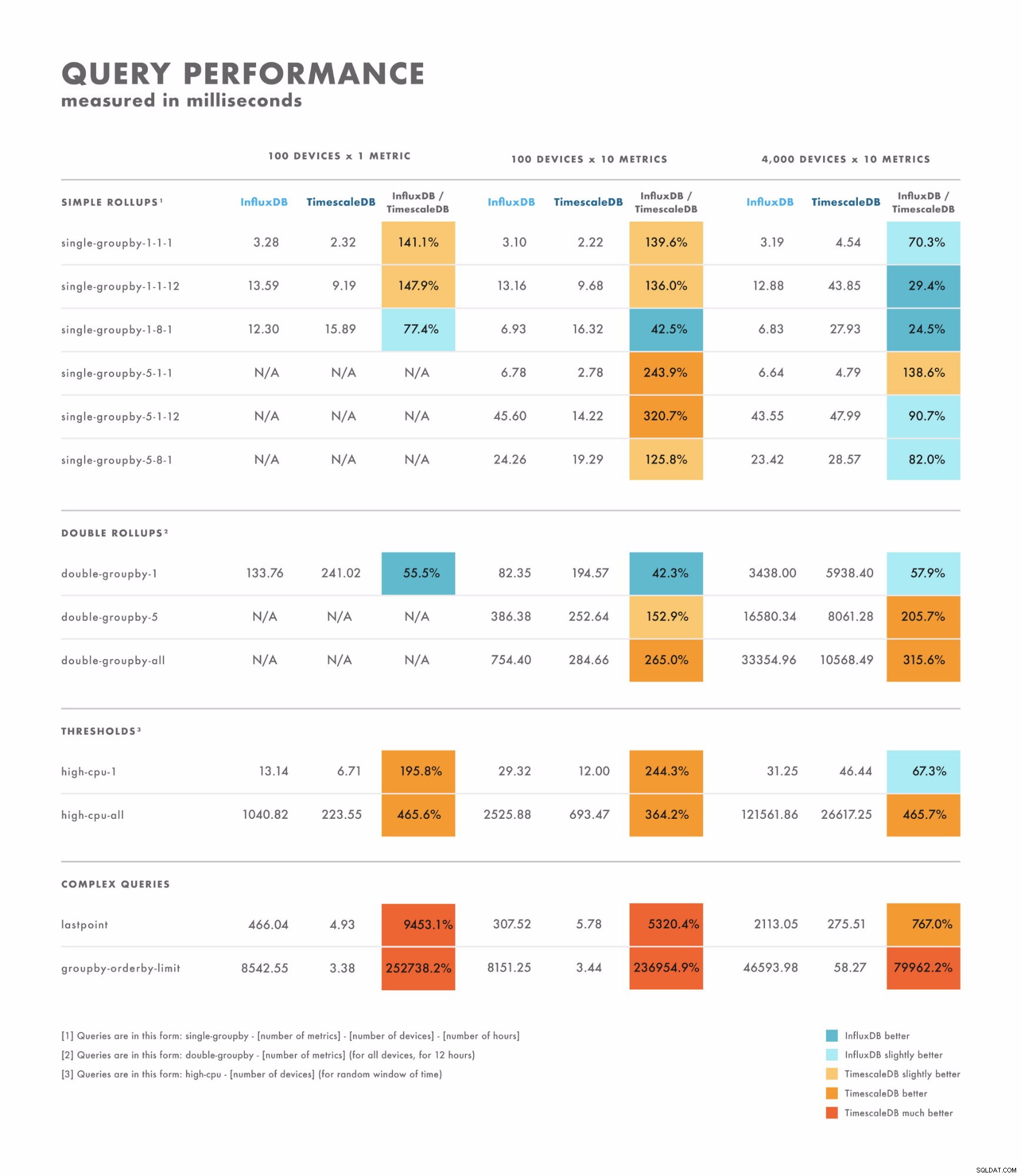
- साधारण प्रश्नों के लिए, परिणाम काफी भिन्न होते हैं:कुछ ऐसे होते हैं जहां एक डेटाबेस दूसरे की तुलना में स्पष्ट रूप से बेहतर होता है, जबकि अन्य आपके डेटासेट की कार्डिनैलिटी पर निर्भर करते हैं। यहां अंतर अक्सर सिंगल-डिजिट से डबल-डिजिट मिलीसेकंड की सीमा में होता है।
- जटिल प्रश्नों के लिए, TimescaleDB InfluxDB से काफी बेहतर प्रदर्शन करता है, और क्वेरी प्रकारों की एक विस्तृत श्रृंखला का समर्थन करता है। यहाँ अंतर अक्सर सेकंड से लेकर दसियों सेकंड तक होता है।
- इसे ध्यान में रखते हुए, ठीक से परीक्षण करने का सबसे अच्छा तरीका उन क्वेरी का उपयोग करके बेंचमार्क करना है जिन्हें आप निष्पादित करने की योजना बना रहे हैं।
स्थिरता संबंधी समस्याएं
- InfluxDB में उच्च (100K+) कार्डिनैलिटी पर स्थिरता और प्रदर्शन संबंधी समस्याएं हैं।
निष्कर्ष
यदि आपका डेटा InfluxDB डेटा मॉडल में फिट बैठता है, और आप भविष्य में बदलने की उम्मीद नहीं करते हैं, तो आपको InfluxDB का उपयोग करने पर विचार करना चाहिए क्योंकि यह मॉडल शुरू करना आसान है, और अधिकांश डेटाबेस की तरह जो कॉलम-ओरिएंटेड दृष्टिकोण का उपयोग करते हैं, PostgreSQL और TimescaleDB की तुलना में बेहतर ऑन-डिस्क संपीड़न प्रदान करता है।
हालाँकि, रिलेशनल मॉडल अधिक बहुमुखी है और अधिक कार्यक्षमता, लचीलापन और नियंत्रण प्रदान करता है जो कि InfluxDB मॉडल है। यह विशेष रूप से महत्वपूर्ण है क्योंकि आपका एप्लिकेशन विकसित होता है। और अपने सिस्टम की योजना बनाते समय आपको इसकी वर्तमान और भविष्य दोनों जरूरतों पर विचार करना चाहिए।
इस ब्लॉग में, हम TimescaleDB और InfluxDB के बीच एक छोटी तुलना देख सकते हैं, और हम TimescaleDB को PostgreSQL एक्सटेंशन के रूप में कह सकते हैं, यह काफी परिपक्व और सुविधा संपन्न दिखता है क्योंकि यह PostgreSQL से बहुत कुछ प्राप्त करता है। लेकिन आप इस ब्लॉग में पहले बताए गए पेशेवरों और विपक्षों के आधार पर अपना निर्णय ले सकते हैं, और सुनिश्चित करें कि आप अपने स्वयं के कार्यभार को बेंचमार्क करते हैं। इस नई समय-श्रृंखला डेटाबेस दुनिया में शुभकामनाएँ!