डैनियल कीज़ मोरन कहते हैं, "आपके पास जानकारी के बिना डेटा हो सकता है, लेकिन आपके पास डेटा के बिना जानकारी नहीं हो सकती"। डेटा हर संगठन में महत्वपूर्ण संपत्ति है, यदि आप डेटा खो देते हैं तो आप जानकारी खो देते हैं। यह बदले में, खराब व्यावसायिक निर्णयों या यहां तक कि व्यवसाय को संचालित करने में सक्षम नहीं होने का कारण बन सकता है। आपके डेटा के लिए डिजास्टर रिकवरी प्लान होना जरूरी है, और क्लाउड यहां विशेष रूप से सहायक हो सकता है। क्लाउड स्टोरेज का लाभ उठाकर, आपको अपने बैकअप डेटा को स्टोर करने के लिए स्टोरेज तैयार करने की जरूरत नहीं है, या महंगे स्टोरेज सिस्टम पर पैसे खर्च करने की जरूरत नहीं है। Amazon S3 और Google क्लाउड स्टोरेज बेहतरीन विकल्प हैं क्योंकि वे विश्वसनीय, सस्ते और टिकाऊ हैं।
हमने पहले आपके PostgreSQL बैकअप को AWS और GCP पर संग्रहीत करने के बारे में लिखा था। तो आइए अपने TimescaleDB डेटा के बैकअप को AWS S3 और क्लाउड स्टोरेज में संग्रहीत करने के लिए कुछ युक्तियों को देखें।
आपका AWS S3 बकेट तैयार करना
AWS S3 में डेटा के प्रबंधन के लिए AWS एक सरल वेब इंटरफ़ेस प्रदान करता है। बकेट शब्द फाइल सिस्टम भंडारण के पारंपरिक शब्दों में "निर्देशिका" के समान है, यह वस्तुओं के लिए एक तार्किक कंटेनर है।
S3 में एक नई बकेट बनाना आसान है, आप सीधे S3 मेनू पर जा सकते हैं, और नीचे दिखाए अनुसार एक नई बकेट बना सकते हैं:
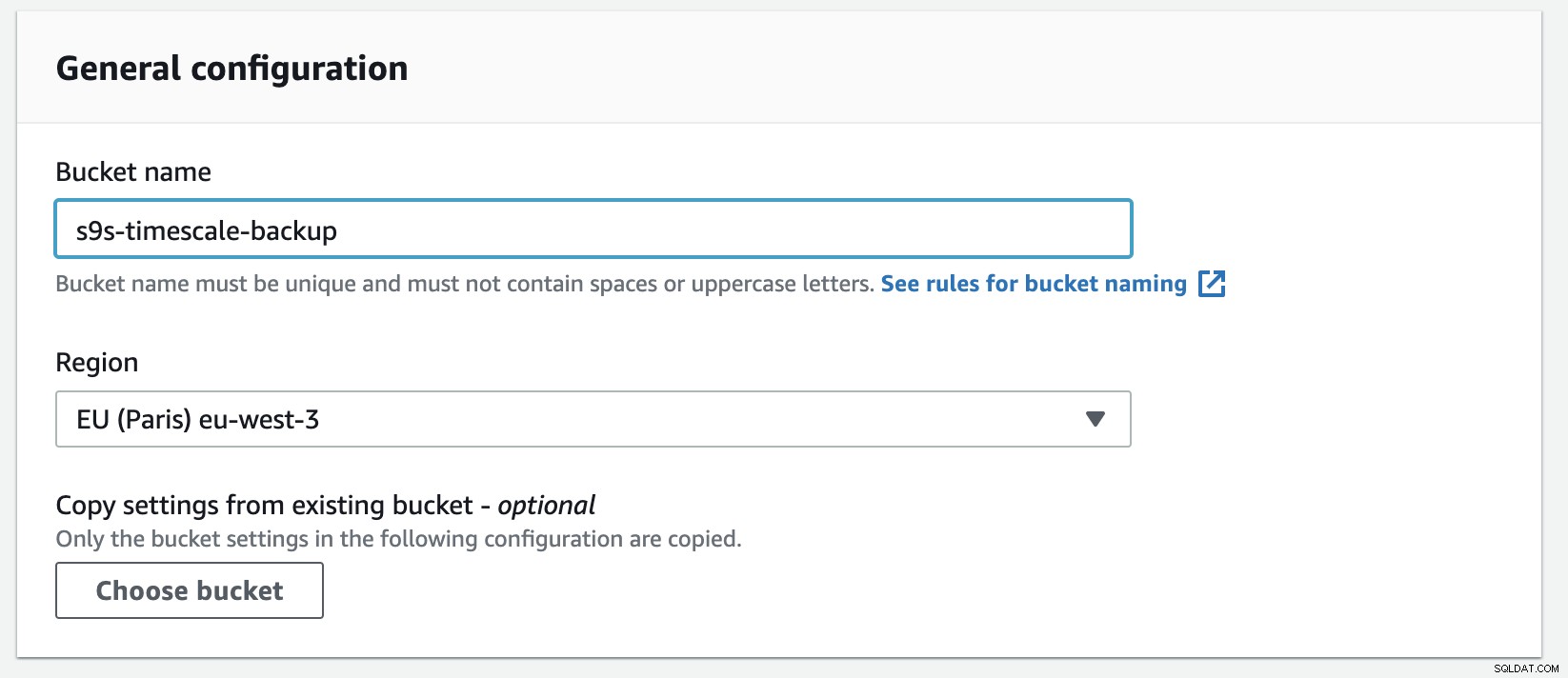
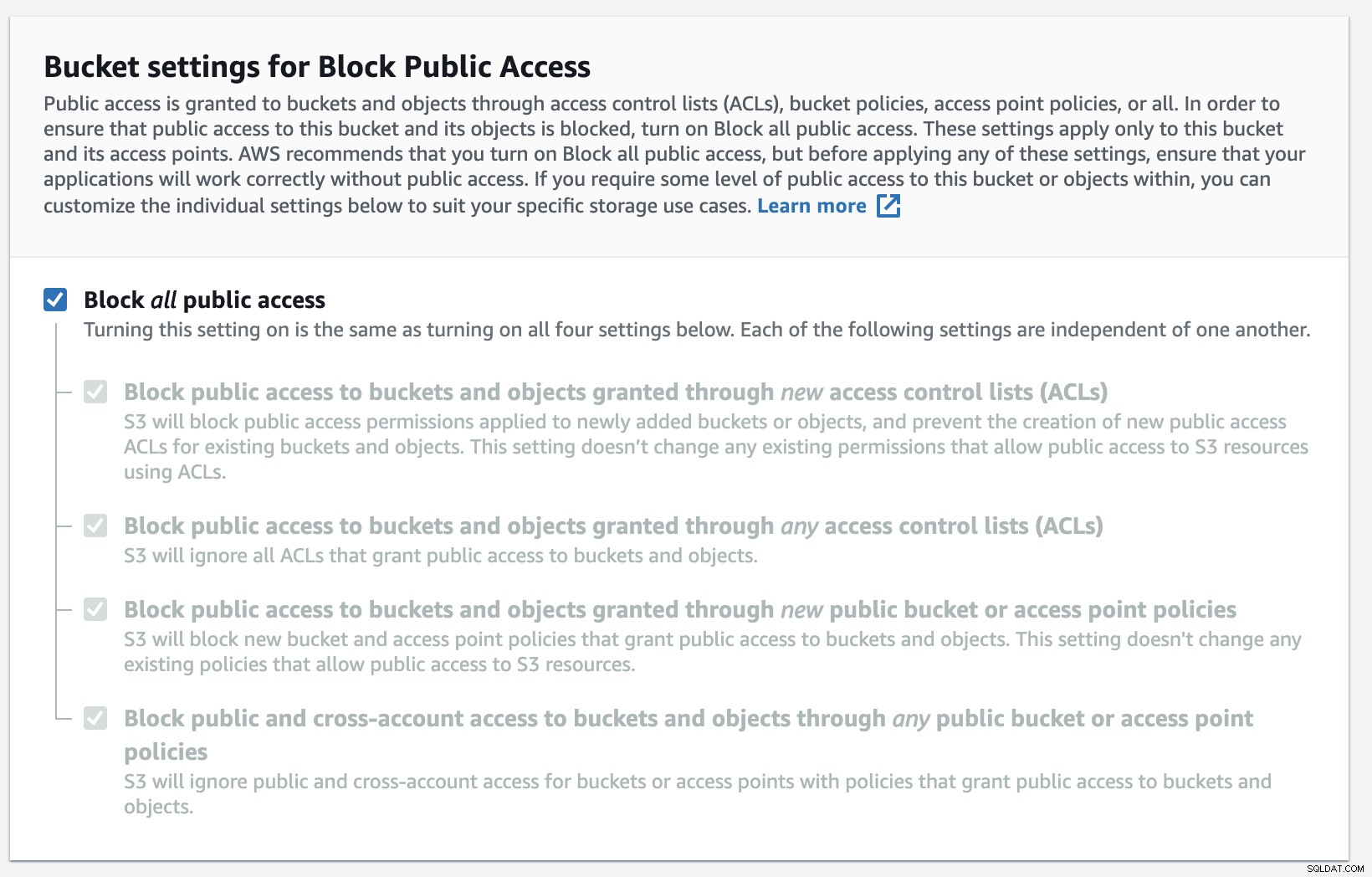
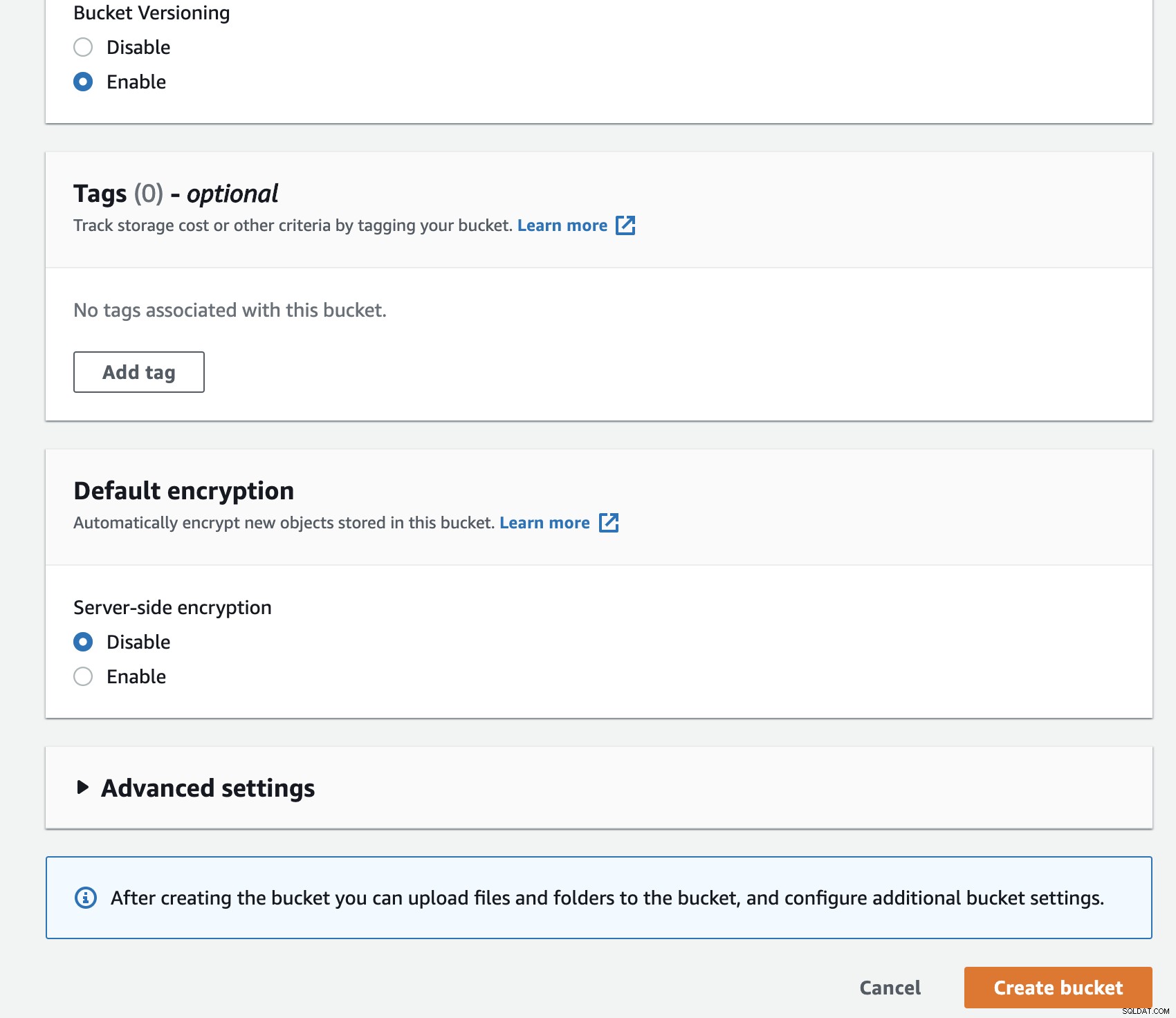
आपको बकेट-नाम भरने की जरूरत है, नाम विश्व स्तर पर अद्वितीय है नाम स्थान के रूप में AWS को सभी AWS खातों में साझा किया जाता है। आप इंटरनेट से बकेट तक पहुंच को प्रतिबंधित कर सकते हैं, या आप इसे एसीएल प्रतिबंधों के साथ प्रकाशित कर सकते हैं। आपके बैकअप डेटा को सुरक्षित करने के लिए एन्क्रिप्शन एक महत्वपूर्ण अभ्यास है।
अपना Google क्लाउड स्टोरेज बकेट तैयार करना
GCP में क्लाउड स्टोरेज को कॉन्फ़िगर करने के लिए, आप स्टोरेज कैटेगरी में जा सकते हैं, और स्टोरेज -> बकेट बनाएं चुन सकते हैं। बाल्टी नाम भरें, Amazon S3 के समान, और बाल्टी नाम भी GCP में विश्व स्तर पर अद्वितीय है।
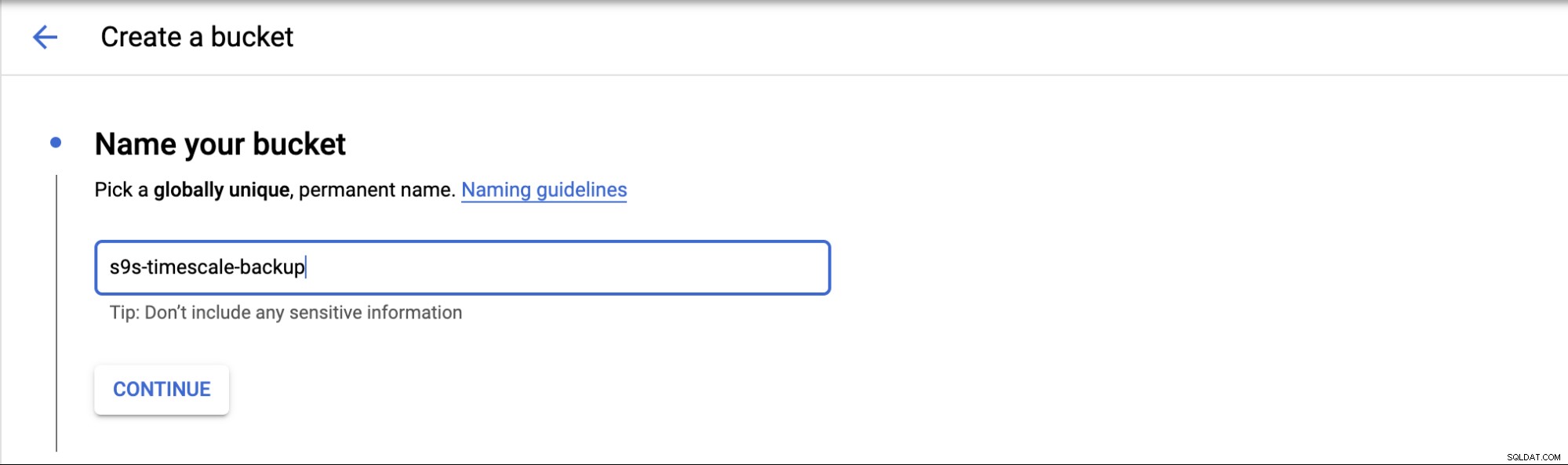
चुनें कि आप अपना बैकअप कहां स्टोर करेंगे, तीन प्रकार के स्थान हैं; आप एक ही क्षेत्र, दोहरे क्षेत्र या बहु-क्षेत्र में स्टोर कर सकते हैं।
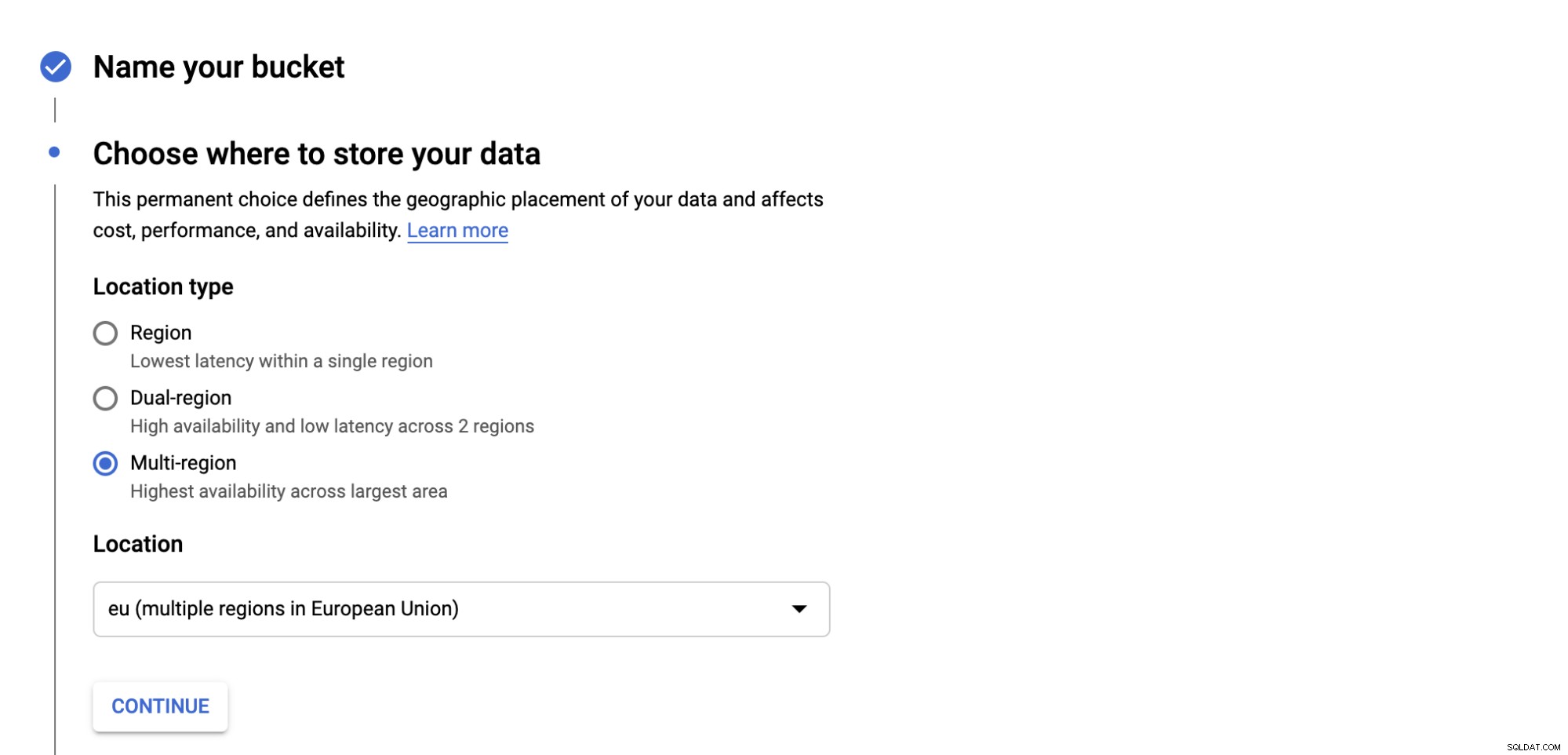
अपनी बकेट के लिए स्टोरेज क्लास का प्रकार चुनें, चार श्रेणियां हैं जो हैं; स्टैंडर्ड, नियरलाइन, कोल्डलाइन और आर्काइव। प्रत्येक श्रेणी के मानदंड हैं कि आप डेटा कैसे प्राप्त कर सकते हैं, और लागत भी।

बकेट के लिए एन्क्रिप्शन, अवधारण नीति से संबंधित कुछ उन्नत सेटिंग्स हैं और अभिगम नियंत्रण।
क्लाउड स्टोरेज यूटिलिटी कॉन्फ़िगर करें
AWS CLI, AWS द्वारा प्रदान किया गया एक इंटरफ़ेस है जो कमांड लाइन के माध्यम से AWS सेवाओं जैसे S3, EC2, सुरक्षा समूहों, VPC, आदि के साथ इंटरैक्ट करता है। आप AWS CLI को उस नोड पर कॉन्फ़िगर कर सकते हैं जहां फ़ाइलों को S3 में स्थानांतरित करने से पहले बैकअप फ़ाइलें रहती हैं। आप यहां एडब्ल्यूएस सीएलआई के लिए इंस्टॉलेशन प्रक्रिया का पालन कर सकते हैं।
आप नीचे दिए गए आदेश को चलाकर अपने AWS CLI संस्करण की जांच कर सकते हैं:
example@sqldat.com:~# /usr/local/bin/aws --version
aws-cli/2.1.7 Python/3.7.3 Linux/4.15.0-91-generic exe/x86_64.ubuntu.18 prompt/offउसके बाद, आपको सर्वर से एक्सेस कुंजी और गुप्त कुंजी को निम्नानुसार कॉन्फ़िगर करना होगा:
example@sqldat.com:~# aws configure
AWS Access Key ID [None]: AKIAREF*******AMKYUY
AWS Secret Access Key [None]: 4C6Cjb1zAIMRfYy******1T16DNXE0QJ3gEb
Default region name [None]: ap-southeast-1
Default output format [None]:फिर आप चलाने के लिए और बैकअप को अपनी बकेट में स्थानांतरित करने के लिए तैयार हैं।
$ aws s3 cp “/mnt/backups/BACKUP-1/full-backup-20201201.tar.gz” s3://s9s-timescale-backup/आप उपरोक्त कमांड के लिए एक शेल स्क्रिप्ट बना सकते हैं और दैनिक चलने के लिए शेड्यूलर को कॉन्फ़िगर कर सकते हैं।
जीसीपी जीएसयूटिल टूल प्रदान करता है, जो आपको कमांड लाइन के माध्यम से क्लाउड स्टोरेज तक पहुंचने देता है। GSUtil के लिए इंस्टॉलेशन प्रक्रिया यहां पाई जा सकती है। स्थापना के बाद, आप GCP तक पहुंच को कॉन्फ़िगर करने के लिए gcloud init चला सकते हैं।
example@sqldat.com:~# gcloud initयह आपको URL पर पहुंचकर और प्रमाणीकरण कोड जोड़कर Google क्लाउड में लॉगिन करने के लिए संकेत देगा।
सभी कॉन्फ़िगर होने के बाद, आप निम्न को चलाकर क्लाउड संग्रहण में बैकअप स्थानांतरण चला सकते हैं:
example@sqldat.com:~# gsutil cp /mnt/backups/BACKUP-1/full-backup-20201201.tar.gz gs://s9s-timescale-backup/ClusterControl के साथ अपना बैकअप प्रबंधित करें
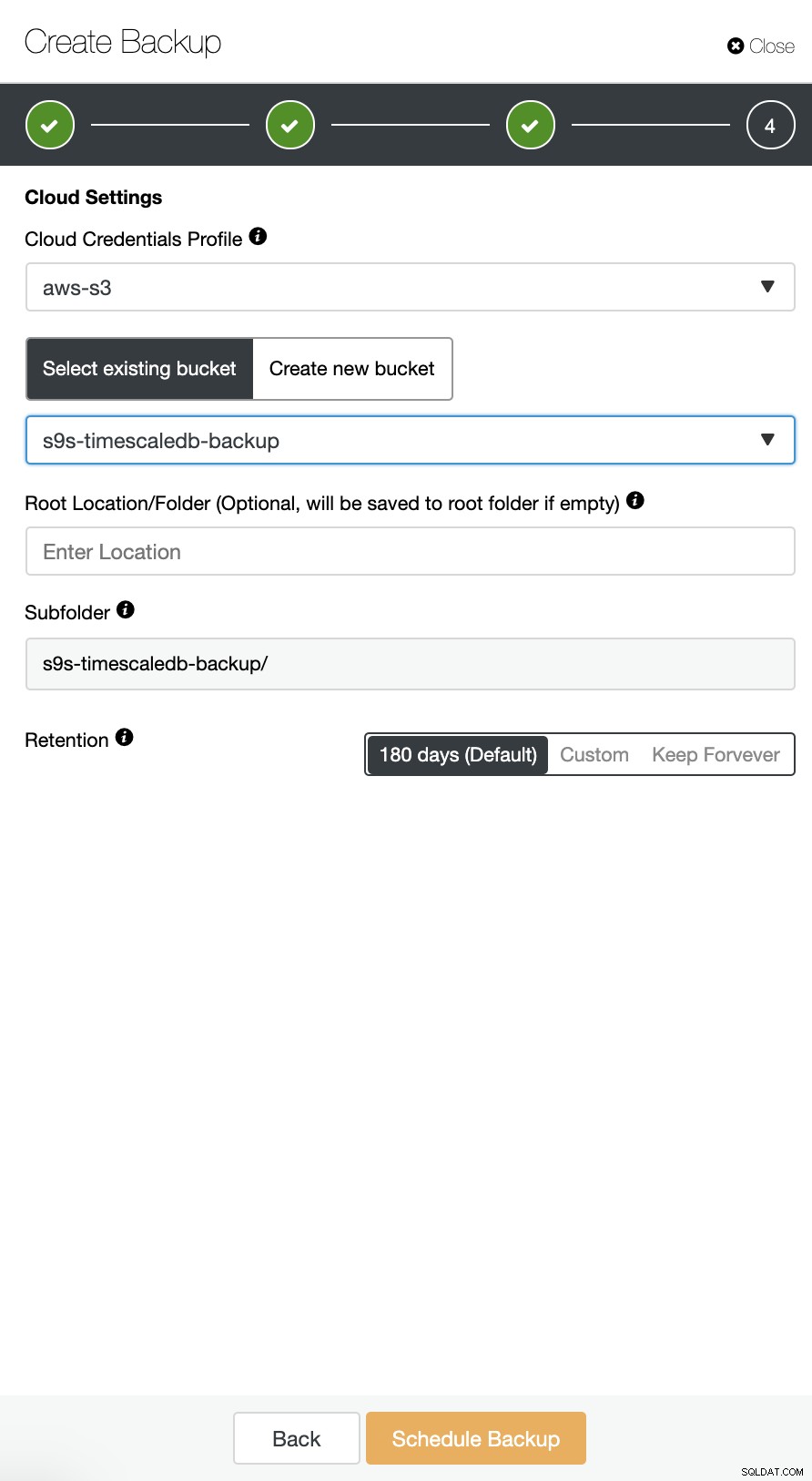
ClusterControl आपके TimeScaleDB बैकअप को क्लाउड पर अपलोड करने का समर्थन करता है। वर्तमान में हम Amazon AWS, Google Cloud Platform और Microsoft Azure का समर्थन करते हैं। अपने TimescaleDB बैकअप को क्लाउड पर कॉन्फ़िगर करने के लिए बहुत सीधा है, आप अपने TimescaleDB क्लस्टर में बैकअप पर जा सकते हैं और नीचे दिखाए अनुसार बैकअप बना सकते हैं:
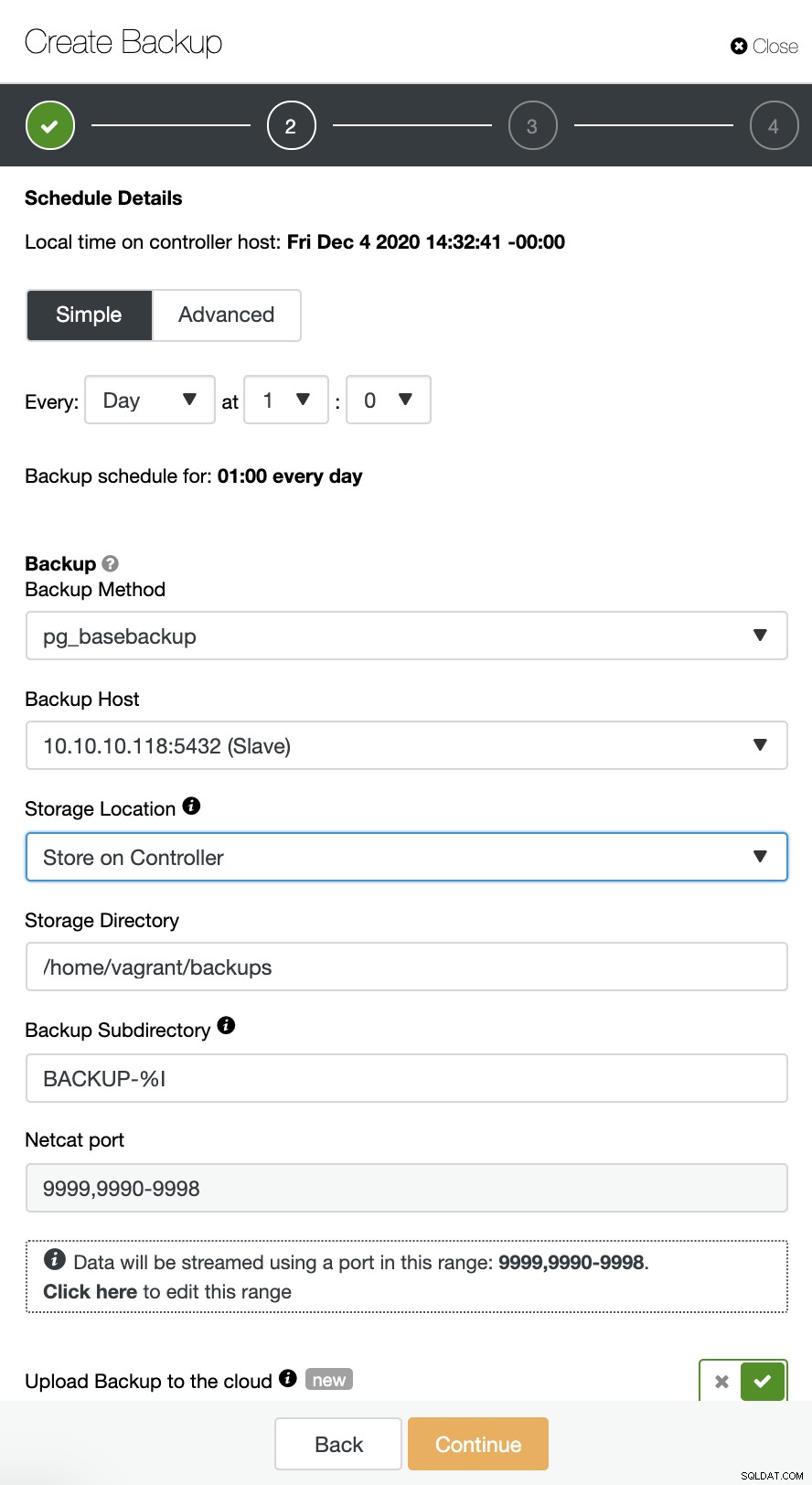
"क्लाउड पर बैकअप अपलोड करें" विकल्प सक्षम करें और जारी रखें। यह आपको क्लाउड प्रदाता चुनने और पहुंच और गुप्त कुंजी भरने के लिए प्रेरित करेगा। इस मामले में, मैं क्लाउड में बैकअप प्रदाता के रूप में AWS S3 का उपयोग करता हूं।
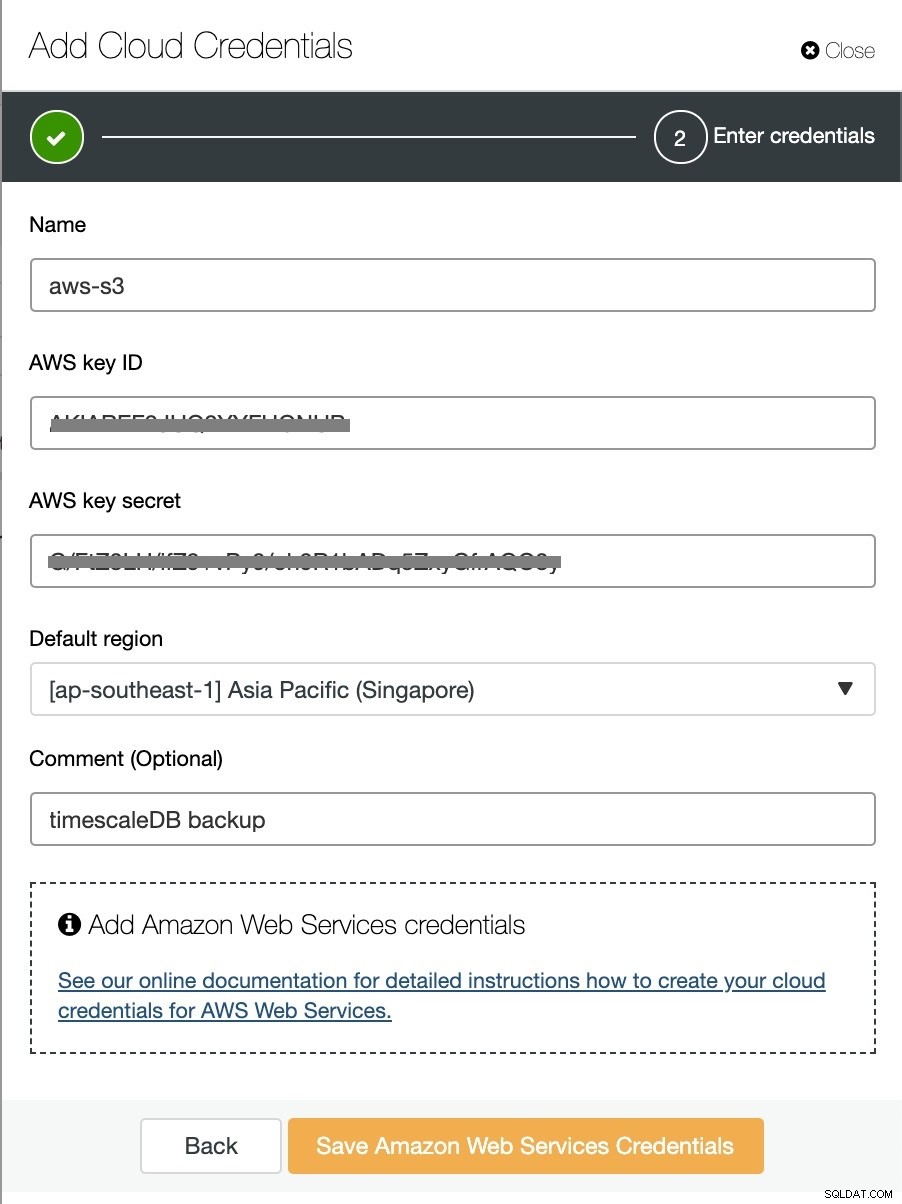
और अंत में, पहले बनाए गए बकेट को चुनें। आप बैकअप की अवधारण को कॉन्फ़िगर कर सकते हैं और बैकअप शेड्यूल कर सकते हैं: