पिछले ब्लॉगों में, मेरे सहयोगियों और मैंने आपको दिखाया था कि आप कैसे प्रदर्शन की निगरानी कर सकते हैं, क्लस्टर का प्रबंधन और तैनाती कर सकते हैं, बैकअप चला सकते हैं और यहां तक कि TimescaleDB के लिए स्वचालित विफलता को सक्षम कर सकते हैं।
इस ब्लॉग में हम आपको दिखाएंगे कि कैसे कुछ सरल चरणों में अपने सिंगल TimescaleDB उदाहरण को मल्टी-नोड क्लस्टर में स्केल किया जाए।
हम एक सामान्य सेटअप के साथ शुरू करेंगे, CentosOS पर चलने वाला एकल नोड इंस्टेंस। नोड अप-एंड-रनिंग है और इसकी पहले से ही ClusterControl द्वारा निगरानी और प्रबंधन किया जा रहा है।
यदि आप सीखना चाहते हैं कि अपने TimescaleDB उदाहरण को कैसे परिनियोजित या आयात करना है, तो मेरे सहयोगी सेबेस्टियन इनसॉस्टी द्वारा लिखे गए ब्लॉग को देखें, "टाइमस्केलडीबी को आसानी से कैसे तैनात करें।"
सेटअप इस प्रकार दिखता है...
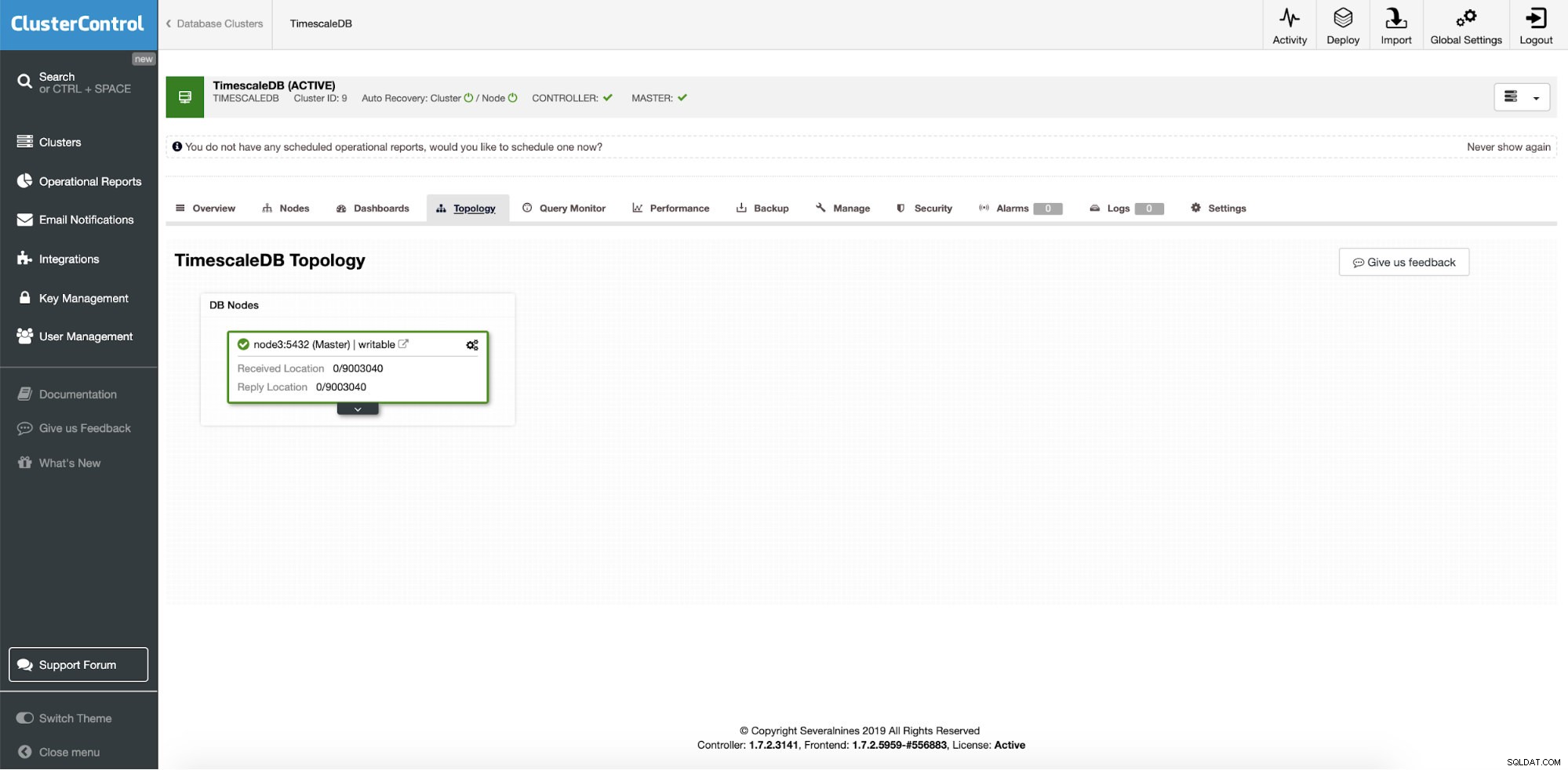 ClusterControl:सिंगल इंस्टेंस TimescaleDB
ClusterControl:सिंगल इंस्टेंस TimescaleDB इसलिए, यह एक एकल उत्पादन उदाहरण है और हम इसे बिना डाउनटाइम के क्लस्टर में बदलना चाहते हैं। हमारा मुख्य लक्ष्य अन्य मशीनों के लिए एप्लिकेशन रीड ऑपरेशंस को स्केल करना है, जिसमें सर्वर क्रैश लिखते समय उन्हें स्टेजिंग HA सर्वर के रूप में उपयोग करने का विकल्प होता है।
अधिक नोड्स को एप्लिकेशन रखरखाव डाउनटाइम को भी कम करना चाहिए। रोलिंग रीस्टार्ट मोड में लागू पैचिंग की तरह - एक नोड को उस समय पैच किया जाता है जबकि अन्य नोड डेटाबेस कनेक्शन प्रदान कर रहे होते हैं।
अंतिम आवश्यकता हमारे नए क्लस्टर के लिए एक ही पता बनाने की है ताकि हमारे नए नोड एक ही स्थान से एप्लिकेशन के लिए दिखाई दें।

हम अपनी कार्य योजना को दो प्रमुख चरणों में सारांशित कर सकते हैं:
- प्रतिलिपि जोड़ना पढ़ता है
- Haproxy को स्थापित और कॉन्फ़िगर करें
प्रतिकृति पढ़ना जोड़ना
यदि हम क्लस्टर क्रियाओं पर जाते हैं और "प्रतिकृति दास जोड़ें" का चयन करते हैं, तो हम या तो खरोंच से एक नई प्रतिकृति बना सकते हैं या एक मौजूदा TimescaleDB डेटाबेस को प्रतिकृति के रूप में जोड़ सकते हैं।
 ClusterControl:प्रतिकृति स्लेव जोड़ें
ClusterControl:प्रतिकृति स्लेव जोड़ें  ClusterControl:नया प्रतिकृति स्लेव जोड़ें, मौजूदा प्रतिकृति स्लेव आयात करें
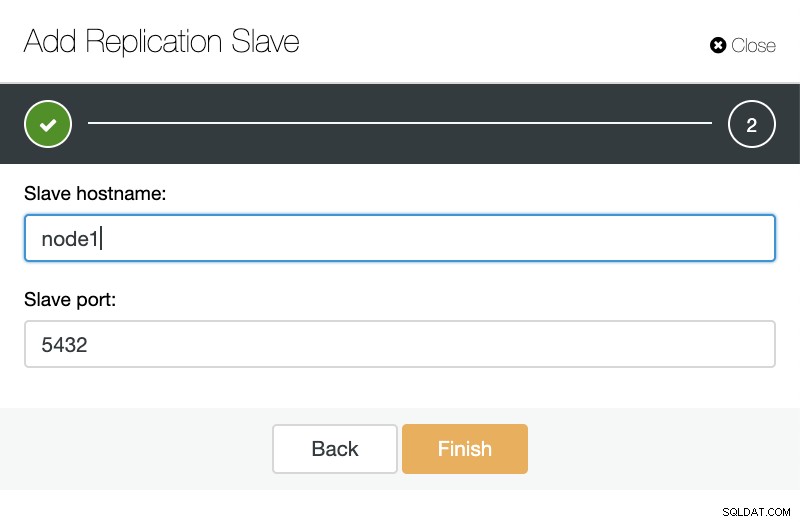
ClusterControl:नया प्रतिकृति स्लेव जोड़ें, मौजूदा प्रतिकृति स्लेव आयात करें जैसा कि आप नीचे की छवि में देख सकते हैं, हमें केवल अपना मास्टर सर्वर चुनने की जरूरत है, हमारे नए दास सर्वर और डेटाबेस पोर्ट के लिए आईपी पता दर्ज करें।
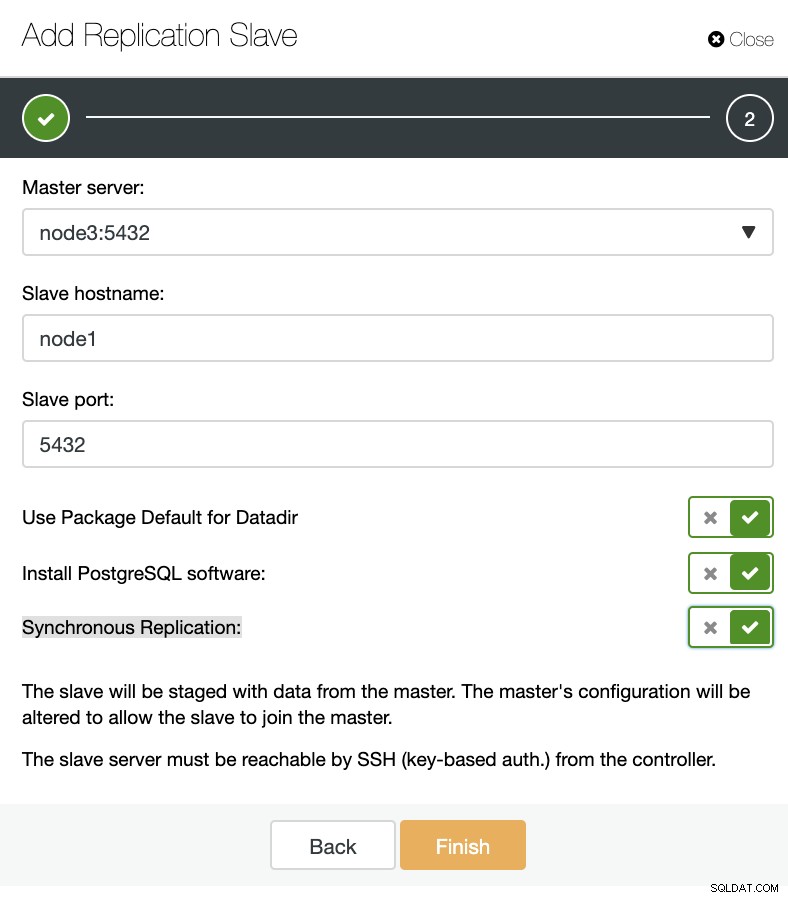 ClusterControl:प्रतिकृति स्लेव जोड़ें
ClusterControl:प्रतिकृति स्लेव जोड़ें फिर हम चुन सकते हैं कि क्या हम चाहते हैं कि क्लस्टर कंट्रोल हमारे लिए सॉफ़्टवेयर स्थापित करे और यदि प्रतिकृति दास सिंक्रोनस या एसिंक्रोनस होना चाहिए। जब आप मौजूदा स्लेव सर्वर का आयात कर रहे हों तो आप निम्न प्रकार से आयात विकल्प का उपयोग कर सकते हैं:
 ClusterControl:TimescaleDB के लिए प्रतिकृति स्लेव आयात करें
ClusterControl:TimescaleDB के लिए प्रतिकृति स्लेव आयात करें दोनों तरीकों से, हम जितनी चाहें उतनी प्रतिकृतियां जोड़ सकते हैं। हमारे उदाहरण के मामले में, हम दो नोड जोड़ेंगे। CusterControl एक आंतरिक कार्य सृजित करेगा और एक समय में एक के बिना सभी आवश्यक चरणों का ध्यान रखेगा।
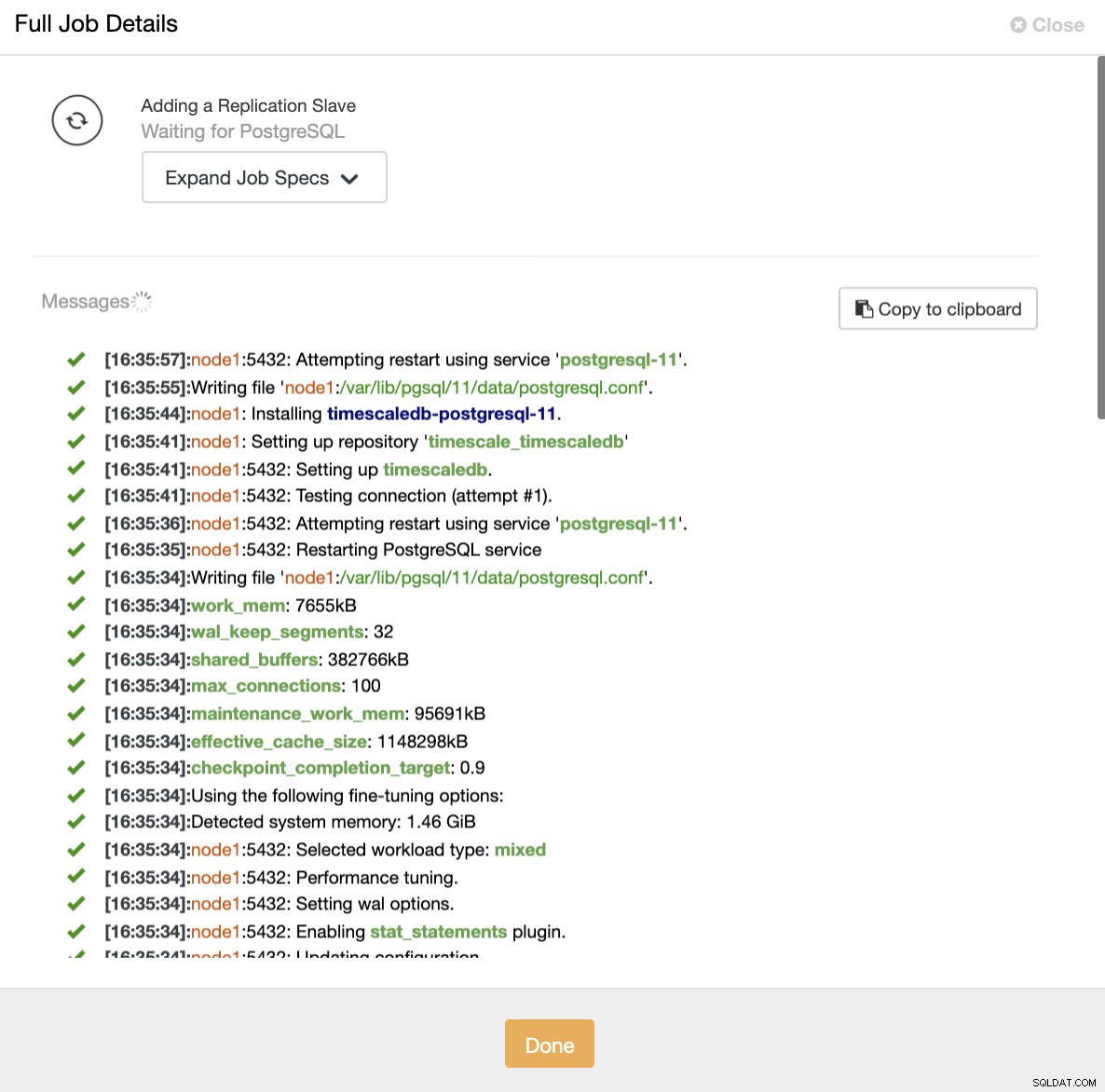 ClusterControl:रीड रेप्लिका जोड़ें
ClusterControl:रीड रेप्लिका जोड़ें TimescaleDB में लोड बैलेंसर जोड़ना
इस बिंदु पर, यदि आप किसी भिन्न स्थान पर प्रतिकृति स्लेव नोड्स जोड़ना चुनते हैं, तो हमारा डेटा कई नोड्स या डेटा केंद्रों में वितरित किया जाता है। क्लस्टर को दो अतिरिक्त रीड रेप्लिका नोड्स के साथ बढ़ाया गया है।
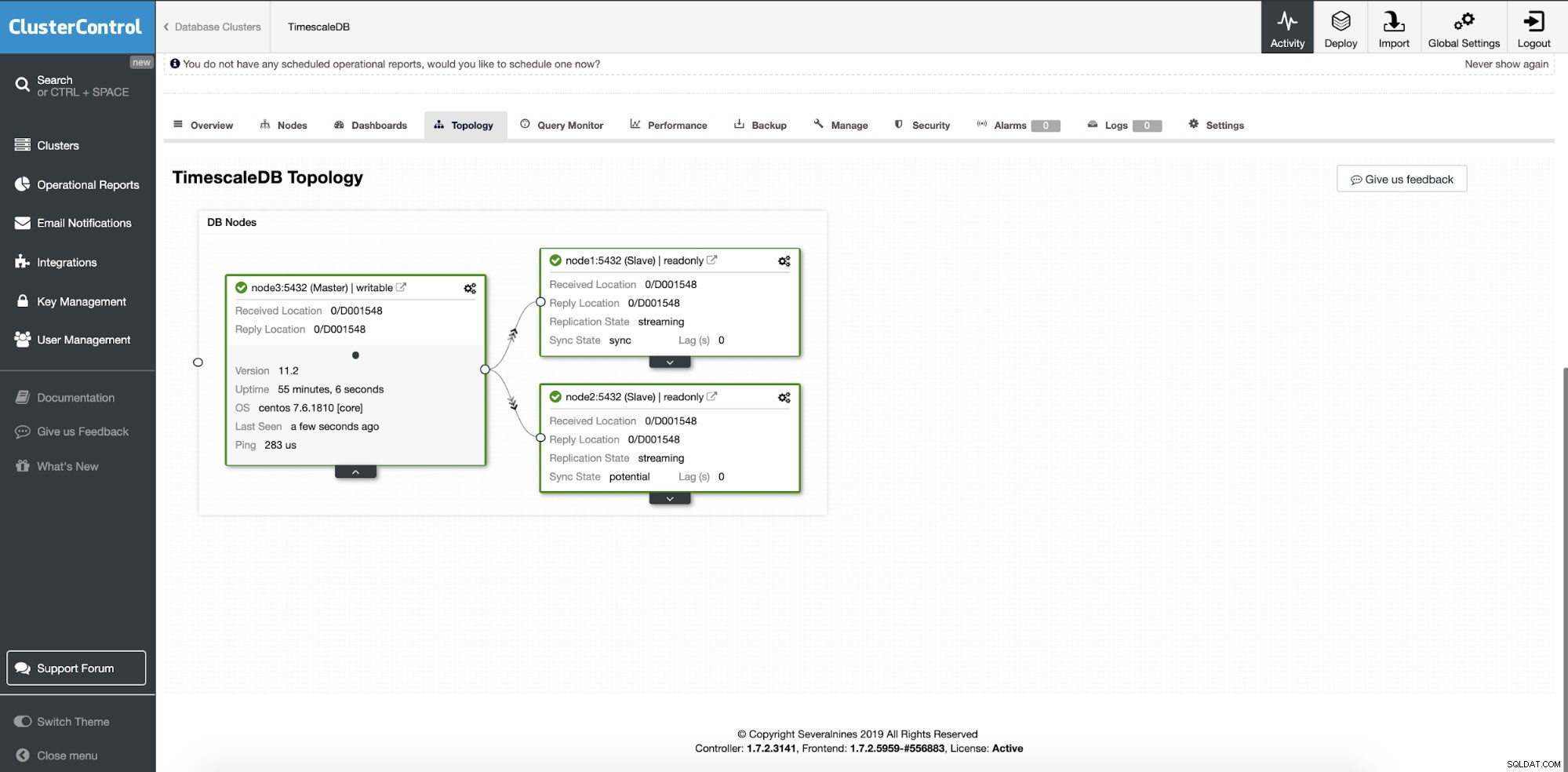 ClusterControl:दो नोड जोड़े गए
ClusterControl:दो नोड जोड़े गए सवाल यह है कि एप्लिकेशन को कैसे पता चलता है कि किस डेटाबेस नोड को एक्सेस करना है? हम लिखने और पढ़ने के संचालन के लिए HAProxy और विभिन्न बंदरगाहों का उपयोग करेंगे।
TimescaleDB क्लस्टर से, संदर्भ मेनू लोड बैलेंसर जोड़ने के लिए चुनें।

अब हमें सर्वर का स्थान प्रदान करने की आवश्यकता है जहां हैप्रोक्सी स्थापित किया जाना चाहिए, डेटाबेस कनेक्शन के लिए हम किस नीति का उपयोग करना चाहते हैं और कौन से नोड हैप्रोक्सी कॉन्फ़िगरेशन का हिस्सा लेते हैं।
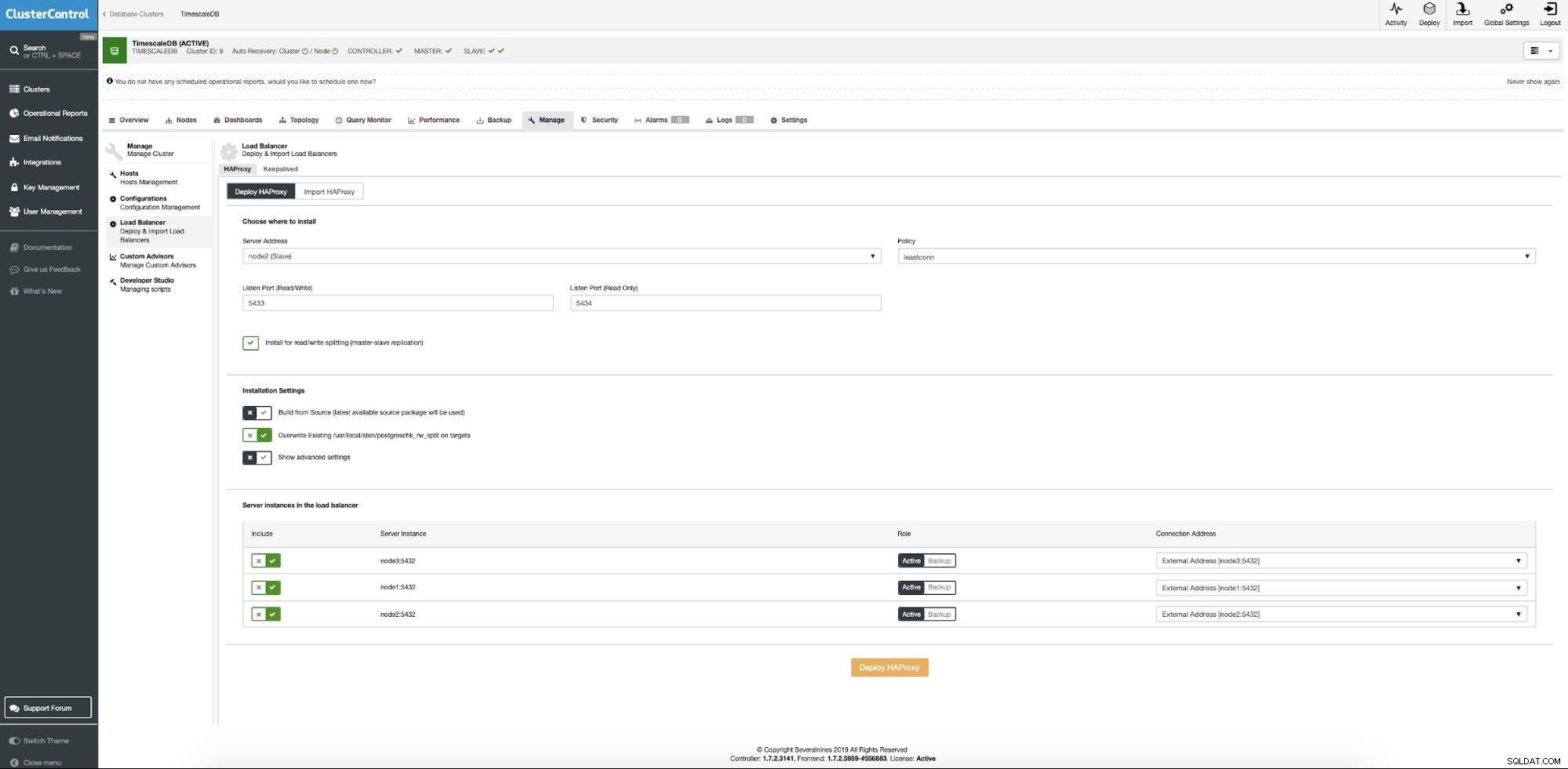
जब सब सेट हो जाए तो डिप्लॉय बटन दबाएं। कुछ मिनटों के बाद, हमें अपना क्लस्टर कॉन्फ़िगरेशन तैयार करना चाहिए। ClusterControl लोड बैलेंसर को परिनियोजित करने के लिए सभी पूर्वापेक्षाओं और कॉन्फ़िगरेशन का ध्यान रखेगा।
एक सफल परिनियोजन के बाद, हम अपने नए क्लस्टर की टोपोलॉजी देख सकते हैं; लोड संतुलन और अतिरिक्त रीड नोड्स के साथ। ऑन-बोर्ड अधिक नोड्स के साथ, ClusterControl स्वचालित रूप से स्वतः पुनर्प्राप्ति को सक्षम करता है। इस तरह जब मास्टर नोड नीचे चला जाता है, तो फ़ेलओवर ऑपरेशन अपने आप शुरू हो जाएगा।
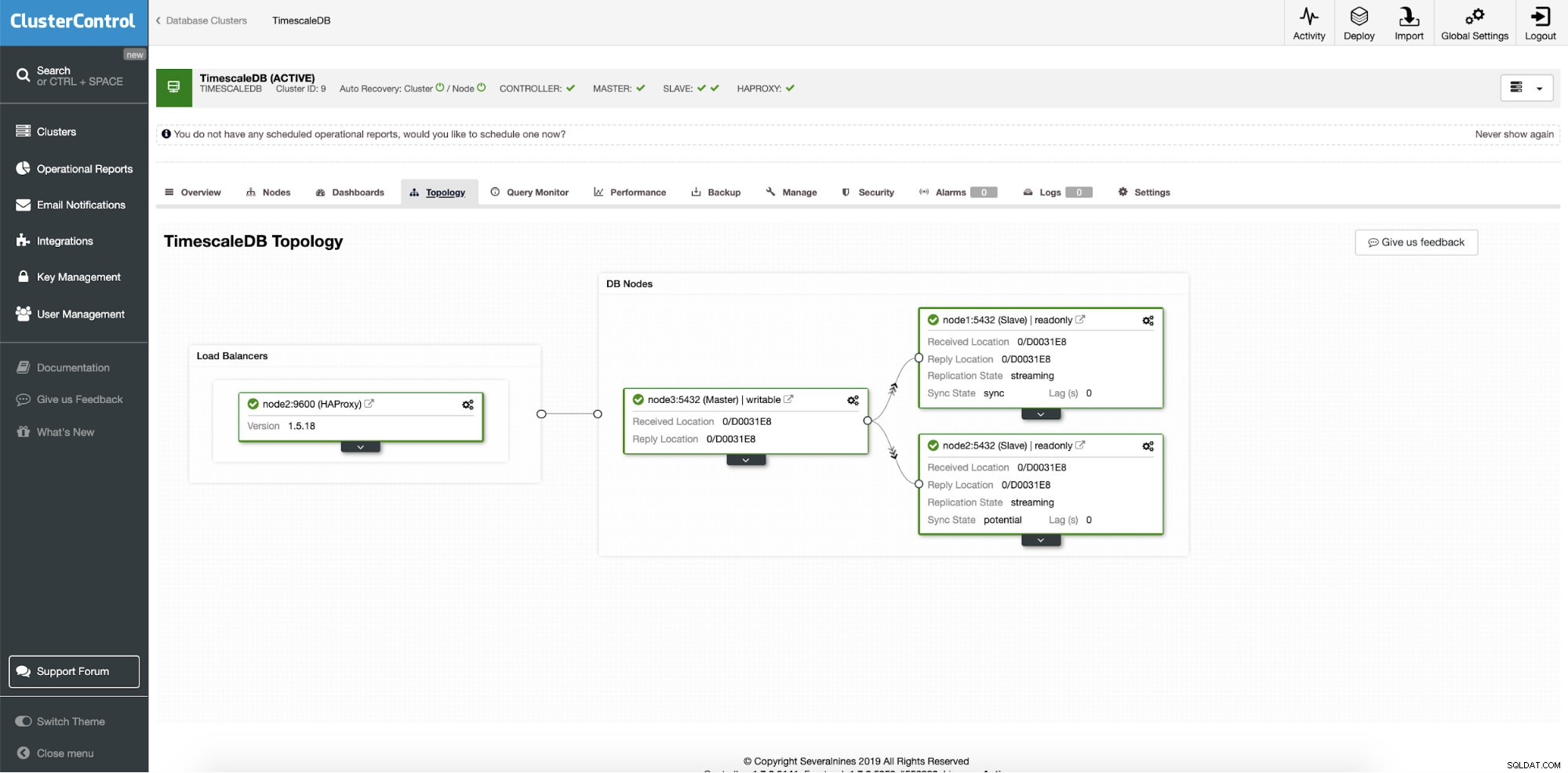 ClusterControl:फाइनल टोपोलॉजी
ClusterControl:फाइनल टोपोलॉजी निष्कर्ष
TimescaleDB एक ओपन-सोर्स डेटाबेस है जिसका आविष्कार समय-श्रृंखला डेटा के लिए SQL को स्केलेबल बनाने के लिए किया गया है। अपने क्लस्टर का विस्तार करने का एक स्वचालित तरीका प्रदर्शन और दक्षता प्राप्त करने की कुंजी है। जैसा कि हमने ऊपर देखा है, अब आप आसानी से ClusterControl का उपयोग करके TimescaleDB को माप सकते हैं।