उच्च उपलब्धता प्रणालियों की बढ़ती मांग और कड़े एसएलए हमें स्वचालित समाधानों के साथ मैन्युअल प्रक्रियाओं को बदलने के लिए प्रेरित करते हैं। लेकिन क्या आपके पास विफलता संचालन की जटिलता को स्वयं दूर करने के लिए समय और आवश्यक संसाधन हैं? क्या आप इसे कठिन तरीके से सीखने के लिए उत्पादन डेटाबेस डाउनटाइम का त्याग करेंगे?
ClusterControl विफलता का पता लगाने और संभालने के लिए उन्नत समर्थन प्रदान करता है। इसका उपयोग कई उद्यम संगठनों द्वारा किया जाता है, जो सबसे महत्वपूर्ण प्रोडक्शन सिस्टम को 24/7 मोड में चालू और चालू रखता है।
यह डेटाबेस प्रबंधन समाधान विभिन्न लोड प्रॉक्सी के परिनियोजन में भी आपकी सहायता करता है। ये प्रॉक्सी HA स्टैक में एक महत्वपूर्ण भूमिका निभाते हैं, इसलिए एप्लिकेशन कनेक्शन को नए मास्टर नोड पर रीडायरेक्ट करने के लिए एप्लिकेशन कनेक्शन स्ट्रिंग या DNS प्रविष्टि को समायोजित करने की कोई आवश्यकता नहीं है।
जब विफलता का पता चलता है, तो ClusterControl एक नया मास्टर चुनने, फेल-ओवर स्लेव सर्वर को परिनियोजित करने और लोड बैलेंसर्स को कॉन्फ़िगर करने के लिए सभी पृष्ठभूमि कार्य करता है। इस ब्लॉग में, आप सीखेंगे कि अपने उत्पादन प्रणालियों में TimescaleDB की स्वचालित विफलता कैसे प्राप्त करें।
संपूर्ण प्रतिकृति टोपोलॉजी को परिनियोजित करना
ClusterControl 1.7.2 से शुरू करके आप एक संपूर्ण TimescaleDB प्रतिकृति सेटअप को उसी तरह परिनियोजित कर सकते हैं जैसे आप PostgreSQL को परिनियोजित करेंगे:आप प्राथमिक और एक या अधिक TimescaleDB स्टैंडबाय सर्वर को परिनियोजित करने के लिए "क्लस्टर परिनियोजित करें" मेनू का उपयोग कर सकते हैं। आइए देखें कि यह कैसा दिखता है।
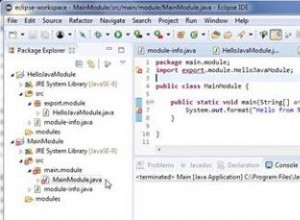
सबसे पहले, आपको ClusterControl का उपयोग करके नए क्लस्टर को परिनियोजित करते समय एक्सेस विवरण को परिभाषित करने की आवश्यकता है। इसके लिए उन सभी नोड्स के लिए रूट या सूडो पासवर्ड एक्सेस की आवश्यकता होती है जिन पर आपका नया क्लस्टर तैनात किया जाएगा।
 ClusterControl:नया क्लस्टर परिनियोजित करें
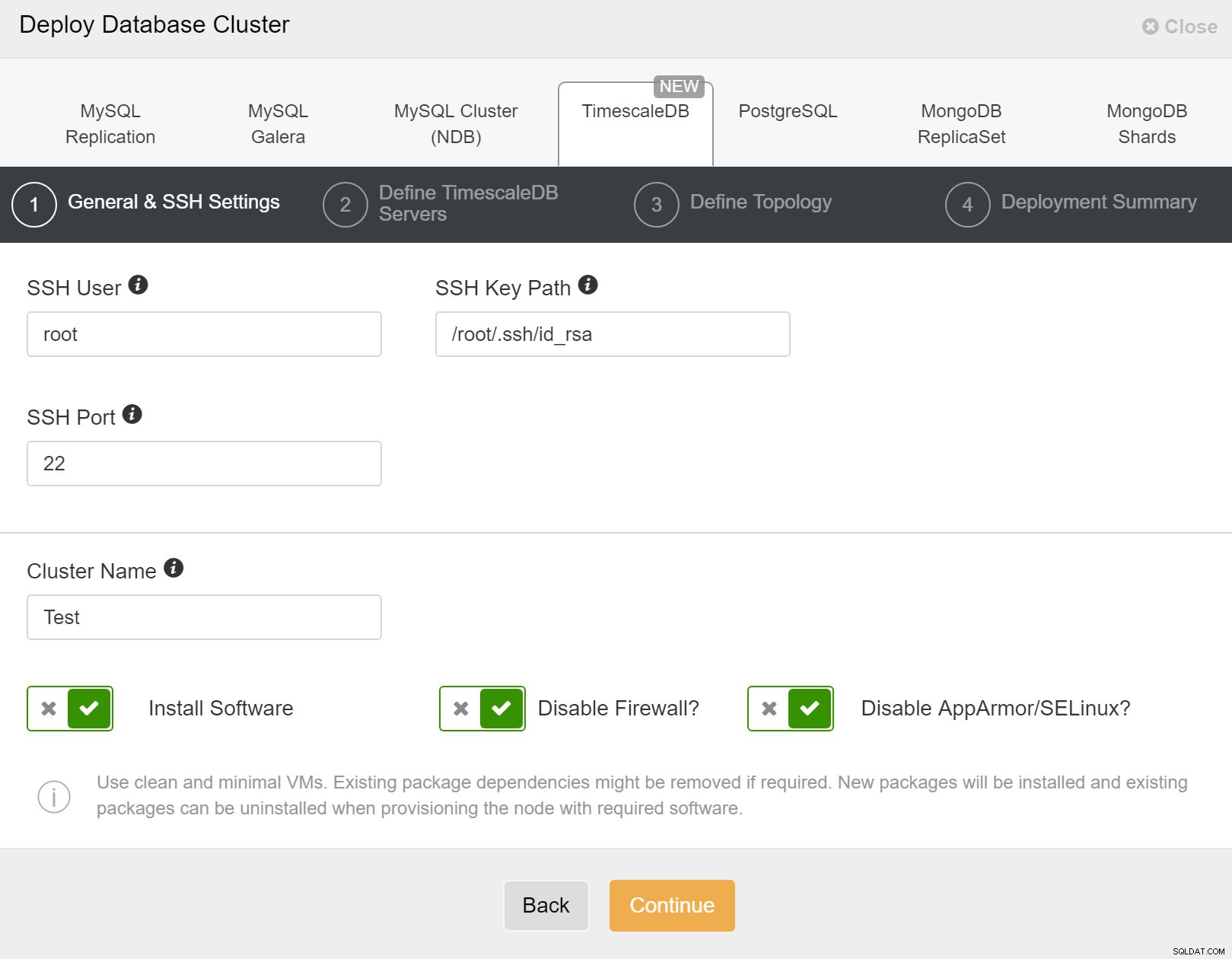
ClusterControl:नया क्लस्टर परिनियोजित करें इसके बाद, हमें TimescaleDB उपयोगकर्ता के लिए उपयोगकर्ता और पासवर्ड को परिभाषित करने की आवश्यकता है।
 ClusterControl:डेटाबेस क्लस्टर परिनियोजित करें
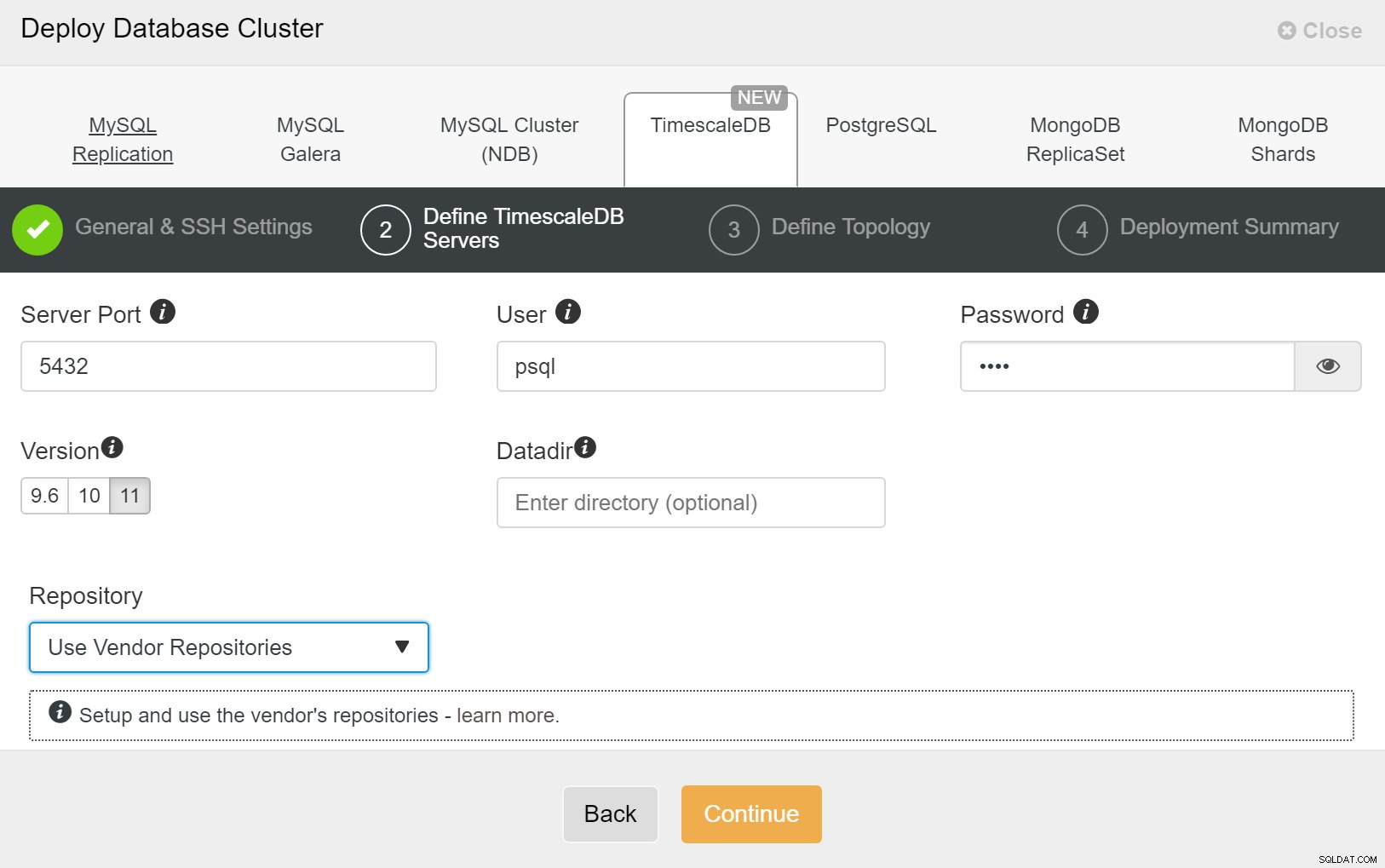
ClusterControl:डेटाबेस क्लस्टर परिनियोजित करें अंत में, आप टोपोलॉजी को परिभाषित करना चाहते हैं - कौन सा होस्ट प्राथमिक होना चाहिए और कौन से होस्ट को स्टैंडबाय के रूप में कॉन्फ़िगर किया जाना चाहिए। जब आप टोपोलॉजी में होस्ट्स को परिभाषित करते हैं, तो ClusterControl जाँच करेगा कि क्या ssh एक्सेस अपेक्षित रूप से काम करता है - यह आपको किसी भी कनेक्टिविटी समस्या को जल्दी पकड़ने देता है। आखिरी स्क्रीन पर, आपसे सिंक्रोनस या एसिंक्रोनस प्रतिकृति के प्रकार के बारे में पूछा जाएगा।
 ClusterControl परिनियोजन
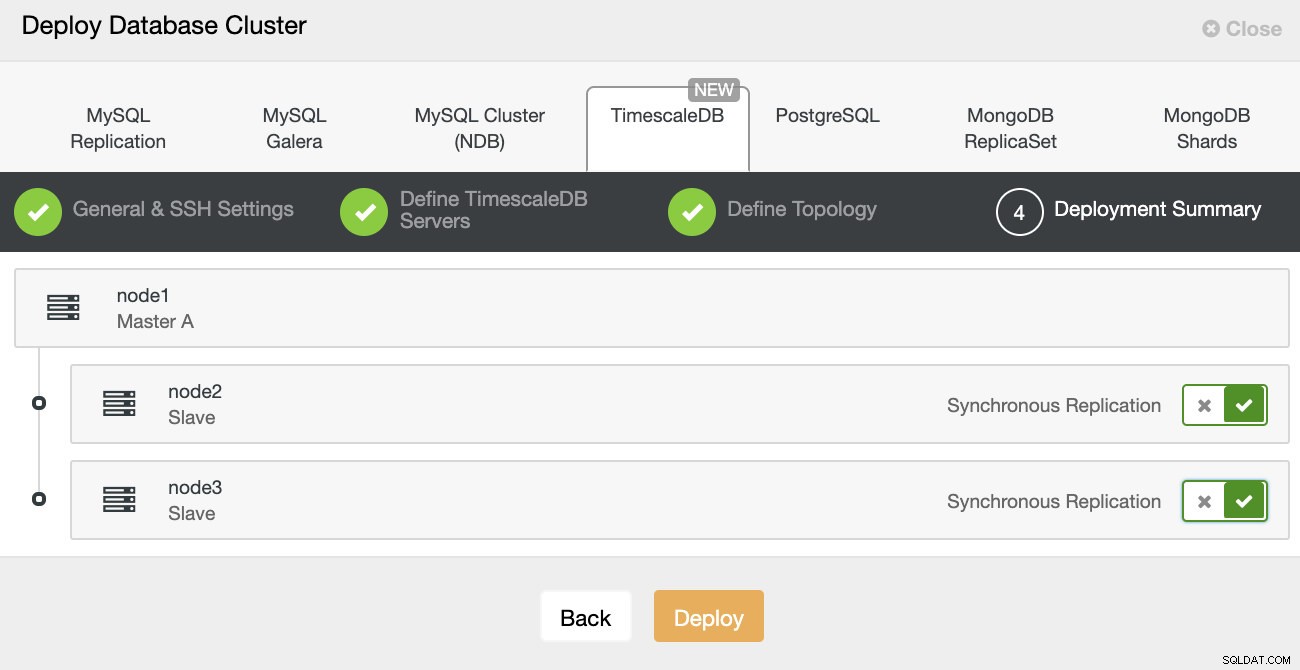
ClusterControl परिनियोजन बस इतना ही, फिर तैनाती शुरू करने की बात है। ClusterControl में एक कार्य बनाया गया है, और आप प्रगति का अनुसरण करने में सक्षम होंगे।
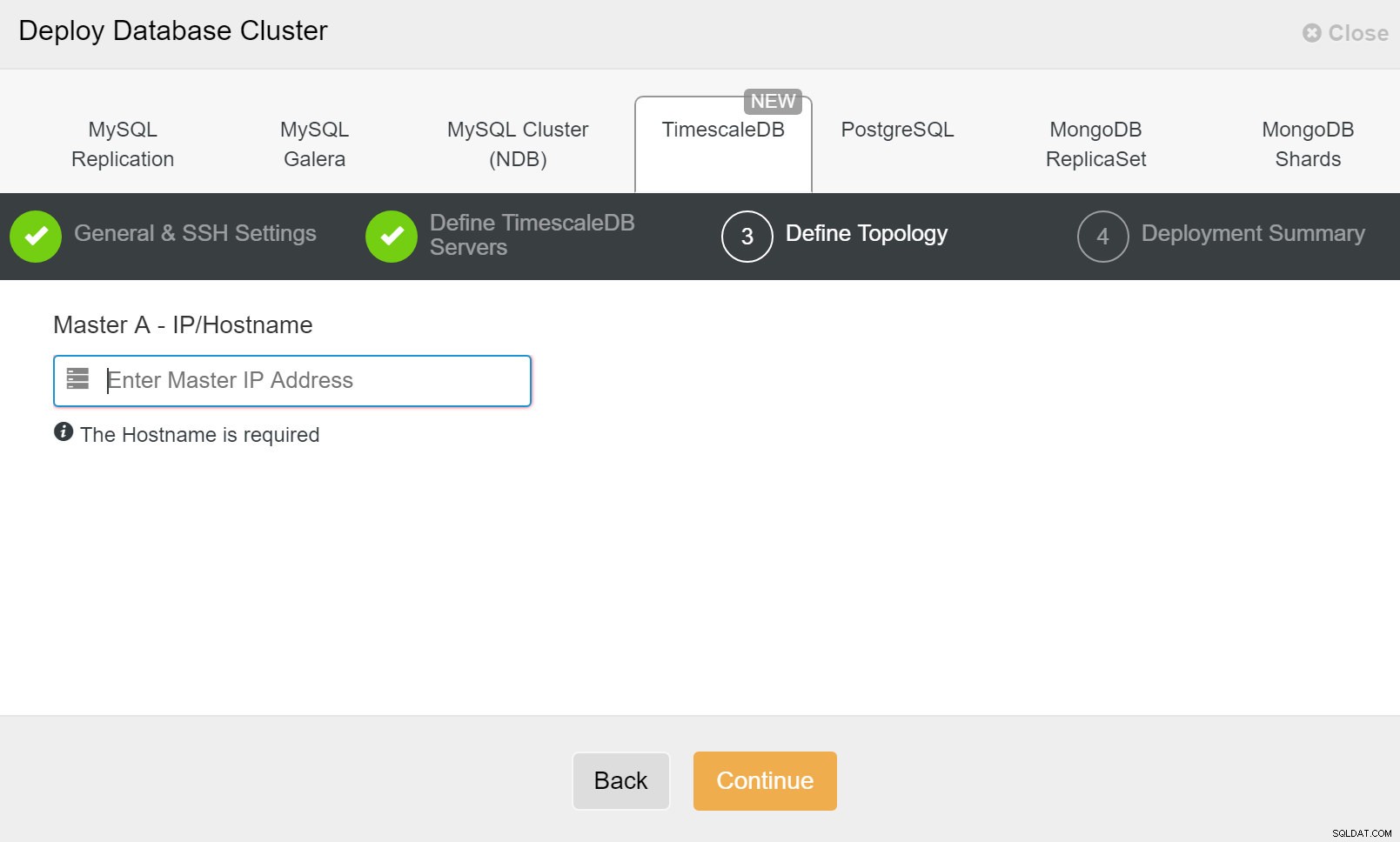 ClusterControl:TimescleDb क्लस्टर के लिए टोपोलॉजी को परिभाषित करें
ClusterControl:TimescleDb क्लस्टर के लिए टोपोलॉजी को परिभाषित करें एक बार जब आप समाप्त कर लेंगे तो आप क्लस्टर में भूमिकाओं के साथ टोपोलॉजी सेटअप देखेंगे। ध्यान दें कि हमने डेटाबेस इंस्टेंस के सामने एक लोड बैलेंसर (HAProxy) भी जोड़ा है ताकि स्वचालित विफलता के लिए डेटाबेस कनेक्शन सेटिंग्स में बदलाव की आवश्यकता न हो।
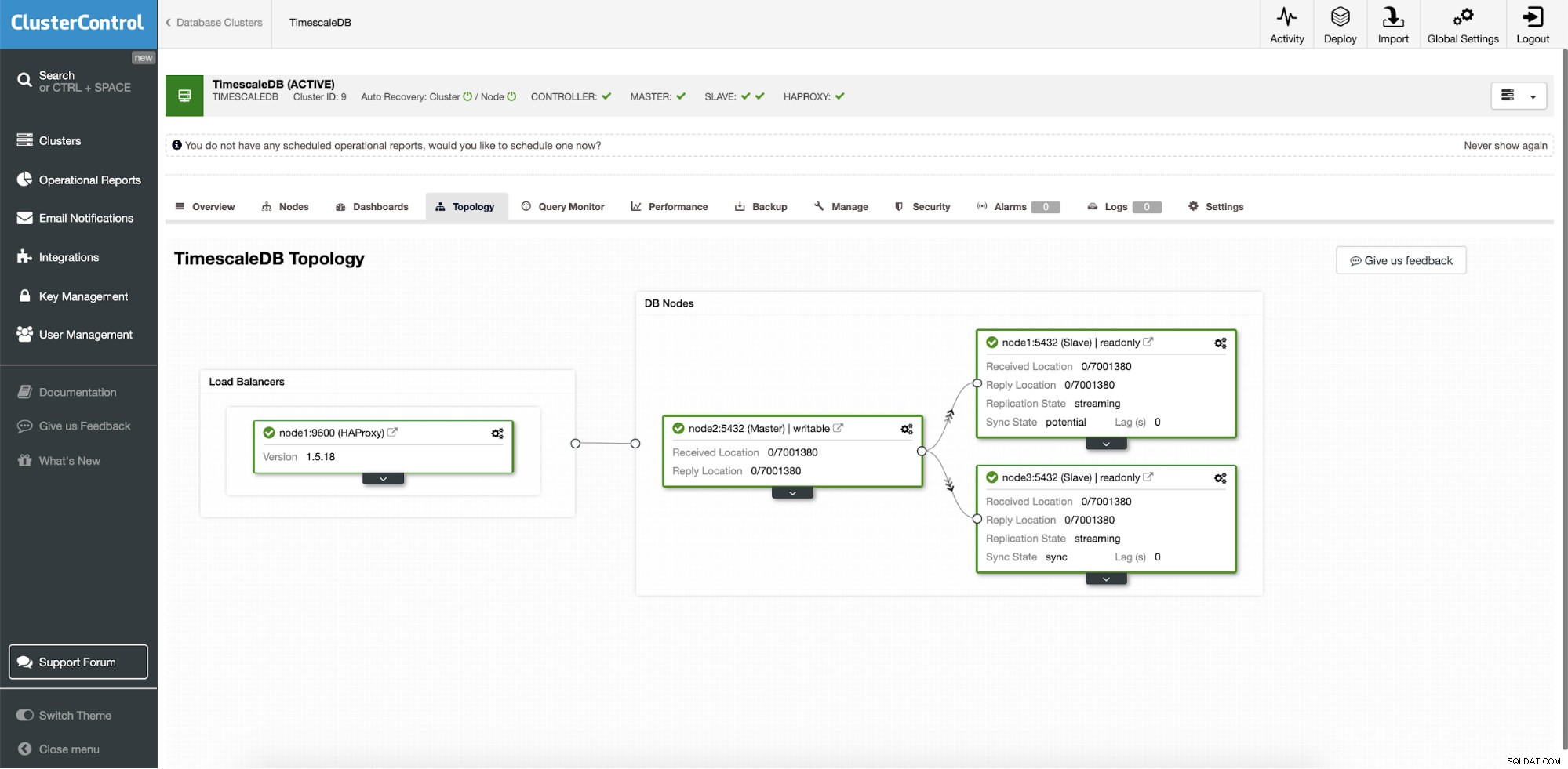 ClusterControl:टोपोलॉजी
ClusterControl:टोपोलॉजी जब Timescale को ClusterControl द्वारा परिनियोजित किया जाता है, तो डिफ़ॉल्ट रूप से स्वचालित पुनर्प्राप्ति सक्षम हो जाती है। राज्य को क्लस्टर बार में चेक किया जा सकता है।
 ClusterControl:ऑटो रिकवरी क्लस्टर और नोड स्थिति
ClusterControl:ऑटो रिकवरी क्लस्टर और नोड स्थिति विफलता कॉन्फ़िगरेशन
एक बार प्रतिकृति सेटअप परिनियोजित हो जाने पर, ClusterControl सेटअप की निगरानी करने और किसी भी विफल सर्वर को स्वचालित रूप से पुनर्प्राप्त करने में सक्षम होता है। यह टोपोलॉजी में बदलाव को भी व्यवस्थित कर सकता है।
ClusterControl स्वचालित विफलता को निम्नलिखित सिद्धांतों के साथ डिज़ाइन किया गया था:
- सुनिश्चित करें कि आपके विफल होने से पहले मास्टर वास्तव में मर चुका है
- केवल एक बार विफलता
- असंगत दास को विफल न करें
- केवल मास्टर को लिखें
- असफल मास्टर को स्वचालित रूप से पुनर्प्राप्त न करें
अंतर्निहित एल्गोरिदम के साथ, फ़ेलओवर अक्सर बहुत तेज़ी से किया जा सकता है ताकि आप अपने डेटाबेस परिवेश के लिए उच्चतम SLA का आश्वासन दे सकें।
प्रक्रिया विन्यास योग्य है। यह कई मापदंडों के साथ आता है जिनका उपयोग आप अपने पर्यावरण की विशिष्टताओं के लिए पुनर्प्राप्ति को अपनाने के लिए कर सकते हैं।
| max_replication_lag | अधिकतम अनुमत प्रतिकृति अंतराल सेकंड पहले |
| replication_stop_on_error | यदि ऐसी त्रुटियाँ आती हैं जो डेटा हानि का कारण बन सकती हैं, तो विफलता/स्विचओवर प्रक्रियाएँ विफल हो जाएँगी। डिफ़ॉल्ट रूप से सक्षम। 0 का अर्थ है अक्षम, |
| replication_auto_rebuild_slave | यदि SQL THREAD को रोक दिया जाता है और त्रुटि कोड गैर-शून्य है, तो दास स्वचालित रूप से फिर से बन जाएगा। 1 का अर्थ है सक्षम करना, 0 का अर्थ अक्षम (डिफ़ॉल्ट) है। |
| replication_failover_blacklist | होस्टनाम की अल्पविराम से अलग सूची:पोर्ट जोड़े। फेलओवर के दौरान ब्लैक लिस्टेड सर्वर को उम्मीदवार नहीं माना जाएगा। यदि प्रतिकृति_विफलता_श्वेतसूची सेट है, तो प्रतिकृति_फेलओवर_ब्लैकलिस्ट पर ध्यान नहीं दिया जाता है। |
| प्रतिकृति_विफलता_श्वेतसूची | होस्टनाम की अल्पविराम से अलग की गई सूची:पोर्ट जोड़े। फेलओवर के दौरान केवल श्वेतसूचीबद्ध सर्वरों को ही उम्मीदवार माना जाएगा। यदि श्वेतसूची में कोई सर्वर उपलब्ध नहीं है (ऊपर/जुड़ा हुआ) तो फ़ेलओवर विफल हो जाएगा। यदि प्रतिकृति_विफलता_श्वेतसूची सेट है, तो प्रतिकृति_फेलओवर_ब्लैकलिस्ट पर ध्यान नहीं दिया जाता है। |
विफलता प्रबंधन
जब एक मास्टर विफलता का पता चलता है, तो मास्टर उम्मीदवारों की एक सूची बनाई जाती है और उनमें से एक को नया मास्टर बनने के लिए चुना जाता है। प्राथमिक को बढ़ावा देने के लिए सर्वरों की श्वेतसूची के साथ-साथ उन सर्वरों की ब्लैकलिस्ट होना संभव है जिन्हें प्राथमिक में पदोन्नत नहीं किया जा सकता है। शेष दास अब नए प्राथमिक से गुलाम हो गए हैं, और पुराने प्राथमिक को फिर से शुरू नहीं किया गया है।
नीचे हम नोड विफलता का अनुकरण देख सकते हैं।
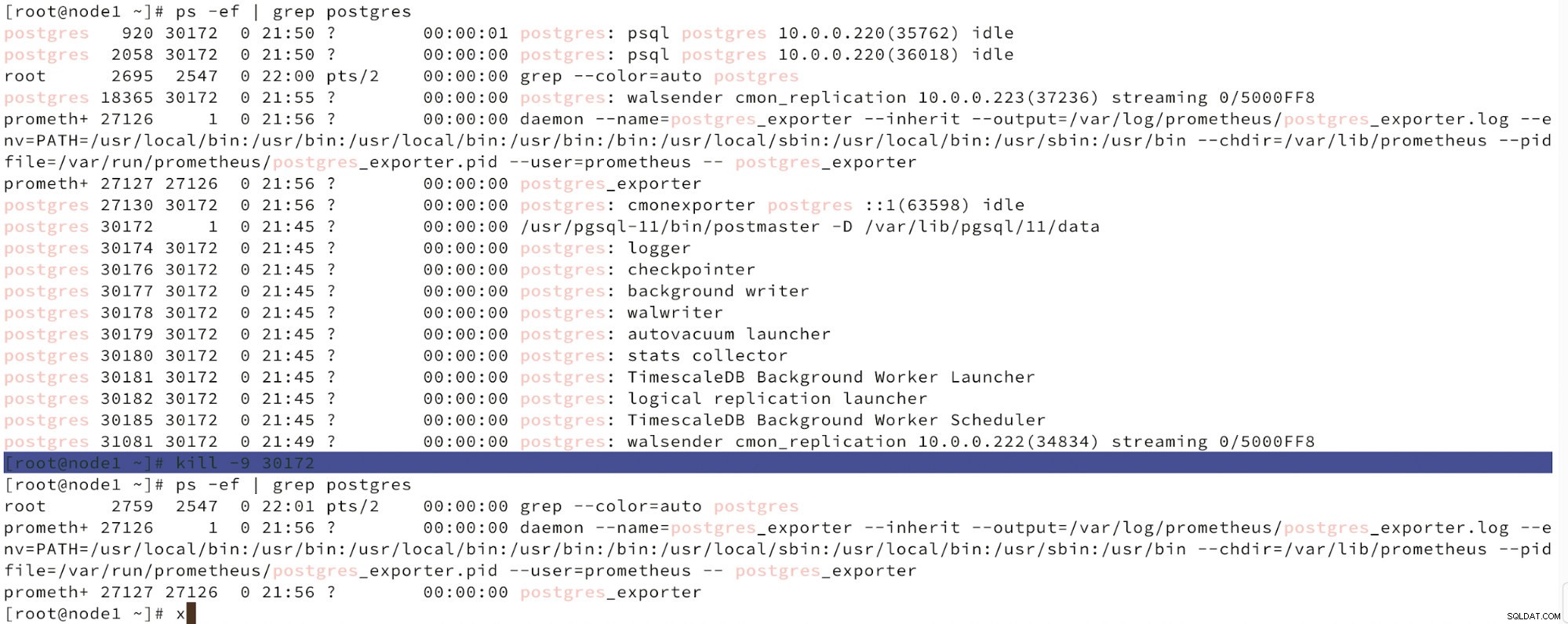 किल के साथ मास्टर नोड विफलता का अनुकरण करें
किल के साथ मास्टर नोड विफलता का अनुकरण करें जब नोड्स की खराबी का पता लगाया जाता है और ऑटो रिकवरी का पता लगाया जाता है तो ClusterControl फेलओवर करने के लिए कार्य को ट्रिगर करता है। नीचे हम क्लस्टर को पुनर्प्राप्त करने के लिए की गई कार्रवाइयों को देख सकते हैं।
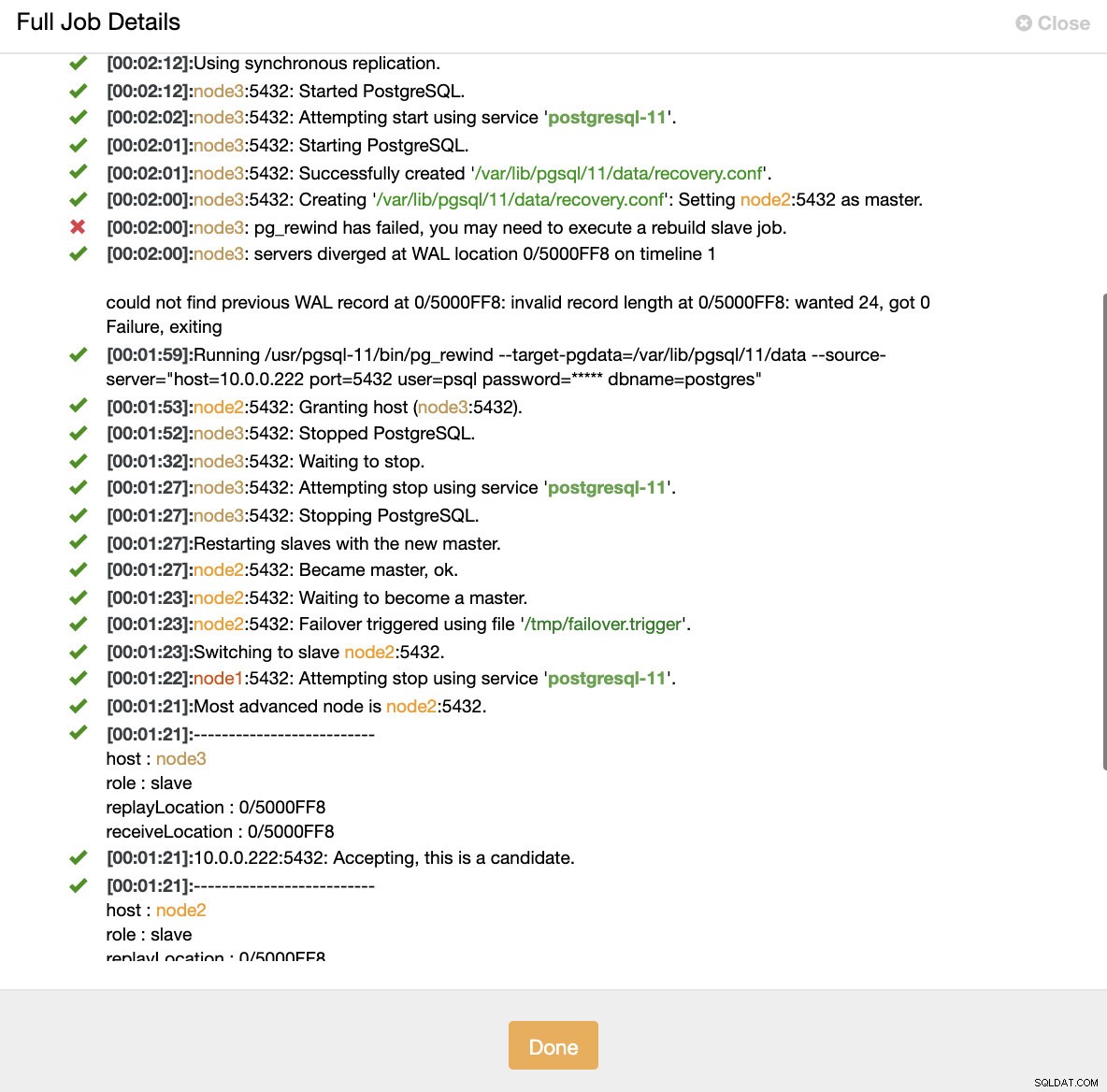 ClusterControl:क्लस्टर के पुनर्निर्माण के लिए कार्य ट्रिगर
ClusterControl:क्लस्टर के पुनर्निर्माण के लिए कार्य ट्रिगर ClusterControl जानबूझकर पुराने प्राथमिक को ऑफ़लाइन रखता है क्योंकि ऐसा हो सकता है कि कुछ डेटा स्टैंडबाय सर्वर पर स्थानांतरित नहीं किया गया हो। ऐसे मामले में, प्राथमिक ही एकमात्र होस्ट है जिसमें यह डेटा होता है और आप लापता डेटा को मैन्युअल रूप से पुनर्प्राप्त करना चाह सकते हैं। जो लोग विफल प्राथमिक को स्वचालित रूप से पुनर्निर्माण करना चाहते हैं, उनके लिए सीमोन कॉन्फ़िगरेशन फ़ाइल में एक विकल्प है:प्रतिकृति_ऑटो_रेबिल्ड_स्लेव। डिफ़ॉल्ट रूप से, यह अक्षम है, लेकिन जब उपयोगकर्ता इसे सक्षम करता है, तो विफल प्राथमिक को नए प्राथमिक के दास के रूप में फिर से बनाया जाएगा। बेशक, अगर कोई कमी डेटा है जो केवल विफल प्राथमिक पर मौजूद है, तो वह डेटा खो जाएगा।
स्टैंडबाय सर्वर का पुनर्निर्माण
अलग विशेषता "पुनर्निर्माण स्लेव" कार्य है जो प्रतिकृति सेटअप में सभी दासों (या स्टैंडबाय सर्वर) के लिए उपलब्ध है। उदाहरण के लिए इसका उपयोग तब किया जाता है जब आप स्टैंडबाय पर डेटा को साफ़ करना चाहते हैं और प्राथमिक के डेटा की एक नई प्रति के साथ इसे फिर से बनाना चाहते हैं। यह फायदेमंद हो सकता है अगर कोई स्टैंडबाय सर्वर किसी कारण से प्राथमिक से कनेक्ट और दोहराने में सक्षम नहीं है।
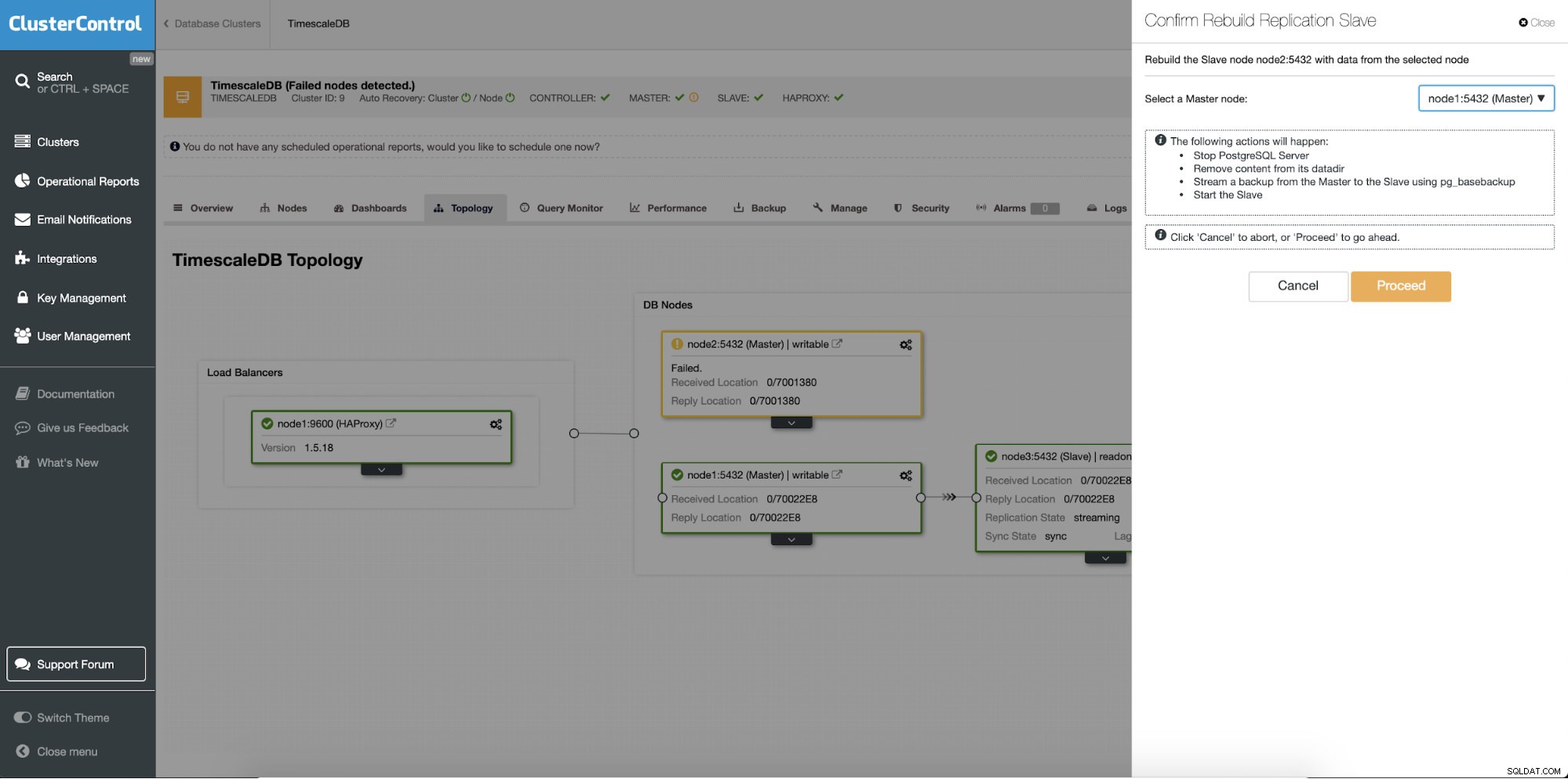 ClusterControl:प्रतिकृति स्लेव का पुनर्निर्माण करें
ClusterControl:प्रतिकृति स्लेव का पुनर्निर्माण करें 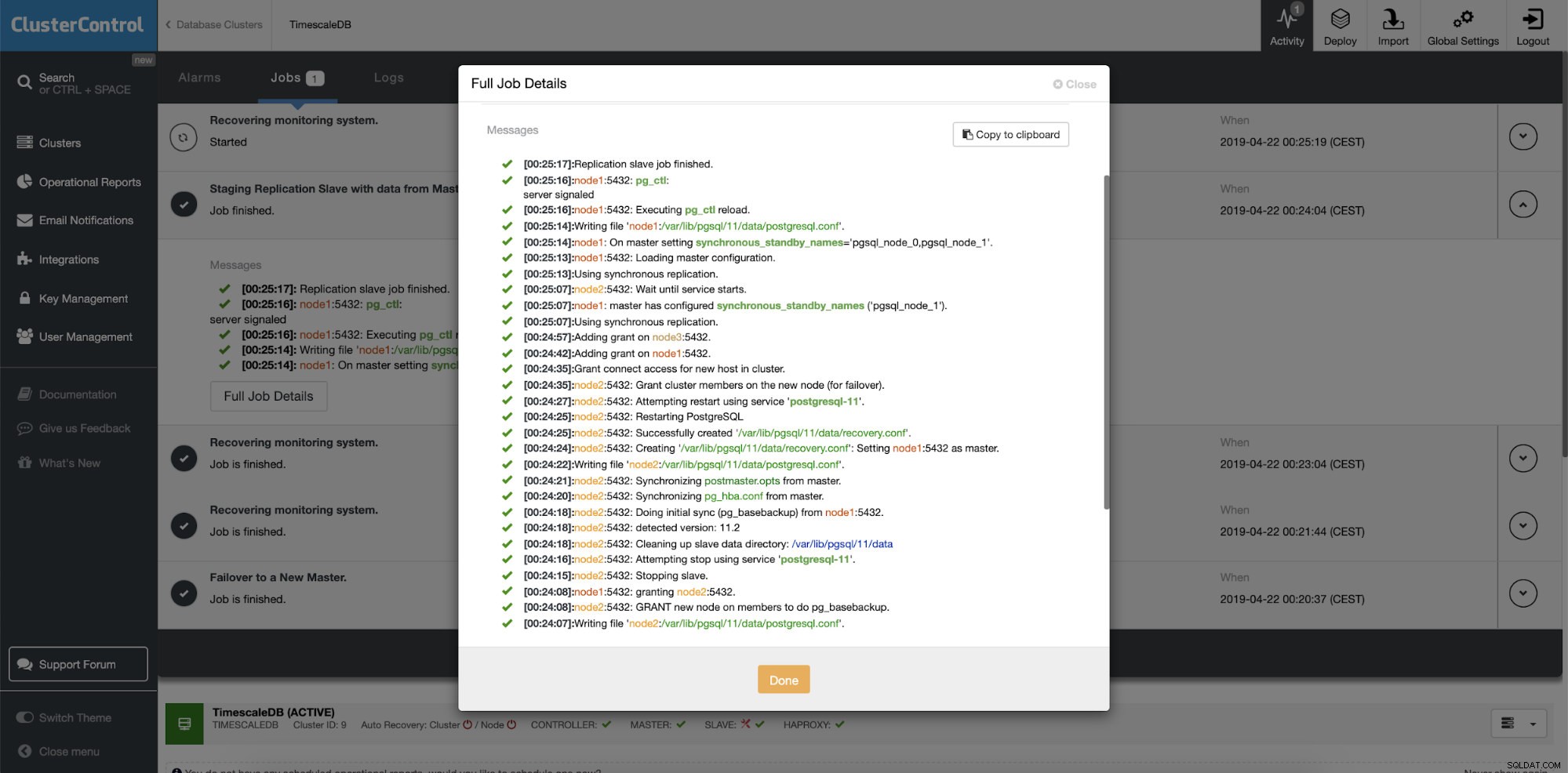 ClusterControl:रीबिल्ड स्लेव
ClusterControl:रीबिल्ड स्लेव