स्वस्थ और फिट रहना एक जीवनशैली है, सनक नहीं। जो लोग स्वास्थ्य के मूल्य का एहसास करते हैं, वे अपने फिटनेस से संबंधित सभी तथ्यों का रिकॉर्ड रखते हुए इसे प्राथमिकता देते हैं। इस लेख में, हम स्वास्थ्य और फिटनेस एप्लिकेशन के पीछे डेटाबेस के डिज़ाइन की जांच करेंगे।
ऐसे कई एप्लिकेशन हैं जो उपयोगकर्ताओं को उनके स्वास्थ्य और फिटनेस की जानकारी लॉग करने देते हैं। Apple, Google और Microsoft जैसे कुछ बड़े खिलाड़ियों ने विशेष रूप से इस बाज़ार के लिए अपने स्वयं के विकास API लॉन्च किए हैं। उदाहरण के लिए, Google के पास 'Fit' है और Microsoft के पास 'HealthVault' है।
इस लेख में, मैं स्वास्थ्य रिकॉर्ड एप्लिकेशन के पीछे डेटा मॉडल की व्याख्या करूंगा। सबसे पहले, आइए चर्चा करें कि हम इस तरह के ऐप से क्या उम्मीद करते हैं।
स्वास्थ्य जानकारी ऐप के लिए परियोजना आवश्यकताएँ
नीचे कुछ विशेषताएं दी गई हैं जिनका एक स्वास्थ्य जानकारी ऐप को समर्थन करना चाहिए:
- उपयोगकर्ता एक खाता बना सकते हैं और कई प्रोफाइल के लिए स्वास्थ्य जानकारी संग्रहीत कर सकते हैं, यानी एक व्यक्ति अपने परिवार के सभी सदस्यों के लिए स्वास्थ्य जानकारी संग्रहीत कर सकता है।
- उपयोगकर्ता अपने संपूर्ण स्वास्थ्य इतिहास को रिकॉर्ड कर सकते हैं, जिसमें टीकाकरण, पिछले प्रयोगशाला परिणाम, एलर्जी, और पारिवारिक चिकित्सा इतिहास शामिल हैं। ।
- उपयोगकर्ता स्वास्थ्य और फिटनेस के विभिन्न मापों को संग्रहीत कर सकते हैं, जैसे रक्त शर्करा (रक्त शर्करा) के स्तर, रक्तचाप, शरीर की संरचना और बॉडी मास इंडेक्स (बीएमआई), कोलेस्ट्रॉल, ऊंचाई, वजन, प्रजनन स्वास्थ्य, आदि सहित आयाम। ली>
- जानकारी को विभिन्न विधियों और माप की इकाइयों का उपयोग करके रिकॉर्ड किया जा सकता है . उदाहरण के तौर पर, रक्त शर्करा को mg/dL या mmol/L में मापा जा सकता है।
- उपयोगकर्ता कितनी जानकारी स्टोर कर सकते हैं, इसकी कोई सीमा नहीं है।
- सिस्टम स्वीकृत स्वास्थ्य मानकों को भी बनाए रखेगा, जैसे रक्तचाप या बीएमआई नंबर, और उपयोगकर्ताओं को सतर्क करेगा यदि उनकी संख्या "सुरक्षित" या "सामान्य" सीमा से बाहर है।
- उपयोगकर्ता अपने व्यक्तिगत डैशबोर्ड पर प्रदर्शित करने के लिए जानकारी (जैसे रक्त ग्लूकोज, ऊंचाई, वजन, आदि) भी चुन सकते हैं। इस तरह, वे अपनी ज़रूरत की हर चीज़ पर नज़र रख सकते हैं।
डेटा मॉडल में प्रत्येक अनुभाग और तालिका क्या करती है, यह स्पष्ट करने के बजाय, आइए इसके बारे में कुछ प्रश्नों के उत्तर दें। जैसे-जैसे हम आगे बढ़ेंगे, विभिन्न तालिकाओं का कार्य स्पष्ट होता जाएगा।
यदि आप चाहें तो सबसे पहले, आप संपूर्ण डेटा मॉडल देख सकते हैं।
डेटा मॉडल
स्वास्थ्य जानकारी डेटा मॉडल के बारे में सवालों के जवाब देना
उपयोगकर्ता अपने परिवार के सभी सदस्यों के लिए व्यक्तिगत रूप से स्वास्थ्य जानकारी कैसे संग्रहीत कर सकते हैं?
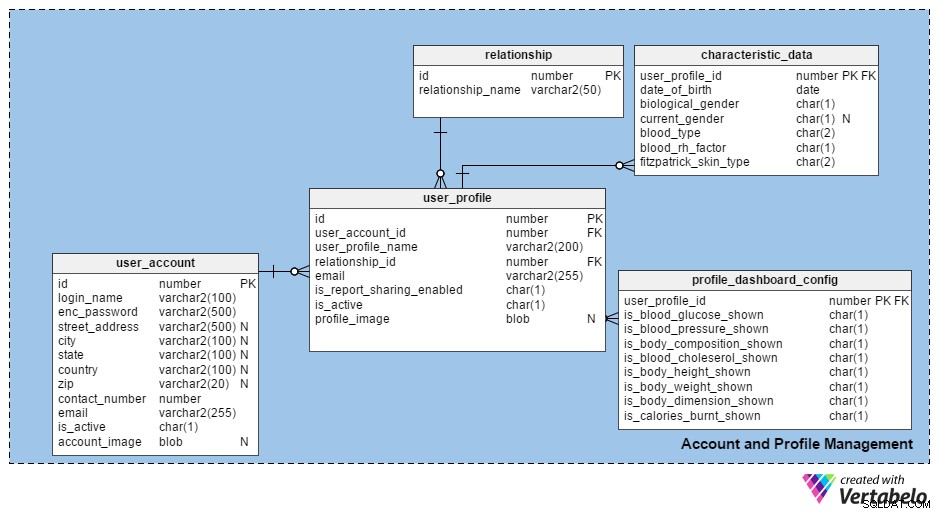
सबसे पहले, खाता और प्रोफ़ाइल प्रबंधन के बारे में बात करते हैं . यह दो अलग-अलग तालिकाओं के द्वारा प्राप्त किया जा सकता है; एक (user_account ) आवेदन के साथ पंजीकरण करने वाले लोगों के विवरण दर्ज करने के लिए, और एक (user_profile ) एक पंजीकृत उपयोगकर्ता द्वारा बनाए गए सभी विभिन्न प्रोफाइल के विवरण लॉगिंग के लिए। लोग कई प्रोफाइल बना सकते हैं - उदा। उनके परिवार के प्रत्येक सदस्य के लिए एक।
आइए विभिन्न तालिकाओं को देखें जो इसे संभव बनाती हैं।
user_account तालिका में आवेदन के साथ पंजीकरण करने वाले व्यक्ति के बारे में बुनियादी विवरण हैं। इसके स्तंभ हैं:
id-इस तालिका के लिए एक सरोगेट कुंजी कॉलम जो प्रत्येक उपयोगकर्ता को विशिष्ट रूप से पहचानता है।login_name- वह नाम या अन्य आईडी जिसे उपयोगकर्ता अपने लॉगिन नाम के रूप में चुनता है। यह सुनिश्चित करने के लिए कि प्रत्येक लॉगिन नाम अलग है, इस कॉलम पर एक अद्वितीय बाधा लगाई जानी चाहिए।enc_password- उपयोगकर्ता द्वारा चयनित खाता पासवर्ड, एन्क्रिप्टेड रूप में।- पता कॉलम - पंजीकरण के समय उपयोगकर्ताओं के लिए पता और संपर्क विवरण स्टोर करें। इन स्तंभों में शामिल हैं
street_address,city,state,country, औरzip. चूंकि ये फ़ील्ड पंजीकरण प्रक्रिया में वैकल्पिक हैं, इसलिए मैंने इन स्तंभों को शून्य के रूप में रखा है। contact_numberऔरemail- उपयोगकर्ता के संपर्क नंबर (यानी फोन नंबर) और उनके ईमेल पते को स्टोर करता है। ये फ़ील्ड भी पंजीकरण प्रक्रिया का हिस्सा हैं, लेकिन वे अशक्त नहीं हैं।is_active- यह इंगित करने के लिए कि कोई खाता वर्तमान में सक्रिय है या नहीं, 'Y' या 'N' धारण करता है।account_image- उपयोगकर्ताओं को अपनी छवियों को अपलोड करने की अनुमति है। चूंकि एक उपयोगकर्ता प्रति खाता शून्य या (अधिकतम) एक छवि अपलोड कर सकता है, यह एक अशक्त बीएलओबी-प्रकार का कॉलम है।
user_profile तालिका पंजीकृत उपयोगकर्ताओं द्वारा बनाई गई सभी प्रोफाइलों का विवरण संग्रहीत करती है। इस तालिका में कॉलम हैं:
id- प्रत्येक नई प्रोफ़ाइल को एक विशिष्ट संख्या दी गई है।user_account_id- यह दर्शाता है कि किस उपयोगकर्ता ने प्रोफ़ाइल बनाई है।user_profile_name- प्रोफाइल में व्यक्ति का नाम स्टोर करता है। (हम इस व्यक्ति को "प्रोफ़ाइल व्यक्ति" और प्रोफ़ाइल बनाने वाले उपयोगकर्ता को "खाता धारक" कहेंगे।)relationship_id- खाताधारक और प्रोफ़ाइल व्यक्ति के बीच संबंध को इंगित करता है। यह कॉलमrelationshipतालिका, जिसमें सभी संभावित प्रकार के संबंध होते हैं (जैसे स्वयं , माँ , पिता , बहन , भाई , बेटा , बेटी , पालतू , आदि)।email- इस कॉलम में प्रोफ़ाइल व्यक्ति का ईमेल पता होता है। रिपोर्ट या अन्य जानकारी उनके साथ इस ईमेल के माध्यम से साझा की जाएगी; खाताधारक को भी जानकारी भेजी जाएगी। उदाहरण के लिए, यदि मेलिसा ने अपनी बेटी ईवा के लिए एक प्रोफ़ाइल बनाई है, तो ईवा की जानकारी मेलिसा के ईमेल और संभवतः ईवा के ईमेल पर भेजी जाएगी - नीचे देखें।is_report_sharing_enabled- रिपोर्ट हमेशा खाताधारक के साथ साझा की जाती है, लेकिन इस डेटा को प्रोफ़ाइल व्यक्ति के साथ साझा करना वैकल्पिक है। यह कॉलम दिखाता है कि प्रोफ़ाइल व्यक्ति के साथ जानकारी साझा की जाएगी या नहीं।is_active- पहचानता है कि कोई प्रोफ़ाइल वर्तमान में सक्रिय है या नहीं। यदि प्रोफ़ाइल गलती से हटा दी जाती है तो यह एक सॉफ्ट डिलीट फ़ंक्शन है।profile_image- प्रोफ़ाइल व्यक्ति की एक छवि संग्रहीत करता है। यह विशेषता वैकल्पिक है और इस प्रकार निरर्थक है।
characteristic_data तालिका में व्यक्तिगत प्रोफ़ाइल विवरण (जैसे रक्त समूह) होते हैं जो समय के साथ कभी नहीं बदलते हैं। fitzpatrick_skin_type को छोड़कर इस तालिका के सभी कॉलम स्व-व्याख्यात्मक हैं , जो किसी की त्वचा की प्रकृति को I से शुरू करता है (हमेशा जलता है, कभी तन नहीं) VI (कभी नहीं जलता, तन होने पर उपस्थिति में कोई बदलाव नहीं)।
मैंने लिंग के लिए दो कॉलम जोड़े हैं; biological_gender जन्म के समय किसी के लिंग को दर्शाता है, और current_gender प्रोफ़ाइल व्यक्ति के वर्तमान लिंग को दर्शाता है। यह दूसरा कॉलम केवल ट्रांसजेंडर लोगों पर लागू होता है, और इसलिए मैंने इसे निरर्थक रखा है।
इस सिस्टम में कौन-सी महत्वपूर्ण जानकारी संग्रहीत की जा सकती है? इसे कैसे स्टोर किया जाता है?
अब हम स्वास्थ्य डेटा प्रबंधन की ओर बढ़ रहे हैं . शरीर की संरचना, रक्त शर्करा का स्तर और शरीर के आयाम अलग-अलग तालिकाओं में संग्रहीत होते हैं। हालांकि लोग एक समय में एक से अधिक प्रकार की जानकारी दर्ज कर सकते हैं, इसलिए हम body_vitals_log एक प्रोफ़ाइल में कौन सी जानकारी लॉग की गई है और कब दर्ज की गई है, इसका ट्रैक रखने के लिए तालिका।

सभी महत्वपूर्ण आँकड़े निम्न तालिकाओं में रखे गए हैं:
body_composition- विभिन्न शरीर संरचना प्रतिशत जैसे वसा, दुबला द्रव्यमान, हड्डी, या पानी के बारे में विवरण संग्रहीत करता है। यह व्यक्तियों के लिए बीएमआई (बॉडी मास इंडेक्स) मान भी रखता है।blood_cholesterol- एलडीएल, एचडीएल, ट्राइग्लिसराइड्स, और कुल जैसे कोलेस्ट्रॉल विवरण रखता है।body_dimension- शरीर के विभिन्न क्षेत्रों के आयामों को रिकॉर्ड करता है, जैसे कि कमर या छाती का माप।body_weight- शरीर के वजन के लिए मूल्यों को स्टोर करता है।body_height- किसी व्यक्ति की ऊंचाई के लिए मान रखता है।blood_pressure- ब्लड प्रेशर नंबर (सिस्टोलिक और डायस्टोलिक) रखता है।blood_glucose- रक्त शर्करा के स्तर को रिकॉर्ड करता है।
कुछ अपवादों के साथ, उपरोक्त तालिकाओं के अधिकांश स्तंभ स्व-व्याख्यात्मक हैं। आपको कुछ अतिरिक्त कॉलम दिखाई देंगे जैसे measurement_method_id , compare_to_normal_id , measurement_unit_id और measurement_context इनमें से लगभग हर एक टेबल में। मैं इन स्तंभों के बारे में बाद में बताऊंगा।
body_vitals_log किसी प्रोफ़ाइल के लिए दिए गए समय में कौन सी जानकारी लॉग की जाती है, इसका ट्रैक रखता है। इस तालिका में कॉलम हैं:
user_profile_id- दिखाता है कि कौन सी प्रोफ़ाइल जानकारी दर्ज कर रही है।dt_created- जानकारी दर्ज करने की तारीख और समय को स्टोर करता है।data_source_id- डेटा के स्रोत को दर्शाता है, जैसे मैनुअल, इलेक्ट्रॉनिक उपकरण, आदि।- मैंविभिन्न महत्वपूर्ण आंकड़ों के डी.एस. - मैंने इन सभी कॉलमों को अशक्त रखा है, क्योंकि उपयोगकर्ताओं को एक समय में एक या अधिक आइटम लॉग करने की अनुमति है। सभी उपयोगकर्ता समान स्वास्थ्य आँकड़ों को ट्रैक नहीं करना चाहेंगे।
हम सिस्टम को विभिन्न क्षेत्रों में कैसे काम कर सकते हैं?
कुछ सूचनाओं को विभिन्न क्षेत्रों में विभिन्न इकाइयों में मापा जाता है। उदाहरण के लिए, एशिया में शरीर का वजन किलोग्राम में मापा जाता है, लेकिन उत्तरी अमेरिका में इसे पाउंड में मापा जाता है। इसलिए इसे हमारे डेटाबेस में काम करने योग्य बनाने के लिए, हमें मापने की इकाइयों को ट्रैक करने के लिए एक तरीके की आवश्यकता है।
id- इस तालिका की प्राथमिक कुंजी के रूप में कार्य करता है, और यह वही है जिसे अन्य तालिकाएं संदर्भित करती हैं।measurement_parameter- एक इकाई द्वारा मापी जाने वाली महत्वपूर्ण जानकारी (जैसे वजन, ऊंचाई, रक्तचाप, आदि) के प्रकार को दर्शाता है।unit_name- यूनिट का नाम स्टोर करता है। वजन के लिए किलोग्राम और पाउंड, रक्त शर्करा के लिए mg/dL और mmol/L के बारे में सोचें।
लोगों को कैसे पता चलेगा कि उनकी संख्या अच्छी है?
जब तक यह लोगों को स्वास्थ्य जोखिमों या कमजोरियों के प्रति सचेत नहीं करता, तब तक हमारी प्रणाली बहुत मददगार नहीं है। हम comparison_to_normal_id . जोड़कर इस फ़ंक्शन को सक्षम करते हैं सभी महत्वपूर्ण सूचना डेटा तालिकाओं में कॉलम।
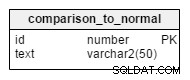
जब कोई नई महत्वपूर्ण जानकारी सिस्टम में लॉग इन की जाती है, तो रिकॉर्ड की तुलना उनके संबंधित बेंचमार्क मूल्यों के साथ की जाएगी और इस कॉलम को तदनुसार सेट किया जाएगा।
इस तालिका के संभावित मान हैं:
| मैं | पाठ |
|---|---|
| 1 | पता नहीं |
| 2 | बहुत कम |
| 3 | निचला |
| 4 | सामान्य |
| 5 | उच्चतर |
| 6 | बहुत अधिक |
क्या उपयोगकर्ता रिकॉर्ड कर सकते हैं जब माप लिया गया था?
उदाहरण के लिए, उपयोगकर्ताओं को यह बताने की आवश्यकता हो सकती है कि उनके रक्त शर्करा को कब मापा गया - यानी भोजन से पहले या बाद में। या वे व्यायाम करने से पहले और बाद में खुद को तौल सकते हैं और परिणाम रिकॉर्ड कर सकते हैं। इसे सुविधाजनक बनाने के लिए, मैंने एक कॉलम जोड़ा है, measurement_context , महत्वपूर्ण सूचना तालिकाओं में जिन्हें प्रासंगिक जानकारी की आवश्यकता हो सकती है। इस कॉलम के लिए कुछ संभावित मान नीचे दिखाए गए हैं:
| नाश्ते से पहले |
| नाश्ते के बाद |
| दोपहर के भोजन से पहले |
| दोपहर के भोजन के बाद |
| रात्रिभोज से पहले |
| रात के खाने के बाद |
| व्यायाम से पहले |
| व्यायाम के बाद |
| उपवास |
| गैर-उपवास |
| भोजन के बाद |
| भोजन से पहले |
| सोने से पहले |
क्या होगा यदि कोई व्यक्ति मधुमेह रोगी है और उसे अपने रक्त शर्करा के स्तर की निगरानी करने की आवश्यकता है?
मैं जिस प्रणाली का प्रस्ताव कर रहा हूं उसमें एक डैशबोर्ड होगा जो ग्राफिकल प्रारूप में महत्वपूर्ण आंकड़े प्रदर्शित कर सकता है। उपयोगकर्ताओं को यह चुनने की अनुमति है कि वे अपने प्रोफ़ाइल डैशबोर्ड पर क्या देखना चाहते हैं, और प्रत्येक प्रोफ़ाइल का अपना डैशबोर्ड होता है। खाताधारकों को उनके द्वारा बनाए गए सभी प्रोफ़ाइल डैशबोर्ड देखने की अनुमति है।
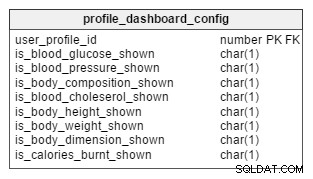
मैंने प्रत्येक पैरामीटर के लिए एक CHAR(1) कॉलम जोड़ा है जिसे डैशबोर्ड पर दिखाया जा सकता है। जब कोई नई प्रोफ़ाइल बनाई जाती है, तो डिफ़ॉल्ट रूप से, सभी कॉलम 'N' (डिस्प्ले बंद हो जाता है) से भर जाएंगे। उपयोगकर्ता बाद में ऐप के उपयोगकर्ता इंटरफ़ेस में एक विकल्प से अपने डैशबोर्ड कॉन्फ़िगरेशन को संशोधित कर सकते हैं।
यह सिस्टम लोगों को फिट रहने में कैसे मदद करता है?
दूसरे शब्दों में, हम बात कर रहे हैं फिटनेस डेटा संग्रहण . स्वास्थ्य संबंधी जानकारी के अलावा, सिस्टम उनके उपयोगकर्ताओं को उनकी फिटनेस और व्यायाम दिनचर्या के बारे में जानकारी लॉग करने की भी अनुमति देता है।
activity_log तालिका इस विषय क्षेत्र में मुख्य तालिका है। यह प्रत्येक प्रकार की गतिविधि प्रोफ़ाइल व्यक्तियों के प्रदर्शन के बारे में विवरण प्राप्त करता है।
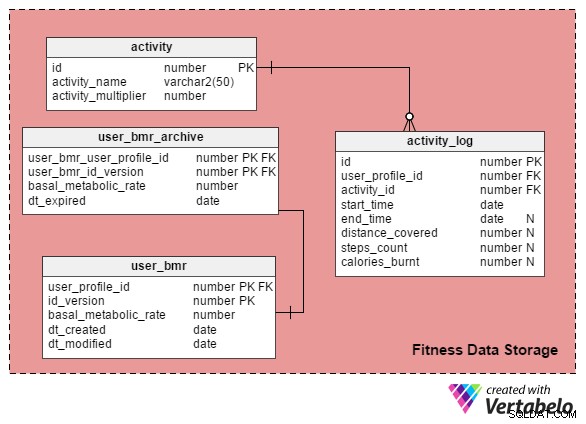
प्रत्येक गतिविधि को निम्नलिखित तीन मापदंडों में से एक या अधिक द्वारा मापा जा सकता है:
- आरंभ और समाप्ति समय - खेल या खेल खेलना, कतार में खड़े होना आदि गतिविधियों को प्रारंभ और समाप्ति समय के संदर्भ में मापा जाता है। यह
start_time. के माध्यम से किया जाता है औरend_timeactivity_log। - दूरी तय की गई है - दौड़ने या साइकिल चलाने जैसी गतिविधियों को तय की गई दूरी के संदर्भ में मापा जाता है। इसे
distance_covered. में स्टोर किया जाता है कॉलम। - चरणों की संख्या - चलने जैसी गतिविधियों को चरणों की संख्या के आधार पर मापा जाता है, और मानों को
steps_countमें संग्रहीत किया जाता है कॉलम।
आप सोच रहे होंगे कि calories_burnt क्यों कॉलम activity_log टेबल। जैसा कि इसके नाम से पता चलता है, यह कॉलम किसी विशेष गतिविधि को करते समय प्रोफ़ाइल व्यक्ति द्वारा जलाई गई कैलोरी का मान रखता है। मैं समझाऊंगा कि हम बाद के अनुभाग में इन मानों की गणना कैसे कर सकते हैं।
मैंने activity सभी संभावित गतिविधियों की एक सूची रखने के लिए। इस तालिका में कॉलम हैं:
id- प्रत्येक गतिविधि के लिए एक विशिष्ट आईडी नंबर निर्दिष्ट करता है।activity_name- स्टोर गतिविधि के नाम।activity_multiplier- यह कॉलम गतिविधियों में लगे लोगों द्वारा बर्न की गई कैलोरी की संख्या की गणना करने में महत्वपूर्ण भूमिका निभाता है।
आप प्रत्येक गतिविधि के लिए बर्न की गई कैलोरी की गणना कैसे करते हैं?
यह समझने के लिए कि कैलोरी बर्न की गणना कैसे की जाती है, हमें सबसे पहले किसी व्यक्ति के बीएमआर, या बेसल मेटाबॉलिक रेट को समझना होगा। इससे हमें पता चलता है कि आराम करने पर शरीर कितनी कैलोरी बर्न करता है। प्रत्येक व्यक्ति का बीएमआर उनके लिंग, उम्र, वजन और ऊंचाई पर निर्भर करता है। डेटा मॉडलिंग के दृष्टिकोण से, BMR एक धीरे-धीरे बदलने वाला आयाम है, और इस तरह यह समय के साथ बदलता रहता है। हम नवीनतम व्यक्तिगत बीएमआर मानों को user_bmr टेबल।
बीएमआर मूल्यों की गणना के लिए विभिन्न तरीकों का इस्तेमाल किया जाता है:
विधि# 1:हैरिस-बेनेडिक्ट विधि
BMR पुरुष:66 + (6.23 X वजन पाउंड में) + (12.7 X ऊंचाई इंच में) - (6.8 X आयु)
BMR महिला:655 + (पाउंड में 4.35 X वजन) + (4.7 X ऊंचाई इंच में) - (4.7 X आयु)
विधि# 2:कैच-मैकआर्डल विधि
BMR (पुरुष + महिला):370 + (21.6 * दुबला द्रव्यमान किलोग्राम में)
दुबला द्रव्यमान =किलोग्राम में वजन - (किलोग्राम में वजन * शरीर में वसा%)
हम किसी व्यक्ति के बीएमआर और ऊपर बताए गए गतिविधि गुणक का उपयोग यह पता लगाने के लिए कर सकते हैं कि दी गई गतिविधि करते समय एक व्यक्ति कितनी कैलोरी बर्न करता है। सूत्र है:
कैलोरी बर्न =गतिविधि गुणक * BMR
नोट:उपरोक्त दोनों बीएमआर गणना विधियां गतिविधियों के लिए समान गुणक मानों का उपयोग करती हैं। अधिक जानकारी के लिए, इस लेख को देखें।
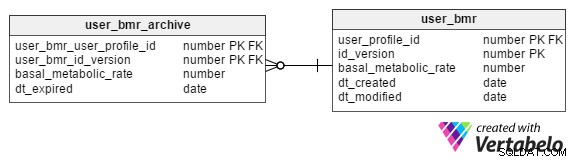
क्या हम प्रोफ़ाइल के ऐतिहासिक BMR मान रख सकते हैं?
हां। हम BMR मानों को user_bmr_archive टेबल।
हम एक कॉलम जोड़कर शुरू करते हैं, id_version , मौजूदा user_bmr टेबल। जब भी किसी प्रोफ़ाइल व्यक्ति का BMR मान अपडेट किया जाता है, तो हम इस मान को 1 से बढ़ाते रहते हैं।
user_bmr_archive तालिका लगभग user_bmr टेबल। फर्क सिर्फ इतना है कि इसमें एक dt_expired . है dt_created . के बजाय कॉलम और dt_modified स्तंभ। dt_expired कॉलम उस तारीख को संग्रहीत करता है जब संस्करण अमान्य हो गया था, यानी जब बीएमआर मान user_bmr ।
क्या होगा यदि उपयोगकर्ता अपने टीकाकरण, पारिवारिक चिकित्सा इतिहास और एलर्जी का रिकॉर्ड रखना चाहते हैं?
उपयोगकर्ताओं को अतिरिक्त स्वास्थ्य जानकारी संग्रहीत करने की क्षमता प्रदान करने के लिए यह प्रणाली निम्नलिखित तालिकाओं का लाभ उठाती है।
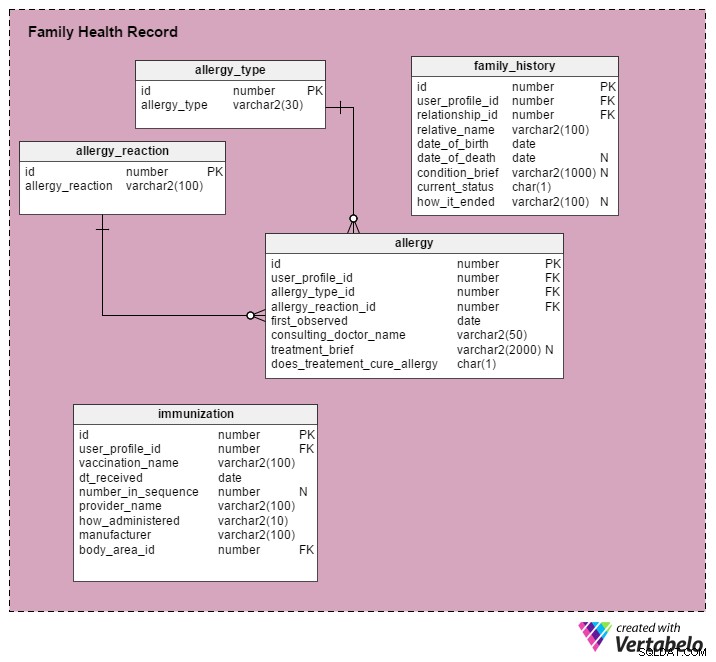
immunization टेबल प्रोफाइल लोगों द्वारा प्राप्त टीकाकरण के बारे में विवरण संग्रहीत करता है। उदाहरण के बाद, आप इस तालिका में शामिल स्तंभों का संक्षिप्त विवरण देखेंगे:
उदाहरण - जॉन सू को हेपेटाइटिस बी के टीके की तीन में से दूसरी खुराक मिली। यह 28 नवंबर 2016 को डॉ डेविड मूर द्वारा प्रशासित किया गया था। टीकाकरण बाएं हाथ में एक इंजेक्शन द्वारा दिया गया था। यह सिप्ला (एक दवा कंपनी) द्वारा निर्मित है।
id- इस तालिका की प्राथमिक कुंजीuser_profile_id-user_profile_IDको संदर्भित करता है जॉन सू कीvaccination_name- "हेपेटाइटिस बी"dt_received- "28 नवंबर 2016"number_in_sequence- "02"body_area_id- बाएं हाथ की आईडी,body_areaटेबलprovider_name- "डॉ। डेविड मूर”how_administered- "इंजेक्शन" (अन्य संभावित मूल्यों में नेज़ल स्प्रे, टैबलेट, ड्रॉप्स, सिरप शामिल हैं )manufacturer- "सिप्ला"
allergy टेबल प्रोफाइल व्यक्तियों द्वारा अनुभव की गई किसी भी एलर्जी के बारे में विवरण संग्रहीत करता है। उदाहरण के अनुसार प्रत्येक के लिए दिए गए प्रासंगिक मानों के साथ कॉलम की सूची नीचे दी गई है:
उदाहरण - एलिसन डिसूजा को दही खाने पर खांसी होती है। पहली बार उन्हें यह प्रतिक्रिया तब हुई जब वह 8 साल की थीं। वह डॉ. बिल स्मिथ से सलाह लेती हैं, जो कुछ दवाएं लिखते हैं और कुछ सावधानियों की सलाह देते हैं। यह एलर्जी अभी भी बनी हुई है, लेकिन इसकी तीव्रता अब कम है।
id– तालिका की प्राथमिक कुंजीuser_profile_id- R का अर्थuser_profile_idसे है एलिसन डिसूजा कीallergy_type_id-allergy_typeटेबल। (allergy_typeतालिका विभिन्न प्रकार की एलर्जी को परिभाषित करती है जैसे भोजन, दवा, पर्यावरण, पशु, पौधे, आदि)allergy_reaction_id-allergy_reactionटेबल.first_observed- वह तारीख जब यह प्रतिक्रिया पहली बार देखी गई थी, यानी जब एलिसन 8 साल की थी।consulting_doctor_name- "डॉ। बिल स्मिथ”treatment_brief- निर्धारित दवाओं और अनुशंसित सावधानियों का संक्षिप्त विवरण।does_treatment_cure_allergy- "आंशिक रूप से ठीक हो गया। प्रतिक्रिया की तीव्रता कम हो गई।"
family_history तालिका उपयोगकर्ताओं के चिकित्सा परिवार के इतिहास के बारे में विवरण संग्रहीत करती है। फिर से, हमने निम्नलिखित उदाहरण के आधार पर कॉलम और उनमें संग्रहीत की जाने वाली जानकारी के प्रकार को सूचीबद्ध किया है।
उदाहरण - डायना की मां लिसा को पार्किंसन रोग (एक तंत्रिका संबंधी विकार) है। उसका इलाज चल रहा है, लेकिन कोई ठोस सुधार नहीं हुआ है।
id- तालिका की प्राथमिक कुंजीuser_profile_id- डायना काuser_profile_IDuser_profileटेबलRelationship_id-relationshipटेबलRelative_name- "लिसा"Date_of_birth- लिसा की जन्म तिथिDate_of_death- NULL (लिसा अभी भी जीवित है, और बीमारी के खिलाफ कड़ा संघर्ष कर रही है।)Condition_brief- कैसे, कब और कहां से स्थिति शुरू हुई, परामर्श, कोई राहत, आदि का संक्षिप्त विवरण।Current_status- 'वर्तमान' (अन्य संभावित स्थितियां 'आंतरायिक' और 'अतीत' हैं।)How_it_ended- नल
आप इस डेटा मॉडल में क्या जोड़ेंगे?
यह प्रणाली लोगों को यह बताती है कि विभिन्न गतिविधियों को करते समय वे कितनी कैलोरी बर्न करते हैं, लेकिन यह ट्रैक नहीं करता कि वे कितनी कैलोरी का उपभोग करते हैं, या उनके भोजन के विकल्प कितने पौष्टिक हैं। साथ ही, सिस्टम उन्हें अपने फिटनेस डेटा को दैनिक आधार पर रिकॉर्ड करने की अनुमति देता है, लेकिन यह उन्हें एक लक्ष्य निर्धारित करने, एक योजना तैयार करने और उनकी प्रगति को ट्रैक करने की अनुमति नहीं देता है ताकि वे प्रेरित रहें।
क्या हमें इन सुविधाओं को इसमें शामिल करने पर विचार करना चाहिए? इन सुविधाओं को जोड़ने के लिए क्या बदलाव करने होंगे?
हमें अपने विचार बताएं!



