इस ब्लॉग पोस्ट में, हम MySQL के लिए Percona सर्वर की निगरानी करते समय कुछ प्रमुख मेट्रिक्स और स्थिति पर गौर करने जा रहे हैं ताकि हमें लंबे समय तक MySQL सर्वर कॉन्फ़िगरेशन को ठीक करने में मदद मिल सके। केवल सिर के लिए, पेरकोना सर्वर में कुछ निगरानी मेट्रिक्स हैं जो केवल इस निर्माण पर उपलब्ध हैं। संस्करण 8.0.20 पर तुलना करते समय, निम्नलिखित 51 स्थितियां केवल MySQL के लिए Percona सर्वर पर उपलब्ध हैं, जो अपस्ट्रीम Oracle के MySQL समुदाय सर्वर में उपलब्ध नहीं हैं:
- Binlog_snapshot_file
- Binlog_snapshot_position
- Binlog_snapshot_gtid_executed
- Com_create_compression_dictionary
- Com_drop_compression_dictionary
- Com_lock_tables_for_backup
- Com_show_client_statistics
- Com_show_index_statistics
- Com_show_table_statistics
- Com_show_thread_statistics
- Com_show_user_statistics
- Innodb_background_log_sync
- Innodb_buffer_pool_pages_LRU_flushed
- Innodb_buffer_pool_pages_made_not_young
- Innodb_buffer_pool_pages_made_young
- Innodb_buffer_pool_pages_old
- Innodb_checkpoint_age
- Innodb_ibuf_free_list
- Innodb_ibuf_segment_size
- Innodb_lsn_current
- Innodb_lsn_flushed
- Innodb_lsn_last_checkpoint
- Innodb_master_thread_active_loops
- Innodb_master_thread_idle_loops
- Innodb_max_trx_id
- Innodb_oldest_view_low_limit_trx_id
- Innodb_pages0_read
- Innodb_purge_trx_id
- Innodb_purge_undo_no
- Innodb_secondary_index_triggered_cluster_reads
- Innodb_secondary_index_triggered_cluster_reads_avoided
- Innodb_buffered_aio_submitted
- Innodb_scan_pages_contiguous
- Innodb_scan_pages_disjointed
- Innodb_scan_pages_total_seek_distance
- Innodb_scan_data_size
- Innodb_scan_deleted_recs_size
- Innodb_scrub_log
- Innodb_scrub_background_page_reorganizations
- Innodb_scrub_background_page_splits
- Innodb_scrub_background_page_split_failures_underflow
- Innodb_scrub_background_page_split_failures_out_of_filespace
- Innodb_scrub_background_page_split_failures_missing_index
- Innodb_scrub_background_page_split_failures_unknown
- Innodb_encryption_n_merge_blocks_encrypted
- Innodb_encryption_n_merge_blocks_decrypted
- Innodb_encryption_n_rowlog_blocks_encrypted
- Innodb_encryption_n_rowlog_blocks_decrypted
- Innodb_encryption_redo_key_version
- थ्रेडपूल_आइडल_थ्रेड्स
- थ्रेडपूल_थ्रेड्स
ऊपर दिए गए प्रत्येक मॉनिटरिंग मेट्रिक्स के बारे में अधिक जानकारी के लिए विस्तृत InnoDB स्थिति पृष्ठ देखें। ध्यान दें कि थ्रेड पूल जैसी कुछ अतिरिक्त स्थिति केवल Oracle के MySQL एंटरप्राइज़ में उपलब्ध है। Oracle के MySQL कम्युनिटी सर्वर 8.0 पर इस बिल्ड के लिए विशेष रूप से सभी सुधारों को देखने के लिए MySQL 8.0 दस्तावेज़ के लिए Percona सर्वर देखें।
MySQL वैश्विक स्थिति को पुनः प्राप्त करने के लिए, बस निम्नलिखित कथनों में से एक का उपयोग करें:
mysql> SHOW GLOBAL STATUS;
mysql> SHOW GLOBAL STATUS LIKE '%connect%'; -- list all status that contain string "connect"
mysql> SELECT * FROM performance_schema.global_status;
mysql> SELECT * FROM performance_schema.global_status WHERE VARIABLE_NAME LIKE '%connect%'; -- list all status that contain string "connect"डेटाबेस स्थिति और अवलोकन
हम अपटाइम स्थिति के साथ शुरू करेंगे, सर्वर कितने सेकंड ऊपर रहा है।
सभी com_* स्टेटस स्टेटमेंट काउंटर वेरिएबल हैं जो इंगित करते हैं कि प्रत्येक स्टेटमेंट को कितनी बार निष्पादित किया गया है। प्रत्येक प्रकार के कथन के लिए एक स्थिति चर है। उदाहरण के लिए, com_delete और com_update क्रमशः DELETE और UPDATE स्टेटमेंट गिनते हैं। com_delete_multi और com_update_multi एक जैसे हैं लेकिन DELETE और UPDATE स्टेटमेंट पर लागू होते हैं जो मल्टीपल-टेबल सिंटैक्स का उपयोग करते हैं।
MySQL द्वारा सभी चल रही प्रक्रियाओं को सूचीबद्ध करने के लिए, बस निम्नलिखित कथनों में से एक चलाएँ:
mysql> SHOW PROCESSLIST;
mysql> SHOW FULL PROCESSLIST;
mysql> SELECT * FROM information_schema.processlist;
mysql> SELECT * FROM information_schema.processlist WHERE command <> 'sleep'; -- list all active processes except 'sleep' command.कनेक्शन और थ्रेड
वर्तमान कनेक्शन
वर्तमान में खुले कनेक्शन (कनेक्शन थ्रेड) का अनुपात। यदि अनुपात अधिक है, तो यह इंगित करता है कि MySQL सर्वर से कई समवर्ती कनेक्शन हैं और इससे "बहुत अधिक कनेक्शन" त्रुटि हो सकती है। कनेक्शन प्रतिशत प्राप्त करने के लिए:
Current connections(%) = (threads_connected / max_connections) x 100एक अच्छा मूल्य 80% और उससे कम होना चाहिए। max_connections चर बढ़ाने का प्रयास करें या पूर्ण प्रक्रिया दिखाएं का उपयोग करके कनेक्शन का निरीक्षण करें। जब "बहुत अधिक कनेक्शन" त्रुटियां होती हैं, तो MySQL डेटाबेस सर्वर गैर-सुपर उपयोगकर्ता के लिए अनुपलब्ध हो जाएगा जब तक कि कुछ कनेक्शन मुक्त नहीं हो जाते। ध्यान दें कि max_connections वेरिएबल को बढ़ाने से संभावित रूप से MySQL की मेमोरी फ़ुटप्रिंट भी बढ़ सकती है।
अब तक देखे गए अधिकतम कनेक्शन
अब तक देखे गए MySQL सर्वर से अधिकतम कनेक्शन का अनुपात। एक साधारण गणना होगी:
Max connections ever seen(%) = (max_used_connections / max_connections) x 100अच्छा मान 80% से कम होना चाहिए। यदि अनुपात अधिक है, तो यह इंगित करता है कि MySQL एक बार उच्च संख्या में कनेक्शन तक पहुंच गया है जिससे 'बहुत अधिक कनेक्शन' त्रुटि हो जाएगी। यह देखने के लिए कि क्या यह वास्तव में लगातार कम रह रहा है, वर्तमान कनेक्शन अनुपात का निरीक्षण करें। अन्यथा, max_connections चर बढ़ाएँ। max_used_connections_time स्थिति की जांच करके इंगित करें कि max_used_connections स्थिति अपने वर्तमान मान पर कब पहुंच गई है।
थ्रेड कैशे हिट दर
थ्रेड्स_क्रिएटेड की स्थिति कनेक्शन को संभालने के लिए बनाए गए थ्रेड्स की संख्या है। यदि थ्रेड्स_क्रिएटेड बड़ा है, तो आप थ्रेड_कैश_साइज़ मान बढ़ाना चाह सकते हैं। कैश हिट/मिस दर की गणना इस प्रकार की जा सकती है:
Threads cache hit rate (%) = (threads_created / connections) x 100यह एक अंश है जो थ्रेड कैश हिट दर का संकेत देता है। 50% से कम के करीब, बेहतर। यदि आपका सर्वर प्रति सेकंड सैकड़ों कनेक्शन देखता है, तो आपको सामान्य रूप से पर्याप्त थ्रेड_कैश_साइज़ सेट करना चाहिए ताकि अधिकांश नए कनेक्शन कैश्ड थ्रेड्स का उपयोग करें।
क्वेरी प्रदर्शन
पूर्ण तालिका स्कैन
पूर्ण तालिका स्कैन का अनुपात, एक ऐसा ऑपरेशन जिसमें किसी अनुक्रमणिका का उपयोग करके केवल चयनित भागों के बजाय तालिका की संपूर्ण सामग्री को पढ़ने की आवश्यकता होती है। यह मान अधिक है यदि आप बहुत सी क्वेरी कर रहे हैं जिसके लिए परिणामों को छांटने या टेबल स्कैन की आवश्यकता होती है। आम तौर पर, इससे पता चलता है कि तालिकाओं को ठीक से अनुक्रमित नहीं किया गया है या आपके प्रश्नों को आपके पास मौजूद अनुक्रमणिका का लाभ उठाने के लिए नहीं लिखा गया है। पूर्ण तालिका स्कैन के प्रतिशत की गणना करने के लिए:
Full table scans (%) = (handler_read_rnd_next + handler_read_rnd) /
(handler_read_rnd_next + handler_read_rnd + handler_read_first + handler_read_next + handler_read_key + handler_read_prev)
x 100अच्छा मान 25% से कम होना चाहिए। उप-इष्टतम प्रश्नों का पता लगाने के लिए MySQL धीमी क्वेरी लॉग आउटपुट की जांच करें।
पूर्ण जॉइन चुनें
Select_full_join की स्थिति तालिका स्कैन करने वाले जोड़ों की संख्या है क्योंकि वे अनुक्रमणिका का उपयोग नहीं करते हैं। यदि यह मान 0 नहीं है, तो आपको अपनी तालिकाओं के अनुक्रमितों की सावधानीपूर्वक जाँच करनी चाहिए।
रेंज चेक चुनें
Select_range_check की स्थिति बिना कुंजी के जुड़ने की संख्या है जो प्रत्येक पंक्ति के बाद कुंजी उपयोग की जांच करती है। अगर यह 0 नहीं है, तो आपको अपनी टेबल के इंडेक्स को ध्यान से देखना चाहिए।
पास क्रमबद्ध करें
मर्ज का अनुपात गुजरता है कि सॉर्ट एल्गोरिदम को करना पड़ता है। यदि यह मान अधिक है, तो आपको sort_buffer_size और read_rnd_buffer_size का मान बढ़ाने पर विचार करना चाहिए। एक साधारण अनुपात गणना है:
Sort passes = sort_merge_passes / (sort_scan + sort_range)3 से कम अनुपात मान एक अच्छा मान होना चाहिए। अगर आप sort_buffer_size या read_rnd_buffer_size बढ़ाना चाहते हैं, तो जब तक आप स्वीकार्य अनुपात तक नहीं पहुंच जाते, तब तक छोटे वेतन वृद्धि में वृद्धि करने का प्रयास करें।
InnoDB प्रदर्शन
InnoDB बफर पूल हिट रेट
डिस्क के बजाय मेमोरी से आपके पृष्ठों को कितनी बार पुनर्प्राप्त किया जाता है इसका अनुपात। यदि प्रारंभिक MySQL स्टार्टअप के दौरान मान कम है, तो कृपया बफर पूल को गर्म होने के लिए कुछ समय दें। बफ़र पूल हिट दर प्राप्त करने के लिए, इंजन INNODB स्थिति दिखाएँ विवरण का उपयोग करें:
mysql> SHOW ENGINE INNODB STATUS\G
...
----------------------
BUFFER POOL AND MEMORY
----------------------
...
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
...सर्वोत्तम मान 1000/10000 हिट दर है। कम मान के लिए, उदाहरण के लिए, 986/1000 की हिट दर इंगित करती है कि 1000 पृष्ठों में से, यह 986 बार रैम में पृष्ठों को पढ़ने में सक्षम था। शेष 14 बार, MySQL को डिस्क से पृष्ठों को पढ़ना पड़ा। सीधे शब्दों में कहें तो 1000/1000 सबसे अच्छा मूल्य है जिसे हम यहां हासिल करने की कोशिश कर रहे हैं, जिसका अर्थ है कि बार-बार एक्सेस किया जाने वाला डेटा पूरी तरह से रैम में फिट बैठता है।
innodb_buffer_pool_size वेरिएबल को बढ़ाने से MySQL के काम करने के लिए अधिक जगह को समायोजित करने में बहुत मदद मिलेगी। हालाँकि, सुनिश्चित करें कि आपके पास पहले से पर्याप्त RAM संसाधन हैं। अनावश्यक अनुक्रमणिका को हटाने से भी मदद मिल सकती है। यदि आपके पास एकाधिक बफर पूल उदाहरण हैं, तो सुनिश्चित करें कि प्रत्येक आवृत्ति के लिए हिट दर 1000/1000 तक पहुंच जाए।
InnoDB डर्टी पेज
कितनी बार InnoDB को फ्लश करने की आवश्यकता है इसका अनुपात। राइट-हैवी लोड के दौरान, यह प्रतिशत बढ़ जाना सामान्य है।
एक आसान गणना होगी:
InnoDB dirty pages(%) = (innodb_buffer_pool_pages_dirty / innodb_buffer_pool_pages_total) x 100एक अच्छा मूल्य 75% और उससे कम होना चाहिए। यदि गंदे पृष्ठों का प्रतिशत लंबे समय तक उच्च रहता है, तो आप बफर पूल को बढ़ाना चाहते हैं या प्रदर्शन बाधाओं से बचने के लिए तेज़ डिस्क प्राप्त कर सकते हैं।
InnoDB चेकपॉइंट की प्रतीक्षा कर रहा है
InnoDB को कितनी बार एक पृष्ठ को पढ़ने या बनाने की आवश्यकता होती है, जहां कोई साफ पृष्ठ उपलब्ध नहीं हैं, इसका अनुपात। आम तौर पर, InnoDB बफर पूल को लिखता है जो पृष्ठभूमि में होता है। हालाँकि, यदि किसी पृष्ठ को पढ़ना या बनाना आवश्यक है और कोई साफ़ पृष्ठ उपलब्ध नहीं हैं, तो पहले पृष्ठों के फ़्लश होने की प्रतीक्षा करना भी आवश्यक है। Innodb_buffer_pool_wait_free काउंटर गिनता है कि ऐसा कितनी बार हुआ है। चेकपॉइंटिंग के लिए इंतजार कर रहे InnoDB के अनुपात की गणना करने के लिए, हम निम्नलिखित गणना का उपयोग कर सकते हैं:
InnoDB waits for checkpoint = innodb_buffer_pool_wait_free / innodb_buffer_pool_write_requestsयदि innodb_buffer_pool_wait_free 0 से अधिक है, तो यह एक मजबूत संकेतक है कि InnoDB बफर पूल बहुत छोटा है, और संचालन को एक चेकपॉइंट पर इंतजार करना पड़ता है। innodb_buffer_pool_size को बढ़ाने से आमतौर पर innodb_buffer_pool_wait_free और साथ ही यह अनुपात कम हो जाएगा। एक अच्छा अनुपात मान 1 से नीचे रहना चाहिए।
InnoDB Redolog की प्रतीक्षा कर रहा है
पुन:लॉग विवाद का अनुपात। innodb_log_waits चेक करें और अगर यह लगातार बढ़ता रहे तो innodb_log_buffer_size को बढ़ा दें। इसका मतलब यह भी हो सकता है कि डिस्क बहुत धीमी हैं और डिस्क IO को बनाए नहीं रख सकती हैं, शायद पीक राइट लोड के कारण। पुन:लॉग प्रतीक्षा अनुपात की गणना करने के लिए निम्न गणना का उपयोग करें:
InnoDB waits for redolog = innodb_log_waits / innodb_log_writesएक अच्छा अनुपात मान 1 से नीचे होना चाहिए। अन्यथा, innodb_log_buffer_size बढ़ाएँ।
टेबल्स
टेबल कैश उपयोग
सभी थ्रेड्स के लिए टेबल कैश उपयोग का अनुपात। एक साधारण गणना होगी:
Table cache usage(%) = (opened_tables / table_open_cache) x 100अच्छा मान 80% से कम होना चाहिए। टेबल_ओपन_कैश वैरिएबल को तब तक बढ़ाएं जब तक कि प्रतिशत अच्छे मान तक न पहुंच जाए।
टेबल कैश हिट अनुपात
टेबल कैश हिट उपयोग का अनुपात। एक साधारण गणना होगी:
Table cache hit ratio(%) = (open_tables / opened_tables) x 100एक अच्छा हिट अनुपात मान 90% और उससे अधिक होना चाहिए। अन्यथा, table_open_cache वैरिएबल को तब तक बढ़ाएं जब तक कि हिट अनुपात एक अच्छे मान तक न पहुंच जाए।
ClusterControl के साथ मेट्रिक्स मॉनिटरिंग
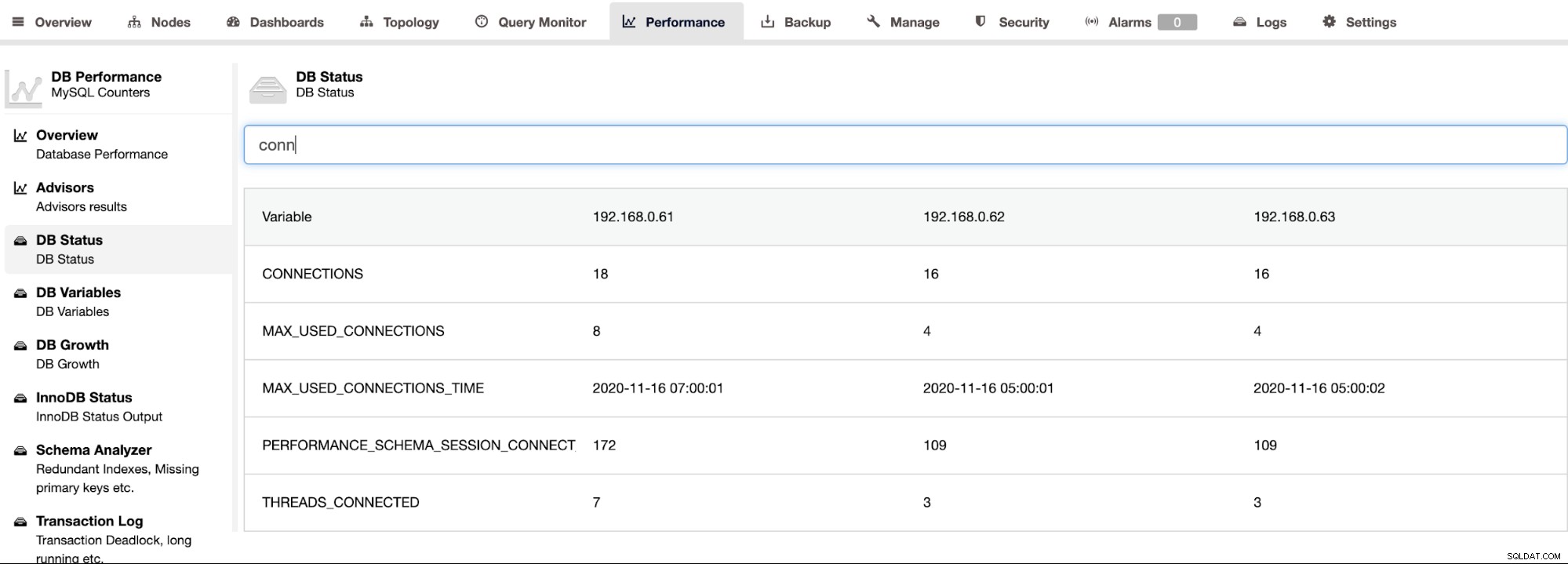
ClusterControl MySQL के लिए Percona सर्वर का समर्थन करता है और यह ClusterControl -> Performance -> DB Status पेज के अंतर्गत क्लस्टर में सभी नोड्स का एक समग्र दृश्य प्रदान करता है। यह स्थिति को फ़िल्टर करने की क्षमता के साथ सभी होस्ट पर सभी स्थिति देखने के लिए एक केंद्रीकृत दृष्टिकोण प्रदान करता है, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है:
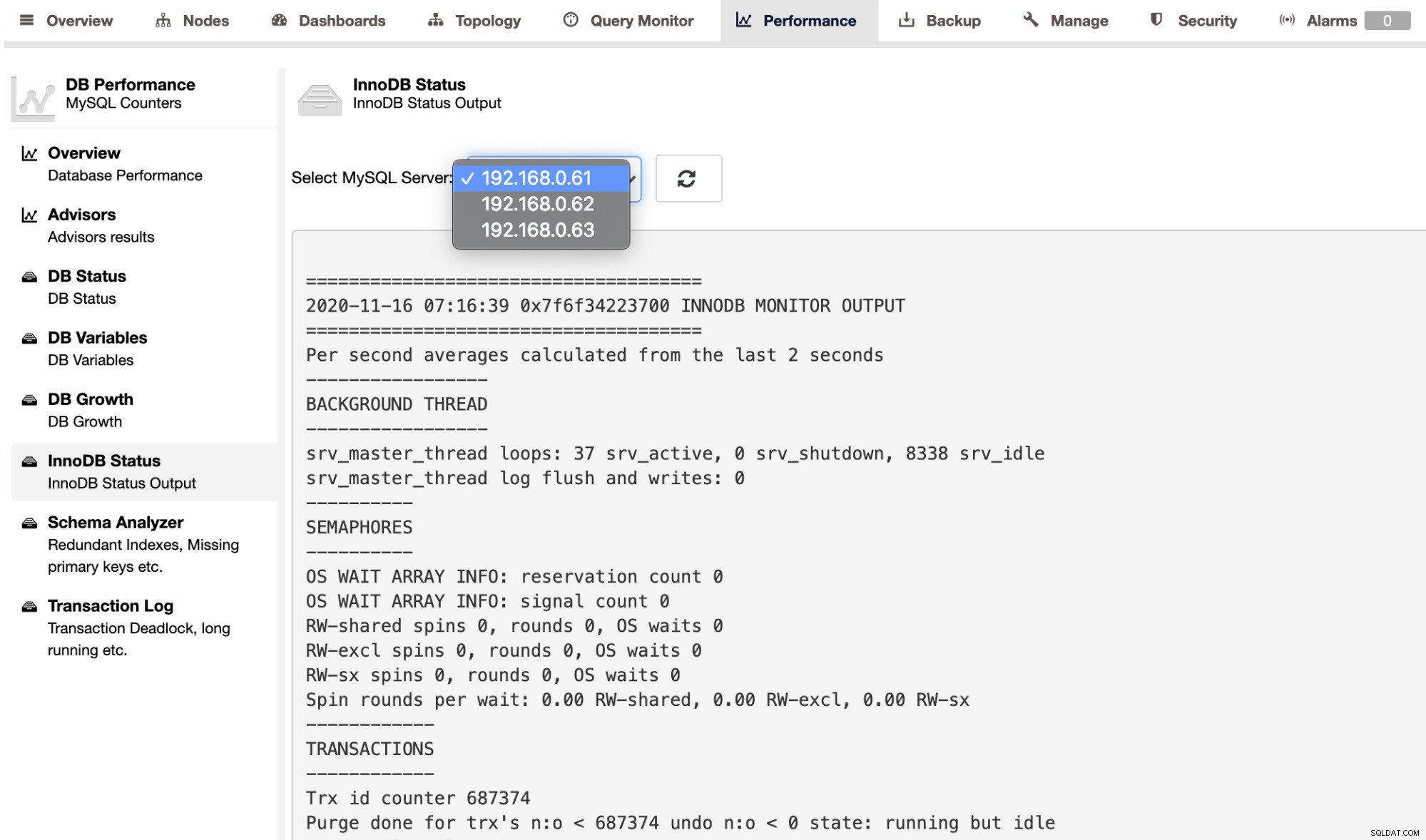
एक व्यक्तिगत सर्वर के लिए SHOW ENGINE INNODB STATUS आउटपुट प्राप्त करने के लिए, आप प्रदर्शन -> InnoDB स्थिति पृष्ठ का उपयोग करें, जैसा कि नीचे दिखाया गया है:
ClusterControl बिल्ट-इन एडवाइज़र्स भी प्रदान करता है जिनका उपयोग आप अपने डेटाबेस को ट्रैक करने के लिए कर सकते हैं। प्रदर्शन। यह सुविधा ClusterControl -> प्रदर्शन -> सलाहकार:
. के अंतर्गत उपलब्ध है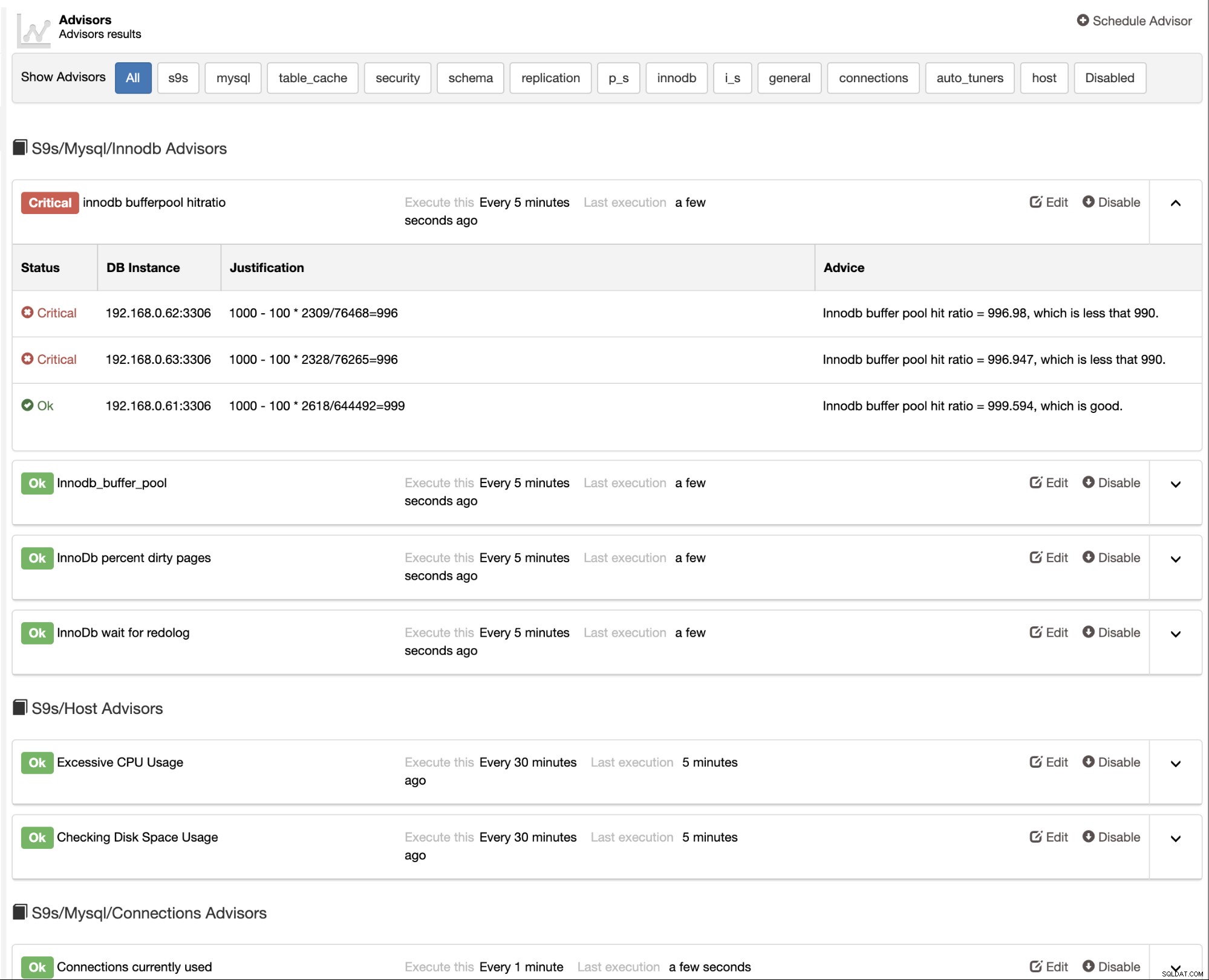
सलाहकार मूल रूप से क्रोन जैसे निर्धारित समय में ClusterControl द्वारा निष्पादित मिनी-प्रोग्राम हैं। नौकरियां। आप "अनुसूची सलाहकार" बटन पर क्लिक करके सलाहकार को शेड्यूल कर सकते हैं, और डेवलपर स्टूडियो ऑब्जेक्ट ट्री से कोई मौजूदा सलाहकार चुन सकते हैं:
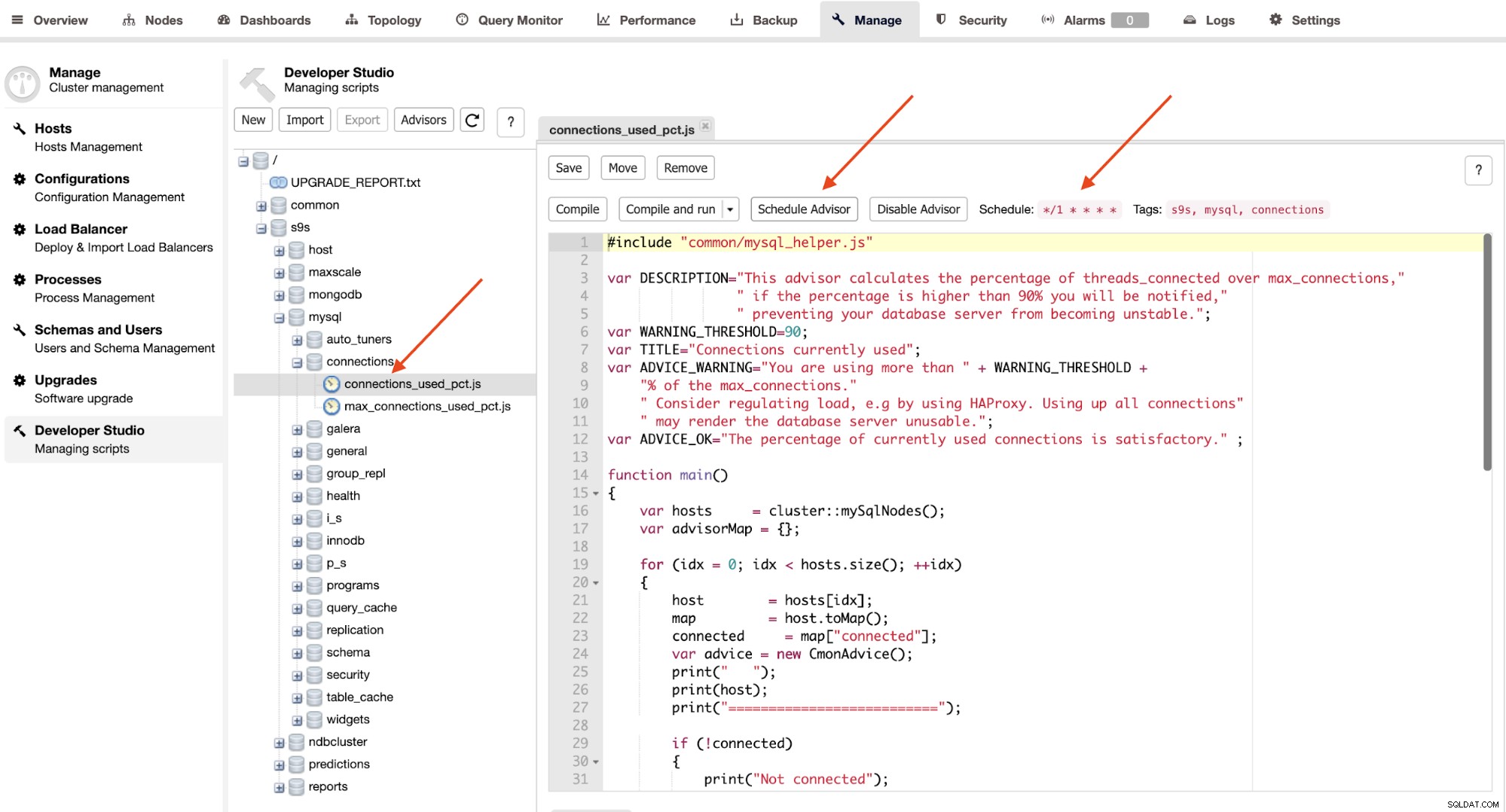
शेड्यूल एडवाइजर बटन पर क्लिक करके शेड्यूलिंग सेट करें। पास और सलाहकार के टैग भी। आप "संकलित करें और चलाएँ" बटन पर क्लिक करके तुरंत आउटपुट देखने के लिए सलाहकार को संकलित भी कर सकते हैं, जहाँ आपको इसके नीचे "संदेश" के अंतर्गत निम्न आउटपुट देखना चाहिए:

आप इसमें लिखी गई इस डेवलपर गाइड का हवाला देकर अपना खुद का सलाहकार बना सकते हैं। ClusterControl डोमेन विशिष्ट भाषा (जावास्क्रिप्ट के समान), या अपनी निगरानी नीतियों के अनुरूप किसी मौजूदा सलाहकार को अनुकूलित करें। संक्षेप में, ClusterControl सलाहकारों के माध्यम से असीमित संभावनाओं के साथ ClusterControl निगरानी शुल्क बढ़ाया जा सकता है।