परिचय
इस लेख में, हम चर्चा करेंगे कि SQL सर्वर मेमोरी-ऑप्टिमाइज़्ड टेबल में विभिन्न प्रकार के इंडेक्स प्रदर्शन को कैसे प्रभावित करते हैं। हम उदाहरणों की जांच करेंगे कि विभिन्न इंडेक्स प्रकार मेमोरी-अनुकूलित तालिकाओं के प्रदर्शन को कैसे प्रभावित कर सकते हैं।
विषय चर्चा को आसान बनाने के लिए, हम एक बड़े उदाहरण का उपयोग करेंगे। सरलता के उद्देश्य से, इस उदाहरण में एक ही तालिका के विभिन्न प्रतिरूप होंगे, जिसके विरुद्ध हम विभिन्न प्रश्नों को चलाएंगे। ये प्रतिकृतियां अलग-अलग इंडेक्स का उपयोग करेंगी, या बिल्कुल भी इंडेक्स का उपयोग नहीं करेंगी (बेशक, प्राथमिक कुंजी - पीके को छोड़कर)।
ध्यान दें, कि इस आलेख का वास्तविक उद्देश्य SQL सर्वर में डिस्क-आधारित और स्मृति-अनुकूलित तालिकाओं के बीच प्रदर्शन की तुलना करना नहीं है। इसका उद्देश्य यह जांचना है कि अनुक्रमणिका स्मृति-अनुकूलित तालिकाओं में प्रदर्शन को कैसे प्रभावित करती है। हालांकि, प्रयोगों की पूरी तस्वीर रखने के लिए, संबंधित डिस्क-आधारित तालिका प्रश्नों के लिए समय भी प्रदान किया जाता है और स्पीडअप की गणना बेसलाइन के रूप में डिस्क-आधारित तालिकाओं के सबसे इष्टतम कॉन्फ़िगरेशन का उपयोग करके की जाती है।
परिदृश्य
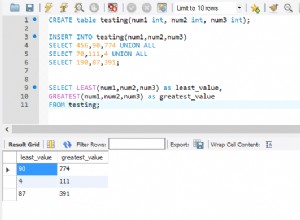
हमारे परिदृश्य के लिए नमूना डेटा निम्नलिखित के रूप में परिभाषित एकल तालिका पर आधारित है:
सूची 1:नमूना डेटा स्रोत तालिका.
ऊपर दी गई तालिका नमूना डेटा से भरी हुई थी और शेष तालिकाओं के लिए डेटा स्रोत के रूप में कार्य करेगी।
इसलिए, उपरोक्त तालिका के आधार पर, हम निम्नलिखित 9 तालिका विविधताएं बनाते हैं और उन्हें समान नमूना डेटा से भरते हैं:
- 3 डिस्क-आधारित टेबल:
- d_tblSample1
- "आईडी" कॉलम पर क्लस्टर इंडेक्स - प्राथमिक कुंजी (पीके)
- d_tblSample2
- “आईडी” कॉलम (पीके) पर क्लस्टर इंडेक्स
- “देश कोड” कॉलम पर गैर-संकुल अनुक्रमणिका
- d_tblSample3
- “आईडी” कॉलम (पीके) पर क्लस्टर इंडेक्स
- “regDate” कॉलम पर गैर-संकुल अनुक्रमणिका
- “देश कोड” कॉलम पर गैर-संकुल अनुक्रमणिका
- d_tblSample1
- 3 मेमोरी-अनुकूलित टेबल (सेट 1:हैश इंडेक्स):
- m1_tblSample1
- “आईडी” कॉलम पर गैर-संकुल हैश इंडेक्स – प्राथमिक कुंजी (पीके)
- m1_tblSample2
- “आईडी” कॉलम (पीके) पर गैर-क्लस्टर हैश इंडेक्स
- "कंट्रीकोड" कॉलम पर हैश इंडेक्स
- m1_tblSample3
- “आईडी” कॉलम (पीके) पर गैर-क्लस्टर हैश इंडेक्स
- “regDate” कॉलम पर हैश इंडेक्स
- "कंट्रीकोड" कॉलम पर हैश इंडेक्स
- 3 मेमोरी-अनुकूलित टेबल (सेट 2:नॉन-क्लस्टर इंडेक्स):
- m2_tblSample1
- “आईडी” कॉलम पर गैर-संकुल अनुक्रमणिका – प्राथमिक कुंजी (पीके)
- m2_tblSample2
- “आईडी” कॉलम (पीके) पर गैर-संकुल अनुक्रमणिका
- “देश कोड” कॉलम पर गैर-संकुल अनुक्रमणिका
- m2_tblSample3
- “आईडी” कॉलम (पीके) पर गैर-संकुल अनुक्रमणिका
- “regDate” कॉलम पर गैर-संकुल अनुक्रमणिका
- “देश कोड” कॉलम पर गैर-संकुल अनुक्रमणिका
- m2_tblSample1
- m1_tblSample1
नीचे दी गई सूचियों में, आप उपरोक्त तालिकाओं के लिए परिभाषाएँ पा सकते हैं।
परिदृश्य तर्क यह है कि हम एक ही तालिका (लेकिन अलग-अलग इंडेक्स के साथ) की विविधताओं के खिलाफ अलग-अलग डेटाबेस संचालन करते हैं, और देखते हैं कि प्रत्येक मामले में प्रदर्शन कैसे प्रभावित होता है।
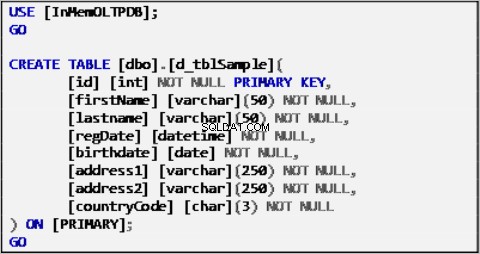
परिभाषाएं
डिस्क-आधारित टेबल
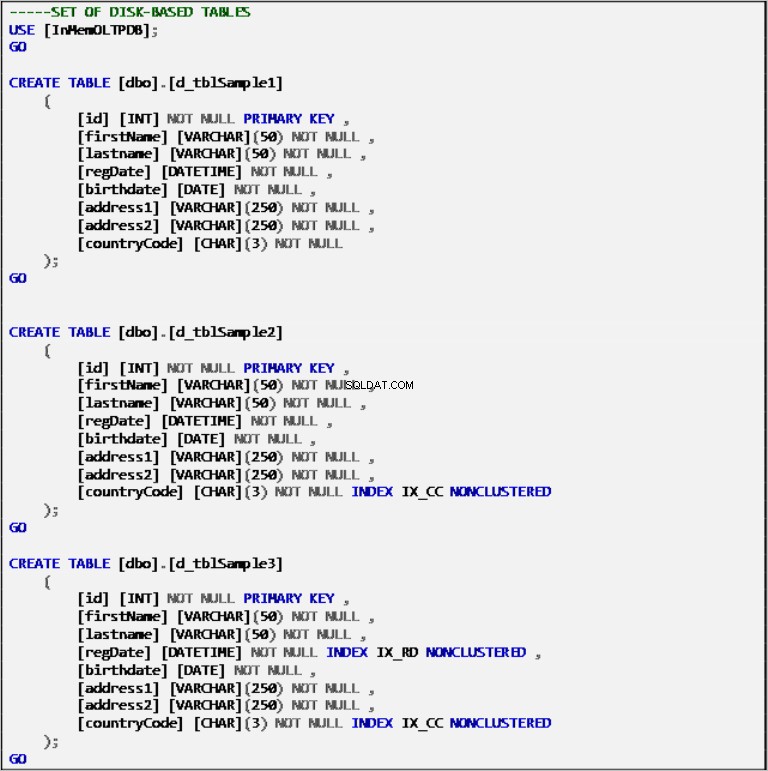
लिस्टिंग 2:डिस्क-आधारित टेबल्स परिभाषा।
मेमोरी-ऑप्टिमाइज़्ड टेबल्स (सेट 1:हैश इंडेक्स)

लिस्टिंग 3:मेमोरी-ऑप्टिमाइज़्ड टेबल्स - सेट 1 (हैश इंडेक्स)।
मेमोरी-ऑप्टिमाइज़्ड टेबल्स (सेट 2:नॉन-क्लस्टर्ड इंडेक्स)

लिस्टिंग 4:मेमोरी-ऑप्टिमाइज़्ड टेबल्स - सेट 2 (गैर-क्लस्टर इंडेक्स)।
फिर, हम उपरोक्त सभी तालिकाओं को समान नमूना डेटा के साथ भरते हैं, जो प्रत्येक तालिका में कुल 5 मिलियन रिकॉर्ड में है।
यहाँ तालिकाओं के प्रत्येक सेट के लिए काउंट कमांड का आउटपुट दिया गया है:
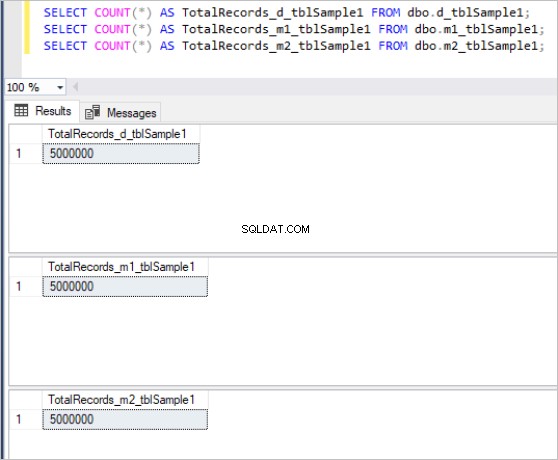
चित्र 1:तालिका के पहले सेट के लिए रिकॉर्ड की कुल संख्या।
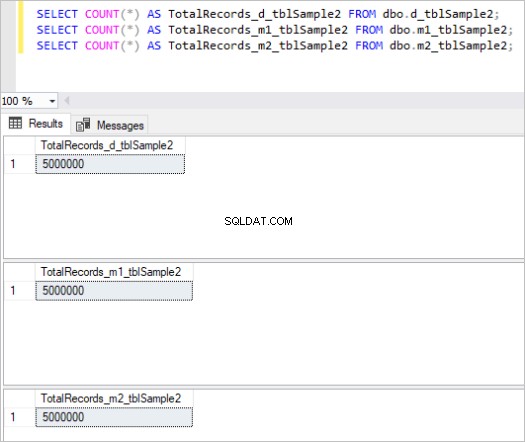
चित्र 2:तालिका के दूसरे सेट के लिए रिकॉर्ड की कुल संख्या।
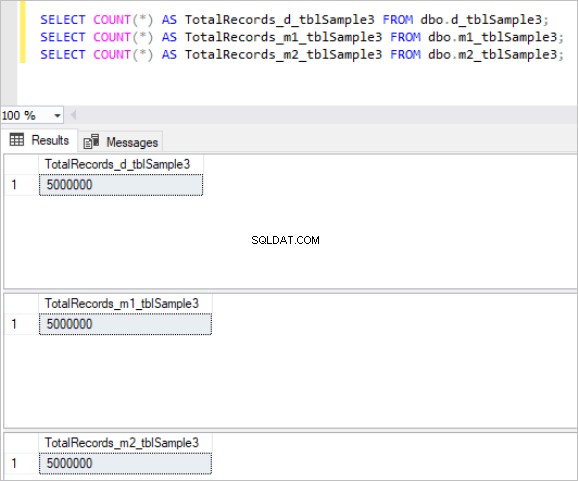
चित्र 3:तालिका के तीसरे सेट के लिए रिकॉर्ड की कुल संख्या।
प्रश्न और परिदृश्य निष्पादन
अब, हम उपरोक्त तालिकाओं के विरुद्ध प्रश्नों का एक सेट चलाने जा रहे हैं और देखें कि प्रत्येक तालिका कैसा प्रदर्शन करती है।
ये प्रश्न निम्नलिखित कार्य करते हैं:
- प्रश्न 1:एकत्रीकरण (ग्रुप बाय)
- प्रश्न 2:समानता विधेय पर अनुक्रमणिका खोज
- प्रश्न 3:सूचकांक समानता और असमानता विधेय पर खोज करता है
निम्नलिखित के अनुसार प्रश्नों को निष्पादित करने की योजना है:
प्रश्न 1 - निम्नलिखित तालिकाओं के विरुद्ध निष्पादन:
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1 (लक्षित स्तंभों पर कोई अनुक्रमणिका नहीं)
- m2_tblSample1 (लक्षित स्तंभों पर कोई अनुक्रमणिका नहीं)
प्रश्न 2 - निम्नलिखित तालिकाओं के विरुद्ध निष्पादन:
- d_tblSample2
- m1_tblSample2
- m2_tblSample2
- m1_tblSample1 (लक्षित स्तंभों पर कोई अनुक्रमणिका नहीं)
- m2_tblSample1 (लक्षित स्तंभों पर कोई अनुक्रमणिका नहीं)
प्रश्न 3 - निम्न तालिकाओं के विरुद्ध निष्पादन:
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1 (लक्षित स्तंभों पर कोई अनुक्रमणिका नहीं)
- m2_tblSample1 (लक्षित स्तंभों पर कोई अनुक्रमणिका नहीं)
नोट :भले ही d_tblSample1 . की परिभाषा डिस्क-आधारित तालिका उपरोक्त तालिका परिभाषाओं में शामिल है, इसका उपयोग इस आलेख में दिए गए प्रश्नों में नहीं किया गया है। इसका कारण यह है कि, प्रत्येक परिदृश्य में, डिस्क-आधारित तालिका के लिए सबसे इष्टतम संभव कॉन्फ़िगरेशन का उपयोग किया जाता है, क्योंकि हम चाहते हैं कि जब हम स्मृति-अनुकूलित तालिकाओं के प्रदर्शन के साथ इसकी तुलना करते हैं तो हमारी आधार रेखा जितनी जल्दी हो सके। इसके लिए, d_tblSample1 तालिका केवल सूचना के उद्देश्यों के लिए प्रस्तुत की गई है।
नीचे आप निष्पादन समय मापने के तंत्र के साथ तीन प्रश्नों के लिए टी-एसक्यूएल स्क्रिप्ट पा सकते हैं।

सूची 5:प्रश्न 1 - एकत्रीकरण (सूचकांक के साथ)।
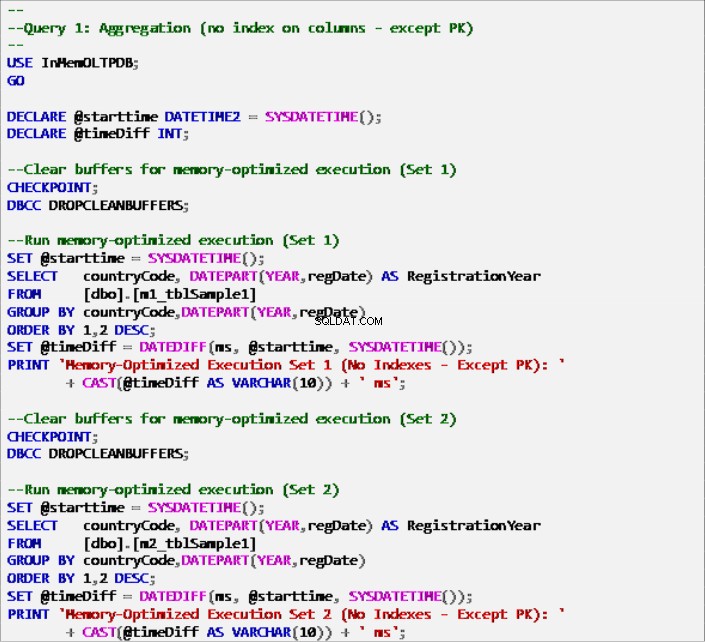
लिस्टिंग 6:क्वेरी 1 - एग्रीगेशन (बिना इंडेक्स के - प्राइमरी की को छोड़कर)।
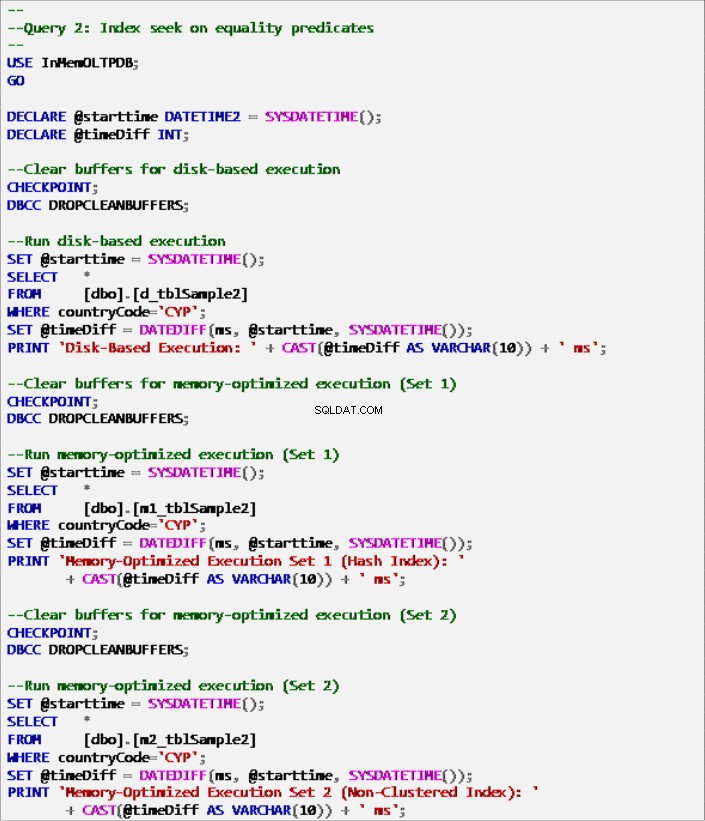
लिस्टिंग 7:क्वेरी 2 - इंडेक्स सीक ऑन इक्वलिटी प्रेडिकेट्स (इंडेक्स के साथ)।

लिस्टिंग 8:क्वेरी 2 - इंडेक्स सीक ऑन इक्वलिटी प्रेडिकेट्स (बिना किसी इंडेक्स के - प्राइमरी की को छोड़कर)।
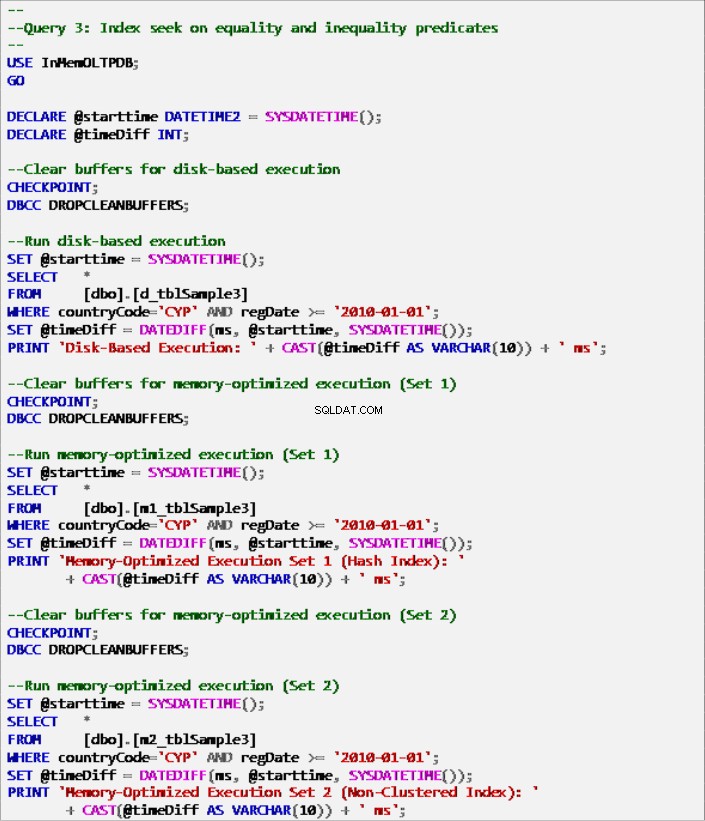
लिस्टिंग 9:क्वेरी 3 - इंडेक्स सीक ऑन इक्वलिटी एंड इनइक्वलिटी प्रेडिकेट्स (इंडेक्स के साथ)।

लिस्टिंग 10:क्वेरी 3 - इंडेक्स सीक ऑन इक्वलिटी एंड इनइक्वलिटी प्रेडिकेट्स (बिना किसी इंडेक्स के - प्राइमरी की को छोड़कर)।
नीचे दिए गए स्क्रीनशॉट प्रत्येक क्वेरी निष्पादन का आउटपुट दिखाते हैं:
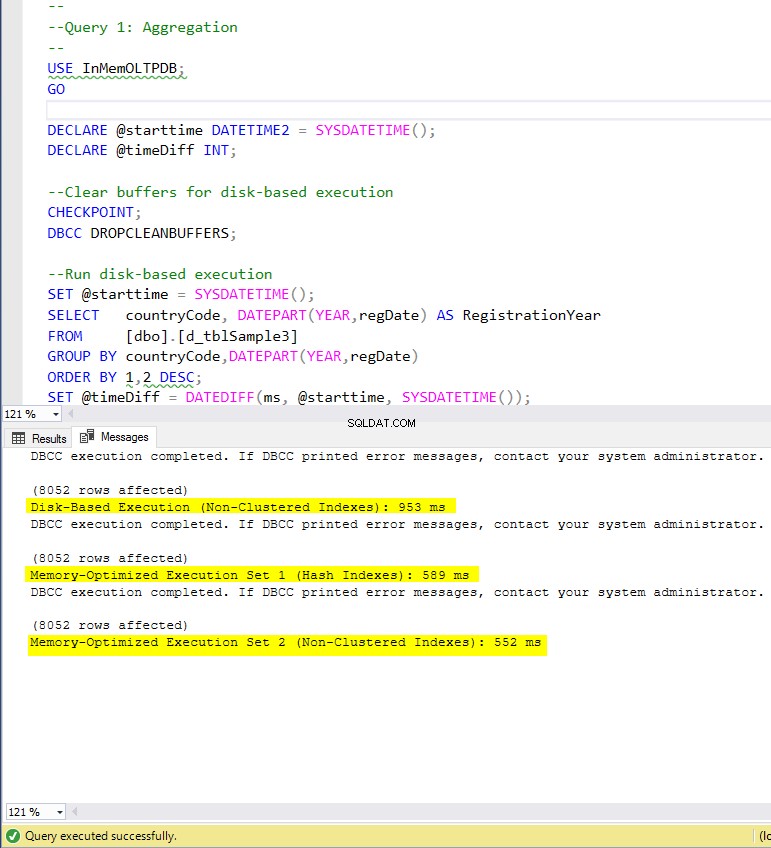
चित्र 4:क्वेरी 1 निष्पादन समय (इंडेक्स के साथ)।
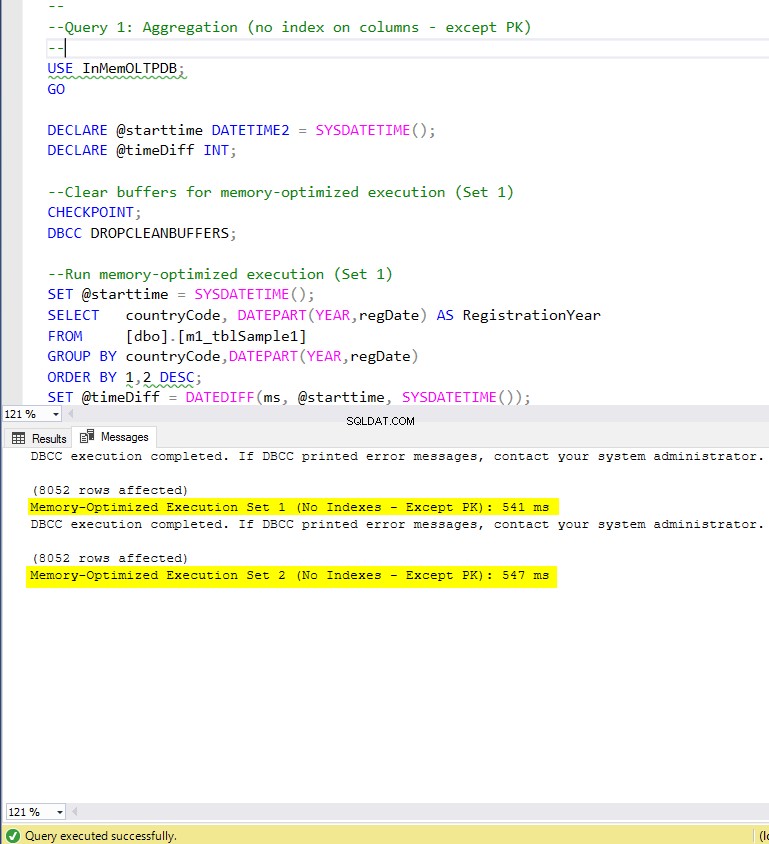
चित्र 5:क्वेरी 1 निष्पादन समय (बिना किसी अनुक्रमणिका के - PK को छोड़कर)।
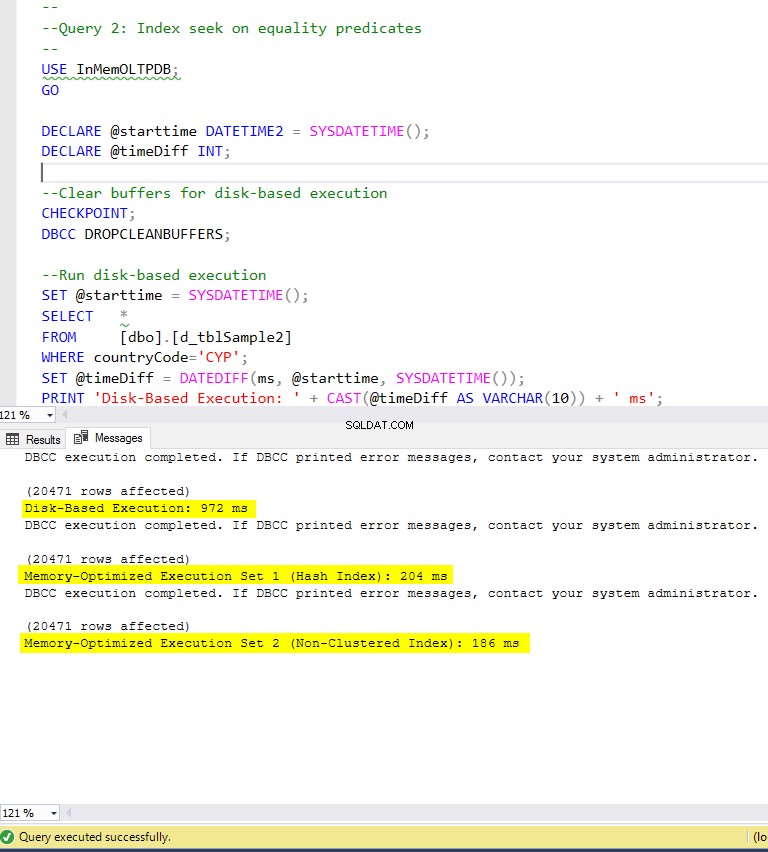
चित्र 6:क्वेरी 2 निष्पादन समय (इंडेक्स के साथ)।
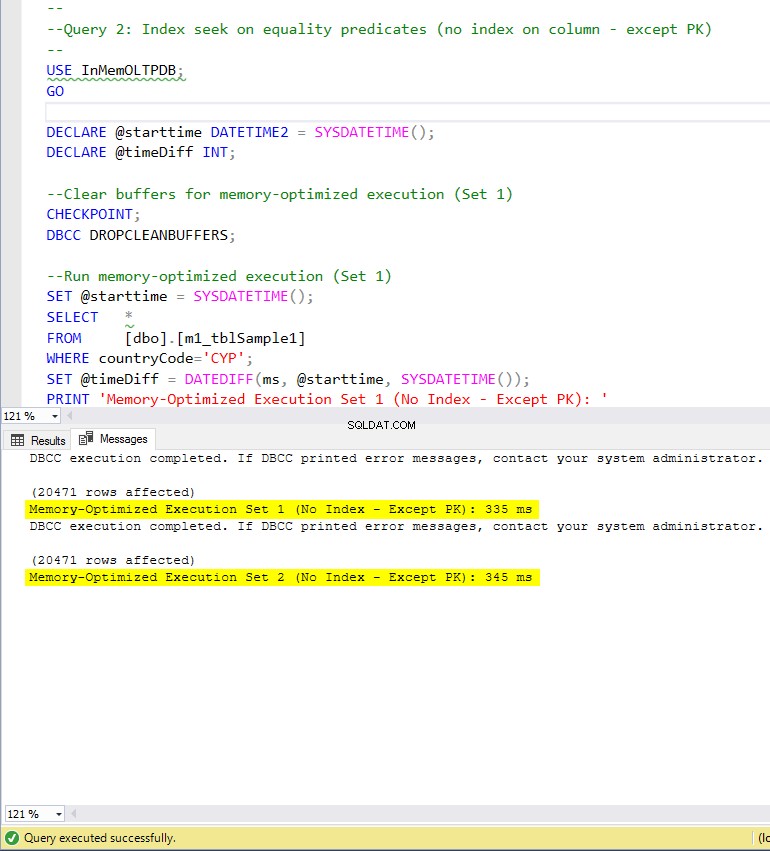
चित्र 7:क्वेरी 2 निष्पादन समय (बिना किसी अनुक्रमणिका के - PK को छोड़कर)।
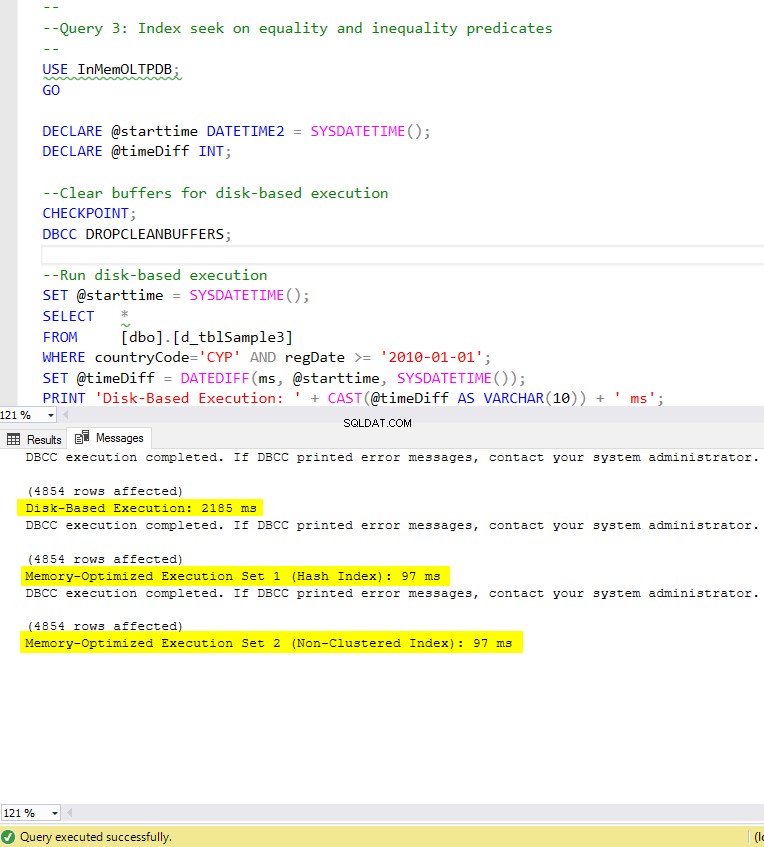
चित्र 8:क्वेरी 3 निष्पादन समय (सूचकांक के साथ)।
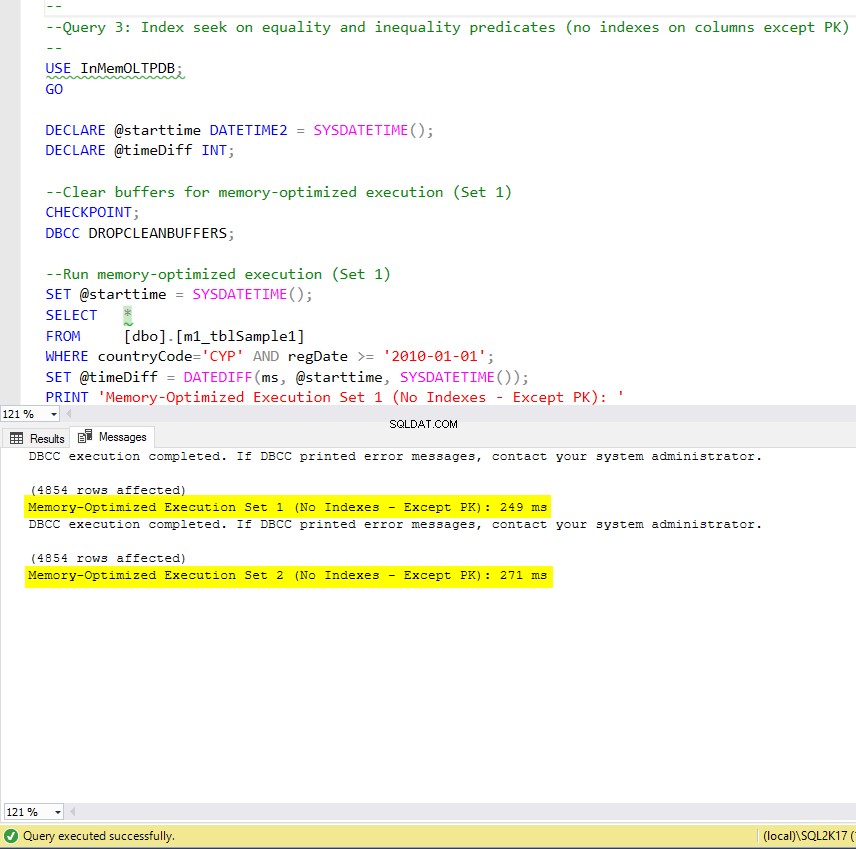
चित्र 9:क्वेरी 3 निष्पादन समय (बिना किसी अनुक्रमणिका के - PK को छोड़कर)।
अब, ऊपर प्राप्त परिणामों को संक्षेप में प्रस्तुत करते हैं। निम्न तालिका उपरोक्त सभी प्रश्नों और तालिका/सूचकांक संयोजनों के लिए मापा निष्पादन समय प्रदर्शित करती है।
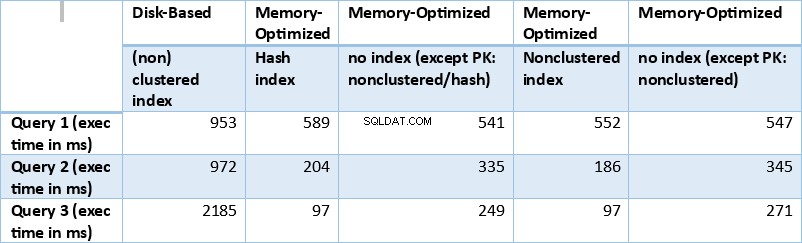
तालिका 1:सभी प्रश्नों के लिए निष्पादन समय (एमएस) का सारांश।
चर्चा
यदि हम उपरोक्त तालिका में संक्षेपित निष्पादन परिणामों की जांच करते हैं, तो हम कुछ निष्कर्षों पर पहुंच सकते हैं। आइए प्रत्येक क्वेरी परिणाम को ग्राफ़ में प्लॉट करें। नीचे दिए गए ग्राफ़ निष्पादन के समय के साथ-साथ डिस्क-आधारित तालिकाओं पर मेमोरी-अनुकूलित तालिकाओं की गति को दर्शाते हैं।
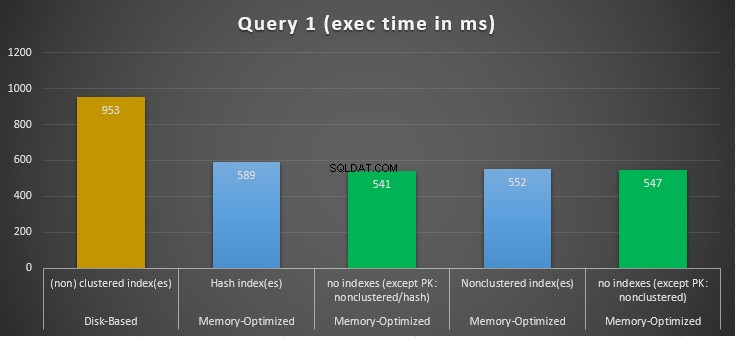
चित्र 10:क्वेरी 1 निष्पादन समय तुलना।
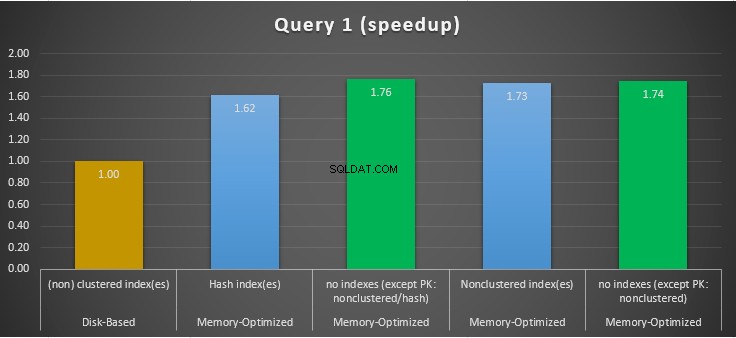
चित्र 11:क्वेरी 1 स्पीडअप तुलना।
क्वेरी 1 के संबंध में, जो एक समूह द्वारा एकत्रीकरण था, हम देख सकते हैं कि स्मृति-अनुकूलित तालिकाओं के दोनों संस्करण (अनुक्रमणिका बनाम कोई अनुक्रमणिका नहीं), डिस्क-आधारित तालिका (अनुक्रमणिका के साथ सक्षम) पर स्पीडअप के बीच लगभग समान प्रदर्शन करते हैं 1.62 और 1.76 गुना तेज।
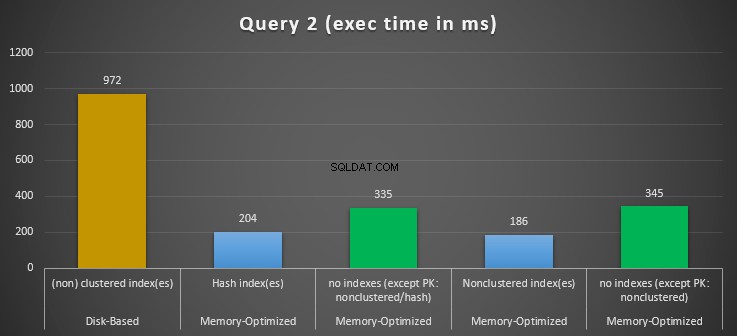
चित्र 12:क्वेरी 2 एक्ज़ीक्यूशन टाइम्स तुलना।
चित्र 13:क्वेरी 2 स्पीडअप तुलना।
क्वेरी 2 के संबंध में, जिसमें समानता विधेय पर एक अनुक्रमणिका की तलाश शामिल है, हम देख सकते हैं कि अनुक्रमणिका के साथ स्मृति-अनुकूलित तालिकाओं ने बिना अनुक्रमणिका वाली स्मृति-अनुकूलित तालिकाओं की तुलना में बहुत बेहतर प्रदर्शन किया है। इसके अलावा, हम देखते हैं कि विधेय के रूप में उपयोग किए जाने वाले कॉलम में गैर-क्लस्टर इंडेक्स वाली मेमोरी-ऑप्टिमाइज़्ड टेबल हैश इंडेक्स वाले से बेहतर प्रदर्शन करती है।
तो, क्वेरी 2 के लिए, विजेता गैर-संकुल अनुक्रमणिका वाली स्मृति-अनुकूलित तालिका है, जिसका समग्र गति 5.23 है डिस्क-आधारित निष्पादन से कई गुना तेज़।
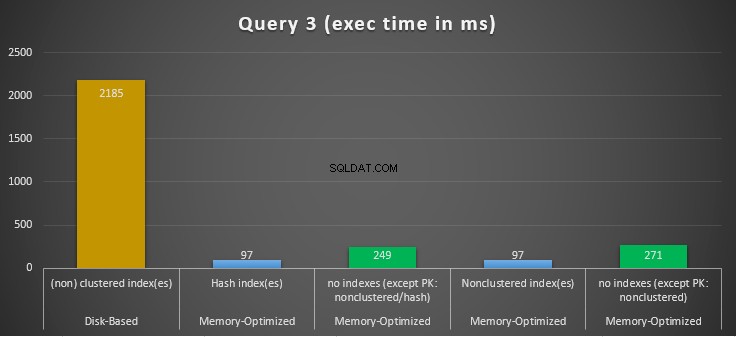
चित्र 14:क्वेरी 3 निष्पादन समय तुलना।
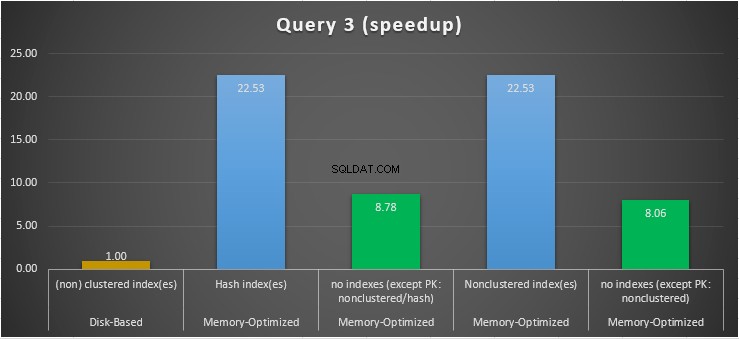
चित्र 15:क्वेरी 3 स्पीडअप तुलना।
क्वेरी 3 के संबंध में, जिसमें समानता और असमानता पर एक इंडेक्स की तलाश शामिल है, संयुक्त रूप से भविष्यवाणी करता है, हम देख सकते हैं कि इंडेक्स के साथ मेमोरी-ऑप्टिमाइज़्ड टेबल, बिना इंडेक्स वाले मेमोरी-ऑप्टिमाइज़्ड टेबल की तुलना में बेहतर प्रदर्शन करते हैं। इसके अलावा, हम देखते हैं कि विधेय के रूप में उपयोग किए जाने वाले कॉलम में गैर-क्लस्टर इंडेक्स वाली मेमोरी-ऑप्टिमाइज़्ड टेबल ने हैश इंडेक्स वाले के समान ही प्रदर्शन किया।
इसके लिए, हम देख सकते हैं कि दोनों मेमोरी-अनुकूलित टेबल, जो विधेय के रूप में उपयोग किए गए कॉलम में इंडेक्स का उपयोग करते हैं, बिना इंडेक्स वाले लोगों की तुलना में तेजी से प्रदर्शन करते हैं और 22.53 गुना तेज का स्पीडअप हासिल करते हैं। डिस्क-आधारित निष्पादन पर।
निष्कर्ष
इस आलेख में, हमने SQL सर्वर में स्मृति-अनुकूलित तालिकाओं में अनुक्रमणिका के उपयोग की जांच की। हमने प्रत्येक क्वेरी के लिए आधार रेखा के रूप में उपयोग किया, सर्वोत्तम संभव डिस्क-आधारित तालिका कॉन्फ़िगरेशन, और फिर हमने डिस्क-आधारित तालिकाओं के विरुद्ध तीन प्रश्नों के प्रदर्शन की तुलना की, और स्मृति-अनुकूलित तालिकाओं के 4 रूपांतरों की तुलना की। चार में से दो मेमोरी-ऑप्टिमाइज़्ड टेबल में इंडेक्स (हैश/गैर-क्लस्टर) का इस्तेमाल किया गया और अन्य दो में इंडेक्स का इस्तेमाल नहीं किया गया, सिवाय प्राथमिक कुंजियों के लिए इस्तेमाल किए गए इंडेक्स को छोड़कर।
समग्र निष्कर्ष यह है कि आपको हमेशा यह जांचने की आवश्यकता होती है कि अनुक्रमणिका प्रदर्शन को कैसे प्रभावित करती है, न केवल स्मृति-अनुकूलित तालिकाओं के लिए बल्कि डिस्क-आधारित तालिकाओं के लिए भी, और जब भी आप पहचानते हैं कि वे प्रदर्शन में सुधार करते हैं, तो उनका उपयोग करें। इस आलेख के उदाहरणों के निष्कर्ष बताते हैं कि यदि आप स्मृति-अनुकूलित तालिकाओं में उचित अनुक्रमणिका का उपयोग करते हैं, तो आप अनुक्रमणिका के बिना स्मृति-अनुकूलित तालिकाओं का उपयोग करने की तुलना में इस आलेख में उपयोग किए गए प्रश्नों के समान बेहतर प्रदर्शन प्राप्त कर सकते हैं। ।
संदर्भ और आगे पढ़ना:
- माइक्रोसॉफ्ट डॉक्स:मेमोरी-ऑप्टिमाइज़्ड टेबल्स
- माइक्रोसॉफ्ट डॉक्स:मेमोरी-ऑप्टिमाइज़्ड टेबल्स पर इंडेक्स का उपयोग करने के लिए दिशानिर्देश
- माइक्रोसॉफ्ट डॉक्स:मेमोरी-ऑप्टिमाइज़्ड टेबल्स पर इंडेक्स
उपयोगी टूल:
डीबीफोर्ज इंडेक्स मैनेजर - एसक्यूएल इंडेक्स की स्थिति का विश्लेषण करने और इंडेक्स विखंडन के साथ मुद्दों को ठीक करने के लिए आसान एसएसएमएस ऐड-इन।