कड़ी प्रतिस्पर्धा के इस युग में, जॉब पोर्टल केवल प्रकाशन और नौकरी खोजने के लिए मंच नहीं हैं। वे अपने ग्राहकों को जोड़े रखने के लिए उन्नत सेवाओं और सुविधाओं का लाभ उठा रहे हैं। आइए कुछ उन्नत सुविधाओं के बारे में जानें और एक ऐसा डेटा मॉडल बनाएं जो उन्हें संभाल सके।
मैंने पिछले लेख में जॉब पोर्टल वेबसाइट के लिए आवश्यक मूलभूत सुविधाओं के बारे में बताया था। मॉडल नीचे दिखाया गया है। हम इस मॉडल को आधार मानेंगे, जिसे हम नई आवश्यकताओं को पूरा करने के लिए बदल देंगे। सबसे पहले, आइए विचार करें कि ये आवश्यकताएं (या एन्हांसमेंट) क्या होनी चाहिए।
हम ऑनलाइन जॉब पोर्टल डेटा मॉडल में क्या जोड़ रहे हैं?
संक्षेप में, हम अपने पुराने डेटा मॉडल में चार एन्हांसमेंट जोड़ने जा रहे हैं:
- नौकरी चाहने वालों के लिए एक व्यक्तिगत डैशबोर्ड। यह उनके सभी नौकरी आवेदनों का ट्रैक रखता है और किसी भी स्थिति परिवर्तन पर रीयल टाइम अपडेट प्रदान करता है (यानी एक आवेदन प्राप्त होने से समीक्षा की जा रही है)।
- प्रोफ़ाइल डैशबोर्ड. यह विवरण जो नौकरी चाहने वाले की प्रोफ़ाइल पर जा रहा है और अंतिम दिन, सप्ताह या महीने में कितनी बार उनका बायोडाटा डाउनलोड किया गया था।
- सशुल्क सेवा प्रबंधन। जॉब पोर्टल अक्सर विशेषज्ञ रिज्यूम तैयारी, सोशल प्रोफाइल प्रबंधन, करियर परामर्श आदि जैसी सेवाएं प्रदान करते हैं। हमारी नई कार्यक्षमताएं भुगतान के लिए पेशकशों का समर्थन करने में सक्षम होंगी।
- आवेदन-पूर्व प्रपत्र प्रबंधन। जैसे ही आवेदक नौकरी के लिए आवेदन जमा करते हैं, उन्हें कार्य समय, स्थान और पृष्ठभूमि की जांच से संबंधित एक छोटी प्रश्नावली भरने के लिए कहा जा सकता है। हम इस फ़ॉर्म को भर्ती करने वालों द्वारा अनुकूलित करने के लिए और सिस्टम द्वारा कैप्चर किए जाने वाले प्रश्नों और प्रतिक्रियाओं के लिए तैयार करेंगे।
एन्हांसमेंट# 1:व्यक्तिगत डैशबोर्ड
उत्तर देने के लिए प्रश्न: सबमिट किए गए आवेदन की वर्तमान स्थिति क्या है? क्या इसे साक्षात्कार के लिए शॉर्टलिस्ट किया गया है? क्या इसे अभी तक देखा भी गया है?
हम job_application_status_id . डालकर नौकरी के आवेदनों पर नज़र रख सकते हैं job_post_activity टेबल। यह कॉलम नौकरी आवेदन की वर्तमान स्थिति रखता है। हमें एक और टेबल बनाने की जरूरत है, job_application_status , सभी संभावित आवेदन स्थितियों को धारण करने के लिए। कुछ स्थितियां 'सबमिट', 'समीक्षा अधीन', 'संग्रहीत', 'अस्वीकार', 'साक्षात्कार के लिए शॉर्टलिस्टेड', 'भर्ती प्रक्रिया के तहत', आदि हो सकती हैं।
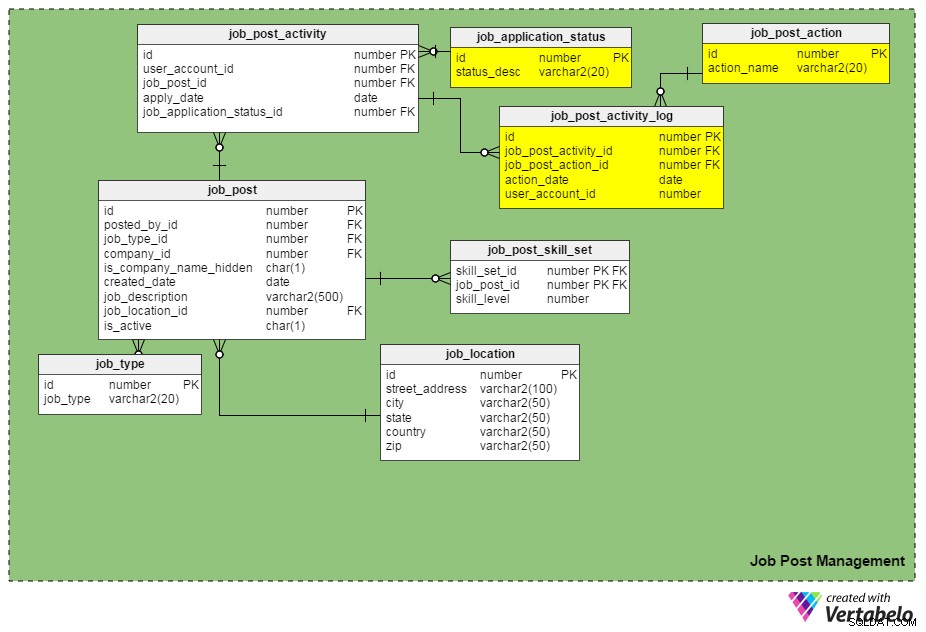
एक और नई तालिका, job_post_activity_log , नौकरी के आवेदनों पर की गई सभी कार्रवाइयों के बारे में जानकारी संग्रहीत करता है, जिसने कार्रवाई की, और इसे कब किया गया। इस तालिका में निम्नलिखित कॉलम हैं:
id- तालिका की प्राथमिक कुंजी।job_post_activity_id- आवेदन आईडी जिस पर कार्रवाई की जाती है।job_post_action_id- की गई कार्रवाई की आईडी। यह एक विदेशी कुंजी है जोjob_post_actionटेबल। हम यहां जिस प्रकार की कार्रवाइयां संग्रहीत कर सकते हैं उनमें 'सबमिट', 'देखा', 'साक्षात्कार', 'लिखित परीक्षा', 'प्रक्रिया में प्रस्ताव', 'प्रस्ताव भेजा गया', 'स्वीकृत प्रस्ताव' आदि शामिल हैं।action_date- वह तारीख जब कोई कार्रवाई की गई थी।user_account_id- कार्रवाई करने वाले व्यक्ति की आईडी।
क्या "job_post_action" "job_application_status" के समान है? वे किस प्रकार भिन्न हैं?
वे पहली बार में एक जैसे लगते हैं, लेकिन वास्तव में वे अलग हैं। हमें दो समान क्षेत्रों की आवश्यकता के वैध कारण हैं:
- एक उम्मीदवार का साक्षात्कार दो या दो से अधिक लोगों द्वारा अलग-अलग किया जाता है। इस मामले में, नौकरी के आवेदन की स्थिति वही रहती है (यानी 'भर्ती प्रक्रिया से गुजरना') जब तक कि सभी साक्षात्कार दौर पूरे नहीं हो जाते। हालांकि, प्रत्येक व्यक्तिगत साक्षात्कारकर्ता के रिकॉर्ड
job_post_activity_logतालिका, और उनके पास 'साक्षात्कार' की कार्रवाई है। - एक आवेदन को एक ही कंपनी में एक से अधिक भर्तीकर्ता देख सकते हैं। इन दो विशेषताओं का उपयोग करके, आप किसी आवेदक की जानकारी नहीं खोएंगे।
- चयनित उम्मीदवार को प्रस्ताव देना कई अनुमोदनों के अधीन है (यानी वित्त टीम से अनुमोदन, भर्ती विभाग प्रबंधक से अनुमोदन, और इसी तरह)। इस मामले में, नौकरी के आवेदन की स्थिति 'समीक्षा के तहत प्रस्ताव' बनी रहती है, लेकिन डेटाबेस लॉग कर सकता है कि कौन से अनुमोदन आए हैं और कौन से नहीं
job_post_activity_logटेबल.
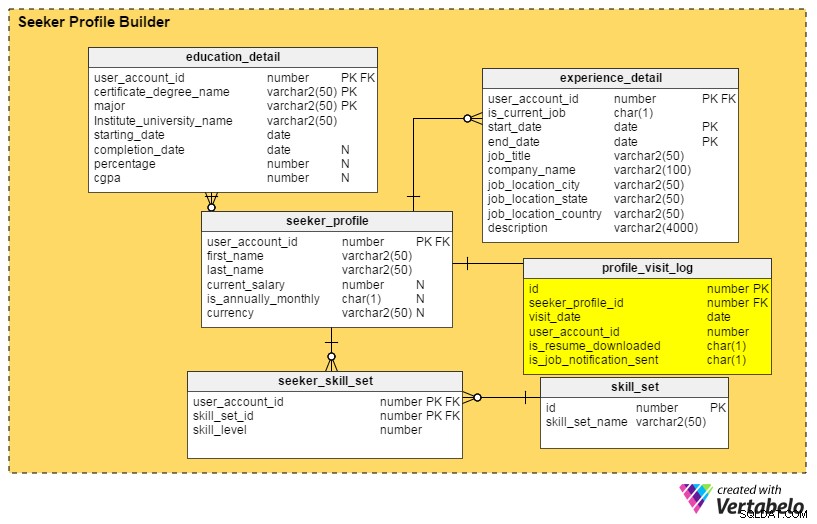
एन्हांसमेंट# 2:एक प्रोफ़ाइल डैशबोर्ड
उत्तर देने के लिए प्रश्न: हाल ही में मेरी प्रोफ़ाइल किसने ढूंढी है? पिछले महीने, सप्ताह या दिन में नियोक्ताओं द्वारा इसे कितनी बार देखा गया? क्या शीर्ष कंपनियों के नियोक्ताओं ने मेरी प्रोफ़ाइल देखी?
इन सभी सवालों के जवाब profile_visit_log टेबल। यह तालिका सभी प्रोफ़ाइल विज़िट डेटा को कैप्चर करती है, जिसमें किसी प्रोफ़ाइल को किसने देखा, कब देखा, इत्यादि शामिल हैं। इस तालिका में कॉलम हैं:
id- तालिका की प्राथमिक कुंजी।seeker_profile_id- कौन सी प्रोफ़ाइल देखी गई थी।visit_date- जब प्रोफ़ाइल को एक्सेस किया गया था।user_account_id- प्रोफ़ाइल किसने देखी।is_resume_downloaded- एक फ़्लैग कॉलम जो दर्शाता है कि विज़िट के दौरान संबंधित रेज़्यूमे डाउनलोड किया गया था या नहीं। यह कॉलम हमें यह जानने में मदद करेगा कि रिक्रूटर्स कितनी बार रिज्यूमे डाउनलोड करते हैं।is_job_notification_sent- एक और फ़्लैग कॉलम, यह बताता है कि प्रोफ़ाइल के मालिक को नौकरी की सूचना भेजी गई थी या नहीं।
एन्हांसमेंट# 3:सशुल्क सेवा प्रबंधन
उत्तर देने के लिए प्रश्न: ऑनलाइन पोर्टल अतिरिक्त भुगतान सेवाओं का लाभ कैसे उठा सकते हैं?
नौकरियों को पोस्ट करने और खोजने के लिए एक मंच के अलावा, कई ऑनलाइन पोर्टल अन्य सेवाएं प्रदान करते हैं, जैसे विशेषज्ञ रिज्यूम बिल्डिंग, करियर परामर्श, आदि। वे नौकरी चाहने वालों को अपने सपनों के शहर में अपने सपनों की नौकरी खोजने में मदद करने के लिए उत्पाद भी प्रदान करते हैं। उदाहरण के लिए, प्रमुख नौकरी साइटों में से एक एक ऐसा उत्पाद पेश करती है जो आपकी प्रोफ़ाइल को भर्ती करने वालों की सूची में सबसे ऊपर रखता है ताकि आप अधिक साक्षात्कार प्रस्ताव प्राप्त कर सकें। इनमें से अधिकतर उत्पाद या सेवाएं सदस्यता के आधार पर उपलब्ध हैं। जब कोई उपयोगकर्ता कोई सेवा या उत्पाद खरीदता है, तो वे उस उत्पाद या सेवा के उपयोग के लिए एक विशिष्ट समय अवधि (यानी एक महीने, तीन महीने, एक वर्ष) में भुगतान करते हैं।
जब मैंने इन जॉब पोर्टल्स को देखा, तो मैंने देखा कि शायद ही कोई उत्पाद या सेवा अकेले पेश की जाती है। अधिकांश भाग के लिए, कई उत्पादों और सेवाओं को एक पैकेज में एक साथ बंडल किया जाता है, और यह पैकेज नौकरी चाहने वालों या भर्ती करने वालों को दिया जाता है।
इन सभी बातों को ध्यान में रखते हुए, मैं अपनी मौजूदा ऑनलाइन जॉब साइट में सशुल्क सेवाओं और उत्पादों को शामिल करने के लिए निम्नलिखित डेटा मॉडल के साथ आया:
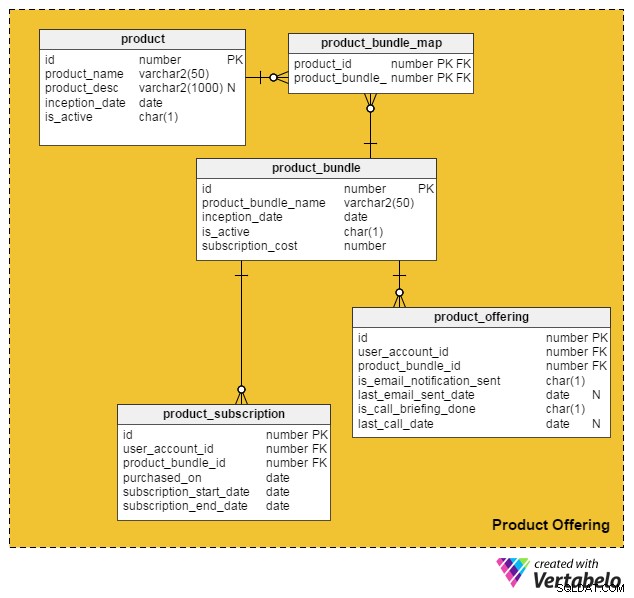
product तालिका व्यक्तिगत उत्पादों के बारे में विवरण रखती है। (हम उत्पादों और सेवाओं दोनों को "उत्पाद" के रूप में संदर्भित करेंगे)। इस तालिका में कॉलम हैं:
id- इस तालिका की प्राथमिक कुंजी, जो हमारे पोर्टल पर पेश किए जाने वाले प्रत्येक उत्पाद को एक विशिष्ट आईडी देती है।product_name- उत्पाद का नाम रखता है।product_desc- उत्पाद का संक्षिप्त विवरण संग्रहीत करता है।inception_date- वह तारीख जब कोई उत्पाद पेश किया गया था।is_active- उत्पाद सक्रिय है या नहीं।
चूंकि उत्पादों और सेवाओं को एक साथ बंडल में जोड़ा जा सकता है और ग्राहकों को पेश किया जा सकता है, इसलिए मैंने product_bundle ऐसे सभी बंडलों के रिकॉर्ड को स्टोर करने के लिए टेबल। विशेषताएं हैं:
id– तालिका की प्राथमिक कुंजी, जो प्रत्येक उत्पाद बंडल के लिए एक अद्वितीय आईडी प्रदान करती है।product_bundle_name- बंडल का नाम स्टोर करता है।inception_date- वह तारीख जब बंडल पेश किया गया था।is_active- यह दर्शाता है कि बंडल सक्रिय है या नहीं।subscription_cost- बंडल के लिए मांगी गई कीमत को स्टोर करता है।
क्या ग्राहकों को एक ही उत्पाद पेश किया जा सकता है?
हां। इस डेटा मॉडल में, एक एकल उत्पाद का अपना "बंडल" हो सकता है। निम्न तालिकाएँ इसे और कुछ अन्य महत्वपूर्ण कार्यों को संभालती हैं।
product_bundle_map तालिका उन सभी उत्पादों की सूची संग्रहीत करती है जो एक बंडल का हिस्सा हैं। इसकी विशेषताएँ स्व-व्याख्यात्मक हैं।
अगली तालिका, product_subscription , तब चलन में आता है जब ग्राहक उत्पाद बंडलों की सदस्यता लेते हैं। यह विवरण दर्ज करता है कि ग्राहकों ने किन बंडलों को लिखा है। इस तालिका में कॉलम हैं:
id- तालिका की प्राथमिक कुंजी।user_account_id- वह उपयोगकर्ता जिसने बंडल खरीदा है।product_bundle_id- उपयोगकर्ता द्वारा खरीदा गया उत्पाद बंडल।purchased_on- खरीद की तारीख।subscription_start_date- वह तारीख जब सदस्यता शुरू होती है। ध्यान दें कि उत्पाद की खरीद की तारीख और सदस्यता की शुरुआत की तारीख अलग-अलग हो सकती है। इस प्रकार, हमारे पास इनके लिए दो अलग-अलग कॉलम हैं।subscription_end_date- सदस्यता कब समाप्त होगी।
अंतिम तालिका, product_offering , मुख्य रूप से विपणन के लिए उपयोग किया जाता है। आमतौर पर जॉब पोर्टल उपयोगकर्ताओं की हाल की गतिविधियों (नौकरी चाहने वालों और भर्ती करने वालों दोनों) का विश्लेषण करते हैं और फिर तय करते हैं कि कौन से उत्पाद किन उपयोगकर्ताओं के लिए फायदेमंद होंगे। फिर वे चुनिंदा पेशकशों के साथ ग्राहकों से संपर्क करने के लिए ईमेल या फोन कॉल का उपयोग करते हैं। इस तालिका के लिए कॉलम हैं:
id- तालिका की प्राथमिक कुंजी।user_account_id- वह उपयोगकर्ता जिसे जॉब पोर्टल लक्षित कर रहा है।product_bundle_id- उत्पाद बंडल जो पोर्टल विपणक ने उपयोगकर्ता से मिलान किया है।is_email_notification_sent- क्या उत्पाद की पेशकश के संबंध में कोई ईमेल भेजा गया है।last_email_sent_date- जब उपयोगकर्ता को पिछली बार मार्केटिंग टीम से उत्पाद ईमेल प्राप्त हुआ था। विपणक के लिए उपयोगकर्ता को कई सूचनाएं भेजना और समय-समय पर अन्य सूचनाएं भेजना आम बात है। यह कॉलम उस तारीख को संग्रहीत करता है जब अंतिम अधिसूचना भेजी गई थी।is_call_briefing_done- क्या ग्राहक को किसी उत्पाद के बारे में जानकारी देते हुए फोन आया था।last_call_date-सबसे हालिया टेलीफोन कॉल की तारीख। ग्राहकों को कई कॉल (फॉलो-अप कॉल) की जा सकती हैं।
एन्हांसमेंट# 4:आवेदन-पूर्व फॉर्म प्रबंधन
उत्तर देने के लिए प्रश्न: एक भर्तीकर्ता सभी संभावित नौकरी उम्मीदवारों द्वारा भरा गया एक अनुकूलित सहमति फॉर्म कैसे प्राप्त कर सकता है?
कई बार, नौकरी चाहने वालों को किसी पद के लिए आवेदन करते समय विशिष्ट प्रश्नों का उत्तर देना पड़ता है। इसमें आमतौर पर आपराधिक पृष्ठभूमि की जांच के लिए सहमति देने जैसी चीजें शामिल होती हैं। हालाँकि, कई अन्य प्रकार की सहमतिएँ हैं जिनकी आवश्यकता हो सकती है। उदाहरण के लिए, मार्केटिंग में नौकरी के लिए बहुत सारी यात्रा की आवश्यकता हो सकती है; बिजनेस प्रोसेस आउटसोर्सिंग (बीपीओ) में नौकरियों के लिए कर्मचारियों को कब्रिस्तान (यानी देर रात) की पाली में काम करना पड़ सकता है। इन्हें पूर्व-आवेदन प्रपत्रों में संबोधित किया जाता है।
नौकरी आवेदन जमा करते समय सहमति प्राप्त करना हमेशा सर्वोत्तम होता है। इस तरह, इन आवश्यकताओं को पूरा करने के इच्छुक उम्मीदवार नौकरी के लिए आवेदन नहीं करेंगे।
डेटा मॉडल पर जाने से पहले, मुझे पहले सहमति फ़ॉर्म के बारे में कुछ बुनियादी तथ्यों पर प्रकाश डालना चाहिए:
- एक नौकरी पोस्ट में एक से अधिक सहमति फ़ॉर्म हो सकते हैं।
- प्रत्येक सहमति फॉर्म में विभिन्न अनुभागों से जुड़े विभिन्न प्रश्न होते हैं।
- एक प्रश्न को अनिवार्य या वैकल्पिक के रूप में सेट किया जा सकता है, यह इस बात पर निर्भर करता है कि प्रश्न को फॉर्म में कैसे टैग किया गया है। एक प्रश्न एक रूप में वैकल्पिक और दूसरे रूप में अनिवार्य हो सकता है।
- प्रत्येक प्रश्न का उत्तर या तो (1) हां, (2) नहीं, या (3) लागू नहीं हो सकता है।
- सभी उत्तर रिकॉर्ड किए जाएंगे।
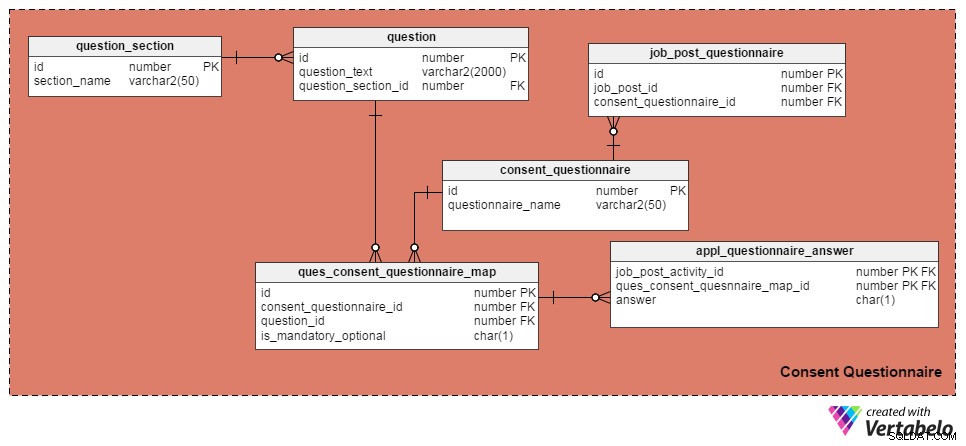
मैंने प्रश्नों और सहमति प्रपत्रों को प्रबंधित करने के लिए निम्नलिखित चार तालिकाओं का उपयोग किया है। पहला, question तालिका, प्रश्नों की एक सूची रखती है। इसमें ये विशेषताएं हैं:
id- तालिका की प्राथमिक कुंजी, जो प्रत्येक प्रश्न के लिए एक विशिष्ट आईडी नंबर देती है।question_text- वास्तविक प्रश्न पाठ संग्रहीत करता है।question_section_id- वह खंड जहां प्रश्न दिखाई देता है। (उदाहरण के लिए "क्या आपने कम से कम पांच वर्षों के लिए सॉफ्टवेयर विकास में काम किया है?" "कार्य अनुभव" अनुभाग में दिखाई देगा।) यह एक विदेशी कुंजी कॉलम है जिसेquestion_sectionटेबल.
question_section टेबल स्टोर अनुभाग की जानकारी। यह एक ही विषय से संबंधित प्रश्नों को समूहबद्ध करने का एक तरीका है। id . के अलावा विशेषता, जो तालिका के लिए प्राथमिक कुंजी है, एकमात्र विशेषता section_name . है , जो स्व-व्याख्यात्मक है।
consent_questionnaire तालिका सहमति प्रपत्र नाम रखती है। इसकी दो विशेषताएँ भी स्व-व्याख्यात्मक हैं।
ques_consent_questionnaire_map तालिका इस विषय क्षेत्र का मूल है। इस विषय क्षेत्र की अन्य सभी तालिकाएँ प्रत्यक्ष या अप्रत्यक्ष रूप से इससे जुड़ी हैं। इसका उद्देश्य सहमति प्रपत्रों में टैग किए गए प्रश्नों की एक सूची रखना है। इस तालिका में कॉलम हैं:
id- इस तालिका की प्राथमिक कुंजी।consent_questionnaire_id- सहमति फॉर्म का आईडी नंबर।question_id- प्रश्न का आईडी नंबर।is_mandatory_optional- यह दर्शाता है कि दिए गए सहमति फॉर्म के लिए प्रश्न अनिवार्य है या वैकल्पिक। एक प्रश्न एकाधिक सहमति प्रपत्रों का हिस्सा हो सकता है, लेकिन यह कुछ में अनिवार्य और अन्य में वैकल्पिक हो सकता है। इस कॉलम कोquestionटेबल.
अगले कुछ टेबल में हम अलग-अलग जॉब पोस्ट के लिए टैग सहमति फॉर्म पर चर्चा करेंगे और उम्मीदवारों के जवाब रिकॉर्ड करेंगे। आइए job_post_questionnaire तालिका, जो इस बारे में जानकारी संग्रहीत करती है कि कौन से सहमति प्रपत्र नौकरी पोस्ट का हिस्सा हैं। जॉब पोस्ट के साथ टैग किए गए एक या अधिक सहमति फॉर्म हो सकते हैं। इस तालिका में कॉलम हैं:
id- तालिका की प्राथमिक कुंजी।job_post_id- यह दर्शाता है कि सहमति फ़ॉर्म को किस नौकरी के बाद टैग किया गया है।consent_questionnaire_id- सहमति फ़ॉर्म को नौकरी की पोस्ट से टैग किया गया है.
इसके बाद, appl_questionnaire_answer तालिका आवेदकों द्वारा भरे गए प्रत्येक सहमति फॉर्म प्रश्न के व्यक्तिगत उत्तरों को लॉग करती है। इस तालिका में कॉलम हैं:
job_post_activity_id-job_post_activityटेबल। यह उस उम्मीदवार के बारे में जानकारी संग्रहीत करता है जिसने प्रश्न का उत्तर दिया है।quest_consent_quesnnaire_map_id-quest_consent_questionnaire_mapटेबल। यह उस प्रश्न को संग्रहीत करता है जिससे सहमति प्रपत्र का उत्तर दिया जा रहा है।answer- नौकरी आवेदक का वास्तविक उत्तर। मैंने इसे CHAR(1) कॉलम के रूप में रखा है क्योंकि हमारे मॉडल में सभी प्रश्नों का उत्तर 'हां' (उत्तर ='वाई'), 'नहीं' (उत्तर ='एन') या 'लागू नहीं' के रूप में दिया जा सकता है (उत्तर ='एक्स')।
नया और बेहतर ऑनलाइन जॉब पोर्टल डेटा मॉडल
आप नीचे पूरा डेटा मॉडल देख सकते हैं।
आप क्या जोड़ेंगे?
क्या आप हमारे ऑनलाइन जॉब पोर्टल में जोड़ने के लिए अन्य सुविधाओं के बारे में सोच सकते हैं? कृपया अपने विचार कमेंट सेक्शन में साझा करें।