दुनिया भर में, जॉब पोर्टल साइट इंटरनेट परिदृश्य की एक प्रसिद्ध विशेषता है। इंडिड और मॉन्स्टर जैसे बड़े खिलाड़ियों ने नौकरी की तलाश और भर्ती को एक वास्तविक ऑनलाइन उद्योग में बदल दिया है। आइए जॉब पोर्टल्स द्वारा उपयोग की जाने वाली प्राथमिक सुविधाओं के बारे में जानें और एक ऐसा डेटा मॉडल बनाएं जो उनका समर्थन कर सके।
लोग तकनीकी नवाचारों का उपयोग करके समय बचाना पसंद करते हैं; ऑनलाइन जॉब पोर्टल बेहतर तरीके से काम करने का एक और संस्करण है, कठिन नहीं। नौकरी चाहने वालों और कंपनियों को समान रूप से अपनी खोज को ऑनलाइन करने में मूल्य का एहसास होता है:उन्हें उच्च गति और कम लागत पर बेहतर पहुंच मिलती है।
कम से कम ट्रैफिक वॉल्यूम के मामले में जॉब पोर्टल उद्योग अब काफी स्थिर है। नौकरी तलाशने वाले इन पोर्टलों का उपयोग कई उद्योगों में पदों को खोजने के लिए कर रहे हैं, आईटी से आगे बढ़कर इंजीनियरिंग, बिक्री, विनिर्माण और वित्तीय सेवाओं जैसे क्षेत्रों में जा रहे हैं। हालाँकि, उन्हें सोशल मीडिया और लिंक्डइन जैसी पेशेवर नेटवर्किंग साइटों से कड़ी प्रतिस्पर्धा मिल रही है। लेकिन अभी भी तलाशने के अवसर हैं, जैसे कि ग्रामीण क्षेत्रों और छोटे शहरों में अपनी पहुंच का विस्तार करना।
इसलिए जैसा कि हमने कहा, हम इस विषय को डेटाबेस डिजाइन के नजरिए से तलाशने जा रहे हैं। आइए जॉब पोर्टल के लिए मूलभूत अपेक्षाओं की गणना के साथ शुरुआत करें।
ऑनलाइन जॉब पोर्टल से लोग क्या उम्मीद करते हैं?
नियोक्ता और नौकरी चाहने वाले दोनों एक ऑनलाइन नौकरी साइट से निम्नलिखित कार्यात्मकताओं की अपेक्षा करते हैं:
- लोग नौकरी चाहने वालों के रूप में पंजीकरण कर सकते हैं, अपनी प्रोफाइल बना सकते हैं, और अपने कौशल से मेल खाने वाली नौकरियों की तलाश कर सकते हैं।
- उपयोगकर्ता अपने मौजूदा रिज्यूमे को अपलोड कर सकते हैं। यदि उनके पास एक नहीं है, तो उन्हें एक फॉर्म भरने और उनके लिए एक बायोडाटा तैयार करने में सक्षम होना चाहिए।
- लोग सीधे पोस्ट की गई नौकरियों के लिए आवेदन कर सकते हैं।
- कंपनियां पंजीकरण कर सकती हैं, नौकरी पोस्ट कर सकती हैं, और नौकरी चाहने वालों की प्रोफाइल खोज सकती हैं।
- एक कंपनी के कई प्रतिनिधियों को पंजीकरण और नौकरी पोस्ट करने में सक्षम होना चाहिए।
- कंपनी के प्रतिनिधि नौकरी के आवेदकों की सूची देख सकते हैं और उनसे संपर्क कर सकते हैं, एक साक्षात्कार की पहल कर सकते हैं या अपने पद से संबंधित कुछ अन्य कार्रवाई कर सकते हैं।
- पंजीकृत उपयोगकर्ता नौकरियों की खोज करने और स्थान, आवश्यक कौशल, वेतन, अनुभव स्तर आदि के आधार पर परिणामों को फ़िल्टर करने में सक्षम होना चाहिए।
डेटा मॉडल बनाना
उपरोक्त आवश्यकताओं पर विचार करने के बाद, मैं तीन व्यापक कार्यात्मक श्रेणियों के साथ आया:
- उपयोगकर्ताओं को प्रबंधित करना - पोर्टल उपयोगकर्ताओं, यानी नौकरी चाहने वालों, मानव संसाधन कर्मियों और स्वतंत्र या परामर्श देने वाले नियोक्ताओं का प्रबंधन कैसे करता है। (इस मॉडल के प्रयोजन के लिए, व्यक्तिगत एचआर प्रतिनिधि और स्वतंत्र या परामर्शी भर्ती करने वालों को कम से कम इस संदर्भ में कि वे पोर्टल का उपयोग कैसे करते हैं, कंपनियों के रूप में माना जाता है।)
- प्रोफाइल बनाना - कैसे पोर्टल नौकरी चाहने वालों और संगठनों को प्रोफाइल और रिज्यूमे बनाने की अनुमति देता है।
- नौकरियों की पोस्टिंग और तलाश करना - पोर्टल नौकरियों के लिए पोस्टिंग, खोज और आवेदन करने की प्रक्रिया को कैसे सुगम बनाता है।
आइए इनमें से प्रत्येक क्षेत्र को अलग-अलग देखें।
<एच3>1. उपयोगकर्ताओं को प्रबंधित करना 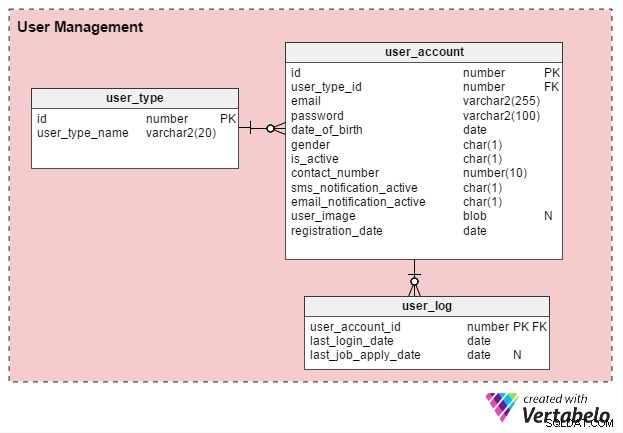
मुख्य रूप से दो प्रकार के ऑनलाइन जॉब पोर्टल उपयोगकर्ता हैं:व्यक्तिगत नौकरी चाहने वाले और एचआर भर्तीकर्ता (या स्वतंत्र भर्ती सलाहकार)। आइए user_type इन अभिलेखों को संग्रहीत करने के लिए। शुरू करने के लिए, इसके दो रिकॉर्ड होंगे - एक नौकरी चाहने वालों के लिए और दूसरा भर्ती करने वालों के लिए। (हम हमेशा आवश्यकतानुसार अतिरिक्त रिकॉर्ड प्रकार बना सकते हैं।)
उपयोगकर्ताओं को पोर्टल का उपयोग करने से पहले पंजीकरण करना आवश्यक है। user_account तालिका उनके मूल खाता विवरण संग्रहीत करती है। मैंने पहले इस तालिका को "उपयोगकर्ता" नाम देने पर विचार किया था, लेकिन चूंकि उपयोगकर्ता लगभग सभी डेटाबेस में एक सिस्टम-परिभाषित कीवर्ड है, इसलिए मैं "user_account" के साथ रहना पसंद करता हूं।
user_account तालिका में निम्नलिखित स्तंभ हैं:
- आईडी - यह तालिका की प्राथमिक कुंजी और प्रत्येक उपयोगकर्ता के लिए एक विशिष्ट पहचानकर्ता दोनों है। इस आईडी को डेटा मॉडल में अन्य तालिकाओं द्वारा संदर्भित किया जाएगा।
- user_type_id - यह दर्शाता है कि उपयोगकर्ता नौकरी तलाशने वाला है या भर्ती करने वाला।
- ईमेल - इस कॉलम में उपयोगकर्ता का ईमेल पता होता है। यह पोर्टल के लिए एक अन्य उपयोगकर्ता आईडी के रूप में कार्य करता है।
- पासवर्ड - यह एक एन्क्रिप्टेड खाता पासवर्ड संग्रहीत करता है (पंजीकरण के दौरान उपयोगकर्ताओं द्वारा बनाया गया)।
- date_of_birth और लिंग - जैसा कि उनके नाम से पता चलता है, ये कॉलम उपयोगकर्ताओं की जन्मतिथि और लिंग को दर्शाते हैं।
- is_active - प्रारंभ में यह कॉलम "Y" होगा, लेकिन उपयोगकर्ता अपनी प्रोफ़ाइल को निष्क्रिय, या "N" पर सेट कर सकते हैं। यह कॉलम उनकी पसंद को संग्रहित करता है।
- contact_number - यह पंजीकरण के दौरान प्रदान किया गया फोन नंबर (आमतौर पर मोबाइल) है। उपयोगकर्ता इस नंबर पर एसएमएस (पाठ) सूचनाएं प्राप्त कर सकते हैं। यह वही संख्या (या नहीं) हो सकती है, जो नौकरी चाहने वालों की उनके प्रोफाइल या रिज्यूमे में सूचीबद्ध होती है।
- sms_notification_active और email_notification_active - ये कॉलम टेक्स्ट और/या ईमेल के माध्यम से सूचनाएं प्राप्त करने के संबंध में उपयोगकर्ताओं की प्राथमिकताओं को संग्रहीत करते हैं।
- user_image - यह एक BLOB-प्रकार की विशेषता है जो प्रत्येक उपयोगकर्ता की प्रोफ़ाइल छवि को संग्रहीत करती है। चूंकि यह पोर्टल प्रति उपयोगकर्ता केवल एक प्रोफ़ाइल छवि की अनुमति देता है, इसलिए इसे यहां संग्रहीत करना समझ में आता है।
- पंजीकरण_तिथि - यह कॉलम इस बात का रिकॉर्ड रखता है कि उपयोगकर्ता ने पोर्टल के साथ कब पंजीकरण कराया था।
हम एक और टेबल बनाएंगे, user_log , जो उपयोगकर्ताओं की अंतिम लॉगिन तिथि और उनकी अंतिम नौकरी आवेदन तिथि का रिकॉर्ड संग्रहीत करता है। इस ज्ञान से बहुत सी विशेषताएं बनाई जा सकती हैं। उदाहरण के लिए, हम इस जानकारी का उपयोग प्रश्न का उत्तर देने के लिए कर सकते हैं क्या उपयोगकर्ता X सक्रिय रूप से नौकरी की तलाश में है ? यदि हां, तो उन्हें एक प्रभावी रेज़्यूमे बनाने के लिए एक उत्पाद की पेशकश की जा सकती है। जो उपयोगकर्ता सक्रिय रूप से नौकरी की तलाश में नहीं हैं, उन्हें ऐसा कोई प्रस्ताव नहीं मिलेगा।
हम इस अनुभाग को आगे दो क्षेत्रों में विभाजित कर सकते हैं:कंपनी या संगठनात्मक प्रोफ़ाइल, और नौकरी चाहने वाले प्रोफ़ाइल।
कंपनी प्रोफाइल
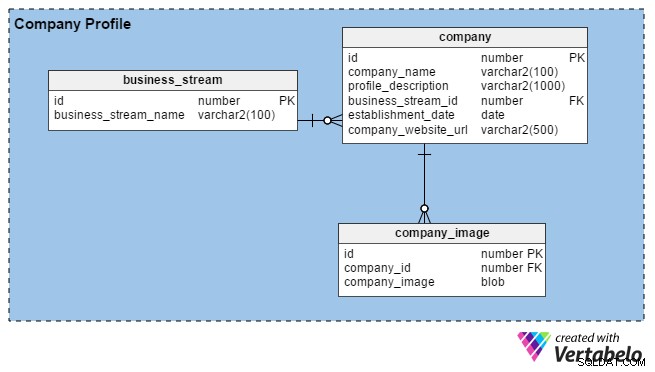
आमतौर पर एचआर टीमें अपने संगठन और अपने कार्यालयों, भवनों आदि की छवियों के बारे में विवरण दर्ज करके कंपनी प्रोफाइल बनाती हैं। उनका मुख्य उद्देश्य अच्छी प्रतिभाओं को आकर्षित करना है। जब भर्तीकर्ता पोर्टल के साथ पंजीकरण करते हैं, तो वे भी कुछ बुनियादी विवरण प्रदान करके अपनी कंपनियों (या उनके व्यक्तिगत ब्रांड, यदि वे स्वतंत्र हैं) की प्रोफाइल बना सकते हैं जैसे कि वे कितने समय से व्यवसाय में हैं, उनका स्थान और उनकी मुख्य व्यवसाय धारा ( जैसे विनिर्माण, आईटी सेवाएं, वित्तीय, आदि)।
पोर्टल एचआर और कंसल्टिंग रिक्रूटर्स को जितनी चाहें उतनी इमेज अपलोड करने की अनुमति देता है (नौकरी चाहने वालों के विपरीत, जो केवल एक अपलोड कर सकते हैं)। इसलिए, हमने company_image प्रत्येक भर्ती खाते के लिए एकाधिक छवियों को संग्रहीत करने के लिए तालिका। company_id इस तालिका में कॉलम एक विदेशी कुंजी है जो company टेबल।
company तालिका, हमारे पास निम्नलिखित कॉलम हैं:
- आईडी - इस तालिका की प्राथमिक कुंजी का उपयोग विशिष्ट रूप से कंपनियों की पहचान करने के लिए भी किया जाता है।
- कंपनी_नाम - जैसा कि कॉलम के नाम से पता चलता है, इसमें कंपनी का कानूनी नाम होता है।
- प्रोफ़ाइल_विवरण - इसमें प्रत्येक कंपनी का संक्षिप्त विवरण होता है।
- business_stream_id - यह कॉलम दर्शाता है कि कंपनी किस बिजनेस स्ट्रीम से संबंधित है। उदाहरण के लिए, एक तेल और गैस की खोज करने वाली कंपनी आईटी इंजीनियरों को काम पर रख सकती है, लेकिन उनका मुख्य व्यवसाय "तेल और गैस" ही रहता है।
- स्थापना_तिथि - यह कॉलम आपको बताता है कि कंपनी कितनी पुरानी है।
- company_website_url - यह एक अनिवार्य (गैर-शून्य) कॉलम है। यह कंपनी की आधिकारिक वेबसाइट के लिए एक संकेतक रखता है ताकि नौकरी चाहने वाले अधिक जानकारी प्राप्त कर सकें।
अंत में, business_stream तालिका में केवल दो विशेषताएं हैं, एक आईडी जो इस तालिका की प्राथमिक कुंजी है, और कंपनी की मुख्य व्यवसाय स्ट्रीम का विवरण (business_stream_name )।
नौकरी चाहने वाले प्रोफाइल
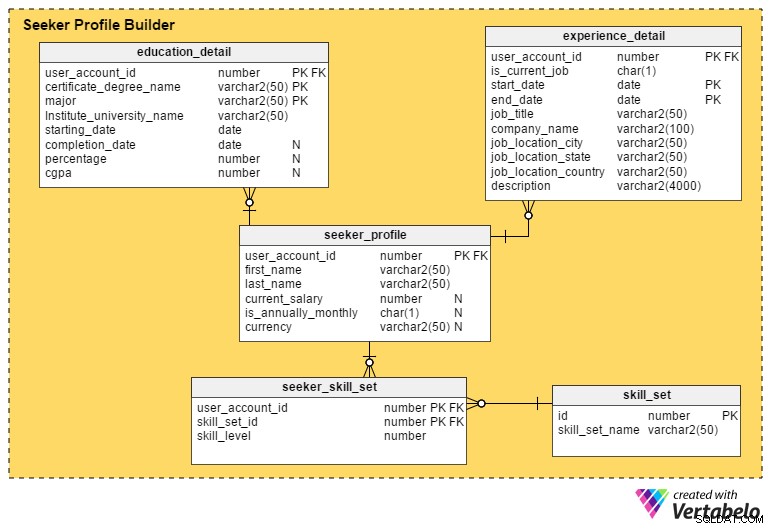
यह जॉब पोर्टल का सबसे महत्वपूर्ण खंड है। जब तक कोई पोर्टल नौकरी चाहने वालों से अधिक से अधिक विवरण प्राप्त नहीं करता है, तब तक भर्ती करने वालों के लिए प्रोफाइल या उम्मीदवारों को शॉर्टलिस्ट करना मुश्किल होता है।
seeker_profile तालिका में अतिरिक्त विवरण हैं जो पंजीकरण प्रक्रिया के दौरान कैप्चर नहीं किए गए थे। इसमें ये फ़ील्ड शामिल हैं:
- user_account_id – यह कॉलम
user_accountतालिका, और यह इस तालिका के लिए प्राथमिक कुंजी के रूप में कार्य करता है। यह सुनिश्चित करता है कि प्रति नौकरी चाहने वाले की अधिकतम एक प्रोफ़ाइल होगी। - प्रथम_नाम और last_name - जैसा कि नाम से पता चलता है, इन कॉलम में नौकरी तलाशने वाले के पहले और अंतिम नाम होते हैं।
- वर्तमान_वेतन - इस विशेषता में नौकरी चाहने वाले का वर्तमान वेतन होता है। यह अशक्त है क्योंकि लोग इसका खुलासा नहीं करना चाहते हैं।
- सालाना_मासिक है - यह परिभाषित करता है कि उनकी वेतन राशि प्रति वर्ष है या प्रति माह।
- मुद्रा - यह वेतन की मुद्रा को स्टोर करता है।
education_detail तालिका प्रत्येक नौकरी चाहने वाले के शैक्षिक इतिहास को संग्रहीत करती है, जैसा कि उनके द्वारा प्रदान किया गया है। इसकी संयुक्त प्राथमिक कुंजी user_account_id . से बनी होती है , प्रमाणपत्र_डिग्री_नाम और प्रमुख स्तंभ। यह सुनिश्चित करता है कि उपयोगकर्ता केवल एक . दर्ज करें प्रत्येक डिग्री या प्रमाण पत्र के लिए रिकॉर्ड। तालिका में ये विशेषताएं हैं:
- user_account_id – यह कॉलम
user_accountतालिका और इस तालिका के लिए प्राथमिक कुंजी के रूप में कार्य करता है। - सर्टिफिकेट_डिग्री_नाम - यह प्रमाणपत्र या डिग्री प्रकार है; जैसे हाई स्कूल, हायर सेकेंडरी, ग्रेजुएट, पोस्ट ग्रेजुएट, या प्रोफेशनल सर्टिफिकेट।
- प्रमुख - इस कॉलम में प्रमाणपत्र या डिग्री के लिए अध्ययन का मुख्य पाठ्यक्रम है - उदा। कंप्यूटर विज्ञान में एक प्रमुख के साथ स्नातक की डिग्री।
- संस्थान_विश्वविद्यालय_नाम - यह वह संस्थान, स्कूल या विश्वविद्यालय है जिसने डिग्री या प्रमाणपत्र प्रदान किया है।
- प्रारंभ_दिनांक - यह विशेषता उस तारीख को संग्रहीत करती है जब उपयोगकर्ता को एक शैक्षिक कार्यक्रम में स्वीकार किया गया था।
- पूर्ण होने की तिथि - यह वह तिथि है जब डिग्री या प्रमाणपत्र प्रदान किया गया था। हालाँकि, यह विशेषता अशक्त है; हो सकता है कि लोग नौकरी की तलाश में अपना कार्यक्रम पूरा कर रहे हों, या हो सकता है कि वे कार्यक्रम से पूरी तरह बाहर हो गए हों।
- प्रतिशत और सीजीपीए - ये कॉलम उपयोगकर्ताओं द्वारा उनकी डिग्री या प्रमाणपत्र पाठ्यक्रम में प्राप्त ग्रेड प्रतिशत या सीजीपीए (संचयी ग्रेड बिंदु औसत) को संग्रहीत करते हैं।
experience_detail तालिका उपयोगकर्ताओं के अतीत और वर्तमान पेशेवर अनुभव का रिकॉर्ड रखती है। इसमें निम्नलिखित महत्वपूर्ण कॉलम हैं:
- user_account_id – यह कॉलम
user_accountतालिका और इस तालिका की प्राथमिक कुंजी है। - is_current_job - यह एक संकेतक कॉलम है जो उपयोगकर्ता की वर्तमान नौकरी को दर्शाता है। यह कॉलम उपयोगकर्ताओं के वर्तमान स्थान और उनकी वर्तमान स्थिति का पता लगाने में भी प्रमुख भूमिका निभाता है।
- प्रारंभ_तिथि - यह तब स्टोर होता है जब उपयोगकर्ता कोई काम शुरू करता है।
- समाप्ति तिथि - यह तब संग्रहीत होता है जब कोई उपयोगकर्ता नौकरी समाप्त करता है।
- job_title - इसमें उपयोगकर्ता की नौकरी की भूमिका के बारे में जानकारी होती है।
- कंपनी_नाम - यह विशेषता नौकरी से संबंधित कंपनी का नाम रखती है।
- job_location_city - यह उस शहर को दर्शाता है जहां नौकरी स्थित थी।
- job_location_state - यह उस राज्य को दर्शाता है जहां नौकरी स्थित थी।
- job_location_country - यह उस देश को दर्शाता है जहां नौकरी स्थित थी।
- विवरण - यह कॉलम नौकरी की भूमिकाओं और जिम्मेदारियों, चुनौतियों और उपलब्धियों के बारे में विवरण संग्रहीत करता है।
नौकरी चाहने वालों के पास कई कौशल हो सकते हैं। इन सभी कौशल सेटों का रिकॉर्ड रखने के लिए, हम seeker_skill_set . कॉलम हैं:
- user_account_id – यह कॉलम
user_accountतालिका और इस तालिका की प्राथमिक कुंजी है। - कौशल_सेट_आईडी - यह आईडी दर्शाता है कि उपयोगकर्ता के पास कौन सा कौशल है।
- कौशल_स्तर - यह संख्यात्मक विशेषता किसी विशेष कौशल में नौकरी चाहने वालों की विशेषज्ञता को निर्धारित करती है। 1 (शुरुआती) से 10 (विशेषज्ञ) तक की संख्या उनके अनुभव के स्तर को दर्शाती है।
अंत में, skill_set तालिका में उपरोक्त तालिका के skill_set_id में उल्लिखित सभी कौशलों का विवरण है गुण। इसमें केवल दो कॉलम हैं, एक skill_set_name और इससे संबंधित आईडी ।
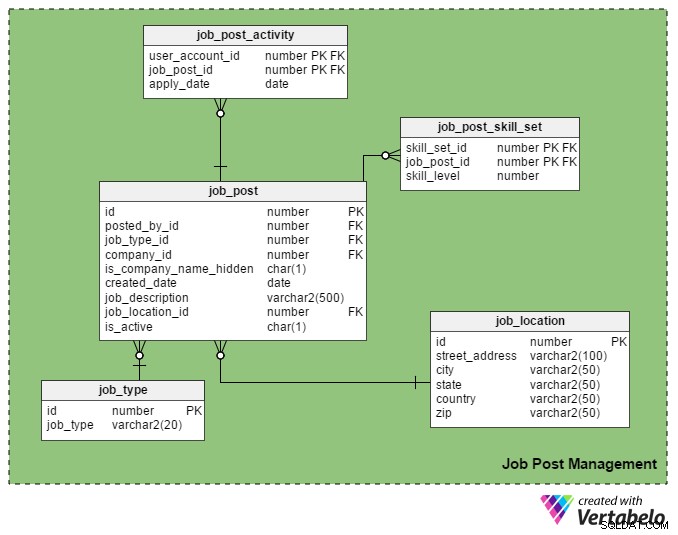
यह जॉब पोर्टल की मुख्य यूएसपी (यूनीक सेलिंग प्वाइंट) है। केवल पंजीकृत भर्तीकर्ताओं को ही पोर्टल पर नौकरी पोस्ट करने की अनुमति है और केवल पंजीकृत नौकरी चाहने वालों को ही उनके लिए आवेदन करने की अनुमति है।
job_post तालिका इस विषय क्षेत्र में मुख्य तालिका है। जैसा कि आप अनुमान लगा सकते हैं, इसमें नौकरी के पदों के बारे में विवरण है। इस खंड की अन्य सभी तालिकाएँ इसके चारों ओर बनाई गई हैं और इससे जुड़ी हुई हैं।
- आईडी - यह इस तालिका की प्राथमिक कुंजी है। प्रत्येक जॉब पोस्ट को एक विशिष्ट संख्या दी जाती है, और इस संख्या को अन्य तालिकाओं में संदर्भित किया जाता है।
- posted_by_id - इस कॉलम में register_user_id है भर्ती करने वाले के बारे में जिसने नौकरी पोस्ट की है।
- job_type_id - यह कॉलम दर्शाता है कि नौकरी की अवधि स्थायी है या अस्थायी (अनुबंध)।
- company_id - यह कॉलम जॉब पोस्ट से संबंधित कंपनी की आईडी को स्टोर करता है। यह
companyटेबल. - is_company_name_hidden - यह एक फ्लैग कॉलम है जो दिखाता है कि नौकरी चाहने वालों को कंपनी का नाम दिखाया जाना चाहिए या नहीं। भर्तीकर्ता अपने पद पर कंपनी के नाम नहीं दिखाना पसंद कर सकते हैं। इसके बजाय वे 'ग्लोबल ऑटोमोबाइल कंपनी', 'कैलिफ़ोर्निया-आधारित आईटी कंपनी', आदि जैसे शब्दों का उपयोग करते हैं।
- बनाई गई तारीख - यह उस तारीख को संग्रहीत करता है जब नौकरी पोस्ट की जाती है।
- job_description - इसमें नौकरी का संक्षिप्त विवरण होता है।
- job_location_id - यह
job_locationतालिका जो नौकरी के वास्तविक स्थान को संग्रहीत करती है:सड़क का पता, शहर, राज्य, देश और डाक कोड। - is_active - यह दर्शाता है कि नौकरी अभी भी खुली है या नहीं। जैसे ही पद भरे जाते हैं, भर्तीकर्ता अपने पदों को निष्क्रिय के रूप में चिह्नित कर सकते हैं।
job_post_skill_set तालिका नौकरी के लिए आवश्यक कौशल सेट के बारे में विवरण संग्रहीत करती है। तालिका संरचना seeker_skill_set टेबल।
और इस अनुभाग की अंतिम तालिका, job_post_activity तालिका, विवरण रखती है कि नौकरी के लिए कौन से नौकरी चाहने वाले और कब आवेदन करते हैं।
आप इस ऑनलाइन जॉब पोर्टल डेटा मॉडल में क्या जोड़ेंगे?
आज के ऑनलाइन जॉब पोर्टल नौकरियों के लिए पोस्ट करने और आवेदन करने के लिए एक मंच प्रदान करने के अलावा और भी बहुत कुछ करते हैं। उनमें अक्सर अन्य पेशेवर सेवाएं शामिल होती हैं जैसे:
- नौकरी के आवेदनों पर नज़र रखने के लिए एक व्यक्तिगत डैशबोर्ड
- एप्लिकेशन पर रीयल-टाइम अपडेट
- वीडियो फिर से शुरू करने वाले निर्माता
- विशेषज्ञ फिर से शुरू-लेखन सेवाएं
- लिंक्डइन या अन्य सोशल मीडिया प्रोफाइल निर्माता
- नौकरी की भूमिकाओं, कंपनियों, उद्योगों, या भौगोलिक स्थानों पर वेतन रिपोर्ट
अगर हम इन सुविधाओं को अपने सिस्टम में बनाना चाहते हैं, तो हमें और क्या बदलाव करने होंगे? क्या आप जॉब पोर्टल में किसी अन्य जरूरी चीज के बारे में सोच सकते हैं?
कृपया हमें अपने विचार कमेंट सेक्शन में बताएं।