पिछले हफ्ते मैंने #BackToBasics नाम से एक पोस्ट प्रकाशित की:DATEFROMPARTS() , जहां मैंने दिखाया कि इस 2012+ फ़ंक्शन का उपयोग क्लीनर, व्यवस्थित तिथि सीमा प्रश्नों के लिए कैसे किया जाता है। मैंने इसका उपयोग यह प्रदर्शित करने के लिए किया है कि यदि आप एक ओपन-एंडेड डेट विधेय का उपयोग करते हैं, और आपके पास प्रासंगिक दिनांक/समय कॉलम पर एक इंडेक्स है, तो आप बेहतर इंडेक्स उपयोग और कम I/O (या, सबसे खराब स्थिति में) के साथ समाप्त कर सकते हैं। , वही, यदि किसी कारण से खोज का उपयोग नहीं किया जा सकता है, या यदि कोई उपयुक्त अनुक्रमणिका मौजूद नहीं है):
लेकिन यह कहानी का केवल एक हिस्सा है (और स्पष्ट होने के लिए, DATEFROMPARTS() तकनीकी रूप से तलाश करने की आवश्यकता नहीं है, यह उस मामले में सिर्फ क्लीनर है)। यदि हम थोड़ा ज़ूम आउट करते हैं, तो हम देखते हैं कि हमारे अनुमान सटीक नहीं हैं, एक जटिलता जिसे मैं पिछली पोस्ट में नहीं बताना चाहता था:
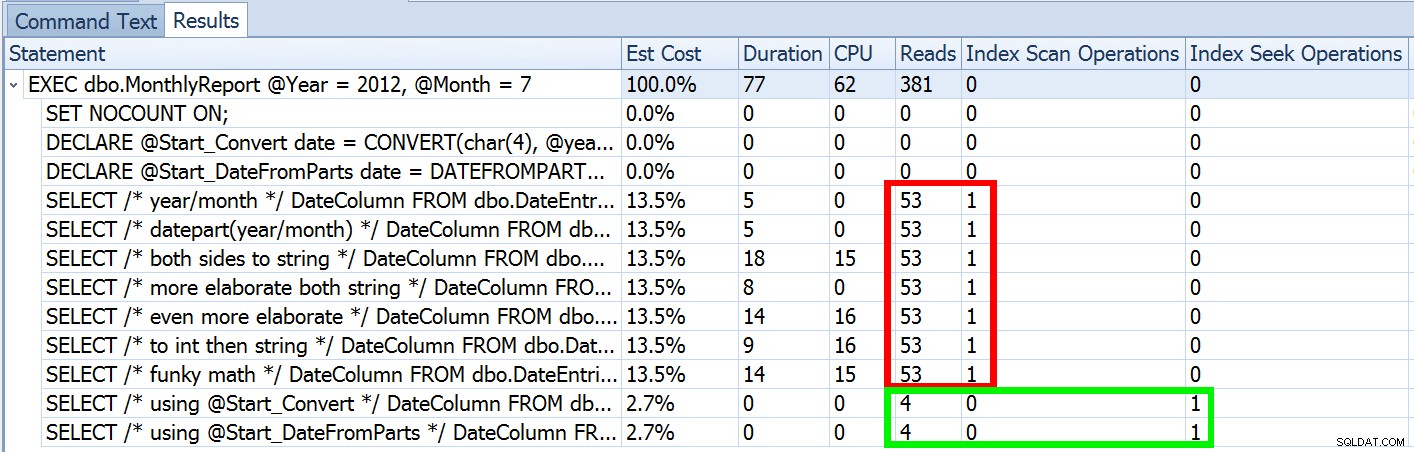
असमानता विधेय और जबरन स्कैन दोनों के लिए यह असामान्य नहीं है। और निश्चित रूप से, क्या मेरे द्वारा सुझाई गई विधि सबसे गलत आँकड़े नहीं देगी? यहां मूल दृष्टिकोण है (आप मेरी पिछली पोस्ट से तालिका स्कीमा, अनुक्रमणिका और नमूना डेटा प्राप्त कर सकते हैं):
CREATE PROCEDURE dbo.MonthlyReport_Original
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO अब, गलत अनुमान हमेशा एक समस्या नहीं होगी, लेकिन यह दो चरम सीमाओं पर अक्षम योजना विकल्पों के साथ समस्या पैदा कर सकता है। एक एकल योजना इष्टतम नहीं हो सकती है जब चुनी हुई श्रेणी तालिका या अनुक्रमणिका का एक बहुत छोटा या बहुत बड़ा प्रतिशत प्राप्त करेगी, और SQL सर्वर के लिए यह अनुमान लगाना बहुत कठिन हो सकता है कि डेटा वितरण कब असमान है। जोसेफ सैक ने अपनी पोस्ट "निष्पादन योजना गुणवत्ता के लिए दस सामान्य खतरे:" में खराब अनुमानों को प्रभावित करने वाली अधिक विशिष्ट चीजों की रूपरेखा तैयार की:
"[...] खराब पंक्ति अनुमान इंडेक्स चयन, तलाश बनाम स्कैन संचालन, समानांतर बनाम सीरियल निष्पादन, एल्गोरिदम चयन में शामिल होने, आंतरिक बनाम बाहरी भौतिक शामिल चयन (उदाहरण के निर्माण बनाम जांच), स्पूल पीढ़ी सहित विभिन्न निर्णयों को प्रभावित कर सकते हैं। बुकमार्क लुकअप बनाम पूर्ण क्लस्टर या हीप टेबल एक्सेस, स्ट्रीम या हैश एग्रीगेट चयन, और डेटा संशोधन एक विस्तृत या संकीर्ण योजना का उपयोग करता है या नहीं।"
स्मृति अनुदान जैसे अन्य भी हैं जो बहुत बड़े या बहुत छोटे हैं। वह खराब अनुमानों के कुछ अधिक सामान्य कारणों का वर्णन करता है, लेकिन इस मामले में प्राथमिक कारण उसकी सूची से गायब है:गेस्स्टिमेट्स। क्योंकि हम आने वाले int . को बदलने के लिए एक स्थानीय चर का उपयोग कर रहे हैं एक स्थानीय date . के लिए पैरामीटर चर, SQL सर्वर नहीं जानता कि मान क्या होगा, इसलिए यह संपूर्ण तालिका के आधार पर कार्डिनैलिटी का मानकीकृत अनुमान लगाता है।
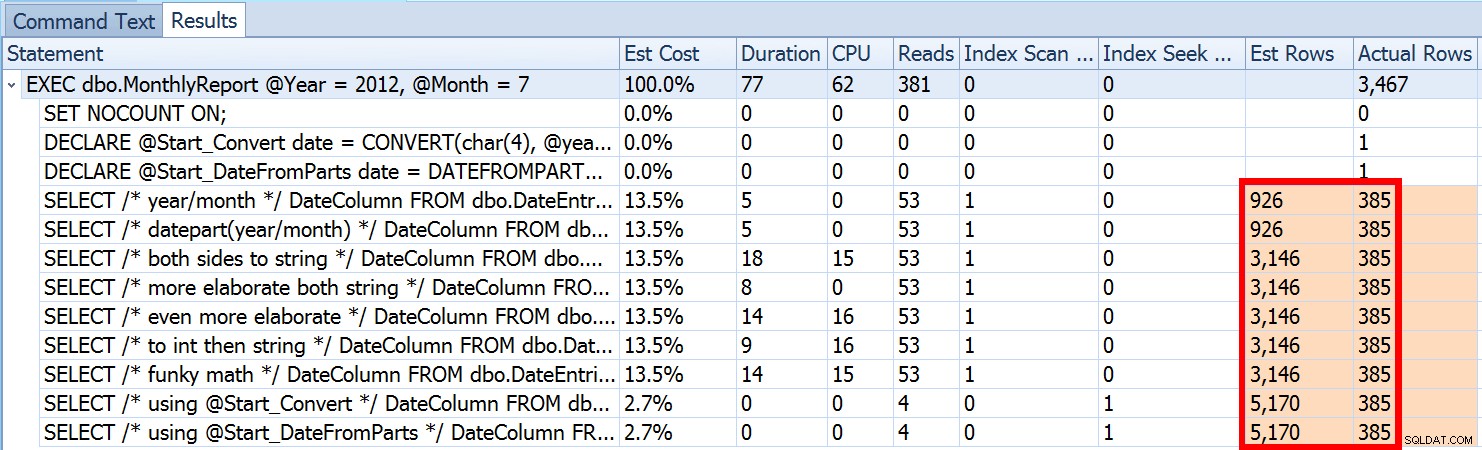
हमने ऊपर देखा कि मेरे सुझाए गए दृष्टिकोण का अनुमान 5,170 पंक्तियों का था। अब, हम जानते हैं कि असमानता विधेय के साथ, और SQL सर्वर पैरामीटर मानों को नहीं जानने के साथ, यह तालिका के 30% का अनुमान लगाएगा। 31,645 * 0.3 5,170 नहीं है। न ही 31,465 * 0.3 * 0.3 . है , जब हमें याद आता है कि वास्तव में एक ही कॉलम के विरुद्ध दो विधेय कार्य कर रहे हैं। तो यह 5,170 मूल्य कहां से आता है?
जैसा कि पॉल व्हाइट ने अपनी पोस्ट में वर्णन किया है, "एकाधिक भविष्यवाणी के लिए कार्डिनैलिटी अनुमान," SQL सर्वर 2014 में नया कार्डिनैलिटी अनुमानक घातीय बैकऑफ़ का उपयोग करता है, इसलिए यह पहले विधेय (0.3) की चयनात्मकता से तालिका की पंक्ति गणना (31,465) को गुणा करता है। , और फिर उसे वर्गमूल . से गुणा करें दूसरे विधेय की चयनात्मकता (~0.547723)।
31,645 * (0.3) * वर्ग (0.3) ~ =5,170.227तो, अब हम देख सकते हैं कि SQL सर्वर अपने अनुमान के साथ कहां आया; इसके बारे में कुछ भी करने के लिए हम किन तरीकों का उपयोग कर सकते हैं?
- तारीख पैरामीटर पास करें। जब संभव हो, आप एप्लिकेशन को बदल सकते हैं ताकि यह अलग पूर्णांक पैरामीटर के बजाय उचित दिनांक पैरामीटर में पास हो जाए।
- रैपर प्रक्रिया का उपयोग करें। विधि # 1 पर एक भिन्नता - उदाहरण के लिए यदि आप एप्लिकेशन को नहीं बदल सकते हैं - एक दूसरी संग्रहीत प्रक्रिया बनाना होगा जो पहले से निर्मित दिनांक पैरामीटर स्वीकार करता है।
OPTION (RECOMPILE)का प्रयोग करें । हर बार क्वेरी चलाने पर संकलन की मामूली लागत पर, यह SQL सर्वर को अज्ञात, पहले, या औसत पैरामीटर मानों के लिए एकल योजना को अनुकूलित करने के बजाय हर बार प्रस्तुत मूल्यों के आधार पर अनुकूलित करने के लिए मजबूर करता है। (इस विषय के गहन उपचार के लिए, पॉल व्हाइट का "पैरामीटर सूँघना, एम्बेड करना, और पुन:संयोजन विकल्प" देखें।
- गतिशील SQL का उपयोग करें। डायनेमिक SQL होने से निर्मित
dateaccept को स्वीकार किया जाता है वेरिएबल उचित पैरामीटराइजेशन को बाध्य करता है (जैसे कि आपनेdate. के साथ एक संग्रहीत कार्यविधि को कॉल किया था पैरामीटर), लेकिन यह थोड़ा बदसूरत है, और इसे बनाए रखना कठिन है।
- संकेतों और ट्रेस फ़्लैग के साथ खिलवाड़ करें। उपरोक्त पोस्ट में पॉल व्हाइट इनमें से कुछ के बारे में बात करते हैं।
मैं यह सुझाव नहीं देने जा रहा हूं कि यह एक विस्तृत सूची है, और मैं संकेत या ट्रेस झंडे के बारे में पॉल की सलाह को दोहराने नहीं जा रहा हूं, इसलिए मैं केवल यह दिखाने पर ध्यान केंद्रित करूंगा कि कैसे पहले चार दृष्टिकोण खराब अनुमानों के साथ समस्या को कम कर सकते हैं ।
- <एच4>1. दिनांक पैरामीटर
CREATE PROCEDURE dbo.MonthlyReport_TwoDates
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Two Dates */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO <एच4>2. आवरण प्रक्रिया CREATE PROCEDURE dbo.MonthlyReport_WrapperTarget
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Wrapper */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO
CREATE PROCEDURE dbo.MonthlyReport_WrapperSource
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
EXEC dbo.MonthlyReport_WrapperTarget @Start = @Start, @End = @End;
END
GO <एच4>3. विकल्प (पुनः संकलित) CREATE PROCEDURE dbo.MonthlyReport_Recompile
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT /* Recompile */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End OPTION (RECOMPILE);
END
GO <एच4>4. गतिशील एसक्यूएल CREATE PROCEDURE dbo.MonthlyReport_DynamicSQL
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
DECLARE @sql nvarchar(max) = N'SELECT /* Dynamic SQL */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;';
EXEC sys.sp_executesql @sql, N'@Start date, @End date', @Start, @End;
END
GO
परीक्षा
प्रक्रियाओं के चार सेटों के साथ, परीक्षणों का निर्माण करना आसान था जो मुझे SQL सर्वर द्वारा प्राप्त योजनाओं और अनुमानों को दिखाएगा। चूंकि कुछ महीने दूसरों की तुलना में अधिक व्यस्त होते हैं, इसलिए मैंने तीन अलग-अलग महीनों को चुना, और उन सभी को कई बार निष्पादित किया।
DECLARE @Year int = 2012, @Month int = 7; -- 385 rows DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1); DECLARE @End date = DATEADD(MONTH, 1, @Start); EXEC dbo.MonthlyReport_Original @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_TwoDates @Start = @Start, @End = @End; EXEC dbo.MonthlyReport_WrapperSource @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_Recompile @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_DynamicSQL @Year = @Year, @Month = @Month; /* repeat for @Year = 2011, @Month = 9 -- 157 rows */ /* repeat for @Year = 2014, @Month = 4 -- 2,115 rows */
परिणाम? प्रत्येक एक योजना समान अनुक्रमणिका खोज उत्पन्न करती है, लेकिन अनुमान केवल सभी तीन दिनांक सीमाओं में सही हैं। OPTION (RECOMPILE) . में संस्करण। शेष पैरामीटर के पहले सेट (जुलाई 2012) से प्राप्त अनुमानों का उपयोग करना जारी रखते हैं, और इसलिए जब वे पहले के लिए बेहतर अनुमान प्राप्त करते हैं निष्पादन, यह अनुमान आवश्यक रूप से बाद के . के लिए बेहतर नहीं होगा विभिन्न मापदंडों का उपयोग करके निष्पादन (पैरामीटर सूँघने का एक क्लासिक, पाठ्यपुस्तक मामला):
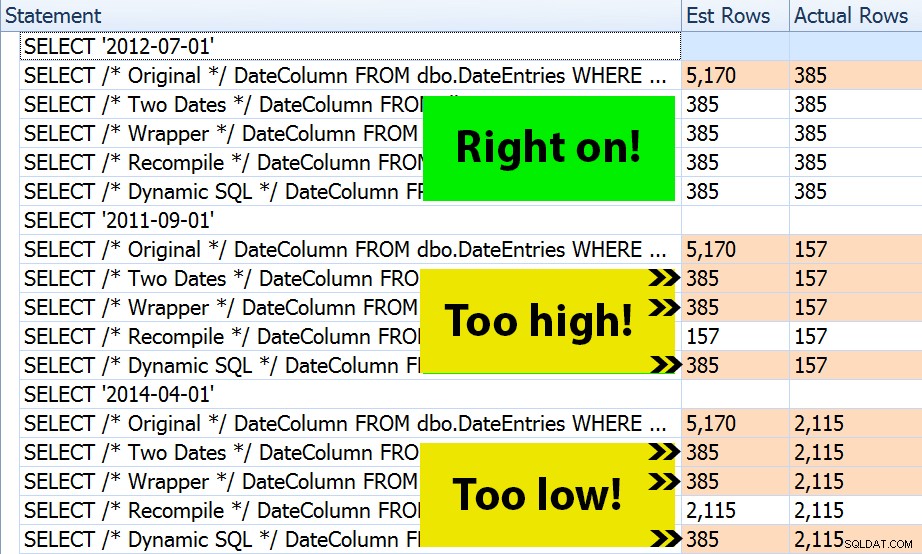
ध्यान दें कि उपरोक्त SQL सेंट्री प्लान एक्सप्लोरर से *सटीक* आउटपुट नहीं है - उदाहरण के लिए, मैंने स्टेटमेंट ट्री पंक्तियों को हटा दिया है जो बाहरी संग्रहीत प्रक्रिया कॉल और पैरामीटर घोषणाओं को दिखाती हैं।
यह निर्धारित करना आपके ऊपर होगा कि क्या हर बार संकलन करने की रणनीति आपके लिए सबसे अच्छी है, या आपको पहली बार में कुछ भी "ठीक" करने की आवश्यकता है या नहीं। यहां, हमने समान योजनाओं के साथ समाप्त किया, और रनटाइम प्रदर्शन मेट्रिक्स में कोई ध्यान देने योग्य अंतर नहीं था। लेकिन बड़ी तालिकाओं पर, अधिक विषम डेटा वितरण के साथ, और विधेय मूल्यों में बड़े भिन्नताएं (उदाहरण के लिए एक रिपोर्ट पर विचार करें जो एक सप्ताह, एक वर्ष और बीच में कुछ भी कवर कर सकती है), यह कुछ जांच के लायक हो सकता है। और ध्यान दें कि आप यहां विधियों को जोड़ सकते हैं - उदाहरण के लिए, आप उचित दिनांक पैरामीटर पर स्विच कर सकते हैं *और* OPTION (RECOMPILE) जोड़ सकते हैं , अगर आप चाहते थे।
निष्कर्ष
इस विशिष्ट मामले में, जो एक जानबूझकर सरलीकरण है, सही अनुमान प्राप्त करने के प्रयास ने वास्तव में भुगतान नहीं किया - हमें एक अलग योजना नहीं मिली, और रनटाइम प्रदर्शन बराबर था। निश्चित रूप से अन्य मामले हैं, हालांकि, इससे फर्क पड़ेगा, और अनुमान असमानता को पहचानना और यह निर्धारित करना महत्वपूर्ण है कि क्या यह एक मुद्दा बन सकता है क्योंकि आपका डेटा बढ़ता है और/या आपके वितरण में कमी आती है। दुर्भाग्य से, कोई श्वेत-श्याम उत्तर नहीं है, क्योंकि कई चर प्रभावित करेंगे कि क्या संकलन ओवरहेड उचित है - जैसा कि कई परिदृश्यों के साथ होता है, IT DEPENDS™ …