यह पोस्ट पंक्ति लक्ष्यों के बारे में एक श्रृंखला का हिस्सा है। आप अन्य भागों को यहाँ पा सकते हैं:
- भाग 1:पंक्ति लक्ष्य निर्धारित करना और उनकी पहचान करना
- भाग 2:सेमी जॉइन
- भाग 3:एंटी जॉइन
एक शीर्ष ऑपरेटर के साथ एंटी जॉइन लागू करें
आप अक्सर एंटी जॉइन लागू करें . में एक इनर-साइड टॉप (1) ऑपरेटर देखेंगे निष्पादन योजनाएं। उदाहरण के लिए, एडवेंचरवर्क्स डेटाबेस का उपयोग करना:
SELECT P.ProductID
FROM Production.Product AS P
WHERE
NOT EXISTS
(
SELECT 1
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
); योजना एक शीर्ष (1) ऑपरेटर को लागू (बाहरी संदर्भ) के अंदर की तरफ एंटी जॉइन दिखाती है:
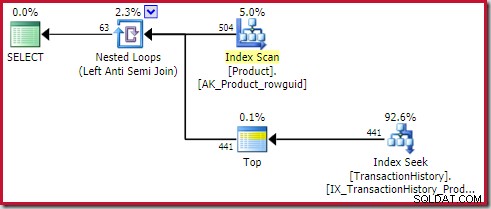
यह शीर्ष ऑपरेटर पूरी तरह से बेमानी है . यह शुद्धता, दक्षता या पंक्ति लक्ष्य निर्धारित करने के लिए आवश्यक नहीं है।
लागू एंटी जॉइन ऑपरेटर जैसे ही जॉइन पर एक पंक्ति दिखाई देता है, आंतरिक पक्ष (वर्तमान पुनरावृत्ति के लिए) पर पंक्तियों की जांच करना बंद कर देगा। शीर्ष के बिना एक लागू एंटी जॉइन प्लान तैयार करना पूरी तरह से संभव है। तो इस योजना में एक शीर्ष ऑपरेटर क्यों है?
शीर्ष ऑपरेटर का स्रोत
यह समझने के लिए कि यह व्यर्थ टॉप ऑपरेटर कहां से आता है, हमें अपनी उदाहरण क्वेरी के संकलन और अनुकूलन के दौरान उठाए गए प्रमुख कदमों का पालन करना होगा।
हमेशा की तरह, क्वेरी को पहले एक ट्री में पार्स किया जाता है। यह एक तार्किक 'अस्तित्व में नहीं है' ऑपरेटर को एक सबक्वेरी के साथ पेश करता है, जो इस मामले में क्वेरी के लिखित रूप से निकटता से मेल खाता है:

मौजूद नहीं है सबक्वेरी एक लागू एंटी जॉइन में अनियंत्रित है:

इसके बाद इसे लॉजिकल लेफ्ट एंटी सेमी जॉइन में बदल दिया जाता है। लागत-आधारित अनुकूलन के लिए पारित परिणामी ट्री इस तरह दिखता है:

लागत-आधारित अनुकूलक द्वारा किया गया पहला अन्वेषण एक तार्किक विशिष्ट . का परिचय देना है एंटी जॉइन कुंजी के लिए अद्वितीय मान उत्पन्न करने के लिए, निचले एंटी जॉइन इनपुट पर ऑपरेशन। सामान्य विचार यह है कि शामिल होने पर डुप्लीकेट मानों का परीक्षण करने के बजाय, योजना को उन मानों को सामने समूहित करने से लाभ हो सकता है।
जिम्मेदार अन्वेषण नियम को LASJNtoLASJNonDist . कहा जाता है (लेफ्ट एंटी सेमी जॉइन टू लेफ्ट एंटी सेमी जॉइन ऑन डिफरेंट)। अभी तक कोई भौतिक कार्यान्वयन या लागत का प्रदर्शन नहीं किया गया है, इसलिए यह केवल एक अनुकूलक है जो डुप्लिकेट ProductID की उपस्थिति के आधार पर तार्किक तुल्यता की खोज कर रहा है। मूल्य। जोड़ा गया ग्रुपिंग ऑपरेशन वाला नया ट्री नीचे दिखाया गया है:

अगला तार्किक परिवर्तन माना जाता है कि एक लागू करें . के रूप में शामिल होने को फिर से लिखना है . इसे LASJNtoApply rule नियम का उपयोग करके खोजा गया है (रिलेशनल सिलेक्शन के साथ अप्लाई करने के लिए लेफ्ट एंटी सेमी जॉइन)। जैसा कि पहले श्रृंखला में उल्लेख किया गया है, लागू से जुड़ने के लिए पहले का परिवर्तन उन परिवर्तनों को सक्षम करना था जो विशेष रूप से जुड़ने पर काम करते हैं। एक आवेदन के रूप में शामिल होने को फिर से लिखना हमेशा संभव होता है, इसलिए यह उपलब्ध अनुकूलन की सीमा का विस्तार करता है।
अब, अनुकूलक हमेशा नहीं करता है लागत-आधारित अनुकूलन के भाग के रूप में लागू पुनर्लेखन पर विचार करें। लॉजिकल ट्री में कुछ ऐसा होना चाहिए जो इसे जोड़ने योग्य बनाने के लिए आंतरिक पक्ष को नीचे की ओर धकेलता है। आमतौर पर, यह एक मेल खाने वाले सूचकांक का अस्तित्व होगा, लेकिन अन्य आशाजनक लक्ष्य भी हैं। इस मामले में, यह ProductID . पर तार्किक कुंजी है कुल संचालन द्वारा बनाया गया।
इस नियम का परिणाम आंतरिक पक्ष पर चयन के साथ एक सहसंबद्ध विरोधी जुड़ाव है:

इसके बाद, ऑप्टिमाइज़र रिलेशनल सिलेक्शन (सहसंबद्ध जॉइन प्रेडिकेट) को आंतरिक पक्ष में और नीचे ले जाने पर विचार करता है, जो पहले ऑप्टिमाइज़र द्वारा पेश किए गए विशिष्ट (ग्रुप बाय एग्रीगेट) से पहले होता है। यह नियम SelOnGbAgg . द्वारा किया जाता है , जो एक उपयुक्त समूह से अधिक से अधिक चयन (विधेय) को कुल मिलाकर आगे बढ़ाता है (चयन का हिस्सा पीछे छोड़ा जा सकता है)। यह गतिविधि चयनों को आगे बढ़ाने . में सहायता करती है पहले पंक्तियों को खत्म करने और बाद में इंडेक्स मिलान को आसान बनाने के लिए, लीफ-लेवल डेटा एक्सेस ऑपरेटरों के जितना संभव हो उतना करीब।
इस मामले में, फ़िल्टर समूहीकरण ऑपरेशन के समान कॉलम पर है, इसलिए परिवर्तन मान्य है। इसके परिणामस्वरूप संपूर्ण चयन को समग्र के अंतर्गत धकेल दिया जाता है:

ब्याज का अंतिम संचालन नियम GbAggToConstScanOrTop . द्वारा किया जाता है . यह परिवर्तन प्रतिस्थापित . जैसा दिखता है लगातार स्कैन या शीर्ष . के साथ समग्र रूप से एक समूह तार्किक संचालन। यह नियम हमारे पेड़ से मेल खाता है क्योंकि पुश-डाउन चयन से गुजरने वाली प्रत्येक पंक्ति के लिए ग्रुपिंग कॉलम स्थिर है। सभी पंक्तियों के समान ProductID . होने की गारंटी है . उस एकल मान पर समूह बनाना हमेशा एक पंक्ति उत्पन्न करेगा। इसलिए, समुच्चय को शीर्ष (1) में बदलना मान्य है। तो यहीं से सबसे ऊपर आता है।
कार्यान्वयन और लागत
ऑप्टिमाइज़र अब तक प्रत्येक होनहार तार्किक विकल्प के लिए भौतिक ऑपरेटरों को खोजने के लिए कार्यान्वयन नियमों की एक श्रृंखला चलाता है जिसे उसने अब तक माना है (एक ज्ञापन संरचना में कुशलता से संग्रहीत)। हैश और मर्ज एंटी जॉइन फिजिकल ऑप्शंस प्रारंभिक ट्री से शुरू किए गए एग्रीगेट से आते हैं (सौजन्य से नियम LASJNtoLASJNonDist याद रखना)। फिजिकल टॉप बनाने और चयन को इंडेक्स सीक से मिलाने के लिए आवेदन को थोड़ा और काम करने की आवश्यकता है।
सबसे अच्छा हैश एंटी जॉइन मिले समाधान की कीमत 0.362143 . है इकाइयां:
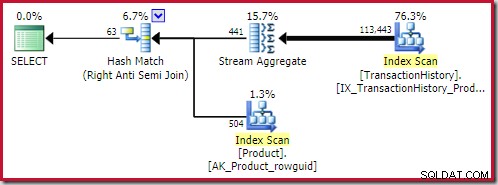
सबसे अच्छा मर्ज एंटी जॉइन समाधान 0.353479 . पर आता है इकाइयाँ (थोड़ा सस्ता):
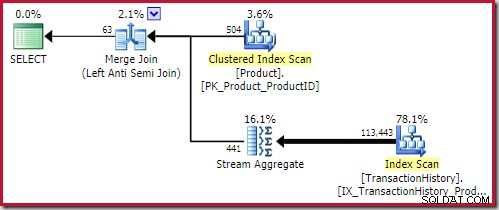
एंटी जॉइन लागू करें लागत 0.091823 इकाइयाँ (एक विस्तृत अंतर से सबसे सस्ता):
चतुर पाठक यह देख सकता है कि लागू एंटी जॉइन (504) के अंदरूनी हिस्से में पंक्तियों की संख्या उसी योजना के पिछले स्क्रीनशॉट से भिन्न है। ऐसा इसलिए है क्योंकि यह एक अनुमानित योजना है, जबकि पिछली योजना निष्पादन के बाद की थी। जब इस योजना को क्रियान्वित किया जाता है, तो सभी पुनरावृत्तियों पर केवल कुल 441 पंक्तियाँ आंतरिक भाग में पाई जाती हैं। यह सेमी/एंटी जॉइन योजनाओं को लागू करने के साथ प्रदर्शन कठिनाइयों में से एक को हाइलाइट करता है:न्यूनतम ऑप्टिमाइज़र अनुमान एक पंक्ति है, लेकिन एक अर्ध या एंटी जॉइन हमेशा प्रत्येक पुनरावृत्ति पर एक पंक्ति या कोई पंक्ति नहीं ढूंढेगा। ऊपर दिखाई गई 504 पंक्तियाँ 504 पुनरावृत्तियों में से प्रत्येक पर 1 पंक्ति का प्रतिनिधित्व करती हैं। संख्याओं का मिलान करने के लिए, अनुमान को हर बार 441/504 =0.875 पंक्तियों की आवश्यकता होगी, जो शायद लोगों को उतना ही भ्रमित करेगा।
वैसे भी, उपरोक्त योजना 'भाग्यशाली' है जो दो कारणों से लागू विरोधी शामिल होने के आंतरिक पक्ष पर एक पंक्ति लक्ष्य के लिए अर्हता प्राप्त करने के लिए पर्याप्त है:
- एंटी जॉइन को जॉइन से कॉस्ट-बेस्ड ऑप्टिमाइज़र में अप्लाई में बदल दिया जाता है। यह एक पंक्ति लक्ष्य निर्धारित करता है (जैसा कि भाग तीन में स्थापित किया गया है)।
- शीर्ष(1) ऑपरेटर अपने सबट्री पर एक पंक्ति लक्ष्य भी निर्धारित करता है।
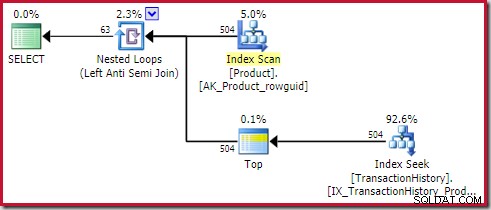
शीर्ष ऑपरेटर के पास स्वयं कोई पंक्ति लक्ष्य नहीं है (लागू होने से) क्योंकि 1 का पंक्ति लक्ष्य कम नहीं होगा नियमित अनुमान की तुलना में, जो 1 पंक्ति भी है (नीचे PhyOp_Top के लिए कार्ड=1):
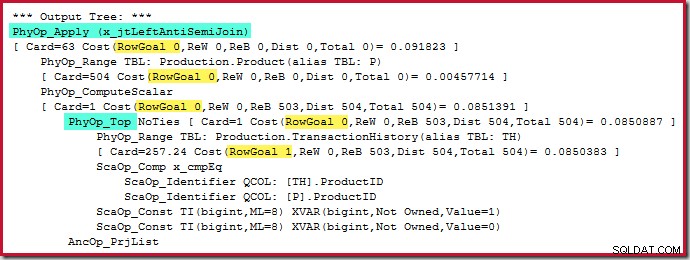
एंटी जॉइन एंटी पैटर्न
निम्नलिखित सामान्य योजना आकार एक है जिसे मैं एक विरोधी पैटर्न के रूप में मानता हूं:
प्रत्येक निष्पादन योजना जिसमें एक शीर्ष (1) ऑपरेटर के साथ आंतरिक पक्ष पर लागू विरोधी शामिल है, समस्याग्रस्त नहीं होगा। फिर भी, यह पहचानने का एक पैटर्न है और एक जिसे लगभग हमेशा आगे की जांच की आवश्यकता होती है।
देखने के लिए चार मुख्य तत्व हैं:
- सहसंबद्ध नेस्टेड लूप (लागू करें ) विरोधी शामिल हों
- एक शीर्ष (1) ऑपरेटर तुरंत भीतर की तरफ
- बाहरी इनपुट पर पंक्तियों की एक महत्वपूर्ण संख्या (इसलिए आंतरिक पक्ष कई बार चलाया जाएगा)
- एक संभावित रूप से महंगा शीर्ष के नीचे उप-वृक्ष
"$$$" सबट्री वह है जो रनटाइम पर संभावित रूप से महंगा है . इसे पहचानना मुश्किल हो सकता है। यदि हम भाग्यशाली हैं, तो पूर्ण तालिका या अनुक्रमणिका स्कैन जैसा कुछ स्पष्ट होगा। अधिक चुनौतीपूर्ण मामलों में, पहली नज़र में सबट्री पूरी तरह से निर्दोष दिखाई देगी, लेकिन अधिक बारीकी से देखने पर इसमें कुछ महंगा होगा। एक बहुत ही सामान्य उदाहरण देने के लिए, आपको एक इंडेक्स सीक दिखाई दे सकता है, जिसमें पंक्तियों की एक छोटी संख्या लौटाने की उम्मीद की जाती है, लेकिन जिसमें एक महंगा अवशिष्ट विधेय होता है, जो बहुत बड़ी संख्या में पंक्तियों का परीक्षण करता है ताकि कुछ योग्य पंक्तियों को ढूंढा जा सके।
पिछले एडवेंचरवर्क्स कोड उदाहरण में "संभावित रूप से महंगा" सबट्री नहीं था। पंक्ति लक्ष्य विचारों की परवाह किए बिना इंडेक्स सीक (अवशिष्ट विधेय के बिना) एक इष्टतम पहुंच विधि होगी। यह एक महत्वपूर्ण बिंदु है:अनुकूलक को हमेशा कुशल . प्रदान करना एक सहसंबद्ध जुड़ाव के अंदरूनी हिस्से पर डेटा एक्सेस पथ हमेशा एक अच्छा विचार है। यह तब और भी सही होता है जब एप्लाइड एक टॉप (1) ऑपरेटर के साथ एंटी जॉइन मोड में चल रहा हो।
आइए अब एक ऐसे उदाहरण को देखें जिसमें इस विरोधी पैटर्न के कारण काफी निराशाजनक रनटाइम प्रदर्शन है।
उदाहरण
निम्न स्क्रिप्ट दो ढेर अस्थायी तालिकाएँ बनाती है। पहली में 500 पंक्तियाँ हैं जिनमें 1 से 500 तक के पूर्णांक शामिल हैं। दूसरी तालिका में कुल 250,000 पंक्तियों के लिए पहली तालिका में प्रत्येक पंक्ति की 500 प्रतियां हैं। दोनों टेबल sql_variant . का इस्तेमाल करते हैं डेटा प्रकार।
DROP TABLE IF EXISTS #T1, #T2;
CREATE TABLE #T1 (c1 sql_variant NOT NULL);
CREATE TABLE #T2 (c1 sql_variant NOT NULL);
-- Numbers 1 to 500 inclusive
-- Stored as sql_variant
INSERT #T1
(c1)
SELECT
CONVERT(sql_variant, SV.number)
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 500;
-- 500 copies of each row in table #T1
INSERT #T2
(c1)
SELECT
T1.c1
FROM #T1 AS T1
CROSS JOIN #T1 AS T2;
-- Ensure we have the best statistical information possible
CREATE STATISTICS sc1 ON #T1 (c1) WITH FULLSCAN, MAXDOP = 1;
CREATE STATISTICS sc1 ON #T2 (c1) WITH FULLSCAN, MAXDOP = 1; प्रदर्शन
अब हम छोटी तालिका में पंक्तियों की तलाश में एक क्वेरी चलाते हैं जो बड़ी तालिका में मौजूद नहीं हैं (निश्चित रूप से कोई भी नहीं हैं):
SELECT
T1.c1
FROM #T1 AS T1
WHERE
NOT EXISTS
(
SELECT 1
FROM #T2 AS T2
WHERE T2.c1 = T1.c1
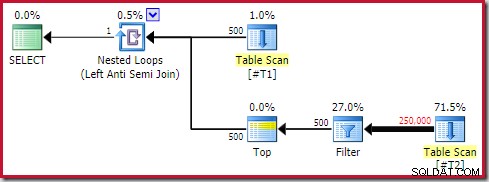
); यह क्वेरी लगभग 20 सेकंड तक चलती है , जो 250,000 के साथ 500 पंक्तियों की तुलना करने के लिए बहुत लंबा समय है। SSMS अनुमानित योजना यह देखना कठिन बना देती है कि प्रदर्शन इतना खराब क्यों हो सकता है:
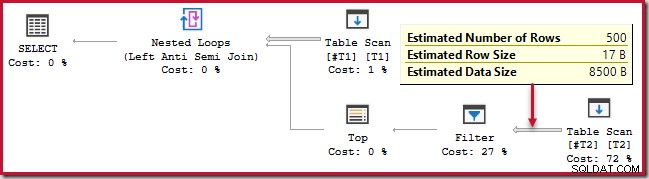
पर्यवेक्षक को पता होना चाहिए कि SSMS अनुमानित योजनाएं प्रति पुनरावृत्ति . आंतरिक पक्ष अनुमान दिखाती हैं नेस्टेड लूप में शामिल हों। भ्रामक रूप से, SSMS वास्तविक योजनाएँ सभी पुनरावृत्तियों . पर पंक्तियों की संख्या दिखाती हैं . अनुमानित योजनाओं के लिए अपेक्षित पंक्तियों की कुल संख्या दिखाने के लिए प्लान एक्सप्लोरर स्वचालित रूप से आवश्यक सरल गणना करता है:
फिर भी, रनटाइम प्रदर्शन अनुमान से बहुत खराब है। निष्पादन के बाद (वास्तविक) निष्पादन योजना है:
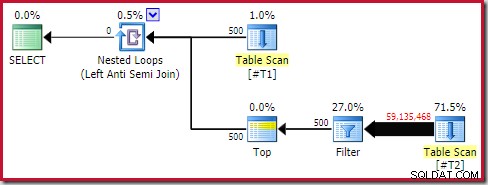
अलग फ़िल्टर पर ध्यान दें, जिसे आम तौर पर एक अवशिष्ट विधेय के रूप में स्कैन में नीचे धकेला जाएगा। sql_variant . का उपयोग करने का यही कारण है डेटा प्रकार; यह विधेय को आगे बढ़ाने से रोकता है, जिससे स्कैन से बड़ी संख्या में पंक्तियों को देखना आसान हो जाता है।
विश्लेषण
विसंगति का कारण नीचे आता है कि कैसे अनुकूलक फ़िल्टर पर निर्धारित एक-पंक्ति लक्ष्य को पूरा करने के लिए टेबल स्कैन से पढ़ने के लिए आवश्यक पंक्तियों की संख्या का अनुमान लगाता है। साधारण धारणा यह है कि मान तालिका में समान रूप से वितरित किए जाते हैं, इसलिए मौजूद 500 अद्वितीय मानों में से 1 का सामना करने के लिए, SQL सर्वर को 250,000 / 500 =500 पंक्तियों को पढ़ने की आवश्यकता होगी। 500 से अधिक पुनरावृत्तियों, जो 250,000 पंक्तियों में आता है।
ऑप्टिमाइज़र की एकरूपता धारणा एक सामान्य है, लेकिन यह यहाँ अच्छी तरह से काम नहीं करती है। आप इसके बारे में जो ओबिश द्वारा एक पंक्ति लक्ष्य अनुरोध में अधिक पढ़ सकते हैं, और टॉप के साथ एक नेस्टेड लूप के इनर साइड पर एक स्कैन की लागत से अधिक घनत्व का उपयोग करें पर कनेक्ट प्रतिस्थापन फ़ीडबैक फ़ोरम पर उनके सुझाव के लिए वोट कर सकते हैं।
इस विशिष्ट पहलू पर मेरा विचार यह है कि ऑप्टिमाइज़र को एक साधारण एकरूपता धारणा से जल्दी से पीछे हटना चाहिए जब ऑपरेटर नेस्टेड लूप के अंदरूनी हिस्से में शामिल हो (यानी अनुमानित रिवाइंड प्लस रिबाइंड एक से अधिक हो)। यह मान लेना एक बात है कि लूप के पहले पुनरावृत्ति पर एक मैच खोजने के लिए हमें 500 पंक्तियों को पढ़ने की जरूरत है। हर पुनरावृत्ति पर यह मानने के लिए सटीक होने की संभावना नहीं है; इसका मतलब है कि सामने आई पहली 500 पंक्तियों में प्रत्येक विशिष्ट मान में से एक होना चाहिए। व्यवहार में ऐसा होने की अत्यधिक संभावना नहीं है।
दुर्भाग्यपूर्ण घटनाओं की एक श्रृंखला
चाहे जिस तरह से बार-बार शीर्ष ऑपरेटरों की कीमत चुकानी पड़े, मुझे ऐसा लगता है कि पूरी स्थिति को पहली जगह से बचना चाहिए . याद करें कि इस योजना में शीर्ष कैसे बनाया गया था:
- ऑप्टिमाइज़र ने प्रदर्शन अनुकूलन के रूप में inner .
- यह समुच्चय परिभाषा के अनुसार जॉइन कॉलम पर एक कुंजी प्रदान करता है (यह विशिष्टता पैदा करता है)।
- यह निर्मित कुंजी एक जुड़ाव से एक आवेदन में रूपांतरण के लिए एक लक्ष्य प्रदान करती है।
- आवेदन से जुड़े विधेय (चयन) को समुच्चय से नीचे धकेल दिया जाता है।
- समुच्चय अब प्रति पुनरावृत्ति एक अलग मूल्य पर संचालित होने की गारंटी है (क्योंकि यह एक सहसंबंध मूल्य है)।
- समग्र को एक शीर्ष (1) से बदल दिया गया है।
ये सभी परिवर्तन व्यक्तिगत रूप से मान्य हैं। वे सामान्य अनुकूलक संचालन का हिस्सा हैं क्योंकि यह एक उचित निष्पादन योजना की खोज करता है। दुर्भाग्य से, यहाँ परिणाम यह है कि अनुकूलक द्वारा पेश किया गया सट्टा समुच्चय एक संबद्ध पंक्ति लक्ष्य के साथ शीर्ष (1) में बदल जाता है। . पंक्ति लक्ष्य एकरूपता की धारणा के आधार पर गलत लागत की ओर ले जाता है, और फिर एक ऐसी योजना का चयन करता है जो अच्छी तरह से प्रदर्शन करने की अत्यधिक संभावना नहीं है।
अब, किसी को आपत्ति हो सकती है कि लागू एंटी जॉइन का वैसे भी एक पंक्ति लक्ष्य होगा - उपरोक्त परिवर्तन अनुक्रम के बिना। प्रतिवाद यह है कि अनुकूलक विचार नहीं करेगा एंटी जॉइन से लागू करें . में परिवर्तन LASJNtoApply देने वाले ऑप्टिमाइज़र द्वारा पेश किए गए एग्रीगेट के बिना एंटी जॉइन (पंक्ति लक्ष्य निर्धारित करना) किसी चीज से बंधने के लिए शासन करना। इसके अलावा, हमने (भाग तीन में) देखा है कि यदि एंटी जॉइन ने लागत-आधारित ऑप्टिमाइज़ेशन को एक आवेदन (शामिल होने के बजाय) के रूप में दर्ज किया था, तो फिर से कोई पंक्ति लक्ष्य नहीं होगा ।
संक्षेप में, अंतिम योजना में पंक्ति लक्ष्य पूरी तरह से कृत्रिम है, और मूल क्वेरी विनिर्देश में इसका कोई आधार नहीं है। शीर्ष और पंक्ति लक्ष्य के साथ समस्या इस अधिक मौलिक पहलू का दुष्प्रभाव है।
समाधान
इस समस्या के कई संभावित समाधान हैं। ऊपर दिए गए ऑप्टिमाइज़ेशन क्रम में किसी एक चरण को हटाने से यह सुनिश्चित होगा कि ऑप्टिमाइज़र नाटकीय रूप से (और कृत्रिम रूप से) कम लागत के साथ एक लागू एंटी जॉइन कार्यान्वयन नहीं करता है। उम्मीद है कि SQL सर्वर में इस समस्या का जल्द ही समाधान किया जाएगा।
इस बीच, मेरी सलाह है कि एंटी जॉइन एंटी पैटर्न से सावधान रहें। सुनिश्चित करें कि लागू एंटी जॉइन के अंदरूनी हिस्से में हमेशा सभी रनटाइम स्थितियों के लिए एक कुशल पहुंच पथ होता है। यदि यह संभव नहीं है, तो आपको संकेतों का उपयोग करने, पंक्ति लक्ष्यों को अक्षम करने, योजना मार्गदर्शिका का उपयोग करने या क्वेरी स्टोर योजना को शामिल करने से रोकने वाली क्वेरी से स्थिर प्रदर्शन प्राप्त करने के लिए बाध्य करने की आवश्यकता हो सकती है।
श्रृंखला सारांश
हमने चार किश्तों में बहुत कुछ कवर किया है, इसलिए यहां एक उच्च स्तरीय सारांश दिया गया है:
- भाग 1 - पंक्ति लक्ष्य निर्धारित करना और उनकी पहचान करना
- क्वेरी सिंटैक्स एक पंक्ति लक्ष्य की उपस्थिति या अनुपस्थिति का निर्धारण नहीं करता है।
- एक पंक्ति लक्ष्य केवल तभी निर्धारित किया जाता है जब लक्ष्य नियमित अनुमान से कम हो।
- भौतिक शीर्ष ऑपरेटर (ऑप्टिमाइज़र द्वारा पेश किए गए सहित) अपने सबट्री में एक पंक्ति लक्ष्य जोड़ते हैं।
- एक
FASTयाSET ROWCOUNTकथन योजना के मूल में एक पंक्ति लक्ष्य निर्धारित करता है। - सेमी जॉइन और एंटी जॉइन हो सकता है एक पंक्ति लक्ष्य जोड़ें।
- SQL सर्वर 2017 CU3 शोप्लान विशेषता जोड़ता है EstimateRowsWithoutRowGoal पंक्ति लक्ष्य से प्रभावित ऑपरेटरों के लिए
- पंक्ति लक्ष्य की जानकारी अनिर्दिष्ट ट्रेस फ़्लैग 8607 और 8612 द्वारा प्रकट की जा सकती है।
- भाग 2 - सेमी जॉइन
- टी-एसक्यूएल में सीधे सेमी जॉइन को व्यक्त करना संभव नहीं है, इसलिए हम इनडायरेक्ट सिंटैक्स का उपयोग करते हैं उदा।
IN,EXISTS, याINTERSECT। - इन सिंटैक्स को एक लागू (सहसंबद्ध जुड़ाव) वाले पेड़ में पार्स किया जाता है।
- अनुकूलक आवेदन को नियमित जुड़ाव में बदलने का प्रयास करता है (हमेशा संभव नहीं)।
- हैश, मर्ज, और नियमित नेस्टेड लूप सेमी जॉइन एक पंक्ति लक्ष्य निर्धारित नहीं करते हैं।
- अर्ध जुड़ाव लागू करें हमेशा एक पंक्ति लक्ष्य निर्धारित करता है।
- नेस्टेड लूप्स जॉइन ऑपरेटर पर आउटर रेफरेंस होने से सेमी जॉइन को लागू किया जा सकता है।
- अर्ध-जुड़ाव लागू करें आंतरिक पक्ष पर शीर्ष (1) ऑपरेटर का उपयोग न करें।
- भाग 3 - एंटी जॉइन
- एक आवेदन में भी पार्स किया गया, इसे एक जुड़ने के रूप में फिर से लिखने के प्रयास के साथ (हमेशा संभव नहीं)।
- हैश, मर्ज, और नियमित नेस्टेड लूप एंटी जॉइन एक पंक्ति लक्ष्य निर्धारित नहीं करते हैं।
- एंटी जॉइन लागू करना हमेशा एक पंक्ति लक्ष्य निर्धारित नहीं करता है।
- केवल लागत-आधारित अनुकूलन (सीबीओ) नियम जो एक पंक्ति लक्ष्य निर्धारित करने के लिए एंटी जॉइन को रूपांतरित करते हैं।
- एंटी जॉइन को सीबीओ में शामिल होना चाहिए (लागू नहीं)। अन्यथा परिवर्तन लागू करने के लिए शामिल नहीं हो सकता।
- सीबीओ को एक जॉइन के रूप में दर्ज करने के लिए, प्री-सीबीओ रीराइट टू अप्लाई टू जॉइन सफल होना चाहिए।
- CBO केवल आशाजनक मामलों में एक आवेदन में शामिल होने के लिए एक विरोधी को फिर से लिखने की खोज करता है।
- पूर्व-सीबीओ सरलीकरण को गैर-दस्तावेज ट्रेस फ्लैग 8621 के साथ देखा जा सकता है।
- भाग 4 - एंटी जॉइन एंटी पैटर्न
- अनुकूलक केवल एंटी जॉइन लागू करने के लिए एक पंक्ति लक्ष्य निर्धारित करता है जहां ऐसा करने का एक आशाजनक कारण होता है।
- दुर्भाग्य से, कई इंटरैक्टिंग ऑप्टिमाइज़र ट्रांसफ़ॉर्म एक टॉप (1) ऑपरेटर को एक लागू एंटी जॉइन के अंदरूनी हिस्से में जोड़ते हैं।
- शीर्ष ऑपरेटर बेमानी है; शुद्धता या दक्षता के लिए इसकी आवश्यकता नहीं है।
- शीर्ष हमेशा एक पंक्ति लक्ष्य निर्धारित करता है (लागू के विपरीत, जिसके लिए एक अच्छे कारण की आवश्यकता होती है)।
- अवांछित पंक्ति लक्ष्य अत्यंत खराब प्रदर्शन का कारण बन सकता है।
- कृत्रिम शीर्ष (1) के तहत संभावित रूप से महंगी उपट्री से सावधान रहें।