हमारे पिछले हाइब्रिड क्लाउड ब्लॉग में, हम अक्सर उल्लेख करते हैं कि हाइब्रिड क्लाउड टोपोलॉजी सेटअप का लाभ उठाने के प्राथमिक विकल्पों में से एक इसे अपने आपदा पुनर्प्राप्ति लक्ष्य के रूप में उपयोग करना है। एक संगठनात्मक संरचना के लिए यह सामान्य है कि एक आपदा रिकवरी योजना (डीआरपी) को हमेशा आपके डेटाबेस सेटअप के आर्किटेक्चरल कार्यान्वयन से पहले संबोधित किया जाता है, या तो क्लाउड में या ऑन-प्रिमाइसेस। आप सोच सकते हैं कि सब कुछ अप्रत्याशित रूप से विफल हो जाएगा और आपके व्यवसाय को दुखद रूप से प्रभावित कर सकता है यदि इसे सही तरीके से संबोधित और समझा नहीं गया है। इन चुनौतियों पर काबू पाने के लिए एक प्रभावी डीआरपी (आपदा वसूली योजना) की आवश्यकता होती है, जिसके लिए आपका सिस्टम आपके आवेदन, बुनियादी ढांचे और व्यावसायिक आवश्यकताओं के अनुसार अच्छी तरह से कॉन्फ़िगर किया गया है। इस प्रकार की स्थितियों में सफलता की कुंजी यह है कि हम कितनी तेजी से समस्या को ठीक कर सकते हैं या उससे उबर सकते हैं।
जबकि DRP आपदा परिस्थितियों को संबोधित करता है, व्यावसायिक निरंतरता सुनिश्चित करेगी कि DRP का परीक्षण और संचालन हर समय आवश्यक होने पर किया जाता है। आपके डेटाबेस के लिए आपके डिजास्टर रिकवरी विकल्पों को निरंतर संचालन और अपेक्षाओं की सीमा तक सुनिश्चित करना चाहिए। यह आपके वांछित आरटीओ और आरपीओ के अनुरूप होना चाहिए। यह सुनिश्चित करना अनिवार्य है कि आपदाओं के दौरान भी अनुप्रयोगों के लिए उत्पादन डेटाबेस उपलब्ध हैं; अन्यथा, यह एक महंगा सौदा हो सकता है। डीबीए, आर्किटेक्ट्स को यह सुनिश्चित करने की आवश्यकता है कि डेटाबेस वातावरण आपदाओं को बनाए रख सकते हैं और आपदा वसूली एसएलए अनुपालन कर रहे हैं। डेटाबेस परिनियोजन को यह सुनिश्चित करने के लिए सही ढंग से कॉन्फ़िगर किया जाना चाहिए कि आपदाएँ डेटाबेस उपलब्धता और व्यवसाय निरंतरता को प्रभावित न करें।
आपदा रिकवरी विकल्प
आपके PostgreSQL क्लस्टर को एक व्यवस्थित दृष्टिकोण के साथ कॉन्फ़िगर किया जाना चाहिए जो सर्वोत्तम प्रथाओं के लिए प्रतिबद्ध हो और उद्योग मानकों के लिए स्वीकार्य हो। व्यवस्थित दृष्टिकोण के साथ, निम्नलिखित प्रक्रियाएं या तंत्र आपको यह सुनिश्चित करने में मदद करते हैं कि हाइब्रिड क्लाउड पर तैनात आपके PostgreSQL में ये उपस्थितियां हैं:
-
विफलता/स्विचओवर
-
स्वचालित बैकअप
-
अत्यधिक उपलब्ध
-
लोड संतुलन
-
अत्यधिक वितरित वातावरण
विफलता/स्विचओवर
आपके मास्टर के विफल होने की स्थिति में विफलता एक स्वचालित प्रक्रिया है; या तो हॉट स्टैंडबाय या वार्म स्टैंडबाय सर्वर को प्राथमिक/मास्टर की भूमिका में पदोन्नत किया जाता है। फेलओवर नोड के लिए उम्मीदवार के रूप में कार्य करने के लिए कम से कम एक माध्यमिक नोड रखने के लिए यह एक सर्वोत्तम अभ्यास है जो उच्च उपलब्धता वातावरण प्रदान करता है। एक बार जब प्राथमिक सर्वर विफल हो जाता है, तो स्टैंडबाय सर्वर को विफलता प्रक्रिया शुरू करनी चाहिए, और फिर द्वितीयक या स्टैंडबाय सर्वर मास्टर की भूमिका निभाएगा। एक फ़ेलओवर सिस्टम सामान्य व्यवहार में न्यूनतम दो सर्वरों का उपयोग करता है, जो प्राथमिक और स्टैंडबाय के रूप में कार्य करता है। इसकी कनेक्टिविटी जांच को दिल की धड़कन तंत्र द्वारा सहायता प्रदान की जाती है जो नॉन-स्टॉप जांच करता है और सत्यापित करता है कि दोनों अच्छी स्थिति में हैं और संचार जीवित है। हालांकि, कुछ मामलों में, कनेक्टिविटी एक झूठा अलार्म दे सकती है। इसलिए, कुछ सेटअप और वातावरण में, एक निगरानी नोड जैसे तीसरे सिस्टम की उपस्थिति एक अलग नेटवर्क या डेटासेंटर पर होती है। अनुपयुक्त या अवांछित विफलता को रोकने के लिए यह एक फुलप्रूफ विकल्प है। एक फुलप्रूफ सत्यापन नोड में अतिरिक्त सुविधाएं और जांच हो सकती है, जो जटिलता को जोड़ती है। इस सेटअप को पूर्ण और कठोर परीक्षण की आवश्यकता है ताकि यह सुनिश्चित किया जा सके कि कार्यान्वयन में परिवर्तन होने पर विफलता सही हो। साथ ही, आपके PostgreSQL को किसी भी तरह की गिरावट से बचाने के लिए यह महत्वपूर्ण है
मान लें कि आपके पास एक अलग हार्डवेयर सेटअप के साथ एक अलग डेटासेंटर पर आपका सेकेंडरी या स्टैंडबाय क्लस्टर है; हो सकता है कि आप अचानक से फेलओवर नहीं करना चाहें, खासकर अगर यह सिर्फ एक झूठी सकारात्मकता के कारण आदर्श मामला नहीं है। हालाँकि, इस परिदृश्य में, आपके डेटा पुनर्प्राप्ति लक्ष्य नोड या क्लस्टर में आपके प्राथमिक नोड या क्लस्टर के समान संसाधन और विनिर्देश होने चाहिए। यदि आपका डेटा पुनर्प्राप्ति लक्ष्य सार्वजनिक क्लाउड में है और प्राथमिक ऑन-प्रिमाइसेस है, तो सुनिश्चित करें कि यह आपकी क्षमता नियोजन में पहले से ही शामिल है और अवांछित परिणामों से बचने के लिए संसाधनों में लगभग समान विनिर्देश हैं।
हाइब्रिड क्लाउड के भीतर अपने PostgreSQL क्लस्टर में अपने फेलओवर तंत्र का उपयोग और तैयारी करते समय, आपको यह सुनिश्चित करना होगा कि आपका टूल उस कार्य को करने के लिए एकदम उपयुक्त है जिसे प्राप्त करना है। ऐसे तृतीय-पक्ष उपकरण हैं जो अग्रिम विफलता के संबंध में PostgreSQL में बंडल नहीं किए गए हैं। उदाहरण के लिए, ClusterControl, pg_auto_failover by CitrusData (c/o Microsoft), Pgpool-II, Bucardo और अन्य हैं। ये उन्नत उपयोगिता उपकरण नोड फेंसिंग प्रदान करते हैं या प्रसिद्ध रूप से STONITH के रूप में जाना जाता है (सिर में दूसरे नोड को शूट करें)। यह सुनिश्चित करता है कि आपका विफल प्राथमिक या मास्टर नोड सामान्य लेनदेन की सेवा के लिए अपनी पिछली स्थिति के रूप में लिखने या ऑनलाइन वापस आने से बच जाएगा। इस समस्या को आमतौर पर स्प्लिट-ब्रेन परिदृश्य के रूप में जाना जाता है। यह विफलता (हार्डवेयर या संसाधन स्तर) के कारण डेटा सिंक्रोनाइज़ेशन खो देता है, लेकिन फिर भी आपके प्राथमिक सर्वर, जो माना जाता है कि केवल एक प्राथमिक सर्वर है, ऐसा कार्य करते हैं जैसे डेटा के सामान्य प्राप्तकर्ता क्लस्टर-वाइड डेटा भ्रष्टाचार के कारण अनुरोध लिखते हैं।
स्वचालित बैकअप
बैकअप हमेशा डेटा हानि के खिलाफ उच्च आश्वासन और सुरक्षा उपाय प्रदान करते हैं। बैकअप आपके आरपीओ को अधिकतम करता है क्योंकि यह आपदा आने पर डेटा हानि को कम करने में सहायता करता है। जिन चीज़ों पर आपको विचार करना है और अपने स्वचालित बैकअप के लिए तैयार करना है, उनमें आपके बैकअप उपकरण/हार्डवेयर, बैकअप डेटा अतिरेक, सुरक्षा, प्रदर्शन, गति और डेटा संग्रहण शामिल हैं।
बैकअप उपकरण
आपके पास अपने बैकअप उपकरण के लिए यहां सबसे अच्छा विकल्प होना चाहिए। गति, महत्वपूर्ण भंडारण मात्रा, और अत्यधिक उपलब्ध आपकी वांछित पसंद हो सकती है। कुछ सैन या एनएएस स्टोरेज पर भरोसा करते हैं या अपने डेटा को अन्य तृतीय-पक्ष बैकअप स्टोरेज प्रदाताओं तक फैलाते हैं। यह आवश्यक है कि आपका बैकअप उपकरण डेटा लिखने और पढ़ने के लिए गति प्रदान करता है, खासकर यदि आप आराम से अपने डेटा के लिए संपीड़न और एन्क्रिप्शन लागू करते हैं। डीकंप्रेसन और डिक्रिप्शन के लिए संसाधनों की आवश्यकता होती है, इसलिए आपको यह विचार करना होगा कि आपको डेटा रिकवरी का उपयोग कब करना है। इस स्थिति के दौरान, आपको यह निर्धारित करना होगा कि आपको अपना अधिकतम आरपीओ प्राप्त करना है और अपने ग्राहकों को प्राप्त करने योग्य एसएलए (सेवा-स्तर समझौता) करना है। यह भी आदर्श है कि आपको अपने बैकअप को अपने स्थानीय नेटवर्क से अलग करना पड़ सकता है या इसे किसी दूरस्थ स्थान पर संग्रहीत करना पड़ सकता है। एक वैकल्पिक तरीका तृतीय-पक्ष प्रदाताओं के साथ जुड़ना है। उदाहरण के लिए, अपने बैकअप को क्लाउड में संग्रहीत करना एक विकल्प हो सकता है, और उनकी सुविधा अत्यधिक परिष्कृत है और आपकी आवश्यकताओं को पूरा करती है।
बैकअप डेटा अतिरेक
अपने डेटा को कई स्थानों पर फैलाना एक आदर्श समाधान है। यह आपके डेटा पुनर्प्राप्ति अवसरों को मजबूत करता है, उदाहरण के लिए, एक मानवीय त्रुटि या एक सॉफ़्टवेयर तर्क त्रुटि जिसके कारण आप बैकअप की पुरानी प्रतियाँ हटाते हैं लेकिन गलती से संपूर्ण महत्वपूर्ण बैकअप प्रतियाँ हटा देते हैं। कुछ परिष्कृत वातावरणों में, जैसे कि Amazon S3, Google द्वारा क्लाउड स्टोरेज, या Azure ब्लॉब स्टोरेज जैसे क्लाउड वातावरण में संग्रहीत करना आपकी संग्रहीत फ़ाइल की प्रतिकृति प्रदान करता है। यह अधिक अतिरेक प्रदान करता है और इसे लचीले तरीके से सेटअप किया जा सकता है जो आपकी आवश्यकताओं के अनुरूप हो।
अत्यधिक उपलब्ध
हाइब्रिड क्लाउड में अत्यधिक उपलब्ध PostgreSQL क्लस्टर हमेशा यह सुनिश्चित करता है कि आपका डेटाबेस संचार अपटाइम सुनिश्चित करता है। उच्च उपलब्धता का आदर्श मामला आपकी उपलब्धता के माप पर निर्भर करता है। इस मामले में, हाइब्रिड क्लाउड में तैनात पोस्टग्रेएसक्यूएल के लिए एक सामान्य सेटअप या तो सार्वजनिक क्लाउड में होस्ट किया गया आपका डेटाबेस हो सकता है, प्राथमिक क्लस्टर विफल होने या नेटवर्क आपदा से ग्रस्त होने की स्थिति में आपके डेटा रिकवरी क्लस्टर के रूप में कार्य करने वाला आपका द्वितीयक क्लस्टर हो सकता है और ले सकता है बहुत डाउनटाइम। कुछ सेटअप में, यह संभव है कि पब्लिक क्लाउड में पड़ा सेकेंडरी क्लस्टर प्राइमरी जितना परिष्कृत न हो, मान लें कि यह आपका ऑन-प्रिमाइसेस या प्राइवेट क्लाउड है। आपका एप्लिकेशन आगंतुकों या ट्रैफ़िक को सीमित करने के लिए खेल सकता है जो आपके डेटाबेस से जुड़ सकते हैं। इस प्रकार का परिदृश्य आपकी सेटअप लागत को कम कर सकता है, लेकिन निश्चित रूप से, यह केवल आपकी आवश्यकताओं पर निर्भर करता है। यदि आपका आवेदन प्रकार बहुत बड़ा है और सामान्य से व्यस्त ट्रैफ़िक स्थितियों में नॉन-स्टॉप प्राप्त करना है, तो सुनिश्चित करें कि उच्च उपलब्धता सुनिश्चित करने के लिए आपके द्वितीयक क्लस्टर संसाधन प्राथमिक के समान शक्तिशाली होने चाहिए, अर्थात 99.9999999%।
हाइब्रिड क्लाउड वातावरण में अत्यधिक उपलब्ध PostgreSQL क्लस्टर प्राप्त करने के लिए, आपके पास एक विफलता तंत्र होना चाहिए। एक विफलता के मामले में और एक प्राथमिक क्लस्टर या प्राथमिक सर्वर नीचे चला जाता है, एक माध्यमिक या स्टैंडबाय सर्वर तब मास्टर की भूमिका निभा सकता है, चाहे उसका स्थान कुछ भी हो। सबसे महत्वपूर्ण बात कार्यक्षमता है, और प्रदर्शन, विशेष रूप से एप्लिकेशन या क्लाइंट के दृष्टिकोण से, बिल्कुल या कम से कम बहुत कम प्रभावित नहीं होते हैं।
लोड संतुलन
आपके PostgreSQL क्लस्टर के लिए लोड संतुलन तंत्र आपके हाइब्रिड क्लाउड सेटअप में सहायता करता है, जो अधिक प्रबंधनीय और कम जोखिम भरा है, खासकर जब उच्च ट्रैफ़िक लोड होता है। कई स्थितियों में, एक सर्वर को एक गंभीर उच्च भार प्राप्त हो रहा है जिससे सर्वर घबरा जाता है। यह पृष्ठभूमि में चल रहे बहुत सारे थ्रेड्स द्वारा उपभोग किए गए व्यस्त संसाधनों के कारण सर्वर अनुपयोगी स्थिति की ओर जाता है। खराब क्वेरी और आपके डेटाबेस के डिज़ाइन आर्किटेक्चर को ठीक करके इस स्थिति में सुधार किया जा सकता है। इसमें शामिल होना चाहिए कि आप रीड को राइट लोड के खिलाफ कैसे वितरित करते हैं और मास्टर-मास्टर सेटअप या सिर्फ एक मास्टर जैसी आपकी एप्लिकेशन आवश्यकताओं की गहराई से समझ लेकिन उच्च कंप्यूटिंग और मेमोरी संसाधन प्रदान करने के लिए इसे लंबवत रूप से स्केल करना। हाइब्रिड क्लाउड वातावरण में आपके PostgreSQL परिनियोजन में सहायता के लिए pgbouncer और Pgpool II जैसे तृतीय पक्ष टूल का एक बड़ा चयन भी है।
अत्यधिक वितरित वातावरण
स्केलेबिलिटी के लिहाज से, कई स्थानों या विभिन्न क्लाउड प्रदाताओं (ऑन-प्रिमाइसेस या निजी और सार्वजनिक क्लाउड) में अत्यधिक वितरित होने के कारण हाइब्रिड क्लाउड वातावरण में अधिक लचीलापन और सहनशीलता प्रदान करता है और यह आपदा वसूली के लिए बहुत अच्छा है। यह तब लचीला होता है जब इसे प्राकृतिक आपदा या आपदा के अनुकूल किसी विशेष बादल स्थान पर विफल होने की आवश्यकता होती है, खासकर यदि आपका निर्दिष्ट क्षेत्र जहां आपका प्राथमिक क्लस्टर रहता है, वर्तमान में प्राकृतिक कारणों से तबाह या प्रभावित होता है। यह एक अपरिहार्य कारण है जिसे आपको समझना होगा और वर्तमान स्थिति पर भरोसा करना होगा। आपके आवेदन और ग्राहकों को लगातार नॉन-स्टॉप परोसा जाना है। यह निजी या ऑन-प्रिमाइसेस वातावरण में सेवा करते हुए सार्वजनिक रूप से क्लाउड में उपलब्ध होने के उद्देश्य को पूरा करता है। यह सेटअप अधिक उच्च जटिलता जोड़ता है और डेटाबेस पक्ष और सुरक्षा और नेटवर्किंग पर उन्नत ज्ञान की आवश्यकता होती है। यहां सफलता के लिए ऑप्टिमाइज़ेशन और ट्यूनिंग महत्वपूर्ण हैं क्योंकि यह बहुत महत्वपूर्ण है कि इंटरनेट पर यात्रा करते समय अपने डेटा को सुरक्षित रखने के लिए कड़ी सुरक्षा प्रदान करते हुए, प्रदर्शन को स्थिर करने के लिए सिद्ध किया जाना चाहिए और कार्यान्वित सेटअप से प्रभावित नहीं होना चाहिए।
सेटअप जटिलता के कारण, एक उपकरण का होना परिनियोजन के प्रबंधन और आपके डेटाबेस की समग्र स्थिति को सुविधाजनक बनाने के लिए आदर्श है, आपके क्लस्टर के एक पहलू की देखरेख करना, लेकिन ऑन-प्रिमाइसेस, निजी क्लाउड से पूरे स्तर पर, और सार्वजनिक बादल पहलू पर। सभी सेटअप को एक प्रबंधनीय और सीधे स्तर पर रखा जाना चाहिए ताकि अलार्म और अलर्ट के मामले में, समस्या को ठीक से और समय पर ठीक करना और हल करना आसान हो।
एक हाइब्रिड क्लाउड वातावरण में आपदा पुनर्प्राप्ति के लिए क्लस्टर नियंत्रण
ClusterControl संगठन या कंपनियों को लचीलेपन के साथ डेटाबेस का प्रबंधन करने और सेटअप की समग्र जटिलता को कम करने की अनुमति देता है। ClusterControl फेलओवर, स्वचालित बैकअप प्रदान करता है, अत्यधिक उपलब्ध सेटअप प्रदान करता है, लोड संतुलन प्रदान करता है, और एक वितरित पर्यावरण परिनियोजन का समर्थन करता है, जिससे सार्वजनिक क्लाउड में या निजी तौर पर या ऑन-प्रिमाइसेस में नोड्स जोड़ना आसान हो जाता है।
ClusterControl स्वतः पुनर्प्राप्ति
ClusterControl की स्वतः पुनर्प्राप्ति कई फ़ेलओवर तंत्र और पुनर्प्राप्ति विशेषताओं का प्रतिनिधित्व करती है, विशेष रूप से जब कोई नोड नीचे चला जाता है या क्लस्टर ख़राब स्थिति में चला जाता है। यह आसानी से किया जा सकता है जैसा कि नीचे स्क्रीनशॉट में दिखाया गया है:
बैकअप और पुनर्स्थापना
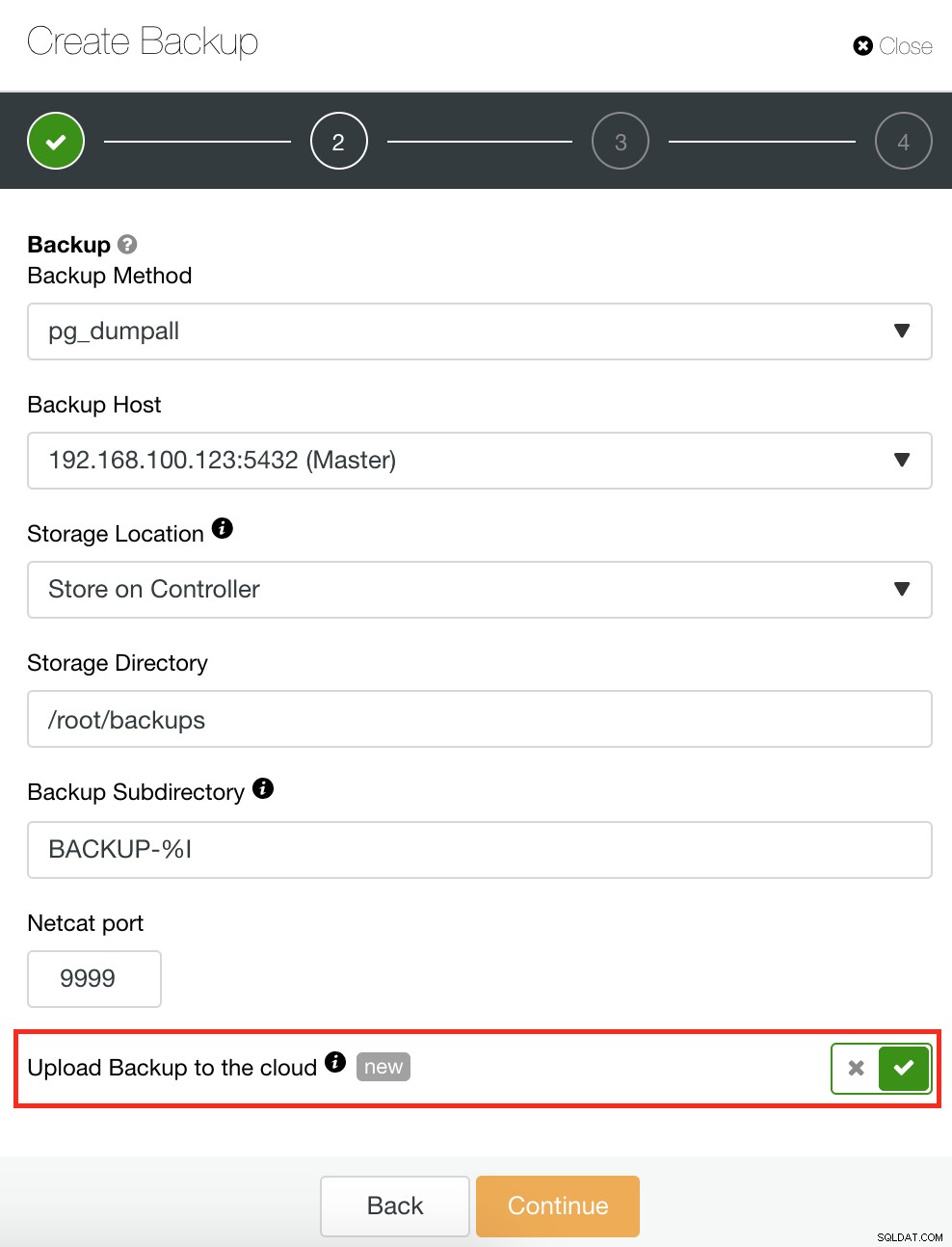
ClusterControl में एक बैकअप और पुनर्स्थापना सुविधा भी है जो आपको अपना बैकअप प्रबंधित करने, बैकअप बनाने, बैकअप शेड्यूल करने और बैकअप पुनर्स्थापित करने की अनुमति देती है। अपने बैकअप को प्रबंधित करना बहुत सीधा है और बैकअप बनाना या शेड्यूल करना सरल है फिर भी उन्नत विकल्प भी प्रदान करता है। यह क्लाउड बैकअप विकल्प भी प्रदान करता है जो आपको बैकअप डेटा अतिरेक की अनुमति देता है,, आपके आपदा पुनर्प्राप्ति विकल्पों को मजबूत करता है। नीचे देखें:
जैसा कि नीचे दिखाया गया है, अपने बैकअप को प्रबंधित करने से आपको यह चुनने के लिए एक सरल UI मिलता है कि आप किस बैकअप को पुनर्स्थापित करना चाहते हैं, या आपको ड्रॉप करना पड़ सकता है। ClusterControl बैकअप आपको एक अवधारण अवधि चुनने की अनुमति देता है, इसलिए यदि आपके पास एक लंबी सूची है, तो इनमें से कुछ को उसकी अवधारण अवधि तक पहुंचने पर हटाया जा सकता है। 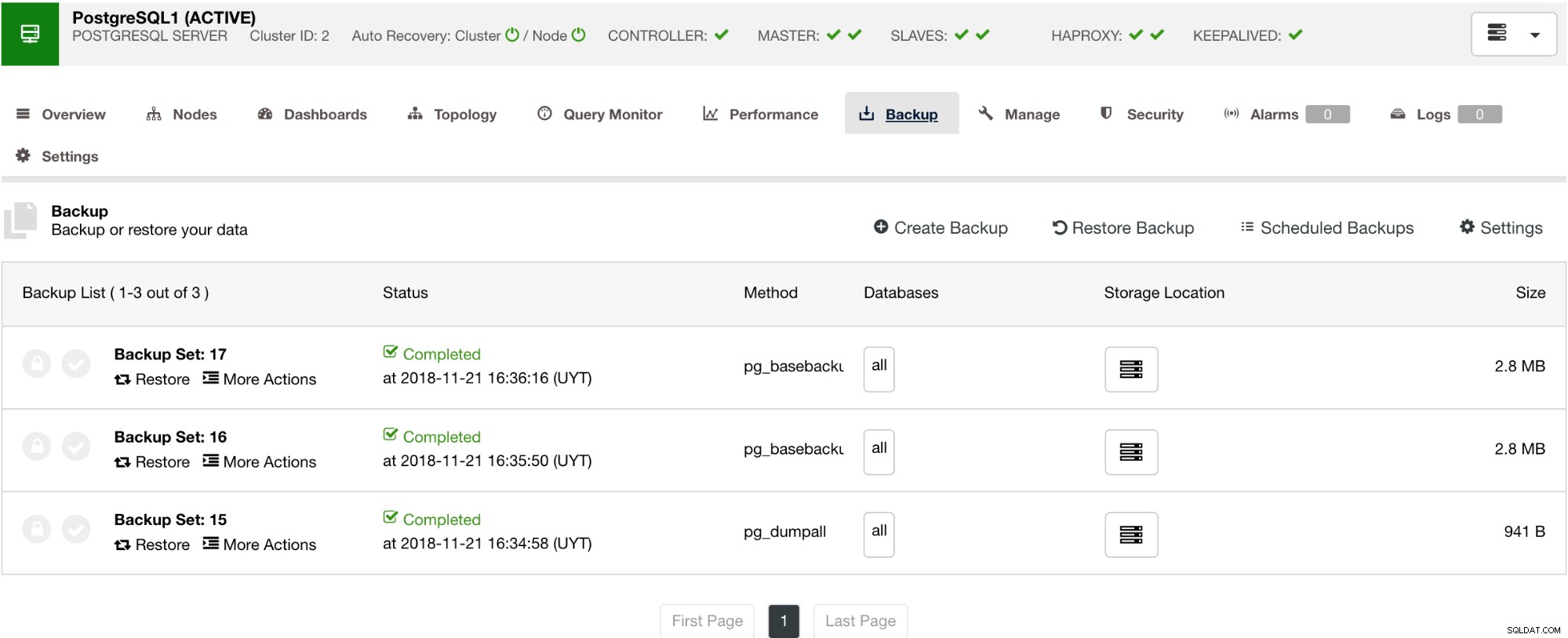
उच्च उपलब्धता (HA) और लोड बैलेंसिंग (LB) तंत्र का समर्थन करता है
आपको अपने PostgreSQL क्लस्टर में उच्च उपलब्धता जोड़ने के लिए मैन्युअल रूप से सेटअप करने या यहां तक कि कुछ तरीकों पर शोध करने की आवश्यकता नहीं है। ClusterControl के साथ काम पूरा करने का एक आसान और सुविधाजनक तरीका है। यदि आप उदाहरण स्क्रीनशॉट देख सकते हैं, तो इसमें HAProxy और Keepalived सेटअप है। नीचे स्क्रीनशॉट देखें:
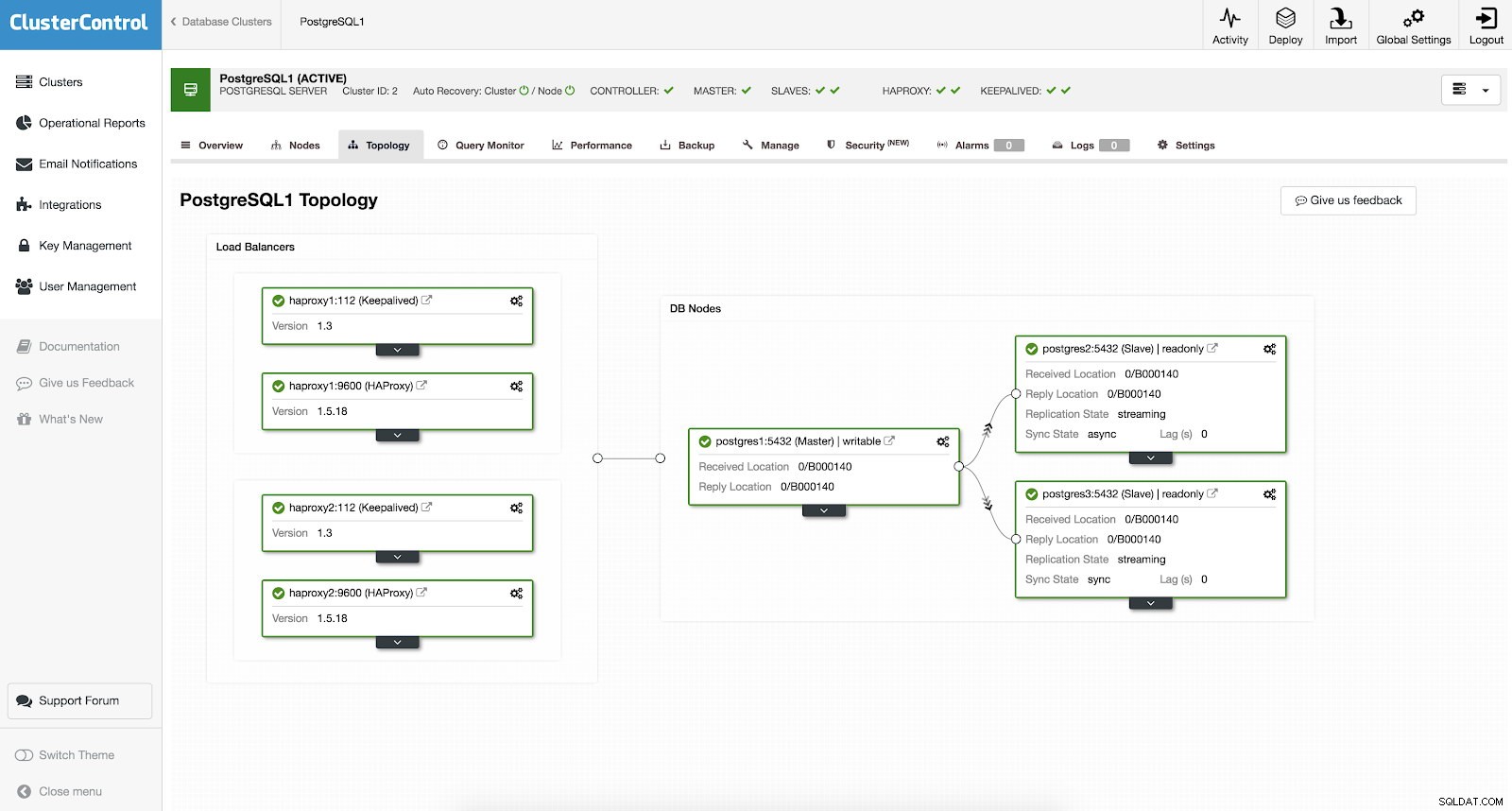
ClusterControl के साथ उच्च उपलब्धता को सेट करना <अपना क्लस्टर चुनें> → प्रबंधित करें → बैलेंसर लोड करें
के माध्यम से किया जा सकता है।वितरित पर्यावरण का समर्थन करता है
यदि आप ऑन-प्रिमाइसेस या निजी क्लाउड से सार्वजनिक क्लाउड में समान रूप से वितरण करना चाहते हैं, तो ClusterControl क्लाउड परिनियोजन का भी समर्थन करता है। लेकिन एक पोस्टग्रेएसक्यूएल क्लस्टर के लिए और आप एक अलग क्लाउड पर रहने वाले एक सेकेंडरी स्लेव की योजना बना रहे हैं, आप एक स्लेव क्लस्टर बना सकते हैं जैसा कि नीचे दिखाया गया है,
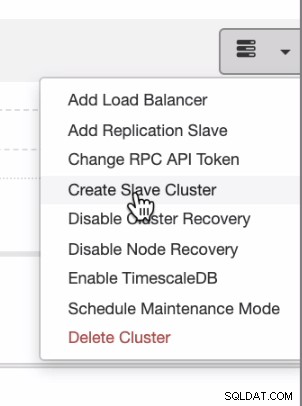
और आप नीचे दिखाए गए अंतिम परिणाम के साथ पहुंच सकते हैं,

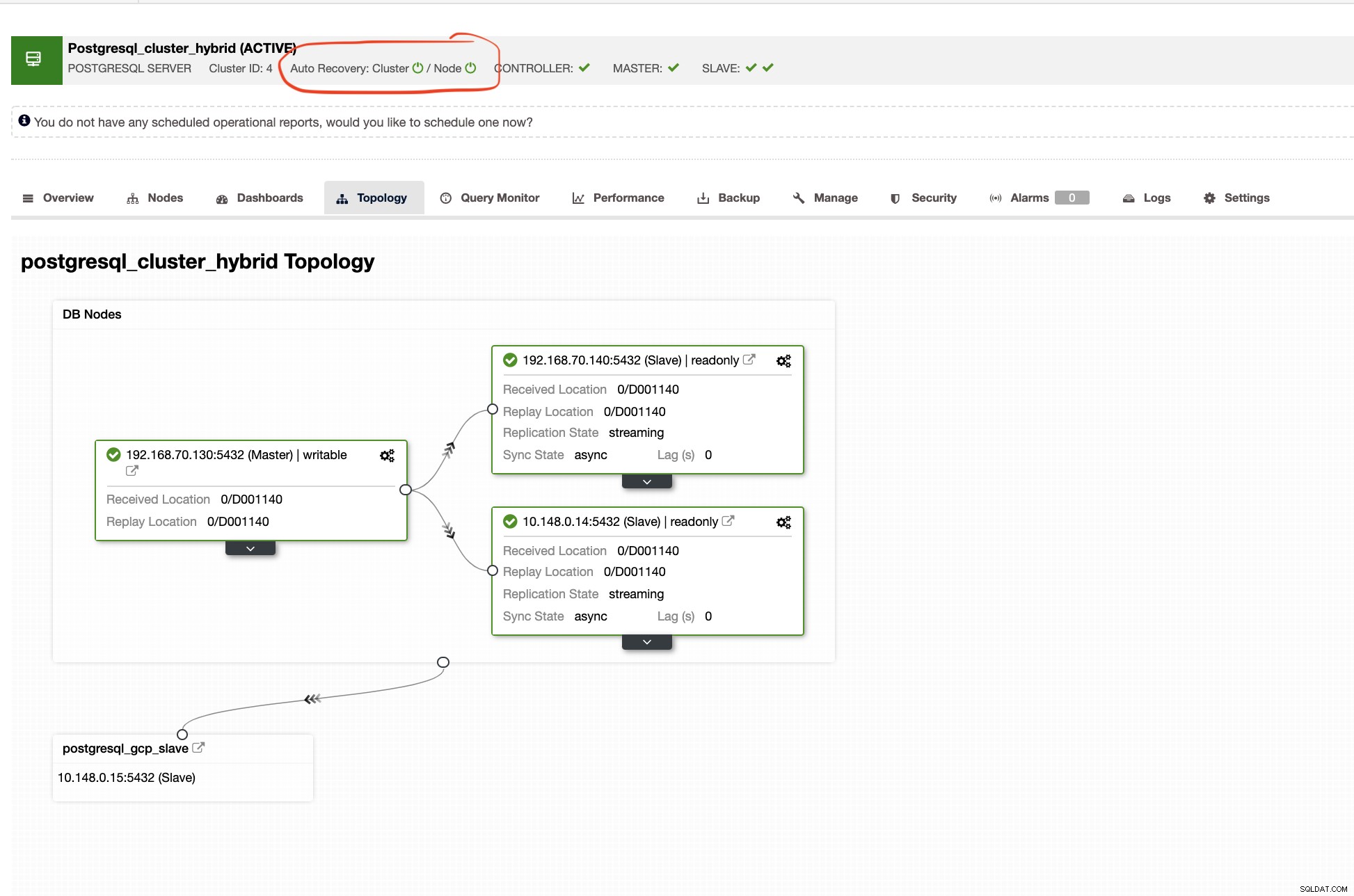
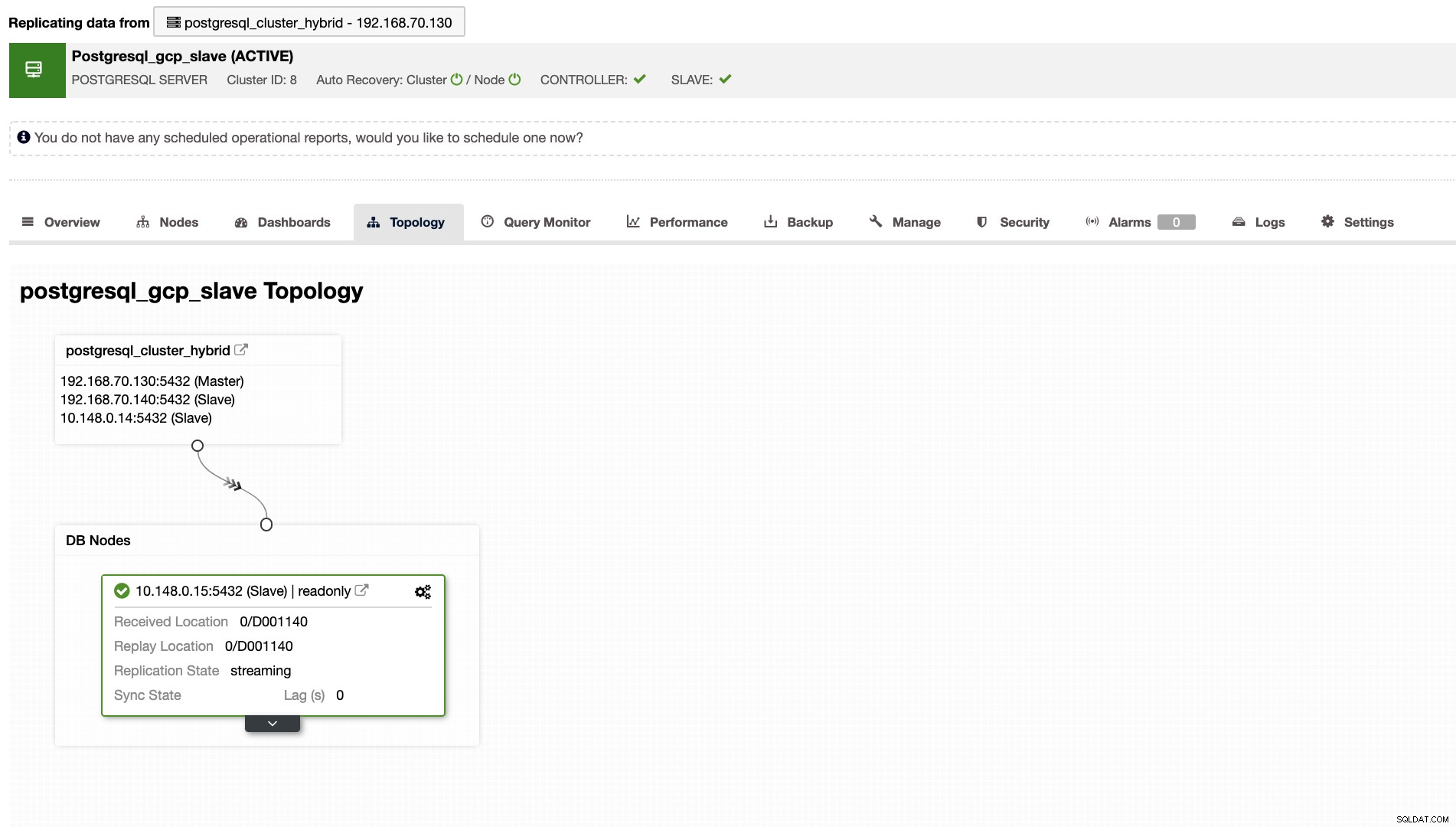
ClusterControl आपको आपके क्लस्टर की सही टोपोलॉजी भी दिखाएगा, जब भी आपके पास हाइब्रिड क्लाउड परिवेश सेटअप होगा। निम्नलिखित को नीचे देखें,
जबकि स्लेव क्लस्टर में, टोपोलॉजी अपने मालिक को प्रकट करते हुए अपने मूल के पेड़ को दिखाएगा। यहां दास दिखाता है कि यह मुख्य रूप से Google क्लाउड में स्थित एक अलग नेटवर्क में स्थित है, जबकि मास्टर ऑन-प्रिमाइसेस है।
निष्कर्ष
यह स्वीकार करना स्वीकार्य है कि हाइब्रिड क्लाउड सेटअप, विशेष रूप से PostgreSQL क्लस्टर के साथ जटिलता जोड़ता है। आपके पास अपनी आपदा वसूली योजना का समर्थन करने के लिए मौजूद विकल्पों के साथ सही उपकरण होना चाहिए। आपके व्यवसाय को वित्तीय क्षति और ग्राहक के विश्वास को खोने की संभावित तबाही से बचाने और बचने के लिए ये बहुत महत्वपूर्ण हैं। अपनी तकनीक के सही टूल और कौशल में निवेश करें, और आप अपने व्यवसाय को नकारात्मक प्रभाव से बचाएंगे।