इस श्रृंखला के भाग 1 में, आपने एक REST API बनाने के लिए फ्लास्क और Connexion का उपयोग किया था, जो PEOPLE नामक एक साधारण इन-मेमोरी संरचना को CRUD संचालन प्रदान करता है। . यह प्रदर्शित करने के लिए काम करता है कि कैसे Connexion मॉड्यूल इंटरैक्टिव दस्तावेज़ीकरण के साथ एक अच्छा REST API बनाने में आपकी मदद करता है।
जैसा कि कुछ ने भाग 1 की टिप्पणियों में उल्लेख किया है, PEOPLE हर बार एप्लिकेशन के पुनरारंभ होने पर संरचना को फिर से शुरू किया जाता है। इस लेख में, आप सीखेंगे कि PEOPLE को कैसे स्टोर किया जाए SQLAlchemy और Marshmallow का उपयोग कर डेटाबेस को संरचना, और API द्वारा प्रदान की जाने वाली क्रियाएं।
SQLAlchemy एक ऑब्जेक्ट रिलेशनल मॉडल (ORM) प्रदान करता है, जो पायथन ऑब्जेक्ट को ऑब्जेक्ट के डेटा के डेटाबेस प्रतिनिधित्व में संग्रहीत करता है। यह आपको पाइथोनिक तरीके से सोचना जारी रखने में मदद कर सकता है और इस बात से चिंतित नहीं है कि डेटाबेस में ऑब्जेक्ट डेटा का प्रतिनिधित्व कैसे किया जाएगा।
मार्शमैलो पायथन ऑब्जेक्ट्स को क्रमबद्ध और deserialize करने के लिए कार्यक्षमता प्रदान करता है क्योंकि वे हमारे JSON- आधारित REST API से बाहर और अंदर प्रवाहित होते हैं। मार्शमैलो पायथन वर्ग के उदाहरणों को उन वस्तुओं में परिवर्तित करता है जिन्हें JSON में बदला जा सकता है।
आप इस लेख के लिए पायथन कोड यहाँ पा सकते हैं।
निःशुल्क बोनस: "REST API उदाहरण" मार्गदर्शिका की एक प्रति डाउनलोड करने के लिए यहां क्लिक करें और कार्रवाई योग्य उदाहरणों के साथ Python + REST API सिद्धांतों का व्यावहारिक परिचय प्राप्त करें।
यह लेख किसके लिए है
यदि आपने इस श्रृंखला के भाग 1 का आनंद लिया है, तो यह लेख आपके टूल बेल्ट को और भी विस्तृत करता है। आप सीधे SQL की तुलना में अधिक पाइथोनिक तरीके से डेटाबेस तक पहुँचने के लिए SQLAlchemy का उपयोग कर रहे होंगे। आप मार्शमैलो का उपयोग REST API द्वारा प्रबंधित डेटा को क्रमानुसार और डीसेरियलाइज़ करने के लिए भी करेंगे। ऐसा करने के लिए, आप Python में उपलब्ध मूल ऑब्जेक्ट ओरिएंटेड प्रोग्रामिंग सुविधाओं का उपयोग कर रहे होंगे।
आप डेटाबेस बनाने के साथ-साथ इसके साथ इंटरैक्ट करने के लिए SQLAlchemy का भी उपयोग करेंगे। REST API को PEOPLE . के साथ चलाने और चलाने के लिए यह आवश्यक है भाग 1 में प्रयुक्त डेटा।
भाग 1 में प्रस्तुत वेब एप्लिकेशन में इसकी HTML और जावास्क्रिप्ट फाइलें मामूली तरीकों से संशोधित होंगी ताकि परिवर्तनों का भी समर्थन किया जा सके। आप यहां भाग 1 से कोड के अंतिम संस्करण की समीक्षा कर सकते हैं।
अतिरिक्त निर्भरता
इससे पहले कि आप इस नई कार्यक्षमता का निर्माण शुरू करें, आपको भाग 1 कोड चलाने के लिए बनाए गए वर्चुअलएन्व को अपडेट करना होगा, या इस प्रोजेक्ट के लिए एक नया कोड बनाना होगा। अपने वर्चुअलएन्व को सक्रिय करने के बाद इसे करने का सबसे आसान तरीका यह कमांड चलाना है:
$ pip install Flask-SQLAlchemy flask-marshmallow marshmallow-sqlalchemy marshmallow
यह आपके वर्चुअलएन्व में अधिक कार्यक्षमता जोड़ता है:
-
Flask-SQLAlchemyफ्लास्क में कुछ टाई-इन के साथ SQLAlchemy जोड़ता है, प्रोग्राम को डेटाबेस तक पहुंचने की अनुमति देता है। -
flask-marshmallowमार्शमैलो के फ्लास्क भागों को जोड़ता है, जो प्रोग्राम को पायथन ऑब्जेक्ट्स को क्रमबद्ध संरचनाओं में और से परिवर्तित करने देता है। -
marshmallow-sqlalchemySQLAlchemy में कुछ मार्शमैलो हुक जोड़ता है ताकि प्रोग्राम को SQLAlchemy द्वारा उत्पन्न पायथन ऑब्जेक्ट्स को क्रमबद्ध और अक्रमांकन करने की अनुमति मिल सके। -
marshmallowमार्शमैलो कार्यक्षमता का बड़ा हिस्सा जोड़ता है।
लोगों का डेटा
जैसा कि ऊपर बताया गया है, PEOPLE पिछले लेख में डेटा संरचना एक इन-मेमोरी पायथन डिक्शनरी है। उस शब्दकोश में, आपने लुकअप कुंजी के रूप में व्यक्ति के अंतिम नाम का उपयोग किया था। कोड में डेटा संरचना इस तरह दिखती थी:
# Data to serve with our API
PEOPLE = {
"Farrell": {
"fname": "Doug",
"lname": "Farrell",
"timestamp": get_timestamp()
},
"Brockman": {
"fname": "Kent",
"lname": "Brockman",
"timestamp": get_timestamp()
},
"Easter": {
"fname": "Bunny",
"lname": "Easter",
"timestamp": get_timestamp()
}
}
प्रोग्राम में आप जो संशोधन करेंगे, वे सभी डेटा को डेटाबेस तालिका में स्थानांतरित कर देंगे। इसका मतलब है कि डेटा आपकी डिस्क में सहेजा जाएगा और server.py . के रन के बीच मौजूद रहेगा कार्यक्रम।
क्योंकि अंतिम नाम डिक्शनरी कुंजी था, कोड ने किसी व्यक्ति के अंतिम नाम को बदलना प्रतिबंधित कर दिया:केवल पहला नाम बदला जा सकता था। इसके अलावा, डेटाबेस में जाने से आप अंतिम नाम बदल सकेंगे क्योंकि यह अब किसी व्यक्ति के लिए लुकअप कुंजी के रूप में उपयोग नहीं किया जाएगा।
संकल्पनात्मक रूप से, एक डेटाबेस तालिका को दो-आयामी सरणी के रूप में माना जा सकता है जहां पंक्तियां रिकॉर्ड होती हैं, और कॉलम उन रिकॉर्ड्स में फ़ील्ड होते हैं।
डेटाबेस टेबल में आमतौर पर पंक्तियों की लुकअप कुंजी के रूप में एक ऑटो-इंक्रीमेंटिंग पूर्णांक मान होता है। इसे प्राथमिक कुंजी कहा जाता है। तालिका में प्रत्येक रिकॉर्ड में एक प्राथमिक कुंजी होगी जिसका मान संपूर्ण तालिका में अद्वितीय है। तालिका में संग्रहीत डेटा से स्वतंत्र प्राथमिक कुंजी होने से आप पंक्ति में किसी भी अन्य फ़ील्ड को संशोधित करने के लिए मुक्त हो जाते हैं।
नोट:
ऑटो-इन्क्रीमेंटिंग प्राइमरी की का मतलब है कि डेटाबेस निम्नलिखित का ध्यान रखता है:
- तालिका में हर बार एक नया रिकॉर्ड डालने पर सबसे बड़े मौजूदा प्राथमिक कुंजी फ़ील्ड को बढ़ाना
- नए सम्मिलित डेटा के लिए प्राथमिक कुंजी के रूप में उस मान का उपयोग करना
तालिका के बढ़ने पर यह एक अद्वितीय प्राथमिक कुंजी की गारंटी देता है।
आप तालिका को एकवचन के रूप में नाम देने के डेटाबेस सम्मेलन का पालन करने जा रहे हैं, इसलिए तालिका को person कहा जाएगा . हमारे PEOPLE का अनुवाद कर रहे हैं person . नामक डेटाबेस तालिका में ऊपर की संरचना आपको यह देता है:
| person_id | <थ>नामfname | <थ>टाइमस्टैम्प||
|---|---|---|---|
| 1 | फैरेल | डौग | 2018-08-08 21:16:01.888444 |
| 2 | ब्रॉकमैन | केंट | 2018-08-08 21:16:01.889060 |
| 3 | ईस्टर | बनी | 2018-08-08 21:16:01.886834 |
तालिका के प्रत्येक स्तंभ का एक फ़ील्ड नाम इस प्रकार है:
person_id: प्रत्येक व्यक्ति के लिए प्राथमिक कुंजी फ़ील्डlname: व्यक्ति का अंतिम नामfname: व्यक्ति का पहला नामtimestamp: सम्मिलित/अद्यतन कार्रवाइयों से संबद्ध टाइमस्टैम्प
डेटाबेस इंटरैक्शन
आप PEOPLE . को स्टोर करने के लिए SQLite को डेटाबेस इंजन के रूप में उपयोग करने जा रहे हैं जानकारी। SQLite दुनिया में सबसे व्यापक रूप से वितरित डेटाबेस है, और यह मुफ्त में पायथन के साथ आता है। यह तेज़ है, फाइलों का उपयोग करके अपना सारा काम करता है, और कई बड़ी परियोजनाओं के लिए उपयुक्त है। यह एक संपूर्ण RDBMS (रिलेशनल डेटाबेस मैनेजमेंट सिस्टम) है जिसमें SQL, कई डेटाबेस सिस्टम की भाषा शामिल है।
फिलहाल, person की कल्पना करें तालिका पहले से ही SQLite डेटाबेस में मौजूद है। यदि आपके पास आरडीबीएमएस के साथ कोई अनुभव है, तो आप शायद एसक्यूएल के बारे में जानते हैं, संरचित क्वेरी भाषा अधिकांश आरडीबीएमएस डेटाबेस के साथ बातचीत करने के लिए उपयोग करते हैं।
पायथन जैसी प्रोग्रामिंग भाषाओं के विपरीत, SQL कैसे . को परिभाषित नहीं करता है डेटा प्राप्त करने के लिए:यह वर्णन करता है कि क्या डेटा वांछित है, कैसे . छोड़कर डेटाबेस इंजन तक।
हमारे person . में सभी डेटा प्राप्त करने वाली एक SQL क्वेरी तालिका, अंतिम नाम के अनुसार क्रमबद्ध, यह इस तरह दिखेगी:
SELECT * FROM person ORDER BY 'lname';
यह क्वेरी डेटाबेस इंजन को व्यक्ति तालिका से सभी फ़ील्ड प्राप्त करने और lname का उपयोग करके डिफ़ॉल्ट, आरोही क्रम में सॉर्ट करने के लिए कहती है। खेत।
यदि आप इस क्वेरी को person . वाले SQLite डेटाबेस के विरुद्ध चलाना चाहते हैं तालिका में, परिणाम तालिका में सभी पंक्तियों वाले रिकॉर्ड का एक सेट होगा, जिसमें प्रत्येक पंक्ति में एक पंक्ति बनाने वाले सभी फ़ील्ड के डेटा होंगे। नीचे person . के विरुद्ध उपरोक्त क्वेरी को चलाने वाले SQLite कमांड लाइन टूल का उपयोग करके एक उदाहरण दिया गया है डेटाबेस तालिका:
sqlite> SELECT * FROM person ORDER BY lname;
2|Brockman|Kent|2018-08-08 21:16:01.888444
3|Easter|Bunny|2018-08-08 21:16:01.889060
1|Farrell|Doug|2018-08-08 21:16:01.886834
उपरोक्त आउटपुट person . में सभी पंक्तियों की एक सूची है पाइप वर्णों के साथ डेटाबेस तालिका ('|') पंक्ति में फ़ील्ड को अलग करती है, जो SQLite द्वारा प्रदर्शन उद्देश्यों के लिए किया जाता है।
पायथन कई डेटाबेस इंजनों के साथ इंटरफेस करने और उपरोक्त SQL क्वेरी को निष्पादित करने में पूरी तरह से सक्षम है। परिणाम सबसे अधिक संभावना tuples की एक सूची होगी। बाहरी सूची में person . के सभी रिकॉर्ड शामिल हैं टेबल। प्रत्येक व्यक्तिगत आंतरिक टपल में तालिका पंक्ति के लिए परिभाषित प्रत्येक फ़ील्ड का प्रतिनिधित्व करने वाला सभी डेटा होगा।
इस तरह से डेटा प्राप्त करना बहुत पाइथोनिक नहीं है। अभिलेखों की सूची ठीक है, लेकिन प्रत्येक व्यक्तिगत रिकॉर्ड केवल डेटा का एक गुच्छा है। किसी विशेष क्षेत्र को पुनः प्राप्त करने के लिए प्रत्येक क्षेत्र के सूचकांक को जानना कार्यक्रम पर निर्भर है। निम्नलिखित पायथन कोड उपरोक्त क्वेरी को चलाने और डेटा प्रदर्शित करने के तरीके को प्रदर्शित करने के लिए SQLite का उपयोग करता है:
1import sqlite3
2
3conn = sqlite3.connect('people.db')
4cur = conn.cursor()
5cur.execute('SELECT * FROM person ORDER BY lname')
6people = cur.fetchall()
7for person in people:
8 print(f'{person[2]} {person[1]}')
उपरोक्त कार्यक्रम निम्नलिखित करता है:
-
पंक्ति 1
sqlite3आयात करता है मॉड्यूल। -
पंक्ति 3 डेटाबेस फ़ाइल से कनेक्शन बनाता है।
-
पंक्ति 4 कनेक्शन से एक कर्सर बनाता है।
-
पंक्ति 5
SQLexecute को निष्पादित करने के लिए कर्सर का उपयोग करता है एक स्ट्रिंग के रूप में व्यक्त की गई क्वेरी। -
पंक्ति 6
SQL. द्वारा लौटाए गए सभी रिकॉर्ड प्राप्त करता है क्वेरी करें और उन्हेंPEOPLE. को असाइन करें चर। -
पंक्ति 7 और 8
PEOPLE. पर पुनरावृति सूची चर और प्रत्येक व्यक्ति का पहला और अंतिम नाम प्रिंट करें।
PEOPLE पंक्ति 6 . से चर ऊपर पायथन में इस तरह दिखेगा:
people = [
(2, 'Brockman', 'Kent', '2018-08-08 21:16:01.888444'),
(3, 'Easter', 'Bunny', '2018-08-08 21:16:01.889060'),
(1, 'Farrell', 'Doug', '2018-08-08 21:16:01.886834')
]
उपरोक्त कार्यक्रम का आउटपुट इस तरह दिखता है:
Kent Brockman
Bunny Easter
Doug Farrell
उपरोक्त कार्यक्रम में, आपको यह जानना होगा कि किसी व्यक्ति का पहला नाम इंडेक्स 2 . पर है , और एक व्यक्ति का अंतिम नाम इंडेक्स 1 . पर है . इससे भी बदतर, person . की आंतरिक संरचना जब भी आप इटरेशन वेरिएबल person किसी फ़ंक्शन या विधि के पैरामीटर के रूप में।
person . के लिए आपको जो वापस मिला है, वह बहुत बेहतर होगा एक पायथन ऑब्जेक्ट था, जहां प्रत्येक फ़ील्ड ऑब्जेक्ट की विशेषता है। यह उन चीजों में से एक है जो SQLAlchemy करती है।
छोटी बॉबी टेबल्स
उपरोक्त कार्यक्रम में, SQL कथन निष्पादित करने के लिए सीधे डेटाबेस में पारित एक साधारण स्ट्रिंग है। इस मामले में, यह कोई समस्या नहीं है क्योंकि SQL पूरी तरह से प्रोग्राम के नियंत्रण में एक स्ट्रिंग अक्षर है। हालांकि, आपके आरईएसटी एपीआई के लिए उपयोग का मामला वेब एप्लिकेशन से उपयोगकर्ता इनपुट लेगा और एसक्यूएल क्वेरी बनाने के लिए इसका इस्तेमाल करेगा। यह हमला करने के लिए आपके आवेदन को खोल सकता है।
आपको भाग 1 से याद होगा कि REST API को एक person प्राप्त करने के लिए PEOPLE . से डेटा इस तरह दिखता था:
GET /api/people/{lname}
इसका मतलब है कि आपका एपीआई एक वैरिएबल की उम्मीद कर रहा है, lname , URL समापन बिंदु पथ में, जिसका उपयोग वह किसी एकल person . को खोजने के लिए करता है . ऐसा करने के लिए ऊपर से Python SQLite कोड को संशोधित करना कुछ इस तरह दिखाई देगा:
1lname = 'Farrell'
2cur.execute('SELECT * FROM person WHERE lname = \'{}\''.format(lname))
उपरोक्त कोड स्निपेट निम्न कार्य करता है:
-
पंक्ति 1
lnameसेट करता है चर से'Farrell'. यह REST API URL समापन बिंदु पथ से आएगा। -
पंक्ति 2 SQL स्ट्रिंग बनाने और उसे निष्पादित करने के लिए Python स्ट्रिंग स्वरूपण का उपयोग करता है।
चीजों को सरल रखने के लिए, उपरोक्त कोड lname . सेट करता है एक स्थिर के लिए परिवर्तनीय, लेकिन वास्तव में यह एपीआई यूआरएल एंडपॉइंट पथ से आएगा और उपयोगकर्ता द्वारा आपूर्ति की जा सकती है। स्ट्रिंग स्वरूपण द्वारा उत्पन्न SQL इस तरह दिखता है:
SELECT * FROM person WHERE lname = 'Farrell'
जब यह SQL डेटाबेस द्वारा निष्पादित किया जाता है, तो यह person को खोजता है एक रिकॉर्ड के लिए तालिका जहां अंतिम नाम 'Farrell' . के बराबर है . यही इरादा है, लेकिन उपयोगकर्ता इनपुट स्वीकार करने वाला कोई भी प्रोग्राम दुर्भावनापूर्ण उपयोगकर्ताओं के लिए भी खुला है। उपरोक्त कार्यक्रम में, जहां lname वेरिएबल उपयोगकर्ता द्वारा आपूर्ति किए गए इनपुट द्वारा सेट किया गया है, यह आपके प्रोग्राम को SQL इंजेक्शन अटैक कहलाता है। इसे प्यार से लिटिल बॉबी टेबल्स के नाम से जाना जाता है:
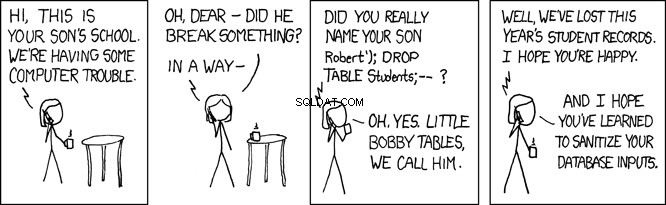
उदाहरण के लिए, एक दुर्भावनापूर्ण उपयोगकर्ता की कल्पना करें, जिसे आपका REST API इस प्रकार कहा जाता है:
GET /api/people/Farrell');DROP TABLE person;
ऊपर दिया गया REST API अनुरोध lname . सेट करता है चर से 'Farrell');DROP TABLE person;' , जो उपरोक्त कोड में यह SQL कथन उत्पन्न करेगा:
SELECT * FROM person WHERE lname = 'Farrell');DROP TABLE person;
उपरोक्त SQL कथन मान्य है, और जब डेटाबेस द्वारा निष्पादित किया जाता है तो उसे एक रिकॉर्ड मिलेगा जहां lname 'Farrell' . से मेल खाता है . फिर, यह SQL स्टेटमेंट डिलीमीटर कैरेक्टर ; को ढूंढेगा और ठीक आगे जाकर पूरी मेज गिरा देगा। यह अनिवार्य रूप से आपके आवेदन को नष्ट कर देगा।
आप अपने एप्लिकेशन के उपयोगकर्ताओं से प्राप्त होने वाले सभी डेटा को स्वच्छ करके अपने कार्यक्रम की सुरक्षा कर सकते हैं। इस संदर्भ में डेटा को साफ करने का मतलब है कि आपका प्रोग्राम उपयोगकर्ता द्वारा प्रदत्त डेटा की जांच कर रहा है और यह सुनिश्चित कर रहा है कि इसमें प्रोग्राम के लिए कुछ भी खतरनाक नहीं है। यह सही करना मुश्किल हो सकता है और इसे हर जगह करना होगा जहां उपयोगकर्ता डेटा डेटाबेस के साथ इंटरैक्ट करता है।
एक और तरीका है जो बहुत आसान है:SQLAlchemy का उपयोग करें। यह SQL स्टेटमेंट बनाने से पहले आपके लिए यूजर डेटा को सेनिटाइज करेगा। डेटाबेस के साथ काम करते समय SQLAlchemy का उपयोग करने का यह एक और बड़ा लाभ और कारण है।
SQLAlchemy के साथ मॉडलिंग डेटा
SQLAlchemy एक बड़ी परियोजना है और पायथन का उपयोग करके डेटाबेस के साथ काम करने के लिए बहुत सारी कार्यक्षमता प्रदान करती है। इसके द्वारा प्रदान की जाने वाली चीजों में से एक ORM, या ऑब्जेक्ट रिलेशनल मैपर है, और इसका उपयोग आप person बनाने और काम करने के लिए करने जा रहे हैं। डेटाबेस तालिका। यह आपको डेटाबेस तालिका से एक पायथन ऑब्जेक्ट में फ़ील्ड की एक पंक्ति को मैप करने की अनुमति देता है।
ऑब्जेक्ट ओरिएंटेड प्रोग्रामिंग आपको डेटा को व्यवहार के साथ जोड़ने की अनुमति देता है, उस डेटा पर काम करने वाले फ़ंक्शन। SQLAlchemy कक्षाएं बनाकर, आप डेटाबेस तालिका पंक्तियों से फ़ील्ड को व्यवहार से जोड़ने में सक्षम हैं, जिससे आप डेटा के साथ बातचीत कर सकते हैं। person . में डेटा के लिए SQLAlchemy वर्ग की परिभाषा यहां दी गई है डेटाबेस तालिका:
class Person(db.Model):
__tablename__ = 'person'
person_id = db.Column(db.Integer,
primary_key=True)
lname = db.Column(db.String)
fname = db.Column(db.String)
timestamp = db.Column(db.DateTime,
default=datetime.utcnow,
onupdate=datetime.utcnow)
वर्ग person db.Model . से इनहेरिट करता है , जो आपको तब मिलेगा जब आप प्रोग्राम कोड बनाना शुरू करेंगे। अभी के लिए, इसका मतलब है कि आप Model . नामक बेस क्लास से इनहेरिट कर रहे हैं , इससे प्राप्त सभी वर्गों के लिए सामान्य गुण और कार्यक्षमता प्रदान करना।
बाकी परिभाषाएँ वर्ग-स्तरीय विशेषताएँ हैं जिन्हें निम्नानुसार परिभाषित किया गया है:
-
__tablename__ = 'person'वर्ग की परिभाषा कोperson. से जोड़ता है डेटाबेस तालिका। -
person_id = db.Column(db.Integer, primary_key=True)एक डेटाबेस कॉलम बनाता है जिसमें एक पूर्णांक होता है जो तालिका के लिए प्राथमिक कुंजी के रूप में कार्य करता है। यह डेटाबेस को यह भी बताता है किperson_idएक स्वत:वृद्धिशील पूर्णांक मान होगा। -
lname = db.Column(db.String)अंतिम नाम फ़ील्ड बनाता है, एक डेटाबेस कॉलम जिसमें एक स्ट्रिंग मान होता है। -
fname = db.Column(db.String)पहला नाम फ़ील्ड बनाता है, एक डेटाबेस कॉलम जिसमें एक स्ट्रिंग मान होता है। -
timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)एक टाइमस्टैम्प फ़ील्ड बनाता है, एक डेटाबेस कॉलम जिसमें दिनांक/समय मान होता है।default=datetime.utcnowपैरामीटर टाइमस्टैम्प मान को वर्तमानutcnow. पर डिफॉल्ट करता है मूल्य जब एक रिकॉर्ड बनाया जाता है।onupdate=datetime.utcnowपैरामीटर टाइमस्टैम्प को वर्तमानutcnow. के साथ अपडेट करता है मान जब रिकॉर्ड अपडेट किया जाता है।
नोट:UTC टाइमस्टैम्प
आप सोच रहे होंगे कि उपरोक्त वर्ग में टाइमस्टैम्प डिफ़ॉल्ट क्यों है और इसे datetime.utcnow() द्वारा अपडेट किया जाता है। विधि, जो एक यूटीसी, या कोऑर्डिनेटेड यूनिवर्सल टाइम लौटाती है। यह आपके टाइमस्टैम्प के स्रोत को मानकीकृत करने का एक तरीका है।
स्रोत, या शून्य समय, यूके के माध्यम से पृथ्वी के उत्तर से दक्षिण ध्रुव तक उत्तर और दक्षिण में चलने वाली एक रेखा है। यह शून्य समय क्षेत्र है जिससे अन्य सभी समय क्षेत्र ऑफसेट होते हैं। इसे शून्य समय स्रोत के रूप में उपयोग करके, आपके टाइमस्टैम्प इस मानक संदर्भ बिंदु से ऑफ़सेट हो जाते हैं।
क्या आपके आवेदन को अलग-अलग समय क्षेत्रों से एक्सेस किया जाना चाहिए, आपके पास दिनांक/समय की गणना करने का एक तरीका है। आपको बस एक UTC टाइमस्टैम्प और गंतव्य समय क्षेत्र चाहिए।
यदि आप अपने टाइमस्टैम्प स्रोत के रूप में स्थानीय समय क्षेत्रों का उपयोग करते हैं, तो आप शून्य समय से ऑफसेट स्थानीय समय क्षेत्र के बारे में जानकारी के बिना दिनांक/समय की गणना नहीं कर सकते। टाइमस्टैम्प स्रोत की जानकारी के बिना, आप तारीख/समय की तुलना या गणित बिल्कुल भी नहीं कर सकते।
UTC पर आधारित टाइमस्टैम्प के साथ काम करना पालन करने के लिए एक अच्छा मानक है। उनके साथ काम करने और उन्हें बेहतर ढंग से समझने के लिए यहां एक टूलकिट साइट है।
आप इस person के साथ कहां जा रहे हैं? वर्ग परिभाषा? अंतिम लक्ष्य SQLAlchemy का उपयोग करके एक क्वेरी चलाने में सक्षम होना और person के उदाहरणों की एक सूची वापस प्राप्त करना है कक्षा। उदाहरण के तौर पर, आइए पिछले SQL स्टेटमेंट को देखें:
SELECT * FROM people ORDER BY lname;
ऊपर से वही छोटा सा उदाहरण प्रोग्राम दिखाएं, लेकिन अब SQLAlchemy का उपयोग कर रहे हैं:
1from models import Person
2
3people = Person.query.order_by(Person.lname).all()
4for person in people:
5 print(f'{person.fname} {person.lname}')
फिलहाल लाइन 1 को नजरअंदाज करते हुए, आप जो चाहते हैं वह सब person है lname . द्वारा आरोही क्रम में क्रमबद्ध रिकॉर्ड खेत। SQLAlchemy कथनों से आपको क्या मिलता है Person.query.order_by(Person.lname).all() person . की एक सूची है person . में सभी रिकॉर्ड के लिए ऑब्जेक्ट उस क्रम में डेटाबेस तालिका। उपरोक्त कार्यक्रम में, PEOPLE वेरिएबल में person . की सूची है वस्तुओं।
कार्यक्रम PEOPLE . पर पुनरावृति करता है चर, प्रत्येक person . को लेकर बदले में और डेटाबेस से व्यक्ति का पहला और अंतिम नाम प्रिंट करना। ध्यान दें कि प्रोग्राम को fname . प्राप्त करने के लिए अनुक्रमणिका का उपयोग करने की आवश्यकता नहीं है या lname मान:यह person . पर परिभाषित विशेषताओं का उपयोग करता है वस्तु।
SQLAlchemy का उपयोग करने से आप कच्चे SQL . के बजाय व्यवहार वाली वस्तुओं के संदर्भ में सोच सकते हैं . यह तब और भी फायदेमंद हो जाता है जब आपके डेटाबेस टेबल बड़े हो जाते हैं और इंटरैक्शन अधिक जटिल हो जाते हैं।
मॉडल किए गए डेटा को क्रम से लगाना/डिसेरिएलाइज़ करना
अपने प्रोग्राम के अंदर SQLAlchemy मॉडल किए गए डेटा के साथ काम करना बहुत सुविधाजनक है। यह उन कार्यक्रमों में विशेष रूप से सुविधाजनक है जो डेटा में हेरफेर करते हैं, शायद गणना करते हैं या स्क्रीन पर प्रस्तुतियाँ बनाने के लिए इसका उपयोग करते हैं। आपका एप्लिकेशन एक REST API है जो अनिवार्य रूप से डेटा पर CRUD संचालन प्रदान करता है, और इस तरह यह अधिक डेटा हेरफेर नहीं करता है।
REST API JSON डेटा के साथ काम करता है, और यहाँ आप SQLAlchemy मॉडल के साथ किसी समस्या का सामना कर सकते हैं। क्योंकि SQLAlchemy द्वारा लौटाया गया डेटा पायथन वर्ग के उदाहरण हैं, Connexion इन वर्ग उदाहरणों को JSON स्वरूपित डेटा में क्रमबद्ध नहीं कर सकता है। भाग 1 से याद रखें कि Connexion वह टूल है जिसका उपयोग आपने YAML फ़ाइल का उपयोग करके REST API को डिज़ाइन और कॉन्फ़िगर करने के लिए किया है, और इसे Python विधियों से कनेक्ट करें।
इस संदर्भ में, क्रमांकन का अर्थ है पायथन ऑब्जेक्ट्स को परिवर्तित करना, जिसमें अन्य पायथन ऑब्जेक्ट और जटिल डेटा प्रकार शामिल हो सकते हैं, सरल डेटा संरचनाओं में जिन्हें JSON डेटाटाइप में पार्स किया जा सकता है, जो यहां सूचीबद्ध हैं:
string: एक स्ट्रिंग प्रकारnumber: पायथन द्वारा समर्थित संख्याएँ (पूर्णांक, फ़्लोट, लंबा)object: एक JSON ऑब्जेक्ट, जो मोटे तौर पर एक पायथन डिक्शनरी के बराबर हैarray: मोटे तौर पर एक पायथन सूची के बराबरboolean: JSON मेंtrue. के रूप में दर्शाया गया है याfalse, लेकिन पायथन मेंTrue. के रूप में याfalsenull: अनिवार्य रूप से एकNoneपायथन में
उदाहरण के तौर पर, आपका person क्लास में एक टाइमस्टैम्प होता है, जो एक पायथन DateTime है . JSON में कोई दिनांक/समय परिभाषा नहीं है, इसलिए JSON संरचना में मौजूद रहने के लिए टाइमस्टैम्प को एक स्ट्रिंग में बदलना होगा।
आपका person वर्ग काफी सरल है इसलिए इससे डेटा विशेषताएँ प्राप्त करना और हमारे REST URL समापन बिंदुओं से वापस आने के लिए मैन्युअल रूप से एक शब्दकोश बनाना बहुत कठिन नहीं होगा। कई बड़े SQLAlchemy मॉडल के साथ अधिक जटिल अनुप्रयोग में, ऐसा नहीं होगा। आपके लिए काम करने के लिए मार्शमैलो नामक मॉड्यूल का उपयोग करना एक बेहतर उपाय है।
मार्शमैलो आपको एक PersonSchema बनाने में मदद करता है वर्ग, जो SQLAlchemy की तरह है person वर्ग हमने बनाया है। हालाँकि, यहाँ डेटाबेस तालिकाओं और फ़ील्ड नामों को वर्ग और उसकी विशेषताओं से मैप करने के बजाय, PersonSchema वर्ग परिभाषित करता है कि किसी वर्ग की विशेषताओं को JSON-अनुकूल स्वरूपों में कैसे परिवर्तित किया जाएगा। हमारे person . में डेटा के लिए मार्शमैलो वर्ग की परिभाषा यहां दी गई है तालिका:
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
वर्ग PersonSchema ma.ModelSchema . से इनहेरिट करता है , जो आपको तब मिलेगा जब आप प्रोग्राम कोड बनाना शुरू करेंगे। अभी के लिए, इसका अर्थ है PersonSchema ModelSchema . नामक मार्शमैलो बेस क्लास से इनहेरिट किया जा रहा है , इससे प्राप्त सभी वर्गों के लिए सामान्य गुण और कार्यक्षमता प्रदान करना।
बाकी की परिभाषा इस प्रकार है:
-
class MetaMeta. नामक वर्ग को परिभाषित करता है अपनी कक्षा के भीतर।ModelSchemaवर्ग किPersonSchemaइस आंतरिकMetaकी तलाश से वर्ग विरासत में मिला है वर्ग और इसका उपयोग SQLAlchemy मॉडल को खोजने के लिए करता हैpersonऔरdb.session. इस प्रकार मार्शमैलोpersonमें विशेषताओं को ढूंढता है वर्ग और उन विशेषताओं के प्रकार ताकि यह जान सके कि उन्हें कैसे क्रमबद्ध/deserialize करना है। -
Modelवर्ग को बताता है कि किस SQLAlchemy मॉडल का उपयोग डेटा को क्रमबद्ध/deserialize करने के लिए और से करना है। -
db.sessionकक्षा को बताता है कि आत्मनिरीक्षण और विशेषता डेटा प्रकारों को निर्धारित करने के लिए किस डेटाबेस सत्र का उपयोग करना है।
आप इस वर्ग परिभाषा के साथ कहाँ जा रहे हैं? आप person . के उदाहरण को क्रमानुसार करने में सक्षम होना चाहते हैं JSON डेटा में क्लास करें, और JSON डेटा को डीसेरियलाइज़ करें और एक person बनाएं इससे क्लास इंस्टेंस।
आरंभिक डेटाबेस बनाएं
SQLAlchemy विशेष डेटाबेस के लिए विशिष्ट कई इंटरैक्शन को संभालता है और आपको डेटा मॉडल के साथ-साथ उनका उपयोग करने पर ध्यान केंद्रित करने देता है।
अब जब आप वास्तव में एक डेटाबेस बनाने जा रहे हैं, जैसा कि पहले उल्लेख किया गया है, तो आप SQLite का उपयोग करेंगे। आप कुछ कारणों से ऐसा कर रहे हैं। यह पायथन के साथ आता है और इसे एक अलग मॉड्यूल के रूप में स्थापित करने की आवश्यकता नहीं है। यह सभी डेटाबेस जानकारी को एक फ़ाइल में सहेजता है और इसलिए इसे स्थापित करना और उपयोग करना आसान है।
MySQL या PostgreSQL जैसे एक अलग डेटाबेस सर्वर को स्थापित करना ठीक काम करेगा, लेकिन इसके लिए उन सिस्टमों को स्थापित करने और उन्हें चालू करने और चलाने की आवश्यकता होगी, जो इस लेख के दायरे से बाहर है।
क्योंकि SQLAlchemy डेटाबेस को संभालता है, कई मायनों में यह वास्तव में कोई फर्क नहीं पड़ता कि अंतर्निहित डेटाबेस क्या है।
आप build_database.py . नामक एक नया उपयोगिता प्रोग्राम बनाने जा रहे हैं SQLite people.db को बनाने और इनिशियलाइज़ करने के लिए डेटाबेस फ़ाइल जिसमें आपका person है डेटाबेस तालिका। रास्ते में, आप दो पायथन मॉड्यूल बनाएंगे, config.py और models.py , जिसका उपयोग build_database.py . द्वारा किया जाएगा और संशोधित server.py भाग 1 से।
यहां आप उन मॉड्यूल के लिए स्रोत कोड पा सकते हैं, जिन्हें आप बनाने जा रहे हैं, जिन्हें यहां पेश किया गया है:
-
config.pyप्रोग्राम में आयात किए गए और कॉन्फ़िगर किए गए आवश्यक मॉड्यूल प्राप्त करता है। इसमें फ्लास्क, कनेक्शन, SQLAlchemy और मार्शमैलो शामिल हैं। क्योंकि इसका उपयोग दोनोंbuild_database.py. द्वारा किया जाएगा औरserver.py, कॉन्फ़िगरेशन के कुछ भाग केवलserver.py. पर लागू होंगे आवेदन। -
models.pyवह मॉड्यूल है जहां आपpersonबनाएंगे SQLAlchemy औरPersonSchemaऊपर वर्णित मार्शमैलो वर्ग की परिभाषाएँ। यह मॉड्यूलconfig.py. पर निर्भर है वहां बनाई और कॉन्फ़िगर की गई कुछ वस्तुओं के लिए।
कॉन्फ़िगर मॉड्यूल
config.py मॉड्यूल, जैसा कि नाम का तात्पर्य है, वह जगह है जहां सभी कॉन्फ़िगरेशन जानकारी बनाई और प्रारंभ की जाती है। हम अपने build_database.py . दोनों के लिए इस मॉड्यूल का उपयोग करने जा रहे हैं प्रोग्राम फ़ाइल और जल्द ही अपडेट होने वाली server.py भाग 1 लेख से फ़ाइल। इसका मतलब है कि हम यहां फ्लास्क, कनेक्शन, SQLAlchemy और मार्शमैलो को कॉन्फ़िगर करने जा रहे हैं।
भले ही build_database.py प्रोग्राम फ्लास्क, कनेक्शन या मार्शमैलो का उपयोग नहीं करता है, यह SQLAlchemy का उपयोग SQLite डेटाबेस से हमारा कनेक्शन बनाने के लिए करता है। यहां config.py के लिए कोड दिया गया है मॉड्यूल:
1import os
2import connexion
3from flask_sqlalchemy import SQLAlchemy
4from flask_marshmallow import Marshmallow
5
6basedir = os.path.abspath(os.path.dirname(__file__))
7
8# Create the Connexion application instance
9connex_app = connexion.App(__name__, specification_dir=basedir)
10
11# Get the underlying Flask app instance
12app = connex_app.app
13
14# Configure the SQLAlchemy part of the app instance
15app.config['SQLALCHEMY_ECHO'] = True
16app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:////' + os.path.join(basedir, 'people.db')
17app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
18
19# Create the SQLAlchemy db instance
20db = SQLAlchemy(app)
21
22# Initialize Marshmallow
23ma = Marshmallow(app)
यहाँ उपरोक्त कोड क्या कर रहा है:
-
पंक्तियां 2 – 4 आयात कनेक्शन जैसा आपने
server.py. में किया था भाग 1 से कार्यक्रम। यहSQLAlchemy. भी आयात करता हैflask_sqlalchemy. से मापांक। यह आपके प्रोग्राम को डेटाबेस एक्सेस देता है। अंत में, यहmarshmallowआयात करता हैflask_marshamllow. से मॉड्यूल। -
पंक्ति 6 वेरिएबल
basedir. बनाता है उस निर्देशिका की ओर इशारा करते हुए जिसमें प्रोग्राम चल रहा है। -
पंक्ति 9
basedir. का उपयोग करता है Connexion ऐप इंस्टेंस बनाने के लिए वैरिएबल और इसेswagger.ymlका रास्ता दें फ़ाइल। -
पंक्ति 12 एक वैरिएबल बनाता है
app, जो कि Connexion द्वारा आरंभ किया गया फ्लास्क इंस्टेंस है। -
पंक्तियां 15
app. का उपयोग करता है SQLAlchemy द्वारा उपयोग किए गए मानों को कॉन्फ़िगर करने के लिए चर। सबसे पहले यहSQLALCHEMY_ECHO. सेट करता है करने के लिएTrue. यह SQLAlchemy को SQL कथनों को प्रतिध्वनित करने का कारण बनता है जो इसे कंसोल पर निष्पादित करता है। डेटाबेस प्रोग्राम बनाते समय समस्याओं को डीबग करने के लिए यह बहुत उपयोगी है। इसेfalseपर सेट करें उत्पादन वातावरण के लिए। -
पंक्ति 16 सेट
SQLALCHEMY_DATABASE_URIकरने के लिएsqlite:////' + os.path.join(basedir, 'people.db'). यह SQLAlchemy को डेटाबेस के रूप में SQLite का उपयोग करने औरpeople.db. नामक फ़ाइल का उपयोग करने के लिए कहता है वर्तमान निर्देशिका में डेटाबेस फ़ाइल के रूप में। अलग-अलग डेटाबेस इंजन, जैसे MySQL और PostgreSQL, में अलग-अलगSQLALCHEMY_DATABASE_URIहोंगे। उन्हें कॉन्फ़िगर करने के लिए तार। -
पंक्ति 17 सेट
SQLALCHEMY_TRACK_MODIFICATIONSकरने के लिएfalse, SQLAlchemy इवेंट सिस्टम को बंद करना, जो डिफ़ॉल्ट रूप से चालू है। ईवेंट सिस्टम ईवेंट-संचालित कार्यक्रमों में उपयोगी ईवेंट उत्पन्न करता है लेकिन महत्वपूर्ण ओवरहेड जोड़ता है। चूंकि आप कोई इवेंट-संचालित प्रोग्राम नहीं बना रहे हैं, इसलिए इस सुविधा को बंद कर दें। -
पंक्ति 19
dbबनाता हैSQLAlchemy(app). पर कॉल करके वेरिएबल . यहapp. पास करके SQLAlchemy को इनिशियलाइज़ करता है कॉन्फ़िगरेशन जानकारी बस सेट करें।dbवेरिएबल वह है जोbuild_database.py. में आयात किया जाता है इसे SQLAlchemy और डेटाबेस तक पहुंच प्रदान करने के लिए प्रोग्राम। यहserver.py. में इसी उद्देश्य को पूरा करेगा कार्यक्रम औरpeople.pyमॉड्यूल। -
पंक्ति 23
maबनाता हैMarshmallow(app). पर कॉल करके वेरिएबल . यह मार्शमैलो को इनिशियलाइज़ करता है और इसे ऐप से जुड़े SQLAlchemy घटकों का आत्मनिरीक्षण करने की अनुमति देता है। यही कारण है कि मार्शमैलो को SQLAlchemy के बाद इनिशियलाइज़ किया गया है।
मॉडल मॉड्यूल
models.py मॉड्यूल person . प्रदान करने के लिए बनाया गया है और PersonSchema डेटा को मॉडलिंग और क्रमबद्ध करने के बारे में ऊपर दिए गए अनुभागों में ठीक उसी तरह से कक्षाएं। यहाँ उस मॉड्यूल के लिए कोड है:
1from datetime import datetime
2from config import db, ma
3
4class Person(db.Model):
5 __tablename__ = 'person'
6 person_id = db.Column(db.Integer, primary_key=True)
7 lname = db.Column(db.String(32), index=True)
8 fname = db.Column(db.String(32))
9 timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
10
11class PersonSchema(ma.ModelSchema):
12 class Meta:
13 model = Person
14 sqla_session = db.session
यहाँ उपरोक्त कोड क्या कर रहा है:
-
पंक्ति 1
datetimeआयात करता हैdatetime. से ऑब्जेक्ट मॉड्यूल जो पायथन के साथ आता है। यह आपकोperson. में टाइमस्टैम्प बनाने का एक तरीका देता है कक्षा। -
पंक्ति 2
dbआयात करता है औरmaconfig.py. में परिभाषित आवृत्ति चर मापांक। यह मॉड्यूल को SQLAlchemy विशेषताओं औरdb. से जुड़ी विधियों तक पहुंच प्रदान करता है चर, और मार्शमैलो विशेषताएँ और विधियाँma. से जुड़ी हैं चर। -
पंक्तियां 4 – 9
personको परिभाषित करें वर्ग जैसा कि ऊपर डेटा मॉडलिंग अनुभाग में चर्चा की गई है, लेकिन अब आप जानते हैं किdb.Modelकि वर्ग की उत्पत्ति से विरासत में मिला है। This gives thePersonclass SQLAlchemy features, like a connection to the database and access to its tables. -
Lines 11 – 14 define the
PersonSchemaclass as was discussed in the data serialzation section above. This class inherits fromma.ModelSchemaand gives thePersonSchemaclass Marshmallow features, like introspecting thePersonclass to help serialize/deserialize instances of that class.
Creating the Database
You’ve seen how database tables can be mapped to SQLAlchemy classes. Now use what you’ve learned to create the database and populate it with data. You’re going to build a small utility program to create and build the database with the People data. Here’s the build_database.py program:
1import os
2from config import db
3from models import Person
4
5# Data to initialize database with
6PEOPLE = [
7 {'fname': 'Doug', 'lname': 'Farrell'},
8 {'fname': 'Kent', 'lname': 'Brockman'},
9 {'fname': 'Bunny','lname': 'Easter'}
10]
11
12# Delete database file if it exists currently
13if os.path.exists('people.db'):
14 os.remove('people.db')
15
16# Create the database
17db.create_all()
18
19# Iterate over the PEOPLE structure and populate the database
20for person in PEOPLE:
21 p = Person(lname=person['lname'], fname=person['fname'])
22 db.session.add(p)
23
24db.session.commit()
Here’s what the above code is doing:
-
Line 2 imports the
dbinstance from theconfig.pymodule. -
Line 3 imports the
Personclass definition from themodels.pymodule. -
Lines 6 – 10 create the
PEOPLEdata structure, which is a list of dictionaries containing your data. The structure has been condensed to save presentation space. -
Lines 13 &14 perform some simple housekeeping to delete the
people.dbfile, if it exists. This file is where the SQLite database is maintained. If you ever have to re-initialize the database to get a clean start, this makes sure you’re starting from scratch when you build the database. -
Line 17 creates the database with the
db.create_all()बुलाना। This creates the database by using thedbinstance imported from theconfigमापांक।dbinstance is our connection to the database. -
Lines 20 – 22 iterate over the
PEOPLElist and use the dictionaries within to instantiate aPersonकक्षा। After it is instantiated, you call thedb.session.add(p)समारोह। This uses the database connection instancedbto access thesessionवस्तु। The session is what manages the database actions, which are recorded in the session. In this case, you are executing theadd(p)method to add the newPersoninstance to thesessionवस्तु। -
Line 24 calls
db.session.commit()to actually save all the person objects created to the database.
नोट: At Line 22, no data has been added to the database. Everything is being saved within the session वस्तु। Only when you execute the db.session.commit() call at Line 24 does the session interact with the database and commit the actions to it.
In SQLAlchemy, the session is an important object. It acts as the conduit between the database and the SQLAlchemy Python objects created in a program. The session helps maintain the consistency between data in the program and the same data as it exists in the database. It saves all database actions and will update the underlying database accordingly by both explicit and implicit actions taken by the program.
Now you’re ready to run the build_database.py program to create and initialize the new database. You do so with the following command, with your Python virtual environment active:
python build_database.py
When the program runs, it will print SQLAlchemy log messages to the console. These are the result of setting SQLALCHEMY_ECHO to True in the config.py फ़ाइल। Much of what’s being logged by SQLAlchemy is the SQL commands it’s generating to create and build the people.db SQLite database file. Here’s an example of what’s printed out when the program is run:
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine PRAGMA table_info("person")
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine
CREATE TABLE person (
person_id INTEGER NOT NULL,
lname VARCHAR,
fname VARCHAR,
timestamp DATETIME,
PRIMARY KEY (person_id)
)
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,975 INFO sqlalchemy.engine.base.Engine COMMIT
2018-09-11 22:20:29,980 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine ('Farrell', 'Doug', '2018-09-12 02:20:29.983143')
2018-09-11 22:20:29,984 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Brockman', 'Kent', '2018-09-12 02:20:29.984821')
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Easter', 'Bunny', '2018-09-12 02:20:29.985462')
2018-09-11 22:20:29,986 INFO sqlalchemy.engine.base.Engine COMMIT
Using the Database
Once the database has been created, you can modify the existing code from Part 1 to make use of it. All of the modifications necessary are due to creating the person_id primary key value in our database as the unique identifier rather than the lname मूल्य।
Update the REST API
None of the changes are very dramatic, and you’ll start by re-defining the REST API. The list below shows the API definition from Part 1 but is updated to use the person_id variable in the URL path:
| Action | HTTP Verb | URL Path | <थ>विवरण|
|---|---|---|---|
| Create | POST | /api/people | Defines a unique URL to create a new person |
| Read | GET | /api/people | Defines a unique URL to read a collection of people |
| Read | GET | /api/people/{person_id} | Defines a unique URL to read a particular person by person_id |
| Update | PUT | /api/people/{person_id} | Defines a unique URL to update an existing person by person_id |
| Delete | DELETE | /api/orders/{person_id} | Defines a unique URL to delete an existing person by person_id |
Where the URL definitions required an lname value, they now require the person_id (primary key) for the person record in the people टेबल। This allows you to remove the code in the previous app that artificially restricted users from editing a person’s last name.
In order for you to implement these changes, the swagger.yml file from Part 1 will have to be edited. For the most part, any lname parameter value will be changed to person_id , and person_id will be added to the POST and PUT responses. You can check out the updated swagger.yml file.
Update the REST API Handlers
With the swagger.yml file updated to support the use of the person_id identifier, you’ll also need to update the handlers in the people.py file to support these changes. In the same way that the swagger.yml file was updated, you need to change the people.py file to use the person_id value rather than lname .
Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people :
1from flask import (
2 make_response,
3 abort,
4)
5from config import db
6from models import (
7 Person,
8 PersonSchema,
9)
10
11def read_all():
12 """
13 This function responds to a request for /api/people
14 with the complete lists of people
15
16 :return: json string of list of people
17 """
18 # Create the list of people from our data
19 people = Person.query \
20 .order_by(Person.lname) \
21 .all()
22
23 # Serialize the data for the response
24 person_schema = PersonSchema(many=True)
25 return person_schema.dump(people).data
Here’s what the above code is doing:
-
Lines 1 – 9 import some Flask modules to create the REST API responses, as well as importing the
dbinstance from theconfig.pyमापांक। In addition, it imports the SQLAlchemyPersonand MarshmallowPersonSchemaclasses to access thepersondatabase table and serialize the results. -
Line 11 starts the definition of
read_all()that responds to the REST API URL endpointGET /api/peopleand returns all the records in thepersondatabase table sorted in ascending order by last name. -
Lines 19 – 22 tell SQLAlchemy to query the
persondatabase table for all the records, sort them in ascending order (the default sorting order), and return a list ofPersonPython objects as the variablepeople। -
Line 24 is where the Marshmallow
PersonSchemaclass definition becomes valuable. You create an instance of thePersonSchema, passing it the parametermany=True. This tellsPersonSchemato expect an interable to serialize, which is what thepeoplevariable is. -
Line 25 uses the
PersonSchemainstance variable (person_schema), calling itsdump()method with thepeopleसूची। The result is an object having adataattribute, an object containing apeoplelist that can be converted to JSON. This is returned and converted by Connexion to JSON as the response to the REST API call.
नोट: The people list variable created on Line 24 above can’t be returned directly because Connexion won’t know how to convert the timestamp field into JSON. Returning the list of people without processing it with Marshmallow results in a long error traceback and finally this Exception:
TypeError: Object of type Person is not JSON serializable
Here’s another part of the person.py module that makes a request for a single person from the person डेटाबेस। Here, read_one(person_id) function receives a person_id from the REST URL path, indicating the user is looking for a specific person. Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people/{person_id} :
1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: ID of person to find
7 :return: person matching ID
8 """
9 # Get the person requested
10 person = Person.query \
11 .filter(Person.person_id == person_id) \
12 .one_or_none()
13
14 # Did we find a person?
15 if person is not None:
16
17 # Serialize the data for the response
18 person_schema = PersonSchema()
19 return person_schema.dump(person).data
20
21 # Otherwise, nope, didn't find that person
22 else:
23 abort(404, 'Person not found for Id: {person_id}'.format(person_id=person_id))
Here’s what the above code is doing:
-
Lines 10 – 12 use the
person_idparameter in a SQLAlchemy query using thefiltermethod of the query object to search for a person with aperson_idattribute matching the passed-inperson_id. Rather than using theall()query method, use theone_or_none()method to get one person, or returnNoneif no match is found. -
Line 15 determines whether a
personwas found or not. -
Line 17 shows that, if
personwas notNone(a matchingpersonwas found), then serializing the data is a little different. You don’t pass themany=Trueparameter to the creation of thePersonSchema()उदाहरण। Instead, you passmany=Falsebecause only a single object is passed in to serialize. -
Line 18 is where the
dumpmethod ofperson_schemais called, and thedataattribute of the resulting object is returned. -
Line 23 shows that, if
personwasNone(a matching person wasn’t found), then the Flaskabort()method is called to return an error.
Another modification to person.py is creating a new person in the database. This gives you an opportunity to use the Marshmallow PersonSchema to deserialize a JSON structure sent with the HTTP request to create a SQLAlchemy Person वस्तु। Here’s part of the updated person.py module showing the handler for the REST URL endpoint POST /api/people :
1def create(person):
2 """
3 This function creates a new person in the people structure
4 based on the passed-in person data
5
6 :param person: person to create in people structure
7 :return: 201 on success, 406 on person exists
8 """
9 fname = person.get('fname')
10 lname = person.get('lname')
11
12 existing_person = Person.query \
13 .filter(Person.fname == fname) \
14 .filter(Person.lname == lname) \
15 .one_or_none()
16
17 # Can we insert this person?
18 if existing_person is None:
19
20 # Create a person instance using the schema and the passed-in person
21 schema = PersonSchema()
22 new_person = schema.load(person, session=db.session).data
23
24 # Add the person to the database
25 db.session.add(new_person)
26 db.session.commit()
27
28 # Serialize and return the newly created person in the response
29 return schema.dump(new_person).data, 201
30
31 # Otherwise, nope, person exists already
32 else:
33 abort(409, f'Person {fname} {lname} exists already')
Here’s what the above code is doing:
-
Line 9 &10 set the
fnameandlnamevariables based on thePersondata structure sent as thePOSTbody of the HTTP request. -
Lines 12 – 15 use the SQLAlchemy
Personclass to query the database for the existence of a person with the samefnameandlnameas the passed-inperson। -
Line 18 addresses whether
existing_personisNone. (existing_personwas not found.) -
Line 21 creates a
PersonSchema()instance calledschema। -
Line 22 uses the
schemavariable to load the data contained in thepersonparameter variable and create a new SQLAlchemyPersoninstance variable callednew_person। -
Line 25 adds the
new_personinstance to thedb.session। -
Line 26 commits the
new_personinstance to the database, which also assigns it a new primary key value (based on the auto-incrementing integer) and a UTC-based timestamp. -
Line 33 shows that, if
existing_personis notNone(a matching person was found), then the Flaskabort()method is called to return an error.
Update the Swagger UI
With the above changes in place, your REST API is now functional. The changes you’ve made are also reflected in an updated swagger UI interface and can be interacted with in the same manner. Below is a screenshot of the updated swagger UI opened to the GET /people/{person_id} खंड। This section of the UI gets a single person from the database and looks like this:
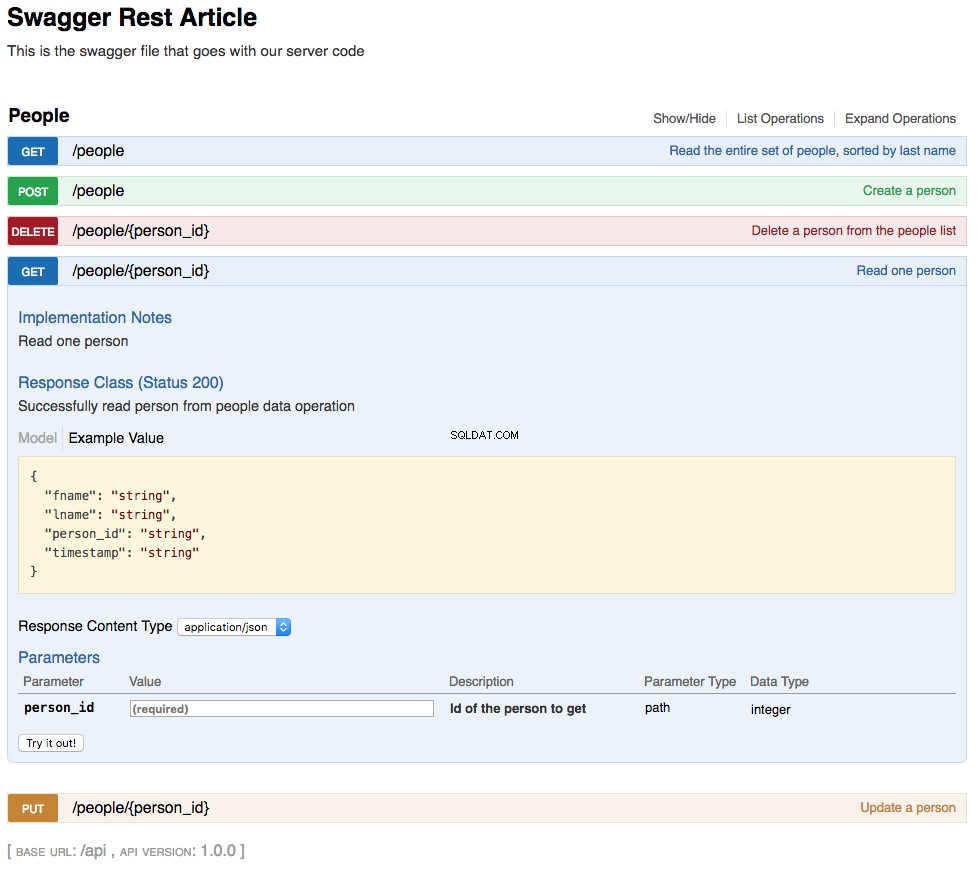
As shown in the above screenshot, the path parameter lname has been replaced by person_id , which is the primary key for a person in the REST API. The changes to the UI are a combined result of changing the swagger.yml file and the code changes made to support that.
Update the Web Application
The REST API is running, and CRUD operations are being persisted to the database. So that it is possible to view the demonstration web application, the JavaScript code has to be updated.
The updates are again related to using person_id instead of lname as the primary key for person data. In addition, the person_id is attached to the rows of the display table as HTML data attributes named data-person-id , so the value can be retrieved and used by the JavaScript code.
This article focused on the database and making your REST API use it, which is why there’s just a link to the updated JavaScript source and not much discussion of what it does.
Example Code
All of the example code for this article is available here. There’s one version of the code containing all the files, including the build_database.py utility program and the server.py modified example program from Part 1.
निष्कर्ष
Congratulations, you’ve covered a lot of new material in this article and added useful tools to your arsenal!
You’ve learned how to save Python objects to a database using SQLAlchemy. You’ve also learned how to use Marshmallow to serialize and deserialize SQLAlchemy objects and use them with a JSON REST API. The things you’ve learned have certainly been a step up in complexity from the simple REST API of Part 1, but that step has given you two very powerful tools to use when creating more complex applications.
SQLAlchemy and Marshmallow are amazing tools in their own right. Using them together gives you a great leg up to create your own web applications backed by a database.
In Part 3 of this series, you’ll focus on the R part of RDBMS :relationships, which provide even more power when you are using a database.