पिछले हफ्ते, मैंने ग्रुपबी सम्मेलन के दौरान अपना टी-एसक्यूएल:खराब आदतें और सर्वोत्तम अभ्यास सत्र प्रस्तुत किया। एक वीडियो रीप्ले और अन्य सामग्रियां यहां उपलब्ध हैं:
- T-SQL :बुरी आदतें और सर्वोत्तम अभ्यास
उस सत्र में जिन वस्तुओं का मैं हमेशा उल्लेख करता हूं उनमें से एक यह है कि मैं आम तौर पर डुप्लीकेट को हटाते समय GROUP BY DISTINCT को प्राथमिकता देता हूं। जबकि DISTINCT बेहतर ढंग से आशय की व्याख्या करता है, और GROUP BY केवल तभी आवश्यक होता है जब एकत्रीकरण मौजूद हो, वे कई मामलों में विनिमेय होते हैं।
आइए वाइड वर्ल्ड इंपोर्टर्स का उपयोग करके कुछ सरल से शुरुआत करें। ये दो प्रश्न एक ही परिणाम उत्पन्न करते हैं:
SELECT DISTINCT Description FROM Sales.OrderLines; SELECT Description FROM Sales.OrderLines GROUP BY Description;
और वास्तव में ठीक उसी निष्पादन योजना का उपयोग करके अपने परिणाम प्राप्त करते हैं:

समान ऑपरेटर, समान संख्या में रीड, CPU में नगण्य अंतर और कुल अवधि (वे बारी-बारी से "जीतते हैं")।
तो मैं DISTINCT पर सिंटैक्स द्वारा वर्डियर और कम सहज ज्ञान युक्त GROUP BY का उपयोग करने की सलाह क्यों दूंगा? खैर, इस साधारण मामले में, यह एक सिक्का फ्लिप है। हालांकि, अधिक जटिल मामलों में, DISTINCT अधिक काम कर सकता है। अनिवार्य रूप से, DISTINCT सभी पंक्तियों को एकत्र करता है, जिसमें किसी भी भाव का मूल्यांकन करने की आवश्यकता होती है, और फिर डुप्लिकेट को बाहर निकाल देता है। GROUP BY (फिर से, कुछ मामलों में) डुप्लिकेट पंक्तियों को पहले . फ़िल्टर कर सकता है उस काम में से कोई भी प्रदर्शन करना।
उदाहरण के लिए, स्ट्रिंग एकत्रीकरण के बारे में बात करते हैं। SQL सर्वर v.Next में रहते हुए आप STRING_AGG (यहां और यहां पोस्ट देखें) का उपयोग करने में सक्षम होंगे, हममें से बाकी लोगों को FOR XML PATH के साथ आगे बढ़ना होगा (और इससे पहले कि आप मुझे बताएं कि इसके लिए रिकर्सिव सीटीई कितने अद्भुत हैं, कृपया इस पोस्ट को भी पढ़ें)। हमारे पास इस तरह की एक क्वेरी हो सकती है, जो Sales.OrderLines तालिका से सभी ऑर्डर को पाइप-सीमांकित सूची के रूप में आइटम विवरण के साथ वापस करने का प्रयास करती है:
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
निम्नलिखित निष्पादन योजना के साथ इस प्रकार की समस्या को हल करने के लिए यह एक विशिष्ट क्वेरी है (सभी योजनाओं में चेतावनी केवल XPath फ़िल्टर से निकलने वाले निहित रूपांतरण के लिए है):
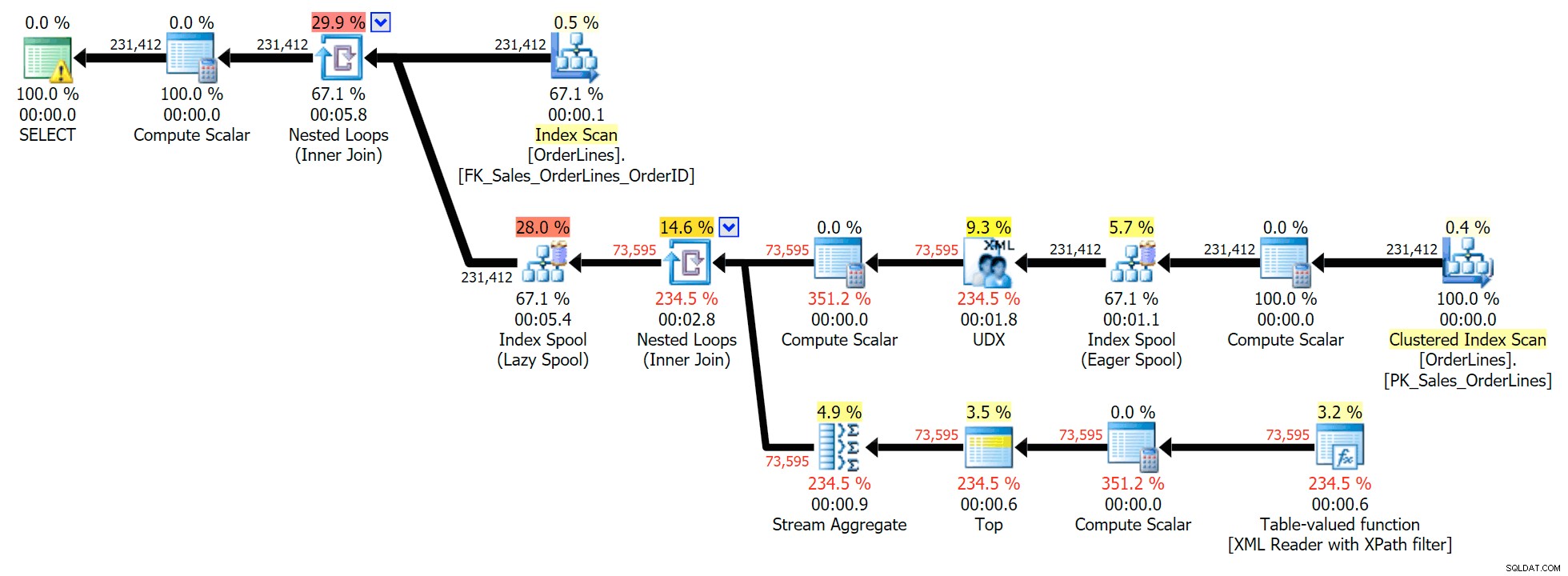
हालाँकि, इसमें एक समस्या है जिसे आप पंक्तियों की आउटपुट संख्या में देख सकते हैं। आउटपुट को आकस्मिक रूप से स्कैन करते समय आप निश्चित रूप से इसका पता लगा सकते हैं:

प्रत्येक आदेश के लिए, हम पाइप-सीमांकित सूची देखते हैं, लेकिन हम प्रत्येक आइटम के लिए एक पंक्ति देखते हैं प्रत्येक क्रम में। कॉलम सूची पर एक DISTINCT फेंकना घुटने के बल चलने वाली प्रतिक्रिया है:
SELECT DISTINCT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
यह डुप्लिकेट को हटा देता है (और स्कैन पर ऑर्डरिंग गुणों को बदल देता है, इसलिए परिणाम आवश्यक रूप से अनुमानित क्रम में प्रकट नहीं होंगे), और निम्नलिखित निष्पादन योजना तैयार करता है:
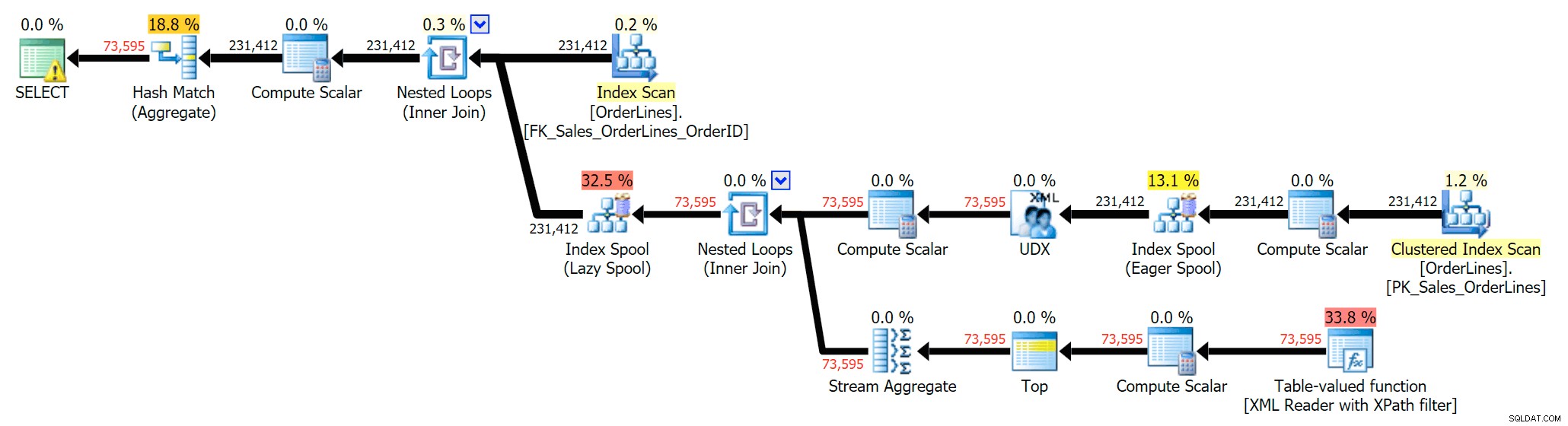
ऐसा करने का एक और तरीका है ऑर्डर आईडी के लिए ग्रुप बाय जोड़ना (चूंकि सबक्वायरी को स्पष्ट रूप से जरूरत नहीं है GROUP BY में फिर से संदर्भित होने के लिए):
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o GROUP BY o.OrderID;
यह वही परिणाम देता है (हालांकि आदेश वापस आ गया है), और थोड़ा अलग योजना:
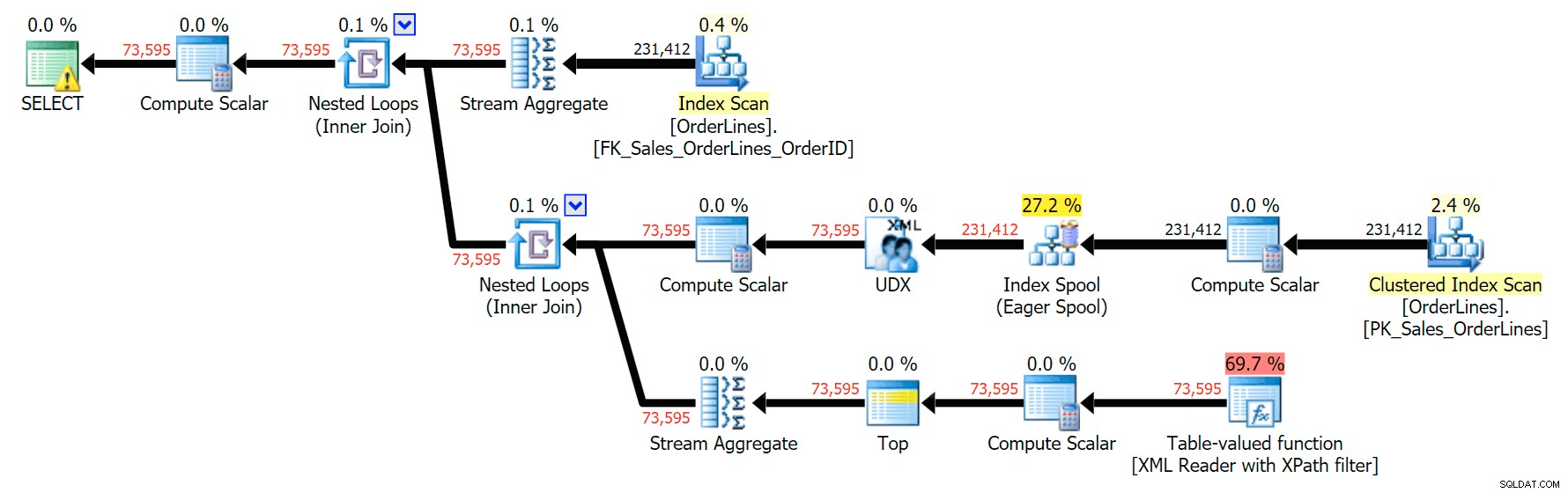
हालांकि, प्रदर्शन मेट्रिक्स की तुलना करना दिलचस्प है।

GROUP BY वेरिएशन की तुलना में DISTINCT वेरिएशन में 4X जितना लंबा समय लगा, CPU का 4X और लगभग 6X रीड्स का इस्तेमाल किया। (याद रखें, ये क्वेरी ठीक वही परिणाम देती हैं।)
हम निष्पादन योजनाओं की तुलना तब भी कर सकते हैं जब हम CPU + I/O से लागतों को केवल I/O से जोड़ते हैं, जो प्लान एक्सप्लोरर के लिए विशिष्ट विशेषता है। हम पुनर्मूल्यांकित मान भी दिखाते हैं (जो वास्तविक . पर आधारित होते हैं क्वेरी निष्पादन के दौरान देखी गई लागत, एक विशेषता जो केवल प्लान एक्सप्लोरर में पाई जाती है)। यहाँ DISTINCT योजना है:
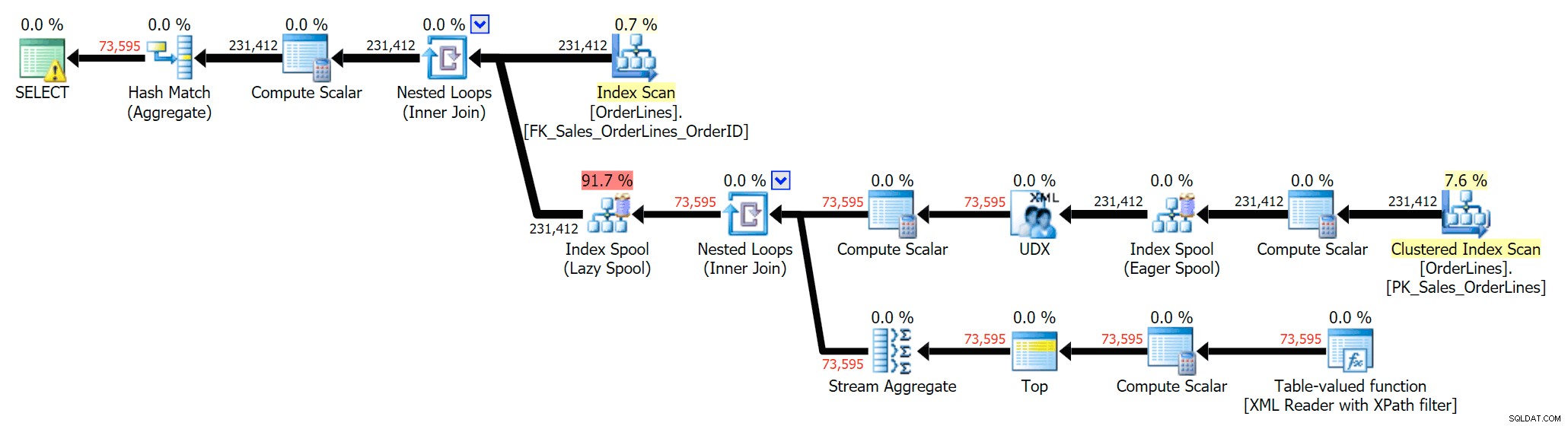
और ये है ग्रुप बाय प्लान:
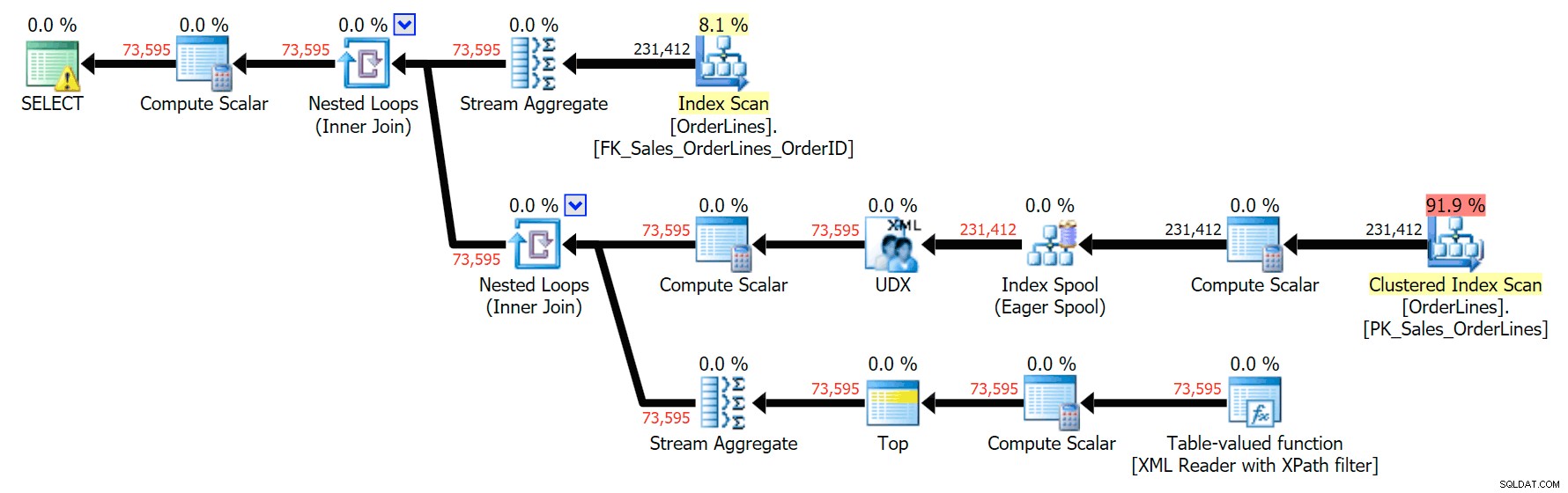
आप देख सकते हैं कि, GROUP BY योजना में, लगभग सभी I/O लागत स्कैन में है (यहां CI स्कैन के लिए टूलटिप है, जो ~3.4 "क्वेरी रुपये" की I/O लागत दिखाती है)। फिर भी DISTINCT योजना में, अधिकांश I/O लागत इंडेक्स स्पूल में है (और यहां वह टूलटिप है; यहां I/O लागत ~ 41.4 "क्वेरी रुपये" है)। ध्यान दें कि सीपीयू इंडेक्स स्पूल के साथ भी बहुत अधिक है। हम दूसरी बार "क्वेरी रुपये" के बारे में बात करेंगे, लेकिन मुद्दा यह है कि इंडेक्स स्पूल स्कैन की तुलना में 10X से अधिक महंगा है - फिर भी दोनों योजनाओं में स्कैन अभी भी समान 3.4 है। यह एक कारण है कि यह हमेशा मुझे परेशान करता है जब लोग कहते हैं कि उन्हें योजना में ऑपरेटर को उच्चतम लागत के साथ "ठीक" करने की आवश्यकता है। योजना में कुछ ऑपरेटर हमेशा . करेंगे सबसे महंगा हो; इसका मतलब यह नहीं है कि इसे ठीक करने की आवश्यकता है।
@AaronBertrand वे प्रश्न वास्तव में तार्किक रूप से समकक्ष नहीं हैं - DISTINCT है दोनों कॉलम पर, जबकि आपका ग्रुप BY केवल एक पर है
- एडम मचानिक (@AdamMachanic) 20 जनवरी, 2017
जबकि एडम मचानिक सही है जब वह कहता है कि ये प्रश्न शब्दार्थ रूप से भिन्न हैं, परिणाम समान है - हमें समान पंक्तियों की संख्या मिलती है, जिसमें बिल्कुल समान परिणाम होते हैं, और हमने इसे बहुत कम रीड और सीपीयू के साथ किया।
इसलिए जबकि DISTINCT और GROUP BY बहुत सारे परिदृश्यों में समान हैं, यहाँ एक ऐसा मामला है जहाँ GROUP BY दृष्टिकोण निश्चित रूप से बेहतर प्रदर्शन की ओर ले जाता है (क्वेरी में ही कम स्पष्ट घोषणात्मक इरादे की कीमत पर)। मुझे यह जानने में दिलचस्पी होगी कि क्या आपको लगता है कि कोई ऐसा परिदृश्य है जहां DISTINCT GROUP BY से बेहतर है, कम से कम प्रदर्शन के मामले में, जो शैली की तुलना में बहुत कम व्यक्तिपरक है या क्या किसी कथन को स्व-दस्तावेज बनाने की आवश्यकता है।
यह पोस्ट मेरी "आश्चर्य और धारणा" श्रृंखला में फिट बैठता है क्योंकि सीमित अवलोकनों या विशेष उपयोग के मामलों के आधार पर हमारे पास सत्य के रूप में कई चीजें अन्य परिदृश्यों में उपयोग किए जाने पर परीक्षण की जा सकती हैं। हमें बस इतना याद रखना है कि इसे SQL क्वेरी ऑप्टिमाइज़ेशन के हिस्से के रूप में करने के लिए समय निकालना है…
संदर्भ
- एसक्यूएल सर्वर में समूहीकृत संयोजन
- ग्रुप्ड कॉन्सटेनेशन :डुप्लीकेट ऑर्डर करना और हटाना
- समूहबद्ध संयोजन के लिए चार व्यावहारिक उपयोग के मामले
- SQL सर्वर v.अगला:STRING_AGG() प्रदर्शन
- SQL सर्वर v.अगला :STRING_AGG प्रदर्शन, भाग 2



