SQL सर्वर 2008 में वापस पेश की गई कई नई सुविधाओं में से एक डेटा संपीड़न था। या तो पंक्ति या पृष्ठ स्तर पर संपीड़न डिस्क स्थान को बचाने का अवसर प्रदान करता है, डेटा को संपीड़ित और डिकम्प्रेस करने के लिए थोड़ा अधिक CPU की आवश्यकता के व्यापार बंद के साथ। यह अक्सर तर्क दिया जाता है कि अधिकांश सिस्टम आईओ-बाध्य हैं, सीपीयू-बाध्य नहीं हैं, इसलिए व्यापार बंद इसके लायक है। कैच? डेटा संपीड़न का उपयोग करने के लिए आपको एंटरप्राइज़ संस्करण पर होना था। SQL सर्वर 2016 SP1 की रिलीज़ के साथ, यह बदल गया है! यदि आप SQL Server 2016 SP1 और उच्चतर का मानक संस्करण चला रहे हैं, तो अब आप डेटा संपीड़न का उपयोग कर सकते हैं। कंप्रेशन के लिए एक नया बिल्ट-इन फंक्शन भी है, COMPRESS (और इसके समकक्ष DECOMPRESS)। डेटा संपीड़न ऑफ-पंक्ति डेटा पर काम नहीं करता है, इसलिए यदि आपकी तालिका में NVARCHAR (MAX) जैसा कॉलम है, जिसमें आमतौर पर आकार में 8000 बाइट्स से अधिक मान हैं, तो वह डेटा संपीड़ित नहीं होगा (उस अनुस्मारक के लिए एडम मैकैनिक धन्यवाद) . COMPRESS फ़ंक्शन इस समस्या को हल करता है, और आकार में 2GB तक डेटा को संपीड़ित करता है। इसके अलावा, जबकि मैं तर्क दूंगा कि फ़ंक्शन का उपयोग केवल बड़े, ऑफ-रो डेटा के लिए किया जाना चाहिए, मैंने सोचा कि इसे सीधे पंक्ति और पृष्ठ संपीड़न के साथ तुलना करना एक सार्थक प्रयोग था।
सेटअप
परीक्षण डेटा के लिए, मैं एक स्क्रिप्ट से काम कर रहा हूं जिसे हारून बर्ट्रेंड ने पहले इस्तेमाल किया है, लेकिन मैंने कुछ बदलाव किए हैं। मैंने परीक्षण के लिए एक अलग डेटाबेस बनाया लेकिन आप tempdb या किसी अन्य नमूना डेटाबेस का उपयोग कर सकते हैं, और फिर मैंने एक ग्राहक तालिका के साथ शुरुआत की जिसमें तीन NVARCHAR कॉलम हैं। मैंने बड़े कॉलम बनाने और उन्हें दोहराए जाने वाले अक्षरों के तारों के साथ पॉप्युलेट करने पर विचार किया, लेकिन पठनीय पाठ का उपयोग एक नमूना देता है जो अधिक यथार्थवादी है और इस प्रकार अधिक सटीकता प्रदान करता है।
नोट: यदि आप संपीड़न को लागू करने में रुचि रखते हैं और जानना चाहते हैं कि यह आपके वातावरण में भंडारण और प्रदर्शन को कैसे प्रभावित करेगा, तो मैं अत्यधिक अनुशंसा करता हूं कि आप इसका परीक्षण करें। मैं आपको नमूना डेटा के साथ कार्यप्रणाली दे रहा हूं; इसे अपने परिवेश में लागू करने में अतिरिक्त कार्य शामिल नहीं होना चाहिए।
आप नीचे देखेंगे कि डेटाबेस बनाने के बाद हम क्वेरी स्टोर को सक्षम कर रहे हैं। जब हम केवल SQL सर्वर में अंतर्निहित कार्यक्षमता का उपयोग कर सकते हैं, तो हमारे प्रदर्शन मेट्रिक्स को आज़माने और ट्रैक करने के लिए एक अलग तालिका क्यों बनाएं?!
उपयोग [मास्टर]; डेटाबेस बनाएं [ग्राहक डीबी] कंटेनर =प्राथमिक पर कोई नहीं (नाम =एन'ग्राहक डीबी', फ़ाइलनाम =एन'सी:\ डेटाबेस \ ग्राहकडीबी.एमडीएफ', आकार =4096 एमबी, MAXSIZE =असीमित, FILEGROWTH =65536केबी) लॉग ऑन करें (नाम =एन'ग्राहकडीबी_लॉग', फ़ाइलनाम =एन'सी:\डेटाबेस\ग्राहकडीबी_लॉग.एलडीएफ', आकार =2048एमबी, MAXSIZE =असीमित, फ़ाइलग्रोथ =65536केबी);; गोल्टर डेटाबेस [CustomerDB] रिकवरी सिंपल सेट करें; गोल्टर डेटाबेस [CustomerDB] सेट क्वेरी_स्टोर =ऑन; गोल्टर डेटाबेस [CustomerDB] सेट क्वेरी_स्टोर (ऑपरेशन_मोड =read_write, क्लीनअप_फॉली =256, QUERY_CAPTURE_MODE =सभी, SIZE_BASED_CLEANUP_MODE =AUTO, MAX_PLANS_PER_QUERY =200);GO
अब हम डेटाबेस के अंदर कुछ चीजें सेट करेंगे:
उपयोग [CustomerDB];GOALTER DATABASE SCOPED CONFIGURATION SET MAXDOP =0;GO -- नोट:मैंने [ईमेल] पर अद्वितीय अनुक्रमणिका को हटा दिया जो कि हारून के संस्करण CREATE TABLE [dbo] में था। [ग्राहक] ( [ग्राहक आईडी] [int ] न्यूल नहीं, [फर्स्टनाम] [नवरचर] (64) नॉट न्यूल, [लास्टनाम] [नवरचर] (64) नॉट न्यूल, [ईमेल] [नवरचर] (320) नॉट न्यूल, [एक्टिव] [बिट] नॉट न्यूल डिफॉल्ट 1 , [बनाया गया] [डेटाटाइम] नॉट डिफॉल्ट सिस्डेटटाइम (), [अपडेटेड] [डेटटाइम] न्यूल, कंस्ट्रेंट [पीके_कस्टमर] प्राथमिक कुंजी क्लस्टर ([ग्राहक आईडी])); गैर-अनुक्रमित सूचकांक बनाएं [सक्रिय_ग्राहक] पर [डीबीओ]। [ग्राहक ]([प्रथम नाम], [अंतिम नाम], [ईमेल]) जहां ([सक्रिय] =1); गैर-अनुक्रमित अनुक्रमणिका बनाएं [फ़ोनबुक_ग्राहक] [डीबीओ] पर जाएं। [ग्राहक] ([अंतिम नाम], [प्रथम नाम]) शामिल करें ([ ईमेल]);
बनाई गई तालिका के साथ, हम कुछ डेटा जोड़ेंगे, लेकिन हम 1 मिलियन के बजाय 5 मिलियन पंक्तियाँ जोड़ रहे हैं। इसे मेरे लैपटॉप पर चलने में लगभग आठ मिनट का समय लगता है।
INSERT dbo.Customers with (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) सेलेक्ट rn =ROW_NUMBER() ओवर (ऑर्डर बाय n), fn, ln, em, a FROM ( सेलेक्ट टॉप (5000000) ) fn, ln, em, a =MAX(a), n =MAX(NEWID ()) से (चुनें fn, ln, em, a, r =ROW_NUMBER() ओवर (उन्हें ऑर्डर के अनुसार विभाजन) से (चुनें) टॉप (20000000) fn =LEFT (o.name, 64), ln =LEFT(c.name, 64), em =LEFT(o.name, LEN(c.name)%5+1) + '.' + LEFT(c.name, LEN(o.name)%5+2) + '@' + RIGHT(c.name, LEN(o.name + c.name)%12 + 1) + LEFT(RTRIM(CHECKSUM( NEWID ())), 3) + '.com', a =मामला जब c.name '%y%' जैसा हो, तो 0 ELSE 1 sys.all_objects से समाप्त होता है जैसे कि sys.all_columns के रूप में sys.all_columns को क्रॉस जॉइन करें NEWID द्वारा आदेश () ) AS x ) AS y जहाँ r =1 ग्रुप बाय fn, ln, em ORDER BY n ) AS z ORDER BY rn;GO
अब हम तीन और तालिकाएँ बनाएंगे:एक पंक्ति संपीड़न के लिए, एक पृष्ठ संपीड़न के लिए, और एक COMPRESS फ़ंक्शन के लिए। ध्यान दें कि COMPRESS फ़ंक्शन के साथ, आपको कॉलम को VARBINARY डेटा प्रकार के रूप में बनाना होगा। परिणामस्वरूप, टेबल पर कोई गैर-संकुल अनुक्रमणिका नहीं है (क्योंकि आप एक varbinary स्तंभ पर अनुक्रमणिका कुंजी नहीं बना सकते हैं)।
टेबल बनाएं [dbo]। nvarchar](320) नॉट न्यूल, [सक्रिय] [बिट] नॉट डिफॉल्ट 1, [बनाया गया] [डेटाटाइम] नॉट डिफॉल्ट सिस्टमटाइम (), [अपडेटेड] [डेटाटाइम] न्यूल, कॉन्स्ट्रेंट [पीके_कस्टमर_पेज] प्राथमिक कुंजी क्लस्टर ([ग्राहक आईडी) ]));जाओ गैर-अनुक्रमित अनुक्रमणिका बनाएं [Active_Customers_Page] पर [dbo]। dbo]। ) न्यूल नहीं, [लास्टनाम] [नवरचर] (64) नॉट न्यूल, [ईमेल] [नवरचर] (320) न्यूल नहीं, [सक्रिय] [बिट] नॉट डिफॉल्ट 1, [बनाया गया] [डेटाटाइम] नॉट डिफॉल्ट सिस्टमटाइम ( ), [अपडेट किया गया] [डेटाटाइम] शून्य, सीमित [PK_Customers_Row] प्राथमिक कुंजी क्लस्टर ([ग्राहक आईडी])); गैर-संकुलित भारत बनाएं EX [Active_Customers_Row] ऑन [dbo]। [अंतिम नाम], [प्रथम नाम]) शामिल करें ([ईमेल]); तालिका बनाएं [डीबीओ]। [varbinary] (अधिकतम) न्यूल नहीं, [ईमेल] [varbinary] (अधिकतम) न्यूल नहीं, [सक्रिय] [बिट] न्यूल डिफॉल्ट 1, [बनाया गया] [डेटाटाइम] नॉट डिफॉल्ट SYSDATETIME (), [अपडेट किया गया] [डेटाटाइम ] शून्य, सीमित [PK_Customers_Compress] प्राथमिक कुंजी क्लस्टर ([ग्राहक आईडी]));जाओ
आगे हम [dbo] से डेटा कॉपी करेंगे। [ग्राहक] अन्य तीन तालिकाओं में। यह हमारे पृष्ठ और पंक्ति तालिकाओं के लिए एक सीधा INSERT है और प्रत्येक INSERT के लिए लगभग दो से तीन मिनट का समय लगता है, लेकिन COMPRESS फ़ंक्शन के साथ एक स्केलेबिलिटी समस्या है:एक बार में 5 मिलियन पंक्तियों को सम्मिलित करने का प्रयास करना उचित नहीं है। नीचे दी गई स्क्रिप्ट 50,000 के बैच में पंक्तियों को सम्मिलित करती है, और 5 मिलियन के बजाय केवल 1 मिलियन पंक्तियों को सम्मिलित करती है। मुझे पता है, इसका मतलब है कि हम यहां तुलना के लिए वास्तव में सेब-से-सेब नहीं हैं, लेकिन मैं इसके साथ ठीक हूं। मेरी मशीन पर 1 मिलियन पंक्तियों को सम्मिलित करने में 10 मिनट लगते हैं; बेझिझक स्क्रिप्ट में बदलाव करें और अपने स्वयं के परीक्षणों के लिए 50 लाख पंक्तियाँ सम्मिलित करें।
INSERT dbo.Customers_Page with (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) Select CustomerID, FirstName, LastName, EMail, [Active]FROM dbo.Customers;GO INSERT dbo.Customers_Row with (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) Select CustomerID, FirstName, LastName, EMail, [Active] from dbo.Customers; GO DECLARE ON DECLARE @StartID INT =1DECLARE @EndID INT =50000DECLARE @Increment INT =50000DECLARE @IDMax INT =1000000 जबकि @StartID <@IDMaxBEGIN INSERT dbo.Customers_Compress with (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) शीर्ष 100000 CustomerID, COMPRESS (FirstName), COMPRESS (LastName), COMPRESS(EMAIL) का चयन करें ), [सक्रिय] dbo.Customers से जहां [CustomerID] @StartID और @EndID के बीच; सेट @StartID =@StartID + @Increment; SET @EndID =@EndID + @Increment;END
हमारे सभी तालिकाओं के साथ, हम आकार की जांच कर सकते हैं। इस बिंदु पर, हमने ROW या PAGE कंप्रेशन को लागू नहीं किया है, लेकिन COMPRESS फ़ंक्शन का उपयोग किया गया है:
चुनें [ओ]। /1024 एएस [इंडेक्स साइज (एमबी)], [पी]। [डेटा_कंप्रेशन_डेस्क] [एसआईएस] से। ]। [विभाजन_आईडी] [एसआईएस] में शामिल हों। [ऑब्जेक्ट्स] [ओ] ऑन [पी]। [ऑब्जेक्ट_आईडी] =[ओ]। [ऑब्जेक्ट_आईडी] जॉइन [एसआईएस]। [इंडेक्स] [आई] ऑन [पी]। [ऑब्जेक्ट_आईडी ] =[i]। [object_id] और [p]। [index_id] =[i]। [index_id] जहां [o]। [is_ms_shipped] =0GROUP BY [o]। [नाम], [i]। [index_id ], [i]। [नाम], [p]। [पंक्तियाँ], [p]। [data_compression_desc] [o] द्वारा आदेश। [नाम], [i]। [index_id];
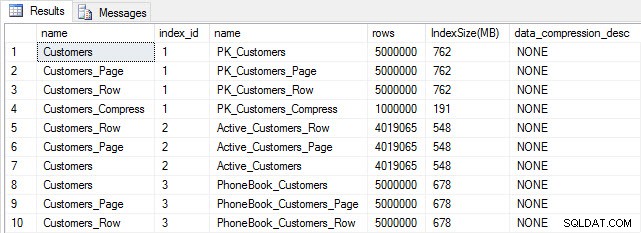 सम्मिलित करने के बाद तालिका और अनुक्रमणिका का आकार
सम्मिलित करने के बाद तालिका और अनुक्रमणिका का आकार
जैसी अपेक्षित थी, Customers_Compress को छोड़कर सभी तालिकाएँ लगभग समान आकार की हैं। अब हम क्रमशः Customers_Row और Customers_Page पर पंक्ति और पृष्ठ संपीड़न को लागू करते हुए, सभी तालिकाओं पर अनुक्रमणिका का पुनर्निर्माण करेंगे।
ऑल्टर इंडेक्स ऑल ऑन डीबीओ। कस्टमर्स रीबिल्ड;गोल्टर इंडेक्स ऑल ऑन डीबीओ। कस्टमर्स_पेज रीबिल्ड विथ (DATA_COMPRESSION =पेज); GOALTER INDEX ऑल ऑन डीबीओ। Customers_Row रिबिल्ड विद (DATA_COMPRESSION);;
यदि हम संपीड़न के बाद तालिका आकार की जांच करते हैं, तो अब हम अपनी डिस्क स्थान बचत देख सकते हैं:
चुनें [ओ]। /1024 एएस [इंडेक्स साइज (एमबी)], [पी]। [डेटा_कंप्रेशन_डेस्क] [एसआईएस] से। ]। [विभाजन_आईडी] [एसआईएस] में शामिल हों। [ऑब्जेक्ट्स] [ओ] ऑन [पी]। [ऑब्जेक्ट_आईडी] =[ओ]। [ऑब्जेक्ट_आईडी] जॉइन [एसआईएस]। [इंडेक्स] [आई] ऑन [पी]। [ऑब्जेक्ट_आईडी ] =[i]। [object_id] और [p]। [index_id] =[i]। [index_id] जहां [o]। [is_ms_shipped] =0GROUP BY [o]। [नाम], [i]। [index_id ], [i]। [नाम], [p]। [पंक्तियाँ], [p]। [data_compression_desc] [i] द्वारा आदेश। [index_id], [IndexSize(MB)] DESC;
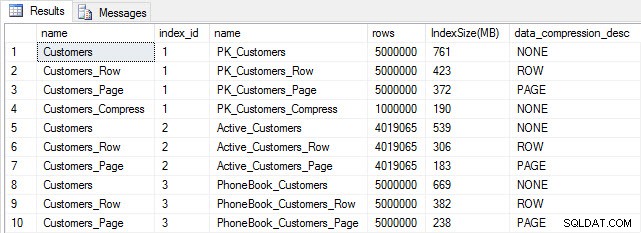
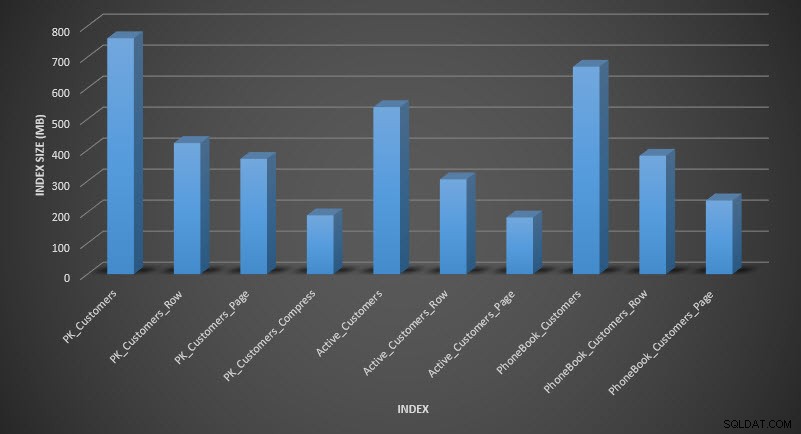 संपीड़न के बाद सूचकांक का आकार
संपीड़न के बाद सूचकांक का आकार
जैसा कि अपेक्षित था, पंक्ति और पृष्ठ संपीड़न तालिका और उसके सूचकांक के आकार को काफी कम कर देता है। COMPRESS फ़ंक्शन ने हमें सबसे अधिक स्थान बचाया - क्लस्टर इंडेक्स मूल तालिका के आकार का एक चौथाई है।
क्वेरी प्रदर्शन की जांच करना
क्वेरी प्रदर्शन का परीक्षण करने से पहले, ध्यान दें कि हम INSERT और REBUILD प्रदर्शन को देखने के लिए क्वेरी स्टोर का उपयोग कर सकते हैं:
चुनें [क्यू]। [क्वेरी_आईडी], [क्यूटी]। [क्वेरी_एसक्यूएल_टेक्स्ट], एसयूएम ([आरएस]। AVG([rs].[avg_cpu_time]) [AvgCPU], AVG([rs].[avg_logic_io_reads]) [AvgLogicalReads], AVG([rs]। क्यू] [sys] में शामिल हों। [query_store_query_text] [क्यूटी] पर [क्यू]। [query_text_id] =[क्यूटी]। [query_text_id] बाएं बाहरी जॉइन [sys]। [ऑब्जेक्ट्स] [ओ] ऑन [क्यू]। [ऑब्जेक्ट_आईडी] =[ओ]। [ऑब्जेक्ट_आईडी] [एसआईएस] में शामिल हों। [क्वेरी_स्टोर_प्लान] [पी] ऑन [क्यू]। [क्वेरी_आईडी] =[पी]। [क्वेरी_आईडी] जॉइन [एसआईएस]। [क्वेरी_स्टोर_रनटाइम_स्टैट्स] [आरएस] ऑन [पी] .[plan_id] =[rs]। [क्यू]। [ऑब्जेक्ट_आईडी], [ओ]। [नाम], [क्यूटी]। [क्वेरी_एसक्यूएल_टेक्स्ट], [आरएस]। [प्लान_आईडी] ऑर्डर बाय [क्यू]। [क्वेरी_आईडी];
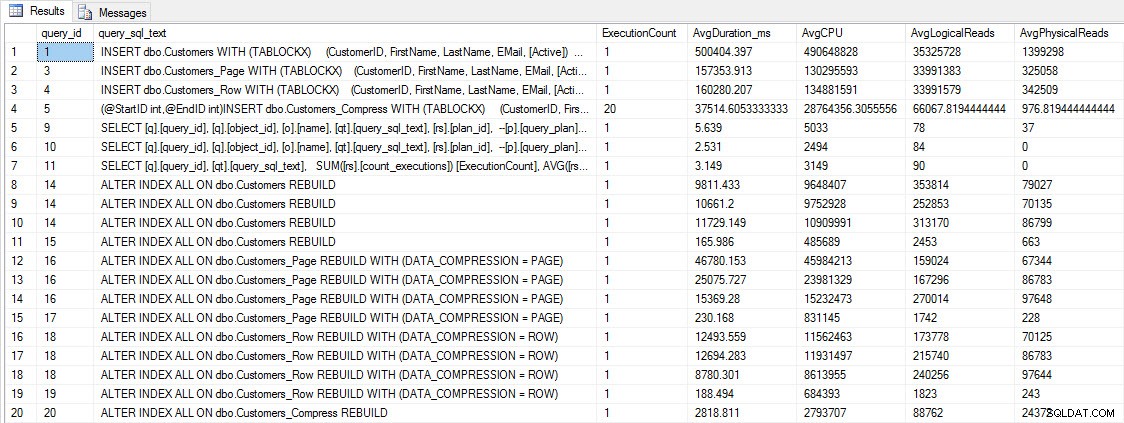 INSERT और REBUILD प्रदर्शन मेट्रिक्स
INSERT और REBUILD प्रदर्शन मेट्रिक्स
हालांकि यह डेटा दिलचस्प है, मैं इस बारे में अधिक उत्सुक हूं कि संपीड़न मेरे दैनिक चयन प्रश्नों को कैसे प्रभावित करता है। मेरे पास तीन संग्रहीत प्रक्रियाओं का एक सेट है जिसमें प्रत्येक के पास एक चयन क्वेरी है, ताकि प्रत्येक अनुक्रमणिका का उपयोग किया जा सके। मैंने प्रत्येक तालिका के लिए इन प्रक्रियाओं को बनाया, और फिर परीक्षण के लिए उपयोग करने के लिए पहले और अंतिम नामों के मूल्यों को खींचने के लिए एक स्क्रिप्ट लिखी। प्रक्रियाओं को बनाने के लिए यहां स्क्रिप्ट है।
एक बार हमारे पास संग्रहीत कार्यविधियाँ बन जाने के बाद, हम उन्हें कॉल करने के लिए नीचे दी गई स्क्रिप्ट चला सकते हैं। इसे शुरू करें और फिर कुछ मिनट प्रतीक्षा करें…
सेट नोकाउंट ऑन; GO DECLARE @RowNum INT =1; DECLARE @Round INT =1; DECLARE @ID INT =1; DECLARE @FN NVARCHAR (64); DECLARE @LN NVARCHAR (64); DECLARE @SQLstring NVARCHAR ( मैक्स); ड्रॉप टेबल अगर मौजूद है #FirstNames, #LastNames; DISTINCT [FirstName], DENSE_RANK() ओवर ([FirstName] द्वारा ऑर्डर करें) RowNumINTO के रूप में #FirstNamesFROM [dbo] चुनें। dbo]। [ग्राहक] जबकि 1=1BEGIN @FN =चुनें (#FirstNames से चुनें [FirstName] जहां RowNum =@RowNum) @LN चुनें =(#LastNames से [LastName] चुनें जहां RowNum =@RowNum) SET @FN =सबस्ट्रिंग(@FN, 1,5) + '%' SET @LN =सबस्ट्रिंग(@LN, 1,5) + '%' EXEC [dbo]। [usp_FindActiveCustomer_C] @FN; EXEC [डीबीओ]। [usp_FindAnyCustomer_C] @LN; EXEC [डीबीओ]। [usp_FindSpecificCustomer_C] @ID; EXEC [डीबीओ]। [usp_FindActiveCustomer_P] @FN; EXEC [डीबीओ]। [usp_FindAnyCustomer_P] @LN; EXEC [डीबीओ]। [usp_FindSpecificCustomer_P] @ID; EXEC [डीबीओ]। [usp_FindActiveCustomer_R] @FN; EXEC [डीबीओ]। [usp_FindAnyCustomer_R] @LN; EXEC [डीबीओ]। [usp_FindSpecificCustomer_R] @ID; EXEC [डीबीओ]। [usp_FindActiveCustomer_CS] @FN; EXEC [डीबीओ]। [usp_FindAnyCustomer_CS] @LN; EXEC [डीबीओ]। [usp_FindSpecificCustomer_CS] @ID; IF @ID <5000000 BEGIN SET @ID =@ID + @Round END ELSE BEGIN SET @ID =2 END IF @Round <26 BEGIN SET @Round =@Round + 1 END ELSE BEGIN IF @RowNum <2260 BEGIN SET @RowNum =@RowNum + 1 SET @Round =1 END ELSE BEGIN SET @RowNum =1 SET @Round =1 END ENDENDGO
कुछ मिनटों के बाद, देखें कि क्वेरी स्टोर में क्या है:
चुनें [क्यू]। CAST(AVG([rs].[avg_duration])/1000 AS DECIMAL(10,2)) [AvgDuration_ms], CAST(AVG([rs].[avg_cpu_time]) AS DECIMAL(10,2)) [AvgCPU], कास्ट(एवीजी([आरएस]। ]। [query_store_query] [क्यू] [sys] में शामिल हों। [query_store_query_text] [क्यूटी] पर [क्यू]। [query_text_id] =[क्यूटी]। [query_text_id] [sys] में शामिल हों। [ऑब्जेक्ट्स] [ओ] पर [क्यू] [ऑब्जेक्ट_आईडी] =[ओ]। [ऑब्जेक्ट_आईडी] [एसआईएस] में शामिल हों। [क्वेरी_स्टोर_प्लान] [पी] ऑन [क्यू]। [क्वेरी_आईडी] =[पी]। [क्वेरी_आईडी] जॉइन [एसआईएस]। [क्वेरी_स्टोर_रनटाइम_स्टैट्स] [आरएस] [पी] पर। ], [क्यूटी]। [query_sql_text], [आरएस]। [प्लान_आईडी] [ओ] द्वारा आदेश। [नाम];आप देखेंगे कि अधिकांश संग्रहीत कार्यविधियाँ केवल 20 बार निष्पादित हुई हैं क्योंकि [dbo] के विरुद्ध दो कार्यविधियाँ [Customers_Compress] वास्तव में हैं। धीमा। ये आश्चर्यजनक नहीं है; न तो [प्रथम नाम] और न ही [अंतिम नाम] अनुक्रमित है, इसलिए किसी भी प्रश्न को तालिका को स्कैन करना होगा। मैं नहीं चाहता कि वे दो प्रश्न मेरे परीक्षण को धीमा करें, इसलिए मैं कार्यभार को संशोधित करने जा रहा हूं और EXEC [dbo] पर टिप्पणी करूंगा। [usp_FindActiveCustomer_CS] और EXEC [dbo]। [usp_FindAnyCustomer_CS] और फिर इसे फिर से शुरू करें। इस बार, मैं इसे लगभग 10 मिनट तक चलने दूंगा, और जब मैं फिर से क्वेरी स्टोर आउटपुट को देखता हूं, तो अब मेरे पास कुछ अच्छा डेटा है। नीचे प्रबंधक-पसंदीदा ग्राफ़ के साथ कच्चे नंबर नीचे हैं।
क्वेरी स्टोर से प्रदर्शन डेटा
संग्रहीत प्रक्रिया अवधि
संग्रहीत प्रक्रिया CPU
अनुस्मारक:सभी संग्रहीत कार्यविधियाँ जो _C के साथ समाप्त होती हैं, गैर-संपीड़ित तालिका से होती हैं। _R के साथ समाप्त होने वाली प्रक्रियाएं पंक्ति संकुचित तालिका हैं, जो _P के साथ समाप्त होती हैं वे पृष्ठ संकुचित होती हैं, और _CS वाला एक COMPRESS फ़ंक्शन का उपयोग करता है (मैंने usp_FindAnyCustomer_CS और usp_FindActiveCustomer_CS के लिए उक्त तालिका के परिणामों को हटा दिया क्योंकि उन्होंने ग्राफ़ को इतना तिरछा कर दिया कि हमने खो दिया शेष डेटा में अंतर)। Usp_FindAnyCustomer_* और usp_FindActiveCustomer_* प्रक्रियाओं ने गैर-संकुल अनुक्रमणिका का उपयोग किया और प्रत्येक निष्पादन के लिए हज़ारों पंक्तियों को लौटाया।
मुझे उम्मीद थी कि डेटा को डीकंप्रेस करने के ओवरहेड के कारण, गैर-संपीड़ित तालिका की तुलना में, पंक्ति और पृष्ठ संपीड़ित तालिकाओं के विरुद्ध usp_FindAnyCustomer_* और usp_FindActiveCustomer_* प्रक्रियाओं की अवधि अधिक होगी। क्वेरी स्टोर डेटा मेरी अपेक्षा का समर्थन नहीं करता है - उन तीन तालिकाओं में उन दो संग्रहीत प्रक्रियाओं की अवधि लगभग समान (या एक मामले में कम!) है। प्रश्नों के लिए तार्किक IO गैर-संपीड़ित और पृष्ठ और पंक्ति संपीड़ित तालिकाओं में लगभग समान था।
सीपीयू के संदर्भ में, usp_FindActiveCustomer और usp_FindAnyCustomer संग्रहीत कार्यविधियों में यह संपीड़ित तालिकाओं के लिए हमेशा अधिक था। CPU usp_FindSpecificCustomer प्रक्रिया के लिए तुलनीय था, जो कि क्लस्टर इंडेक्स के खिलाफ हमेशा सिंगलटन लुकअप था। [dbo] के विरुद्ध usp_FindSpecificCustomer प्रक्रिया के लिए उच्च CPU (लेकिन अपेक्षाकृत कम अवधि) पर ध्यान दें।[Customer_Compress] तालिका, जिसे पढ़ने योग्य प्रारूप में डेटा प्रदर्शित करने के लिए DECOMPRESS फ़ंक्शन की आवश्यकता होती है।
सारांश
संपीड़ित डेटा को पुनः प्राप्त करने के लिए आवश्यक अतिरिक्त सीपीयू मौजूद है और इसे क्वेरी स्टोर या पारंपरिक बेसलाइनिंग विधियों का उपयोग करके मापा जा सकता है। इस प्रारंभिक परीक्षण के आधार पर, सीपीयू सिंगलटन लुकअप के लिए तुलनीय है, लेकिन अधिक डेटा के साथ बढ़ता है। मैं SQL सर्वर को केवल 10 पृष्ठों से अधिक डीकंप्रेस करने के लिए बाध्य करना चाहता था - मैं कम से कम 100 चाहता था। मैंने इस स्क्रिप्ट की विविधताओं को निष्पादित किया, जहां दसियों हज़ार पंक्तियों को वापस कर दिया गया था, और निष्कर्ष जो आप यहाँ देख रहे थे, उसके अनुरूप थे। मेरी अपेक्षा यह है कि डेटा को डीकंप्रेस करने के समय के कारण अवधि में महत्वपूर्ण अंतर देखने के लिए, प्रश्नों को सैकड़ों हजारों, या लाखों पंक्तियों को वापस करने की आवश्यकता होगी। यदि आप एक OLTP सिस्टम में हैं, तो आप इतनी अधिक पंक्तियों को वापस नहीं करना चाहते हैं, इसलिए यहां परीक्षण से आपको यह पता चल जाएगा कि संपीड़न प्रदर्शन को कैसे प्रभावित कर सकता है। यदि आप डेटा वेयरहाउस में हैं, तो बड़े डेटा सेट लौटाते समय आपको संभवतः उच्च CPU के साथ उच्च अवधि दिखाई देगी। जबकि COMPRESS फ़ंक्शन पृष्ठ और पंक्ति संपीड़न की तुलना में महत्वपूर्ण स्थान बचत प्रदान करता है, CPU के संदर्भ में प्रदर्शन हिट, और उनके डेटा प्रकार के कारण संपीड़ित स्तंभों को अनुक्रमित करने में असमर्थता, इसे केवल बड़ी मात्रा में डेटा के लिए व्यवहार्य बनाता है जो नहीं होगा खोजा।