टिपिंग पॉइंट एक शब्द है जिसे मैंने पहली बार SQL सर्वर प्रदर्शन ट्यूनिंग गुरु और लंबे समय तक SentryOne सलाहकार बोर्ड के सदस्य किम्बर्ली ट्रिप द्वारा उपयोग किया था - उसके पास इस पर एक महान ब्लॉग श्रृंखला है। टिपिंग बिंदु वह सीमा है जिस पर एक क्वेरी योजना एक गैर-कवर गैर-संकुल सूचकांक की तलाश से लेकर संकुल सूचकांक या ढेर को स्कैन करने तक "टिप" करेगी। मूल सूत्र, जो एक कठिन और तेज़ नियम नहीं है क्योंकि कई अन्य प्रभावित करने वाले कारक हैं, यह है:
- एक क्लस्टर इंडेक्स (या टेबल) स्कैन अक्सर तब होता है जब अनुमानित पंक्तियां तालिका में पृष्ठों की संख्या के 33% से अधिक हो जाती हैं
- गैर-संकुल खोज प्लस कुंजी लुकअप अक्सर तब होता है जब अनुमानित पंक्तियां तालिका के पृष्ठों के 25% से कम होती हैं
- 25% से 33% के बीच यह किसी भी तरह से जा सकता है
ध्यान दें कि अन्य अनुकूलक "टिपिंग पॉइंट" भी हैं, जैसे कि जब कोई कवरिंग सूचकांक एक खोज से एक स्कैन की ओर इशारा करेगा, या जब कोई क्वेरी समानांतर होगी, लेकिन जिस पर हम ध्यान केंद्रित कर रहे हैं वह है गैर-कवरिंग गैर-क्लस्टर इंडेक्स परिदृश्य क्योंकि यह सबसे आम होता है - प्रत्येक प्रश्न को कवर करना कठिन होता है! यह प्रदर्शन के लिए संभावित रूप से सबसे खतरनाक भी है, और जब आप किसी को SQL सर्वर इंडेक्स टिपिंग पॉइंट का संदर्भ देते हुए सुनते हैं, तो आमतौर पर उनका यही मतलब होता है।
पूर्व प्लान एक्सप्लोरर संस्करणों में टिपिंग प्वाइंट
जब पैरामीटर सूँघना इंडेक्स विश्लेषण पर चल रहा हो, तब प्लान एक्सप्लोरर ने पहले टिपिंग पॉइंट का शुद्ध प्रभाव दिखाया था टैब, विशेष रूप से अनुमानित (इमेटेड) संचालन . के माध्यम से पैरामीटर . में पंक्ति फलक:
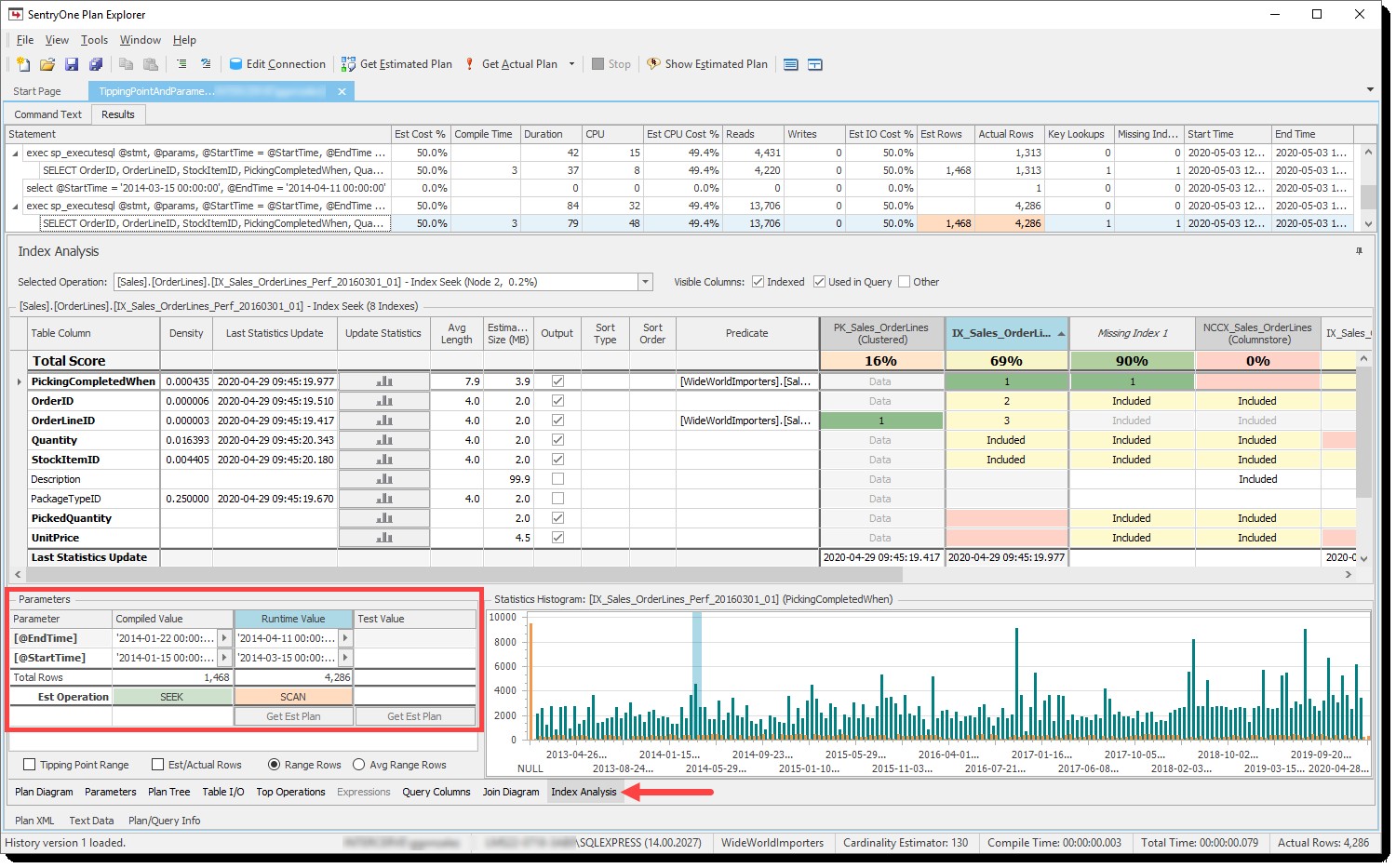 पंक्तियों की संख्या के आधार पर संकलित और रनटाइम मापदंडों के लिए अनुमानित संचालन
पंक्तियों की संख्या के आधार पर संकलित और रनटाइम मापदंडों के लिए अनुमानित संचालन
यदि आपने अभी तक इंडेक्स एनालिसिस मॉड्यूल की खोज नहीं की है तो मैं आपको ऐसा करने के लिए प्रोत्साहित करता हूं। हालांकि योजना आरेख और अन्य प्लान एक्सप्लोरर विशेषताएं महान हैं, स्पष्ट रूप से, इंडेक्स विश्लेषण वह जगह है जहां आपको अपना अधिकांश समय प्रश्नों और इंडेक्स को ट्यून करते समय व्यतीत करना चाहिए। यहां सुविधाओं और परिदृश्यों की आरोन बर्ट्रेंड की गहन समीक्षा और डेवोन लीन विल्सन द्वारा एक महान कवरिंग इंडेक्स ट्यूटोरियल देखें।
दृश्यों के पीछे, हम टिपिंग पॉइंट गणित करते हैं और संकलित और रनटाइम पैरामीटर दोनों के लिए तालिका में अनुमानित पंक्तियों और पृष्ठों की संख्या के आधार पर इंडेक्स ऑपरेशन (तलाश या स्कैन) की भविष्यवाणी करते हैं, और फिर संबंधित कोशिकाओं को रंग-कोड करते हैं ताकि आप जल्दी से देख सकते हैं कि क्या वे मेल खाते हैं। यदि वे नहीं करते हैं, जैसा कि ऊपर दिए गए उदाहरण में है, यह एक मजबूत संकेतक हो सकता है कि आपको पैरामीटर सूँघने की समस्या है।
सांख्यिकी हिस्टोग्राम चार्ट समान पंक्तियों (नारंगी) और श्रेणी पंक्तियों (चैती) के लिए स्तंभों का उपयोग करके सूचकांक की प्रमुख कुंजी के लिए मानों के वितरण को दर्शाता है। ये वही मान हैं जो आपको DBCC SHOW_STATISTICS . से मिलेंगे या sys.dm_db_stats_histogram . वितरण के कुछ हिस्सों को संकलित और रनटाइम दोनों मापदंडों द्वारा प्रभावित किया जा रहा है, आपको यह अनुमान लगाने के लिए हाइलाइट किया गया है कि प्रत्येक के लिए कितनी पंक्तियाँ शामिल हैं। बस या तो संकलित मान . चुनें या रनटाइम मान चयनित श्रेणी देखने के लिए कॉलम:
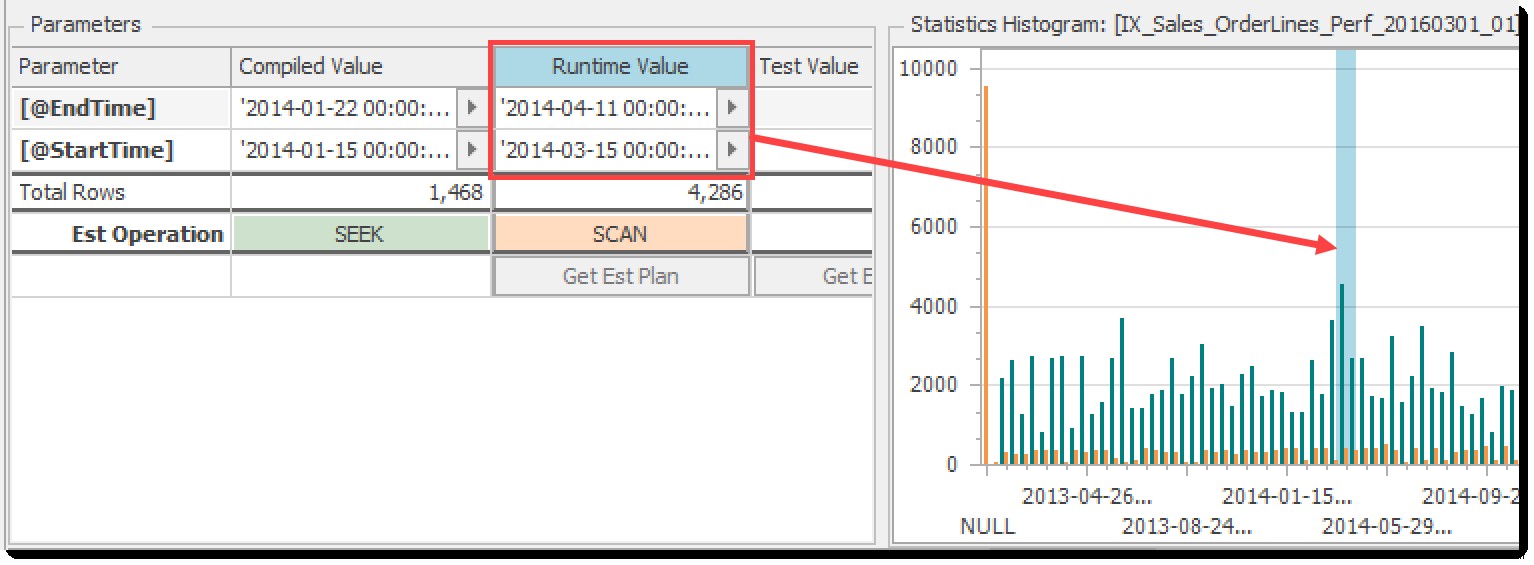 हिस्टोग्राम चार्ट रनटाइम पैरामीटर्स द्वारा प्रभावित रेंज को दर्शाता है
हिस्टोग्राम चार्ट रनटाइम पैरामीटर्स द्वारा प्रभावित रेंज को दर्शाता है
नए नियंत्रण और दृश्य
उपरोक्त विशेषताएं अच्छी थीं, लेकिन कुछ समय के लिए मुझे लगा कि चीजों को स्पष्ट करने के लिए हम और भी बहुत कुछ कर सकते हैं। इसलिए, प्लान एक्सप्लोरर (2020.8.7) की नवीनतम रिलीज़ में, पैरामीटर्स फलक के निचले भाग में हिस्टोग्राम चार्ट पर संबद्ध दृश्यों के साथ कुछ नए नियंत्रण हैं:
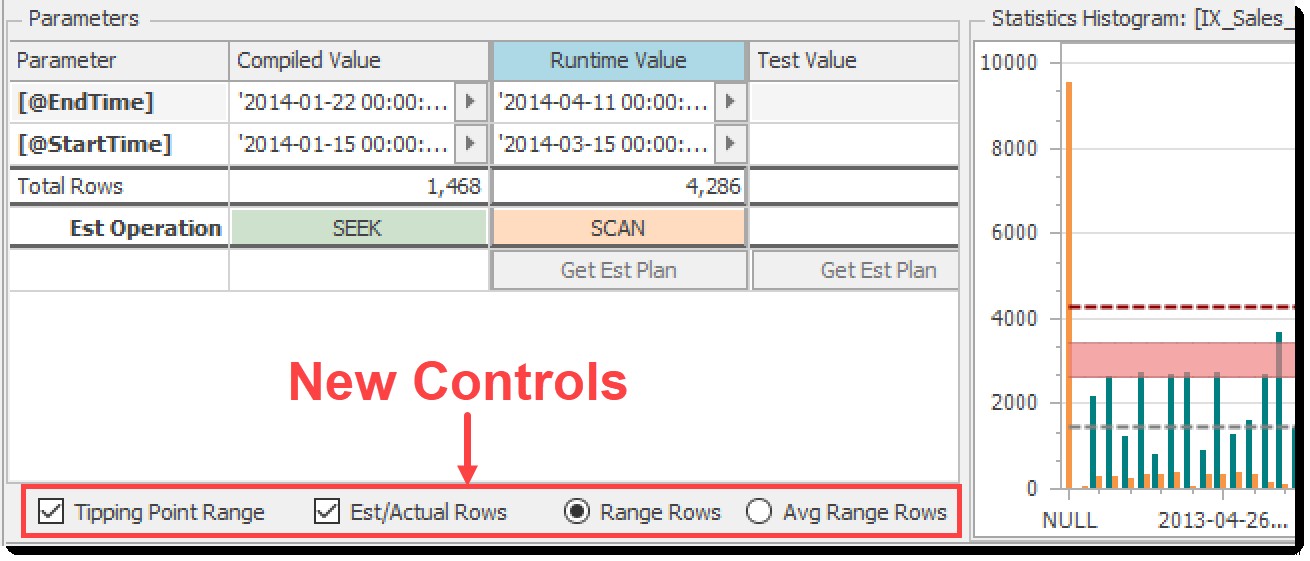 हिस्टोग्राम विज़ुअल के लिए नए नियंत्रण
हिस्टोग्राम विज़ुअल के लिए नए नियंत्रण
ध्यान दें कि डिफ़ॉल्ट रूप से दिखाया गया हिस्टोग्राम चयनित तालिका तक पहुंचने के लिए क्वेरी द्वारा उपयोग किए गए इंडेक्स के लिए है, लेकिन आप अन्य हिस्टोग्राम देखने के लिए ग्रिड में किसी अन्य इंडेक्स हेडर या टेबल कॉलम पर क्लिक कर सकते हैं।
टिपिंग पॉइंट रेंज
टिपिंग पॉइंट रेंज चेकबॉक्स हिस्टोग्राम चार्ट पर दिखाए गए हल्के लाल बैंड को टॉगल करता है:
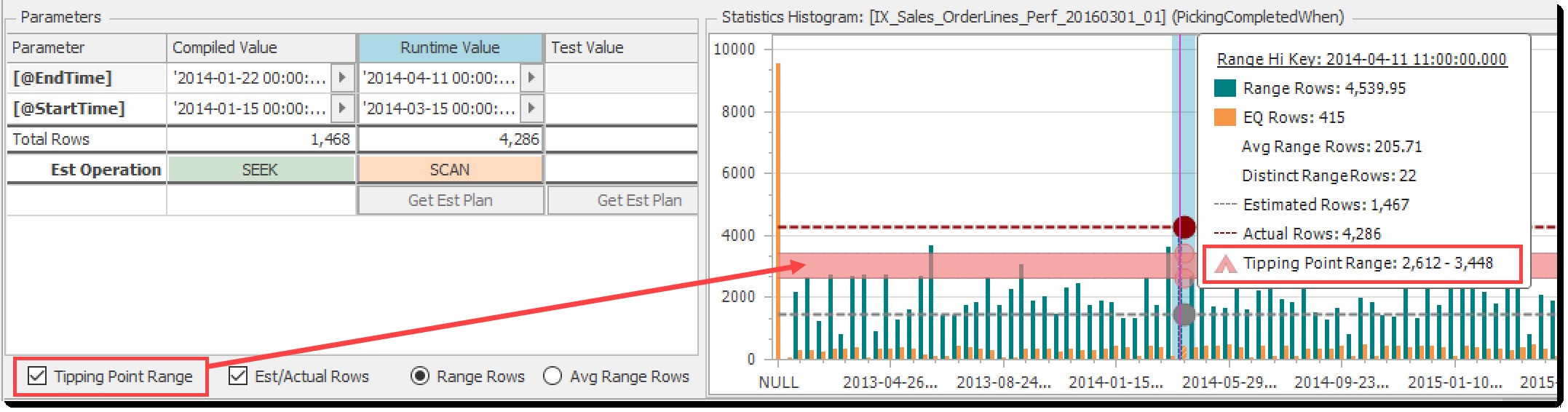 टिपिंग प्वाइंट रेंज बैंड के लिए टॉगल करें
टिपिंग प्वाइंट रेंज बैंड के लिए टॉगल करें
यदि अनुमानित पंक्तियाँ इस सीमा से नीचे हैं, तो ऑप्टिमाइज़र एक खोज + लुकअप और इसके ऊपर एक टेबल स्कैन का पक्ष लेगा। सीमा के अंदर किसी का अनुमान है।
अनुमानित (इमेटेड)/वास्तविक पंक्तियां
अनुमानित/वास्तविक पंक्तियां चेकबॉक्स टॉगल अनुमानित पंक्तियों (संकलित मापदंडों से) और वास्तविक पंक्तियों (रनटाइम मापदंडों से) का प्रदर्शन करता है। नीचे दिए गए चार्ट में तीर इस नियंत्रण और संबंधित तत्वों के बीच संबंध को दर्शाते हैं:
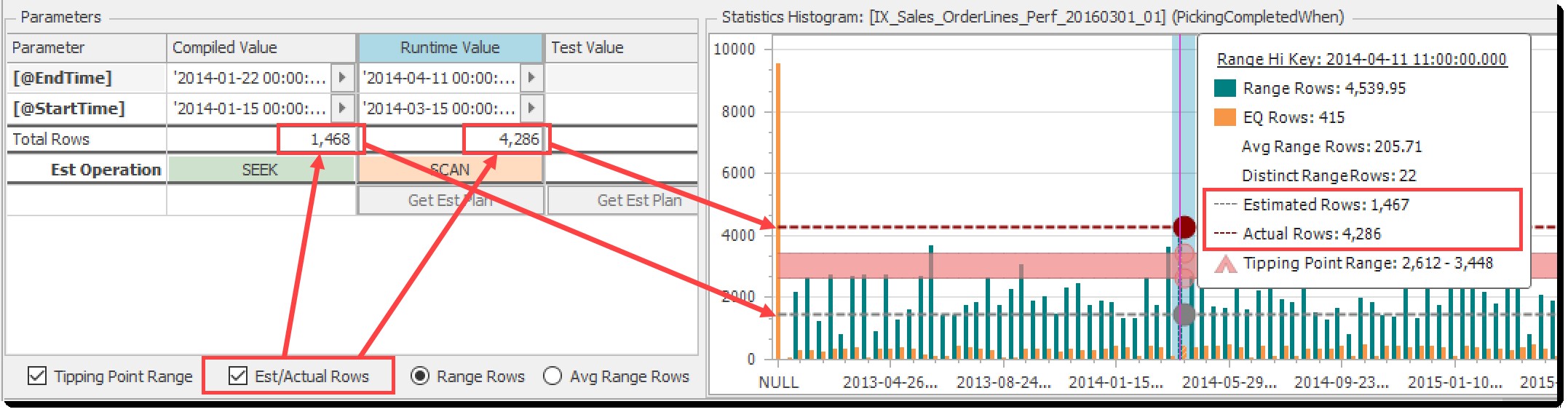 हिस्टोग्राम चार्ट पर अनुमानित और वास्तविक पंक्तियों के लिए टॉगल करें
हिस्टोग्राम चार्ट पर अनुमानित और वास्तविक पंक्तियों के लिए टॉगल करें
इस उदाहरण में, यह स्पष्ट है कि अनुमानित पंक्तियाँ टिपिंग बिंदु से नीचे हैं और वास्तविक पंक्तियाँ इसके ऊपर हैं, जो सूचीबद्ध अनुमानित और वास्तविक संचालन (सीक बनाम स्कैन) के बीच अंतर में परिलक्षित होता है। यह सूँघने का क्लासिक पैरामीटर है, सचित्र!
भविष्य की पोस्ट में मैं इस बात पर ध्यान दूंगा कि यह योजना आरेख और स्टेटमेंट ग्रिड पर आप जो देखते हैं उससे कैसे संबंधित है। इस बीच, यहां एक प्लान एक्सप्लोरर सत्र फ़ाइल है जिसमें यह उदाहरण (सीक-टू-स्कैन पैरामीटर सूँघने) के साथ-साथ स्कैन-टू-सीक उदाहरण भी है। दोनों विस्तारित WideWorldImporters डेटाबेस का लाभ उठाते हैं।
श्रेणी पंक्तियाँ या औसत श्रेणी पंक्तियाँ
प्लान एक्सप्लोरर के पिछले संस्करणों ने हिस्टोग्राम बकेट में पंक्तियों की कुल संख्या का प्रतिनिधित्व करने के लिए समान पंक्तियों और श्रेणी पंक्तियों को एक कॉलम में स्टैक किया था। यह तब अच्छी तरह से काम करता है जब आपके पास ऊपर दिखाए गए अनुसार असमानता या सीमा विधेय होती है, लेकिन समानता के लिए यह बहुत मायने नहीं रखता है। आप वास्तव में औसत श्रेणी पंक्तियों को देखना चाहते हैं क्योंकि ऑप्टिमाइज़र अनुमान के लिए इसका उपयोग करेगा। दुर्भाग्य से, इसे पाने का कोई तरीका नहीं था।
नए प्लान एक्सप्लोरर हिस्टोग्राम में, स्टैक्ड कॉलम श्रृंखला के बजाय अब हम समान पंक्तियों और श्रेणी पंक्तियों के साथ-साथ क्लस्टर कॉलम का उपयोग करते हैं, और आप श्रेणी पंक्तियों / औसत श्रेणी पंक्तियों का उपयोग करके नियंत्रित करें कि कुल या औसत श्रेणी पंक्तियों को उपयुक्त के रूप में दिखाया जाए या नहीं चयनकर्ता। इस पर और जल्द ही…
रैपिंग अप
मैं इन नई सुविधाओं के बारे में वास्तव में उत्साहित हूं, और मुझे आशा है कि आप उन्हें उपयोगी पाएंगे। नया प्लान एक्सप्लोरर डाउनलोड करके उन्हें आज़माएं। यह केवल एक संक्षिप्त परिचय था, और मैं यहां कुछ अलग परिदृश्यों को शामिल करने के लिए उत्सुक हूं। हमेशा की तरह, हमें बताएं कि आप क्या सोचते हैं!