हाल ही के एक टिप में, मैंने एक ऐसे परिदृश्य का वर्णन किया है जहां एक SQL सर्वर 2016 उदाहरण चेकपॉइंट समय के साथ संघर्ष कर रहा था। त्रुटि लॉग इस तरह की फ्लश कैश प्रविष्टियों की एक खतरनाक संख्या के साथ पॉप्युलेट किया गया था:
FlushCache: cleaned up 394031 bufs with 282252 writes in 65544 ms (avoided 21 new dirty bufs) for db 19:0
average writes per second: 4306.30 writes/sec
average throughput: 46.96 MB/sec, I/O saturation: 53644, context switches 101117
last target outstanding: 639360, avgWriteLatency 1 मैं इस मुद्दे से थोड़ा हैरान था, क्योंकि सिस्टम निश्चित रूप से कोई स्लच नहीं था - बहुत सारे कोर, 3TB मेमोरी और XtremIO स्टोरेज। और इनमें से कोई भी FlushCache संदेश कभी भी त्रुटि लॉग में 15 सेकंड I/O चेतावनियों के साथ जोड़ा नहीं गया था। फिर भी, यदि आप वहां पर उच्च-लेनदेन डेटाबेस का एक गुच्छा ढेर करते हैं, तो चेकपॉइंट प्रसंस्करण बहुत सुस्त हो सकता है। प्रत्यक्ष I/O के कारण इतना अधिक नहीं है, लेकिन अधिक सामंजस्य है जो भारी संख्या में गंदे पृष्ठों के साथ किया जाना है (न कि केवल प्रतिबद्ध से) लेन-देन) इतनी बड़ी मात्रा में स्मृति में बिखरा हुआ है, और संभावित रूप से आलसी लेखक की प्रतीक्षा कर रहा है (क्योंकि पूरे उदाहरण के लिए केवल एक ही है)।
मैंने कुछ बहुत ही मूल्यवान पोस्टों को शीघ्रता से "फ़्रेशेन-अप" किया:
- चौकियां कैसे काम करती हैं और क्या लॉग हो जाती हैं
- डेटाबेस चेकपॉइंट्स (एसक्यूएल सर्वर)
- tempdb के लिए चेकपॉइंट क्या करता है?
- एक SQL सर्वर DBA मिथक एक दिन:(15/30) चेकपॉइंट केवल प्रतिबद्ध लेनदेन से पृष्ठ लिखता है
- फ्लश कैश संदेश वास्तविक आईओ स्टॉल नहीं हो सकते हैं
- अप्रत्यक्ष चेकपॉइंट और tempdb - अच्छा, बुरा और गैर-उपज अनुसूचक
- डेटाबेस का लक्ष्य पुनर्प्राप्ति समय बदलें
- यह कैसे काम करता है:FlushCache संदेश SQL सर्वर त्रुटि लॉग में कब जोड़ा जाता है?
- SQL सर्वर 2016 चेकपॉइंट व्यवहार में परिवर्तन
- लक्ष्य पुनर्प्राप्ति अंतराल और अप्रत्यक्ष चेकपॉइंट - SQL सर्वर 2016 में 60 सेकंड का नया डिफ़ॉल्ट
- एसक्यूएल 2016 - यह बस तेजी से चलता है:अप्रत्यक्ष चेकपॉइंट डिफ़ॉल्ट
- एसक्यूएल सर्वर:बड़ी रैम और डीबी चेकपॉइंटिंग
मैंने जल्दी से फैसला किया कि मैं इनमें से कुछ अधिक परेशानी वाले डेटाबेस के लिए चेकपॉइंट अवधि को ट्रैक करना चाहता हूं, उनके लक्ष्य पुनर्प्राप्ति अंतराल को 0 (पुराने तरीके) से 60 सेकंड (नया तरीका) में बदलने से पहले और बाद में। जनवरी में वापस, मैंने मित्र और साथी कनाडाई हन्ना वर्नोन से एक विस्तारित ईवेंट सत्र उधार लिया:
CREATE EVENT SESSION CheckpointTracking ON SERVER
ADD EVENT sqlserver.checkpoint_begin
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
, ADD EVENT sqlserver.checkpoint_end
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
ADD TARGET package0.event_file
(
SET filename = N'L:\SQL\CP\CheckPointTracking.xel',
max_file_size = 50, -- MB
max_rollover_files = 50
)
WITH
(
MAX_MEMORY = 4096 KB,
MAX_DISPATCH_LATENCY = 30 SECONDS,
TRACK_CAUSALITY = ON,
STARTUP_STATE = ON
);
GO
ALTER EVENT SESSION CheckpointTracking ON SERVER
STATE = START; मैंने उस समय को चिह्नित किया जब मैंने प्रत्येक डेटाबेस को बदल दिया, और फिर मूल टिप में प्रकाशित एक क्वेरी का उपयोग करके विस्तारित ईवेंट डेटा से परिणामों का विश्लेषण किया। परिणामों से पता चला कि अप्रत्यक्ष चौकियों में बदलने के बाद, प्रत्येक डेटाबेस 30 सेकंड के औसत चौकियों से एक सेकंड के दसवें हिस्से से कम (और ज्यादातर मामलों में बहुत कम चौकियों, भी) चौकियों से चला गया। इस ग्राफिक से अनपैक करने के लिए बहुत कुछ है, लेकिन यह कच्चा डेटा है जिसका उपयोग मैंने अपना तर्क प्रस्तुत करने के लिए किया था (विस्तार करने के लिए क्लिक करें):
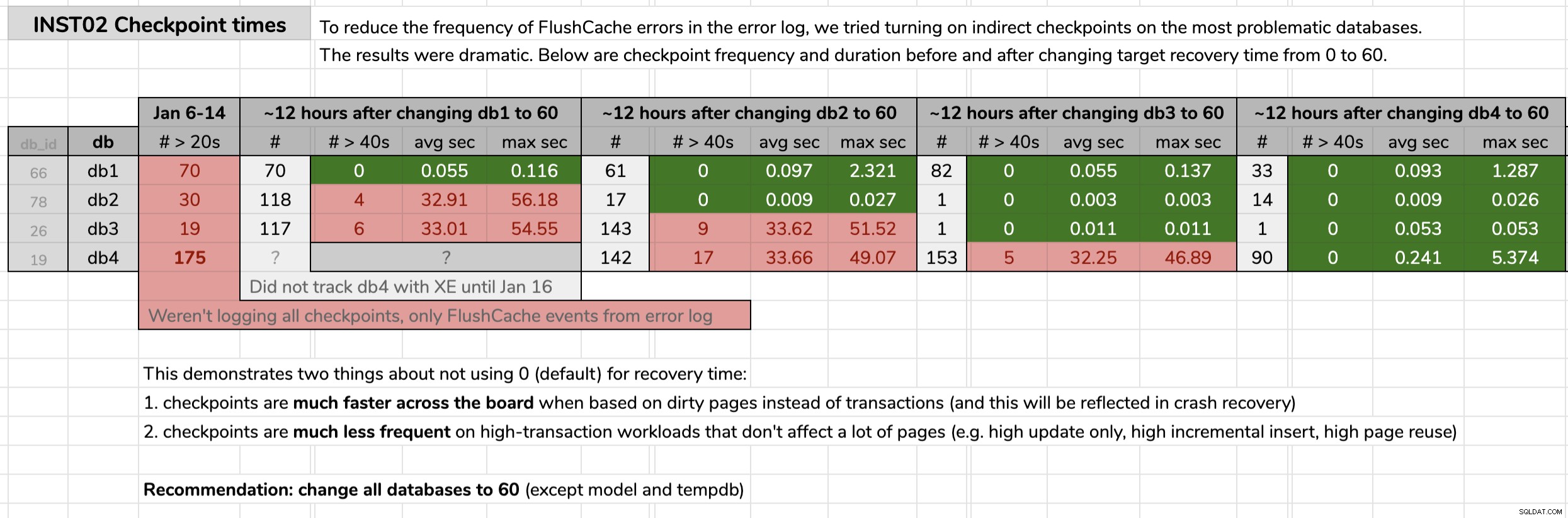 मेरे साक्ष्य
मेरे साक्ष्य
एक बार जब मैंने इन समस्याग्रस्त डेटाबेस में अपना मामला साबित कर दिया, तो मुझे हमारे पूरे पर्यावरण में हमारे सभी उपयोगकर्ता डेटाबेस में इसे लागू करने के लिए हरी बत्ती मिली। पहले देव में, और फिर उत्पादन में, मैंने एक सीएमएस क्वेरी के माध्यम से निम्नलिखित को चलाया ताकि यह पता लगाया जा सके कि हम कितने डेटाबेस के बारे में बात कर रहे थे:
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += CASE
WHEN (ag.role = N'PRIMARY' AND ag.ag_status = N'READ_WRITE') OR ag.role IS NULL THEN N'
ALTER DATABASE ' + QUOTENAME(d.name) + N' SET TARGET_RECOVERY_TIME = 60 SECONDS;'
ELSE N'
PRINT N''-- fix ' + QUOTENAME(d.name) + N' on Primary.'';'
END
FROM sys.databases AS d
OUTER APPLY
(
SELECT role = s.role_desc,
ag_status = DATABASEPROPERTYEX(c.database_name, N'Updateability')
FROM sys.dm_hadr_availability_replica_states AS s
INNER JOIN sys.availability_databases_cluster AS c
ON s.group_id = c.group_id
AND d.name = c.database_name
WHERE s.is_local = 1
) AS ag
WHERE d.target_recovery_time_in_seconds <> 60
AND d.database_id > 4
AND d.[state] = 0
AND d.is_in_standby = 0
AND d.is_read_only = 0;
SELECT DatabaseCount = @@ROWCOUNT, Version = @@VERSION, cmd = @sql;
--EXEC sys.sp_executesql @sql; क्वेरी के बारे में कुछ नोट्स:
database_id > 4
मैंmasterको स्पर्श नहीं करना चाहता था बिल्कुल भी, और मैंtempdbको बदलना नहीं चाहता था अभी तक क्योंकि हम नवीनतम SQL सर्वर 2017 CU पर नहीं हैं (एक कारण के लिए KB #4497928 देखें कि विवरण महत्वपूर्ण है)। बाद वालाmodel. को बाहर कर देता है , भी, क्योंकि बदलते मॉडल सेtempdb. प्रभावित होगा अगली विफलता/पुनरारंभ पर। मैं बदल सकता थाmsdb, और मैं किसी समय ऐसा करने के लिए वापस जा सकता हूं, लेकिन यहां मेरा ध्यान उपयोगकर्ता डेटाबेस पर था।
[state] / is_read_only / is_in_standby
हमें यह सुनिश्चित करने की आवश्यकता है कि हम जिन डेटाबेस को बदलने का प्रयास कर रहे हैं वे ऑनलाइन हैं और केवल पढ़ने के लिए नहीं हैं (मैंने एक को मारा जो वर्तमान में केवल पढ़ने के लिए सेट किया गया था, और उस पर बाद में वापस आना होगा)।
OUTER APPLY (...)
हम अपने कार्यों को उन डेटाबेस तक सीमित रखना चाहते हैं जो या तो एजी में प्राथमिक हैं या एजी में बिल्कुल नहीं हैं (और वितरित एजी के लिए भी खाते हैं, जहां हम प्राथमिक और स्थानीय हो सकते हैं लेकिन फिर भी लिखने योग्य नहीं हैं) . यदि आप किसी सेकेंडरी पर चेक चलाते हैं, तो आप वहां समस्या को ठीक नहीं कर सकते हैं, लेकिन फिर भी आपको इसके बारे में एक चेतावनी मिलनी चाहिए। इस तर्क में मदद करने के लिए एरिक डार्लिंग और सुधारों को प्रेरित करने के लिए टेलर मार्टेल को धन्यवाद।
- यदि आपके पास SQL Server 2008 R2 जैसे पुराने संस्करण चल रहे हैं (मुझे एक मिल गया!), तो आपको इसे थोड़ा बदलना होगा, क्योंकि
target_recovery_time_in_secondsकॉलम वहां मौजूद नहीं है। मुझे एक मामले में इसे प्राप्त करने के लिए गतिशील एसक्यूएल का उपयोग करना पड़ा, लेकिन आप अस्थायी रूप से स्थानांतरित या हटा सकते हैं जहां वे उदाहरण आपके सीएमएस पदानुक्रम में आते हैं। आप भी मेरी तरह आलसी नहीं हो सकते हैं, और सीएमएस क्वेरी विंडो के बजाय पावरहेल में कोड चला सकते हैं, जहां आप संकलन-समय के मुद्दों को मारने से पहले किसी भी संख्या में गुणों को दिए गए डेटाबेस को आसानी से फ़िल्टर कर सकते हैं।
उत्पादन में, पुरानी सेटिंग का उपयोग करते हुए 102 उदाहरण (लगभग आधे) और कुल 1,590 डेटाबेस थे। सब कुछ SQL सर्वर 2017 पर था, तो यह सेटिंग इतनी प्रचलित क्यों थी? क्योंकि वे SQL सर्वर 2016 में अप्रत्यक्ष चौकियों के डिफ़ॉल्ट बनने से पहले बनाए गए थे। यहाँ परिणामों का एक नमूना है:
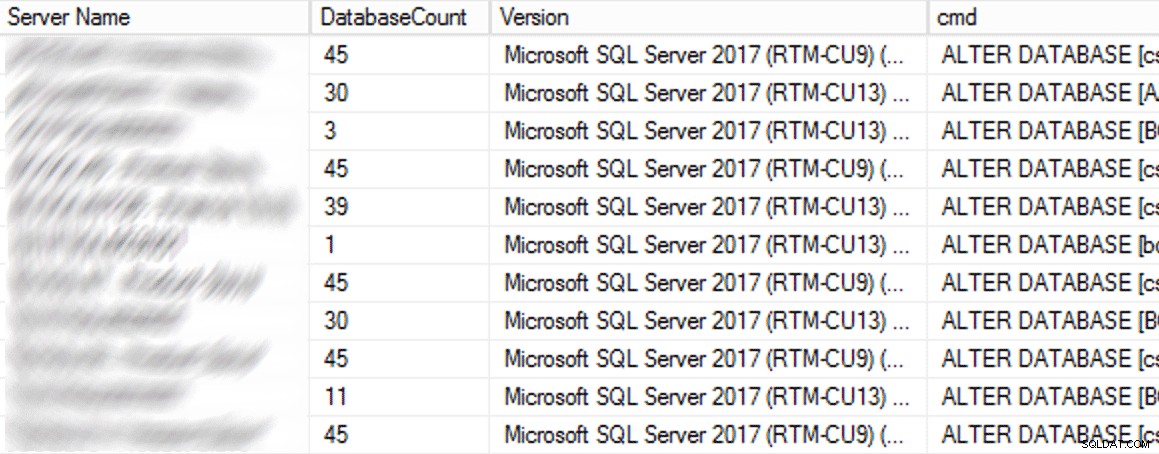 CMS क्वेरी से आंशिक परिणाम।
CMS क्वेरी से आंशिक परिणाम।
फिर मैंने सीएमएस क्वेरी को फिर से चलाया, इस बार sys.sp_executesql . के साथ टिप्पणी नहीं की गई सभी 1,590 डेटाबेस में इसे चलाने में लगभग 12 मिनट का समय लगा। घंटे के भीतर, मुझे पहले से ही कुछ व्यस्त मामलों में सीपीयू में महत्वपूर्ण गिरावट देखने वाले लोगों की रिपोर्ट मिल रही थी।
मुझे अभी और करना है। उदाहरण के लिए, मुझे tempdb . पर संभावित प्रभाव का परीक्षण करने की आवश्यकता है , और क्या मेरे द्वारा सुनी गई डरावनी कहानियों के लिए हमारे उपयोग के मामले में कोई भार है। और हमें यह सुनिश्चित करने की आवश्यकता है कि 60 सेकंड की सेटिंग हमारे स्वचालन और सभी डेटाबेस निर्माण अनुरोधों का हिस्सा है, विशेष रूप से वे जो स्क्रिप्टेड हैं या बैकअप से पुनर्स्थापित किए गए हैं।