पृष्ठभूमि
जब मैं किसी प्रदर्शन समस्या का निवारण कर रहा होता हूं, तो सबसे पहले मैं देखता हूं कि sys.dm_os_wait_stats DMV के माध्यम से प्रतीक्षा आँकड़े हैं। यह देखने के लिए कि SQL सर्वर किस पर प्रतीक्षा कर रहा है, मैं ग्लेन बेरी के SQL सर्वर डायग्नोस्टिक क्वेरी के वर्तमान सेट से क्वेरी का उपयोग करता हूं। आउटपुट के आधार पर, मैं SQL सर्वर के भीतर विशिष्ट क्षेत्रों में खुदाई शुरू करता हूं।
एक उदाहरण के रूप में, यदि मुझे उच्च CXPACKET प्रतीक्षा दिखाई देती है, तो मैं सर्वर पर कोर की संख्या, NUMA नोड्स की संख्या, और समांतरता की अधिकतम डिग्री और समांतरता के लिए लागत सीमा के मानों की जांच करता हूं। यह पृष्ठभूमि की जानकारी है जिसका उपयोग मैं कॉन्फ़िगरेशन को समझने के लिए करता हूं। इससे पहले कि मैं कोई बदलाव करने पर विचार करूं, मैं और इकट्ठा करता हूं मात्रात्मक डेटा, CXPACKET प्रतीक्षा के साथ एक प्रणाली के रूप में जरूरी नहीं कि समानांतरता की अधिकतम डिग्री के लिए गलत सेटिंग हो।
इसी तरह, एक सिस्टम जिसमें I/O-संबंधित प्रतीक्षा प्रकारों जैसे PAGEIOLATCH_XX, WRITELOG, और IO_COMPLETION के लिए उच्च प्रतीक्षा है, में आवश्यक रूप से एक निम्न स्टोरेज सबसिस्टम नहीं है। जब मैं I/O-संबंधित प्रतीक्षा प्रकारों को शीर्ष प्रतीक्षा के रूप में देखता हूं, तो मैं तुरंत अंतर्निहित संग्रहण के बारे में अधिक समझना चाहता हूं। क्या यह डायरेक्ट-अटैच्ड स्टोरेज या सैन है? RAID स्तर क्या है, सरणी में कितने डिस्क मौजूद हैं, और डिस्क की गति क्या है? मैं यह भी जानना चाहता हूं कि क्या अन्य फाइलें या डेटाबेस भंडारण साझा करते हैं। और जबकि कॉन्फ़िगरेशन को समझना महत्वपूर्ण है, एक तार्किक अगला चरण sys.dm_io_virtual_file_stats DMV के माध्यम से वर्चुअल फ़ाइल आँकड़ों को देखना है।
SQL सर्वर 2005 में पेश किया गया, यह DMV fn_virtualfilestats फ़ंक्शन के लिए एक प्रतिस्थापन है जिसे आप में से जो SQL Server 2000 पर चलते हैं और पहले शायद जानते हैं और पसंद करते हैं। DMV में प्रत्येक डेटाबेस फ़ाइल के लिए संचयी I/O जानकारी होती है, लेकिन जब डेटाबेस बंद होता है, ऑफ़लाइन लिया जाता है, अलग किया जाता है और फिर से जोड़ा जाता है, तो डेटा पुनरारंभ होने पर डेटा रीसेट हो जाता है। यह समझना महत्वपूर्ण है कि वर्चुअल फ़ाइल आँकड़े डेटा वर्तमान का प्रतिनिधि नहीं है प्रदर्शन - यह एक स्नैपशॉट है जो उपरोक्त घटनाओं में से एक द्वारा अंतिम समाशोधन के बाद से I/O डेटा का एकत्रीकरण है। भले ही डेटा पॉइंट-इन-टाइम न हो, फिर भी यह उपयोगी हो सकता है। यदि किसी उदाहरण के लिए उच्चतम प्रतीक्षा I/O-संबंधित हैं, लेकिन औसत प्रतीक्षा समय 10 ms से कम है, तो भंडारण शायद कोई समस्या नहीं है - लेकिन sys.dm_io_virtual_stats में जो आप देखते हैं उसके साथ आउटपुट को सहसंबंधित करना अभी भी निम्न की पुष्टि करने के लिए उपयुक्त है विलंबता इसके अलावा, भले ही आपको sys.dm_io_virtual_stats में उच्च विलंबता दिखाई दे, फिर भी आपने यह साबित नहीं किया है कि संग्रहण एक समस्या है।
सेटअप
वर्चुअल फ़ाइल आँकड़ों को देखने के लिए, मैंने AdventureWorks2012 डेटाबेस की दो प्रतियाँ सेट की हैं, जिन्हें आप Codeplex से डाउनलोड कर सकते हैं। पहली प्रति के लिए, जिसे इसके बाद EX_AdventureWorks2012 के रूप में जाना जाता है, मैंने Sales.SalesOrderHeader और Sales.SalesOrderDetail तालिका को क्रमशः 1.2 मिलियन और 4.9 मिलियन पंक्तियों में विस्तारित करने के लिए जोनाथन केहैयस की स्क्रिप्ट चलाई। दूसरे डेटाबेस के लिए, BIG_AdventureWorks2012, मैंने 123 मिलियन पंक्तियों के साथ Sales.SalesOrderHeader तालिका की एक प्रति बनाने के लिए अपनी पिछली विभाजन पोस्ट की स्क्रिप्ट का उपयोग किया। दोनों डेटाबेस एक बाहरी USB ड्राइव (सीगेट स्लिम 500GB) पर संग्रहीत किए गए थे, मेरी स्थानीय डिस्क (SSD) पर tempdb के साथ।
परीक्षण से पहले, मैंने प्रत्येक डेटाबेस (Create_Custom_SPs.zip) में चार कस्टम संग्रहीत कार्यविधियाँ बनाईं, जो मेरे "सामान्य" कार्यभार के रूप में काम करेंगी। प्रत्येक डेटाबेस के लिए मेरी परीक्षण प्रक्रिया इस प्रकार थी:
- इंस्टेंस को पुनरारंभ करें।
- वर्चुअल फ़ाइल आँकड़े कैप्चर करें।
- दो मिनट के लिए "सामान्य" कार्यभार चलाएं (प्रक्रियाओं को एक PowerShell स्क्रिप्ट के माध्यम से बार-बार कहा जाता है)।
- वर्चुअल फ़ाइल आँकड़े कैप्चर करें।
- उपयुक्त SalesOrder तालिका(तालिकाओं) के लिए सभी अनुक्रमणिकाओं का पुनर्निर्माण करें।
- वर्चुअल फ़ाइल आँकड़े कैप्चर करें।
डेटा
वर्चुअल फ़ाइल आँकड़ों को कैप्चर करने के लिए, मैंने ऐतिहासिक जानकारी रखने के लिए एक तालिका बनाई, और फिर स्नैपशॉट के लिए उनकी DMV ऑल-स्टार्स स्क्रिप्ट से जिमी मे की क्वेरी की विविधता का उपयोग किया:
USE [msdb];
GO
CREATE TABLE [dbo].[SQLskills_FileLatency]
(
[RowID] [INT] IDENTITY(1,1) NOT NULL,
[CaptureID] [INT] NOT NULL,
[CaptureDate] [DATETIME2](7) NULL,
[ReadLatency] [BIGINT] NULL,
[WriteLatency] [BIGINT] NULL,
[Latency] [BIGINT] NULL,
[AvgBPerRead] [BIGINT] NULL,
[AvgBPerWrite] [BIGINT] NULL,
[AvgBPerTransfer] [BIGINT] NULL,
[Drive] [NVARCHAR](2) NULL,
[DB] [NVARCHAR](128) NULL,
[database_id] [SMALLINT] NOT NULL,
[file_id] [SMALLINT] NOT NULL,
[sample_ms] [INT] NOT NULL,
[num_of_reads] [BIGINT] NOT NULL,
[num_of_bytes_read] [BIGINT] NOT NULL,
[io_stall_read_ms] [BIGINT] NOT NULL,
[num_of_writes] [BIGINT] NOT NULL,
[num_of_bytes_written] [BIGINT] NOT NULL,
[io_stall_write_ms] [BIGINT] NOT NULL,
[io_stall] [BIGINT] NOT NULL,
[size_on_disk_MB] [NUMERIC](25, 6) NULL,
[file_handle] [VARBINARY](8) NOT NULL,
[physical_name] [NVARCHAR](260) NOT NULL
) ON [PRIMARY];
GO
CREATE CLUSTERED INDEX CI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureDate], [RowID]);
CREATE NONCLUSTERED INDEX NCI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureID]);
DECLARE @CaptureID INT;
SELECT @CaptureID = MAX(CaptureID) FROM [msdb].[dbo].[SQLskills_FileLatency];
PRINT (@CaptureID);
IF @CaptureID IS NULL
BEGIN
SET @CaptureID = 1;
END
ELSE
BEGIN
SET @CaptureID = @CaptureID + 1;
END
INSERT INTO [msdb].[dbo].[SQLskills_FileLatency]
(
[CaptureID],
[CaptureDate],
[ReadLatency],
[WriteLatency],
[Latency],
[AvgBPerRead],
[AvgBPerWrite],
[AvgBPerTransfer],
[Drive],
[DB],
[database_id],
[file_id],
[sample_ms],
[num_of_reads],
[num_of_bytes_read],
[io_stall_read_ms],
[num_of_writes],
[num_of_bytes_written],
[io_stall_write_ms],
[io_stall],
[size_on_disk_MB],
[file_handle],
[physical_name]
)
SELECT
--virtual file latency
@CaptureID,
GETDATE(),
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([io_stall_read_ms]/[num_of_reads])
END [ReadLatency],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([io_stall_write_ms]/[num_of_writes])
END [WriteLatency],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE ([io_stall]/([num_of_reads] + [num_of_writes]))
END [Latency],
--avg bytes per IOP
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([num_of_bytes_read]/[num_of_reads])
END [AvgBPerRead],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([num_of_bytes_written]/[num_of_writes])
END [AvgBPerWrite],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE (([num_of_bytes_read] + [num_of_bytes_written])/([num_of_reads] + [num_of_writes]))
END [AvgBPerTransfer],
LEFT([mf].[physical_name],2) [Drive],
DB_NAME([vfs].[database_id]) [DB],
[vfs].[database_id],
[vfs].[file_id],
[vfs].[sample_ms],
[vfs].[num_of_reads],
[vfs].[num_of_bytes_read],
[vfs].[io_stall_read_ms],
[vfs].[num_of_writes],
[vfs].[num_of_bytes_written],
[vfs].[io_stall_write_ms],
[vfs].[io_stall],
[vfs].[size_on_disk_bytes]/1024/1024. [size_on_disk_MB],
[vfs].[file_handle],
[mf].[physical_name]
FROM [sys].[dm_io_virtual_file_stats](NULL,NULL) AS vfs
JOIN [sys].[master_files] [mf]
ON [vfs].[database_id] = [mf].[database_id]
AND [vfs].[file_id] = [mf].[file_id]
ORDER BY [Latency] DESC; मैंने इंस्टेंस को पुनरारंभ किया और फिर तुरंत फ़ाइल आंकड़े कैप्चर किए। जब मैंने आउटपुट को केवल EX_AdventureWorks2012 और tempdb डेटाबेस फ़ाइलों को देखने के लिए फ़िल्टर किया, तो केवल tempdb डेटा कैप्चर किया गया था क्योंकि EX_AdventureWorks2012 डेटाबेस से किसी डेटा का अनुरोध नहीं किया गया था:

sys.dm_os_virtual_file_stats के आरंभिक कैप्चर से आउटपुट
फिर मैंने दो मिनट के लिए "सामान्य" कार्यभार चलाया (प्रत्येक संग्रहीत प्रक्रिया के निष्पादन की संख्या थोड़ी भिन्न थी), और इसके बाद फिर से कैप्चर की गई फ़ाइल आँकड़े:

सामान्य कार्यभार के बाद sys.dm_os_virtual_file_stats से आउटपुट
हम EX_AdventureWorks2012 डेटा फ़ाइल के लिए 57ms की विलंबता देखते हैं। आदर्श नहीं है, लेकिन समय के साथ मेरे सामान्य कार्यभार के साथ, यह शायद और भी समाप्त हो जाएगा। Tempdb के लिए न्यूनतम विलंबता है, जिसकी अपेक्षा की जाती है क्योंकि मेरे द्वारा चलाए गए कार्यभार में बहुत अधिक tempdb गतिविधि उत्पन्न नहीं होती है। इसके बाद मैंने Sales.SalesOrderHeaderEnlarged और Sales.SalesOrderDetailEnlarged टेबल के लिए सभी इंडेक्स को फिर से बनाया:
USE [EX_AdventureWorks2012]; GO ALTER INDEX ALL ON Sales.SalesOrderHeaderEnlarged REBUILD; ALTER INDEX ALL ON Sales.SalesOrderDetailEnlarged REBUILD;
पुनर्निर्माण में एक मिनट से भी कम समय लगा, और EX_AdventureWorks2012 डेटा फ़ाइल के लिए रीड लेटेंसी में स्पाइक, और EX_AdventureWorks2012 डेटा और के लिए राइट लेटेंसी में स्पाइक्स को नोटिस किया। लॉग फ़ाइलें:

सूचकांक पुनर्निर्माण के बाद sys.dm_os_virtual_file_stats से आउटपुट
फ़ाइल आँकड़ों के उस स्नैपशॉट के अनुसार, विलंबता भयानक है; लिखने के लिए 600ms से अधिक! अगर मैंने उत्पादन प्रणाली के लिए यह मान देखा तो भंडारण के साथ समस्याओं पर तुरंत संदेह करना आसान होगा। हालाँकि, यह भी ध्यान देने योग्य है कि AvgBPerWrite में भी वृद्धि हुई है, और बड़े ब्लॉक लेखन को पूरा होने में अधिक समय लगता है। अनुक्रमणिका पुनर्निर्माण कार्य के लिए AvgBPerWrite वृद्धि अपेक्षित है।
समझें कि जैसा कि आप इस डेटा को देखते हैं, आपको पूरी तस्वीर नहीं मिल रही है। वर्चुअल फ़ाइल आँकड़ों का उपयोग करके विलंबता को देखने का एक बेहतर तरीका स्नैपशॉट लेना और फिर बीती हुई समयावधि के लिए विलंबता की गणना करना है। उदाहरण के लिए, नीचे दी गई स्क्रिप्ट दो स्नैपशॉट (वर्तमान और पिछला) का उपयोग करती है और फिर उस समय अवधि में पढ़ने और लिखने की संख्या की गणना करती है, io_stall_read_ms और io_stall_write_ms मानों में अंतर, और फिर io_stall_read_ms डेल्टा को पढ़ने की संख्या से विभाजित करती है, और io_stall_write_ms डेल्टा द्वारा लिखने की संख्या। इस पद्धति के साथ, हम गणना करते हैं कि SQL सर्वर I/O पर पढ़ने या लिखने के लिए कितने समय की प्रतीक्षा कर रहा था, और फिर विलंबता निर्धारित करने के लिए इसे पढ़ने या लिखने की संख्या से विभाजित करते हैं।
DECLARE @CurrentID INT, @PreviousID INT; SET @CurrentID = 3; SET @PreviousID = @CurrentID - 1; WITH [p] AS ( SELECT [CaptureDate], [database_id], [file_id], [ReadLatency], [WriteLatency], [num_of_reads], [io_stall_read_ms], [num_of_writes], [io_stall_write_ms] FROM [msdb].[dbo].[SQLskills_FileLatency] WHERE [CaptureID] = @PreviousID ) SELECT [c].[CaptureDate] [CurrentCaptureDate], [p].[CaptureDate] [PreviousCaptureDate], DATEDIFF(MINUTE, [p].[CaptureDate], [c].[CaptureDate]) [MinBetweenCaptures], [c].[DB], [c].[physical_name], [c].[ReadLatency] [CurrentReadLatency], [p].[ReadLatency] [PreviousReadLatency], [c].[WriteLatency] [CurrentWriteLatency], [p].[WriteLatency] [PreviousWriteLatency], [c].[io_stall_read_ms]- [p].[io_stall_read_ms] [delta_io_stall_read], [c].[num_of_reads] - [p].[num_of_reads] [delta_num_of_reads], [c].[io_stall_write_ms] - [p].[io_stall_write_ms] [delta_io_stall_write], [c].[num_of_writes] - [p].[num_of_writes] [delta_num_of_writes], CASE WHEN ([c].[num_of_reads] - [p].[num_of_reads]) = 0 THEN NULL ELSE ([c].[io_stall_read_ms] - [p].[io_stall_read_ms])/([c].[num_of_reads] - [p].[num_of_reads]) END [IntervalReadLatency], CASE WHEN ([c].[num_of_writes] - [p].[num_of_writes]) = 0 THEN NULL ELSE ([c].[io_stall_write_ms] - [p].[io_stall_write_ms])/([c].[num_of_writes] - [p].[num_of_writes]) END [IntervalWriteLatency] FROM [msdb].[dbo].[SQLskills_FileLatency] [c] JOIN [p] ON [c].[database_id] = [p].[database_id] AND [c].[file_id] = [p].[file_id] WHERE [c].[CaptureID] = @CurrentID AND [c].[database_id] IN (2, 11);
जब हम इंडेक्स के पुनर्निर्माण के दौरान विलंबता की गणना करने के लिए इसे निष्पादित करते हैं, तो हमें निम्नलिखित मिलते हैं:

EX_AdventureWorks2012 के लिए अनुक्रमणिका पुनर्निर्माण के दौरान sys.dm_io_virtual_file_stats से परिकलित विलंबता उन्हें>
अब हम देख सकते हैं कि उस समय के दौरान वास्तविक विलंबता अधिक थी - जिसकी हम अपेक्षा करेंगे। और अगर हम फिर अपने सामान्य कार्यभार पर वापस चले गए और इसे कुछ घंटों तक चलाया, तो वर्चुअल फ़ाइल आँकड़ों से गणना की गई औसत मान समय के साथ घट जाएगी। वास्तव में, यदि हम परीक्षण के दौरान कैप्चर किए गए PerfMon डेटा को देखते हैं (और फिर PAL के माध्यम से संसाधित होते हैं), तो हम औसत में महत्वपूर्ण स्पाइक्स देखते हैं। डिस्क सेकंड/पढ़ें और औसत। डिस्क सेकंड/लिखें जो उस समय से संबंधित है जब इंडेक्स पुनर्निर्माण चल रहा था। लेकिन अन्य समय में, विलंबता मान स्वीकार्य मानों से काफी नीचे होते हैं:
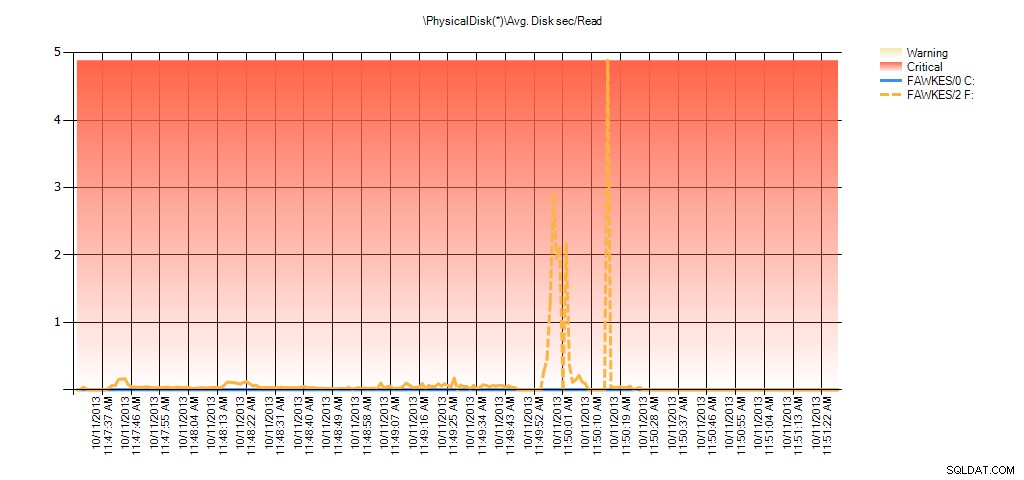
परीक्षण के दौरान EX_AdventureWorks2012 के लिए PAL से औसत डिस्क सेकंड/पढ़ें का सारांश
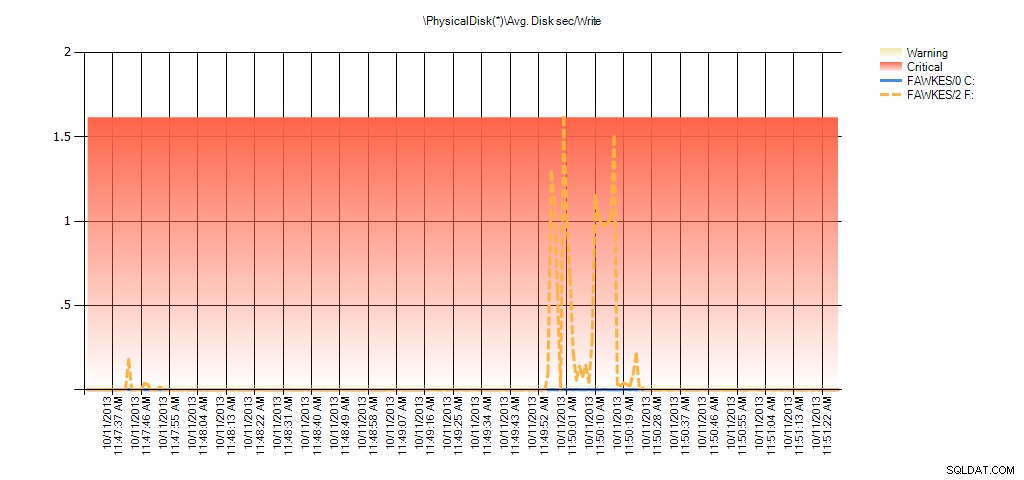
परीक्षण के दौरान EX_AdventureWorks2012 के लिए PAL से औसत डिस्क सेकेंड/लिखने का सारांश
आप BIG_AdventureWorks 2012 डेटाबेस के लिए समान व्यवहार देख सकते हैं। इंडेक्स के पुनर्निर्माण से पहले और बाद में वर्चुअल फ़ाइल आँकड़े स्नैपशॉट पर आधारित विलंबता जानकारी यहाँ दी गई है:

बिग_एडवेंचरवर्क्स2012 के लिए इंडेक्स पुनर्निर्माण के दौरान sys.dm_io_virtual_file_stats से परिकलित लेटेंसी उन्हें>
और प्रदर्शन मॉनिटर डेटा पुनर्निर्माण के दौरान समान स्पाइक दिखाता है:
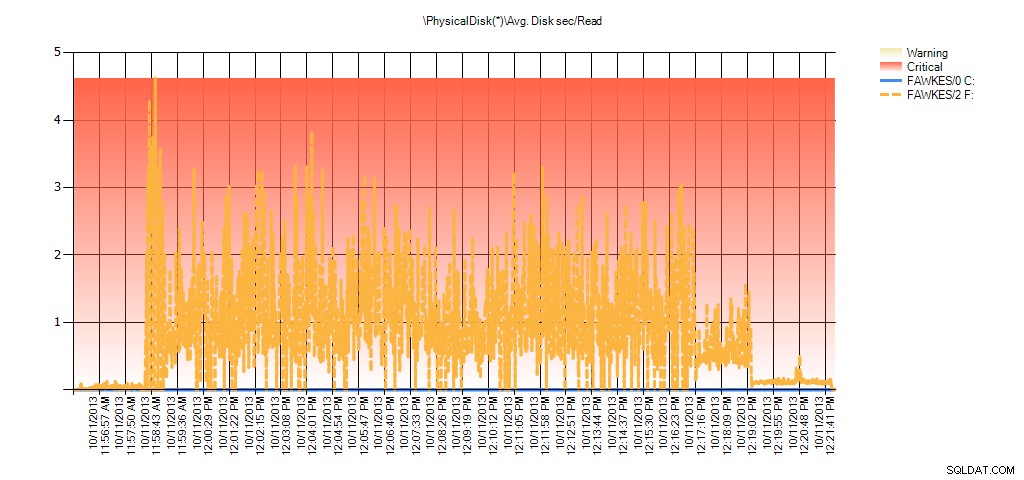
परीक्षण के दौरान BIG_AdventureWorks2012 के लिए PAL से औसत डिस्क सेकंड/पढ़ें का सारांश
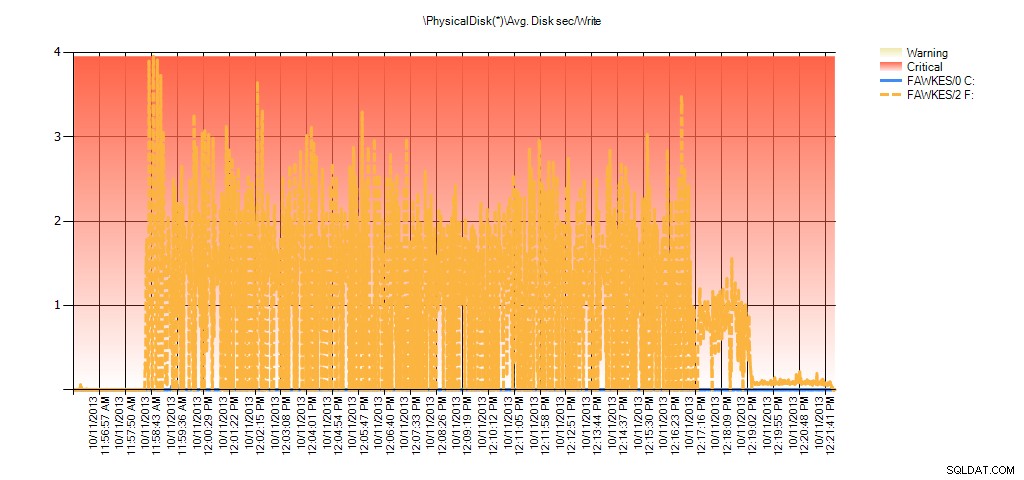
परीक्षण के दौरान BIG_AdventureWorks2012 के लिए PAL से औसत डिस्क सेकंड/लिखने का सारांश
निष्कर्ष
जब आप SQL सर्वर इंस्टेंस के लिए I/O प्रदर्शन को समझना चाहते हैं तो वर्चुअल फ़ाइल आंकड़े एक महान प्रारंभिक बिंदु हैं। यदि आप प्रतीक्षा आँकड़ों को देखते समय I/O-संबंधित प्रतीक्षा देखते हैं, तो sys.dm_io_virtual_file_stats को देखना एक तार्किक अगला चरण है। हालांकि, समझें कि आप जो डेटा देख रहे हैं वह एक कुल है चूंकि आंकड़े पिछली बार संबंधित घटनाओं में से एक द्वारा साफ़ किए गए थे (उदाहरण पुनरारंभ, डेटाबेस का ऑफ़लाइन, आदि)। यदि आप कम विलंबता देखते हैं, तो I/O सबसिस्टम प्रदर्शन भार के साथ बना रहता है। हालाँकि, यदि आप उच्च विलंबता देखते हैं, तो यह पहले से ही निष्कर्ष नहीं है कि भंडारण एक समस्या है। वास्तव में यह जानने के लिए कि आप क्या कर रहे हैं, आप फ़ाइल आँकड़ों को स्नैपशॉट करना शुरू कर सकते हैं, जैसा कि यहाँ दिखाया गया है, या आप वास्तविक समय में विलंबता को देखने के लिए केवल प्रदर्शन मॉनिटर का उपयोग कर सकते हैं। PerfMon में डेटा संग्राहक सेट बनाना बहुत आसान है जो भौतिक डिस्क काउंटर औसत को कैप्चर करता है। डिस्क सेकंड/पढ़ें और औसत। डेटाबेस फ़ाइलों को होस्ट करने वाले सभी डिस्क के लिए डिस्क सेक/रीड। डेटा कलेक्टर को नियमित आधार पर शुरू और बंद करने के लिए शेड्यूल करें, और प्रत्येक n . का नमूना लें सेकंड (उदाहरण के लिए 15), और एक बार उचित समय के लिए PerfMon डेटा कैप्चर करने के बाद, समय के साथ विलंबता की जांच करने के लिए इसे PAL के माध्यम से चलाएं।
यदि आप पाते हैं कि I/O विलंबता आपके सामान्य कार्यभार के दौरान होती है, न कि केवल I/O चलाने वाले रखरखाव कार्यों के दौरान, तो आप अभी भी भंडारण को अंतर्निहित समस्या के रूप में इंगित नहीं कर सकता। भंडारण विलंबता कई कारणों से मौजूद हो सकती है, जैसे:
- अक्षम क्वेरी योजनाओं या अनुपलब्ध अनुक्रमणिका के परिणामस्वरूप SQL सर्वर को बहुत अधिक डेटा पढ़ना पड़ता है
- इंस्टेंस के लिए बहुत कम मेमोरी आवंटित की जाती है और एक ही डेटा को डिस्क से बार-बार पढ़ा जाता है क्योंकि यह मेमोरी में नहीं रह सकता
- अंतर्निहित रूपांतरण अनुक्रमणिका या तालिका स्कैन का कारण बनते हैं
- जब सभी स्तंभों की आवश्यकता न हो, तो क्वेरी का चयन करें * प्रदर्शन करें
- अग्रेषित रिकॉर्ड समस्याओं को ढेर में अतिरिक्त I/O का कारण बनता है
- इंडेक्स फ़्रेग्मेंटेशन, पेज स्प्लिट्स, या गलत फिल फ़ैक्टर सेटिंग्स से कम पेज डेंसिटी के कारण अतिरिक्त I/O होता है
मूल कारण जो भी हो, प्रदर्शन के बारे में समझने के लिए क्या आवश्यक है - विशेष रूप से यह I/O से संबंधित है - यह है कि शायद ही कोई एक डेटा बिंदु है जिसका उपयोग आप समस्या को इंगित करने के लिए कर सकते हैं। वास्तविक मुद्दे को ढूँढ़ने के लिए कई तथ्यों की आवश्यकता होती है, जिन्हें एक साथ रखने पर, समस्या को उजागर करने में आपकी मदद मिलती है।
अंत में, ध्यान दें कि कुछ मामलों में भंडारण विलंबता पूरी तरह से स्वीकार्य हो सकती है। इससे पहले कि आप तेजी से भंडारण या कोड में बदलाव की मांग करें, डेटाबेस के लिए वर्कलोड पैटर्न और सर्विस लेवल एग्रीमेंट (एसएलए) की समीक्षा करें। डेटा वेयरहाउस के मामले में जो सेवाएं उपयोगकर्ताओं को रिपोर्ट करती हैं, प्रश्नों के लिए एसएलए शायद वही उप-सेकंड मान नहीं है जो आप उच्च-मात्रा वाले ओएलटीपी सिस्टम के लिए अपेक्षा करते हैं। DW समाधान में, एक सेकंड से अधिक I/O विलंबता पूरी तरह से स्वीकार्य और अपेक्षित हो सकती है। व्यवसाय और उसके उपयोगकर्ताओं की अपेक्षाओं को समझें, और फिर निर्धारित करें कि क्या कार्रवाई की जानी है, यदि कोई हो। और यदि परिवर्तन की आवश्यकता है, तो अपने तर्क का समर्थन करने के लिए आवश्यक मात्रात्मक डेटा एकत्र करें, अर्थात् प्रतीक्षा आँकड़े, आभासी फ़ाइल आँकड़े, और प्रदर्शन मॉनिटर से विलंबता।