इस लेख में, हम रीयल टाइम ऑपरेशनल एनालिटिक्स और OLTP डेटाबेस पर इस दृष्टिकोण को कैसे लागू करें, इस पर ध्यान देंगे। जब हम पारंपरिक विश्लेषणात्मक मॉडल को देखते हैं, तो हम देख सकते हैं कि OLTP और विश्लेषणात्मक वातावरण अलग-अलग संरचनाएं हैं। सबसे पहले, पारंपरिक विश्लेषणात्मक मॉडल वातावरण को ईटीएल (एक्सट्रैक्ट, ट्रांसफॉर्म और लोड) कार्यों को बनाने की आवश्यकता होती है। क्योंकि हमें ट्रांजेक्शनल डेटा को डेटा वेयरहाउस में ट्रांसफर करने की आवश्यकता होती है। इस प्रकार की वास्तुकला के कुछ नुकसान हैं। वे लागत, जटिलता और डेटा विलंबता हैं। इन कमियों को दूर करने के लिए हमें एक अलग दृष्टिकोण की आवश्यकता है।
रीयल टाइम ऑपरेशनल एनालिटिक्स
Microsoft ने SQL सर्वर 2016 में रीयल-टाइम ऑपरेशनल एनालिटिक्स की घोषणा की। इस सुविधा की क्षमता बिना किसी प्रदर्शन समस्या के ट्रांजेक्शनल डेटाबेस और विश्लेषणात्मक क्वेरी वर्कलोड को संयोजित करना है। रीयल-टाइम ऑपरेशनल एनालिटिक्स प्रदान करता है:
- संकर संरचना
- लेन-देन संबंधी और विश्लेषण संबंधी क्वेरी एक ही समय में निष्पादित की जा सकती हैं
- किसी भी प्रदर्शन और विलंबता के मुद्दों का कारण नहीं बनता है।
- एक सरल कार्यान्वयन।
यह सुविधा पारंपरिक विश्लेषणात्मक वातावरण की कमियों को दूर कर सकती है। इस सुविधा का मुख्य विषय यह है कि कॉलम स्टोर इंडेक्स लेनदेन प्रणाली के प्रदर्शन को प्रभावित किए बिना डेटा की एक प्रति रखता है। यह विषय विश्लेषणात्मक प्रश्नों को प्रदर्शन को प्रभावित किए बिना निष्पादित करने की अनुमति देता है। तो यह प्रदर्शन प्रभाव को कम करता है। इस सुविधा की मुख्य सीमा यह है कि हम विभिन्न डेटा स्रोतों से डेटा एकत्र नहीं कर सकते।
गैर-संकुल कॉलम स्टोर इंडेक्स
SQL सर्वर 2016 अद्यतन करने योग्य "नॉन-क्लस्टर्ड कॉलम स्टोर इंडेक्स" पेश करता है। नॉन-क्लस्टर्ड कॉलम स्टोर इंडेक्स एक कॉलम-आधारित इंडेक्स है जो विश्लेषणात्मक प्रश्नों के लिए प्रदर्शन लाभ प्रदान करता है। यह सुविधा हमें रीयल टाइम ऑपरेशनल एनालिटिक्स फ्रेमवर्क बनाने देती है। इसका मतलब है कि हम एक ही समय में लेनदेन और विश्लेषणात्मक प्रश्नों को निष्पादित कर सकते हैं। विचार करें कि हमें मासिक कुल बिक्री की आवश्यकता है। एक पारंपरिक मॉडल में, हमें ईटीएल कार्यों, डेटा मार्ट और डेटा वेयरहाउस को विकसित करना होगा। लेकिन रीयल टाइम ऑपरेशनल एनालिटिक्स में, हम इसे बिना किसी डेटा वेयरहाउस या OLTP संरचना में किसी भी बदलाव की आवश्यकता के बिना कर सकते हैं। हमें केवल उपयुक्त गैर-संकुल कॉलम स्टोर इंडेक्स बनाने की आवश्यकता है।
गैर-क्लस्टर किए गए कॉलम स्टोर इंडेक्स का आर्किटेक्चर
आइए जल्द ही गैर-संकुल कॉलम स्टोर इंडेक्स और रनिंग मैकेनिज्म की वास्तुकला को देखें। गैर-संकुलित स्तंभ संग्रह अनुक्रमणिका में अंतर्निहित तालिका के किसी भाग या सभी पंक्तियों और स्तंभों की एक प्रति होती है। गैर-संकुल कॉलम स्टोर इंडेक्स का मुख्य विषय डेटा की एक प्रति बनाए रखना और डेटा की इस प्रति का उपयोग करना है। तो यह तंत्र लेनदेन संबंधी डेटाबेस प्रदर्शन प्रभाव को कम करता है। गैर-संकुलित स्तंभ संग्रह अनुक्रमणिका एक या एक से अधिक स्तंभ बना सकता है और स्तंभों पर फ़िल्टर लागू कर सकता है।
जब हम एक तालिका में एक नई पंक्ति सम्मिलित करते हैं जिसमें एक गैर-क्लस्टर कॉलम स्टोर इंडेक्स होता है, तो सबसे पहले, SQL सर्वर एक "पंक्ति समूह" बनाता है। रोग्रुप एक तार्किक संरचना है जो पंक्तियों के एक समूह का प्रतिनिधित्व करती है। फिर SQL सर्वर इन पंक्तियों को अस्थायी संग्रहण में संग्रहीत करता है। इस अस्थायी भंडारण का नाम "डेल्टास्टोर" है। SQL सर्वर इस अस्थायी भंडारण क्षेत्र का उपयोग करता है क्योंकि यह तंत्र संपीड़न अनुपात में सुधार करता है और सूचकांक विखंडन को कम करता है। जब पंक्तियों की संख्या 1,048,577 हो जाती है, तो SQL सर्वर पंक्ति समूह की स्थिति को बंद कर देता है। SQL सर्वर इस पंक्ति समूह को संपीड़ित करता है और स्थिति को "संपीड़ित" में बदल देता है।
अब, हम एक टेबल बनाएंगे और नॉन-क्लस्टर्ड कॉलम स्टोर इंडेक्स जोड़ेंगे।
ड्रॉप टेबल अगर मौजूद है एनालिसिस_टेबलटेस्टक्रिएट टेबल एनालिसिस_टेबलटेस्ट(आईडी INT प्राथमिक कुंजी पहचान(1,1),Continent_Name VARCHAR(20),देश_नाम VARCHAR(20),City_Name VARCHAR(20),Sales_Amnt INT,Profit_Amnt INT)GO > [dbo] परगैर-क्लस्टर किए गए कॉलमस्टोर इंडेक्स [NonClusteredColumnStoreIndex] बनाएं।इस चरण में, हम कई पंक्तियाँ सम्मिलित करेंगे और गैर-संकुलित स्तंभ संग्रह अनुक्रमणिका के गुणों को देखेंगे।
INSERT INTO Analysis_TableTest VALUES('Europe','जर्मनी','Munich','100','12')INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200',' 24') INSERT INTO Analysis_TableTest VALUES ('यूरोप', 'फ्रांस', 'पेरिस', '190', '23') INSERT INTO Analysis_TableTest VALUES ('अमेरिका', 'यूएसए', 'न्यूयॉर्क', '180', ' 19')INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')GOयह क्वेरी पंक्ति समूह की स्थिति, पंक्तियों की कुल संख्या और अन्य मान प्रदर्शित करेगी।
चुनें i.object_id, object_name(i.object_id) AS TableName, i.name AS IndexName, i.index_id, i.type_desc, CSRowGroups.*, 100*(total_rows - ISNULL(deleted_rows,0))/total_rows AS I.object_id =CSRowGroups.object_id और i.index_id =CSRowGroups.index_id> पर sys.column_store_row_groups के रूप में sys.column_store_row_groups के रूप में शामिल होने के रूप में प्रतिशतपूर्ण;
ऊपर की छवि हमें डेल्टास्टोर स्थिति और पंक्तियों की कुल संख्या दिखाती है जो संकुचित नहीं हैं। अब हम तालिका में अधिक डेटा पॉप्युलेट करेंगे और जब पंक्तियों की संख्या 1,048,577 हो जाएगी, तो SQL सर्वर पहले पंक्ति समूह को बंद कर देगा और एक नया पंक्ति समूह खोल देगा।
INSERT INTO Analysis_TableTest VALUES('Europe','जर्मनी','Munich','100','12')INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200',' 24') INSERT INTO Analysis_TableTest VALUES ('यूरोप', 'फ्रांस', 'पेरिस', '190', '23') INSERT INTO Analysis_TableTest VALUES ('अमेरिका', 'यूएसए', 'न्यूयॉर्क', '180', ' 19')INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')GO 2000000
SQL सर्वर इस पंक्ति समूह को संपीड़ित करेगा और एक नया पंक्ति समूह बनाएगा। "COMPRESSION_DELAY" विकल्प हमें यह नियंत्रित करने की अनुमति देता है कि बंद स्थिति में पंक्ति समूह कितने समय तक प्रतीक्षा करता है।
जब हम इंडेक्स मेनटेन कमांड चलाते हैं (पुनर्गठन, पुनर्निर्माण) हटाई गई पंक्तियों को भौतिक रूप से हटा दिया जाता है और इंडेक्स को डीफ़्रैग किया जाता है।
जब हम इस तालिका में कुछ पंक्तियों को अपडेट (डिलीट + इंसर्ट) करते हैं, तो हटाई गई पंक्तियों को "डिलीट" के रूप में चिह्नित किया जाता है और नई अपडेट की गई पंक्तियों को डेल्टास्टोर में डाला जाता है।
विश्लेषणात्मक क्वेरी प्रदर्शन बेंचमार्क
इस शीर्षक में, हम विश्लेषण_टेबलटेस्ट तालिका में डेटा को पॉप्युलेट करेंगे। मैंने 4 मिलियन रिकॉर्ड डाले। (आपको अपने परीक्षण वातावरण में इस चरण और अगले चरणों का परीक्षण करना होगा। प्रदर्शन संबंधी समस्याएं हो सकती हैं और DBCC DROPCLEANBUFFERS कमांड भी प्रदर्शन को नुकसान पहुंचा सकती है। यह आदेश बफर पूल पर सभी बफर डेटा को हटा देगा।)
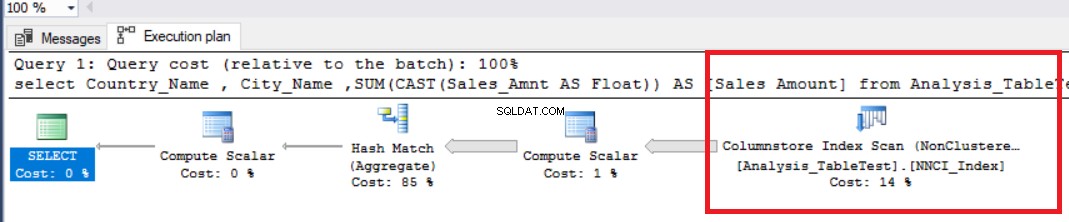
अब हम निम्नलिखित विश्लेषणात्मक क्वेरी चलाएंगे और प्रदर्शन मूल्यों की जांच करेंगे।
सेट स्टेटिस्टिक्स टाइम ऑनसेट स्टैटिस्टिक्स IO ONDBCC DROPCLEANBUFFERSदेश_नाम, शहर_नाम, SUM (CAST(Sales_Amnt AS फ्लोट) का चयन करें) AS [बिक्री राशि] द्वारा Analysis_TableTest समूह द्वारा Country_Name, City_Name
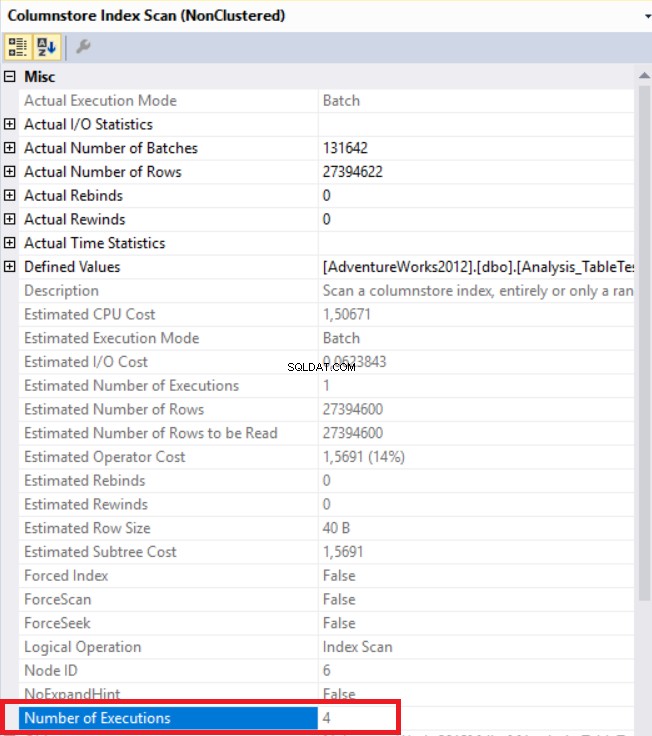
ऊपर की छवि में, हम गैर-संकुल कॉलम स्टोर इंडेक्स स्कैन ऑपरेटर देख सकते हैं। नीचे दी गई तालिका सीपीयू और निष्पादन समय दिखाती है। यह क्वेरी CPU में 1.765 मिलीसेकंड की खपत करती है और 0.791 मिलीसेकंड में पूरी होती है। CPU समय बीता हुआ समय से अधिक है क्योंकि निष्पादन योजना समानांतर प्रोसेसर का उपयोग करती है और कार्यों को 4 प्रोसेसर में वितरित करती है। हम इसे "कॉलमस्टोर इंडेक्स स्कैन" ऑपरेटर गुणों में देख सकते हैं। "निष्पादन की संख्या" मान यह इंगित करता है।
अब हम प्रोसेसर की संख्या को कम करने के लिए क्वेरी में एक संकेत जोड़ेंगे। हम कोई समानांतरवाद ऑपरेटर नहीं देखेंगे।
सेट स्टेटिस्टिक्स टाइम ऑनसेट स्टैटिस्टिक्स IO ONDBCC DROPCLEANBUFFERSदेश_नाम, सिटी_नाम, SUM (CAST (Sales_Amnt AS फ्लोट) का चयन करें) AS [बिक्री राशि] द्वारा Analysis_TableTest समूह द्वारा Country_Name, City_NameOPTION (MAXDOP 1)
नीचे दी गई तालिका निष्पादन समय को परिभाषित करती है। इस चार्ट में, हम देख सकते हैं कि बीता हुआ समय CPU समय से अधिक है क्योंकि SQL सर्वर केवल एक प्रोसेसर का उपयोग करता है।
अब हम गैर-क्लस्टर किए गए कॉलम स्टोर इंडेक्स को अक्षम कर देंगे और उसी क्वेरी को निष्पादित करेंगे।
ALTER INDEX [NNCI_Index] ऑन [dbo]। 1)
उपरोक्त तालिका से पता चलता है कि गैर-संकुलित कॉलम स्टोर इंडेक्स विश्लेषणात्मक प्रश्नों में अविश्वसनीय प्रदर्शन प्रदान करता है। लगभग, कॉलम स्टोर अनुक्रमित क्वेरी अन्य की तुलना में पांच गुना बेहतर है।
निष्कर्ष
रीयल-टाइम ऑपरेशनल एनालिटिक्स अविश्वसनीय लचीलापन प्रदान करता है क्योंकि हम बिना किसी डेटा विलंबता के OLTP सिस्टम में विश्लेषणात्मक प्रश्नों को निष्पादित कर सकते हैं। साथ ही, ये विश्लेषणात्मक क्वेरी OLTP डेटाबेस के प्रदर्शन को प्रभावित नहीं करती हैं। यह सुविधा हमें एक ही वातावरण में लेन-देन संबंधी डेटा और विश्लेषणात्मक प्रश्नों को प्रबंधित करने की क्षमता देती है।
संदर्भ
कॉलम स्टोर इंडेक्स - डेटा लोडिंग गाइडेंस
रीयल टाइम ऑपरेशनल एनालिटिक्स के लिए कॉलम स्टोर के साथ शुरुआत करें
रीयल-टाइम ऑपरेशनल एनालिटिक्स
आगे पढ़ना:
SQL सर्वर इंडेक्स बैकवर्ड स्कैन:अंडरस्टैंडिंग, ट्यूनिंग
SQL सर्वर मेमोरी-ऑप्टिमाइज़्ड टेबल्स में इंडेक्स का उपयोग करना